需求分析
安装requests包
pip install requests
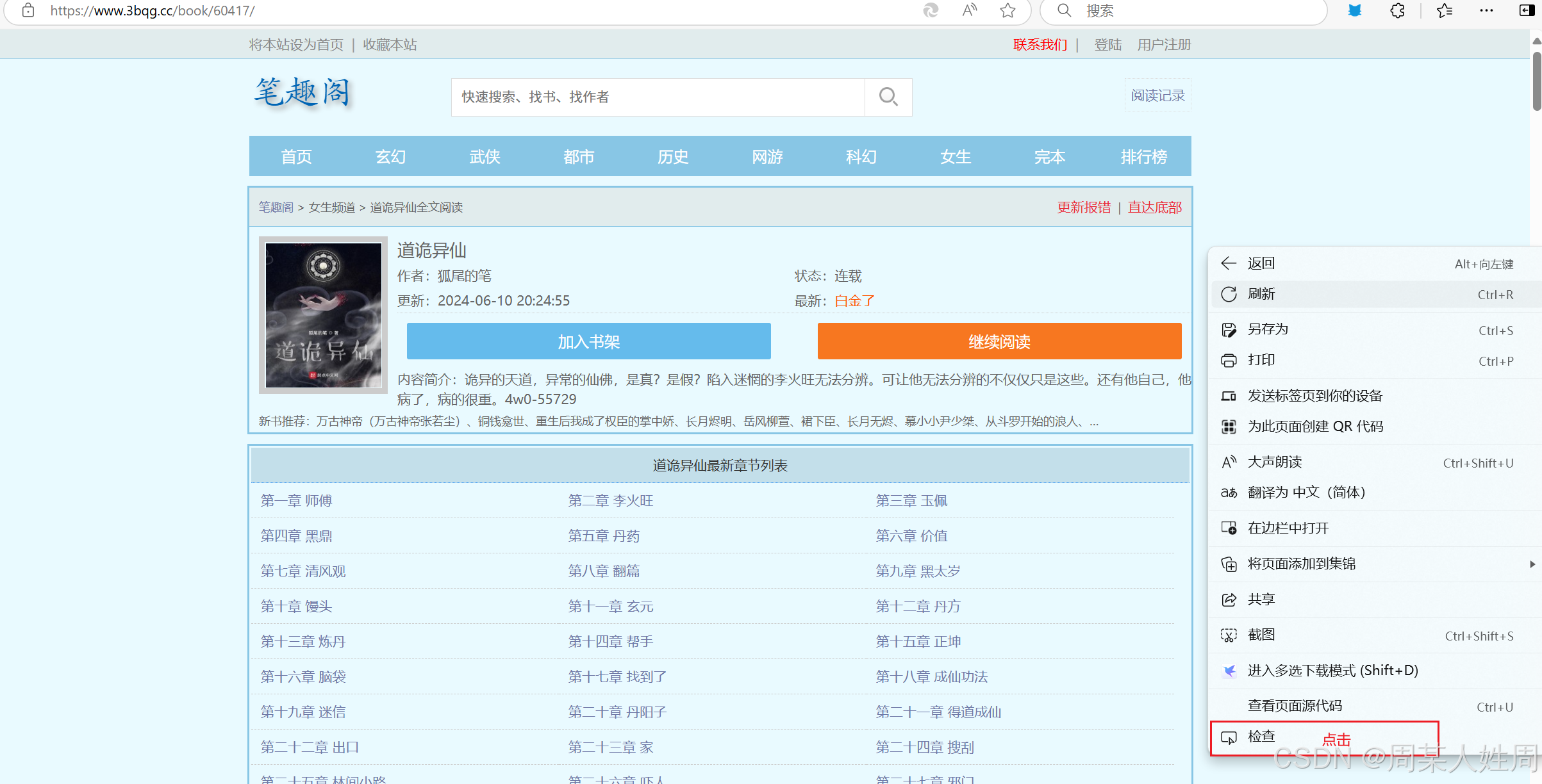

目录采集地址:
h
t
t
p
s
:
/
/
w
w
w
.
3
b
q
g
.
c
c
/
b
o
o
k
/
60417
/
https://www.3bqg.cc/book/60417/
https://www.3bqg.cc/book/60417/
章节采集地址:
h
t
t
p
s
:
/
/
w
w
w
.
3
b
q
g
.
c
c
/
b
o
o
k
/
60417
/
1.
h
t
m
l
https://www.3bqg.cc/book/60417/1.html
https://www.3bqg.cc/book/60417/1.html
pycharm代码实现
#导入requests模块和re模块
import requests,re
#要爬取的网址
url="https://www.3bqg.cc/book/60417"
#伪造请求
#声明一个身份代理信息,随便进入一个网页检查——网络——标头即可找到User-Agent
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"
}
#发起一个伪造请求
# requests.get(url1,headers=headers)
#接收服务器返回的数据
response=requests.get(url,headers=headers)
#设置响应编码
response.encoding="UTF-8"
#查看响应数据
content=response.text
#print(content)
#正则提取章节名称和链接
p=r'<a href ="(.*?)"\>(第.*?)>'
chs=re.findall(p,content,re.DOTALL)
#print(chs)
#提取出来后章节链接与章节名在一个列表中
注意
re.DOTALL:这是一个标志,告诉正则表达式模块 .(点)元字符应该匹配包括换行符在内的任意字符。通常情况下,. 不匹配换行符,但当你使用 re.DOTALL 标志时,它将匹配任何字符,包括换行符。如果不使用 re.DOTALL 标志, . 不匹配换行符,所以无法匹配整个多行字符串。
re.findall 是 Python 的 re(正则表达式)模块中的一个函数,它的作用是在一个字符串中查找所有与正则表达式匹配的部分,并将它们作为一个列表返回。
#声明一个字典
chapter=dict()
for ch in chs:
#以章节名做key,地址做value
chapter[ch[1]]="https://www.3bqg.cc"+ch[0]
#print(chapter)
#导入jasn模块
import json
with open('chapters.txt','wt',encoding='utf-8') as file:
#将 chapter 字典转换为 JSON 格式的字符串,并将其写入到 file 变量所引用的文件中
json.dump(chapter, file)
#加载需要的目录
with open('chapters.txt',encoding='utf-8') as file:
ac=json.load(file)
#print(ac)
#伪造请求
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"
}
import random,time
for title , url in ac.items():
with open("道诡异仙.txt",mode="at",encoding='utf-8') as file:
print(f"准备采集:{title}")
#发起伪造请求
res=requests.get(url,headers=headers)
#设置数据编码
res.encoding=("UTF-8")
#分析数据格式
consequence=res.text
# print(consequence)
#定义正则表达式,匹配数据
a=r'<div id="chaptercontent"+\s+class="Readarea+\s+ReadAjax_content">(.*?)</div>'
#打印获取的某一章的内容
#第一种fangfa
#content=re.findall(a,consequence,re.DOTALL)
#print(content)
#第二种方法
# 只有一条数据,可以用re.search
content=re.search(a,consequence,re.DOTALL)
#使用content.group()获取第一个捕获组的内容
content=content.group(1)
#print(content)
#提取出汉字的正则表达式=r'[\u4e00-\u9fff]+'
content2=re.findall(r'[\u4e00-\u9fff]+', content)
content2="\n".join(content2)
#print(content2)
#保存到文件
file.write("\n\n"+title+"\n\n")#标题
file.write(content2)#内容
time.sleep(random.randint(2,4))
print(f"{title}章节采集完成")
#测试,采集一次
#break
结果

