
一、前言
CNN 的发展历程可以追溯到 20 世纪 80 年代和 90 年代。受生物视觉系统的启发,研究人员开始探索如何构建专门用于处理图像数据的神经网络。早期的一些研究奠定了基础,例如 Fukushima 提出的 Neocognitron 模型。 随着时间的推移,到了 21 世纪初,LeCun 等人提出了 LeNet-5,这是一个具有里程碑意义的 CNN 架构,成功应用于手写数字识别任务,为 CNN 在图像识别领域的广泛应用开启了大门。
二、CNN 的原理
(一)卷积层
卷积层是 CNN 的核心组件之一。它通过卷积核(滤波器)在图像上滑动,对局部区域进行特征提取。卷积核就像是一个小的特征探测器,不同的卷积核可以检测到图像中的不同特征,如边缘、纹理等。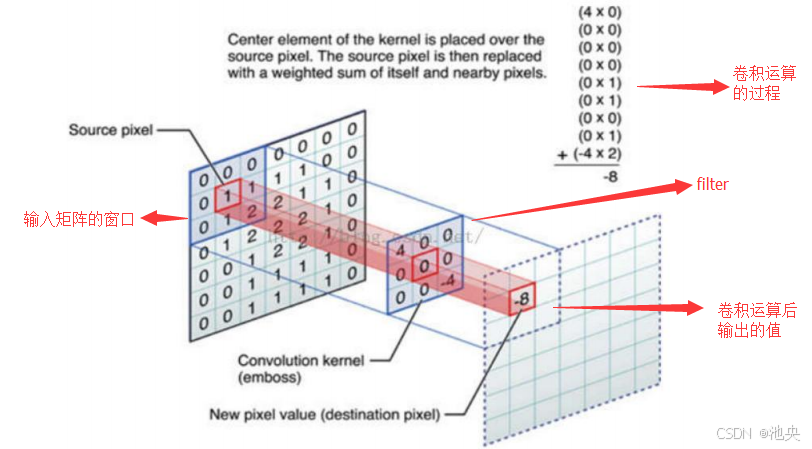
(二)池化层
池化层的主要作用是对特征图进行降维,减少计算量和参数数量,同时保留重要的特征信息。常见的池化操作有最大池化和平均池化。最大池化会在池化窗口内选取最大值作为输出,而平均池化则计算窗口内的平均值。
(三)全连接层
在经过多个卷积层和池化层后,通常会连接全连接层。全连接层将前面提取到的特征进行整合,通过神经元之间的全连接关系进行分类或回归等任务的处理。例如,在图像分类任务中,全连接层根据学习到的特征模式判断图像属于哪一个类别。
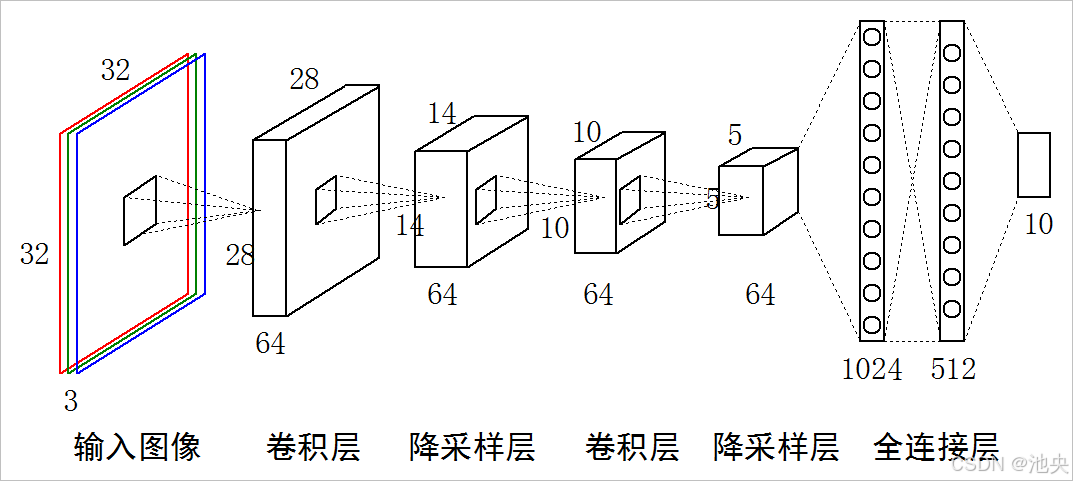
(四)激活函数
与普通神经网络类似,CNN 中也使用激活函数来引入非线性因素。常用的激活函数如 ReLU(Rectified Linear Unit),它在输入大于 0 时输出输入值,小于 0 时输出 0。ReLU 函数能够加速网络的训练,并且有效缓解梯度消失问题。
三、CNN 的实现
(一)选择深度学习框架
目前有许多强大的深度学习框架可供选择,如 TensorFlow、PyTorch 等。这些框架提供了丰富的函数和工具,方便我们构建 CNN 模型。以 TensorFlow 为例,它具有高效的计算图构建和执行能力,适合大规模的深度学习任务。
(二)数据准备
对于图像数据,首先需要进行数据预处理。这包括图像的读取、裁剪、缩放、归一化等操作。例如,将图像统一调整为相同的大小,将像素值归一化到 0 到 1 之间,同时划分训练集、验证集和测试集。
(三)构建模型
在 TensorFlow 中,可以使用 Keras 模块快速构建 CNN 模型。首先定义输入层,指定输入图像的形状。然后添加卷积层,设置卷积核的大小、数量和激活函数等参数。接着添加池化层,选择合适的池化方式和池化窗口大小。之后可以重复添加卷积层和池化层以提取更复杂的特征。最后添加全连接层,并设置输出层的神经元数量和激活函数,用于最终的分类或回归任务。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 构建模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) # 第一个卷积层
model.add(MaxPooling2D((2, 2))) # 第一个池化层
model.add(Conv2D(64, (3, 3), activation='relu')) # 第二个卷积层
model.add(MaxPooling2D((2, 2))) # 第二个池化层
model.add(Flatten()) # 展平层,将多维特征图转换为一维向量
model.add(Dense(128, activation='relu')) # 全连接层
model.add(Dense(10, activation='softmax')) # 输出层,用于 10 分类任务(四)模型训练
构建好模型后,需要选择合适的损失函数(如交叉熵损失函数用于分类任务)和优化器(如 Adam 优化器),然后使用训练数据对模型进行训练。在训练过程中,可以设置训练的轮数、批次大小等参数,并通过回调函数监控训练过程中的损失值和准确率等指标。
# 编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=32,
validation_data=(x_val, y_val))(五)模型评估与应用
训练完成后,使用测试集对模型进行评估,计算模型的准确率、召回率等指标,以评估模型的性能。如果模型性能满足要求,就可以将其应用于实际的图像识别或处理任务中,例如对新的图像进行分类预测。
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test)
# 预测
predictions = model.predict(x_new_images)