一、前言
随着互联网的普及,数据已成为当今信息社会中最为重要的资源之一。在海量的数据中,如何有效地获取、处理并加以应用,已成为一个热门且重要的研究方向。网络爬虫技术正是在这一背景下应运而生,它通过模拟浏览器访问网页,抓取网站内容,实现自动化的数据收集。在众多网站中,豆瓣作为中国最大的电影、书籍及音乐评论网站,其丰富的资源和海量的数据吸引了许多数据分析者和爬虫爱好者的关注。
本文将介绍一个基于Python语言的简单豆瓣电影Top 250爬虫的实现过程,主要通过使用 requests 库进行网页请求,使用 BeautifulSoup 库进行网页解析,并将结果保存为 CSV 格式供后续分析使用。本文不仅将涉及具体的代码实现,还将详细分析实现过程中所涉及的爬虫原理、数据提取方法和解析步骤,同时结合算法优化的实践探讨,帮助读者更好地理解这一过程。
二、技术与原理简介
1. 网络爬虫原理
网络爬虫,又称网络蜘蛛或网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。其基本工作流程如下:
- 发起请求 (Request):爬虫模拟浏览器,向目标网站服务器发送 HTTP 请求,请求获取网页内容。
- 获取响应 (Response):服务器接收到请求后,返回包含网页内容的 HTTP 响应。
- 解析内容 (Parsing):爬虫解析 HTTP 响应中的 HTML 代码,提取所需的数据。
- 存储数据 (Storage):爬虫将提取的数据存储到本地文件、数据库或其他存储介质中。
- 循环抓取 (Iteration):爬虫根据一定的规则,循环抓取其他网页,直到满足预设的条件。
1.1 HTTP 协议
HTTP (Hypertext Transfer Protocol) 超文本传输协议是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。HTTP 协议定义了客户端和服务器之间信息交互的格式和规则。
- 请求方法 (Request Methods):常用的请求方法包括 GET、POST、PUT、DELETE 等。GET 方法用于请求获取资源,POST 方法用于提交数据。
- 请求头 (Request Headers):请求头包含客户端向服务器发送的附加信息,例如 User-Agent (用户代理)、Accept-Language (接受的语言)、Referer (引用页面) 等。
- 响应状态码 (Response Status Codes):响应状态码表示服务器对请求的处理结果。常见的状态码包括 200 (成功)、404 (未找到)、500 (服务器错误) 等。
- 响应头 (Response Headers):响应头包含服务器向客户端发送的附加信息,例如 Content-Type (内容类型)、Content-Length (内容长度) 等。
- 响应体 (Response Body):响应体包含服务器返回的实际内容,例如 HTML 代码、JSON 数据等。
1.2 HTML 结构
HTML (Hypertext Markup Language) 超文本标记语言是用于创建网页的标准标记语言。HTML 文档由一系列的元素组成,每个元素由开始标签、结束标签和内容组成。
- 标签 (Tags):标签用于定义 HTML 元素的类型和属性。例如,
<h1>标签用于定义标题,<p>标签用于定义段落。 - 属性 (Attributes):属性用于为 HTML 元素提供附加信息。例如,
<img src="image.jpg">标签中的src属性指定了图片的 URL。 - DOM 树 (Document Object Model):DOM 树是 HTML 文档的树形结构表示。每个 HTML 元素都对应 DOM 树中的一个节点。
1.3 网页解析技术
网页解析是指从 HTML 代码中提取所需数据的过程。常用的网页解析技术包括:
- 正则表达式 (Regular Expressions):正则表达式是一种强大的文本匹配工具,可以用于从字符串中提取符合特定模式的文本。
- XPath:XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可以用于在 HTML 文档中定位元素和属性。
- Beautiful Soup:Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。Beautiful Soup 提供了一种简单而灵活的方式来遍历 DOM 树,查找元素和属性。
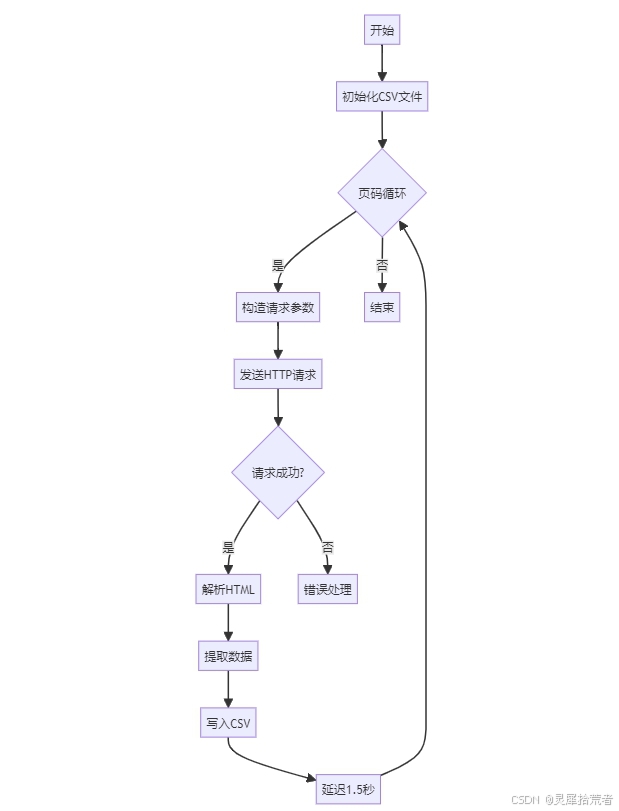
2. 算法步骤
本爬虫的目标是抓取豆瓣电影 Top 250 榜单中的电影名称、评分和评价人数。算法步骤如下:
- 定义目标 URL:确定豆瓣电影 Top 250 榜单的 URL。
- 发送 HTTP 请求:使用
requests库向目标 URL 发送 HTTP GET 请求。 - 获取 HTTP 响应:接收服务器返回的 HTTP 响应。
- 解析 HTML 代码:使用
Beautiful Soup库解析 HTTP 响应中的 HTML 代码。 - 提取数据:从解析后的 HTML 代码中提取电影名称、评分和评价人数。
- 存储数据:将提取的数据存储到 CSV 文件中。
- 循环抓取:循环抓取豆瓣电影 Top 250 榜单的所有页面。
- 控制抓取频率:使用
time.sleep()函数控制抓取频率,避免对服务器造成过大的压力。
三、代码详解
本文的代码主要分为以下几个部分:
1. 导入库
import requests
from bs4 import BeautifulSoup
import csv
import time
说明:
requests:用于发送 HTTP 请求。BeautifulSoup:用于解析 HTML 代码。csv:用于读写 CSV 文件。time:用于控制抓取频率。
2. 定义常量
# 常量定义
BASE_URL = "https://movie.douban.com/top250"
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://www.douban.com/'
}
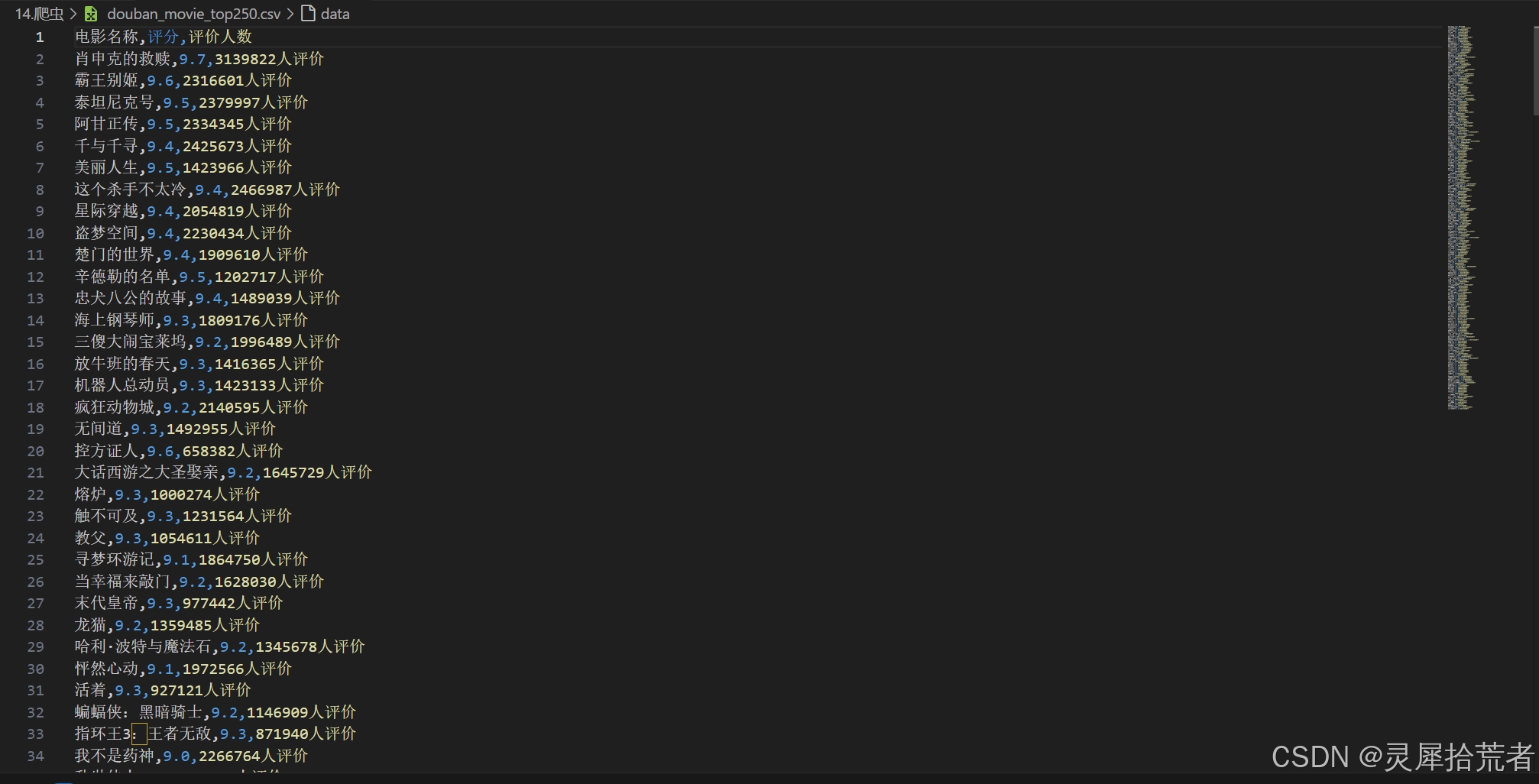
CSV_HEADER = ['电影名称', '评分', '评价人数']
说明:
BASE_URL:豆瓣电影 Top 250 榜单的 URL。HEADERS:HTTP 请求头,用于模拟浏览器。User-Agent:模拟浏览器的用户代理,防止被网站识别为爬虫。Accept-Language:指定接受的语言,确保返回中文页面。Referer:指定引用页面,有些网站会检查 Referer 来防止盗链。
CSV_HEADER:CSV 文件的表头。
3. get_page() 函数
def get_page(url, params=None):
"""带重试机制的请求函数"""
try:
response = requests.get(url, headers=HEADERS, params=params, timeout=10)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(f"请求失败: {url},错误: {e}")
return None
说明:
url:要请求的 URL。params:URL 参数。requests.get(url, headers=HEADERS, params=params, timeout=10):发送 HTTP GET 请求,并设置请求头、URL 参数和超时时间。response.raise_for_status():检查响应状态码,如果状态码不是 200,则抛出异常。response.text:返回 HTTP 响应的文本内容。try...except:捕获请求异常,如果请求失败,则打印错误信息并返回None。timeout=10:设置超时时间为 10 秒,防止程序长时间阻塞。
4. parse_html() 函数
def parse_html(html):
"""解析页面并返回结构化数据"""
soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find('ol', class_='grid_view').find_all('li')
data = []
for movie in movie_list:
try:
title = movie.find('span', class_='title').get_text(strip=True)
rating = movie.find('span', class_='rating_num').get_text(strip=True)
# 更精确匹配评价人数
comment = movie.find('span', string=lambda s: '人评价' in s).get_text(strip=True)
data.append([title, rating, comment])
except AttributeError as e:
print(f"解析失败: {e}")
continue
return data
说明:
html:HTML 代码。soup = BeautifulSoup(html, 'lxml'):使用BeautifulSoup库解析 HTML 代码,并指定解析器为lxml。movie_list = soup.find('ol', class_='grid_view').find_all('li'):查找所有包含电影信息的li标签。soup.find('ol', class_='grid_view'):查找class属性为grid_view的ol标签,该标签包含了所有电影列表。find_all('li'):查找ol标签下的所有li标签,每个li标签包含一个电影的信息。
for movie in movie_list::遍历所有电影。title = movie.find('span', class_='title').get_text(strip=True):提取电影名称。movie.find('span', class_='title'):查找class属性为title的span标签,该标签包含了电影名称。get_text(strip=True):获取标签的文本内容,并去除首尾空格。
rating = movie.find('span', class_='rating_num').get_text(strip=True):提取电影评分。movie.find('span', class_='rating_num'):查找class属性为rating_num的span标签,该标签包含了电影评分。get_text(strip=True):获取标签的文本内容,并去除首尾空格。
comment = movie.find('span', string=lambda s: '人评价' in s).get_text(strip=True):提取评价人数。movie.find('span', string=lambda s: '人评价' in s):查找包含 “人评价” 字符串的span标签,该标签包含了评价人数。get_text(strip=True):获取标签的文本内容,并去除首尾空格。
data.append([title, rating, comment]):将电影名称、评分和评价人数添加到数据列表中。try...except AttributeError as e::捕获AttributeError异常,如果解析失败,则打印错误信息并继续解析下一个电影。
5. save_data() 函数
def save_data(filename='douban_movie_top250.csv'):
"""使用上下文管理器安全保存数据"""
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(CSV_HEADER)
for page in range(10): # 250/25=10页
params = {'start': page*25, 'filter': ''}
html = get_page(BASE_URL, params=params)
if html:
page_data = parse_html(html)
writer.writerows(page_data)
print(f"已保存第{page+1}页数据")
time.sleep(1.5) # 降低请求频率
说明:
filename:CSV 文件的名称。with open(filename, 'w', newline='', encoding='utf-8-sig') as f::使用上下文管理器打开 CSV 文件,并指定写入模式、换行符和编码方式。'w':写入模式,如果文件已存在,则覆盖原有内容。newline='':防止在 Windows 系统中出现空行。encoding='utf-8-sig':指定编码方式为 UTF-8 with BOM,确保 CSV 文件可以被 Excel 正确打开。
writer = csv.writer(f):创建 CSV 写入器。writer.writerow(CSV_HEADER):写入 CSV 表头。for page in range(10)::循环抓取 10 页数据。params = {'start': page*25, 'filter': ''}:设置 URL 参数,start参数指定起始电影的索引,filter参数用于过滤电影。html = get_page(BASE_URL, params=params):获取 HTML 代码。if html::如果 HTML 代码不为空,则解析 HTML 代码并写入 CSV 文件。page_data = parse_html(html):解析 HTML 代码。writer.writerows(page_data):写入 CSV 数据。print(f"已保存第{page+1}页数据"):打印已保存的页数。time.sleep(1.5):暂停 1.5 秒,降低抓取频率。
5. 主函数
if __name__ == '__main__':
save_data()
说明:
if __name__ == '__main__'::当 Python 脚本被直接执行时,该代码块会被执行。save_data():调用save_data()函数,开始抓取数据并保存到 CSV 文件中。
6. 完整代码
import requests
from bs4 import BeautifulSoup
import csv
import time
# 常量定义
BASE_URL = "https://movie.douban.com/top250"
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://www.douban.com/'
}
CSV_HEADER = ['电影名称', '评分', '评价人数']
def get_page(url, params=None):
"""带重试机制的请求函数"""
try:
response = requests.get(url, headers=HEADERS, params=params, timeout=10)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(f"请求失败: {url},错误: {e}")
return None
def parse_html(html):
"""解析页面并返回结构化数据"""
soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find('ol', class_='grid_view').find_all('li')
data = []
for movie in movie_list:
try:
title = movie.find('span', class_='title').get_text(strip=True)
rating = movie.find('span', class_='rating_num').get_text(strip=True)
# 更精确匹配评价人数
comment = movie.find('span', string=lambda s: '人评价' in s).get_text(strip=True)
data.append([title, rating, comment])
except AttributeError as e:
print(f"解析失败: {e}")
continue
return data
def save_data(filename='douban_movie_top250.csv'):
"""使用上下文管理器安全保存数据"""
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(CSV_HEADER)
for page in range(10): # 250/25=10页
params = {'start': page*25, 'filter': ''}
html = get_page(BASE_URL, params=params)
if html:
page_data = parse_html(html)
writer.writerows(page_data)
print(f"已保存第{page+1}页数据")
time.sleep(1.5) # 降低请求频率
if __name__ == '__main__':
save_data()
四、总结与思考
本文以豆瓣电影 Top 250 榜单为例,详细介绍了网络爬虫的原理、实现方法以及优化策略。通过对爬虫代码的逐行解析,读者可以深入理解爬虫的工作机制,掌握爬虫的编写技巧。
4.1 优化策略
- 使用代理 IP:为了防止 IP 地址被网站封禁,可以使用代理 IP 来隐藏真实的 IP 地址。
- 使用多线程或异步 IO:为了提高抓取效率,可以使用多线程或异步 IO 来并发抓取多个页面。
- 使用缓存:为了减少对服务器的压力,可以使用缓存来存储已经抓取过的页面。
- 使用分布式爬虫:为了抓取大规模数据,可以使用分布式爬虫来将抓取任务分配到多台机器上。
- 遵守 Robots 协议:遵守网站的 Robots 协议,避免抓取不允许抓取的页面。
4.2 伦理思考
在进行网络爬虫时,需要遵守以下伦理规范:
- 尊重网站的知识产权:不要抓取受版权保护的内容。
- 避免对服务器造成过大的压力:控制抓取频率,避免对服务器造成拒绝服务攻击。
- 保护用户隐私:不要抓取用户的个人信息。
- 遵守法律法规:遵守国家和地区的法律法规。
【作者声明】
本文所述技术方法仅供学习交流之用,禁止用于任何商业或非法用途。文章中的观点仅代表个人见解,供读者参考交流。若有任何问题或建议,欢迎在评论区留言讨论,共同促进技术进步。