
用于单样本学习的多层语义特征增强
引用:Chen, Zitian, et al. “Multi-level semantic feature augmentation for one-shot learning.” IEEE Transactions on Image Processing 28.9 (2019): 4594-4605.
论文地址:下载地址
论文代码:https://github.com/tankche1/Semantic-Feature-Augmentation-in-Few-shot-Learning
Abstract
人类能够从有限样本中快速识别和学习新的视觉概念,使其能够迅速适应新任务和环境。这种能力源于将新概念与已学习并存储在记忆中的概念进行语义关联。计算机可以通过使用语义概念空间来获得类似的能力。概念空间是一个高维语义空间,其中相似的抽象概念相距较近,而不相似的概念则相距较远。在本文中,我们提出了一种基于这一核心思想的新颖单样本学习方法。我们的方法学习将一个新样本实例映射到一个概念上,将该概念与概念空间中的现有概念关联起来,并利用这些关系,通过概念间的插值生成新实例,以帮助学习。我们没有合成新的图像实例,而是提出直接通过利用语义合成实例特征的方法,采用一种我们称为双重 TriNet 的新型自编码器网络。TriNet 的编码器部分学习将来自 CNN 的多层视觉特征映射到语义向量。在语义空间中,我们搜索相关概念,这些概念随后由 TriNet 的解码器部分投影回图像特征空间。我们在语义空间中探索了两种策略。值得注意的是,这种看似简单的策略在图像特征空间中产生了复杂的增强特征分布,从而显著提高了性能。
1 INTRODUCTION
机器学习,特别是深度学习的最新成功,在很大程度上依赖于训练过程,而这些训练过程需要每个类别中数百甚至数千个标记的训练实例。然而,在实际中,获取大量标记样本可能极为昂贵,甚至不可行,例如对于稀有物体或难以观察的物体而言。相反,人类在看到少数训练样本后便能轻松学习识别新的物体类别1。受此能力的启发,小样本学习旨在从少数甚至单个样本中构建分类器。
在小样本学习设置中,学习优秀分类器的主要障碍是缺乏训练数据。因此,小样本学习的一种自然方法是首先以某种方式扩充数据。已经探索了多种数据扩充方法。先前的研究中采用的主流方法是为每个类别获得更多图像2,并将其用作训练数据。这些额外的扩充训练图像可以从未标记的数据3或其他相关类别4 5 6 7 中借用,以无监督或半监督的方式获取。然而,来自相关类别的扩充数据通常在语义上是嘈杂的,可能导致负迁移,从而导致性能下降而非提升。另一方面,从虚拟示例生成的合成图像8 9 10 11 12 13 在语义上是准确的,但需要仔细的领域适应,以将知识和特征迁移到真实图像域。为了避免直接生成合成图像的困难,更希望在特征空间本身中扩充样本。
例如,最新的深度卷积神经网络(CNN)以分层结构堆叠多个特征层;我们假设,在这种情况下,特征扩充可以在由 CNN 层生成的特征空间中完成。尽管在概念上具有明显的优势,但特征扩充技术相对较少被探索。少数例子包括12 13 14。值得注意的是,文献12和13中采用了物体部分的特征块(例如 HOG),并将它们组合以合成新的特征表示。Dixit 等人14 首次考虑了属性引导的扩充来合成样本特征。然而,他们的工作依赖于一组预定义的语义属性。
一种直接扩充图像特征表示的方法是对每个训练图像的特征表示添加随机(向量)噪声。然而,这种简单的扩充过程可能无法显著提升决策边界的质量。人类学习启发我们在概念空间中搜索相关信息。我们的核心思想是利用额外的语义知识,例如通过使用诸如 Google 的 word2vec 等语言模型预训练的语义空间来封装这些知识15。在这种语义流形中,类似的概念往往具有相似的语义特征表示。整体空间呈现语义连续性,这使得它非常适合用于特征扩充。
为了利用这种语义空间,我们提出了一种双重 TriNet 架构 g ( x ) = g D e c ∘ g E n c ( x ) g(x) = g_{Dec} \circ g_{Enc}(x) g(x)=gDec∘gEnc(x),用于学习多层图像特征与语义空间之间的转换。双重 TriNet 与 18 层残差网络(ResNet-18)16 配对;其包含编码器 TriNet g E n c ( x ) g_{Enc}(x) gEnc(x) 和解码器 TriNet g D e c ( x ) g_{Dec}(x) gDec(x)。具体而言,给定一个训练实例,我们可以使用 ResNet-18 来提取不同层次的特征。 g E n c ( x ) g_{Enc}(x) gEnc(x) 高效地将这些特征映射到语义空间。在语义空间中,投影的实例特征可以通过添加高斯噪声进行扰动,或用其最近的语义词向量替代。我们假设在语义空间中对特征值进行微小调整,可以在保持语义信息的同时涵盖潜在类别的多样性。解码器 TriNet g D e c ( x ) g_{Dec}(x) gDec(x) 随后被调整以将扰动后的语义实例特征映射回多层(ResNet-18)特征空间。值得注意的是,语义空间中的高斯扩充/扰动最终在原始特征空间中产生高度非高斯的扩充。这是语义空间扩充的核心优势。通过使用三种经典的监督分类器,我们展示了扩充特征可以提升小样本分类的性能。
贡献。我们的贡献主要体现在以下几个方面。首先,我们提出了一种简单而优雅的深度学习架构:ResNet-18+双重 TriNet,用于小样本分类的高效端到端训练。其次,我们展示了所提出的双重 TriNet 可以有效地扩充由 ResNet-18 多个层生成的视觉特征。第三,有趣的是,我们表明可以利用各种类型的语义空间,包括语义属性空间、语义词向量空间,甚至是由类别语义关系定义的子空间。最后,在四个数据集上进行的大量实验验证了所提出方法在解决小样本图像识别任务中的有效性。
2 RELATED WORK
2.1 Few-Shot Learning
小样本学习的灵感来自于人类能够从少量实例中学习新概念的能力17 18。能够通过仅一个或少量示例识别并推广到新类别19,超出了典型机器学习算法的能力,这些算法通常依赖于数百甚至数千个训练示例。总体而言,解决此类挑战的方法可分为两类:
直接基于监督学习的方法,直接通过实例学习(例如 K 最近邻)、非参数方法20 21 22、深度生成模型23 24 或贝叶斯自编码器25来学习单样本分类器。与我们的工作相比,这些方法使用丰富的生成模型类来解释观察到的数据,而不是像我们提出的那样直接扩充实例特征。
基于迁移学习的方法,则通过学习如何学习的范式1 或元学习26 来探索。具体来说,这些方法利用辅助数据的知识,通过共享特征19 27 28 29 30 31、语义属性32 33 34 或上下文信息35,在少数示例下识别新类别。最近,从源数据中学习度量空间以支持单样本学习的思想得到了广泛探索,例如匹配网络(Matching Networks)36 和原型网络(Prototypical Networks)37。一般来说,这些方法可以大致分为元学习算法(包括 MAML38、Meta-SGD39、DEML+Meta-SGD40、META-LEARN LSTM41、Meta-Net42、R2-D243、Reptile44、WRN45)和度量学习算法(包括 Matching Nets36、PROTO-NET37、RELATION NET46、MACO47 和 Cos & Att.48)。在文献49 50中,他们维护了用于连续学习的外部记忆。MAML51 可以学习良好的初始神经网络权重,使其易于针对未见过的类别进行微调。文献52 使用图神经网络通过支持图像向测试图像传递消息进行推理。TPN53 提出了一种用于推导的框架,从而解决了数据匮乏的问题。Multi-Attention54 利用语义信息生成注意力图来帮助单样本识别,而我们直接在语义空间中扩充样本并将其映射回视觉空间。
相较于这些工作,我们的框架是正交但具有潜在的实用性——在应用此类方法之前扩充新类别的实例特征是有用的。
2.2 增强训练实例
标准的增强技术通常直接应用于图像域中,例如翻转、旋转、加噪声和随机裁剪图像2 55 56。最近,已经研究了更高级的数据增强技术以训练监督分类器。特别是,增强的训练数据也可以用于缓解实例稀缺的问题,从而避免在单样本/小样本学习设置中过拟合。先前的方法可以分为六类:
(1) 通过在半监督或传导式设置下利用大量未标记数据的流形信息来学习单样本模型3;
(2) 从现成的训练模型中自适应地学习单样本分类器4 5 6;
(3) 从相关类别7 57 或语义词汇58 59 中借用示例以扩充训练集;
(4) 通过渲染虚拟示例8 9 10 11 60、合成表示12 13 61 62 63 64 或扭曲现有训练示例2来合成额外的标记训练实例;
(5) 使用生成对抗网络(GANs)生成新示例65 66 67 68 69 70 71 72 73;
(6) 属性引导的增强(AGA)和特征空间传递14 74,在所需的数值、姿势或强度下合成样本。
尽管研究广泛,先前的方法可能存在以下几个问题:
(1) 半监督算法依赖于流形假设,但该假设在实际中难以有效验证;
(2) 当现成模型或相关类别与单样本类别差异较大时,迁移学习可能会受到负迁移的影响;
(3) 渲染、合成或扭曲现有训练示例可能需要领域专业知识;
(4) 基于 GAN 的方法主要关注学习优质生成器,以合成“逼真”图像来“欺骗”判别器。合成图像不一定保留判别信息。
与此相反,我们的网络结构直接在视觉特征域中合成判别性实例。AGA14 主要利用 3D 深度或姿势信息的属性进行增强;相比之下,我们的方法还可以利用语义信息来扩充数据。此外,所提出的双重 TriNet 网络可以有效地增强多层特征。
2.3 Embedding Network structures
视觉-语义嵌入的学习已通过多种方式进行了探索,包括神经网络(例如,孪生网络(Siamese network)75 76)、判别方法(例如,支持向量回归器(SVR)32 77 78)、度量学习方法36 79 80 或核嵌入方法27 81。一种最常见的嵌入方法是将视觉特征和语义实体投影到一个新的公共空间中。然而,在处理 CNN 的不同层的特征空间时,以往的方法必须为每一层学习一个单独的视觉-语义嵌入。与此相反,所提出的双重 TriNet 可以有效地为多层特征空间学习一个统一的视觉-语义嵌入。
梯度网络(Ladder Networks)82 利用横向连接作为自编码器进行半监督学习任务。在文献83 中,作者融合了不同网络的不同中间层,以提高图像分类性能。深层聚合(Deep Layer Aggregation)84 通过聚合网络中的各层和模块来更好地融合层间信息。我们的方法不同于学习特定的聚合节点来合并不同层次的特征;我们的双重 TriNet 直接在编码-解码结构中变换、重新缩放并连接不同层的特征。
3 用于语义数据增强的双重 TriNet 网络
3.1 Problem setup
在单样本学习中,我们给定基础类别 C b a s e C_{base} Cbase 和新类别 C n o v e l C_{novel} Cnovel( C b a s e ∩ C n o v e l = ∅ C_{base} \cap C_{novel} = \emptyset Cbase∩Cnovel=∅),其总类别标签集为 C = C b a s e ∪ C n o v e l C = C_{base} \cup C_{novel} C=Cbase∪Cnovel。基础类别 C b a s e C_{base} Cbase 具有充足的标记图像数据,并且我们假设基础数据集 D b a s e = { I b a s e ( i ) , z b a s e ( i ) , u b a s e z i } i = 1 N b a s e D_{base} = \{I_{base}^{(i)}, z_{base}^{(i)}, u_{base}^{z_i}\}_{i=1}^{N_{base}} Dbase={Ibase(i),zbase(i),ubasezi}i=1Nbase 包含 N b a s e N_{base} Nbase 个样本。 I b a s e ( i ) I_{base}^{(i)} Ibase(i) 表示原始图像 i i i; z b a s e ( i ) ∈ C b a s e z_{base}^{(i)} \in C_{base} zbase(i)∈Cbase 是来自基础类别集的类别标签; u b a s e z i u_{base}^{z_i} ubasezi 是实例 i i i 在其类别标签上的语义向量。语义向量 u b a s e z i u_{base}^{z_i} ubasezi 可以是语义属性32、语义词向量15 或者任何通过类别的语义关系构建或学习得到的子空间表示。
对于新类别 C n o v e l C_{novel} Cnovel,我们考虑另一个数据集 D n o v e l = { I n o v e l ( i ) , z n o v e l ( i ) , u n o v e l z i } D_{novel} = \{I_{novel}^{(i)}, z_{novel}^{(i)}, u_{novel}^{z_i}\} Dnovel={Inovel(i),znovel(i),unovelzi},其中每个类别 z n o v e l ( i ) ∈ C n o v e l z_{novel}^{(i)} \in C_{novel} znovel(i)∈Cnovel。对于新数据集,我们有一个支持集和一个测试集。支持集 D s u p p o r t = { I s u p p o r t ( i ) , z s u p p o r t ( i ) , u s u p p o r t z i } D_{support} = \{I_{support}^{(i)}, z_{support}^{(i)}, u_{support}^{z_i}\} Dsupport={Isupport(i),zsupport(i),usupportzi}( D s u p p o r t ∈ D n o v e l D_{support} \in D_{novel} Dsupport∈Dnovel)由每个新类别的少量训练实例组成。测试集 D t e s t = { I t e s t ( i ) , z t e s t ( i ) , u t e s t z i } D_{test} = \{I_{test}^{(i)}, z_{test}^{(i)}, u_{test}^{z_i}\} Dtest={Itest(i),ztest(i),utestzi}( D t e s t ∈ D n o v e l D_{test} \in D_{novel} Dtest∈Dnovel,且 D s u p p o r t ∩ D t e s t = ∅ D_{support} \cap D_{test} = \emptyset Dsupport∩Dtest=∅)不可用于训练,但用于测试。通常情况下,我们只在 D b a s e D_{base} Dbase 和 D s u p p o r t D_{support} Dsupport 上进行训练,分别包含基础类别的充足实例和新类别的少量实例。然后我们在仅包含新类别的 D t e s t D_{test} Dtest 上评估我们的模型。我们的目标是通过仅使用少量支持集 D s u p p o r t D_{support} Dsupport 来学习一个能够很好地推广到新类别的模型。
3.2 Overview
目标。我们旨在直接扩充每个目标类别训练实例的特征。给定来自新类别的一个训练实例 I s u p p o r t ( i ) I_{support}^{(i)} Isupport(i),特征提取网络可以输出该实例的特征 { f ( l ) ( I s u p p o r t ( i ) ) } \{f^{(l)}(I_{support}^{(i)})\} {f(l)(Isupport(i))},其中 l = 1 , ⋯ , L l = 1, \cdots, L l=1,⋯,L;扩充网络 g ( x ) g(x) g(x) 能够生成一组合成特征 g ( { f ( l ) ( I s u p p o r t ( i ) ) } ) g(\{f^{(l)}(I_{support}^{(i)})\}) g({f(l)(Isupport(i))})。这些合成特征被用作单样本学习的额外训练实例。如图1所示,我们使用 ResNet-1816 并提出双重 TriNet 网络,分别作为特征提取网络和扩充网络。整个架构通过结合两个网络的损失函数进行端到端训练,公式如下:
{ Ω , Θ } = arg min Ω , Θ J 1 ( Ω ) + λ ⋅ J 2 ( Θ ) \{\Omega, \Theta\} = \arg \min_{\Omega, \Theta} J_1(\Omega) + \lambda \cdot J_2(\Theta) {Ω,Θ}=argΩ,ΘminJ1(Ω)+λ⋅J2(Θ)
其中, J 1 ( Ω ) J_1(\Omega) J1(Ω) 和 J 2 ( Θ ) J_2(\Theta) J2(Θ) 分别是 ResNet-1816 和双重 TriNet 网络的损失函数; Ω \Omega Ω 和 Θ \Theta Θ 代表相应的参数。 J 1 ( Ω ) J_1(\Omega) J1(Ω) 使用交叉熵损失16。公式(1)通过基础数据集 D b a s e D_{base} Dbase 优化。
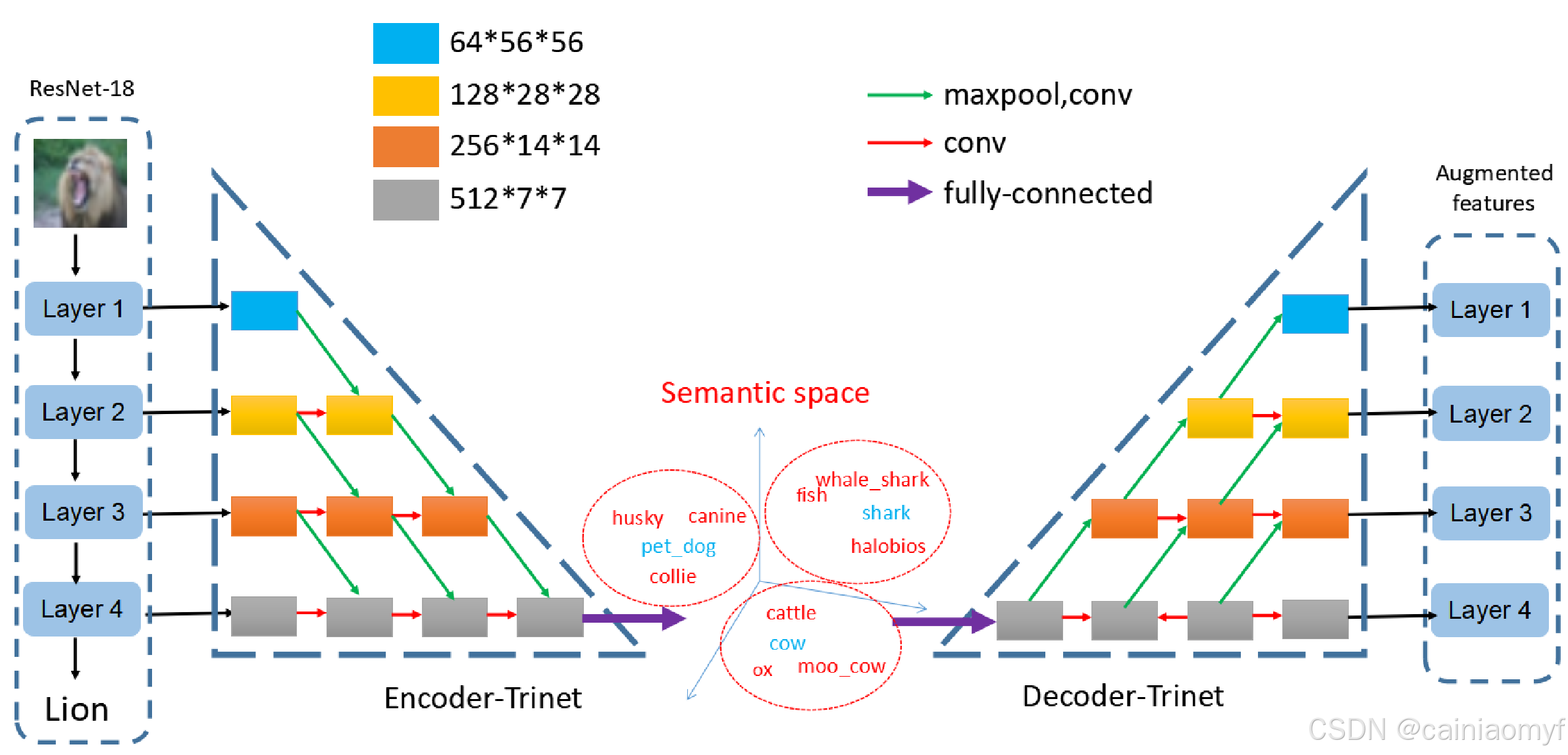
特征提取网络。我们训练 ResNet-1816 将原始图像转换为特征向量。ResNet-18 包含4个顺序残差层,即 layer1、layer2、layer3 和 layer4,如图1所示。每个残差层输出一个相应的特征图 f ( l ) ( I i ) f^{(l)}(I_i) f(l)(Ii),其中 l = 1 , ⋯ , 4 l = 1, \cdots, 4 l=1,⋯,4。如果我们将每个特征图视为不同的图像表示,ResNet-18 实际上学习了多层图像特征(MIF)编码。通常,不同层的特征可用于各种单样本学习任务。例如,在文献2中,全连接层的特征可用于单样本图像分类;而全卷积层的输出特征可能更适用于单样本图像分割任务85 86 87。通过结合多个层级的特征,我们的方法可以应用于各种不同的视觉任务。
扩充网络。我们提出了一种编码器-解码器架构——双重 TriNet ( g ( x ) = g D e c ∘ g E n c ( x ) ) (g(x) = g_{Dec} \circ g_{Enc}(x)) (g(x)=gDec∘gEnc(x))。如图1所示,我们的双重 TriNet 可以分为编码器-TriNet g E n c ( x ) g_{Enc}(x) gEnc(x) 和解码器-TriNet 子网络 g D e c ( x ) g_{Dec}(x) gDec(x)。编码器-TriNet 将视觉特征空间映射到语义空间,这里进行扩充。解码器-TriNet 将扩充后的语义空间表示投影回特征空间。由于 ResNet-18 具有四层,不同层生成的视觉特征空间可以使用相同的编码器-解码器 TriNet 进行数据扩充。
3.3 Dual TriNet Network
双重 TriNet 与 ResNet-18 配对。深度 CNN 架构中不同层获得的特征表示是层次化的,从一般(底层)到更具体(顶层)递进88。例如,前几层生成的特征类似于 Gabor 滤波器56,因此与任务无关;而高层特征则针对特定任务(例如图像分类)具有较强的特异性。ResNet-18 的各层生成的特征表示包含不同层次的抽象语义信息。因此,一个自然的问题是,是否可以在不同层次上扩充特征?为每一层直接学习一个编码器-解码器无法充分利用不同层之间的关系,可能无法有效学习特征空间与语义空间之间的映射。为此,我们提出了双重 TriNet 网络。
双重 TriNet 学习多层图像特征(M-IF)编码与语义空间之间的映射。语义空间可以是语义属性空间,也可以是第 III-A 节中介绍的语义词向量空间。语义属性可以由人类专家预定义14。语义词向量 u b a s e z i u_{base}^{z_i} ubasezi 是每个词汇实体 w i ∈ W w_i \in W wi∈W 的投影,其中词汇 W W W 是通过在大规模语料库上使用 word2vec15 学习的。此外,可以通过类别的语义关系的奇异值分解(SVD)扩展子空间 u b a s e z i u_{base}^{z_i} ubasezi。具体来说,我们可以使用 { u b a s e z i ; u n o v e l z j } z i ∈ C b a s e , z j ∈ C n o v e l \{u_{base}^{z_i}; u_{novel}^{z_j}\}_{z_i \in C_{base}, z_j \in C_{novel}} {ubasezi;unovelzj}zi∈Cbase,zj∈Cnovel 计算类别的语义关系矩阵 M M M,使用余弦相似度来进行计算。我们使用 SVD 算法分解 M = U Σ V M = U \Sigma V M=UΣV。其中 U U U 是一个酉矩阵,定义了一个新的语义空间。 U U U 的每一行作为一个类别的新语义向量。
编码器 TriNet 由四层组成,对应于 ResNet-18 的每一层。其目标是学习函数 u ^ z i = g E n c ( { f ( l ) ( I i ) } ) \hat{u}_{z_i} = g_{Enc}(\{f^{(l)}(I_i)\}) u^zi=gEnc({f(l)(Ii)}),将实例 i i i 的所有层特征 { f ( l ) ( I i ) } \{f^{(l)}(I_i)\} {f(l)(Ii)} 映射到尽可能接近实例 i i i 的语义向量 u z i u_{z_i} uzi 的位置。子网络的结构受到河内塔的启发,如图1所示。这样的结构可以有效利用多层中编码的信息的差异性和互补性。编码器 TriNet 通过合并和组合不同层的输出来匹配 ResNet-18 的四个层次。解码器 TriNet 的结构相反,用于将语义空间中的特征 u ^ z i \hat{u}_{z_i} u^zi 投影回特征空间 f ^ ( l ) ( I i ) = g D e c ( g E n c ( { f ( l ) ( I i ) } ) ) \hat{f}^{(l)}(I_i) = g_{Dec}(g_{Enc}(\{f^{(l)}(I_i)\})) f^(l)(Ii)=gDec(gEnc({f(l)(Ii)}))。我们通过优化以下损失来学习 TriNet:
J 2 ( Θ ) = E [ ∑ l = 1 4 ( f ( l ) ( I i ) − f ^ ( l ) ( I i ) ) 2 + ( u ^ z i − u z i ) 2 ] + λ P ( Θ ) J_2(\Theta) = \mathbb{E}\left[\sum_{l=1}^4 (f^{(l)}(I_i) - \hat{f}^{(l)}(I_i))^2 + (\hat{u}_{z_i} - u_{z_i})^2\right] + \lambda P(\Theta) J2(Θ)=E[l=1∑4(f(l)(Ii)−f^(l)(Ii))2+(u^zi−uzi)2]+λP(Θ)
其中 I i ∈ D b a s e I_i \in D_{base} Ii∈Dbase, Θ \Theta Θ 表示双重 TriNet 网络的参数集, P ( ⋅ ) P(\cdot) P(⋅) 是 L 2 L2 L2 正则化项。双重 TriNet 在 D b a s e D_{base} Dbase 上进行训练,并用于在支持集 D s u p p o r t D_{support} Dsupport 中的给定训练实例上,以 l 层特征扰动的形式合成实例。
图 1. 我们的框架概览。我们通过 ResNet-18 提取图像特征,并通过双 TriNet 增强特征。编码器 TriNet 将特征投射到语义空间。在语义空间中增强数据后,我们使用解码器 TriNet 获取相应的增强特征。真实数据和增强数据都用于训练分类模型。请注意 (1) 绿色小箭头表示 2 × 2 的最大池化,其后的 “conv ”层是 Conv-BN-ReLU 序列。
3.4 Feature Augmentation by Dual TriNet
通过学习到的双重 TriNet,我们有两种方式来扩充训练实例的特征。请注意,该扩充方法仅用于扩展 D s u p p o r t D_{support} Dsupport。
语义高斯(SG)。扩充特征的一种自然方法是从高斯分布中采样实例。具体而言,对于 ResNet-18 提取的特征集 { f ( l ) ( I s u p p o r t ( i ) ) } \{f^{(l)}(I_{support}^{(i)})\} {f(l)(Isupport(i))}( l = 1 , ⋯ , L l = 1, \cdots, L l=1,⋯,L),编码器 TriNet 可以将 { f ( l ) ( I s u p p o r t ( i ) ) } \{f^{(l)}(I_{support}^{(i)})\} {f(l)(Isupport(i))} 投影到语义空间,即 g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\}) gEnc({f(l)(Isupport(i))})。在此空间中,我们假设向量可以通过随机高斯噪声进行扰动,而不会改变其语义标签。这可以用于扩充数据。具体来说,我们使用语义高斯从 I s u p p o r t ( i ) I_{support}^{(i)} Isupport(i) 采样第 k k k 个语义向量 v G k ( i ) v_{G_k}^{(i)} vGk(i),如下所示:
v G k ( i ) ∼ N ( g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) , σ E ) v_{G_k}^{(i)} \sim \mathcal{N} (g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\}), \sigma E) vGk(i)∼N(gEnc({f(l)(Isupport(i))}),σE)
其中, σ ∈ R \sigma \in \mathbb{R} σ∈R 是每个维度的方差, E E E 是单位矩阵; σ \sigma σ 控制所加噪声的标准差。为了使扩充后的语义向量 v G k ( i ) v_{G_k}^{(i)} vGk(i) 仍能代表类别 z s u p p o r t ( i ) z_{support}^{(i)} zsupport(i),我们通过实验设置 σ \sigma σ 为 u s u p p o r t z i u_{support}^{z_i} usupportzi 与其最近的其他类别实例 u s u p p o r t z j u_{support}^{z_j} usupportzj( z s u p p o r t ( i ) ≠ z s u p p o r t ( j ) z_{support}^{(i)} \neq z_{support}^{(j)} zsupport(i)=zsupport(j))之间距离的 15 % 15\% 15%,因为这样可获得最佳性能。解码器 TriNet 生成虚拟合成样本 g D e c ( v G k ( i ) ) g_{Dec}(v_{G_k}^{(i)}) gDec(vGk(i)),其类别标签与原始实例的类别标签 z s u p p o r t ( i ) z_{support}^{(i)} zsupport(i) 相同。通过对语义向量的某些维度值进行微小扰动,我们期望采样的向量 v G k ( i ) v_{G_k}^{(i)} vGk(i) 仍然保持相同的语义含义。
语义邻域(SN)。受最近关于词汇知情学习的工作启发58,语义词向量空间(例如 word2vec15)中的大量词汇也可以用于扩充。这类词汇的分布反映了语言语料库中的一般语义关系。例如,在词向量空间中,“卡车”的向量比“狗”的向量更接近“汽车”的向量。给定训练实例 i i i 的特征 { f ( l ) ( I s u p p o r t ( i ) ) } \{f^{(l)}(I_{support}^{(i)})\} {f(l)(Isupport(i))},第 k k k 个扩充数据 v N k ( i ) v_{N_k}^{(i)} vNk(i) 可以从 g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\}) gEnc({f(l)(Isupport(i))}) 的邻域中采样,即
v N k ( i ) ∈ Neigh ( g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) ) v_{N_k}^{(i)} \in \text{Neigh}(g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\})) vNk(i)∈Neigh(gEnc({f(l)(Isupport(i))}))
其中 Neigh ( g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) ) ⊂ W \text{Neigh}(g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\})) \subset W Neigh(gEnc({f(l)(Isupport(i))}))⊂W 表示 g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\}) gEnc({f(l)(Isupport(i))}) 的最近邻词汇集, W W W 表示通过 word2vec15 在大规模语料库上学习到的词汇集。这些邻居对应于与我们的训练实例最语义相似的示例。合成样本的特征同样可以通过 g D e c ( v N k ( i ) ) g_{Dec}(v_{N_k}^{(i)}) gDec(vNk(i)) 解码得到。
我们要强调以下几点。
(1) 对于一个训练实例
I
s
u
p
p
o
r
t
(
i
)
I_{support}^{(i)}
Isupport(i),我们使用 Eq (3) 中的高斯均值或 Eq (4) 中的邻域中心
g
E
n
c
(
{
f
(
l
)
(
I
s
u
p
p
o
r
t
(
i
)
)
}
)
g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\})
gEnc({f(l)(Isupport(i))}),而不是其实例的真实词向量
u
s
u
p
p
o
r
t
z
i
u_{support}^{z_i}
usupportzi。这是因为
u
s
u
p
p
o
r
t
z
i
u_{support}^{z_i}
usupportzi 仅表示类别
z
s
u
p
p
o
r
t
(
i
)
z_{support}^{(i)}
zsupport(i) 的语义中心,而不是实例
i
i
i 的中心。在 miniImageNet 数据集上,使用
u
s
u
p
p
o
r
t
z
i
u_{support}^{z_i}
usupportzi 进行特征扩充而不是
g
E
n
c
(
{
f
(
l
)
(
I
s
u
p
p
o
r
t
(
i
)
)
}
)
g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\})
gEnc({f(l)(Isupport(i))}) 会导致单样本/五样本分类平均下降
3
%
∼
5
%
3\% \sim 5\%
3%∼5% 的性能。
(2) 在 Eq (3) 中添加的语义空间高斯噪声或在 Eq (4) 中使用的语义邻域生成的合成训练特征对于每个类别来说都是高度非线性的(非高斯的)。这是由 TriNet
g
D
e
c
(
x
)
g_{Dec}(x)
gDec(x) 和 ResNet-18
{
f
(
l
)
(
I
s
u
p
p
o
r
t
(
i
)
)
}
\{f^{(l)}(I_{support}^{(i)})\}
{f(l)(Isupport(i))} 提供的非线性解码导致的。
(3) 直接向
{
f
(
l
)
(
I
s
u
p
p
o
r
t
(
i
)
)
}
\{f^{(l)}(I_{support}^{(i)})\}
{f(l)(Isupport(i))} 添加高斯噪声是另一种简单的特征扩充方法。然而,在 miniImageNet 数据集上,这种策略并未在单样本分类中带来显著提升。
3.5 One-shot Classification
在基础数据集 D b a s e D_{base} Dbase 上训练特征提取网络和双重 TriNet 后,我们现在讨论如何在目标数据集 D n o v e l D_{novel} Dnovel 上进行单样本分类。对于 D n o v e l D_{novel} Dnovel 中的实例 i i i,我们可以使用特征提取网络提取 M-IF 表示 { f ( l ) ( I n o v e l ( i ) ) } \{f^{(l)}(I_{novel}^{(i)})\} {f(l)(Inovel(i))}( l = 1 , 2 , ⋯ , L l = 1, 2, \cdots, L l=1,2,⋯,L)。然后,我们使用 TriNet 的编码器部分将实例 i i i 的所有层特征 { f ( l ) ( I i ) } \{f^{(l)}(I_{i})\} {f(l)(Ii)} 映射到语义向量 g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\}) gEnc({f(l)(Isupport(i))})。我们的框架可以扩充该实例,除了原始实例外,还可以通过语义高斯和/或语义邻域方法生成多个合成实例 { v G k ( i ) } ∪ { v N k ( i ) } \{v_{G_k}^{(i)}\} \cup \{v_{N_k}^{(i)}\} {vGk(i)}∪{vNk(i)}。对于每个新的语义向量 v k ( i ) ∈ { v G k ( i ) } ∪ { v N k ( i ) } v_k^{(i)} \in \{v_{G_k}^{(i)}\} \cup \{v_{N_k}^{(i)}\} vk(i)∈{vGk(i)}∪{vNk(i)},我们使用 TriNet 的解码器将其从语义空间映射回所有层特征 { x a u g m e n t ( i , l ) } = g D e c ( v k ( i ) ) \{x_{augment}^{(i,l)}\} = g_{Dec}(v_k^{(i)}) {xaugment(i,l)}=gDec(vk(i))( l = 1 , 2 , ⋯ , L l = 1, 2, \cdots, L l=1,2,⋯,L)。未在最终第 L L L 层的特征通过特征提取网络的第 l + 1 l+1 l+1 层传递到第 L L L 层,以获得 { x ^ a u g m e n t ( l ) } \{\hat{x}_{augment}^{(l)}\} {x^augment(l)}。技术上讲,一个新的语义向量 v k ( i ) v_k^{(i)} vk(i) 可以生成 L L L 个实例:每个层的特征均为一个实例。与先前的研究一致2 16,最终层生成的特征用于单样本分类任务。因此,从实例 i i i 获得的合成第 L L L 层特征 { x ^ a u g m e n t ( i , l ) } \{\hat{x}_{augment}^{(i,l)}\} {x^augment(i,l)} 以及原始第 L L L 层特征 f ( L ) ( I s u p p o r t ( i ) ) f^{(L)}(I_{support}^{(i)}) f(L)(Isupport(i)) 被用于监督方式下训练单样本分类器 KaTeX parse error: Undefined control sequence: \mathchar at position 7: g_{one\̲m̲a̲t̲h̲c̲h̲a̲r̲`-shot}(x)。注意,从实例 i i i 获得的所有扩充特征向量均假设具有与原始实例 i i i 相同的类别标签。
在本研究中,我们展示了扩充特征可以对多种监督分类器带来益处。为此,利用了三种经典的分类器,即 K 近邻(KNN)、支持向量机(SVM)和逻辑回归(LR),作为单样本分类器 KaTeX parse error: Undefined control sequence: \mathchar at position 7: g_{one\̲m̲a̲t̲h̲c̲h̲a̲r̲`-shot}(x)。特别是,我们使用 KaTeX parse error: Undefined control sequence: \mathchar at position 7: g_{one\̲m̲a̲t̲h̲c̲h̲a̲r̲`-shot}(x) 在测试时对测试样本 I t e s t ( i ) I_{test}^{(i)} Itest(i) 的第 L L L 层特征 f ( L ) ( I t e s t ( i ) ) f^{(L)}(I_{test}^{(i)}) f(L)(Itest(i)) 进行分类。
4 Experiments
4.1 Datasets
我们在四个数据集上进行了实验。请注意:
(1) 在所有数据集上,ResNet-18 仅在指定划分中的训练集(相当于基础数据集)上进行训练,以便与先前的研究结果一致。
(2) 对所有数据集使用相同的网络和参数设置(包括输入图像的大小);因此,所有图像都被调整为
224
×
224
224 \times 224
224×224。
miniImageNet。该数据集最早由文献36 提出,包含来自 100 个类别的 60,000 张图像;每个类别大约有 600 个示例。为了使我们的结果与先前的研究具有可比性,我们使用文献41 中的划分,分别利用 64、16 和 20 个类别用于训练、验证和测试。
Cifar-100。Cifar-100 包含来自 100 个细粒度和 20 个粗粒度类别的 60,000 张图像89。我们使用与文献90 中相同的数据划分,以便与先前方法进行比较。具体而言,64、16 和 20 个类别分别用于训练、验证和测试。
Caltech-UCSD Birds 200-2011 (CUB-200)。CUB-200 是一个细粒度数据集,由 200 个鸟类类别的总计 11,788 张图像组成91。如文献47 中的划分,我们使用 100、50 和 50 个类别分别用于训练、验证和测试。该数据集还在每个类别级别提供了 312 维的语义属性向量。
Caltech-256。Caltech-256 包含来自 256 个类别的 30,607 张图像92。如文献90,我们将数据集划分为 150、56 和 50 个类别分别用于训练、验证和测试。
4.2 Network structures and Settings
对于所有四个数据集和实验,均使用相同的 ResNet-18 和双重 TriNet。
参数。自编码器网络的 dropout 率和学习率分别设置为 0.5 和 1 × 1 0 − 3 1 \times 10^{-3} 1×10−3 以防止过拟合。每 10 个 epoch,学习率减半。批量大小设置为 64。网络使用 Adam 优化器进行训练,通常在 100 个 epoch 内收敛。由于训练集较小,实验多次重复以减少随机性。Top-1 准确率在 95 % 95\% 95% 的置信区间内报告,并在多个测试集上平均,方法与先前的研究相同41。
设置。我们使用从文献58 发布的词汇字典中提取的 100 维语义词向量。类别名称被投影到语义空间中作为向量 u b a s e z i u_{base}^{z_i} ubasezi 或 u n o v e l z i u_{novel}^{z_i} unovelzi。语义属性空间由专家预定义32 91。在所有实验中,给定一个训练实例,双重 TriNet 将在语义空间中生成 4 个扩充实例。因此,我们在每一层上有 4 个合成实例,最终得到 4 层特征的 16 个合成实例。所以,一个训练实例最终成为 17 个训练实例。
4.3 Competitors and Classification models
竞争方法。我们比较的先前方法在相同的源/目标和训练/测试划分下运行,以便与我们的方法进行公平比较。我们与以下方法进行对比:Matching Nets36,MAML38,Meta-SGD39,DEML+Meta-SGD40,PROTO-NET37,RELATION NET46,META-LEARN LSTM41,Meta-Net42,SNAIL93,MACO47,GNN52,MMNet50,Reptile44,TPN53,WRN45,Cos & Att.48,Delta-encoder57 和 R2-D243。为了公平比较,我们实现了一些方法并使用 ResNet-18 作为通用主干架构。
分类模型。KNN、SVM 和 LR 被用作分类模型,以验证我们扩充技术的有效性。分类模型的超参数通过在验证集上的交叉验证进行选择。
4.4 Experimental results on miniImageNet and CUB-200
设置。对于 miniImageNet 数据集,我们仅有语义词空间。给定一个训练实例,我们可以分别为语义高斯(SG)和语义邻域(SN)生成 16 个扩充实例。在 CUB-200 数据集中,我们使用语义词向量和语义属性空间。因此,对于一个训练实例,我们在语义词向量空间中分别为 SG 和 SN 生成 16 个扩充实例;另外,在语义属性空间中为语义高斯(SG)生成 16 个虚拟实例(在所有四层中),我们将其称为属性高斯(AG)。
扩充样本数量的变体。扩充样本数量的变化对我们的性能影响不大。为证明这一点,我们在 CUB 数据集上提供了不同数量扩充样本下的 1-shot 准确率(表 II)。如所示,增加扩充样本数量的改进在某个点上趋于饱和。
表2:cub语义空间增强样本数量的消融研究。我们报告5-way 1-shot准确率。L1、l2、l3和l4表示我们分别只使用了layer 1、layer 2、layer 3和layer 4的增强特征。M-l表示使用四个层的所有增强特征

结果。如表 I 所示,竞争方法可以分为两类:元学习算法(包括 MAML、Meta-SGD、DEML+Meta-SGD、META-LEARN LSTM 和 Meta-Net)和度量学习算法(包括 Matching Nets、PROTO-NET、RELATION NET、SNAIL 和 MACO)。我们还报告了 ResNet-18(无数据扩充)的结果。我们框架(ResNet-18+双重 TriNet)的准确率也进行了报告。双重 TriNet 合成了 ResNet-18 的每一层特征,如第 III-D 节所述。ResNet-18+高斯噪声是一个简单的基线,通过向第 4 层特征添加高斯噪声来合成每个测试样本的 16 个样本。我们在表 I 中为 ResNet-18、ResNet-18+高斯噪声和 ResNet-18+双重 TriNet 使用 SVM 分类器。特别是,我们发现,
表1:在 miniIMAGENET 和 CUB-200 上的表现。 “±” 表示任务的 95% 置信区间。:表示对应的基准方法,这些方法使用的是 RESNET-18。请注意,之前的工作中在 CUB-200 上没有报告 “±”。*
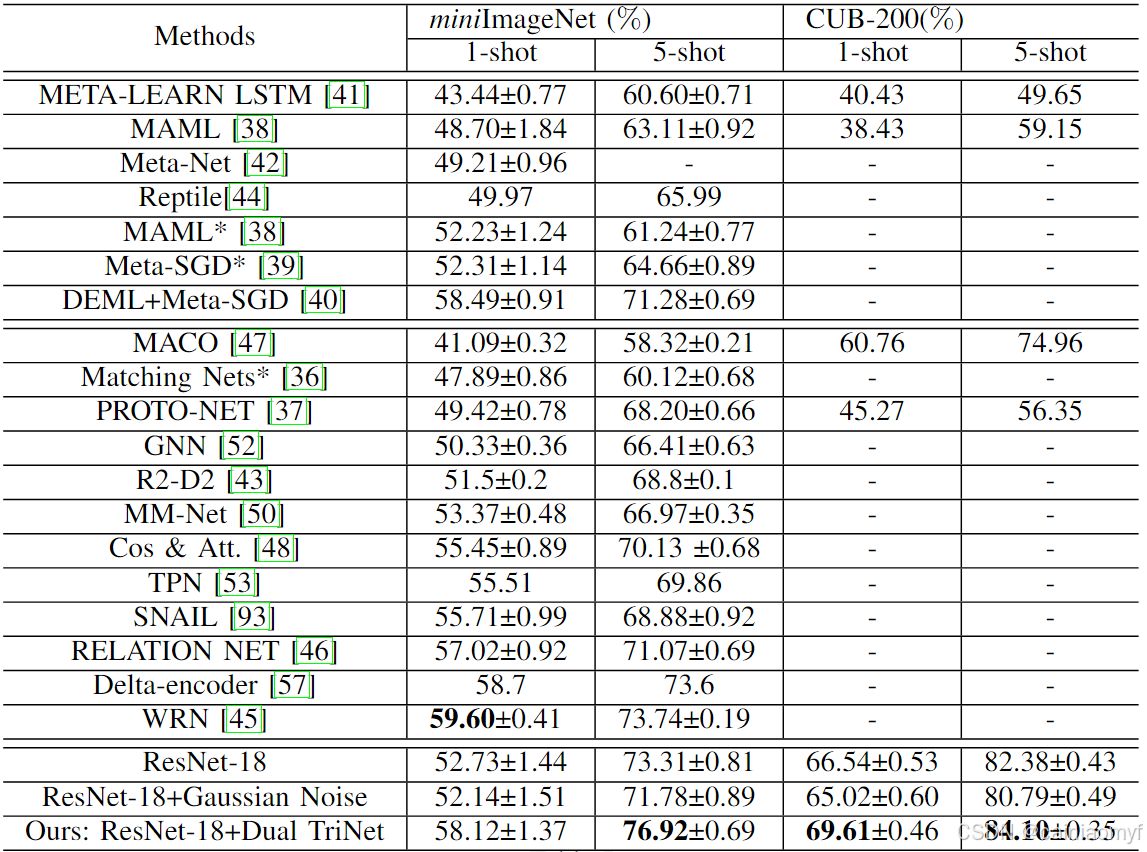
(1) 我们的基线(ResNet-18)几乎优于所有其他基线。ResNet-18 在学习残差的过程中受益匪浅,是单样本学习任务中非常优秀的特征提取器。先前的研究38 39 36 设计了具有较少参数的自定义网络架构并使用了不同的目标函数。如表 I 所示,将这些方法的主干架构替换为 ResNet-18 后,它们的表现仍不及我们的基线(ResNet-18)。我们认为这是因为 ResNet-18 更适合分类任务,并且使用交叉熵损失可以生成比度量学习中其他目标函数更具辨别力的空间。然而,此话题超出了我们的讨论范围。我们想澄清的是,由于我们的扩充方法可以与任意方法结合,我们选择了我们认为最强的基线。这个基线可以通过我们的方法得到增强,展示了我们扩充方法的通用性。
(2) 我们的框架可以实现最佳性能。如表 I 所示,我们的框架,即 ResNet-18+双重 TriNet,可以实现最佳性能,并且在两个数据集上明显优于所有其他基线。这验证了我们的框架在解决单样本学习任务中的有效性。需要注意的是,DEML+Meta-SGD40 使用 ResNet-50 作为基线模型,因此在单样本学习结果上优于我们的 ResNet-18。然而,通过双重 TriNet 生成的扩充数据,我们可以观察到 ResNet-18 有明显的提升。
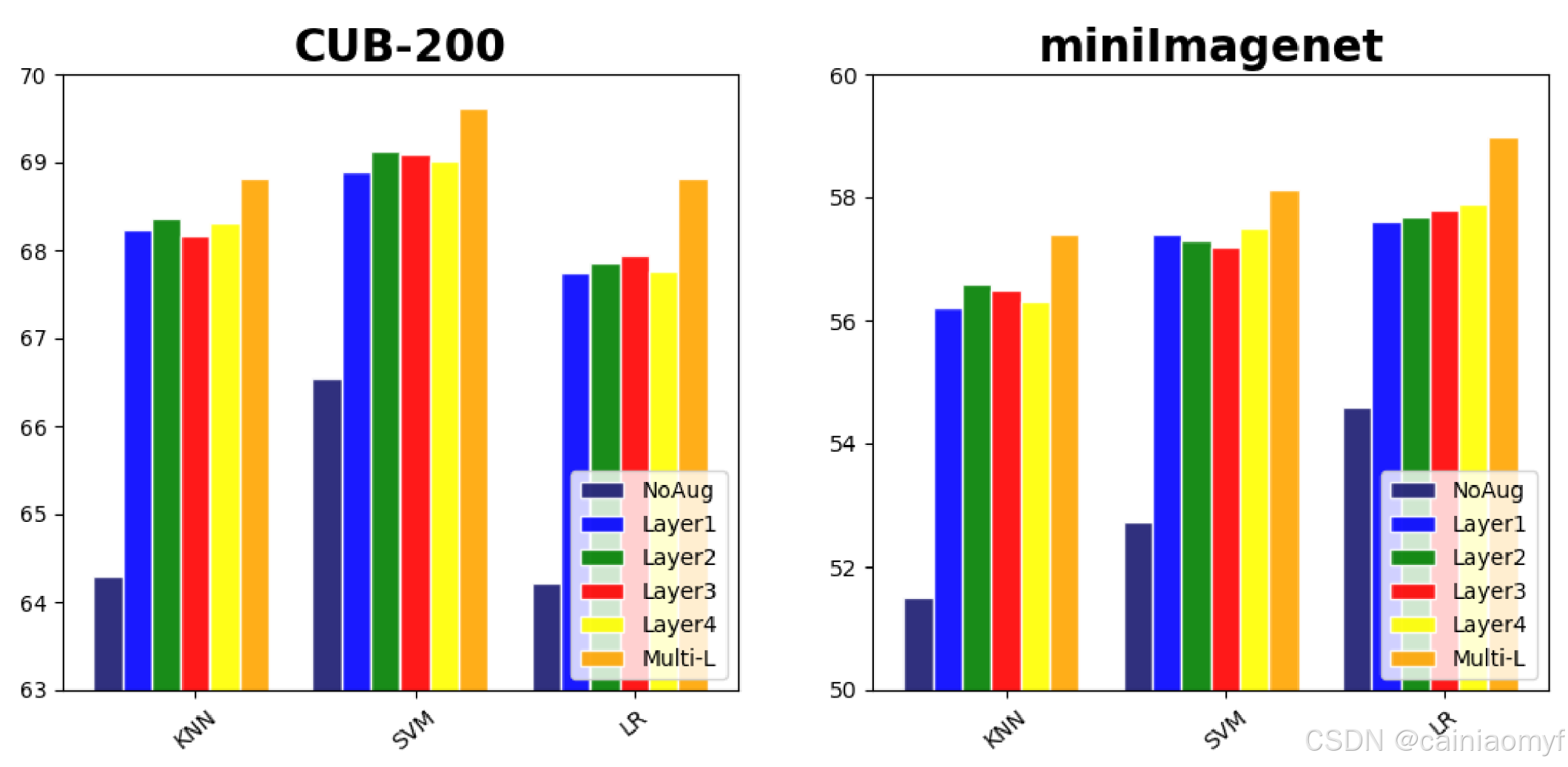
(3) 我们的框架可以有效地扩充多层特征。我们分析了各层扩充特征的有效性,如图 2 所示。在 CUB-200 和 miniImageNet 上,我们报告了 1-shot 学习情况的结果。我们得出以下结论:(1) 仅使用来自单层的扩充特征(例如,图 2 中的 Layer 1 – Layer 4)也可以提升单样本学习结果的性能。这验证了我们的双重 TriNet 在单一框架中合成不同层特征的有效性。(2) 使用来自所有层的合成实例(Multi-L)的结果比单独使用各层特征的结果更好。这表明不同层的扩充特征在本质上是互补的。
图 2. 在 CUB-200 和 miniImageNet 上使用不同层/分类器进行特征增强的单次学习结果。“NoAug“、”Layer1“、”Layer2“、”Layer3“、”Layer4 "表示没有任何增强的单次学习结果,以及使用 ResNet-18 的第 1 层、第 2 层、第 3 层和第 4 层进行特征增强的结果。“Multi-L "表示使用所有增强实例的单次学习结果。X 轴代表不同的监督分类器。
(4) 扩充特征可以提升不同监督分类器的性能。我们的扩充特征并非专为某一监督分类器设计。为证明这一点,并如图 2 所示,我们测试了三个经典的监督分类器(即 KNN、SVM 和 LR),结果显示我们的扩充特征可以在单样本分类中提升这三个监督分类器的性能。这进一步验证了我们扩充框架的有效性。
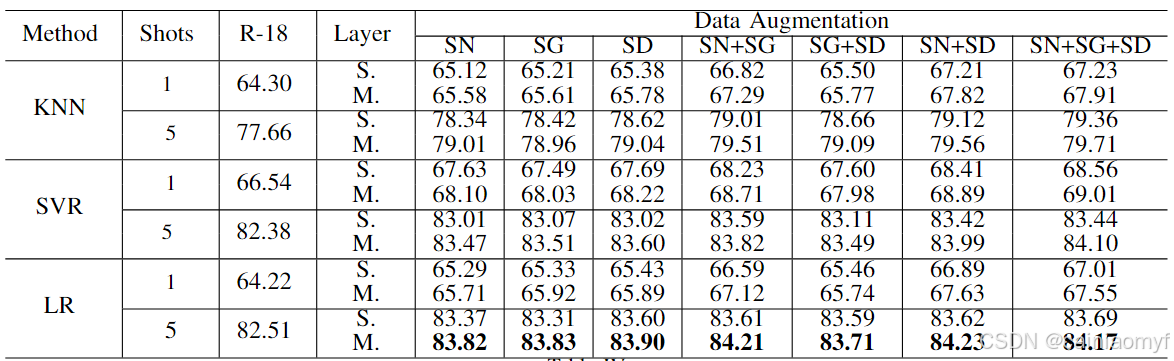
(5) SG、SN 和 AG 生成的扩充特征同样可以提升小样本学习结果。我们在图 3 中比较了不同语义空间的特征扩充方法。具体而言,我们比较了语义词向量空间中的 SG 和 SN 以及语义属性空间中的 AG。在 CUB-200 数据集中,SG、SN 和 AG 生成的扩充结果优于未扩充的结果。结合 SG、SN 和 AG 中任意两个方法生成的合成特征实例的准确率优于单独使用 SG、SN 或 AG 的结果。这意味着 SG、SN 和 AG 生成的扩充特征实例彼此互补。最后,我们观察到通过结合所有方法(SG、SN 和 AG)的扩充实例,单样本学习的准确率达到了最高。
(6) 即使是从类别的语义关系推断的语义空间,也可以很好地与我们的框架配合使用。为证明这一点,我们再次在图 3 中比较了结果。特别地,我们计算了使用语义词向量在 miniImageNet 数据集中获得的类别相似性矩阵。使用 SVD 分解相似性矩阵,SVD 的左奇异向量被认为构成了一个新的语义空间。因此,这个新的空间被用于学习双重 TriNet。我们在新扩展的空间中使用语义高斯(SG)来扩充实例特征以进行单样本分类。该结果称为“SVD-G”。我们在 miniImageNet 数据集中报告了 SVD-G 扩充的结果,见图 3。我们突出了一些有趣的观察:
- SVD-G 特征扩充的结果仍然优于没有任何扩充的结果。
- SVD-G 的准确率实际上略低于 SG,因为新扩展的空间是从原始语义词空间派生的。
- SVD-G 和 SG 之间的扩充特征几乎没有互补信息,这仍部分是由于新的空间由语义和词空间扩展而来。
- SVD-G 生成的扩充特征与 SN 生成的特征也具有很强的互补性,如图 3 中的结果所示。这是因为在派生新语义空间时未使用额外的邻域词汇信息。我们在 CUB-200 数据集上得到了类似的实验结论,如表 IV 所示。
图 3. 在 CUB-200 和 miniImageNet 上使用不同类型语义空间进行特征增强的单次结果。“单层 "表示仅使用单层进行增强的最佳单次结果。“多层 "表示使用所有层合成实例的结果。
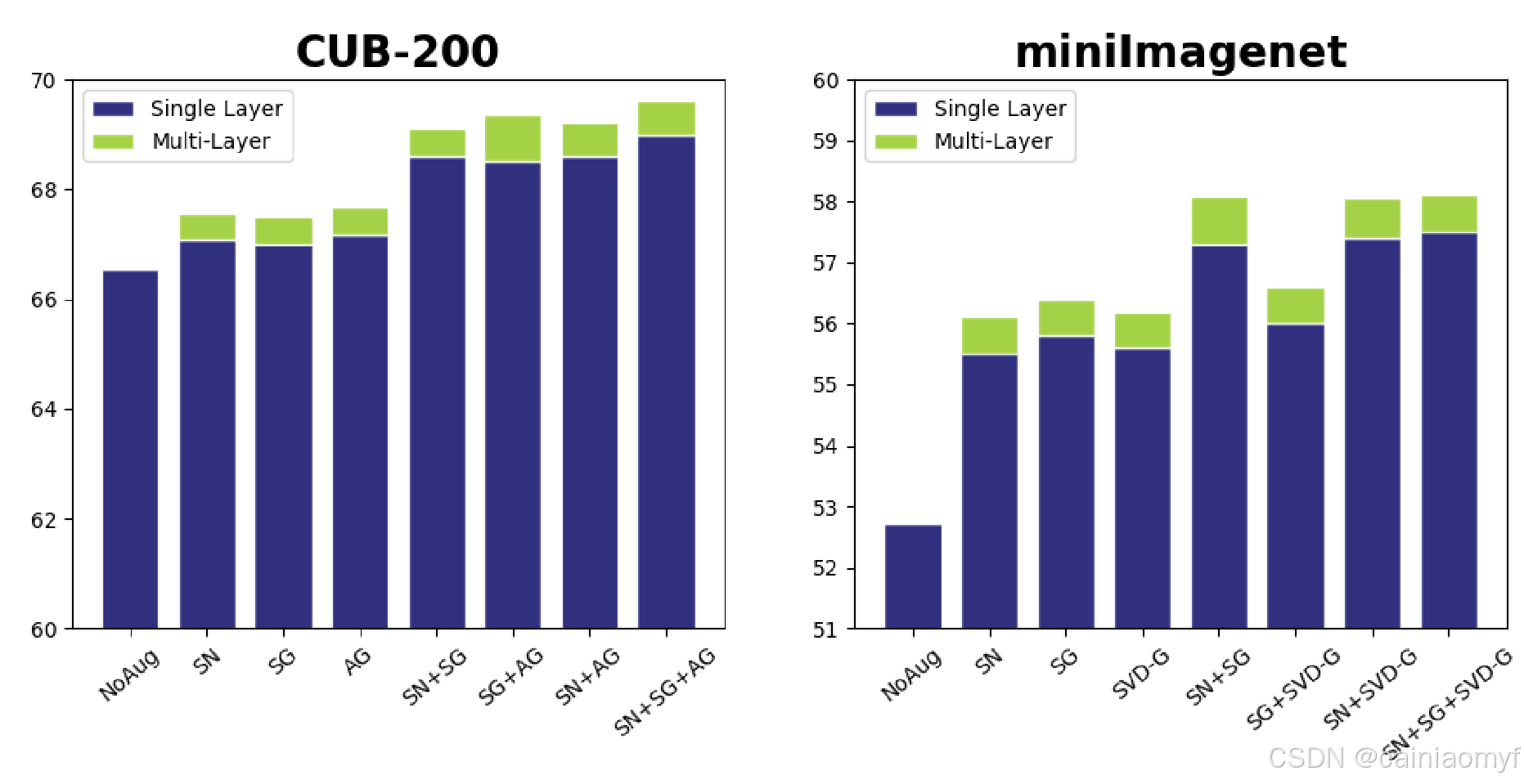
表4:在 CALTECH-UCSD 鸟类数据集上的 5-way 单次学习分类准确率。请注意:“S.” 和 “M.” 分别表示单层和多层。“SD” 是 “SVD-G” 的缩写。“R-18” 是 “RESNET-18” 的缩写。
4.5 Caltech-256 和 CIFAR-100 上的实验结果
设置。在 Caltech-256 和 CIFAR-100 数据集中,我们也使用语义词向量空间。对于一个训练实例,我们从 ResNet-18 的所有四层中分别为 SG 和 SN 合成 16 个扩充特征。在这两个数据集上,竞争方法的结果由文献40 实现并报告。我们报告的结果是使用由 SG 和 SN 生成的所有层的扩充特征实例得到的。SVM 分类器用作分类模型。
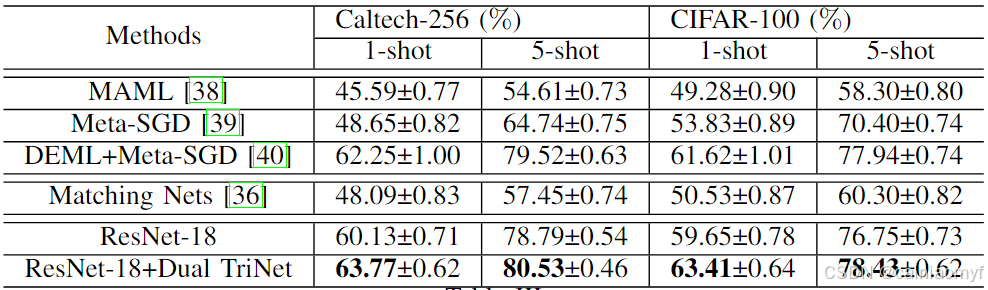
结果。Caltech-256 和 CIFAR-100 的结果在表 III 中显示。我们发现:(1) 与当前最先进的算法相比,我们的方法仍然能够达到最佳性能,这要归功于使用所提出的框架获得的扩充特征实例。(2) ResNet-18 仍然是一个非常强大的基线;它可以击败几乎所有其他基线,除了使用 ResNet-50 作为基线结构的 DEML+Meta-SGD。(3) 使用我们的扩充实例特征比仅使用 ResNet-18 有明显的性能提升。这进一步验证了所提出框架的有效性。
表3:在 CALTECH-256 和 CIFAR-100 数据集上的表现。 “±” 表示任务的 95% 置信区间。
5 FURTHER ANALYSIS
5.1 与标准增强方法的比较
除了我们的特征扩充方法外,我们还在单样本学习设置中比较了标准扩充方法2。这些方法包括对单样本类别的训练图像进行裁剪、旋转、翻转和颜色变换。此外,我们还尝试了向单样本类别训练实例的 ResNet-18 特征中添加高斯噪声的方法,结果见表 I。然而,这些方法均无法提高单样本学习的分类准确率。这是合理的,因为单样本类别只有极少的训练样本。某种程度上,这在意料之中:此类简单的扩充方法本质上只是增加了噪声/方差,而未引入额外信息来帮助单样本分类。
5.2 Dual TriNet structure
我们提出了双重 TriNet 结构,本质上是由编码器-解码器架构派生的。因此,我们进一步分析了用于特征扩充的其他替代网络结构。特别地,扩充网络的替代选择可以是每层的自编码器94 或 U-net95。结果见表 V。我们显示出我们的双重 TriNet 可以最佳地利用不同层次的互补信息,因此我们的结果优于没有扩充(ResNet-18)、使用 U-net 扩充(ResNet-18+U-net)和使用自编码器扩充(ResNet-18+Auto-encoder)的结果。这验证了我们的双重 TriNet 可以有效地融合和利用多层信息进行特征扩充。
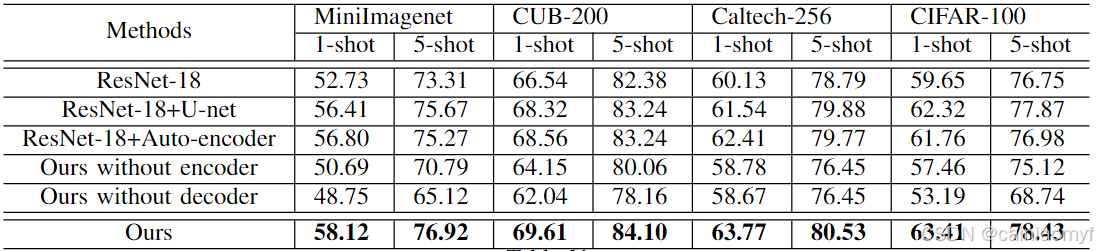
此外,我们进行了实验来证明编码器部分和解码器部分是必要的。如果我们简单地使用真实标签的语义向量 u b a s e z i u_{base}^{z_i} ubasezi,而不是编码器 g E n c ( { f ( l ) ( I s u p p o r t ( i ) ) } ) g_{Enc}(\{f^{(l)}(I_{support}^{(i)})\}) gEnc({f(l)(Isupport(i))}),则扩充样本实际上会降低性能。在仅在语义空间中进行分类的情况下(即有效禁用解码器),性能下降超过 5%。这是因为在从视觉空间到语义空间的映射过程中丢失了信息,而我们的方法保留了原始信息并从语义空间获得了额外信息。
5.3 Visualization
使用文献96 中的技术,我们可以可视化生成 ResNet-18 中扩充特征 f ^ ( l ) ( I i ) = g ( f ( l ) ( I i ) ) \hat{f}^{(l)}(I_i) = g(f^{(l)}(I_i)) f^(l)(Ii)=g(f(l)(Ii)) 的图像。我们首先随机生成一个图像 I i ( 0 ) I_i^{(0)} Ii(0),然后通过减少 f ( l ) ( I i ( 0 ) ) f^{(l)}(I_i^{(0)}) f(l)(Ii(0)) 和 f ^ ( l ) ( I i ) \hat{f}^{(l)}(I_i) f^(l)(Ii) 之间的距离来优化 I i ( 0 ) I_i^{(0)} Ii(0)(两者均为 ResNet-18 的输出):
I i ( 0 ) = arg min I i ( 0 ) 1 2 ∥ f ( l ) ( I i ( 0 ) ) − f ^ ( l ) ( I i ) ∥ 2 2 + λ ⋅ R ( I i ( 0 ) ) I_i^{(0)} = \arg \min_{I_i^{(0)}} \frac{1}{2} \left \| f^{(l)}(I_i^{(0)}) - \hat{f}^{(l)}(I_i) \right \|_2^2 + \lambda \cdot R(I_i^{(0)}) Ii(0)=argIi(0)min21 f(l)(Ii(0))−f^(l)(Ii) 22+λ⋅R(Ii(0))
其中
R
(
⋅
)
R(\cdot)
R(⋅) 是用于图像平滑的总变分正则项,
λ
=
1
×
1
0
−
2
\lambda = 1 \times 10^{-2}
λ=1×10−2。当差异足够小时,
I
i
(
0
)
I_i^{(0)}
Ii(0) 应该能够表示生成相应扩充特征的图像。
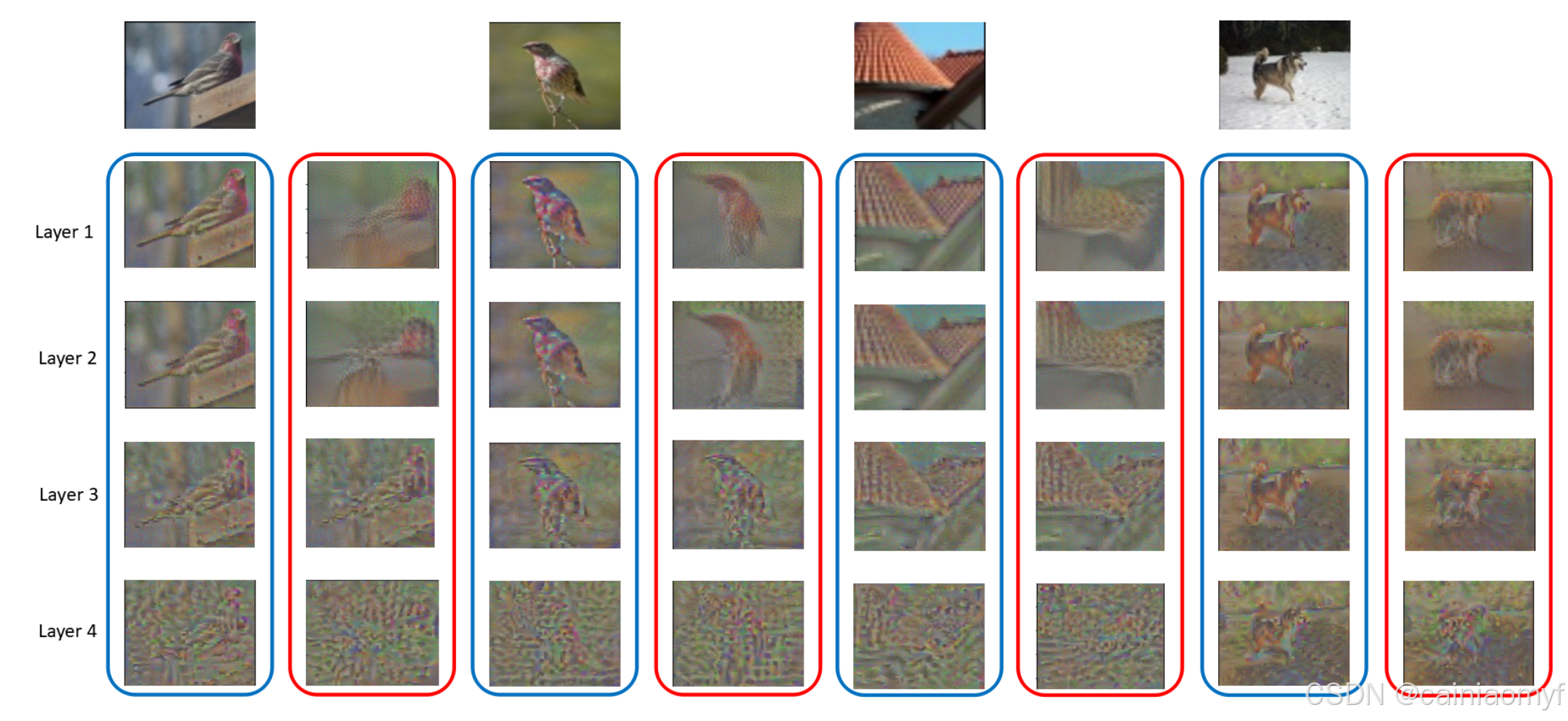
通过使用 SN 和上述可视化算法,我们在图 4 中可视化了原始和扩充特征。顶行显示了两只鸟、一屋顶和一只狗的输入图像。蓝色圆圈和红色圆圈分别表示第 1 层至第 4 层的原始和扩充特征的可视化。扩充特征的可视化与原始图像相似但有所不同。例如,前两列显示,扩充特征的可视化实际上略微改变了鸟的头部姿势。在最后两列中,扩充特征清晰地可视化出了一只狗,其外观与输入图像不同。这直观地展示了我们的框架为何有效。
图4:原始特征和增强特征的可视化
6 CONCLUSIONS
本研究提出了一种用于特征扩充的端到端框架。所提出的双重 TriNet 结构可以高效且直接地扩充多层视觉特征,以提升小样本分类性能。我们展示了该框架可以有效地解决四个数据集上的小样本分类问题。我们主要在分类任务上进行评估;将扩充特征扩展到其他相关任务(如单样本图像/视频分割86 87)也是一个有趣的未来研究方向。此外,尽管双重 TriNet 在这里与 ResNet-18 配对,我们可以轻松地将其扩展到其他特征提取网络,例如 ResNet-50。
Thrun, S.: Learning To Learn: Introduction. Kluwer Academic Publishers (1996) I, II-A ↩︎ ↩︎
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS. (2012) I, II-B, III-B, III-E, V-A ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Fu, Y., Hospedales, T.M., Xiang, T., Gong, S.: Transductive multi-view zero-shot learning. IEEE TPAMI (2015) I, II-B ↩︎ ↩︎
Wang, Y., Hebert, M.: Learning from small sample sets by combining unsupervised meta-training with cnns. In: NIPS. (2016) I, II-B ↩︎ ↩︎
Wang, Y., Hebert, M.: Learning to learn: model regression networks for easy small sample learning. In: ECCV. (2016) I, II-B ↩︎ ↩︎
Li, Z., Hoiem, D.: Learning without forgetting. In: ECCV. (2016) I, II-B ↩︎ ↩︎
Lim, J., Salakhutdinov, R., Torralba, A.: Transfer learning by borrowing examples for multiclass object detection. In: NIPS. (2011) I, II-B ↩︎ ↩︎
Movshovitz-Attias, Y.: Dataset curation through renders and ontology matching. In: Ph.D. thesis, CMU. (2015) I, II-B ↩︎ ↩︎
Park, D., Ramanan, D.: Articulated pose estimation with tiny synthetic videos. In: CVPR. (2015) I, II-B ↩︎ ↩︎
Movshovitz-Attias, Y., Yu, Q., Stumpe, M., Shet, V., Arnoud, S., Yatziv, L.: Ontological supervision for fine grained classification of street view storefronts. In: CVPR. (2015) I, II-B ↩︎ ↩︎
Dosovitskiy, A., Springenberg, J., Brox, T.: Learning to generate chairs with convolutional neural networks. In: CVPR. (2015) I, II-B ↩︎ ↩︎
Zhu, X., Vondrick, C., Fowlkes, C., Ramanan, D.: Do we need more training data? In: IJCV. (2016) I, II-B ↩︎ ↩︎ ↩︎ ↩︎
Opelt, A., Pinz, A., Zisserman, A.: Incremental learning of object detectors using a visual shape alphabet. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 1. (2006) 3–10 I, II-B ↩︎ ↩︎ ↩︎ ↩︎
Dixit, M., Kwitt, R., Niethammer, M., Vasconcelos, N.: Aga: Attribute guided augmentation. In: CVPR. (2017) I, II-B, III-C ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Neural Information Processing Systems. (2013) I, III-A, III-C, III-D, III-D ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. (2015) I, III-B, III-B, III-E ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Jankowski, Norbert, Duch, Wodzislaw, Grabczewski, Krzyszto: Metalearning in computational intelligence. In: Springer Science & Business Media. (2011) II-A ↩︎
Lake, B.M., Salakhutdinov, R.: One-shot learning by inverting a compositional causal process. In: NIPS. (2013) II-A ↩︎
Bart, E., Ullman, S.: Cross-generalization: learning novel classes from a single example by feature replacement. In: CVPR. (2005) II-A ↩︎ ↩︎
Fei-Fei, L., Fergus, R., Perona, P.: A bayesian approach to unsupervised one-shot learning of object categories. In: IEEE International Conference on Computer Vision. (2003) II-A ↩︎
Fei-Fei, L., Fergus, R., Perona, P.: One-shot learning of object categories. IEEE TPAMI (2006) II-A ↩︎
Tommasi, T., Caputo, B.: The more you know, the less you learn: from knowledge transfer to one-shot learning of object categories. In: British Machine Vision Conference. (2009) II-A ↩︎
Rezende, D.J., Mohamed, S., Danihelka, I., Gregor, K., Wierstra, D.: One-shot generalization in deep generative models. In: ICML. (2016) II-A ↩︎
Santoro, Bartunov, S., Botvinick, M., Wierstra, D., Lillicrap, T.: Oneshot learning with memory-augmented neural networks. In: arx. (2016) II-A ↩︎
Kingma, D., Welling, M.: Auto-encoding variational bayes. In: ICLR. (2014) II-A ↩︎
JVilalta, R., Drissi, Y.: A perspective view and survey of meta-learning. Artificial intelligence review (2002) II-A ↩︎
Hertz, T., Hillel, A., Weinshall, D.: Learning a kernel function for classification with small training samples. In: ICML. (2016) II-A, II-C ↩︎ ↩︎
Fleuret, F., Blanchard, G.: Pattern recognition from one example by chopping. In: NIPS. (2005) II-A ↩︎
Amit, Y., Fink, M., S., N., U.: Uncovering shared structures in multiclass classification. In: ICML. (2007) II-A ↩︎
Wolf, L., Martin, I.: Robust boosting for learning from few examples. In: CVPR. (2005) II-A ↩︎
Torralba, A., Murphy, K., Freeman, W.: sharing visual features for multiclass and multiview object detection. In: IEEE TPAMI. (2007) II-A ↩︎
Lampert, C.H., Nickisch, H., Harmeling, S.: Attribute-based classification for zero-shot visual object categorization. IEEE TPAMI (2013) II-A, II-C, III-A, IV-B ↩︎ ↩︎ ↩︎ ↩︎
Rohrbach, M., Ebert, S., Schiele, B.: Transfer learning in a transductive setting. In: NIPS. (2013) II-A ↩︎
Rohrbach, M., Stark, M., Szarvas, G., Gurevych, I., Schiele, B.: What helps where – and why? semantic relatedness for knowledge transfer. In: CVPR. (2010) II-A ↩︎
Torralba, A., Murphy, K.P., Freeman, W.T.: Using the forest to see the trees: Exploiting context for visual object detection and localization. Commun. ACM (2010) II-A ↩︎
Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., Wierstra, D.: Matching networks for one shot learning. In: NIPS. (2016) II-A, II-C, IV-A, IV-C, IV-D, IV-D ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Snell, J., Swersky, K., Zemeln, R.S.: Prototypical networks for few-shot learning. In: NIPS. (2017) II-A, IV-A, IV-C ↩︎ ↩︎ ↩︎
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: ICML. (2017) II-A, IV-A, IV-C, IV-D, IV-D ↩︎ ↩︎ ↩︎
Li, Z., Zhou, F., Chen, F., Li, H.: Meta-sgd: Learning to learn quickly for few shot learning. In: arxiv:1707.09835. (2017) II-A, IV-A, IV-C, IV-D, IV-D ↩︎ ↩︎ ↩︎
Zhou, F., Wu, B., Li, Z.: Deep meta-learning: Learning to learn in the concept space. In: arxiv:1802.03596. (2018) II-A, IV-A, IV-C, IV-D, IV-E, IV-D ↩︎ ↩︎ ↩︎ ↩︎
Ravi, S., Larochelle, H.: Optimization as a model for few-shot learning. In: ICLR. (2017) II-A, IV-A, IV-B, IV-C ↩︎ ↩︎ ↩︎ ↩︎
Munkhdalai, T., Yu, H.: Meta networks. In: ICML. (2017) II-A, IV-A, IV-C ↩︎ ↩︎
Bertinetto, L., Henriques, J.F., Torr, P.H.S., Vedaldi, A.: Meta-learning with differentiable closed-form solvers. In: ICLR. (2019) II-A, IV-A, IV-C ↩︎ ↩︎
Nichol, A., Achiam, J., Schulman, J.: On first-order meta-learning algorithms. CoRR abs/1803.02999 (2018) II-A, IV-A, IV-C ↩︎ ↩︎
Qiao, S., Liu, C., Shen, W., Yuille, A.L.: Few-Shot Image Recognition by Predicting Parameters from Activations. In: CVPR. (2018) II-A, IV-A, IV-C ↩︎ ↩︎
Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P.H., Hospedales, T.M.: Learning to compare: Relation network for few-shot learning. In: CVPR. (2018) II-A, IV-A, IV-C ↩︎ ↩︎
Hilliard, N., Phillips, L., Howland, S., Yankov, A., Corley, C.D., Hodas, N.O.: Few-Shot Learning with Metric-Agnostic Conditional Embeddings. ArXiv e-prints (February 2018) II-A, IV-A, IV-C ↩︎ ↩︎ ↩︎
Gidaris, S., Komodakis, N.: Dynamic Few-Shot Visual Learning without Forgetting. In: CVPR. (2018) II-A, IV-A, IV-C ↩︎ ↩︎
zhongwen xu, linchao zhu, Yang, Y.: Few-shot object recognition from machine-labeled web images. In: arxiv. (2016) II-A ↩︎
Cai, Q., Pan, Y., Yao, T., Yan, C., Mei, T.: Memory Matching Networks for One-Shot Image Recognition. (2018) II-A, IV-A, IV-C ↩︎ ↩︎
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: Proceedings of the 34th International Conference on Machine Learning. (2017) 1126–1135 II-A ↩︎
Garcia, V., Bruna, J.: Few-shot learning with graph neural networks. In: ICLR. (2018) II-A, IV-A, IV-C ↩︎ ↩︎
Liu, Y., Lee, J., Park, M., Kim, S., Yang, Y.: Transductive Propagation Network for Few-shot Learning. In: ICLR. (2019) II-A, IV-A, IV-C ↩︎ ↩︎
Wang, P., Liu, L., Shen, C., Huang, Z., Hengel, A., Tao Shen, H.: Multiattention network for one shot learning. In: CVPR. (07 2017) 6212–6220 II-A ↩︎
Chatfield, K., Simonyan, K., Vedaldi, A., Zisserman, A.: Return of the devil in the details: Delving deep into convolutional nets. In: BMVC. (2014) II-B ↩︎
Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: ECCV. (2014) II-B, III-C ↩︎ ↩︎
Schwartz, E., Karlinsky, L., Shtok, J., Harary, S., Marder, M., Feris, R., Kumar, A., Giryes, R., Bronstein, A.M.: Delta-encoder: an effective sample synthesis method for few-shot object recognition. In: NIPS. (2018) II-B, IV-A, IV-C ↩︎ ↩︎
Fu, Y., Sigal, L.: Semi-supervised vocabulary-informed learning. In: CVPR. (2016) II-B, III-D, IV-B ↩︎ ↩︎ ↩︎
Ba, J.L., Swersky, K., Fidler, S., Salakhutdinov, R.: Predicting deep zero-shot convolutional neural networks using textual descriptions. In: ICCV. (2015) II-B ↩︎
Su, H., Qi, C.R., Li, Y., Guibas, L.J.: render for cnn viewpoint estimation in images using cnns trained with rendered 3d model views. In: ICCV. (2015) II-B ↩︎
Charalambous, C.C., Bharath, A.A.: A data augmentation methodology for training machine/deep learning gait recognition algorithms. In: BMVC. (2016) II-B ↩︎
Rogez, G., Schmid, C.: mocap-guided data augmentation for 3d pose estimation in the wild. In: NIPS. (2016) II-B ↩︎
Peng, X., Sun, B., Ali, K., Saenko, K.: Learning deep object detectors from 3d models. In: ICCV. (2015) II-B ↩︎
Hariharan, B., Girshick, R.: Low-shot visual recognition by shrinking and hallucinating features. In: ICCV. (2017) II-B ↩︎
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: ICCV. (2017) II-B ↩︎
Zhu, J.Y., Kr ̈ahenb ̈uhl, P., Shechtman, E., Efros, A.A.: Generative visual manipulation on the natural image manifold. In: ECCV. (2016) II-B ↩︎
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., DavidWardeFarley, Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: NIPS. (2014) II-B ↩︎
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., Lee, H.: Generative adversarial text-to-image synthesis. In: ICML. (2016) II-B ↩︎
Radford, A., Metz, L., Chintala, S.: Unsupervised representation learning with deep convolutional generative adversarial networks. In: arxiv. (2016) II-B ↩︎
Mao, X., Li, Q., Xie, H., Lau, R.Y., Wang, Z.: Least squares generative adversarial networks. In: arxiv. (2017) II-B ↩︎
Durugkar, I., Gemp, I., Mahadevan, S.: Generative multi-adversarial networks. In: ICLR. (2017) II-B ↩︎
Huang, X., Li, Y., Poursaeed, O., Hopcroft, J., Belongie, S.: Stacked generative adversarial networks. In: CVPR. (2017) II-B ↩︎
Wang, Y.X., Girshick, R., Hebert, M., Hariharan, B.: Low-Shot Learning from Imaginary Data. In: CVPR. (2018) II-B ↩︎
Liu, B., Dixit, M., Kwitt, R., Vasconcelos, N.: Feature space transfer for data augmentation. In: CVPR. (2018) II-B ↩︎
Bromley, J., Bentz, J., Bottou, L., Guyon, I., LeCun, Y., Moore, C., Sackinger, E., Shah, R.: Signature verification using a siamese time delay neural network. In: IJCAI. (1993) II-C ↩︎
Koch, G., Zemel, R., Salakhutdinov, R.: Siamese neural networks for one-shot image recognition. In: ICML – Deep Learning Workshok. (2015) II-C ↩︎
Farhadi, A., Endres, I., Hoiem, D., Forsyth, D.: Describing objects by their attributes. In: CVPR. (2009) II-C ↩︎
Kienzle, W., Chellapilla, K.: Personalized handwriting recognition via biased reg- ularization. In: ICML. (2006) II-C ↩︎
Quattoni, A., Collins, M., Darrell, T.: Transfer learning for image classification with sparse prototype representations. In: IEEE Conference on Computer Vision and Pattern Recognition. (2008) 1–8 II-C ↩︎
Fink, M.: Object classification from a single example utilizing class relevance metrics. In: NIPS. (2005) II-C ↩︎
Wolf, L., Hassner, T., Taigman, Y.: The one-shot similarity kernel. In: ICCV. (2009) II-C ↩︎
Rasmus, A., Valpola, H., Honkala, M., Berglund, M., Raiko, T.: Semisupervised learning with ladder networks. In: NIPS. (2015) II-C ↩︎
Wang, J., Wei, Z., Zhang, T., Zeng, W.: Deeply-fused nets. In: arxiv:1505.05641. (2016) II-C ↩︎
Yu, F., Wang, D., Shelhamer, E., Darrell, T.: Deep layer aggregation. In: CVPR. (2018) II-C ↩︎
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR. (2015) III-B ↩︎
Shaban, A., Bansal, S., Liu, Z., Essa, I., Boots, B.: One-shot learning for semantic segmentation. In: BMVC. (2017) III-B, VI ↩︎ ↩︎
Caelles, S., Maninis, K.K., Pont-Tuset, J., Leal-Taixe, L., Cremers, D., Gool, L.V.: One-shot video object segmentation. In: CVPR. (2017) III-B, VI ↩︎ ↩︎
Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? In: NIPS. (2014) III-C ↩︎
Krizhevsky, A.: Learning multiple layers of features from tiny images. (2009) IV-A ↩︎
Zhou, F., Wu, B., Li, Z.: Deep Meta-Learning: Learning to Learn in the Concept Space. ArXiv e-prints (February 2018) IV-A ↩︎ ↩︎
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The CaltechUCSD Birds-200-2011 Dataset. Technical Report CNS-TR-2011-001, California Institute of Technology (2011) IV-A, IV-B ↩︎ ↩︎
Griffin, G., Holub, A., Perona, P.: Caltech-256 object category dataset. (2007) IV-A ↩︎
Mishra, N., Rohaninejad, M., Chen, X., Abbeel, P.: A simple neural attentive meta-learner. In: ICLR. (2016) IV-A, IV-C ↩︎
Hinton, G.E., Salakhutdinov, R.R.: reducing the dimensionality of data with neural networks. (2006) V-B ↩︎
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI. (2015) V-B ↩︎
Mahendran, A., Vedaldi, A.: Understanding Deep Image Representations by Inverting Them. ArXiv e-prints (November 2014) V-C ↩︎