前言
提醒:
文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。
其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展及意见建议,欢迎评论区讨论交流。
聚类算法
聚类算法在各种领域中有广泛的应用,主要用于发现数据中的自然分组和模式。以下是一些常见的应用场景以及每种算法的优缺点:
经典应用场景
-
市场细分:根据消费者的行为和特征,将他们分成不同的群体,以便进行有针对性的营销。
-
图像分割: 将图像划分为多个区域或对象,以便进行进一步的分析或处理。
-
社交网络分析:识别社交网络中的社区结构。
-
文档分类:自动将文档分组到不同的主题或类别中。
-
异常检测识别数据中的异常点或异常行为。
-
基因表达分析:在生物信息学中,根据基因表达模式对基因进行聚类。
聚合聚类(Agglomerative Clustering)
聚合聚类(Agglomerative Clustering)是一种常用的层次聚类方法。它通过自下而上的方式逐步合并数据点,形成一个树状的聚类结构(也称为树状图或 dendrogram)。以下是聚合聚类的优缺点:
优点
-
直观性: 层次聚类的树状图(dendrogram)提供了可视化的聚类结构,使得用户能直观了解数据的分层关系。
-
无须事先指定聚类数量: 聚合聚类在构建树状图的过程中,不需要事先指定聚类的数量,用户可以选择合适的切割点来决定最后的聚类数。
-
适用于任意形状的聚类:聚合聚类不依赖于特定的聚类形状,能够处理非球形的聚类结构,适用于复杂数据集。
-
灵活性:可以使用不同的距离度量(如欧几里得距离、曼哈顿距离等)和不同的合并策略(如单链接、全链接、中间链接等),以适应不同的数据分布。
-
适合小规模数据集:对于较小规模的数据集,聚合聚类能够有效地进行处理和分析。
缺点
-
计算复杂度高:聚合聚类的时间复杂度为 O ( n 3 ) O(n^3) O(n3),在处理大量数据时会变得非常慢。因此,它不适用于大规模数据集。
-
内存消耗大:需要存储所有数据点的距离矩阵,内存消耗较大,这在数据量大时会导致性能问题。
-
对噪声和离群点敏感:聚合聚类对噪声和离群点非常敏感,可能会影响最终的聚类结果,导致不准确的聚类。
-
合并策略的影响:不同的合并策略(如单链接、全链接等)可能会导致不同的聚类结果,因此正确的选择合并策略显得十分重要。
-
难以处理高维数据:在高维空间中,数据的距离度量可能失去意义,这可能导致聚类效果不佳。
总结
聚合聚类是一种强大且灵活的聚类方法,适合用于小规模数据集或需要可视化层次结构的情境。尽管存在一些限制(如高计算复杂度和对离群点敏感),在许多实际应用中仍然能够提供有效的聚类结果。选择合适的聚类方法需根据具体数据集的特性和分析目的来决定。
简单实例(函数库实现)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import AgglomerativeClustering
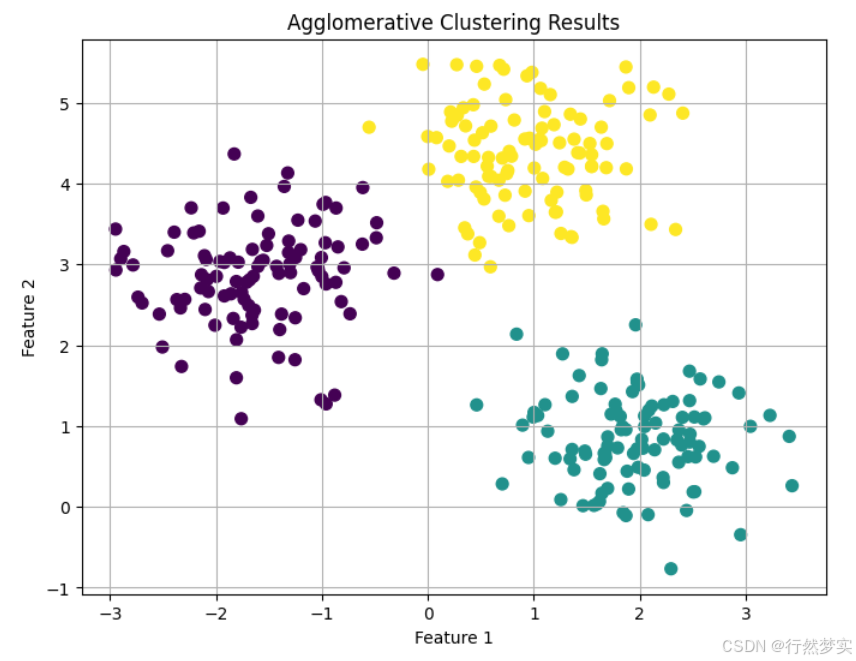
# 1. 生成模拟数据
# 使用 make_blobs 创建一个包含三个簇的数据集
X, _ = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)
# 2. 应用聚合聚类
# 使用 AgglomerativeClustering 进行聚类
agg_clustering = AgglomerativeClustering(n_clusters=3) # 这里指定聚类数量为3
labels = agg_clustering.fit_predict(X)
# 3. 可视化结果
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.title('Agglomerative Clustering Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.grid(True)
plt.show()
代码运行结果:
数学表达
聚合聚类(Agglomerative Clustering)是一种层次聚类方法,它通过逐步合并数据点或数据簇来构建聚类。这个过程可以用数学公式和概念进行解释,下面将详细说明。
- 基本概念
聚合聚类的基本思想是:
- 从每个数据点开始,每个点开始时都被视为一个独立的簇。
- 然后,找到最近的两个簇并将它们合并为一个新簇。
- 重复这一过程,直到满足停止条件(例如,达到指定的簇数量或距离阈值)。
- 距离度量
在聚合聚类中,首先需要定义簇之间的距离。常用的距离度量包括:
- 欧几里得距离:
d ( x i , x j ) = ∑ k = 1 n ( x i k − x j k ) 2 d(x_i, x_j) = \sqrt{\sum_{k=1}^{n} (x_{ik} - x_{jk})^2} d(xi,xj)=k=1∑n(xik−xjk)2
其中 x i x_i xi 和 x j x_j xj 是两个数据点, n n n 是数据的维度。- 曼哈顿距离:
d ( x i , x j ) = ∑ k = 1 n ∣ x i k − x j k ∣ d(x_i, x_j) = \sum_{k=1}^{n} |x_{ik} - x_{jk}| d(xi,xj)=k=1∑n∣xik−xjk∣- 簇间距离的定义
在合并簇时,需要定义如何计算两个簇之间的距离。常见的方法有:
- 单链接(Single Linkage):簇间距离为两个簇中最小距离。
d ( C i , C j ) = min x ∈ C i , y ∈ C j d ( x , y ) d(C_i, C_j) = \min_{x \in C_i, y \in C_j} d(x, y) d(Ci,Cj)=x∈Ci,y∈Cjmind(x,y)- 全链接(Complete Linkage):簇间距离为两个簇中最大距离。
d ( C i , C j ) = max x ∈ C i , y ∈ C j d ( x , y ) d(C_i, C_j) = \max_{x \in C_i, y \in C_j} d(x, y) d(Ci,Cj)=x∈Ci,y∈Cjmaxd(x,y)- 均值链接(Average Linkage):簇间距离为两个簇中所有点对的平均距离。
d ( C i , C j ) = 1 ∣ C i ∣ ⋅ ∣ C j ∣ ∑ x ∈ C i ∑ y ∈ C j d ( x , y ) d(C_i, C_j) = \frac{1}{|C_i| \cdot |C_j|} \sum_{x \in C_i} \sum_{y \in C_j} d(x, y) d(Ci,Cj)=∣Ci∣⋅∣Cj∣1x∈Ci∑y∈Cj∑d(x,y)- 聚类过程
- 初始化:每个数据点初始化为一个簇。
- 计算距离:计算当前所有簇之间的距离。
- 合并簇:
- 找到距离最小的两个簇 C i C_i Ci 和 C j C_j Cj。
- 合并这两个簇,形成新簇 C n e w = C i ∪ C j C_{new} = C_i \cup C_j Cnew=Ci∪Cj。
- 更新距离矩阵:更新新簇与其他簇的距离。
- 重复:重复步骤 2 到 4,直到达到设定的聚类数量或满足其他停止条件。
- 停止条件
聚合聚类可以在达到设定的簇数量(例如,我们希望将数据分为 K 个簇)之前停止,或者当两个簇之间的距离大于某个阈值时停止。- 结果表示
聚合聚类的结果可以用树状图(Dendrogram)表示,树状图展示了簇的合并过程及其相似性。
手动实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
def get_irregular_list_shape(two_d_list):
shape = []
for row in two_d_list:
shape.append(len(row))
return shape
class AgglomerativeClustering:
def __init__(self, n_clusters=2):
self.n_clusters = n_clusters
def fit(self, X):
self.X = X # 存储数据
n_samples = X.shape[0]
# 初始化每个点为一个单独的簇
self.clusters = [[i] for i in range(n_samples)]
# 计算初始距离矩阵
self.distance_matrix = self._compute_distance_matrix(X)
while len(self.clusters) > self.n_clusters:
# 找到最近的两个簇
min_distance = np.inf
to_merge = (0, 0)
for i in range(len(self.clusters)):
for j in range(i + 1, len(self.clusters)):
dist = self._linkage_distance(self.clusters[i], self.clusters[j])
if dist < min_distance:
min_distance = dist
to_merge = (i, j)
# 合并这两个簇
self._merge_clusters(to_merge[0], to_merge[1])
return self.clusters
def _compute_distance_matrix(self, X):
n_samples = X.shape[0]
distance_matrix = np.zeros((n_samples, n_samples))
for i in range(n_samples):
for j in range(n_samples):
if i != j:
distance_matrix[i][j] = np.linalg.norm(X[i] - X[j]) # 欧几里得距离
return distance_matrix
def _linkage_distance(self, cluster1, cluster2):
# 使用单链接
min_distance = np.inf
for i in cluster1:
for j in cluster2:
dist = np.linalg.norm(self.X[i] - self.X[j])
if dist < min_distance:
min_distance = dist
return min_distance
def _merge_clusters(self, cluster_idx1, cluster_idx2):
# 合并两个簇
self.clusters[cluster_idx1].extend(self.clusters[cluster_idx2])
# 删除已合并的簇
del self.clusters[cluster_idx2]
# 示例用法
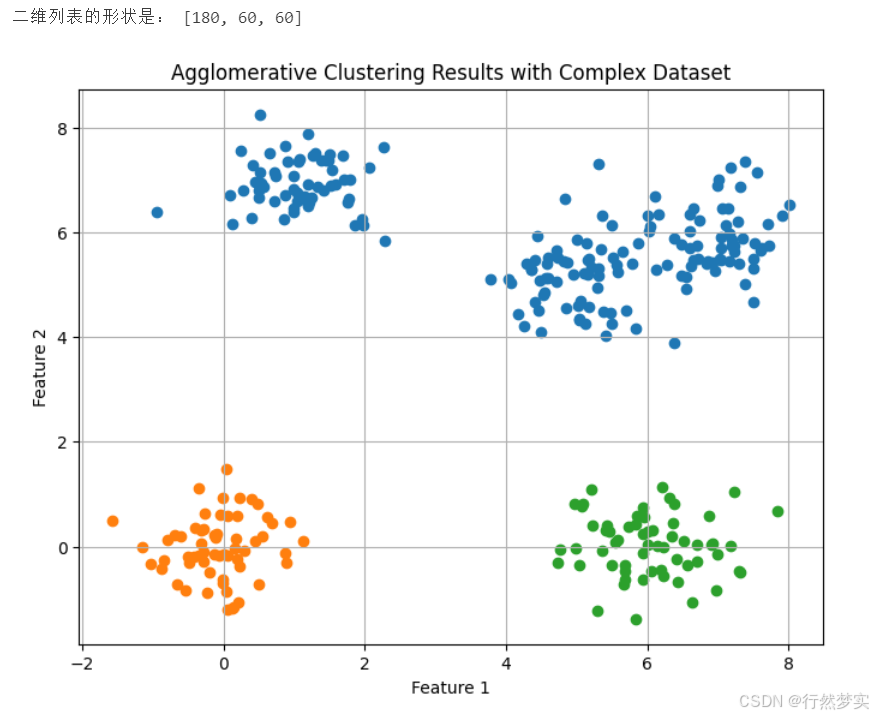
if __name__ == "__main__":
# 创建一个复杂的二元数据集
n_samples = 300
centers = [(0, 0), (5, 5), (1, 7), (6, 0), (7, 6)]
X, y = make_blobs(n_samples=n_samples, centers=centers, cluster_std=0.6, random_state=42)
# 进行聚合聚类
clustering = AgglomerativeClustering(n_clusters=3)
clusters = clustering.fit(X)
# 输出聚类结果
shape = get_irregular_list_shape(clusters)
print("二维列表的形状是:", shape)
# 可视化
plt.figure(figsize=(8, 6))
for cluster in clusters:
plt.scatter(X[cluster, 0], X[cluster, 1])
plt.title('Agglomerative Clustering Results with Complex Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.grid(True)
plt.show()
数据与结果为: