前言
提醒:
文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。
其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展及意见建议,欢迎评论区讨论交流。
文章目录
分类与回归算法
机器学习中的分类与回归算法是两种主要的监督学习任务,它们分别用于解决不同类型的问题。以下是这两种算法的总结:
分类算法:
分类算法用于将数据分成不同的类别,适用于输出为离散标签的问题。常见的分类算法包括:
- 逻辑回归:使用逻辑函数来估计概率,用于二分类问题,也可以扩展到多分类问题。
- 支持向量机(SVM):通过找到最优的决策边界来最大化样本的分类准确率,适用于高维数据。
- 决策树:通过树结构来进行决策,每个节点代表一个特征的选择,叶子节点代表分类结果。
- 随机森林:由多个决策树组成的集成学习方法,通过投票来决定最终分类结果。
- 梯度提升决策树(GBDT):通过构建和结合多个弱学习器来形成强学习器,适用于分类和回归问题。
- 朴素贝叶斯:基于贝叶斯定理,假设特征之间相互独立,适用于文本分类等场景。
- K近邻(KNN):根据样本之间的距离进行分类,适用于小规模数据集。
- 神经网络:通过多层感知机学习数据的复杂模式,适用于图像、语音等复杂分类问题。
回归算法:
回归算法用于预测连续数值输出,适用于输出为连续变量的问题。常见的回归算法包括:
- 线性回归:通过拟合一条直线来预测目标变量的值,是最简单的回归方法。
- 岭回归:线性回归的扩展,通过引入L2正则化项来防止过拟合。
- Lasso回归:线性回归的另一种扩展,通过引入L1正则化项来进行特征选择。
- 弹性网回归:结合了岭回归和Lasso回归,同时引入L1和L2正则化项。
- 决策树回归:使用决策树结构来进行回归预测,适用于非线性关系。
- 随机森林回归:由多个决策树组成的集成学习方法,通过平均来决定最终回归结果。
- 梯度提升决策树回归(GBDT回归):通过构建和结合多个弱学习器来形成强学习器,适用于回归问题。
- 支持向量回归(SVR):支持向量机在回归问题上的应用,通过找到最优的决策边界来最大化样本的回归准确率。
- 神经网络回归:通过多层感知机学习数据的复杂模式,适用于复杂的回归问题。
分类与回归算法的比较:
- 输出类型:分类算法输出离散标签,回归算法输出连续数值。
- 评估指标:分类算法常用准确率、召回率、F1分数等指标,回归算法常用均方误差(MSE)、均方根误差(RMSE)等指标。
- 问题类型:分类算法适用于类别预测问题,如垃圾邮件检测;回归算法适用于数值预测问题,如房价预测。 在实际应用中,选择分类还是回归算法取决于问题的性质和需求。有时,可以将回归问题转化为分类问题,或者将分类问题转化为回归问题,具体取决于问题的特点和目标。
支持向量回归(SVR)数学原理
支持向量机(分类算法)可参见:python_支持向量机(SVM)
支持向量回归(Support Vector Regression,简称SVR)是支持向量机(Support Vector Machine,简称SVM)在回归问题上的应用。SVR的目标是找到一个函数f(x),使得f(x)与实际输出y之间的差异不超过ε,同时不存在误判。SVR通过引入ε不敏感损失函数来处理回归问题。
在SVR中,我们使用ε不敏感损失函数来衡量预测值与实际值之间的差异。该损失函数定义为:
L ϵ ( f ( x ) − y ) = max ( 0 , ∣ f ( x ) − y ∣ − ϵ ) L_\epsilon(f(x) - y) = \max(0, |f(x) - y| - \epsilon) Lϵ(f(x)−y)=max(0,∣f(x)−y∣−ϵ)
这意味着只有当预测值与实际值之间的差异超过ε时,才会计算损失。
1. 目标函数
SVR 通过最小化以下目标函数来实现这一目标:
min w , b , ξ , ξ ∗ ( 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ( ξ i + ξ i ∗ ) ) \min_{w, b, \xi, \xi^*} \left( \frac{1}{2} \|w\|^2 + C \sum_{i=1}^m (\xi_i + \xi_i^*) \right) w,b,ξ,ξ∗min(21∥w∥2+Ci=1∑m(ξi+ξi∗))
其中:
- ∥ w ∥ 2 \|w\|^2 ∥w∥2 代表模型的复杂度。
- C C C 是正则化参数,用于平衡复杂度和误差。
- ξ i \xi_i ξi 和 ξ i ∗ \xi_i^* ξi∗ 是松弛变量,用于处理超出 ϵ \epsilon ϵ 范围的偏差。
2. 约束条件
目标函数受以下约束:
{ y i − ⟨ w , ϕ ( x i ) ⟩ − b ≤ ϵ + ξ i , ⟨ w , ϕ ( x i ) ⟩ + b − y i ≤ ϵ + ξ i ∗ , ξ i , ξ i ∗ ≥ 0 ∀ i . \begin{cases} y_i - \langle w, \phi(x_i) \rangle - b \leq \epsilon + \xi_i, \\ \langle w, \phi(x_i) \rangle + b - y_i \leq \epsilon + \xi_i^*, \\ \xi_i, \xi_i^* \geq 0 \quad \forall i. \end{cases} ⎩ ⎨ ⎧yi−⟨w,ϕ(xi)⟩−b≤ϵ+ξi,⟨w,ϕ(xi)⟩+b−yi≤ϵ+ξi∗,ξi,ξi∗≥0∀i.
其中:
- ϵ \epsilon ϵ 是 ϵ \epsilon ϵ-不敏感损失函数的阈值。
- ϕ ( x i ) \phi(x_i) ϕ(xi) 是输入特征向量 x i x_i xi 的高维映射。
-
⟨
w
,
ϕ
(
x
i
)
⟩
\langle w, \phi(x_i) \rangle
⟨w,ϕ(xi)⟩表示内积,又称为点积或标量积,是两个向量之间的一种运算,返回一个标量值。对于实向量空间
R
n
\mathbb{R}^n
Rn 中的两个向量
u
\mathbf{u}
u 和
v
\mathbf{v}
v,内积定义为:
u ⋅ v = ∑ i = 1 n u i v i \mathbf{u} \cdot \mathbf{v} = \sum_{i=1}^{n} u_i v_i u⋅v=i=1∑nuivi
这表示将两个向量的对应分量相乘,然后将所有这些乘积相加。
为了方便矩阵运算,内积也可以表示为:
u ⋅ v = u T v \mathbf{u} \cdot \mathbf{v} = \mathbf{u}^T \mathbf{v} u⋅v=uTv
在函数空间 L 2 ( [ a , b ] ) L^2([a, b]) L2([a,b]) 中,内积可以定义为积分形式。对于定义在区间 [ a , b ] [a, b] [a,b] 上的两个函数 f f f 和 g g g,内积表示为:
⟨ f , g ⟩ = ∫ a b f ( x ) g ( x ) d x \langle f, g \rangle = \int_{a}^{b} f(x) g(x) \, dx ⟨f,g⟩=∫abf(x)g(x)dx
3. ϵ \epsilon ϵ-不敏感损失函数
SVR 使用 ϵ \epsilon ϵ-不敏感损失函数,定义如下:
L ϵ ( y , f ( x ) ) = { ∣ y − f ( x ) ∣ − ϵ , 如果 ∣ y − f ( x ) ∣ > ϵ 0 , 否则 L_{\epsilon}(y, f(x)) = \begin{cases} |y - f(x)| - \epsilon, & \text{如果 } |y - f(x)| > \epsilon \\ 0, & \text{否则} \end{cases} Lϵ(y,f(x))={∣y−f(x)∣−ϵ,0,如果 ∣y−f(x)∣>ϵ否则
4. 拉格朗日函数
为了将问题转化为对偶问题,引入拉格朗日乘子 α i \alpha_i αi 和 α i ∗ \alpha_i^* αi∗。拉格朗日函数 L L L 表示为:
L ( w , b , ξ , ξ ∗ , α , α ∗ ) = 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ( ξ i + ξ i ∗ ) − ∑ i = 1 m α i ( ϵ + ξ i − y i + ⟨ w , ϕ ( x i ) ⟩ + b ) − ∑ i = 1 m α i ∗ ( ϵ + ξ i ∗ + y i − ⟨ w , ϕ ( x i ) ⟩ − b ) L(w, b, \xi, \xi^*, \alpha, \alpha^*) = \frac{1}{2} \|w\|^2 \\+ C \sum_{i=1}^m (\xi_i + \xi_i^*) - \sum_{i=1}^m \alpha_i (\epsilon + \xi_i - y_i + \langle w, \phi(x_i) \rangle + b) - \sum_{i=1}^m \alpha_i^* (\epsilon + \xi_i^* + y_i - \langle w, \phi(x_i) \rangle - b) L(w,b,ξ,ξ∗,α,α∗)=21∥w∥2+Ci=1∑m(ξi+ξi∗)−i=1∑mαi(ϵ+ξi−yi+⟨w,ϕ(xi)⟩+b)−i=1∑mαi∗(ϵ+ξi∗+yi−⟨w,ϕ(xi)⟩−b)
5. 对偶问题
对 w w w 和 b b b 求偏导数并设为零,得到最优条件:
∂ L ∂ w = w − ∑ i = 1 m ( α i − α i ∗ ) ϕ ( x i ) = 0 ⇒ w = ∑ i = 1 m ( α i − α i ∗ ) ϕ ( x i ) \frac{\partial L}{\partial w} = w - \sum_{i=1}^m (\alpha_i - \alpha_i^*) \phi(x_i) = 0 \Rightarrow w = \sum_{i=1}^m (\alpha_i - \alpha_i^*) \phi(x_i) ∂w∂L=w−i=1∑m(αi−αi∗)ϕ(xi)=0⇒w=i=1∑m(αi−αi∗)ϕ(xi)
∂ L ∂ b = − ∑ i = 1 m ( α i − α i ∗ ) = 0 ⇒ ∑ i = 1 m ( α i − α i ∗ ) = 0 \frac{\partial L}{\partial b} = -\sum_{i=1}^m (\alpha_i - \alpha_i^*) = 0 \Rightarrow \sum_{i=1}^m (\alpha_i - \alpha_i^*) = 0 ∂b∂L=−i=1∑m(αi−αi∗)=0⇒i=1∑m(αi−αi∗)=0
将这些条件代入拉格朗日函数,得到对偶问题:
max α , α ∗ ( ∑ i = 1 m ( α i − α i ∗ ) y i − 1 2 ∑ i , j = 1 m ( α i − α i ∗ ) ( α j − α j ∗ ) K ( x i , x j ) ) \max_{\alpha, \alpha^*} \left( \sum_{i=1}^m (\alpha_i - \alpha_i^*) y_i - \frac{1}{2} \sum_{i,j=1}^m (\alpha_i - \alpha_i^*) (\alpha_j - \alpha_j^*) K(x_i, x_j) \right) α,α∗max(i=1∑m(αi−αi∗)yi−21i,j=1∑m(αi−αi∗)(αj−αj∗)K(xi,xj))
约束条件:
∑ i = 1 m ( α i − α i ∗ ) = 0 和 0 ≤ α i , α i ∗ ≤ C ∀ i \sum_{i=1}^m (\alpha_i - \alpha_i^*) = 0 \quad \text{和} \quad 0 \leq \alpha_i, \alpha_i^* \leq C \quad \forall i i=1∑m(αi−αi∗)=0和0≤αi,αi∗≤C∀i
其中
K
(
x
i
,
x
j
)
=
⟨
ϕ
(
x
i
)
,
ϕ
(
x
j
)
⟩
K(x_i, x_j) = \langle \phi(x_i), \phi(x_j) \rangle
K(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩ 是核函数。
为了使 SVR 能够处理非线性回归问题,通常使用核函数
K
(
x
i
,
x
j
)
K(\mathbf{x}_i, \mathbf{x}_j)
K(xi,xj) 将输入数据映射到高维空间。常用的核函数包括:
- 线性核函数: K ( x i , x j ) = x i T x j K(\mathbf{x}_i, \mathbf{x}_j) = \mathbf{x}_i^T \mathbf{x}_j K(xi,xj)=xiTxj
- 多项式核函数: K ( x i , x j ) = ( γ x i T x j + r ) d K(\mathbf{x}_i, \mathbf{x}_j) = (\gamma \mathbf{x}_i^T \mathbf{x}_j + r)^d K(xi,xj)=(γxiTxj+r)d
- 高斯核(RBF): K ( x i , x j ) = e − γ ∣ ∣ x i − x j ∣ ∣ 2 K(\mathbf{x}_i, \mathbf{x}_j) = e^{-\gamma ||\mathbf{x}_i - \mathbf{x}_j||^2} K(xi,xj)=e−γ∣∣xi−xj∣∣2
6. 解的重构
求解对偶问题后,得到 α i \alpha_i αi 和 α i ∗ \alpha_i^* αi∗。利用这些值计算 w w w:
w = ∑ i = 1 m ( α i − α i ∗ ) ϕ ( x i ) w = \sum_{i=1}^m (\alpha_i - \alpha_i^*) \phi(x_i) w=i=1∑m(αi−αi∗)ϕ(xi)
选择一个合适的样本 j j j,计算 b b b:
b
=
y
j
−
⟨
w
,
ϕ
(
x
j
)
⟩
b = y_j - \langle w, \phi(x_j) \rangle
b=yj−⟨w,ϕ(xj)⟩
预测函数为:
f
(
x
)
=
∑
i
=
1
n
(
α
i
−
α
i
∗
)
K
(
x
i
,
x
)
+
b
f(x) = \sum_{i=1}^n (\alpha_i - \alpha_i^*) K(x_i, x) + b
f(x)=i=1∑n(αi−αi∗)K(xi,x)+b
其中
b
b
b 通过支持向量计算得到。
7. 参数选择
- 正则化参数 C C C:控制模型复杂度和误差的平衡。较大的 C C C 会使模型对误差更加敏感,可能导致过拟合;较小的 C C C 可能导致欠拟合。
- ϵ \epsilon ϵ 容忍度:控制 ϵ \epsilon ϵ-不敏感损失函数的阈值。较大的 ϵ \epsilon ϵ 会使模型对预测偏差更加宽容,而较小的 ϵ \epsilon ϵ 会使模型对误差更加敏感。
- 核函数:选择合适的核函数(如高斯核 K ( x , x ′ ) = exp ( − γ ∥ x − x ′ ∥ 2 ) K(x, x') = \exp(-\gamma \|x - x'\|^2) K(x,x′)=exp(−γ∥x−x′∥2))可以捕捉数据中的复杂关系。
算法实现
手动实现
import numpy as np
from cvxopt import matrix, solvers
import matplotlib.pyplot as plt
class SVR:
def __init__(self, C=1.0, epsilon=0.1):
# 惩罚参数
self.C = C
# ε-不敏感损失函数的参数
self.epsilon = epsilon
# 权重向量
self.w = None
# 偏置项
self.b = None
def fit(self, X, y):
n_samples, n_features = X.shape
# 构建二次规划问题的参数
# 目标函数中的二次项系数矩阵
P = np.zeros((2 * n_samples, 2 * n_samples))
for i in range(n_samples):
for j in range(n_samples):
P[i, j] = X[i].dot(X[j])
P[i + n_samples, j + n_samples] = X[i].dot(X[j])
P[i, j + n_samples] = -X[i].dot(X[j])
P[i + n_samples, j] = -X[i].dot(X[j])
P = matrix(P)
# 目标函数中的一次项系数向量
q = matrix(np.hstack([self.epsilon - y, self.epsilon + y]))
# 不等式约束条件
G1 = np.vstack([-np.eye(2 * n_samples), np.eye(2 * n_samples)])
h1 = np.hstack([np.zeros(2 * n_samples), np.ones(2 * n_samples) * self.C])
G = matrix(G1)
h = matrix(h1)
# 等式约束条件
A = matrix(np.hstack([np.ones(n_samples), -np.ones(n_samples)]).reshape(1, -1))
b = matrix(0.0)
# 求解二次规划问题
sol = solvers.qp(P, q, G, h, A, b)
alphas = np.ravel(sol['x'])
alphas_pos = alphas[:n_samples]
alphas_neg = alphas[n_samples:]
# 计算权重向量
self.w = np.zeros(n_features)
for i in range(n_samples):
self.w += (alphas_pos[i] - alphas_neg[i]) * X[i]
# 计算偏置项
# 找到支持向量
support_vectors = (alphas_pos > 1e-5) | (alphas_neg > 1e-5)
self.b = 0
for i in np.where(support_vectors)[0]:
sgn = np.sign(alphas_pos[i] - alphas_neg[i])
self.b += y[i] - sgn * self.epsilon - self.w.dot(X[i])
self.b /= support_vectors.sum()
def predict(self, X):
return np.dot(X, self.w) + self.b
# 生成一些示例数据
np.random.seed(42)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.randn(80) * 0.1
# 创建SVR模型并拟合数据
svr = SVR(C=1.0, epsilon=0.1)
svr.fit(X, y)
# 生成用于绘制预测曲线的点
X_test = np.linspace(0, 5, 200)[:, np.newaxis]
y_pred = svr.predict(X_test)
# 绘制原始数据点
plt.scatter(X, y, color='darkorange', label='Data')
# 绘制预测曲线
plt.plot(X_test, y_pred, color='navy', lw=2, label='SVR Prediction')
# 绘制 ε-不敏感带
plt.plot(X_test, y_pred + svr.epsilon, color='red', lw=1, linestyle='--', label='Upper Bound')
plt.plot(X_test, y_pred - svr.epsilon, color='green', lw=1, linestyle='--', label='Lower Bound')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Support Vector Regression')
plt.legend()
plt.show()
运行结果:
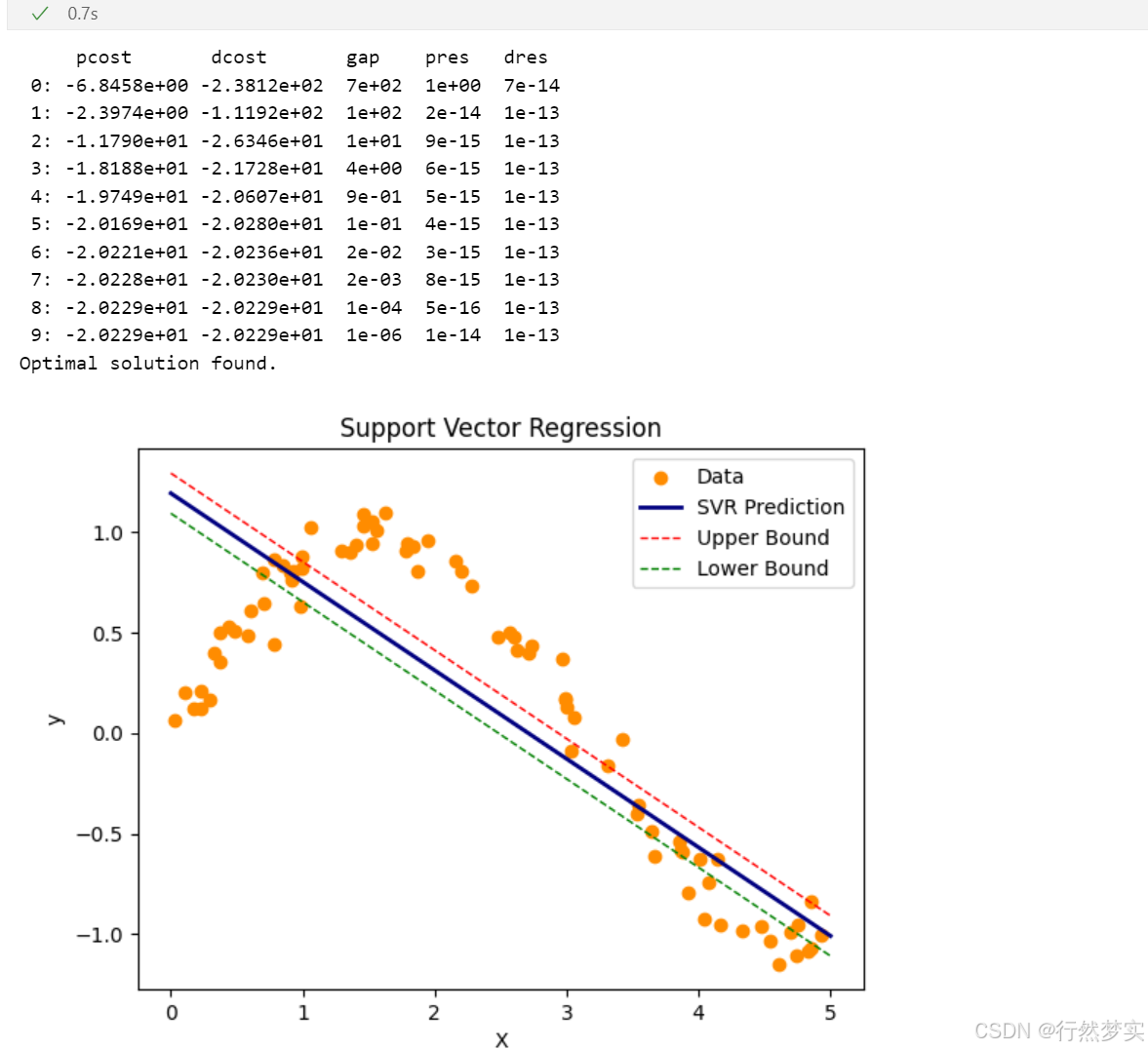
python函数库实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
# 生成示例数据
np.random.seed(42)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.randn(80) * 0.1
# 创建不同核函数的SVR模型
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=0.1)
svr_lin = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=0.1, coef0=1)
# 训练模型
svr_rbf.fit(X, y)
svr_lin.fit(X, y)
svr_poly.fit(X, y)
# 生成用于预测的点
X_test = np.linspace(0, 5, 200)[:, np.newaxis]
# 进行预测
y_rbf = svr_rbf.predict(X_test)
y_lin = svr_lin.predict(X_test)
y_poly = svr_poly.predict(X_test)
# 可视化结果
plt.figure(figsize=(12, 8))
plt.scatter(X, y, color='darkorange', label='Data')
plt.plot(X_test, y_rbf, color='navy', lw=2, label='RBF model')
plt.plot(X_test, y_lin, color='c', lw=2, label='Linear model')
plt.plot(X_test, y_poly, color='cornflowerblue', lw=2, label='Polynomial model')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Support Vector Regression')
plt.legend()
plt.show()
运行结果:
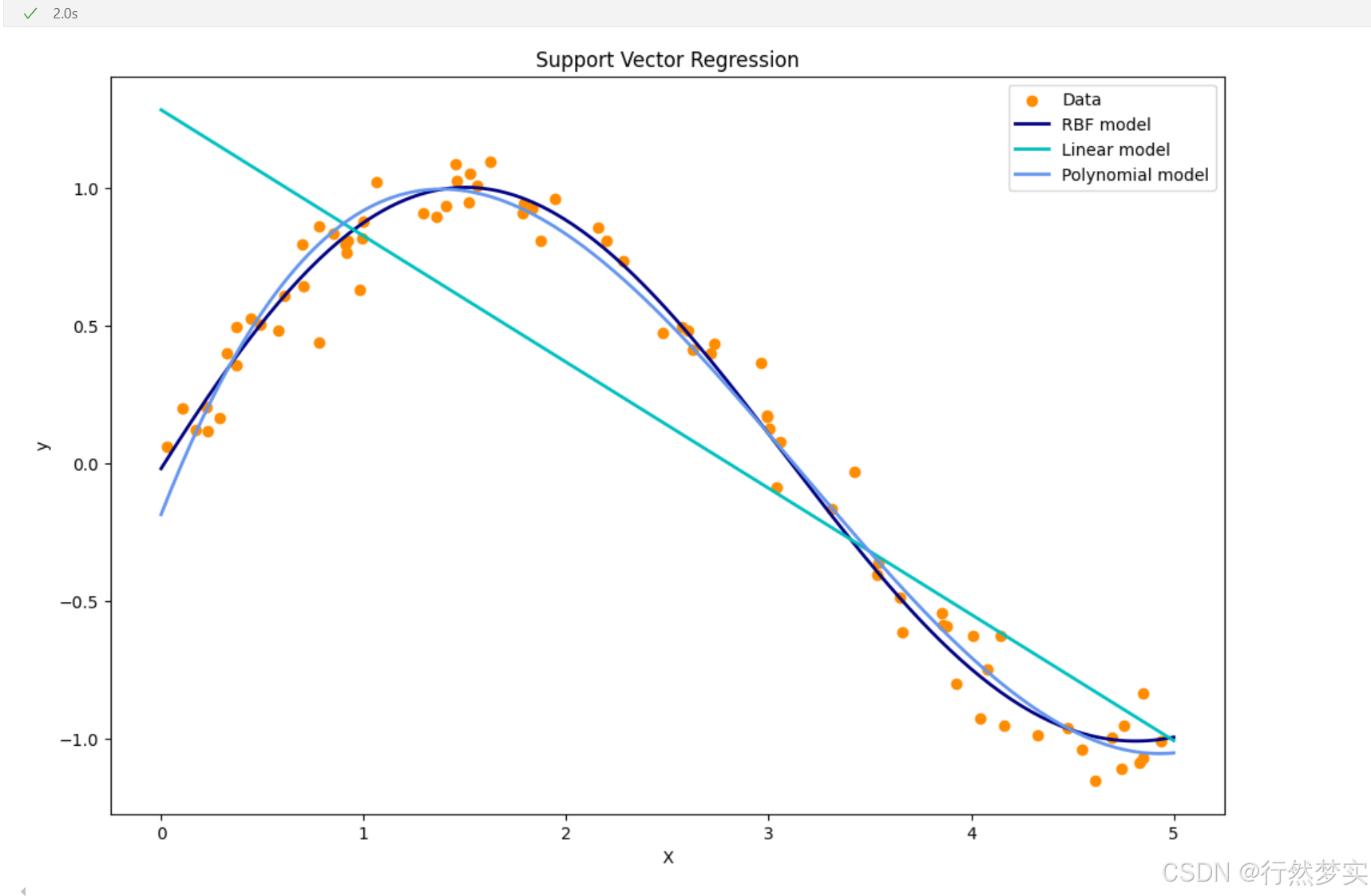
在scikit-learn库中,svr_rbf.fit(X, y)、svr_lin.fit(X, y) 和 svr_poly.fit(X, y) 这三行代码分别用于训练使用径向基核(RBF)、线性核和多项式核的支持向量回归(SVR)模型。下面结合数学公式详细讲解其含义。
不同核函数下的具体含义
线性核(svr_lin.fit(X, y))
当使用线性核时,
f
(
x
)
=
w
T
x
+
b
f(x) = w^T x + b
f(x)=wTx+b,优化问题就是在输入特征空间中寻找一个最优的超平面来拟合数据。在 fit 方法调用时,模型会求解上述优化问题以确定
w
w
w 和
b
b
b 的最优值。
在求解过程中,通常会将原问题转化为对偶问题:
max
α
,
α
∗
−
1
2
∑
i
=
1
n
∑
j
=
1
n
(
α
i
−
α
i
∗
)
(
α
j
−
α
j
∗
)
x
i
T
x
j
−
ϵ
∑
i
=
1
n
(
α
i
+
α
i
∗
)
+
∑
i
=
1
n
y
i
(
α
i
−
α
i
∗
)
\max_{\alpha,\alpha^*} -\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} (\alpha_i - \alpha_i^*) (\alpha_j - \alpha_j^*) x_i^T x_j - \epsilon \sum_{i=1}^{n} (\alpha_i + \alpha_i^*) + \sum_{i=1}^{n} y_i (\alpha_i - \alpha_i^*)
α,α∗max−21i=1∑nj=1∑n(αi−αi∗)(αj−αj∗)xiTxj−ϵi=1∑n(αi+αi∗)+i=1∑nyi(αi−αi∗)
s.t.
{
∑
i
=
1
n
(
α
i
−
α
i
∗
)
=
0
0
≤
α
i
,
α
i
∗
≤
C
\text{s.t.} \begin{cases} \sum_{i=1}^{n} (\alpha_i - \alpha_i^*) = 0 \\ 0 \leq \alpha_i, \alpha_i^* \leq C \end{cases}
s.t.{∑i=1n(αi−αi∗)=00≤αi,αi∗≤C
其中
α
i
\alpha_i
αi 和
α
i
∗
\alpha_i^*
αi∗ 是拉格朗日乘子。求解对偶问题得到最优的拉格朗日乘子后,就可以计算出
w
=
∑
i
=
1
n
(
α
i
−
α
i
∗
)
x
i
w = \sum_{i=1}^{n} (\alpha_i - \alpha_i^*) x_i
w=∑i=1n(αi−αi∗)xi,再通过满足 Karush - Kuhn - Tucker(KKT)条件的样本计算出
b
b
b。
径向基核(RBF)(svr_rbf.fit(X, y))
径向基核函数的表达式为 K ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 ) K(x_i, x_j) = \exp(-\gamma \| x_i - x_j \|^2) K(xi,xj)=exp(−γ∥xi−xj∥2),其中 γ \gamma γ 是核系数。
在使用径向基核时,模型会将输入数据映射到一个高维特征空间,在这个高维空间中进行线性回归。对偶问题变为:
max
α
,
α
∗
−
1
2
∑
i
=
1
n
∑
j
=
1
n
(
α
i
−
α
i
∗
)
(
α
j
−
α
j
∗
)
K
(
x
i
,
x
j
)
−
ϵ
∑
i
=
1
n
(
α
i
+
α
i
∗
)
+
∑
i
=
1
n
y
i
(
α
i
−
α
i
∗
)
\max_{\alpha,\alpha^*} -\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} (\alpha_i - \alpha_i^*) (\alpha_j - \alpha_j^*) K(x_i, x_j) - \epsilon \sum_{i=1}^{n} (\alpha_i + \alpha_i^*) + \sum_{i=1}^{n} y_i (\alpha_i - \alpha_i^*)
α,α∗max−21i=1∑nj=1∑n(αi−αi∗)(αj−αj∗)K(xi,xj)−ϵi=1∑n(αi+αi∗)+i=1∑nyi(αi−αi∗)
s.t.
{
∑
i
=
1
n
(
α
i
−
α
i
∗
)
=
0
0
≤
α
i
,
α
i
∗
≤
C
\text{s.t.} \begin{cases} \sum_{i=1}^{n} (\alpha_i - \alpha_i^*) = 0 \\ 0 \leq \alpha_i, \alpha_i^* \leq C \end{cases}
s.t.{∑i=1n(αi−αi∗)=00≤αi,αi∗≤C
svr_rbf.fit(X, y) 会求解上述对偶问题,得到最优的拉格朗日乘子,然后在预测时使用
f
(
x
)
=
∑
i
=
1
n
(
α
i
−
α
i
∗
)
K
(
x
i
,
x
)
+
b
f(x) = \sum_{i=1}^{n} (\alpha_i - \alpha_i^*) K(x_i, x) + b
f(x)=∑i=1n(αi−αi∗)K(xi,x)+b 进行预测。
多项式核(svr_poly.fit(X, y))
多项式核函数的表达式为 K ( x i , x j ) = ( γ x i T x j + r ) d K(x_i, x_j) = (\gamma x_i^T x_j + r)^d K(xi,xj)=(γxiTxj+r)d,其中 γ \gamma γ 是核系数, r r r 是偏置项, d d d 是多项式的次数。
同样,在使用多项式核时,模型会将输入数据映射到高维特征空间并求解对偶问题:
max
α
,
α
∗
−
1
2
∑
i
=
1
n
∑
j
=
1
n
(
α
i
−
α
i
∗
)
(
α
j
−
α
j
∗
)
K
(
x
i
,
x
j
)
−
ϵ
∑
i
=
1
n
(
α
i
+
α
i
∗
)
+
∑
i
=
1
n
y
i
(
α
i
−
α
i
∗
)
\max_{\alpha,\alpha^*} -\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} (\alpha_i - \alpha_i^*) (\alpha_j - \alpha_j^*) K(x_i, x_j) - \epsilon \sum_{i=1}^{n} (\alpha_i + \alpha_i^*) + \sum_{i=1}^{n} y_i (\alpha_i - \alpha_i^*)
α,α∗max−21i=1∑nj=1∑n(αi−αi∗)(αj−αj∗)K(xi,xj)−ϵi=1∑n(αi+αi∗)+i=1∑nyi(αi−αi∗)
s.t.
{
∑
i
=
1
n
(
α
i
−
α
i
∗
)
=
0
0
≤
α
i
,
α
i
∗
≤
C
\text{s.t.} \begin{cases} \sum_{i=1}^{n} (\alpha_i - \alpha_i^*) = 0 \\ 0 \leq \alpha_i, \alpha_i^* \leq C \end{cases}
s.t.{∑i=1n(αi−αi∗)=00≤αi,αi∗≤C
svr_poly.fit(X, y) 会根据输入的训练数据
X
X
X 和目标值
y
y
y 求解这个对偶问题,确定最优的拉格朗日乘子,进而得到用于预测的函数
f
(
x
)
=
∑
i
=
1
n
(
α
i
−
α
i
∗
)
K
(
x
i
,
x
)
+
b
f(x) = \sum_{i=1}^{n} (\alpha_i - \alpha_i^*) K(x_i, x) + b
f(x)=∑i=1n(αi−αi∗)K(xi,x)+b。
fit 方法的本质是根据不同的核函数,求解对应的优化问题,以确定模型的参数,从而使得模型能够对输入数据进行有效的拟合和预测。