一、引言
自然语言处理作为人工智能领域的关键分支,致力于使计算机能够理解、分析和生成人类语言。近年来,随着深度学习技术的迅猛发展,自然语言处理取得了前所未有的突破,一系列创新技术和应用不断涌现,极大地推动了人机交互、信息检索、智能客服等众多领域的进步。
二、自然语言处理基础任务与传统方法
(一)文本分类
文本分类是 NLP 中的常见任务,例如将新闻文章分类为政治、体育、娱乐等类别。传统的文本分类方法常基于特征工程,如词袋模型(Bag of Words)和 TF-IDF(Term Frequency-Inverse Document Frequency)。以下是一个简单的基于词袋模型和朴素贝叶斯分类器的文本分类代码示例:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 示例文本数据
texts = ["这是一篇体育新闻,讲述了一场精彩的足球比赛。",
"政治新闻:关于国家领导人的重要会议报道。",
"娱乐新闻:某明星的新电影即将上映。"]
labels = ["体育", "政治", "娱乐"]
# 构建词袋模型
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
# 训练朴素贝叶斯分类器
clf = MultinomialNB()
clf.fit(X, labels)
# 测试数据
test_text = "今天有一场盛大的演唱会,众多明星齐聚。"
test_X = vectorizer.transform([test_text])
predicted_label = clf.predict(test_X)
print("预测标签:", predicted_label)
# 评估模型(在完整数据集上)
# 假设这里有完整的训练集和测试集 X_train, X_test, y_train, y_test
# clf.fit(X_train, y_train)
# y_pred = clf.predict(X_test)
# accuracy = accuracy_score(y_test, y_pred)
# print("准确率:", accuracy)(二)命名实体识别(NER)
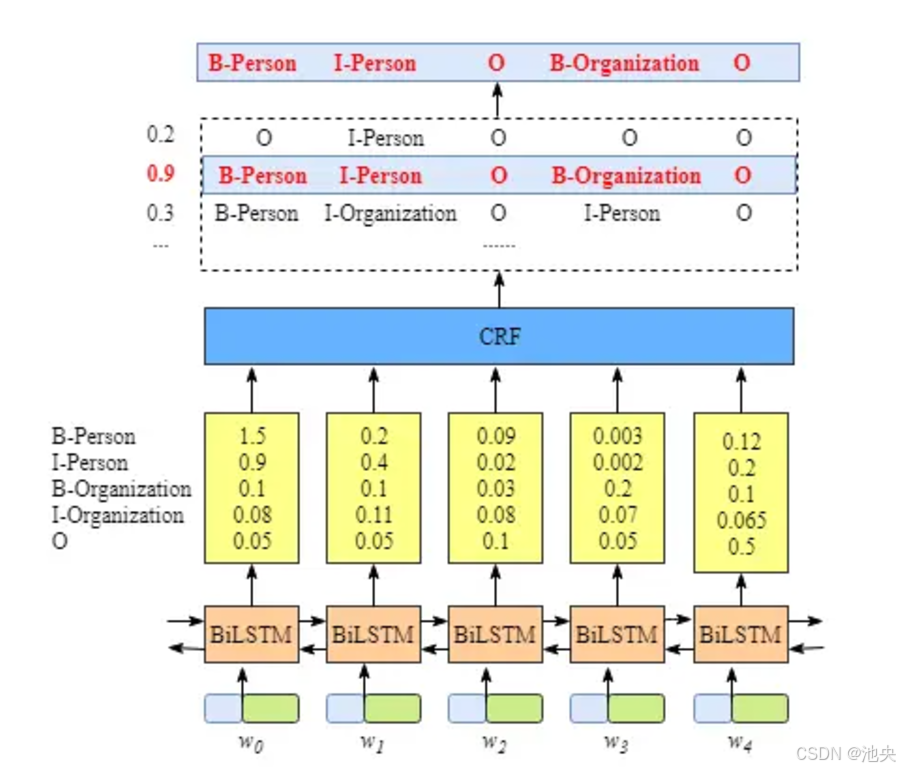
命名实体识别旨在识别文本中的人名、地名、组织机构名等实体。传统方法多采用基于规则和统计的模型,如隐马尔可夫模型(HMM)和条件随机域(CRF)。以下是一个基于 CRF 的命名实体识别代码框架:
import nltk
from sklearn_crfsuite import CRF
# 示例句子
sentence = "苹果公司在加利福尼亚州发布了新款 iPhone。"
# 定义特征提取函数
def word2features(sent, i):
word = sent[i]
features = {
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle()
}
if i > 0:
prev_word = sent[i - 1]
features.update({
'-1:word.lower()': prev_word.lower(),
'-1:word.istitle()': prev_word.istitle()
})
else:
features['BOS'] = True # 句子开头标记
if i < len(sent) - 1:
next_word = sent[i + 1]
features.update({
'+1:word.lower()': next_word.lower(),
'+1:word.istitle()': next_word.istitle()
})
else:
features['EOS'] = True # 句子结尾标记
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
# 这里假设已经有标注好的标签数据,实际应用中需要标注或使用已有的标注数据集
return ["ORG" if word == "苹果公司" else "LOC" if word == "加利福尼亚州" else "O" for word in sent]
# 提取特征和标签
X = [sent2features(nltk.word_tokenize(sentence))]
y = [sent2labels(nltk.word_tokenize(sentence))]
# 训练 CRF 模型
crf = CRF()
crf.fit(X, y)
# 预测
predicted_labels = crf.predict(X)
print("预测的命名实体标签:", predicted_labels)三、神经网络在自然语言处理中的应用
(一)循环神经网络(RNN)及其变体
循环神经网络在处理序列数据方面具有天然的优势,其能够保留序列中的上下文信息。长短期记忆网络(LSTM)和门控循环单元(GRU)是 RNN 的重要变体,有效解决了传统 RNN 的梯度消失和梯度爆炸问题。以下是一个基于 LSTM 的文本生成代码示例:
import torch
import torch.nn as nn
# 定义 LSTM 文本生成模型
class LSTMTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(LSTMTextGenerator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden):
x = self.embedding(x)
output, hidden = self.lstm(x, hidden)
output = self.fc(output)
return output, hidden
def init_hidden(self, batch_size):
return (torch.zeros(1, batch_size, self.lstm.hidden_size),
torch.zeros(1, batch_size, self.lstm.hidden_size))
# 示例数据准备(这里简化为一个小的词汇表和文本序列)
vocab = ['我', '爱', '自然', '语言', '处理']
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
text = "我爱自然语言"
input_sequence = [word_to_idx[word] for word in text]
input_tensor = torch.tensor([input_sequence])
# 模型参数设置
vocab_size = len(vocab)
embedding_dim = 10
hidden_dim = 20
# 初始化模型
model = LSTMTextGenerator(vocab_size, embedding_dim, hidden_dim)
# 训练模型(这里省略训练循环,仅展示前向传播)
hidden = model.init_hidden(1)
output, hidden = model(input_tensor, hidden)
# 生成文本
generated_text = []
input_word = input_sequence[-1]
for _ in range(5): # 生成 5 个单词
input_tensor = torch.tensor([[input_word]])
output, hidden = model(input_tensor, hidden)
# 选择概率最高的单词作为下一个单词
topv, topi = output.topk(1)
input_word = topi.item()
generated_text.append(idx_to_word[input_word])
print("生成的文本:", ''.join(generated_text))(二)卷积神经网络(CNN)在 NLP 中的应用
卷积神经网络在自然语言处理中也有广泛应用,可用于文本分类、情感分析等任务。它通过卷积层提取文本的局部特征,然后通过池化层进行特征融合。以下是一个简单的基于 CNN 的文本分类代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.data import Field, TabularDataset, BucketIterator
# 定义文本字段和标签字段
TEXT = Field(sequential=True, lower=True, batch_first=True)
LABEL = Field(sequential=False, use_vocab=False, batch_first=True)
# 加载数据集(假设已经有数据文件 'data.csv',格式为'text,label')
fields = [('text', TEXT), ('label', LABEL)]
train_data, test_data = TabularDataset.splits(
path='.', train='data.csv', test='test.csv', format='csv', fields=fields)
# 构建词汇表
TEXT.build_vocab(train_data)
# 定义 CNN 模型
class CNNTextClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_filters, filter_sizes, output_dim):
super(CNNTextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(1, num_filters, (fs, embedding_dim)) for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * num_filters, output_dim)
def forward(self, x):
x = self.embedding(x)
# x: [batch_size, seq_len, embedding_dim]
x = x.unsqueeze(1)
# x: [batch_size, 1, seq_len, embedding_dim]
conved = [F.relu(conv(x)).squeeze(3) for conv in self.convs]
# conved: [batch_size, num_filters, seq_len - filter_size + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled: [batch_size, num_filters]
cat = torch.cat(pooled, dim=1)
# cat: [batch_size, num_filters * len(filter_sizes)]
return self.fc(cat)
# 模型参数设置
vocab_size = len(TEXT.vocab)
embedding_dim = 100
num_filters = 100
filter_sizes = [3, 4, 5]
output_dim = 2 # 假设二分类任务
# 初始化模型
model = CNNTextClassifier(vocab_size, embedding_dim, num_filters, filter_sizes, output_dim)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 训练模型(这里省略完整训练循环)
for epoch in range(10):
for batch in BucketIterator(train_data, batch_size=64, shuffle=True):
optimizer.zero_grad()
text = batch.text
label = batch.label
output = model(text)
loss = criterion(output, label)
loss.backward()
optimizer.step()
# 测试模型(这里省略完整测试过程)
# 计算准确率等指标四、预训练模型:BERT 与 GPT 等
(一)BERT(Bidirectional Encoder Representations from Transformers)
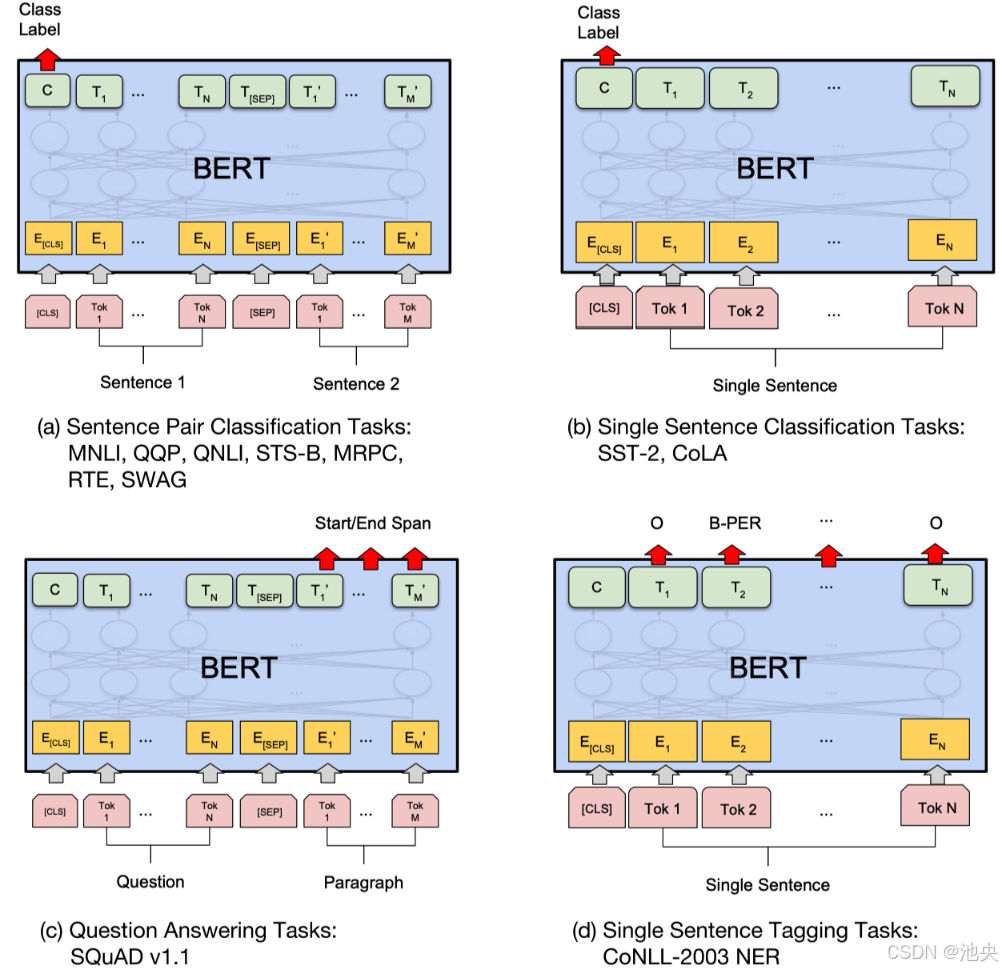
BERT 模型基于 Transformer 架构,通过大规模语料库的预训练,学习到了丰富的语言表示。它在多个自然语言处理任务上取得了 state-of-the-art 的成果,如文本分类、问答系统等。以下是一个使用 BERT 进行文本分类的简单示例:
import torch
from transformers import BertTokenizer, BertForSequenceClassification
# 加载预训练的 BERT 分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
# 示例文本
text = "这部电影非常精彩,值得一看。"
# 文本预处理
encoded_text = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=128,
padding='max_length',
return_attention_mask=True,
return_tensors='pt'
)
input_ids = encoded_text['input_ids']
attention_mask = encoded_text['attention_mask']
# 模型预测
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs[0]
predicted_class = torch.argmax(logits, dim=1).item()
print("预测类别:", predicted_class)(二)GPT(Generative Pretrained Transformer)
GPT 系列模型专注于生成任务,通过自监督学习方式在大规模文本上进行预训练。它能够根据给定的上下文生成连贯的文本。以下是一个使用 GPT-2 生成文本的示例:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 加载 GPT-2 分词器和模型
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 示例上下文
context = "在美丽的森林中,"
# 生成文本
input_ids = tokenizer.encode(context, return_tensors='pt')
output = model.generate(
input_ids,
max_length=50,
num_return_sequences=1,
no_repeat_ngram_size=2,
top_k=50,
top_p=0.95
)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("生成的文本:", generated_text)