恭迎首席

Hello,大家好,这篇博客我们就来为大家讲解一下C++中STL中的stack和queue类,stack和queue这两个类我们感觉不是很陌生,因为这两个类其实就是我们前面在数据结构部分所讲的栈和队列相关的内容。
温馨提示:如果大家还没有接触过数据结构中的栈和队列相关部分内容的话,大家可以先去看一下我前面写的那个关于栈和队列相关的博客,大家可以先去学习一下,再来看我们的这篇博客。链接如下:
 https://blog.csdn.net/2301_81390458/article/details/138822214?spm=1001.2014.3001.5501
https://blog.csdn.net/2301_81390458/article/details/138822214?spm=1001.2014.3001.5501除此之外,我还写过一篇有关栈部分的题目解析,大家如果想要去做一些题来检测一下自己的话,大家也可以去看看我的这一篇博客,如果没有兴趣的话,也可以不用看,本质上是不会影响我们大家去看这一篇博客的。链接如下:
目录
1 简单介绍
我们接下来的这篇博客所要讲的内容就是我们前面在数据结构部分已经讲过的stack和queue部分的内容,与之不同的是,我们这里来讲讲它的模板,这里模板的底层实现和我们在数据结构中所讲述的知识基本上是如出一辙的,主要还是以使用的讲解为主要讲解部分。
我在这里为大家推荐一个英语的相关网站,希望对大家在学习STL时能够有所帮助。
C/C++相关函数查询官网:Reference - C++ Reference
2 stack和queue的使用
2.1 stack(栈)

2.1.1 定义模板(后进先出)

template <class T, class Container = deque<T> >
class stack//我们在定义找这个模板的时候,发现后面多了"class Container = deque<T>"这一部分的内容,这个东西它本质上其实是一个容器(vector/list...这些都属于容器)。当我们从网上搜索一下我们这里所讲的stack或queue时,我们会发现网上说这个stack和queue均是容器适配器,和我们前面所学的list、vector有所不同(list和vector均是容器),什么意思呢?stack/queue和list/vector最大的区别就是容器的底层时我们自己单独设计的,而容器适配器的底层相当于是嵌套了一个容器,就比如说,我们正在讲解的这个stack类,它的底层其实就是嵌套了一个list类类型的对象。stack它支持后进先出的操作(我们这里先不管stack的底层结构是如何实现的,我们这里先看一下它的使用部分),我们来看一下stack类模板中的几个主要的成员函数。
2.1.2 constructor(stack的构造函数)

这个函数就是stack的构造函数,它在初始化的时候可以不用我们去进行传参,比如说,我刚刚开创了一个stack类类型的对象,如果我们不传参过去的话,编译器在对这个stack类类型的对象进行初始化操作时,会用这个对象中存储的元素的类型的默认初始化的值对这个对象进行初始化操作。(container_type就是上面定义模板中的第二个模板参数)
2.1.3 empty()函数

这个函数的主要作用就是判断栈是否为空,若为空,返回1,反之,返回0。
2.1.4 size()函数

这个函数的作用就是求出占中具体的数据个数,并将其作为返回值返回即可。
2.1.5 top()函数

这个函数的主要作用就是取出栈顶的元素,并将其作为返回值返回即可。
2.1.6 push()函数

这个函数的主要功能就是往栈中压入一个元素,将要压入的元素作为实参传过去,传给实参。
2.1.7 pop()函数

这个函数的主要作用是将栈顶的元素给删除掉。(还有一些成员函数,但是没有上面几个常用,因此这里就不写了)
(容器适配器都没有迭代器,只有容器才有迭代器)
int main()
{
stack<int> s;
s.push(1);//往s对象中插入一个int类型的元素1
s.push(2);//往s对象中插入一个int类型的元素2
s.push(3);//往s对象中插入一个int类型的元素3
s.push(4);//往s对象中插入一个int类型的元素4
s.push(5);//往s对象中插入一个int类型的元素5
//容器支持迭代器范围,容器适配器不支持迭代器范围,因此,我们这里就不通过打印s对象中的值来看结果了,等到最后我们统一调试来看效果。
s.pop();//删除栈顶元素,也就是删除5这个元素。
cout << s.size() << endl;//4;输出s对象中的元素个数
cout << s.empty() << endl;//0;说明s对象不为空
return 0;
}2.2 queue(队列)
我们这里要讲的这个队列,它其实和我们上面刚刚讲的那个stack在实现上基本是没有什么问题的,我们可以仿照stack中的使用去使用这个队列的相关知识,queue在本质上它其实也是属于容器适配器,而且它和stack一样,都不支持迭代器去访问元素,当然,如果不支持迭代器去访问的话,自然也就不支持范围for遍历。

我们通过上述的那张图片我们可以得知,queue的函数成员接口与stack的函数成员接口基本是相同的,因此,我们这里就不再进行讲解了,参考上面stack的讲解就可以了。
3 容器适配器
重点:容器适配器都没有迭代器,只有容器才有迭代器。
我们在2中了解到库中的这个stack和queue其实并不是一个容器,它们而是一个容器适配器,这里,我们就来讲解一下这个容器适配器。
3.1 容器适配器的介绍
什么是适配器:适配器是一种设计模式(设计模式是一套被反复使用的、多人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另一个接口,换句话说,就比如我们这里要实现一个stack(模拟实现),我们不会去像我们前面实现list\vector一样写一个类似于那样的类,而是将list\vector这样的类拿过来,我们放到stack中,也就是说,这个stack就是包装了一个list\vector类型的对象的类。
3.2 stack和queue类模板的底层实现
我们在STL中,并没有将它们划分在容器的行列,而是将它们划分在了容器适配器的里面,这是因为stack和queue他们的底层只是对其他容器的接口进行了包装,如stack类,它的内部其实就是封装了一个list\vector类型的对象,我们这个就暂时先说到这里,当我们在这里弄清楚了stack和queue的底层结构之后,,我们再来看它们的底层可以包装一些什么样的类。
OK,经过我们之前学习所积累的知识,我们这里可以使用list类或者是vector类来作为stack和queue底层包装的结构(这里我们以vector类为例来做解释),用vector类中的push_back成员函数来完成stack中的push操作,用vector类中的pop_back成员函数来完成stack中的pop操作...
3.3 deque的简单介绍(大致掌握一下即可)

deque还有一个名字,叫做双端队列,它在容器的队伍中,是一种双开口的"连续"空间的数据结构,说的稍微直白一点,其实就是vector和list这两个数据结构的结合体。当我们通过网站去看deque类的接口时,就会发现vector支持的但list不支持的,它支持,而list不支持的,但是vector支持的,它也支持,由此观之,它就是一个vector和list的缝合怪,比如说vector他不支持头插和头删(因为代价太大),而list不支持下标的随机访问(因为时间复杂度太大),而deque都支持,就说明它的效率还可以。既然说到这里了,那么我们先来这里介绍一下vector和list各自的优缺点吧!
1>. | vector | list
优点 | 1.尾插和尾删效率不错,支持下标 | 1.按需申请释放空间,不需要扩容。
| 的随机访问;2.物理空间连续,高度缓 | 2.任意位置均可插入删除。
| 存率高。 |
缺点 | 1.空间需要扩容,扩容有一点代价 | 1.不支持下标随机访问。
| (效率和空间浪费);2.头部和中间插 |
| 入效率低。 |
2>.我们接下来来看一下deque类的原理介绍:deque类它在底层是一段假象的连续空间,实际上却是分段连续的,也就是说,它的底层其实并不是一段真正连续的空间,而是由一段段连续的小空间拼接起来的,这些一段段的小空间其实均是由指针将其连接起来的,而这些指针全部都存放于一个中控数组(指针数组)中。
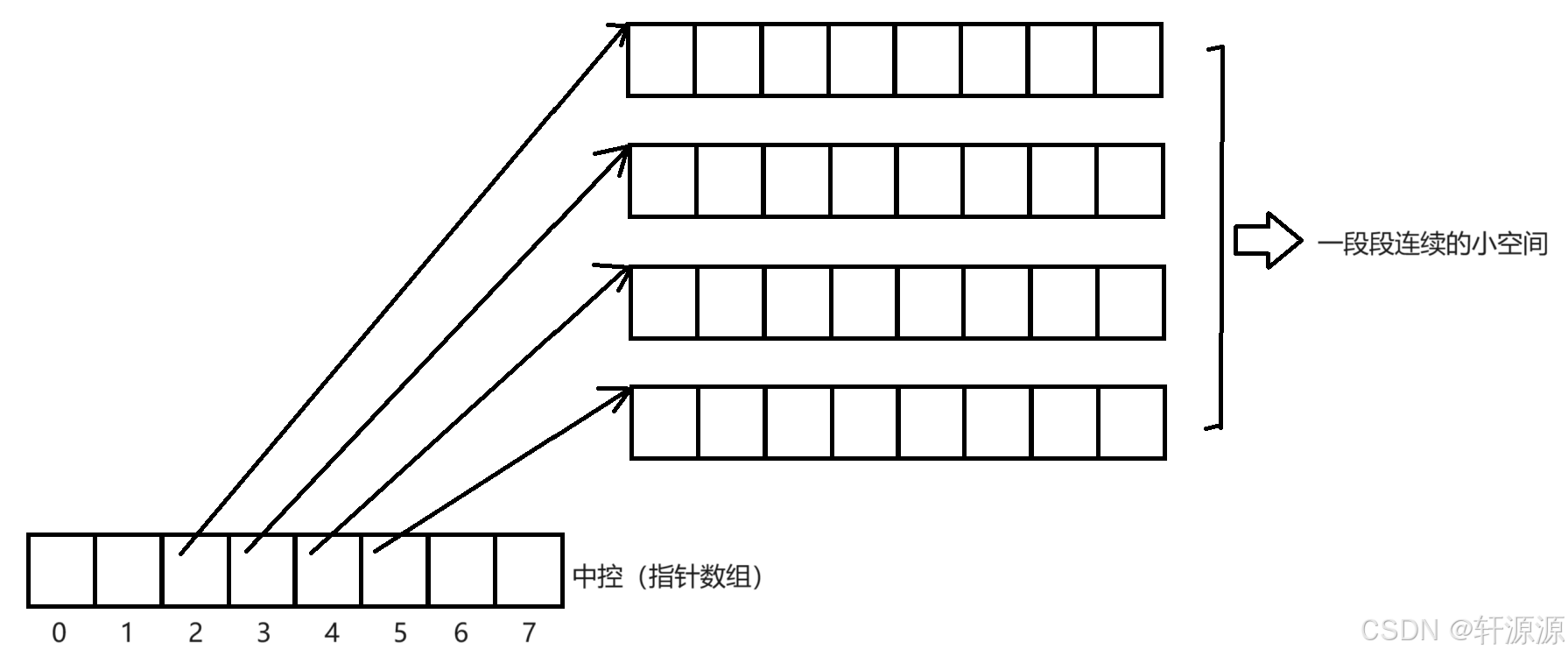
我们知晓了deque的底层结构后,接下来我们来看一下这个deque的底层实现(我们这里以上面那幅图为例,简单的做一个解析,我们假设上面的四个小段数组空间中的元素前三块已满了,最后一块空间差最后一个元素就满了)。
若要实现尾插操作,就会在中控数组的下一个位置(也就是下标为6的这个位置)插入一个指针,再开创一块新的大小相同的一小段数组空间。并让指针指向这一小段数组空间;若要头插,就在中控的前一个紧挨的位置(也就是下标为1的这个位置)插入一个指针,开创一块大小相同的一小段数组空间,让指针指向这一小块数组空间,大致思路就是如此,具体的一些小细节等有机会再说吧,毕竟这只是一个了解知识嘛。
我们在这里既然要实现一个容器,就必然少不了对迭代器这部分知识的学习,我们接下来就具体的来看一下deque中的迭代器相关的知识。
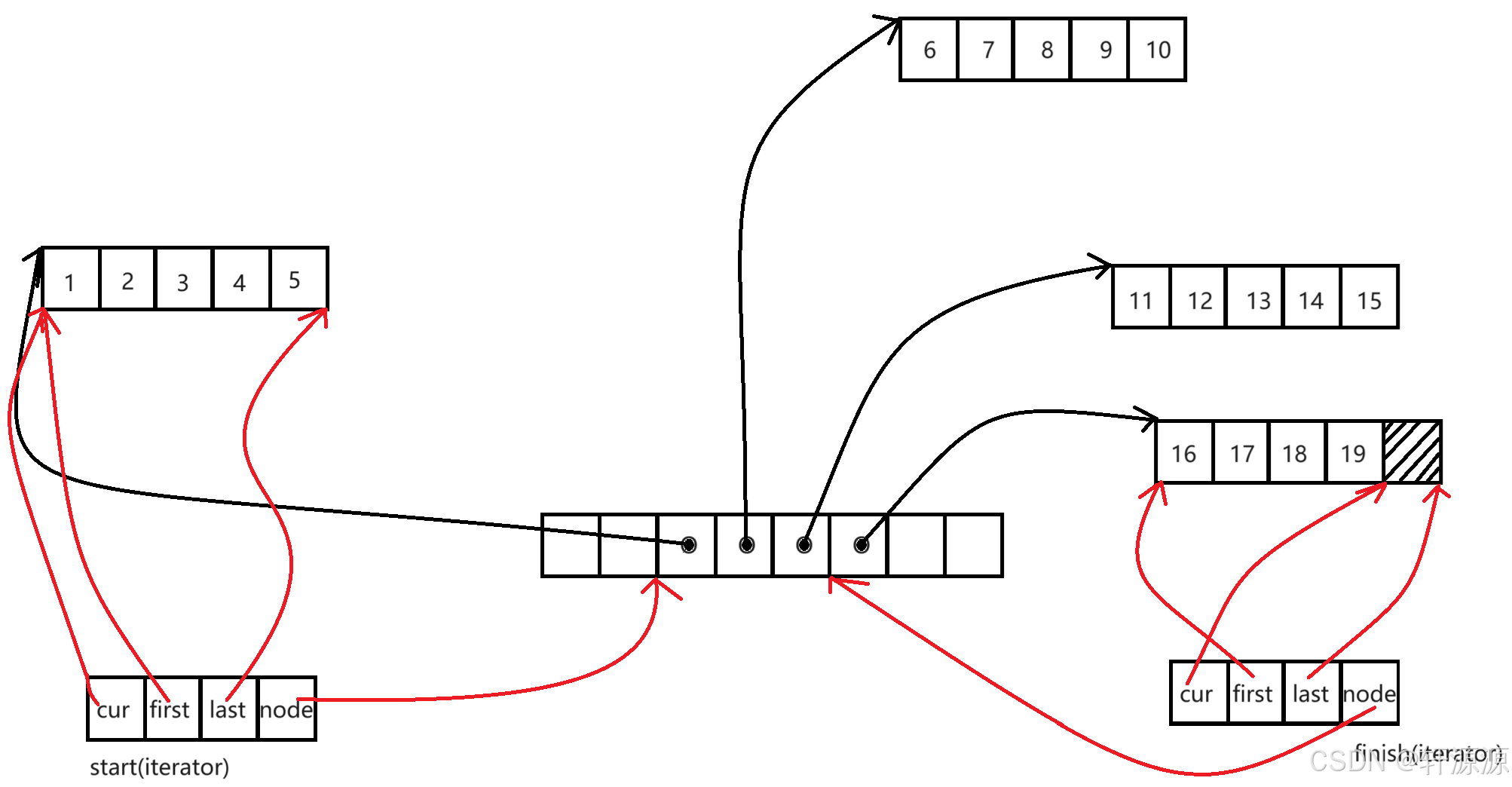
我们上述图(画的稍微有一点点抽象,希望大家将就一下,抱歉了)展示了deque类中start和finish迭代器(就相当于是我们vector/list中所讲的begin和end迭代器),deque类中的迭代器,它里面包含有四个成员变量,cur(一级指针)指向的是当前这个迭代器要访问的那个元素的地址,finish(一级指针)指向的是当前迭代器所指向的元素所在的那一小段数组空间的第一个元素的位置,last(一级指针)指向的是当前这个迭代器所指向的那个元素所在的那一小段数组空间的结束位置(最后一个元素的下一个位置),note(二级指针)指向的是当前这个迭代器所指向的那个元素所在的那一小段数组空间的那个指针的地址,迭代器++,实际上就只是迭代器中的cur这个成员变量在++,当我们想要去得到deque类类型的对象中的某一个元素的时候(假设求第i个位置上的元素,并且每小段空间中的元素个数是n个),它会先让i/n得到的结果就是这个元素位于第几段数字空间中,然后再求出i%n的结果,求出的结果就是在数字空间中的第几个元素,这样我们就可以得到我们想要的那个元素了。
既然我们对deque的底层实现有了一定的了解之后,接下来我们就来看一看deque的插入和删除操作,比如说我们想要在i这个位置前插入一个元素,这个位置在第二段的数组空间中,我们此时可以考虑只将第二个数组进行扩容操作,再扩容几个空间,但是这样的话就会造成一个问题,就是我们无法再次使用 " % " 和 " / " 来确定某一个元素了,因为这种方法的前提是必须保证每段数字空间的长度是一模一样的,若对其中的某一段空间进行扩容或者缩容操作的话,就会导致它们的长度不一样,无法使用 " % " 、" / " 这种方法得到某一个元素了,因此deque为了使访问元素变得高效,因此,deque在这里实现插入和删除这两个操作时就会移动元素,这样就使得删除和插入元素这两个操作的效率变得异常的低,但是其他的操作的效率就要高很多了。
OK了,关于deque的了解,我们就到这里了,具体的其中一些更小的细节我们就不做更深的讲解了,如果大家有兴趣的话,可以结合着网站去了解一下。
总结:1).deque的头插和尾插效率很高,而且更胜于vector和list。
2).下标随机访问的效率也还不错,但相比于vector还要略逊一筹。
3).中间插入删除效率很低,需要挪动数据,时间复杂度为O(N)。
3>.在(2>.)中,我们这里解释了deque的底层实现逻辑,现在我们回归主题,我们在前面讲到了stack和queue其实是容器适配器,它的内部其实是套了一个vector/list类的容器,至于具体封装的是一个什么样的容器,这得我们自己传参过去,如果我们传list过去,那么它的底层就套了一个list类类型的对象,若传vector过去,那么它的底层就套了一个vector类类型的对象,如果我们这里不传这个具体的容器的话,那么这里就会默认使用deque这个容器来作为stack和deque的底层容器,为什么是默认deque作为底层容器而不是vector/list呢?原因如下:
我们在这里讲解原因之前,先来回想一下stack和queue的特点,stack是一种后进先出的特殊的线性数据结构,因此只要具有push_back和pop_back操作的特殊线性数据结构,都可作为stack的底层容器,比如说vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以成为queue的底层容器,如list。上面所说的四种操作(push_back、pop_back、push_back、pop_front),我们在deque类中均有展现,并且效率都很高,原因:
1).stack和queue这两种数据结构,他们不需要去遍历,因此stack和queue没有迭代器,只需要在固定的一端或者两端进行操作即可。
2).在stack中元素增长时,deque比vector的效率高(扩容时不用搬移大量的数据)。deque中的元素增长时,deque不仅效率很高,而且内存使用率还很高,最重要的一点就是stack和queue是不用在中间的某一个地方去进行插入或者删除元素操作的。
综上所述,stack和queue这两个数据结构,它们结合了deque的优点,并且完美的避开了deque的缺点,因此这里我们默认它们的底层结构使用deque。讲到这里,这就说明我们这个stack和queue的讲解结束了。
4 priority_queue(优先级队列)
我们前面讲到了这里有关queue方面相关的一些知识,queue它是一个先进先出的数据结构,他不会在这里区分大小,一切均按顺序来,我们这里再来延伸一个与queue相关的内容,叫做priority_queue(优先级队列,它默认是大的优先),它和queue一样,都是同属于容器适配器这个队伍中的。
4.1 priority_queue的简介
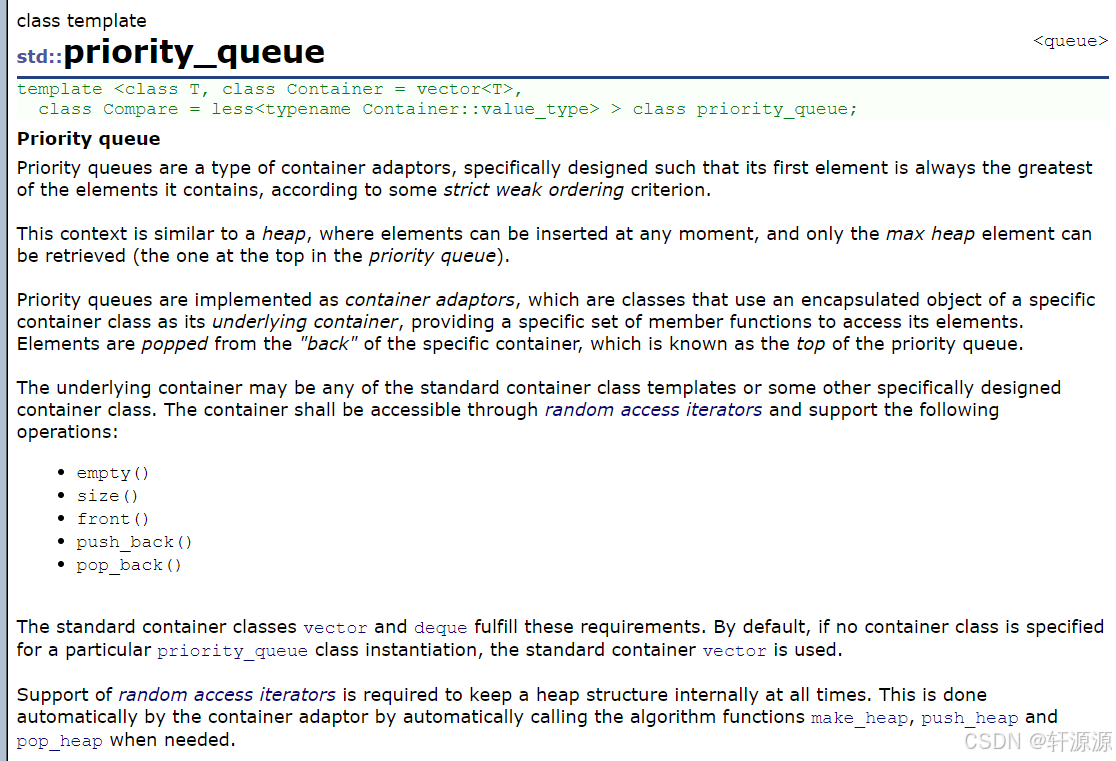
priority_queue它用汉语翻译过来之后,就是优先级队列的意思,当然,它的功能就和它的名字一样,入队列的时候还是和queue中的一样,出队列的时候就不是按照先进入队列的先出这个顺序了,而是优先级大的先出列,优先级小的后出列(优先级大指的是数据大)。
template <class T, class Container = vector<T>,class Compare = less<typename Container::value_type>>
class priority_queue;//我们这里定义了一个模板后,我们发现priority_queue的这个定义相较于queue来说多了一个仿函数的内容,而这里之所以会在这里一个多加一个仿函数的内容,完全是基于priority_queue的底层构建在这里实现的。4.2 priority_queue的底层构建
它这里的底层构建其实就是一个堆,它是一个容器适配器,它在底层实际是套了一个vector/list类(这里我们使用vector来说明更合适),而它的一些成员函数的操作实际上是调用库中的堆的相关操作,这个priority_queue的底层相比于queue而言,它就显得更为复杂了,也就是说,在这里,它的底层不仅嵌套了一个vector,而且还会去调用库中与堆相关的各种操作。
4.3 priority_queue的使用
接下来,我们通过代码的解释来展示这个使用的过程:
int main()
{
priority_queue<int> pq;
pq.push(4);//这里我们去调用push函数,实际上这里调用的是库中的堆的插入操作,去完成pq的这个插入元素的操作,插入到pq之后它就还是一个堆了。
pq.push(1);
pq.push(5);
pq.push(7);
pq.push(9);
//这里我们将pq对象中的元素一一打印出来,根据我们前面的讲解,这里打印出来的结果就应该是从大到小的顺序。
while (!pq.empty())
{
cout << pq.top() << " ";//输出这里面的堆顶元素(我们在学习这个priority_queue的时候,就可以把priority_queue想象成是一个堆来看)。
pq.pop();//删除堆顶元素。
}//9 7 5 4 1
return 0;
}4.4 priority_queue的模拟实现
接下来的模拟实现操作会用到堆方面的知识,如果大家有的还不是很了解的话,可以去看看我前面写的那篇和堆有关的博客,链接如下:
4.4.1 push()函数
void push(const T& x)//由于我们这个priority_queue它是一个容器适配器,它的底层是套了一个vector类类型的对象来实现这里的这个priority_queue类的,因此这个类的成员变量它就是一个vector类类型的对象,我们这里以_con(vector类类型的对象)来作为它的成员变量。
{
_con.push_back(x);
AdjustUp(_con.size() - 1);//传过去的是下标;调用AdjustUp这个函数,采用向上调整建堆的方法去对刚刚插入的那个元素的位置进行一个调整,使得_con始终是一个堆的结构,AdjustUp这个函数我们在这里并没有写(默认这个函数是真实存在的),若想了解这个函数的话,可以去看看我前面的那个有关对堆的博客。
}4.4.2 pop()函数
const T& top()
{
return _con[0];//我们在_con这个对象中是以堆的形式去存储的,因此优先级最高的那个,就必然在堆顶,也就是_con对象的首元素。
}4.4.3 pop()函数
void pop()
{
swap(_con[0], _con[_con.size() - 1]);//根据我们之前在数据结构中所学的知识,我们可以知道,要想pop掉堆顶元素的话,先让其与最后一个元素进行位置交换,之后再对其进行向下调整键堆的操作去进行,让其成为一个堆。
_con.pop_back();
AdjustDown(0);
}OK,我们在这里实现了priority_queue中最常用的3个操作。
4.5 仿函数
前面我们在这里讲解了priority_queue的使用以及它的模拟实现,但是这里的默认输出是降序的,如果我们这里想要输出升序的话,也就是对vector中的数据进行降序的操作,那就需要建一个小堆,这时,若想建成一个小堆,也就是按照升序的顺序在这里进行输出的话,这样我们就要用到一个叫仿函数的东西,接下来我们就来细细的讲解一下:
仿函数,它其实就是我们前面在写模板时的less<T>;说到仿函数这个概念,它本质上其实就是一个类,这个类它只重载了一个operator()成员函数,它定义出来的对象可以像函数一样使用,因此,它在这里才会被称之为是仿函数(我们这里通过展示代码来讲解这里的这个仿函数)。
首先,我们先来模拟实现两个仿函数:
template<class T>
class less//用于小于比较的仿函数
{
public:
bool operator()
{
return x < y;
}
};
template<class T>
class greater//用于大于比较的仿函数
{
public:
bool operator()
{
return x > y;
}
};以上就是我们这里模拟实现的库中最为常见的两个仿函数了,接下来,我们借助冒泡排序来讲解一下仿函数的使用:
template<class Compare>
void bubblesort(int* arr, int n, Compare com)//在开始写代码之前,我们先来解释一下bubblesort函数的形参:a是待排序的数组,n是a中要进行排序的数据的个数,Compare是仿函数的类型(可能是less<int>类型,也有可能是greater<int>类型,con它是类型为仿函数的一个对象)
{
for (int j = 0; j < n; j++)
{
for (int i = 1; i < n - j; i++)
{
if (com(arr[i], arr[i-1]))
{
swap(arr[i - 1], arr[i]);
}
}
}
}以上是我们模拟实现出来的一个冒泡排序的模板,接下来,我们来通过main函数来看看这个冒泡排序的输出结果:
int main()
{
int arr1[] = { 5,3,8,6,1,9,4,7 };
greater<int> great;
bubblesort(arr1, 8, great);
for (int i = 0; i < 8; i++)
{
cout << arr1[i] << " ";
}//9 8 7 6 5 4 3 1
cout << endl;
int arr2[] = { 5,3,8,6,1,9,4,7 };
less<int> les;
bubblesort(arr2, 8, les);
for (int i = 0; i < 8; i++)
{
cout << arr2[i] << " ";
}//1 3 4 5 6 7 8 9
return 0;
}通过上述main函数的输出结果可知,根据我们传过去的仿函数的不同,编译器输出的结果是不同的(这里我们就以less为例来作解析),我们这里传les(less<int>类类型的对象)过去,这样的话,上述的代码中的com就是一个less<int>类类型的对象,我们在代码中的com(arr[i], arr[i-1])这一句代码就会去调用less<int>类中的operator()成员函数,我们前面已经实现了less这个类模板了,根据实现可知operator()这个成员函数会去判断arr[i]和arr[i-1]这两个数谁大,如果arr[i] > arr[i-1]的话,就会去交换这两个元素,否则,不会交换,按照这个逻辑走的话,最后输出的确实是一个升序(传great过去也是这个逻辑)。
通过我们这里利用冒泡排序,我们会发现仿函数在这里可以使排序改变,也就是说可以改变排序的方向,我们在默认的情况下是排降序的,我们可以通过仿函数来排一个升序,既然如此,我们就可以在堆中使用仿函数来达到是建大堆,还是建小堆的效果,以此来决定priority_queue的输出结果是升序还是降序。
当我们讲到这里时,关于仿函数的知识其实还没有结束。在库中,我们是有专门的仿函数的,是不需要我们这里去自己实现的。但是即使库中有相应的仿函数,我们这里仍然有两种特殊的情况,需要我们自己去实现仿函数:
1>.类类型它不支持比大小。
2>.支持比较大小,但是比较的逻辑不是我们这里想要的这种逻辑,就比如以下代码:
int main()
{
priority_queue<date*> pq;
pq.push(new date(2018));//new这个函数返回的是一个地址。
pq.push(new date(2002));
pq.push(new date(2010));
pq.push(new date(2024));
for (int i = 0; i < 4; i++)
{
date* d=pq.top();
cout << d->_year<<" ";
pq.pop();
}
return 0;
}我们这里如果运行多次上述代码的话,就会发现每次输出的结果都是不一样的,输出5次就可能会出现5个不同的结果,之所以会出现这样的情况,归根结底还是因为new这个函数的返回值是一个地址,编译器每次在为我们这里的程序开空间时,空间的位置都是不确定的,因此才会出现这样的结果,也就是说,priority_queue的内部是根据地址的大小去建堆的(仿函数中是用两个地址de),但是这样显然是不行的,因此,基于这种情况,我们就需要自己去实现一个仿函数去进行传参了。
5 其他知识
我们这里来补充一下前面所讲述过的按需实例化的相关知识点,我们这里先说结论:类模板实例化是按需进行实例化操作的,使用哪些成员函数就实例化哪些成员函数,并不会将全部的成员函数均进行实例化操作,例如:
template<class T>
class date
{
public:
date(int year = 1)
:_year(year)
{ }
void func()
{
fas();//我们在date类中不写这个fas()函数,故意在这里写一个错误。
}
void print()
{
cout << _year << endl;
}
private:
int _year;
};
int main()
{
date<int> d;//当我们这里定义一个date类型的对象d时,我们发现编译器在这里并没有报错。
d.print();//编译器不会报错,print这个函数没有错误。
d.func();//编译器会报错,没有找到fas()这个成员函数,就此可以看出,我们在调用哪个成员函数的时候,编译器才会对该成员函数进行实例化并对其进行检查。
return 0;
}OK,今天我们就先讲到这里了,那么,我们下一篇再见,谢谢大家的支持!