简介: DB-GPT 是一个实验性的开源应用,它基于FastChat,并使用vicuna-13b作为基础模型, 模型与数据全部本地化部署, 绝对保障数据的隐私安全。 同时此GPT项目可以直接本地部署连接到私有数据库, 进行私有数据处理, 目前已支持SQL生成、SQL诊断、数据库知识问答、数据处理等一系列的工作。
背景
**项目地址:** [**https://github.com/csunny/DB-GPT**](https://github.com/csunny/DB-GPT)
DB-GPT从5月6号正式发布第一个可运行版本,到目前刚刚经过一周的时间,引起了大家的广泛关注。 但是因为DB-GPT是用的Vicuna-13B的模型作为Base Model,所以很多同学在部署过程中遇到了较大的困难。DB-GPT在消费级GPU即可完成部署, 具体部署的硬件说明如下:
GPU型号 | 显存大小 | 性能
-------|----------|------------------------------
TRX4090| 24G |可以流畅的进行对话推理,无卡顿
TRX3090| 24G |可以流畅进行对话推理,有卡顿感,但好与V100
V100 | 16G | 可以进行对话推理,有明显卡顿
在本文中,为了方便大家部署测试,所以我们基于阿里云写了个完整的部署教程,感兴趣的同学可以基于此教程进行部署实践,因为项目主要是实验性质,不建议生产环境直接使用。
环境准备
创建阿里云GPU实例
- 阿里云账号准备, 如果没有阿里云账号,首先需要在阿里云注册一个账号,并充值100元。充值可以在右上角账号中心进行操作。
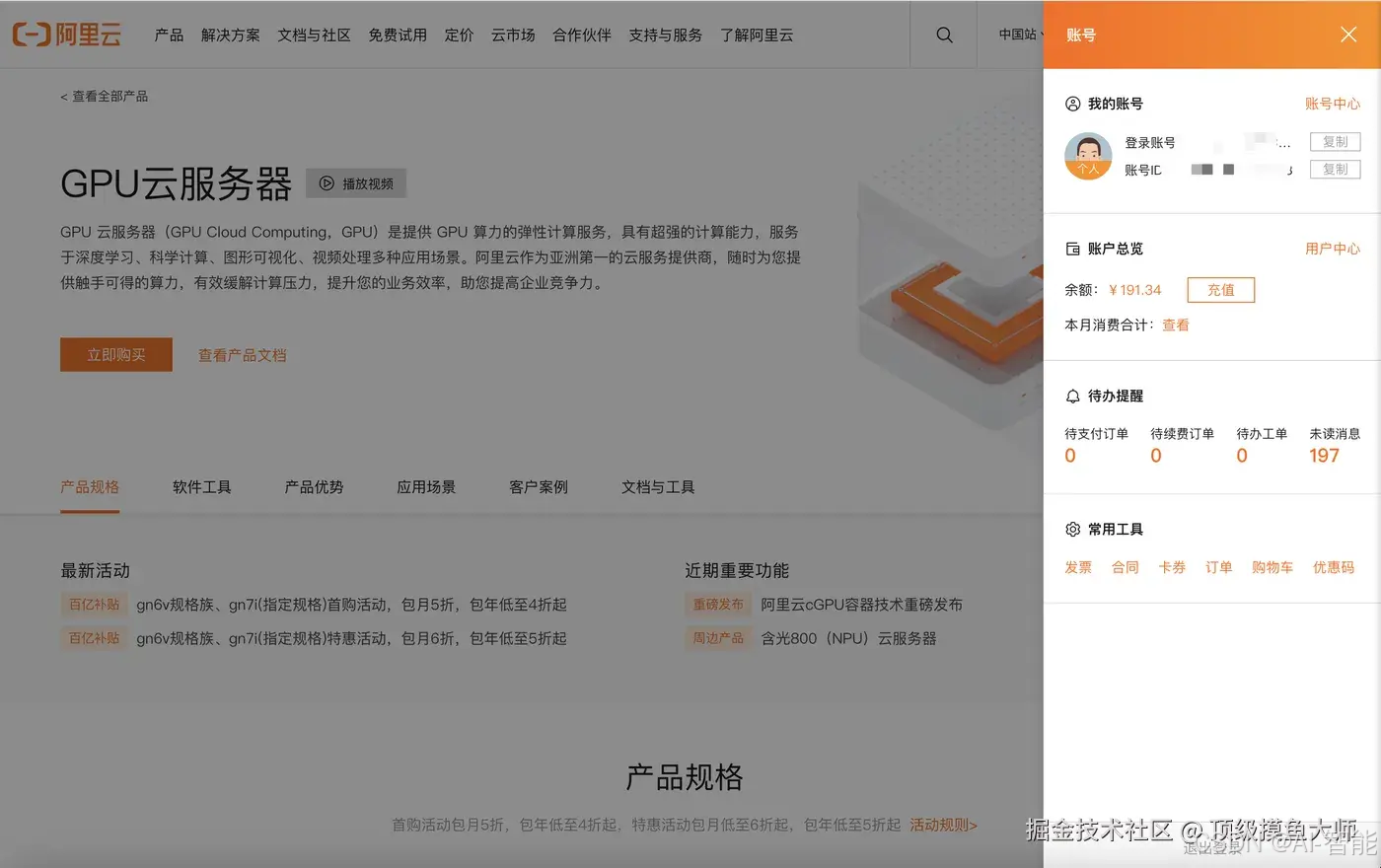
- 充值好之后,我们就可以去购买GPU服务器了。找到GPU云服务器产品,点击购买,进入到选配页面,在如下页面,选择按量付费,然后选择图中所示的型号即可。如果对推理性能有要求,可以选择更高的配置。
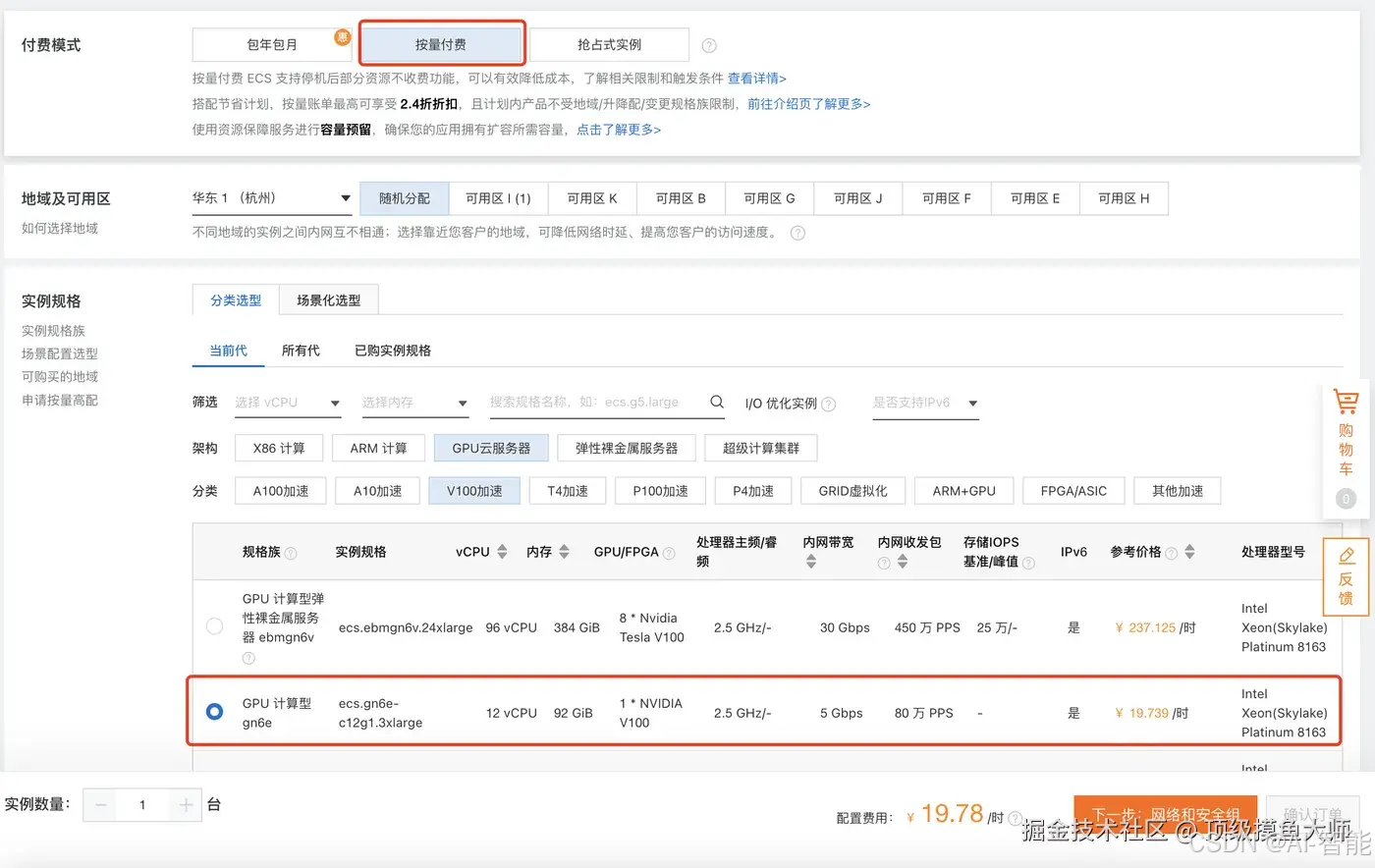
选择型号之后,还需要选择系统、GPU驱动、SSD存储、以及实例释放策略等选项。这里需要注意,云盘的规格不要选择太小,建议不小于200G, 同时去掉随实例释放的选项,这样后续我们可以只释放实例,模型数据可以保留。如果此实例,你想长期使用,建议做个快照备份。当然,考虑到价格原因,也可以挂一块NFS来存储数据。
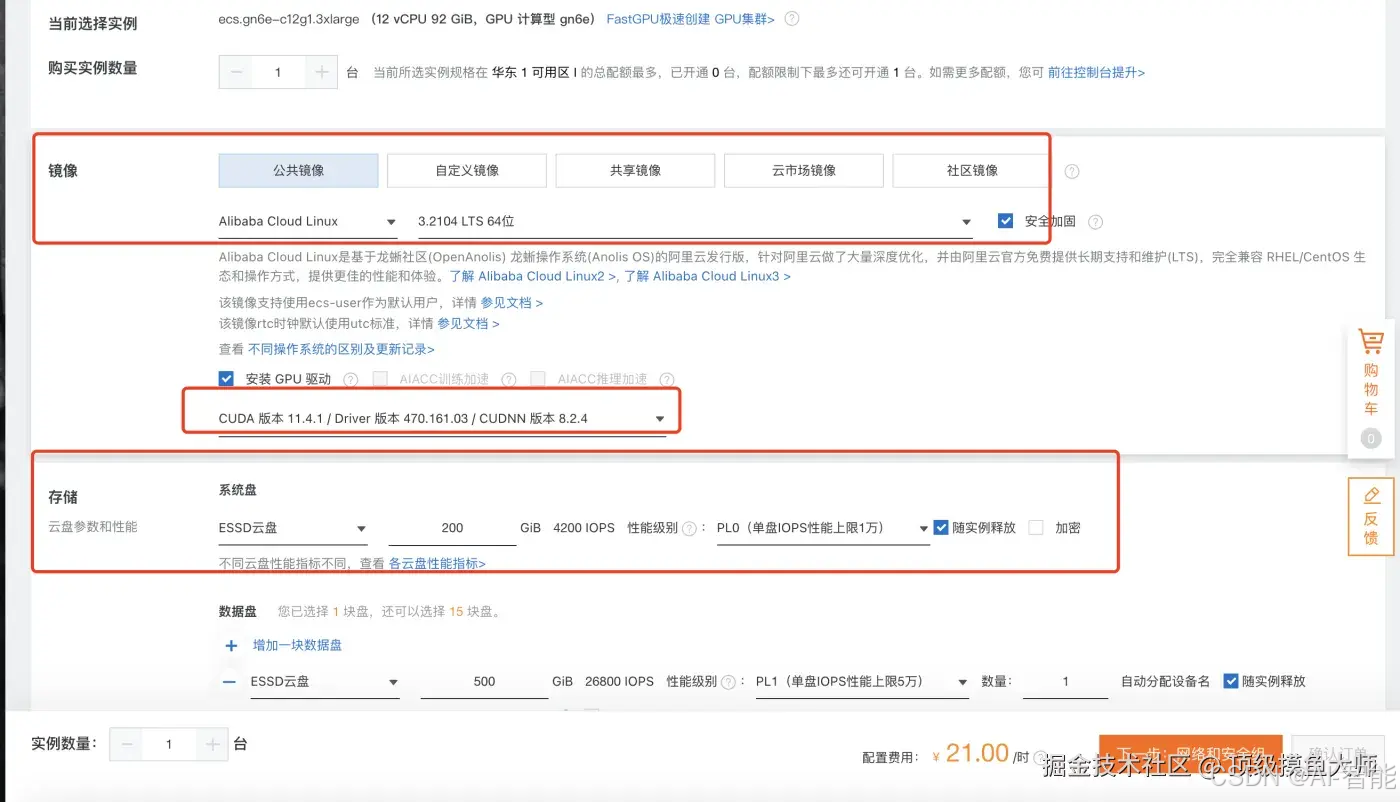
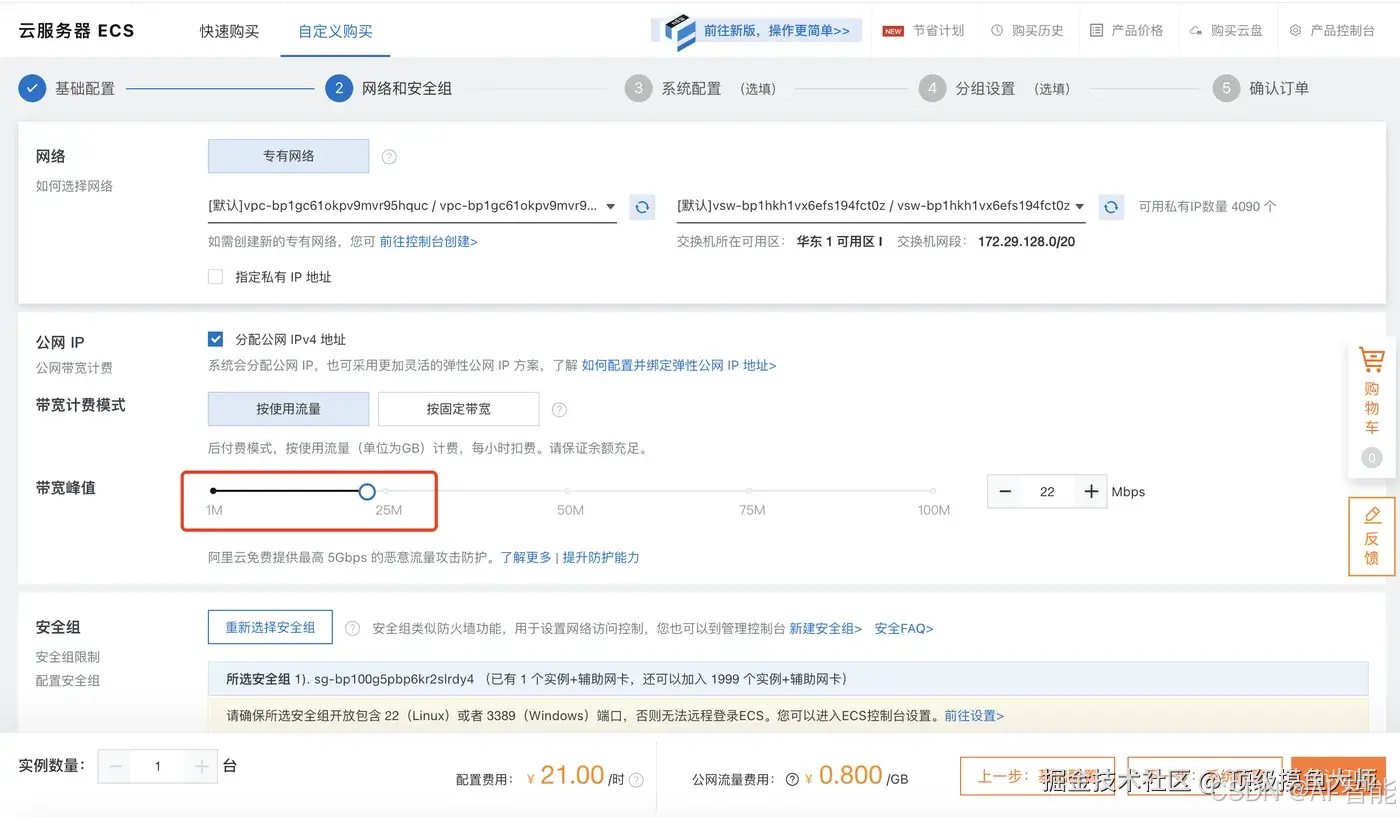
选择完以上步骤之后,点击下一步进入到网络与安全组配置界面,这里注意的是网络带宽我们可以选择大一点。这里我选择的是25M的网络。注意我们要选择按流量付费, 同时需要去买个流量包。
选择好之后,进入下一步, 系统配置界面,注意要选择一下自定义密码,需要设置一下root密码,如果这一步未设置,等机器启动之后设置也可。
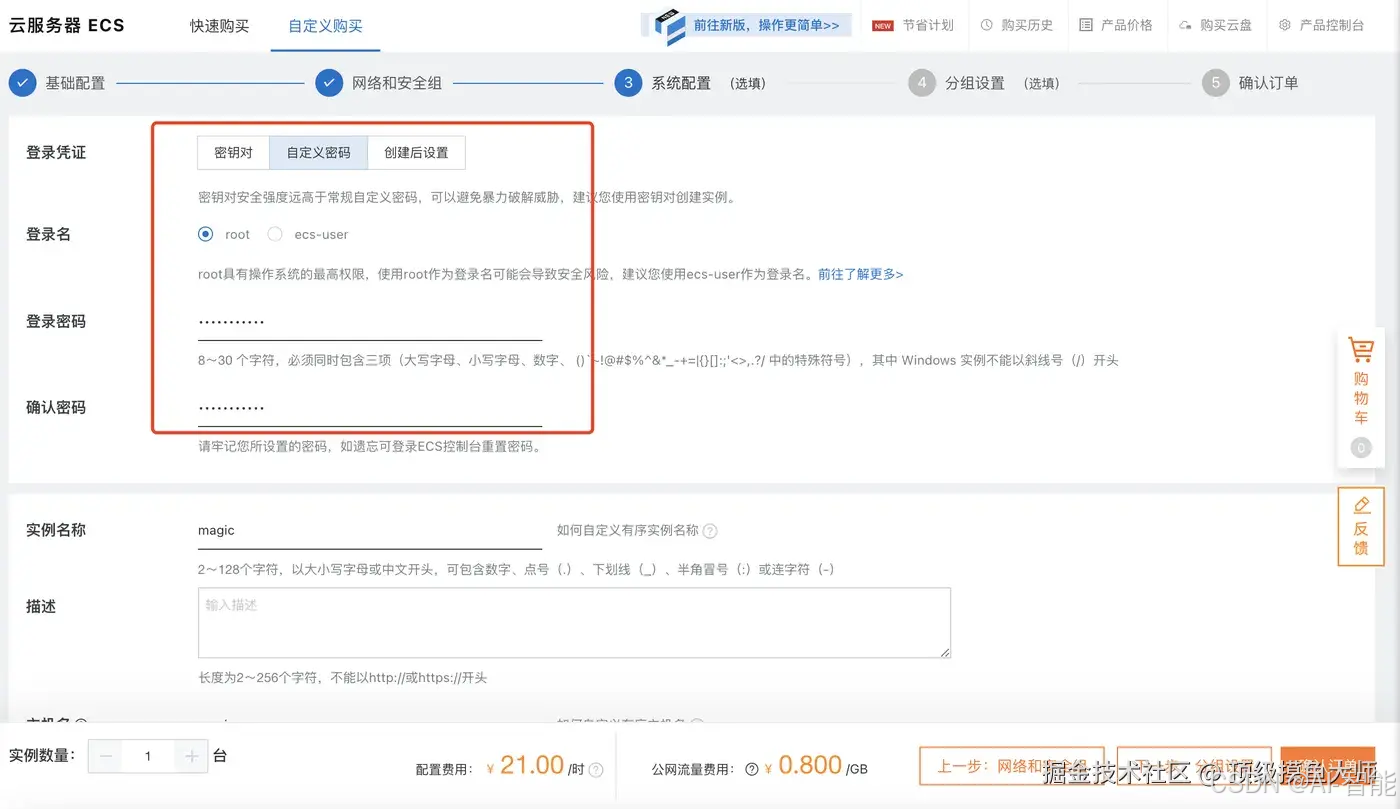
这一步结束之后,分组设置无需特殊设置,直接进入下一步即可。 最后在确认订单界面,我们需要重点设置一下自动释放时间,防止后续忘记释放造成持续的费用。选择好之后,直接点击创建实例,开实例阶段就结束了。
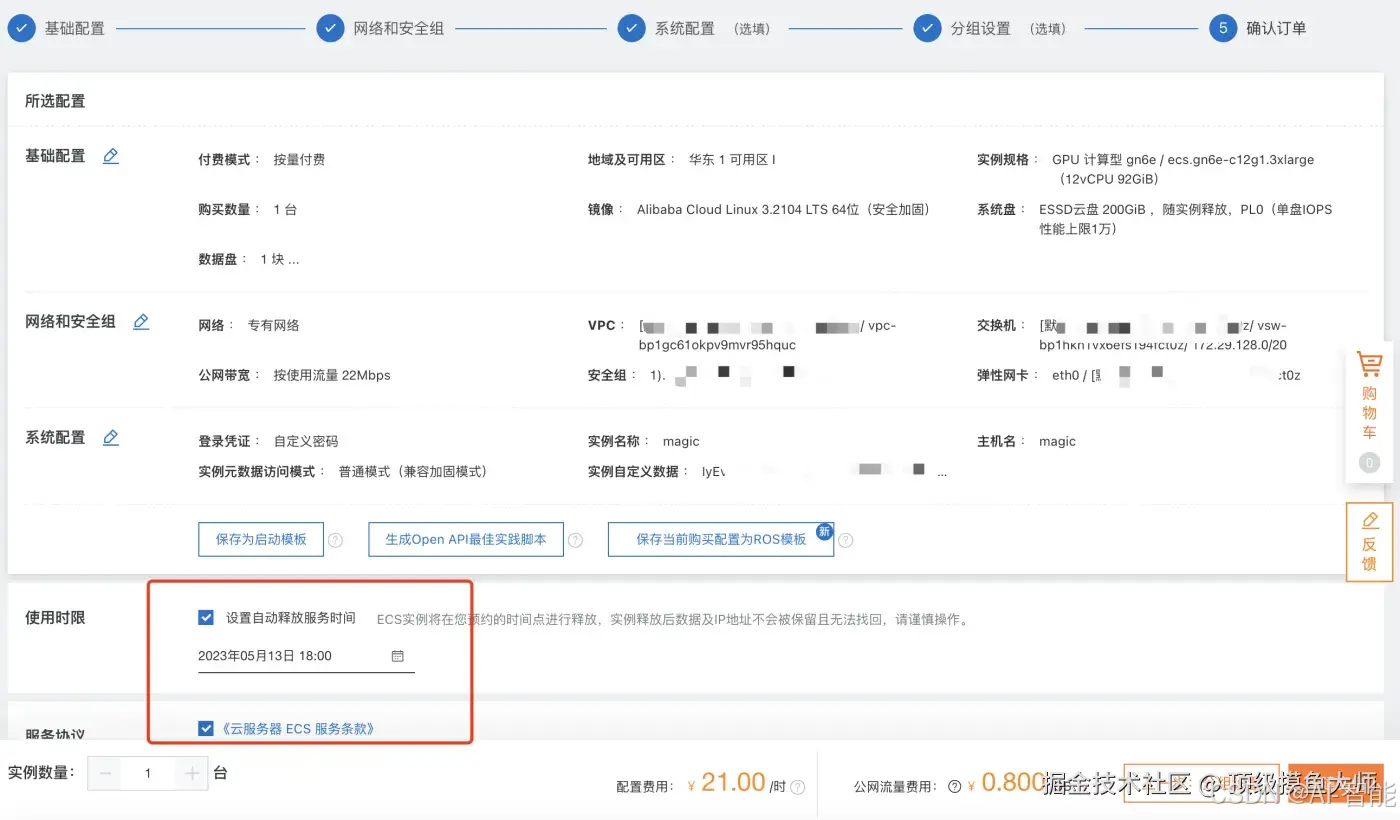
登陆实例安装环境依赖
进入到管理控制台,实例界面,点击远程连接,然后直接登陆,在登陆界面输出对应的密码,即可完成登陆。进入到管理控制台之后,首先会安装对应的GPU显卡驱动。显卡驱动安装完成之后,我们需要安装以下必要的依赖包
yum -y install git
yum install git-lfs
yum install g++
yum install docker
如上,我们的环境准备就完成了,接下来我们开始部署服务。
部署服务
部署服务有以下几步。1. 模型准备 2. 依赖服务启动 3. DB-GPT服务启动
模型准备
在准备模型阶段,我们首先要下载模型。 这里我们依赖两个基础模型,分别是vicuna-13B以及sentence-transformer
git clone https://github.com/csunny/DB-GPT.git
git clone https://huggingface.co/Tribbiani/vicuna-13b
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
模型下载好之后,模型文件需要防止到代码路径下。

DB-GPT/models/
依赖服务启动
我们的项目因为要直接连接数据库,这里我们以MySQL作为样例。前面我们已经安装好了Docker,这里我们只需要通过docker命令启动MySQL即可
docker run --name=mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=aa12345678 -dit mysql:latest
向量数据库我们默认使用的是Chroma内存数据库,所以无需特殊安装,如果有需要连接其他的同学,可以按照我们的教程进行安装配置。
DB-GPT服务启动
首先安装环境与依赖
python 环境我们要起是大于3.9,这里我们用3.10来进行安装。
首先我们需要安装conda环境,我们使用miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh
sh Miniconda3-py310_23.3.1-0-Linux-x86_64.sh
如上,我们就安装conda环境完成了,安装完成之后,需要生效一下环境变量。
source /root/.bashrc
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
如图所示,我们即进入到了我们的环境,接下来安装pip依赖运行就可以啦。

pip install -r requirements.txt
安装完成之后我们就可以运行了,但是运行过程中我们发现报了以下错误。 我们通过添加.pth的方式指定一下环境路径。
echo "/root/workspace/DB-GPT" > /root/miniconda3/env/dbgpt_env/lib/python3.10/site-packages/dbgpt.pth
运行命令启动服务端:
python pilot/server/vicuna_server.py
如下图所示,我们的服务就启动成功了,接下来我们来启动客户端。

运行命令启动客户端
python pilot/server/webserver.py
运行过程中,我们发现报了以下错误。 表明我们的mysql容器未创建成功,需要重新创建一下。
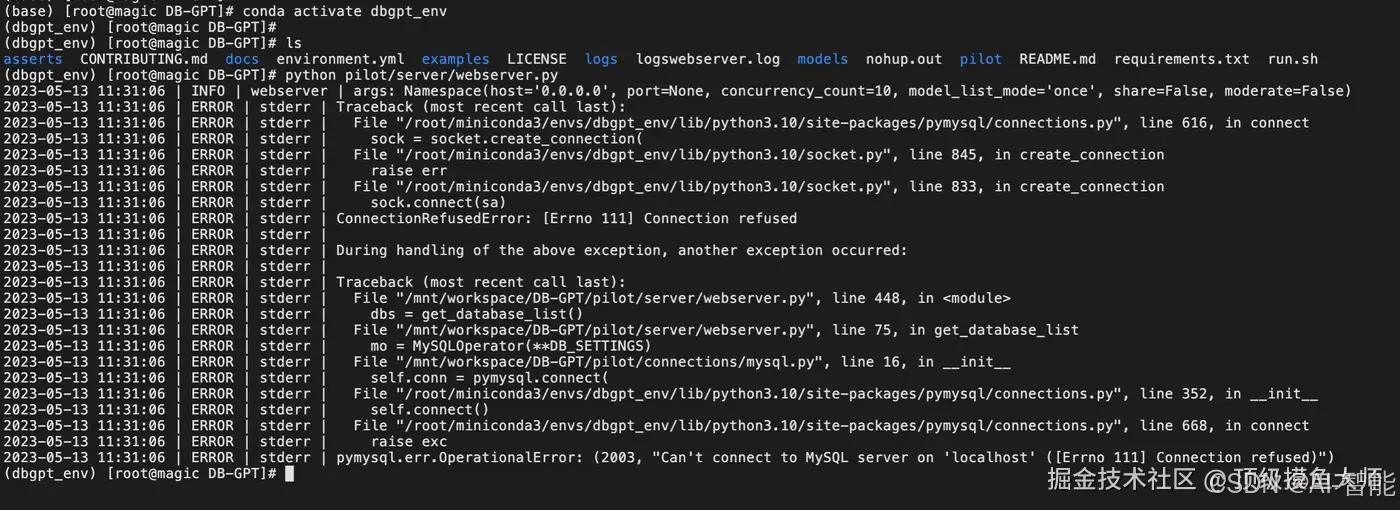
需要注意,mysql容器创建的密码是否与代码配置中的密码一致。 如果不一致可以重新创建或者修改代码。如图所示,我们的客户端服务就启动起来了。

配置安全策略
虽然我们服务已经启动了,但是我们还是无法通过公网访问,我们需要配置安全策略,将端口开放出来。
在阿里云管理控制台,我们找到安全组 -> 管理规则。
通过手动添加开启如下三个规则。
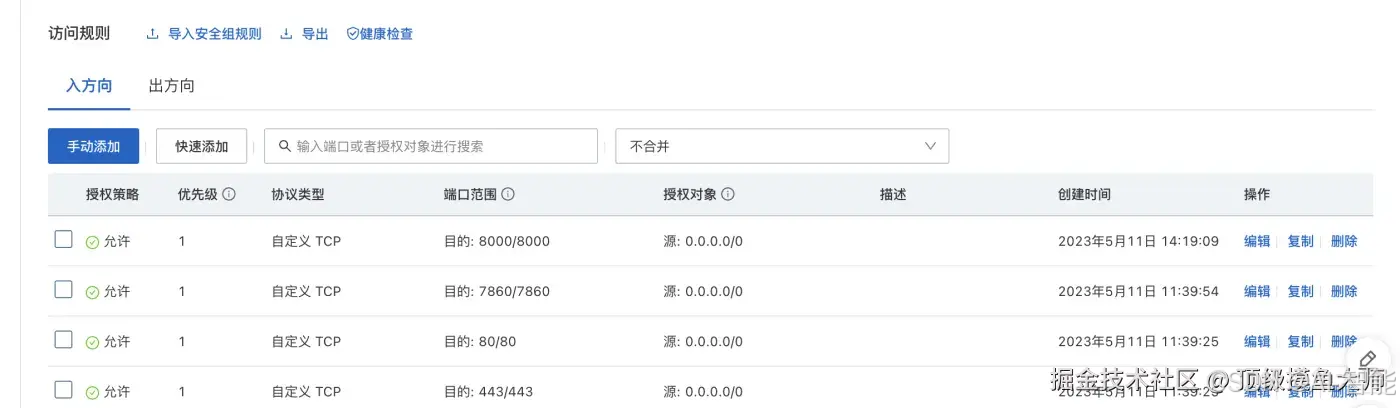
好了,到这里我们就可以访问我们的服务了。如果你需要在本地启动代码,远程连接到阿里云的服务器,只需要在阿里云启动一个后端服务,前端服务本地启动即可。 需要注意要修改本地服务的VICUNA_MODEL_SERVER IP为你的阿里云IP。 然后在本地只启动前端服务即可:
python pilot/server/webserver.py
演示
通过服务器公网ip,我们可以在浏览器打开我们的服务。剩下的就是使用了,我们简单做个小演示吧。
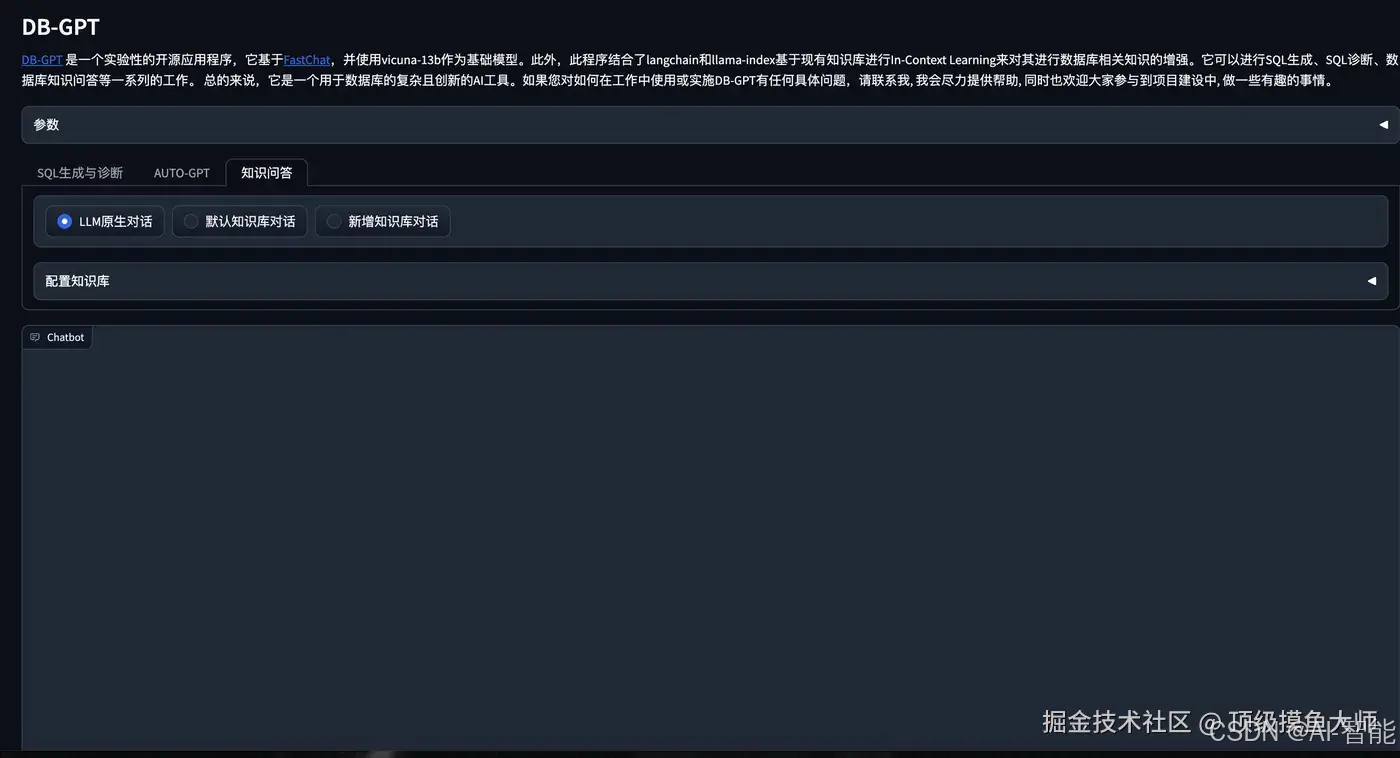
原生回答
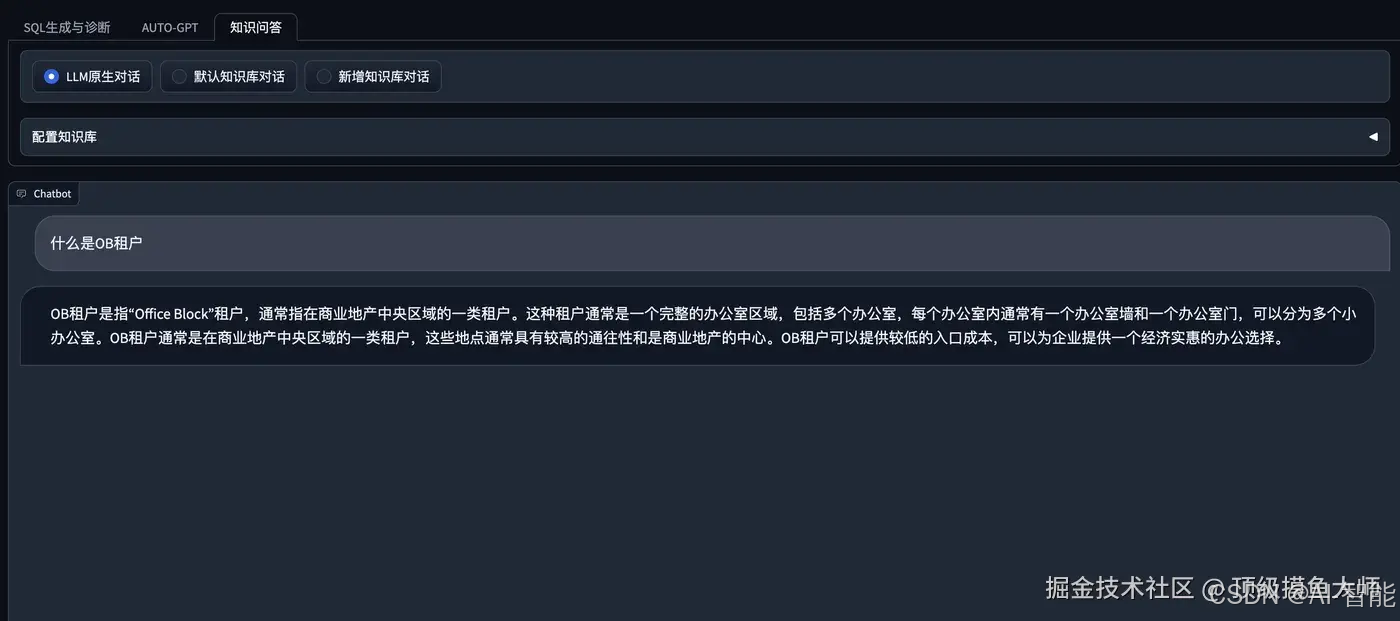
基于知识库
小结
本教程中介绍了如何在阿里云上通过申请GPU来部署DB-GPT服务
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。
二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓