1. 前端(Frontend)
定义:
前端是用户直接与之交互的部分,通常在浏览器中运行。它负责呈现和展示数据,与用户进行交互。
关键点:
- HTML/CSS/JavaScript: HTML定义了页面结构,CSS负责样式和布局,JavaScript处理交互和动态内容。
- 前端框架和库: 如React.js、Angular、Vue.js等,简化了复杂应用的开发。
- 跨平台和响应式设计: 确保应用在各种设备和屏幕尺寸上都有良好的用户体验。
- 性能优化和安全性: 加载速度、缓存策略、安全防护(如跨站脚本攻击防护)。
如何在前端开发中实现高效的用户界面交互?
在前端开发中实现高效的用户界面交互,可以从以下几个方面入手:
代码优化:
- 代码压缩与合并:通过减小文件大小来提高加载速度和响应速度。
- 使用工具监测和测试应用程序的性能:利用工具如Google PageSpeed等,找出潜在的性能瓶颈和问题,并进行优化。
资源加载优化:
- 减少HTTP请求:通过合并资源文件、使用CDN等方式减少HTTP请求次数,从而加快页面加载速度。
- 使用缓存:通过设置缓存策略,减少重复加载资源的次数,提高页面响应速度。
网络请求优化:
- 异步加载:使用AJAX等技术异步加载数据,避免阻塞主渲染线程,提高页面的流畅度。
- 图片优化:对图片进行压缩和格式转换,减少图片大小,提高加载速度。
用户体验设计:
- 用户为中心的设计原则:始终将用户的需求和习惯放在首位,设计出符合用户期望的界面和交互方式。
- 动态响应和流畅体验:确保用户输入后能够快速得到反馈,避免长时间等待,提升用户的满意度和留存率。
实际案例分析和测试:
- 案例分析:通过分析成功案例,了解其优化策略和实施方法。
- 有效测试:使用各种工具和方法对前端性能进行测试,确保优化措施的有效性
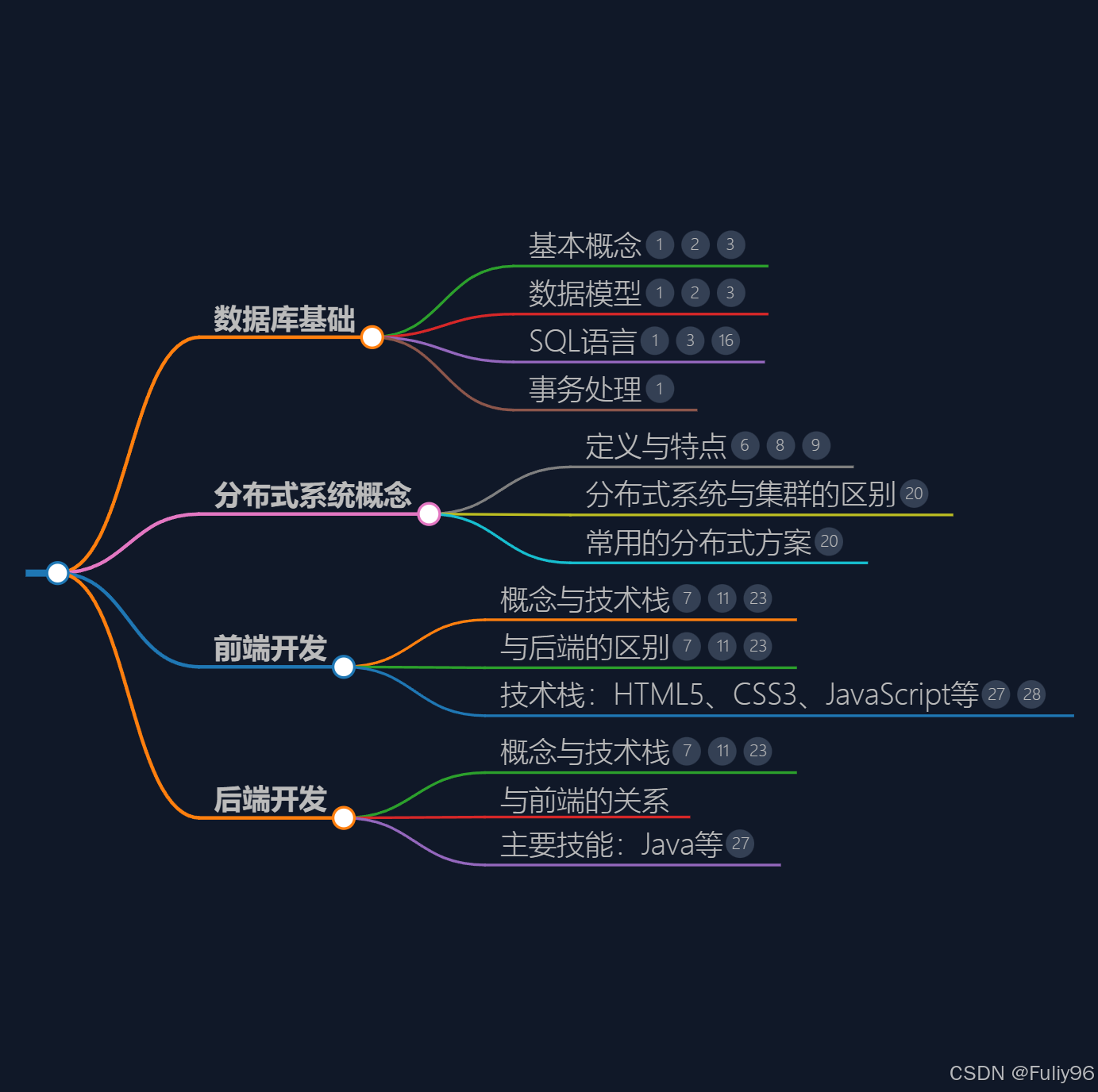
2. 后端(Backend)
定义:
后端是在服务器上运行的应用程序部分,负责处理前端不可见的逻辑和数据。
关键点:
- 后端语言和框架: 如Python(Django、Flask)、JavaScript(Node.js)、Java(Spring Boot)、PHP(Laravel)等。
- API设计和开发: 提供数据和服务的接口,常见的有RESTful API。
- 数据库交互: 与数据库进行交互,处理数据的持久化和检索。
- 安全性和验证: 用户身份验证、数据加密、防止SQL注入等安全措施。
- 性能优化和扩展性: 处理高并发、优化响应时间、水平和垂直扩展。
后端开发中常见的性能优化技巧有哪些?
在后端开发中,性能优化是一个至关重要的环节。以下是一些常见的性能优化技巧:
-
硬件升级:硬件问题对性能的影响不容忽视。例如,数据库集群的硬件配置需要根据实际需求进行升级和优化。
-
缓存策略:通过使用缓存可以显著提高应用响应速度。缓存机制能够减少对数据库的直接访问,从而降低延迟和提高效率。
-
数据库优化:
- 使用索引:避免全表扫描,优先考虑在
WHERE、ORDER BY和GROUP BY涉及的列上建立索引。 - 优化SQL语句:使用工具如
EXPLAIN分析SQL执行效果,选择合适的索引并优化查询语句。 - 合理设计查询语句:包括避免使用
SELECT*、使用JOIN代替子查询、优化WHERE子句等。
- 使用索引:避免全表扫描,优先考虑在
-
并发控制:通过合理的线程管理和锁机制来控制并发访问,避免资源争抢导致的性能瓶颈。
-
网络优化:优化HTTP接口和调用链路,减少数据传输量和延迟,例如压缩数据、使用长连接等技术手段。
-
服务化与异步化:将复杂的业务逻辑拆分成多个小服务,并采用异步处理方式,以提高系统的响应速度和可扩展性。
-
JVM优化:对于Java后端开发,可以通过调整JVM参数、使用垃圾回收器优化等方式来提升性能。
-
分布式系统和云计算:利用分布式系统和云计算资源,可以有效分散负载,提高系统的容错能力和扩展性。
-
代码优化:包括编写高效的算法和数据结构、减少不必要的计算和内存占用等。
-
负载均衡:通过智能的负载均衡技术,将用户请求均匀分配到多个服务器上,从而提高系统的整体性能和可靠性。
3. 数据库(Database)
定义:
数据库是结构化数据的集合,用于有效地存储、管理和检索信息。
关键点:
- 关系型数据库(SQL)和非关系型数据库(NoSQL): 如MySQL、PostgreSQL、MongoDB、Redis等。
- 数据建模和优化: 设计数据库结构、表关系、索引等,以提高查询效率。
- 事务和一致性: ACID(原子性、一致性、隔离性、持久性)属性的理解和实现。
- 备份和恢复: 数据的定期备份和紧急情况下的数据恢复策略。
- 分片和复制: 处理大规模数据和高可用性的技术手段。
数据库设计中的最佳实践是什么?
数据库设计中的最佳实践包括以下几个方面:
-
将所有人的观点列入考量:在设计数据库之前,必须考虑所有相关利益者的观点。通过收集信息和了解他们的期望以及操作熟练度,可以得出数据库应当采用的技术水平。
-
选择符合需求的数据库类型:根据应用的具体需求,选择合适的数据库类型(如关系型、非关系型等),以确保数据库能够高效地支持应用的运行。
-
规范化:遵循数据规范化的原则,减少数据冗余,提高数据的一致性和完整性。这通常包括使用第三范式来规范表结构。
-
文档化:详细记录数据库的设计和实现过程,包括表结构、字段定义、约束条件等,以便于维护和扩展。
-
重视隐私保护:在设计数据库时,要特别注意数据的隐私保护,确保敏感信息不被泄露。
-
考虑长期需求:在设计数据库时,要考虑到未来的扩展和变化需求,避免因设计不当而导致的频繁修改。
-
使用预存程序:利用预存程序(存储过程)来封装复杂的业务逻辑,可以提高执行效率和代码的可维护性。
-
投入时间进行建模和设计:在数据库建模和设计上投入足够的时间,进行充分的分析和规划,以确保设计的合理性和高效性。
-
测试设计:在设计完成后,进行全面的测试,确保数据库能够满足预期的功能和性能要求。
-
设计适当的索引:合理设计索引以提高查询性能,避免不必要的全表扫描。
4. 分布式系统(Distributed Systems)
定义:
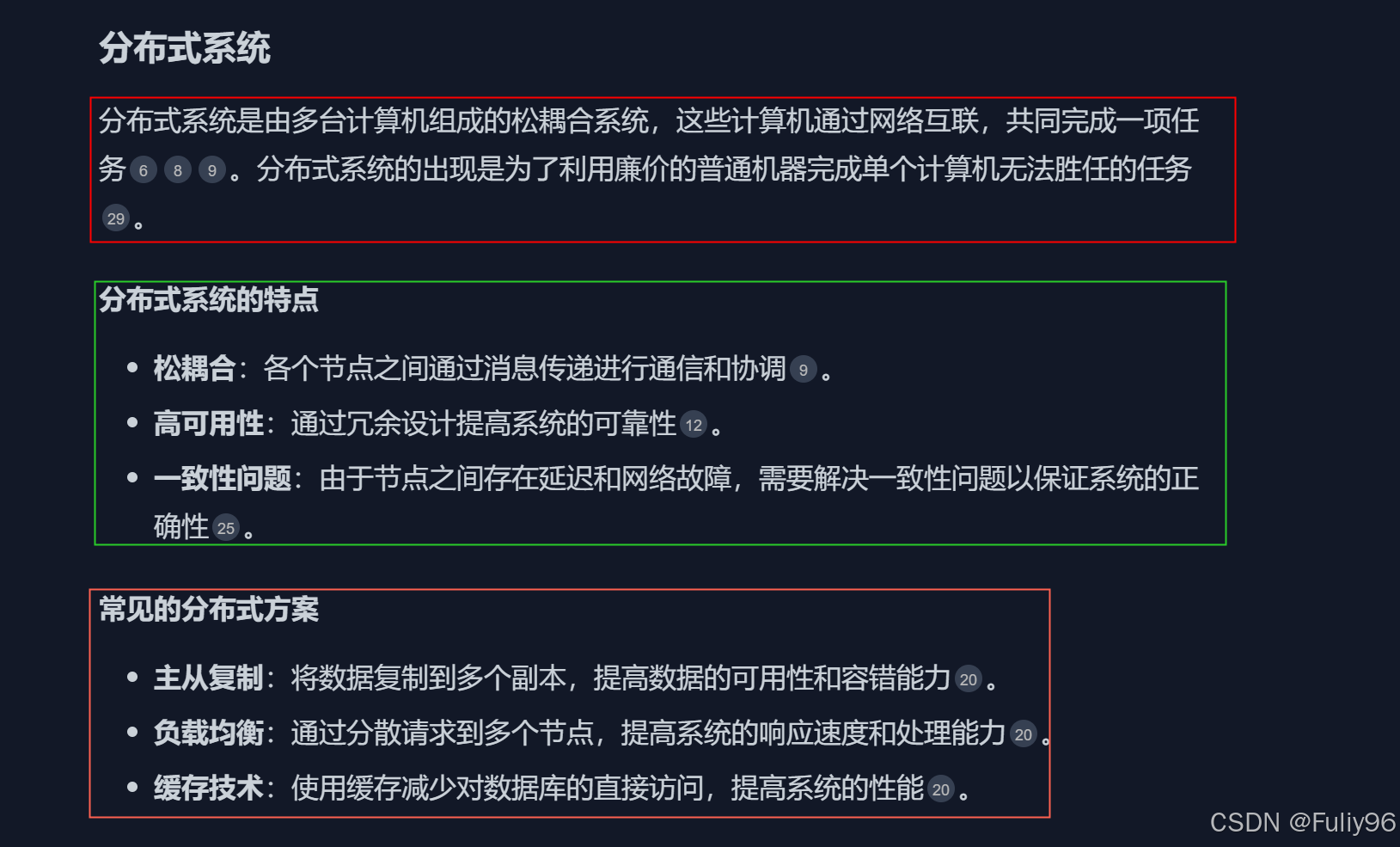
分布式系统是由多个自治计算机通过网络连接组成的系统,共同完成一个任务。
关键点:
- 分布式计算和通信: 节点之间的通信协议、数据同步和一致性保证。
- 负载均衡和故障恢复: 将工作负载分配给多个节点,以提高系统的吞吐量和可用性。
- 分布式存储和数据库: 如分布式文件系统(HDFS)、分布式数据库(Spanner、Cassandra)等。
- CAP定理和BASE理论: CAP理论强调分布式系统中一致性、可用性和分区容错性的权衡,BASE理论则强调基于可用性、柔性状态和最终一致性的系统设计。
分布式系统中的一致性问题如何解决?
在分布式系统中,一致性问题的解决是一个复杂且关键的问题。为了确保各个节点之间的数据保持一致,通常需要采用以下几种方法和技术:
-
一致性协议:一致性协议是实现数据一致性的基础。常见的一致性协议包括Paxos、Raft和ZooKeeper的Zab算法等。这些协议通过在多个节点之间进行协调和通信,确保所有节点在任何时候都拥有相同的数据状态。
-
数据复制和副本:通过在多个节点上复制数据,可以提高系统的可靠性和容错能力。当一个节点发生故障时,其他节点可以提供数据的冗余备份,从而保证系统的连续运行。
-
基于时间戳的方法和向量时钟:这些方法通过记录和比较操作的时间顺序来确保数据的一致性。时间戳和向量时钟可以帮助节点确定数据的更新顺序,从而避免冲突和不一致的情况。
-
CAP理论:CAP定理指出,在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)三个要素最多只能同时实现两点。因此,设计时需要根据具体需求权衡这三者之间的关系。
-
强一致性和弱一致性:强一致性要求每个节点在任何时刻都必须看到最新的数据变化,而弱一致性则允许一定范围内的延迟和不确定性。选择合适的一致性级别可以根据实际应用场景的需求来决定。
-
领导者选举与超时机制:在一些分布式一致性算法中,会通过领导者选举机制来管理节点间的协调和通信。领导者负责处理请求并将其分发给其他节点,同时使用超时机制来处理节点间的通信延迟和故障。
5.总结
- 前端关注于用户界面和交互,使用HTML/CSS/JavaScript等构建。
- 后端处理应用逻辑和数据,使用各种编程语言和框架与数据库交互。
- 数据库负责数据的存储和管理,支持高效的数据检索和操作。
- 分布式系统通过多节点协作完成任务,提高系统的性能、可用性和扩展性。