✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨
✨ 个人主页:余辉zmh–CSDN博客
✨ 文章所属专栏:贪心算法篇–CSDN博客

前言
本篇文章是对贪心算法练习题的讲解,有关贪心算法的讲解可以看本系列的第一篇文章,这里就不再讲解,继续讲解相关练习题。
例题
1.合并区间
题目:

算法原理:
本道题以及下面的两道题都是属于区间问题,对于区间问题,首先就是先排序,排序时可以按照左端点或者右端点排序,因为库函数中的sort函数默认是左端点排序,所以这里题解就是用的是左端点排序,如果是右端点排序,需要自己写排序规则;在排完序后,根据排序结果找到规律进而解决找到解决问题的策略。
本道题要求将重叠区间合并,在经过左端点排序后,能合并的区间都是相邻的,假设现在有两个区间,x和y,以下面的这张图为例:
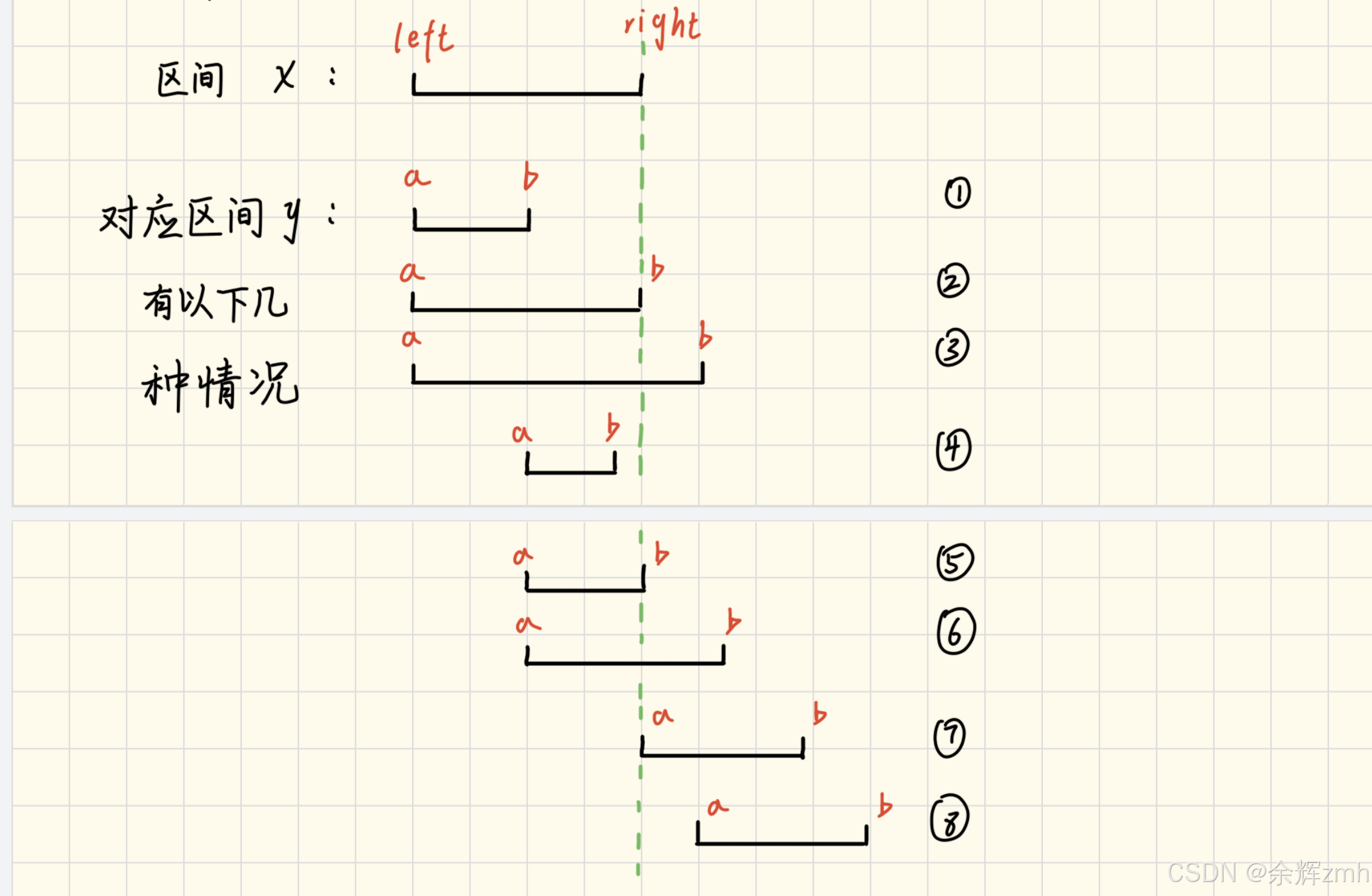
和区间x合并时,区间y有上面8中情况,其中,前六种情况都是,区间y的左端点a<小于区间x的右端点,说明存在重叠部分,可以进行合并,合并区间的左端点依然是区间x的左端点left,而右端点则是区间x的右端点right和区间y的右端点b取最大的那一个。而在本题中第7中情况,区间y的左端点a=区间x的右端点right,同样也可以作为重叠部分进行合并,但不是说每道题中相等的情况都算作重叠,需要根据题意来决定。因此前7中的处理方式相同,合并区间然后和下一个区间比较。
如果是第8中情况,区间y的左端点a大于区间x的右端点right,说明没有重叠部分,则将当前区间x存放到结果数组中,区间y和下一个区间比较。
注意本道题有一个细节点,如果区间x访问下一个区间时越界结束,会导致最后的区间没有存放到结果数组中,因此在遍历完所有区间后,要将最后一个区间存放到结果数组中。
代码实现:
vector<vector<int>> merge(vector<vector<int>>& intervals){
//先将所有区间按照左端点排序
sort(intervals.begin(), intervals.end());
int left = intervals[0][0], right = intervals[0][1];
vector<vector<int>> ret;
for (int i = 1; i < intervals.size(); i++){
int a = intervals[i][0], b = intervals[i][1];
//如果下一个区间的左端点小于上一个区间的右端点,左端点不变,右端点取最大的
if(a<=right){
right = max(b, right);
}
//如果下一个区间的左端点大于上一个区间的右端点,说明没有交集
else{
ret.push_back({left, right});
//更新做右端点
left = a, right = b;
}
ret.push_back({left, right});
}
return ret;
}
2.无重叠的区间
题目:

算法原理:
本道题也属于区间问题,因此同样也需要先将所有区间排序,这里也是左端点排序,排序后,互相重叠的区间是连续的。题意要求移除最少的区间使区间不存在重叠的部分,根据正难则反思想,移除最少也就是最后保留的区间最多。
假设当前有两个区间x和y进行比较,如果区间x越大,和区间y的重叠率就会越高,如果出现重叠,就要移除一个区间,想要不存在重叠部分,那区间x就是越小越好,越小,重叠率就会越低,移除的次数就会变少,保留的区间就会越多,因此两个区间比较时,要取两个区间中较小的,也就是可以理解位取两个区间的交集。
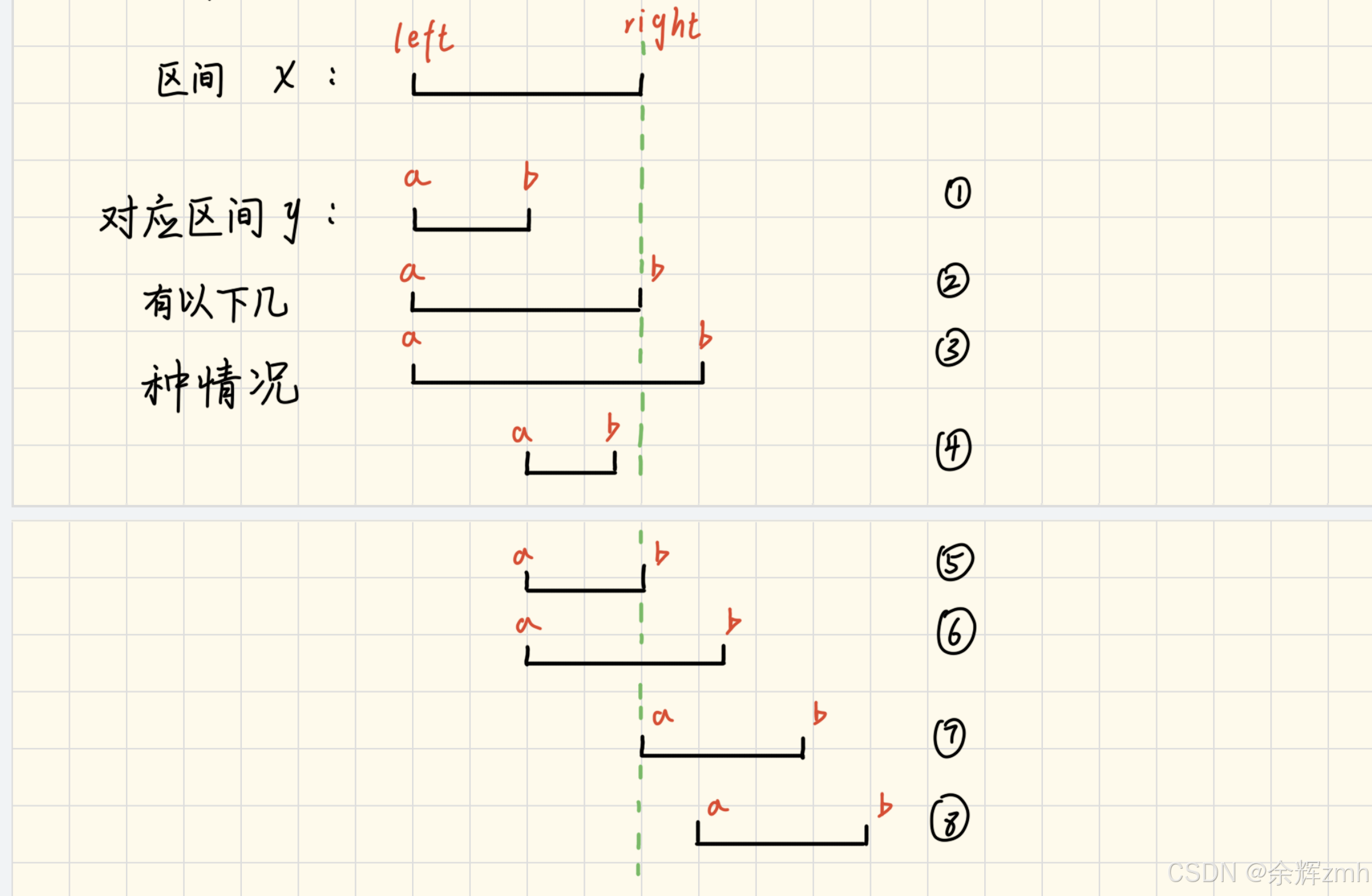
和上一题不同的是,本道题因为要取交集,所以如果区间y是前6种情况右端点要取两个区间中最小的右端点,并且第7种情况不再算作重叠情况,而是和第8种情况归为不存在重叠的情况。如果区间y是后2种情况,更新当前区间位区间y,然后和下一个区间比较。
本道题的细节点,两个区间取交集时其实就相当于移除其中一个区间,因此在统计结果时应该在取交集时统计。
代码实现:
int eraseOverlapIntervals(vector<vector<int>>& intervals){
//删除最少的区间,相当于保留最多的区间
//先将所有区间按照左端点排序
sort(intervals.begin(), intervals.end());
int n = intervals.size();
//左指针表示上一个区间的左端点,右指针表示上一个区间的右端点
int left = intervals[0][0], right = intervals[0][1];
int ret = 0;
for (int i = 1; i < n; i++){
int a = intervals[i][0], b = intervals[i][2];
//如果当前区间的左端点的值小于上一个区间的右端点的值,更新右指针为两个区间右端点最小的
//贪心策略,上一个区间越小,和当前区间的重叠率就越小
if(a<right){
right = min(right, b);
ret++;
}
//如果大于等于,直接更新左右指针
else{
left = a, right = b;
}
}
return ret;
}
3.用最少数量的箭引爆气球
题目:


算法原理:
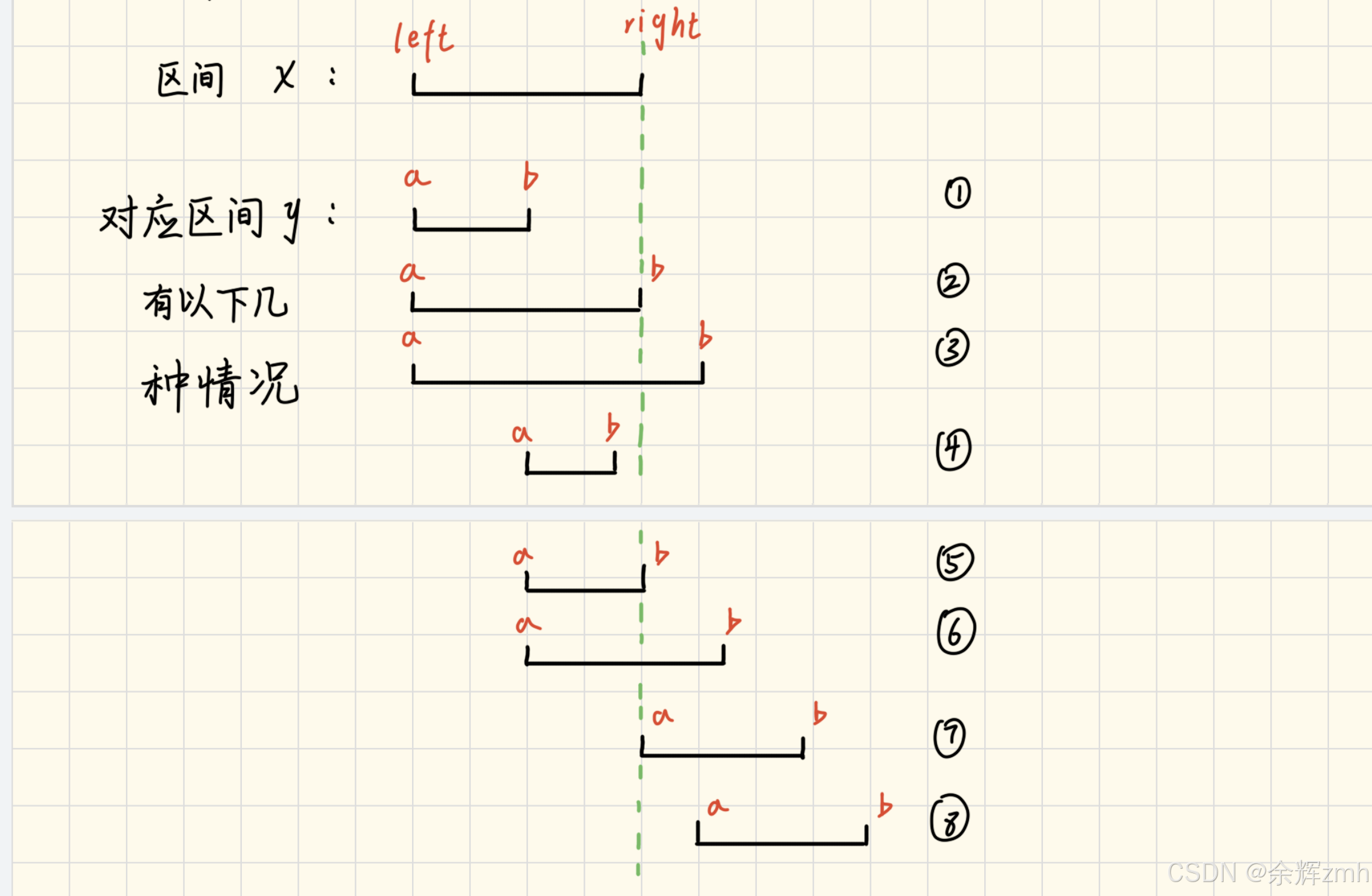
本道题也属于区间问题,根据题意要求,使用最少的箭,因此每次射出的一支箭都要尽可能多的射中更多的气球(贪心策略),所以要找区间的交集。
本道题和第二题的交集分类情况有些不同,本题中第7中情况,区间y的左端点等于区间x的右端点时,可以认为是重叠部分,所以前7种是一类,存在重叠部分的情况;最后一种为一类,不存在重叠的情况。处理方式还是相同的。
还有一个细节点就是,最后的结果统计时间也不同,因为要找多个区间的共同交集,所以当出现不存在重叠部分时,才统计一次结果,相当于找到了n个区间有交集,但是第n+1个区间和前面的没有交集,所以射出一支箭引爆n个气球。
代码实现:
int findMinArrowShots(vector<vector<int>>& points){
//区间问题,找到公共区间合并
//先将所有区间按照左端点排序,重叠的区间是连续的(相当于交集)
sort(points.begin(), points.end());
int n = points.size();
int ret = 0;
//左右指针表示上个区间的左右端点
int left = points[0][0], right = points[0][1];
for (int i = 1; i < n; i++){
int a = points[i][0], b = points[i][1];
//如果当前区间的左端点小于等于上个区间的右端点,取公共区间,右端点取两个中最小的
//这里等于也算是重叠
if(a<=right){
left = a;
right = min(right, b);
}
//如果大于,说明没有公共区间,个数加1,更新左右指针
else{
ret++;
left = a, right = b;
}
}
return ret + 1;
}
4.可被3整除的最大和
题目:

算法原理:
本道题的思路:正难则反思想+贪心+分类讨论。
根据题意要求,找到可被3整除的最大和,如果遍历数组一个一个加再判断效率就会太慢,因此可以反着来,先将所有数字加在一起,求出整个数组和sum,然后再分情况讨论。
一个数模上3只有三种情况,对应数组和sum有三种情况:第一种情况模上3等于0,那当前数组和就是满足要求最大和,直接返回当前和即可;第二种情况模上3等于1;第三种情况模上3等于2,后两种情况还要继续分情况讨论。
先假设x1,x2表示模上3等于1的数,x1<x2;y1,y2表示模上3等于2的数,y1<y2。
如果sum模上3等于1说明至少存在一个1个数x1模上3等于1,该数一定是数组中最小的模上3等于1的数(贪心策略,这样才能保证和最大);或者至少存在两个数,y1,y2模上3等于2,这两个数也一定是数组中最小的和次小的模上3等于2的数(贪心策略),然后判断两种情况那种可以使和最大,然后返回。
如果模上3等于2说明至少存在两个数x1,x2模上3等于1,这两个数也一定是数组中最小的和次小的模上3等于1的数(贪心策略);或者至少存在一个数y1模上3等于2,该数也一定是数组中模上3等于2最小的数(贪心策略),然后判断两种情况那种可以使和最大,然后返回。
如何找到x1,x2和y1,y2:可以直接先将数组按升序排序,这样遍历过程中就是从小到大,第一次遇到的模上3等于1的数一定是x1,第二遇到的就是x2;同理,第一次遇到的模上3等于2的数一定是y1,第二次遇到的就是y2;但是使用排序的话时间复杂度是n乘以log n级别的;这里我是用分类讨论的思想直接在原来基础上遍历一遍找到对应四个数,因为x1<x2;y1<y2;如果当前数num模上3等于1并且小于等于x1,那就更新x2为x1,x1为当前数num;如果当前数num大于等于x1,但是小于等于x2,那就只更新x2为当前数num;同理,y1,y2也是这样判断。这样就能在排序的情况下,遍历一遍找到对应的四个数。
代码实现:
int maxSumDivThree(vector<int>& nums){
//正难则反思想
//求出所有和
int sum=0;
//可以直接sort排序后查找,但是时间复杂度为n方
//这里用分类讨论直接遍历一遍,时间复杂度为n
//x1,x2表示模上3等于1,y1,y2表示模上3等于2
int x1, x2, y1, y2;
x1 = x2 = y1 = y2 = INT_MAX;
for(auto num : nums){
sum += num;
if (num % 3 == 1&&num<=x1){
x2=x1;
x1 = num;
}
else if(num%3==1&&x1<=num&&num<=x2){
x2 = num;
}
if (num % 3 == 2 && num <= y1){
y2=y1;
y1 = num;
}
else if (num % 3 == 2 && y1 <= num && num <= y2){
y2 = num;
}
}
//如果数组和模上3等于1,找到其中最小的x1,最小的y1和次小的y2
if(sum%3==1){
if(y1!=INT_MAX&&y2!=INT_MAX){
return (sum - x1) > (sum - y1 - y2) ? sum - x1 : sum - y1 - y2;
}
else{
return sum - x1;
}
}
//如果数组和模上3等于2,找到其中最小的x1和次小的x2,最小的y1
else if(sum%3==2){
if(x1!=INT_MAX&&x2!=INT_MAX){
return (sum - x1 - x2) > (sum - y1) ? sum - x1 - x2 : sum - y1;
}
else{
return sum - y1;
}
}
//如果模上3等于0,直接返回
return sum;
}
5.距离相等的条形码
题目:

算法原理:
本道题思路:贪心+模拟+鸽巢原理。
既然题意要求,重新排列两两不能相同,其实就是类似于小学时候的在路边种树问题,间隔一个种一棵树,本道题也是同理,可以间隔一个放一个,并且是放完一种再放下一种树,比如有三个1,两个2,要先放完所有的1再放2,因为我们知道数组中下标是从0开始,因此可以先放偶数位,偶数位放完后再放奇数位。先统计所有数字的个数,找到其中个数最多的那个数,这里用到的就是贪心策略和鸽巢原理,先存放个数最多的那个数。
假设当前共有n个数,这里先设n=9,假设个数最多的是1,1的个数一定不会超过(n+1)/2,就是5个,这里用到的就是鸽巢原理,如果有n个巢穴,有n+1个鸽子,如果先一个巢穴放一只,那么最后一定会有一个巢穴存在两只鸽子;这里也是同理,因为是间隔存放,相当于两个位置看作一个巢穴,最多就是(n+1)/2个巢穴,一旦最多的那个数的个数大于(n+1)/2,那么就会出现两个1在一个巢穴,也就是相邻位置的情况:111_1_1_1,就是这种情况,所以最多只能有(n+1)/2个,1_1_1_1_1,如果超过那就是无解,不能排列成两两不相同。
至于为什么先排列最多的那个数,以上面的这种情况为例,1_1_1_1_1,5个1将两两位置间隔开,剩余的数随便排列也不会出现两两相同的情况;如果是这种情况,没有排满1_1_1_ _ _ _,假设下一个要排的是2,绝对不会出现1212122_2,2将剩余的偶数位排满然后排奇数位,循环一圈后奇数位的2和偶数位的2相同,如果是这种情况,2的个数一定会比1多,但是我们要求的是先排最多的数,所以,2的个数一定不会比1多,也就是不可能出现两两相同的情况。这就是本题的贪心策略。
代码实现:
vector<int> rearrangeBarcodes(vector<int>& barcodes){
int n = barcodes.size();
//创建一个哈希表用来统计数字的个数
unordered_map<int, int> hash;
//一个用来标记个数最多的数字,一个用来记录最多数字的个数
int maxval = 0, maxcount = 0;
for(auto x : barcodes){
if(++hash[x]>maxcount){
maxcount=hash[x];
maxval = x;
}
}
//间隔排列,先排列偶数位并且是最多的那个数字
vector<int> ret(n);
int index = 0;
while(maxcount--){
ret[index] = maxval;
index += 2;
}
//从哈希表中删除最多的那个数
hash.erase(maxval);
//将剩下的数依次填充剩余位,偶数位没有填完,优先偶数位,然后奇数位
for(auto& [num,count] : hash){
while(count--){
if(index>=n){
index = 1;
}
ret[index]=num;
index += 2;
}
}
return ret;
}
6.重构字符串
题目:

算法原理:
本道题和上面那道题原理相同,只不过上一个题是将数字排列,本道题是将字符排列。
代码实现:
string reorganizeString(string s){
//和上一道题思路一样
unordered_map<char,int> hash;
char maxval = 'a';
int maxcount = 0;
for(auto ch : s){
if(++hash[ch]>maxcount){
maxcount=hash[ch];
maxval = ch;
}
}
int n=s.size();
//如果最多的个数超过一半,直接结束,鸽巢原理
if(maxcount>(n+1)/2){
return "";
}
string ret;
ret.resize(n);
int index=0;
while(maxcount--){
ret[index] = maxval;
index += 2;
}
hash.erase(maxval);
for(auto& [ch,count] : hash){
while(count--){
if(index>=n){
index = 1;
}
ret[index] = ch;
index += 2;
}
}
return ret;
}
以上就是关于贪心算法练习题四的讲解,如果哪里有错的话,可以在评论区指正,也欢迎大家一起讨论学习,如果对你的学习有帮助的话,点点赞关注支持一下吧!!!
