前言
关于数据结构中的树,想必都不会很陌生,今天,主要给大家一起学习搜索二叉树(BST)前面,我们掌握学习过二叉树的三种遍历方式(前序,中序,后序的递归版本),以及我们实现过顺序结构的树(堆),前面的树在储存数据方面,并没有多大的意义,而今天所说的二叉搜索树在数据存储方面就有了很大的意义。
二叉搜索树的基本概念
二叉搜索树又称二叉排序树,它主要有以下三条特性:
1、若根的左子树不为空,则它左子树上的所有节点都小于根结点。
2、若根的右子树不为空,则它柚子树上的所有结点都大于根结点。
3、他的左右子树也分别为二叉搜索树。
总结:也就是说,对于任何一个结点,若左子树存在,左子结点必小于该结点,若右子树存在,则右子结点必大于该结点;(记住,对于任何结点来说,这里的小于是左子树上所有结点都小于,大于也是如此)
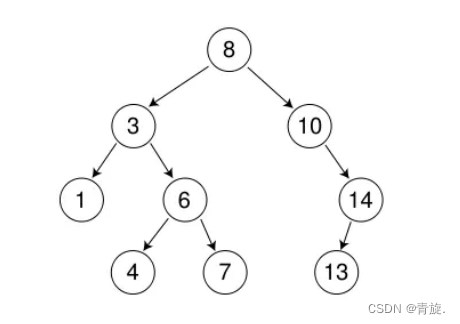
二叉搜索树的操作
二叉搜索树主要操作为查找,插入,删除以及遍历。说到遍历,这里不得不提,二叉搜索树另一特点,二叉搜索树的中序遍历是升序的。接下来我们一一实现二叉搜索树相关接口。
基本框架
我们后面在来实现二叉搜索树的默认构造,拷贝构造,赋值重载以及析构函数,首先我们要清楚二叉搜索树是由一个一个结点组成,我们将这个结点也用类封装起来,二叉搜索树类中存放根节点的地址。
template<class K, class V>
struct BSTreeNode
{
K _key;
V _value;
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
//默认构造函数, 用于后续new创建节点
BSTreeNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _right(nullptr)
, _left(nullptr)
{}
};
template<class K, class V>
class BSTree
{
typedef BSTreeNode<K, V> Node;//节点重命名
public:
//默认构造
BSTree()
:_root(nullptr)
{}
//拷贝构造
BSTree(BSTree<K, V>& t)
{
_root = Copy(t._root);
}
//赋值重载
BSTree<K, V>& operator=(BSTree<K, V> t)
{
swap(_root, t._root);
return *this;
}
//析构函数
~BSTree()
{
Destory(_root);
}
private:
Node* _root = nullptr;
};
}
中序遍历
提供这个接口可以让我们清楚的观察到我们实现的树是否是一棵二叉搜索树,因为二叉搜索树的中序遍历是升序的。对于中序遍历,想必大家都轻车熟路,这里不做特殊讲解,不过这里需要特别注意的是,由于中序遍历的递归版本一般是需要传根节点这一参数的,而类外无法访问私有成员,因此这里做了一个很巧妙地设计,后面许多递归都是使用这个巧妙设计的。
public:
void inorder()
{
_inorder(_root);
std::cout << std::endl;
}
private:
void _inorder(Node* root)
{
if (root == nullptr)
return;
_inorder(root->_left);
std::cout << root->_key << " ";
_inorder(root->_right);
}数据插入
首先我们需要查找数据待插入的位置(为了保证插入数据后整体依然是一颗二叉搜索树).。同时查找插入位置时,只有key是有严格要求的,Value只是附带。
即:如果根节点为空,即是待插入数据位置;否则开始查找,如果待插入数据大于根节点往右子树节点走;如果待插入数据小于根节点往左子树节点走。不断循环,直到查找到空节点时,即为数据待插入的位置;如果查找到的大小和待插入数据值相等则返回false(确保二叉搜索树中的每个节点唯一)
bool InsertR(const K& key, const V& value)
{
//由于我们查找位置需要从根节点开始查找,所以这里通过另一个函数来传递实现
return _InsertR(_root, key, value);
}
bool _InsertR(Node*& root, const K& key, const V& value)
{
if (root == nullptr)
{
//注意上述我们形参都是引用,所以不用新增Parent节点
root = new Node(key, value);
return true;
}
if (root->_key > key)//待插入数据小于当前节点,往左子树查找
return _InsertR(root->_left, key, value);
else if (root->_key < key)//待插入数据大于当前节点,往右子树查找
return _InsertR(root->_right, key, value);
else
return false;
}
数据删除
删除数据,我们首先需要和插入数据一样,先查找到待删除节点。和插入类似就不多说了。
bool Erase(const K& key)
{
if (_root == nullptr)//为空即不存在待删除数据
return false;
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key > key)//待删除数据小于当前节点,往左子树查找
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)//待删除数据大于当前节点,往右子树查找
{
parent = cur;
cur = cur->_right;
}
else
{
//当前位置即为待删除节点,装备删除数据
}
}
return false;//整棵树中不存在待删除数据
}
删除数据及相关节点调整
插找到待删除数据后,显然如果只是简单将该节点删除,有可能将不满足二叉搜索树的要求,那怎么办呢?
删除数据分为以下三种情况:
1.左子树为空
左子树为空主要分为以下情形:右子树为空,左子树不为空;左右子树均为空(省略)。
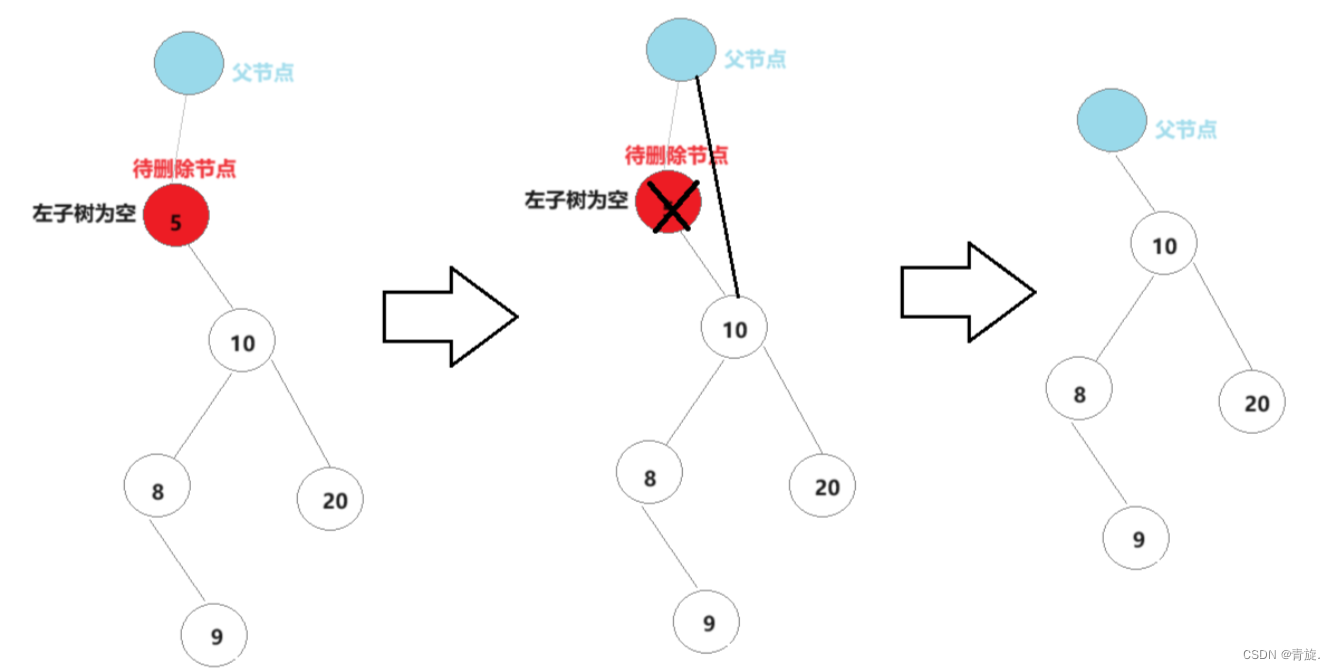
不管上述那种情况,我们发现只需将父节点的下一个节点指向待删除节点的右指针即可。但需要注意的是,如果待删除节点为根节点,它将没有父节点,需要单独处理。
if (cur->_left == nullptr)//左子树为空
{
if (parent == _root)//cur为根节点
{
_root = cur->_right;
}
else
{
if (parent->_key > cur->_key)//待删除节点在父节点左子树中
{
parent->_left = cur->_right;
}
else//待删除节点在父节点右子树中
{
parent->_right = cur->_right;
}
}
delete cur;
}
2.右子树为空
右子树为空分为单纯右子树为空和左右子树均为空(省)。具体处理方式和左子树为空类似就不多说了。

//左右子树均不为空,查找右子树最小元素进行交换后删除
if (parent == _root)//cur为根节点
{
_root = cur->_left;
}
else
{
if (parent->_key > cur->_key)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
3.左右子树均不为空
这种情况我们可以查找左子树最大值或右子树最小值和待删除删除节点进行交换,交换后我们可以转化为上述两种子问题来删除数据。(接下来博主以交换右子树最小值为例)
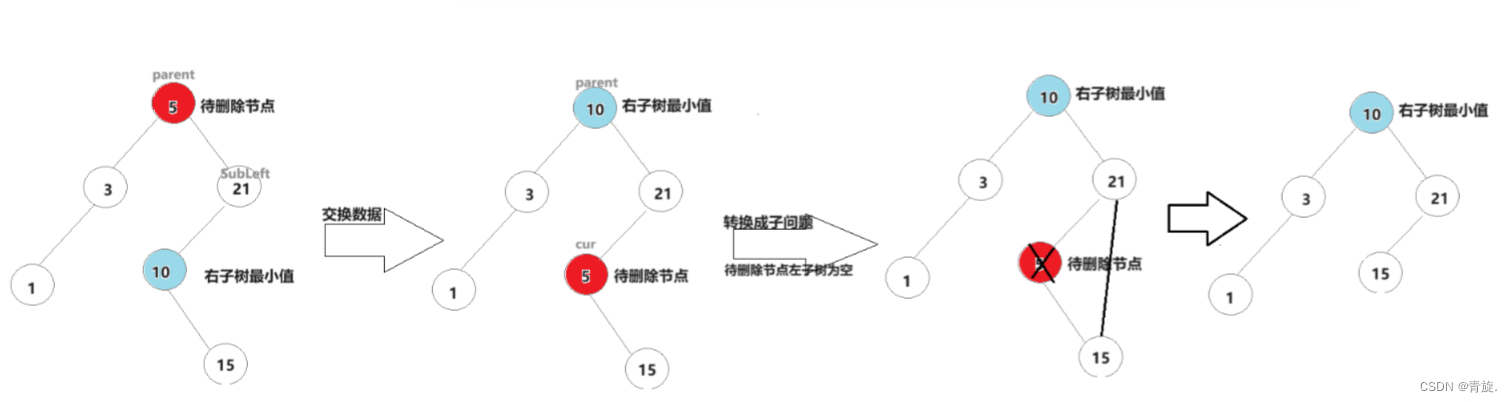
Node* subLeft = cur->_right;
Node* parent = cur;
while (subLeft->_left)
{
parent = cur;
subLeft = subLeft->_left;
}
//交换
swap(cur->_key, subLeft->_key);
swap(cur->_value, subLeft->_value);
//删除
if (parent->_right = subLeft)
{
parent->_right = subLeft->_right;
}
else
{
parent->_left = subLeft->_right;
}
delete subLeft;
完整代码:
//删除:递归版本
bool EraseR(const K& key)
{
return _EraseR(_root, key);//同理,由于需要根节点,在通过一层函数来实现
}
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)//非找到
return false;
if (root->_key > key)//转化成递归子问题,在左子树中删除key
return _EraseR(root->_left, key);
else if (root->_key < key)//转化成递归子问题,在右子树中删除key
return _EraseR(root->_right, key);
else
{//删除数据
if (root->_left == nullptr)
{
Node* del = root;
root = root->_right;
delete del;
return true;
}
else if (_root->_right == nullptr)
{
Node* del = root;
root = root->_left;
delete del;
return true;
}
else
{
Node* subLeft = root->_right;
while (subLeft->_left)
{
subLeft = subLeft->_left;
}
//交换
swap(root->_key, subLeft->_key);
swap(root->_value, subLeft->_value);
return _EraseR(root->_right, key);
}
}
}
查找数据
//查找:递归版本
Node* FindR(const K& key)
{
return _FindR(_root, key);
}
Node* _FindR(Node*& root, const K& key)
{
if (root == nullptr)
return nullptr;
if (root->_key > key)
return _FindR(root->_left, key);
else if (root->_key < key)
return _FindR(root->_right, key);
else
return root;
}
Key模型与Key_Value模型
Key模型应用场景
我们实现的二叉搜索树是Key模型,一个结点存放一个值,这种key类型的模型应用于哪里呢?实际上,这种key模型通常用来解决在不在的问题;
例如:我们想查看一篇文章的单词是否都拼写正确;这时我们使用在不在的思路,我们要将文章中每个单词在词库中查找,查看是否存在,以下我们便写了一个Key模型的使用。
void TestKey()
{
KeyModel::BSTree<std::string> dict;
dict.insert("left");
dict.insert("right");
dict.insert("computer");
dict.insert("insert");
dict.insert("erase");
// 模拟检查每个单词是否拼写正确
while (true)
{
std::string str;
std::cin >> str;
bool is_exist = dict.find(str);
if (is_exist)
std::cout << "在" << std::endl;
else
std::cout << "不在" << std::endl;
}
}
Key_Value模型
关于Key_Value模型,通常主要是通过一个值查找另一个值,是一种一 一对应的关系,一个key对应一个value;
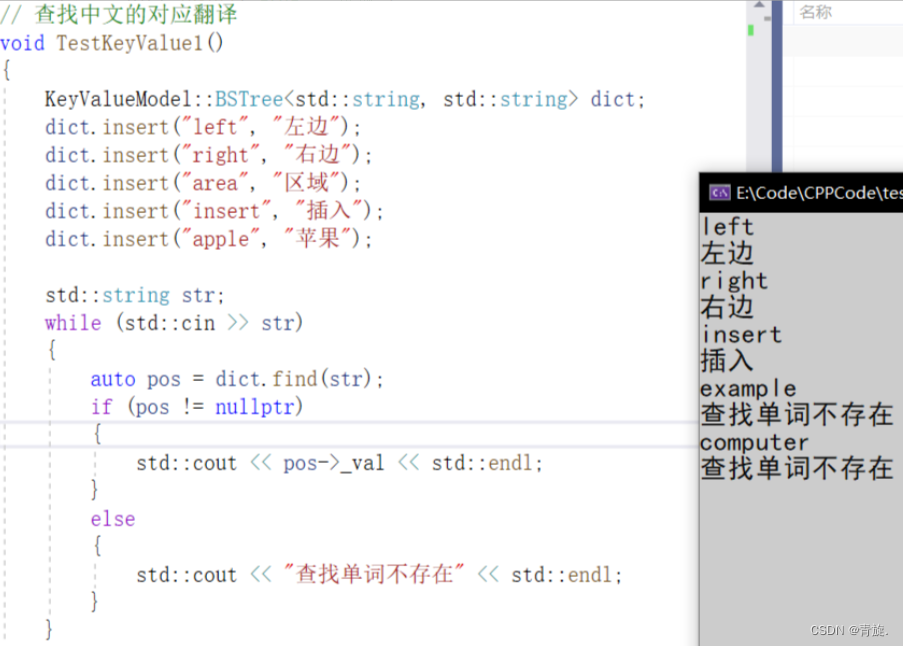
例如:我们想实现一个词典,如下代码所示:
// 查找中文的对应翻译
void TestKeyValue1()
{
KeyValueModel::BSTree<std::string, std::string> dict;
dict.insert("left", "左边");
dict.insert("right", "右边");
dict.insert("area", "区域");
dict.insert("insert", "插入");
dict.insert("apple", "苹果");
std::string str;
while (std::cin >> str)
{
auto pos = dict.find(str);
if (pos != nullptr)
{
std::cout << pos->_val << std::endl;
}
else
{
std::cout << "查找单词不存在" << std::endl;
}
}
}
我们想统计某样物品的个数;如下代码所示:
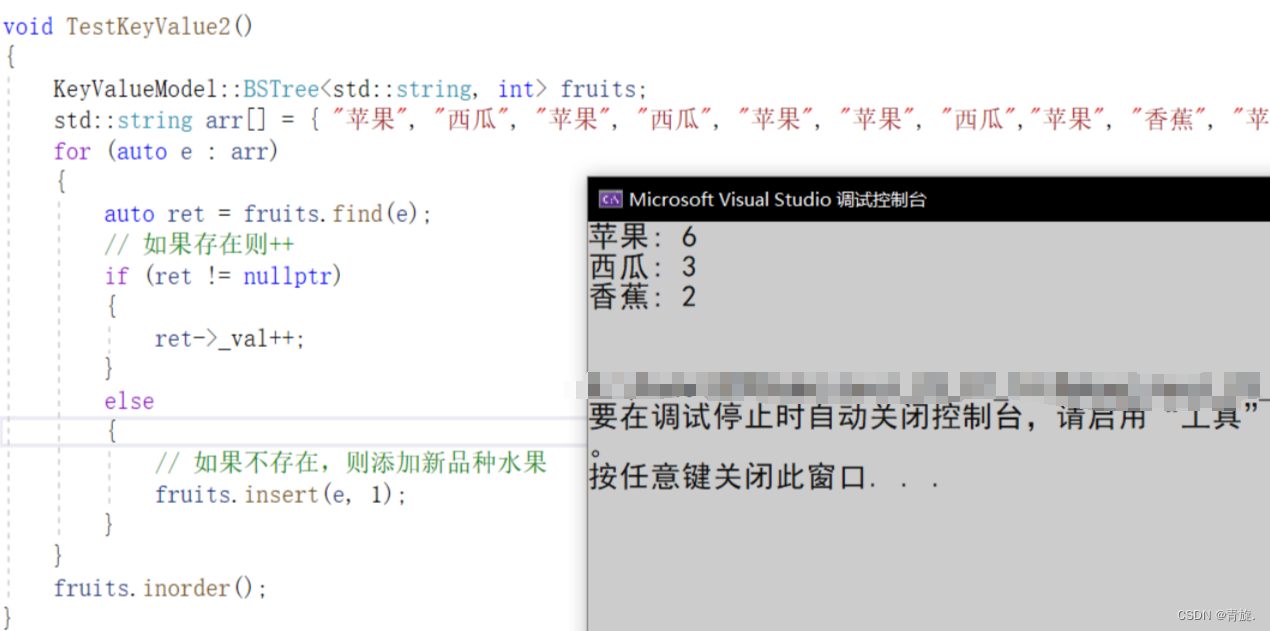
// 统计水果个数
void TestKeyValue2()
{
KeyValueModel::BSTree<std::string, int> fruits;
std::string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };
for (auto e : arr)
{
auto ret = fruits.find(e);
// 如果存在则++
if (ret != nullptr)
{
ret->_val++;
}
else
{
// 如果不存在,则添加新品种水果
fruits.insert(e, 1);
}
}
fruits.inorder();
}
二叉搜索树的性能分析
正常情况下,二叉搜索树想要查找一个值的时间复杂度为树的高度,为O(log N);而实际上,有一种极端场景不可避免,那就是歪脖子树,此时,查找效率由原来的O(log N)退化到O(N);极端场景如下图所示:
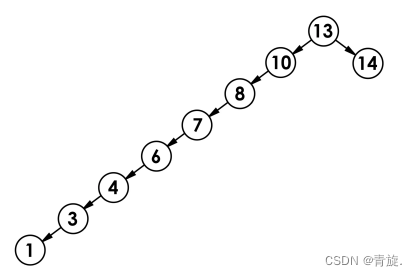
这其实也跟插入顺序有关,因为我们的插入顺序不同,二叉搜索树的形状也就不同,因此,为了解决这个问题,后面我们接着会学习AVL树与红黑树解决这个问题。