01
写在前面
大型语言模型横行,之前非常焦虑,现在全面拥抱。目前也有很多开源项目进行大模型微调等,笔者也做了一阵子大模型了,特此来介绍一下ChatGLM-6B模型微调经验,并汇总了一下目前开源项目&数据。笔者与很多人微调结论不同,本人在采用单指令上进行模型微调,发现模型微调之后,「并没有出现灾难性遗忘现象」。
项目地址:https://github.com/liucongg/ChatGLM-Finetuning
02
ChatGLM-6B模型微调
模型越大对显卡的要求越高,目前主流对大模型进行微调方法有三种:Freeze方法、P-Tuning方法和Lora方法。笔者也通过这三种方法,在信息抽取任务上,对ChatGLM-6B大模型进行模型微调。为了防止大模型的数据泄露,采用一个领域比赛数据集-汽车工业故障模式关系抽取(https://www.datafountain.cn/competitions/584),随机抽取50条作为测试集。
详细代码见上面的GitHub链接,并且也被ChatGLM官方收录。
Freeze方法
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。
微调代码,见finetuning_freeze.py,核心部分如下:

针对模型不同层进行修改,可以自行修改。训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text等,可根据自己的任务配置。

三元组抽取的推理代码,见predict_freeze.py,其他任务可以根据自己的评价标准进行推理预测。
PT方法
PT方法,即P-Tuning方法,参考ChatGLM官方代码(https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md) ,是一种针对于大模型的soft-prompt方法。

-
P-Tuning(https://arxiv.org/abs/2103.10385),仅对大模型的Embedding加入新的参数。
-
P-Tuning-V2(https://arxiv.org/abs/2110.07602),将大模型的Embedding和每一层前都加上新的参数。
微调代码,见finetuning_pt.py,核心部分如下:

当prefix_projection为True时,为P-Tuning-V2方法,在大模型的Embedding和每一层前都加上新的参数;为False时,为P-Tuning方法,仅在大模型的Embedding上新的参数。
可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text、pre_seq_len、prompt_text等, 可根据自己的任务配置。

三元组抽取的推理代码,见predict_pt.py,其他任务可以根据自己的评价标准进行推理预测。
Lora方法
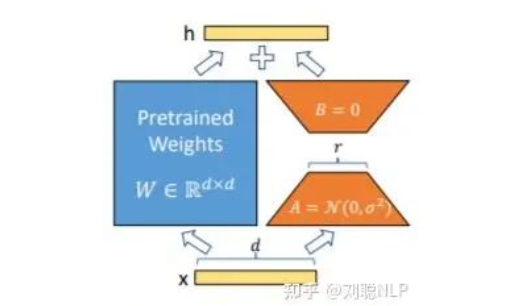
Lora方法,即在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练而外增加的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量很小,达到仅训练很小的参数,就能获取较好的结果。
-
Lora论文:https://arxiv.org/abs/2106.09685
-
官方代码:https://github.com/microsoft/LoRA
-
HuggingFace封装的peft库:https://github.com/huggingface/peft
微调代码,见finetuning_lora.py,核心部分如下:

可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text、lora_r等,可根据自己的任务配置。

三元组抽取的推理代码,见predict_lora.py,其他任务可以根据自己的评价标准进行推理预测。
注意:对于结果需要保持一致的任务(即关掉dropout,解码关掉do_sample),需要保存模型的adapter_config.json文件中,inference_mode参数修改成false,并将模型执行model.eval()操作。主要原因是chatglm模型代码中,没有采用Conv1D函数。
03
三元组抽取实验结果
-
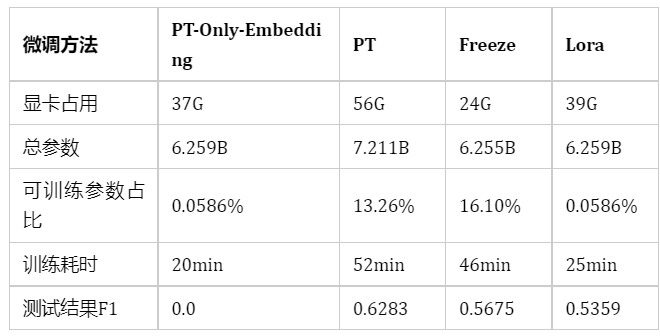
模型训练时,最大长度为768,Batch大小为2,训练轮数为5,fp16训练,采用DeepSpeed的Zero-1训练;
-
PT为官方的P-Tuning V2训练方法,PT-Only-Embedding表示仅对Embedding进行soft-prompt,Freeze仅训练模型后五层参数,Lora采用低秩矩阵方法训练,秩为8;
-
由于之前训练PT在48G-A40显卡上会出现OOM,因此之前进行PT实验时对模型开启了gradient_checkpointing_enable,使得模型显存占用变小,但训练时长增加。
-
训练示例:

时间换空间,可用很好的解决显卡的资源问题,简单玩玩还可以,如果想要模型达到最优效果或可用快速看到效果,还不如租张A100卡,快速实验,推理阶段再用自己的小破卡。
笔者找到一家新的算力平台-揽睿星舟,单张A100仅要6.4元/小时,我翻了一圈,算是便宜的了(反正比AutoDL便宜一点,便宜一点是一点吧)。
下面实验结果均是在租的80G-A100上进行的实验,与Github里用的A40的实验结果会有些差异,主要在训练时长(纯训练速度,剔除模型保存的时间)。说实话,真的要训练一个大模型,多个A100是必不可少的,可以减少很多模型并行的操作,效果上也更好把控一些。
结果分析:
-
效果为PT>Freeze>Lora>PT-Only-Embedding;
-
速度为PT-Only-Embedding>Lora>Freeze>PT;
-
PT-Only-Embedding效果很不理想,发现在训练时,最后的loss仅能收敛到2.几,而其他机制可以收敛到0.几。分析原因为,输出内容形式与原有语言模型任务相差很大,仅增加额外Embedding参数,不足以改变复杂的下游任务;
-
PT方法占用显存更大,因为也增加了很多而外参数;
-
测试耗时,采用float16进行模型推理,由于其他方法均增加了额外参数,因此其他方法的推理耗时会比Freeze方法要高。当然由于是生成模型,所以生成的长度也会影响耗时;
-
模型在指定任务上微调之后,并没有丧失原有能力,例如生成“帮我写个快排算法”,依然可以生成-快排代码;
-
由于大模型微调都采用大量instruction进行模型训练,仅采用单一的指令进行微调时,对原来其他的指令影响不大,因此并没导致原来模型的能力丧失;
-
上面测试仅代表个人测试结果。
很多同学在微调后出现了灾难性遗忘现象,但我这边并没有出现,对“翻译任务”、“代码任务”、“问答任务”进行测试,采用freeze模型,可以用test_forgetting.py进行测试,具体测试效果如下:
- 翻译任务

- 代码任务

- 问答任务

后面会把生成任务、分类任务做完,请持续关注Github,会定期更新。(太忙了,会抓紧时间更新,并且官方代码也在持续更新,如遇到代码代码调不通的情况,请及时联系我,我在github也给出了我的代码版本和模型版本)
04
中文开源大模型&项目
虽然出来很多大模型,但Open的&中文可直接使用的并不多,下面对中文开源大模型、数据集和项目进行一下汇总。
中文开源大模型
直接可微调,无需指令增量训练:
-
ChatGLM-6B:https://huggingface.co/THUDM/chatglm-6b
-
ChatYuan-large-v2:https://huggingface.co/ClueAI/ChatYuan-large-v2
原始模型多语言or英文,需要中文指令数据集增量训练:
-
BloomZ:https://huggingface.co/bigscience/bloomz
-
LLama:https://github.com/facebookresearch/llama
-
Flan-T5:https://huggingface.co/google/flan-t5-xxl
-
OPT:https://huggingface.co/facebook/opt-66b
中文开源指令数据
下面中文指令集,大多数从Alpaca翻译而来,请看下面项目中data目录。目前通过ChatGPT或者GPT4作为廉价标注工为自己的数据进行数据标注一个不错的思路。
-
[1]:https://github.com/LC1332/Chinese-alpaca-lora
-
[2]:https://github.com/hikariming/alpaca_chinese_dataset
-
[3]:https://github.com/carbonz0/alpaca-chinese-dataset
-
[4]:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
-
[5]:https://github.com/LianjiaTech/BELLE
-
[6]:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
开源项目
总结下面较火的开源项目:
-
BELLE:https://github.com/LianjiaTech/BELLE
-
ChatGLM:https://github.com/THUDM/ChatGLM-6B
-
Luotuo-Chinese-LLM:https://github.com/LC1332/Luotuo-Chinese-LLM
-
stanford_alpaca:https://github.com/tatsu-lab/stanford_alpaca
05
总结
目前各大厂的大模型陆陆续续放出,堪称百家争鸣!个人玩家也是全面拥抱,想尽一切办法来训练微调大模型。只愿大家以后可以实现“大模型”自由。愿再无“model-as-a-service”。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;

第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓