项目背景
在大数据时代,企业对数据的需求日益增长。如何高效地管理和分析海量数据,成为企业提升竞争力的重要手段。八维数据平台应运而生,旨在为企业提供一套全面的数据管理和分析解决方案,通过集成多种数据源管理、接口配置、项目和任务管理、规则与流程控制、用户权限管理以及数据分析和服务监测功能,帮助企业实现数据驱动的决策支持和业务流程自动化。
项目概述
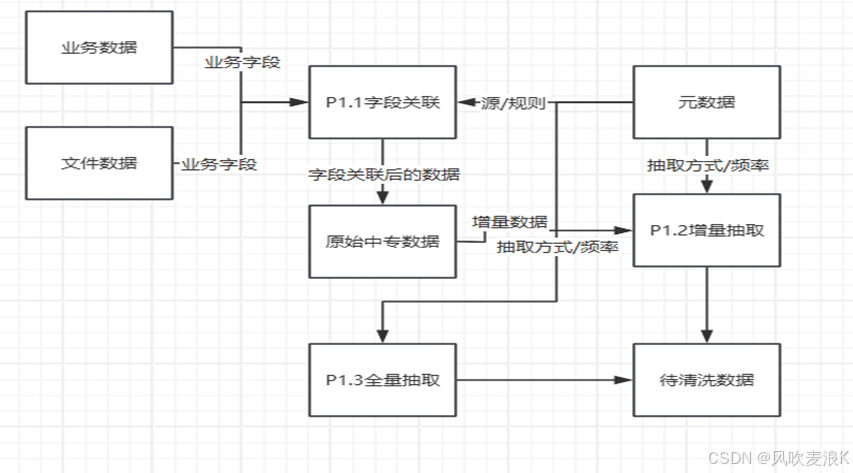
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程。
流程图
项目难点
一、各种数据源的集成
第一块就是各类数据源的一个集成,语言有很多,sql、sqlserver、 oracle、FTP、卡夫卡、es等,或者甚至文件接口,都可能做我们的源端,第一个点是我们如何去整合这种各类型的异构的数据源。
二、如何保证数据的一致性
然后其次的话难点二就是我们如何提升我们的同步性能以及保证数据的一致性。比如说源端有1,000万的人口信息同步到我们的库里边只有800万了,我们需要做好一个对标功能,告诉客户为什么只有800万,另外200万去哪了,比如说有50万是质量不达标的,我给扔了,然后有50万我是发送失败从事的,我也保存起来了等等的,现在数据对标这是一个大难点。整个中台的话,其实底层的核心就是任务调度以及各类gdbc的一个执行。
数据清洗主要流程
作用
通过分析“脏数据”的产生原因和存在形式,利用现有的技术手段和方法去清洗“脏数据”,将原有的不符合要求的数据转化为满足数据质量或应用要求的数据,从而提高数据集的数据质量。
清洗的对象
A. 不完整的数据,其特征是是一些应该有的信息缺失,如供应商的名称,分公司的名称,客户的区域信息缺失、业务系统中主表与明细表不能匹配等。需要将这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
解决措施
根据缺失的内容,将不同类型的缺失数据分别写入不同的Excel文件中。每个文件应标明缺失的内容类别,并准备好模板提醒客户填补缺失信息。
定期检查补全后的数据,确保完整后再将数据写入数据仓库,以保证数据质量。
B. 错误的数据,产生原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不面见字符的问题只能写SQL的方式找出来,然后要求客户在业务系统修正之后抽取;日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
解决措施
使用SQL查询或脚本检查数据库中的错误数据,比如全角字符、不可见字符、日期格式错误、日期越界等。
将检测到的错误数据分为不同的类别:可自动修正的(如全角字符、不可见字符)、需要业务系统修正的(如日期格式错误、日期越界)
C. 重复的数据,特别是维表中比较常见,将重复的数据的记录所有字段导出来,让客户确认并整理。
解决措施
编写SQL查询或脚本从维表或其他数据表中识别重复的记录,包括所有字段。
将识别到的重复数据导出,并提交给客户确认和整理。确保客户确认后的数据是最新和准确的版本
清洗制定了一些规则,制定的思想是什么?
- 数据质量的保证 规则的制定旨在保证数据的质量,确保数据准确、完整、一致和可靠。这些规则可以帮助识别和纠正数据中的错误、重复、缺失或不一致的部分,提高数据的可信度和可用性
- 数据一致性和标准化 制定规则有助于确保数据在不同数据源和不同系统中的一致性和标准化。通过规范化数据格式、命名规范、数据值的范围和格式等,提升数据的统一性和可比性
- 提高数据处理效率 规则的制定有助于优化ETL过程中的数据处理步骤,减少人工干预和错误率,提高数据处理的效率和自动化程度
数据脱敏
在项目中选择使用了Groovy脚本来处理数据脱敏。
具体实现流程
创建一个方法来实现数据脱敏的逻辑,例如将敏感数据替换为特定字符或进行其他处理。
将需要脱敏的数据传递给这个方法,并获取返回的脱敏后的数据。
将脱敏后的数据用于需要保护敏感信息的场景,如日志输出、展示等
为什么使用Groovy
易于集成:
Groovy可以无缝集成到Java应用程序中,利用现有的Java库和框架,使得与Java生态系统中的其他组件(如数据库访问、文件操作等)集成非常方便。
动态性和灵活性:
Groovy是一种动态语言,允许在运行时修改和扩展代码,这在处理不同格式和结构的数据时非常有用。它还支持运行时类型转换,可以根据需要更改变量类型,简化复杂数据处理逻辑。
转换主要体现在哪些方面
- 空值处理:可捕获字段空值,进行加载或替换为其他含义数据,并可根据字段空值实现分流加载到不同目标库。
- 规范化数据格式:可实现字段格式约束定义,对于数据源中时间、数值、字符等数据,可自定义加载格式。
- 拆分数据:依据业务需求对字段可进行分解。例,主叫号 861082585313-8148,可进行区域码和电话号码分解。
- 验证数据正确性:可利用Lookup及拆分功能进行数据验证。例如,主叫号861082585313-8148,进行区域码和电话号码分解后,可利用Lookup返回主叫网关或交换机记载的主叫地区,进行数据验证。
- 数据替换:对于因业务因素,可实现无效数据、缺失数据的替换。
- Lookup:查获丢失数据 Lookup实现子查询,并返回用其他手段获取的缺失字段,保证字段完整性。
- 建立ETL过程的主外键约束:对无依赖性的非法数据,可替换或导出到错误数据文件中,保证主键唯一记录的加载。
数据加载
在数据加载到数据库的过程中,分为 全量加载 和 增量加载(主要)。
全量加载
全量加载从技术角度上说,比增量加载要简单很多。一般只要在数据加载之前,清空目标表,再全量导入源表数据即可。但是由于数据量,系统资源和数据的实时性的要求,很多情况下我们都需要使用增量加载机制
增量加载(4种方式)
- 系统日志分析方式
该方式通过分析数据库自身的日志来判断变化的数据。关系型数据库系统都会将所有的 DML 操作存储在日志文件中,以实现数据库的备份和还原功能。ETL 增量抽取进程通过对数据库的日志进行分析,提取对相关源表在特定时间后发生的 DML 操作信息,就可以得知自上次抽取时刻以来该表的数据变化情况,从而指导增量抽取动作
- 触发器方式
利用增量日志表进行增量加载(回答同上)
- 时间戳方式
实现原理是指增量抽取时,抽取进程通过比较系统时间或者源表上次抽取时的最大时间戳与抽取源表的时间戳字段的值来决定抽取哪些数据。这种方式需要在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值
- 全表比对方式
建立 MD5 临时表,计算 MD5 校验码,并将主键值和对应的 MD5 校验码 插入到临时表中。
如果在 MD5 校验码相同的情况下,说明数据内容没有变化,则跳过该记录
如果 MD5 校验码不同,则表示数据发生了变化,需要进行更新操作。
对于目标表中不存在但在源表中存在的记录,执行插入操作。
对于在源表中已不存在而目标表仍保留的记录(即目标表的主键值不在 MD5 临时表中),执行删除操作