前言
spark:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。简单来说,Spark是一款分布式的计算框架,用于调度成本上千的服务器集群,计算TB、PB乃至EB级别的海量数据。
同时Spark作为全球顶级的分布式计算框架,支持众多编程语言进行开发。而python语言,则是Spark重点支持的方向。
Spark对python语言的支持,重点体现在python第三方库:pyspark上。pyspark是由Spark官方开发的python语言第三方库。python开发者可以使用pip程序快速安装pyspark并像其他三方库那样直接使用。
pyspark的两种用法:
1、作为python库进行数据处理
2、提交至spark集群进行分布式集群计算
1、基础准备
pyspark库的安装:
在终端输入:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
构建pyspark执行环境入口对象:
想要使用pyspark库完成数据处理,首先需要构建一个执行环境入口对象。pyspark的执行环境入口对象是:类 SparkContext 的类对象
# 导包
from pyspark import SparkConf,SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#基于sparkconf类对象创建sparkcontext类对象
sc = SparkContext(conf=conf)
# 打印pyspark的运行版本
print(sc.version)
# 停止sparkcontext对象的运行(停止程序)
sc.stop()
pyspark的编程模型:SparkContext类对象,是pyspark编程中一切功能的入口。pyspark的编程,主要有如下三大步骤:
1、数据输入:通过SparkContext类对象的成员方法,完成数据的读取操作,读取后得到RDD类对象
2、数据处理计算:通过RDD类对象的成员方法完成各种数据计算的需求
3、数据输出:将处理完成后的RDD对象调用各种成员方法完成写出文件、转化为list等操作。
2、数据输入
RDD对象:如图可见,pyspark支持对中数据的输入,再输入完成后,都会得到一个:RDD类对象。RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)。
pyspark针对数据的处理,都是以RDD对象作为载体,即:
数据存储在RDD内
各类数据的计算方法,也都是RDD的成员方法
RDD的数据计算方法,返回值依旧是RDD对象
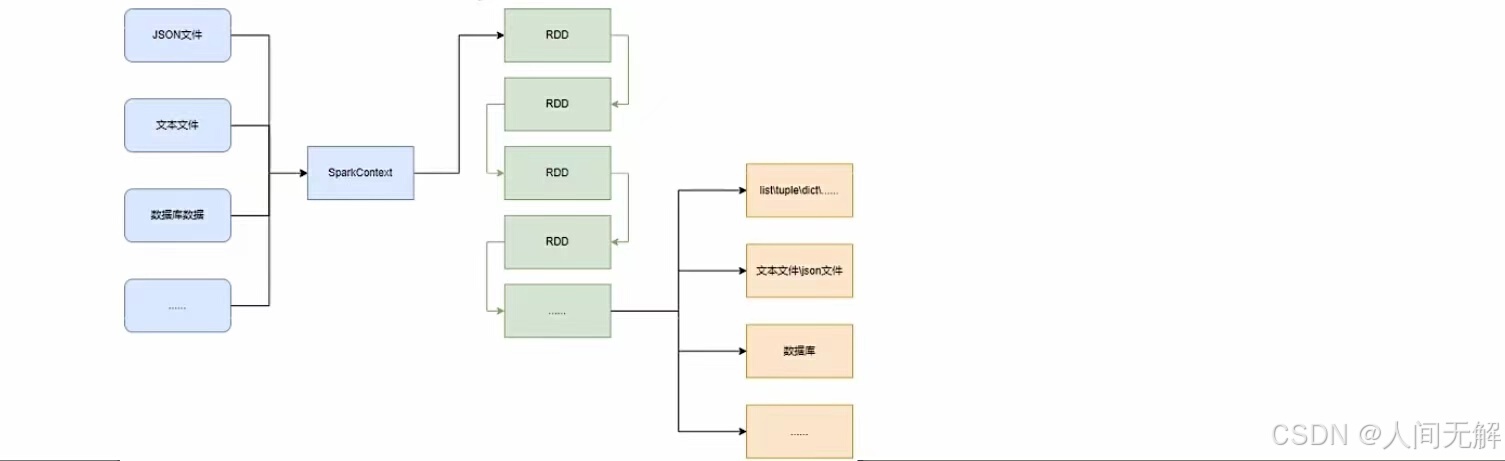
pyspark支持通过SparkContext对象的parallelize成员方法,将:list、tuple、dict、set、str转换为pyspark的RDD类对象。
from pyspark import SparkContext,SparkConf
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize((1,2,3,4,5))
rdd3 = sc.parallelize("abcdef")
rdd4 = sc.parallelize({1,2,3,4,5})
rdd5 = sc.parallelize({"name":"xiaodu","age":23})
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
sc.stop()注意:字符串会被拆分为一个个的字符,存入RDD对象;字典仅有key会被存入RDD对象。
读取文件转RDD对象:
pyspark也支持SparkContext入口对象,来读取文件,构建出RDD对象。
# 读取文件数据输出
from pyspark import SparkContext,SparkConf
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.textFile("test.txt")
print(rdd.collect())
sc.stop()3、数据计算
pyspark的数据计算,都是基于RDD对象来进行的,我们这里列举几个常用数据计算的常用的成员方法(算子)。
3.1、map方法
功能:map算子,是将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数),返回新的RDD。
rdd.map(func)
# func: f:(T) -> U
# (T) -> U 表示的是方法的定义:
# ( ) 表示传入参数,(T) 表示传入1个参数, () 表示没有传入参数
# T 是泛型的代称,在这里表示任意类型
# U 也是泛型的代称,在这里表示任意类型
# -> U 表示返回值
# (T) -> U 总结起来的意思是:这是一个方法,这个方法接受一个参数传入,传入参数类型不限。返回一个返回值,返回值类型不限。
# (A) -> A 总结起来的意思是:这是一个方法,这个方法接受一个参数传入,传入参数类型不限。返回一个返回值,返回值和传入参数类型一致。
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
# spark可能会找不到python解释器,所以我们需要加上上面这句话
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
# 通过map方法将全部数据都乘以10加1
rdd1= rdd.map(lambda x: x * 10 +1)
print(rdd1.collect())
sc.stop()需要注意的是:我们python解释器的版本不能过高,如果过高会出现:Python worker exited unexpectedly (crashed)的Bug,需要降低python解释器版本。
3.2、flatMap方法
功能:对rdd执行map操作,然后进行解除嵌套的操作
# flatMap方法
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["hehe" "halou" "nihao","python pyspark java","C C++ C#"])
rdd1 = rdd.flatMap(lambda x: x.split())
print(rdd1.collect())
sc.stop()3.3、reduceByKey方法
功能:针对KV型(二元元组)RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合操作。
rdd.reduceByKey(func):
# func: (V,V) -> V
# 接受两个传入参数(类型要一致),返回一个返回值,类型和传入要求一致。
# reduceByKey方法
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(("a",1),("a",1),("b",2),("b",1))
rdd1 = rdd.reduceByKey(lambda x,y:x+y)
print(rdd1.collect())
sc.stop()
# 结果:[('b',3),('a',2)]案例1:使用上面一系列算子,统计文件"test.txt"文件中单词出现数量
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.textFile("test.txt")
rdd1 = rdd.flatMap(lambda line: line.split(",")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
print(rdd.collect())
sc.stop()3.4、filter方法
功能:过滤想要的数据进行保留
rdd.filter(func)
# func: (T) -> bool 传入一个任意类型的参数,返回值是布尔类型
返回值是True的数据被保留,False的数据被丢弃
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
# 保留偶数,丢弃奇数
def func(data):
if data % 2 == 0:
return True
rdd1 = rdd.filter(func)
rdd2 = rdd.filter(lambda x: x % 2 == 0)
print(rdd1.collect())
print(rdd2.collect())
sc.stop()3.5、distinct方法
功能:对RDD数据进行去重,返回新的RDD
rdd.distinct() 无需传参
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,2,3,3,4,5,5])
rdd1 = rdd.distinct()
print(rdd1.collect())
sc.stop()
# 结果为:[1,2,3,4,5]3.6、sortBy方法
功能:对RDD数据进行排序,基于直盯盯地排序顺序
rdd.sortBy(func,ascending=False,numPartitions=1)
# func: (T) -> U: 告知按照rdd中的那个顺序进行排序,比如 lambda x: x[1]
# ascending True表示升序,False表示降序
# numPartitions:用多少分区排序
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([("haha",1),("hehe",3),("python",4),("spark",2)])
rdd1 = rdd.sortBy(lambda x:x[1],ascending=False,numPartitions=1) # 按照降序进行排序
print(rdd1.collect())
sc.stop()4、数据输出
4.1、输出为python对象
collect算子,功能:将RDD个各个分区内的数据,同意收集到Driver,形成一个list对象
rdd.collect()
# 返回值是一个list
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf =SparkConf().setMaster("local[*]").setAppName("pyspark_test")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
print(rdd.collect())
print(type(rdd.collect()))
sc.stop()

reduce算子,功能:对RDD数据集按照传入的逻辑进行聚合(有点类似于reduceByKey,但reduce只聚合并不会对key进行分组)。
rdd.reduce(func)
# func: (T,T) -> T
# 两个参数传入一个返回值,返回值和参数要求类型一致
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf =SparkConf().setMaster("local[*]").setAppName("pyspark_test")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
print(rdd.reduce(lambda x,y:x+y))
sc.stop()take算子,功能:取RDD的前N个元素,组合成list返回给你。
# 比如:sc.parallelize([1,2,3,4,5,6]).take(5)
# 结果为:[1,2,3,4,5]
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf =SparkConf().setMaster("local[*]").setAppName("pyspark_test")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
take_rdd = rdd.take(3)
print(rdd.collect())
sc.stop()count算子,功能:计算RDD有多少条数据,返回值是一个数字
sc.parallelize([1,2,3,4,5]).count()
# 结果为:6
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
conf =SparkConf().setMaster("local[*]").setAppName("pyspark_test")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
num_rdd=rdd.count()
print(f"rdd中元素的数量为{num_rdd}")
sc.stop()4.2、输出到文件
saveAsTextFile算子,功能:将RDD的数据写入文本文件中,支持本地写出,hdfs等文件系统。
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python学习/python/python.exe"
os.environ['HADOOP_HOME'] = "D:/hadoop/hadoop.tar/hadoop-3.0.0/hadoop-3.0.0"
conf =SparkConf().setMaster("local[*]").setAppName("pyspark_test")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize([("hello",3),("spark",5),("hi",7)])
rdd3 = sc.parallelize([[1,2,3],[2,4,5],[5,7,9]])
# 输出到文件
rdd1.saveAsTextFile("D:/python学习/python_study/pythonProject/output1")
rdd2.saveAsTextFile("D:/python学习/python_study/pythonProject/output2")
rdd3.saveAsTextFile("D:/python学习/python_study/pythonProject/output3")这里需要安装Hadoop,并配置环境,但具体如何配置环境就不在这里细说了:
Hadoop:hhttp://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gzwinutils.exe:https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
hadoop.dllhttps://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
修改rdd分区为1个:
方式1,SparkConf对象设置属性全局并行度为1:
conf = SparkConf().setMaster("local[*]'"),setAppName("test_spark")
conf.set("spark.default.parallelism","1")
sc = SparkConText(conf=conf)
方式2,创建RDD对象的时候设置(parallelize方法传入numSlices的参数为1)
rdd1 = sc.parallelize([1,2,3,4,5],numSlices=1)
rdd2 = sc.parallelize([1,2,3,4,5],1)