计算机科学中具有特殊含义或易误解混淆的术语辨析
这是我以前收集整理的文档,参考了一些网上的公开资料。这次发到这里,是因为可以随时修改。不足之处,敬请指正,以便修正。
计算机科学中有些术语不具一致性,容易引起混淆。有几方面原因:一是计算机科学相对年轻发展活跃,不可能有周全单一的理论解释所有的方面,不同国家地区、不同组织在开发和技术发展的过程中,使用了各种不同的术语,或多词一意,或一词多义,甚至同一行业中不同人采用的术语也有如此现象。二是翻译差异更加剧此种现象,不论是汉语和英语,有些词本身语义宽泛,一词多义多词一义比较普遍,并且汉语词语和英语词语显然难以一一对应,这就造成有些术语在不同文档资料甚至同一文档资料中不一致。技术不会是静态的,而是不断发展变化着,术语混乱甚至矛盾难以避免。要切贴地理解术语的意义,需要根据专业范围、语境场合、作者的意图综合理解,而不要孤立的对待。我在学习的过程中,受其困惑颇深,故试着辨析总结。这次发到这里,希望对学习者特别是初学者提供有益的一点帮助。
——目录——
目录(Directory)/文件夹(Folder)、路径(Path)
program、subroutine、procedure和method
function和method
process和procedure
进程(process)和线程(thread)
argument 和parameter
interactive(交互式)
form(窗体;表单)、Window(窗口)、dialog(对话框)
操作系统安装(The operating system installation)的方式
兼容(compatibility、Compatible)
Blog和Bloger
主机(Host)和终端(Terminal)
Local(局部的,本地的)
client和server
Internet(因特网)和internet(互连网)
网络分层模型的各种层的数据格式的名称:packet、Message和Datagram
节点(Node)和站点(site)
Frequency(频率)和Clock cycle(时钟周期)
基带(baseband)和宽[频]带(broadband)
信噪比(Signal to Noise Ratio)
射频(RF)
carrier wave(载波)
Synchronization (同步) 与asynchronization (异步)
占位符(placeholder)
接口(interface)和端口(port)
透明的(transparent)
Heap (堆)和stack ([堆]栈)
Rights、permissions、Privileges
Control (控件)和Component (组件)
attribute 和property
document和file
Catalog 、Directory、contents 和folder
backup、copy和 replication、replica
point-to-point和end-to-end
passive和active
Connection、link和 join
Field和Domain
Relationship和relation
引用(reference)、参照[引用]关系(Referencing Relation)、被参照[被引用]关系(Referenced Relation)
pattern、mode、model和Schema
实体(Entity)、实体集(Entity Set)、实体类型(Entity Type)和实体实例(Entity instance)
快照(Snapshot) 和动态集(Dynaset)
类(Class)与类型(Type)
Empty、null
模式(modal)和无模式(modeless)
早绑定(Early binding)和 晚绑定(Late Binding)
焦点(Focus)和 插入点(Insertion point)
超线程(Hyper-Threading)和多核(MultiCore)
并发(concurrent)、并行(parallel)、分布(distributed)
仿真 emulation 模拟 simulation
Caption、title、Heading、Header
label、tab、tag
item和project
standard 和criterion、Criteria
Orthogonality(正交性)
标量(scalar)和向[矢]量(vector)
Literal(字面量)
Graphics(图形)、image(图像)、Picture(图片)
别名(alias)
斜杠/和反斜杠\
人工智能(AI、Artificial Intelligence)、机器学习(machine learning)和深度学习(deep learning)
——解释——
目录(Directory)/文件夹(Folder)、路径(Path)
目录(Directory)是文件系统中的一种特殊文件,用于存储和组织其他文件和子目录。
文件夹(Folder)是目录的另一种称呼,常用于图形用户界面(GUI)环境中。
路径(Path)是指定文件或目录在文件系统中位置的一串字符序列,描述了从根目录或当前目录到达特定文件或目录所经过的目录序列。路径(Path)中的目录通过特定的分隔符(如Unix或Linux系统中的系统中的"/",Windows系统中的"\"或系统中的"/")进行分隔。
路径分为:绝对路径和相对路径
绝对路径:从根目录开始,指定文件或目录的完整路径。根目录是所有文件和目录的起点。在Linux或UNIX系统中,根目录用斜杠(/)表示。在Windows系统中根目录用盘符:斜杠(如C:\)表示。Windows操作系统能够识别和处理这两种分隔符。例如,"C:\Users\John\Documents"和"C:/Users/John/Documents"都是有效的Windows路径。
相对路径:相对于当前目录,指定文件或目录的路径。
program(me)、subroutine、procedure和method
program,[电脑]程序
subroutine(简写为sub), [电脑]子程序,子例程
routine,[电脑]例程(例行程序),子程序
subprogram,[电脑]子程序
function,[电脑]函数
procedure,[电脑]过程,存储过程
method,[电脑]方法
program,指适宜计算机处理的一种指令序列,完成一个所需要的任务。
subroutine,routine,subprogram,function,procedure都含有“具有通用性或经常使用的、为别的程序调用的程序或指令序列”意项,一般不必刻意区分,它们的规模通常比program小。
在计算机编程(计算机程序设计)领域,通常认为,procedure、subroutine、routine 和subprogram含义相同,都是指由另一个程序调用的长度较小或是重要的小程序。subroutine 和sub 、routine,虽然从构词法上分析 subroutine = sub + routine,但三者的意思一样。
Subroutine 在程序设计语言里用,它和 procedure 有相同的意思,但 procedure 这个词的限制更少。RPC (Remote Procedure Call)远程过程调用。
Function 和 subroutine/procedure 含义也差不多,区别在于:前者一般需要指定返回值(C 语言里的过程都是 functions),而后者可能不具有返回值(BASIC 语言当中有两种过程,Sub 和 Function 过程(Procedures))。具体的区别主要取决于适用语言的上下文。
method一般是指对象的成员函数(c++的member function在java叫method,以强调其面向对象属性)。
function和method
函数(function)是可以执行的代码块。函数是一段代码,通过名字来进行调用。它能将一些数据(参数)传递进去进行处理,然后返回一些数据(返回值),也可以没有返回值。
方法(method)是通过对象调用的函数。方法(method)是面向对象程序设计里的概念,方法也是一段代码,也通过名字来进行调用,但它跟一个对象相关联。方法和函数大致上是相同的,简单来讲,“类里叫方法,类外叫函数”。
(请记住,对象是类的实例化——类定义了一个数据类型,而对象是该数据类型的一个实例化)
方法在 C++ 中是被称为成员函数”。因此,在 C++ 中的“方法”和“函数”的区别,就是“成员函数”和“函数”的区别。此外,诸如 Java 一类的编程语言只有“方法”。所以这时候就是“静态方法”和“方法”直接的区别。
Process和procedure
process,进程,过程;加工; 处理
procedure,过程;程序
process,一般地,译为“过程”多与编程语言静态特性有关;译为“进程”多与CPU硬件动态运行有关。操作系统中“进程和线程”的进程是process。VB中的“过程”是procedure。都是名词。另外,process很多时候译为“处理“(动词),如data processing system;online analytical processing (OLAP) 联机分析处理(OLAP) (for database); interprocess communication (IPC)进程间通讯(IPC);online transaction processing (OLTP) 联机事务处理(OLTP) (for database);还有,processor 处理器。
procedure,一般译为“过程”,如RPC (remote procedure call)RPC(远程过程调用),stored procedure 存储过程 (for database)。过程(procedure),命名的语句序列,在语法上为完全的单元,可表达一种动作、声明或定义。尽管可以用分号 (:) 使一行中包含多个语句,但语句通常要占据一行。也可用续行符 ( _) 在第二个物理行上继续一个逻辑行上的内容。过程可作为单元来执行。例如,Function、Property和 Sub 都是过程类型。总是在模块级别定义过程的名称(过程包含在模块中),所有可执行的代码必须包含在过程内,过程不能套在其它过程中。
进程(process)和线程(thread)
线程是进程的可执行单元,是计算机分配CPU机时的基本单元,线程隶属于进程,是进程之内运行的一个单元,同一个进程的多个线程共享该进程的资源和操作系统分配给该进程的内存空间。每个多线程的进程中必有一个主线程,该进程中的其它线程都是由主线程创建的。
进程和线程都是由操作系统所体会的程序运行的基本单元,系统利用该基本单元实现系统对应用的并发性。进程和线程的区别在于:
简而言之,一个程序至少有一个进程,一个进程至少有一个线程。
线程的划分尺度小于进程,使得多线程程序的并发性高。
另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行。
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
argument 和parameter
argument
n. 论点;理由; 论据; 讨论,辩论; 争论;[计]参数,更多的表示实参,在部分翻译中被叫做引数
parameter
n. 参数;决定因素; <物><数>参量;
argument 和parameter都有参数的意思,在编程语言中,通常可以互换,但有区别:一个是实参,一个是形参。调用时用Argument,声明时用Parameter 。
argument是指调用函数时传入的数值—— 实参、 引数。 parameter指的是函数定义中括号里面的变量——形参。
比如:
double CalcArea(double width, double height)
{
// whatever
return whatever;
}
这里的width和height都是parameter
如果你在主程序中调用
void main()
{
...
thisArea = CalcArea(2.4, 5.7);
}
这里的2.4和5.7是argument
parameter更强调声明/形式层面的东西,argument更强调实体层面的。
这两个术语有时可以互换使用,许多程序员或文章交替使用 argument和parameter ,应根据上下文来区分含义。
The term parameter is used to describe the names for values that are expected to be
supplied. The term argument is used for the values provided for each parameter.
形参被用于描述(在函数内)期望被提供的值的名字,而实参则被用于描述(调用函数时)提供给
每个形参的值。
进一步阅读:[ISO/IEC 9899] http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1124.pdf
在这份标准中,第 3 页的 actual parameter 和第 6 页的 formal argument 两种说法均已被弃
用,而在早期的标准中(如 C99)argument 和 parameter 被约定为没有区别。
argument 和 parameter有何区别?
While defining method, variables passed in the method are called parameters.
当定义方法时,传递到方法中的变量称为parameters..
While using those methods, values passed to those variables are called arguments.
当使用方法时,传给变量的值称为arguments.
函数(function)、形参(Parameters)和 实参(Arguments)
A function is a block of code which only runs when it is called.
函数是一个代码块,它只在被调用时运行。
The terms parameter and argument can be used for the same thing: information that are passed into a function.
术语形参(parameter)和实参(argument)可以用于相同的事情:传递到函数(function)中的信息。
From a function's perspective:
从函数的角度来看:
A parameter is the variable listed inside the parentheses in the function definition.
形参(parameter)是函数定义中括号内列出的变量。
An argument is the value that is sent to the function when it is called.
实参(argument)是函数被调用时发送给它的值。
interactive(交互式)
interactive(交互式),简单地说就是有来有往互相的行为,作为用户与计算机系统交换信息的术语,指使用者和程序或计算机系统之间的具有双向的信息传递功能(双向对话),也就是使用者通过按钮、键盘、鼠标等发出控制要求,程序或计算机系统作出相应的反应(比如给出结果)。用户与程序相互作用,这种作用也许简单到只击中一个按钮或键入字符,也许复杂到要操纵一辆汽车或漫游虚拟世界。
Form(窗体)、Window(窗口)、dialog(对话框)
窗体(Form)、窗口(Window)和对话框(dialog)
在编程技术中,窗体(Form)和窗口(Window)这两个概念类似,在各种编程语言或框架(framework)中,窗体(Form)和窗口(Window)都是应用程序中用于承载其他控件的容器,它们可以包含菜单栏、工具栏、状态栏等可见部分。
需要注意的是,不同的编程框架和编程语言通常有它们自己的术语和概念来描述应用程序的用户界面组件和容器。例如,在 .NET Framework 中,Windows Forms 应用程序中的窗体称为 Form,而在 WPF 中,它们称为 Window。在 Java 中,AWT 和 Swing 窗体称为 Frame,而 JavaFX 中的窗体称为 Stage。在 Python 中,Tkinter 窗口称为 Toplevel,而 PyQT 窗口称为 QWidget。
对话框(dialog):是一种特殊类型的窗口,通常用于提示用户提供某些信息或选择操作。对话框分为模态对话框(Modal Dialog)和非模态对话框(Modeless Dialog),前者是指当前窗口将阻止与其交互的所有其他窗口,“强制”用户先处理完对话框中的内容;而后者则允许用户在对话框未关闭的情况下继续与其他窗口交互。
Form:窗体;表单
当“窗体;表单”讲义项时,是指向用户显示信息的可视图界面。
窗体也是对象,窗体类定义了生成窗体的模板,每实例化一个窗体类,就产生一个窗体。窗体都具有自己的特征,可以通过编程来设置。
.NET框架类库的System.Windows.Forms命名控件中定义的Form类是所有窗体类的基类。编写窗体应用程序时,首先需要设计窗体的外观和在窗体中添加控件或组件。Visual Studio 2005提供了一个图形化的可视化窗体设计器,可以实现所见即所得的设计效果,可以快速开发窗体应用程序。虽然可以通过编写代码来实现,但是却不直观、也不方便,而且很难精确地控制界面。
在前端开发中,form也被翻译为表单。表单(form)是一类 HTML 元素,用于在 web 页面中收集用户输入。表单通常由多个输入元素如文本框、下拉框、复选框等和提交按钮组成,用户可以填写表单元素并通过提交按钮将数据发送给服务器。表单是 web 应用程序中最为基础的用户交互形式之一,几乎所有类型的 web 应用都使用表单来收集用户数据。同时,表单还是开发基于输入数据的 web 应用程序的重要组成部分,例如登录页面、注册页面、购物车和搜索功能等。
操作系统安装(The operating system installation)的方式
覆盖安装:主要就是对已有操作系统进行的修复安装,它会保持原有的配置信息,而且大多数已安装的软件不需要在重新安装,如果系统不是崩溃或者不是存在严重的问题,可选择覆盖安装,来修复系统存在的一些问题。注意的就是,最好用原系统相同版本的xp,否则会造成错误,重者导致进不去系统。简单地说,所谓覆盖安装就是不管原文件如何,再用这个安装程序安装一遍,地址路径要一致。这样系统还留有以前的东西。
重新安装:指格式化后再安装,重装后的系统很干净,速度也比覆盖安装快。
升级安装:指同一系列的软件从低版本更新到高级的版本。 如从windows XP升级到windows 7。
全新安装:分两种,一种是指在未安装操作系统的电脑中安装操作系统,一种是在已安装操作系统的电脑中的另一个分区中安装另一个操作系统(双系统)。
兼容(compatibility、Compatible)
简单的说,兼容(Compatibility)是指几个硬件之间、几个软件之间或是几个软硬件之间的相互配合的程度,或者说能共存 相容的程度。
简单说来,老的能够处理新的就称为 向前(forward)或向上(Upward )兼容。新的能够处理老的就称为 向后(Backward)或向下(Downward )兼容。
向上兼容(Upward Compatibility),又称作向前兼容(Forward Compatibility)。在计算机中指在较低档计算机上编写的程序,可以在同一系列的较高档计算机上运行,或者在某一平台的较低版本环境中编写的程序可以在较高版本的环境中运行,都称为向上兼容。
向下兼容(Downward Compatibility),又称作向后兼容(Backward Compatibility)。在计算机中指较高档的计算机或较高版本的软件平台可以运行较为抵挡计算机或早期的软件平台所开发的程序。
Blog和Bloger
Blog是Web Log的简称,指网络日志(网志);Bloger指撰写Blog的人。许多时候,将它们都翻译为“博客”,换句话说 ,中文“博客”分别代表两种意思,Log(网络日志)和Bloger(撰写Blog的人),因此中文“博客”一词,需要留意在不同的场合分别代表不同含义。
主机(Host)和终端(Terminal)
最早的计算机网络是伴随着主机(Host)和终端(Terminal)这两个概念的出现而产生的。当时的主机通常指大型机或功能较强的小型机,而终端则是指一种哑终端(Dumb terminal),是一种由CRT显示器、控制器及键盘合为一体的设备,它与我们平常指的微型计算机的根本区别是没有自己的中央处理单元(CPU),当然也没有自己的内存,其主要功能是将键盘输入的请求数据发往主机(或打印机)并将主机运算的结果显示出来。随着计算技术的发展,引入了新的含义主机是一般指服务器(提供应用程序,数据服务等等),终端一般指客户端(仅提供交互界面或输入输出设备)把以PC为代表的基于开放性工业标准架构、功能比较强大的设备叫做“胖客户端”,其他归入“瘦客户端”。
对互联网而言,终端泛指一切可以接入直接供用户操作的设备,如个人电脑、网络电视、可上网手机、PDA等。
微软从NT及2000后提供“终端服务”这一功能,终端服务起到的作用就是方便多用户一起操作网络中开启终端服务的服务器,所有用户对同一台服务器操作,所有操作和运算都放在该服务器上。允许多个客户端(终端)同时登录服务器。
host一词在不同环境中有不同含义:在互联网协议中,host表示能够同其他机器互相访问的本地计算机 (主机或节点)。对于网站,host指的是网站的网络服务器。在大型机环境中,host指大型机,也称大型服务器。
有时,host也指某种为其他软硬件提供服务的设备或者应用程序。
Window系统中有个Hosts文件(没有后缀名),在Windows98系统下该文件在Windows目录,在Windows2000/XP系统中位于C:\[Winnt|WINDOWS|]\System32\Drivers\Etc 目录中。该文件其实是一个纯文本的文件,用普通的文本编辑软件如记事本等都能打开。
用记事本打开hosts文件,首先看见了微软对这个文件的说明。这个文件是根据TCP/IP for Windows的标准来工作的,它的作用是包含IP地址和Host name(主机名)的映射关系,是一个映射IP地址和Hostname(主机名)的规定,规定要求每段只能包括一个映射关系,IP地址要放在每段的最前面,空格后再写上映射的Host name(主机名)。对于这段的映射说明用“#”分割后用文字说明。
local
【修】局部的,本地的;[局部性的]
local指与用户直接操作的计算机,或指处于用户直接控制之下的设备(如打印机)或进程。与远程主机(remote host)、设备、和进程相对。
local
adj. 1. In general, close at hand or restricted to a particular area. 2. In communications, a device that can be accessed directly rather than by means of a communications line. 3. In information processing, an operation performed by the computer at hand rather than by a remote computer. 4. In programming, a variable that is restricted in scope, that is, used in only one part (subprogram, procedure, or function) of a program. Compare remote.
形容词。 1 、一般而言,就在眼前(在手边 )或仅限于某一特定区域。 2 、在通信中,可以直接访问的设备,而不是通过通信线路。 3 、在信息处理中,操作由手边的计算机而不是由远程计算机执行。 4 、在编程中,一个变量是受限制的范围,也就是只能用于程序的一部分(子程序,过程 ,或函数)。
local variable(局部变量) 只能在一个函数或过程中访问的变量。其他过程或函数不能访问此变量的数据。
local host
用户当前登录进入的主机(host).任何用户的当前本地主机的回调地址(loop back address)总是127.0.0.1。
client和server
A hardware and software device designed to perform a specificfunction for many users.
为多个用户实现某一特定功能而设计的一种硬件和软件设备。
client
客户[机];客户程序
client,发出请求的一方的硬件或软件。
server
服务器;服务程序
server,提供服务的一方的硬件或软件。
计算机网络的主要用途之一是允许共享资源。这种共享是通过相呼应的两个独立程序来完成的。每个程序在相应的计算机上运行。一个程序在服务器中,提供特定资源;另一个程序在客户机中,它使客户机能够使用服务器上的资源。
在INTERNET上,通常看不到硬件,术语“客户机”和“服务器”一般指申请和提供服务的程序。
客户机/服务器系统(Client/Server System)是计算机网络(尤其是Internet)中最重要的应用技术之一,其系统结构是指把一个大型的计算机应用系统变为多个能互为独立的子系统,而服务器便是整个应用系统资源的存储与管理中心,多台客户机则各自处理相应的功能,共同实现完整的应用。用户使用应用程序时,首先启动客户机通过有关命令告知服务器进行连接以完成各种操作,而服务器则按照此请示提供相应的服务。
从硬件角度看,谁是client谁是server也不是绝对的,例如倘若原提供服务之server要使用其它server所提供之服务,则所扮演之角色即转变为client。从软件角度看,client及server不一定建立在两台分开的机器上,也有可能都在同一台机器上,例如我们在提供网页的服务器上执行浏览器浏览本机所提供的网页,这样server和client就在同一台机器上。
客户(Client)和服务器(Server)用于描述“网络”体系结构和“软件系统”体系结构时,含义不完全一致。
Internet(因特网)和internet(互连网)
大写的“Internet”和小写的“internet”所指的对象是不同的。当我们所说的是上文谈到的那个全球最大的的也就是我们通常所使用的互联网络时,我们就称它为“因特网”或称为“国际互联网”,虽然后一个名称并不规范。在这里,“因特网”是作为专有名词出现的,因而开头字母必须大写。但如果作为普通名词使用,即开头字母小写的“internet”(“interreto”),则泛指由多个计算机网络相互连接而成一个大型网络。按全国科学技术审定委员会的审定,这样的网络系统可以通称为“互联网”。这就是说,因特网和其他类似的由计算机相互连接而成的大型网络系统,都可算是“互联网”,因特网只是互联网中最大的一个。《现代汉语词典》2002年增补本对“互联网”和“因特网”所下的定义分别是“指由若干电子机网络相互连接而成的网络”和“目前全球最大的一个电子计算机互联网,是由美国的ARPA网发展演变而来的”。可供参考。
美国2002 年出版的《美国国家信息技术标准词典》(A M E R I C A N N A T I O N A L STANDARD DICTIONARY OF INFORMATIONTECHNOLOGY),对于因特网和互联网给出了如下定义:
Internet: The world wide network connecting users through autonomous networks in industry, education, government, and research. The Internet uses Internet Protocol (IP) for network interconnection and routing, and Transmission Control Protocol (TCP) for end-to-end control. The major Internet services include electronic mail, FTP, telnet, World Wide Web, and electronic bulletin boards (Usenet). Do not confuse an internet (lowercase "i") which is a general concept, with the Internet (uppercase "I") which is a single internet of global proportions.
译成中文如下:因特网:是通过产业、教育、政府和科研部门中的自治网络将用户连接起来的世界范围的网络。因特网采用网际协议(IP)进行网络互连和路由选择,采用传输控制协议(TCP)实现端对端控制。因特网的主要业务包括电子邮件、文件传送协议(FTP)、远程登录、万维网和电子公告板。不要把一般概念的互连网(internet的首字母“i”小写)与一个全球规模的因特网(Internet 的首字母“I”大写)相混淆。
internet: Synonym for"internetwork" internetwork. Do not confuse the Internet (with an uppercase "I"), with an internet (lowercase "I"). The term internet is very general and does NOT imply global. In fact, two or more interconnected local area networks constitute an internet, even if they are both in the same building and owned by the same organization.
译成中文如下: 互连网: 是互连网络(internetwork)的同义词。不要把Internet(首字母“I”大写,因特网)与internet(首字母“i”小写,互连网)相混淆。术语互连网是非常普遍的,并不意味着全球。实际上,两个或多个相互连接的局域网可组成一个互连网,即使它们位于同一座建筑物里和属于同一个机构所有。
internetwork:
A network of two or moresubnetworks. This network may includebridges,routers,gateways,or combinations thereof.Synonymous with internet.
译成中文如下:互联网络:是两个或多个子网络构成的一种网络。这种网络可包括网桥、路由器、网关或它们的组合。与internet 是同义词。
网络分层模型的各种层的数据格式的名称:packet、Message和Datagram
一般地(并不绝对),OSI网络分层模型的各种层的数据格式的名称:
OSI层 数据单元的名称
传输层(transport 4) SEGMENT(段)或Message(报文;消息)
网络层(network 3) PACKET([数据]分组,[数据]包)或Datagram(数据报)
数据链路层(data link 2) Frame(帧)
OSI参考模型的各层传输的数据和控制信息具有多种格式,除了物理层(physical)使用BITS([二进制]位),其它各层,使用的信息格式包括帧、数据包、数据报、段、消息、元素和数据单元。信息交换发生在对等OSI层之间,在源端机中每一层把控制信息附加到数据中,而目的机器的每一层则对接收到的信息进行分析,并从数据中移去控制信息,下面是各信息单元的说明:
帧(frame)是一种信息单位,它的起始点和目的点都是数据链路层。
分组(packet)也是一种信息单位,它的起始和目的地是网络层。
数据报(datagram)通常是指起始点和目的地都使用无连接网络服务的的网络层的信息单元。
段(segment)通常是指起始点和目的地都是传输层的信息单元。
消息(message)是指起始点和目的地都在网络层以上(经常在应用层)的信息单元。
信元(cell)是一种固定长度的信息,它的起始点和目的地都是数据链路层。信元通常用于异步传输模式(ATM)和交换多兆位数据服务(SMDS)网络等交换环境。
节点(Node)和站点(site)
节点(Node)
1.是网络中两个或更多线路的一个的公共结合点或公共连接实体。节点有时被一般用于指任何能够访问网络的实体,节点通常与具有唯一 IP 主机地址的逻辑或物理计算机系统对应。也可称为结点或网点。
2.在计算机网络领域内,ISO(国际标准化组织)把node定义为:A point at which one or more functional units interconnect transmission channels or data circuits(在那里一个或多个操作装置<这里最好不译为:功能单元>和若干条传输信道<有时指计算机的通道>或数据电路互相连接起来的一个地点)。
站点(site)
1.A place where a particular type of computer is installed.
用于安装有某种特定类型计算机的现场或地方。
2. 指网站。
3 .地点,场所。
节点(Node),构成网络的一个个要素。通信网络中的计算机和集线器,路由器等一台台的通信机器就相当于节点。
Active Directory中的站点(site)站点就是高速相连的一组计算机。
站点(site)是指在物理上具有较好的线路连接的能实现较快通信速率的计算机的集合(一般是指一个局域网),站点之间一般是通过慢速连接来实现信息通信(一般是指广域网)。
Frequency(频率)和Clock cycle(时钟周期)
频率,指在一个周期内的重复次数,或每秒的周波数。计量单位为Hz(Hertz),如频率为1000Hz(1kHz)的音频信号每秒便有1000个正弦波的周波。
The number of repetitions of a complete sequence of values of a periodic function per unit variation of an independent variable. 当自变量变化一个单位时,周期函数取同一完整数序的重复次数。
The number of complete cycles of a periodic process occurring per unit time. 单位时间内周期过程中发生的次数。
The number of repetitions per unit time of a complete waveform, as of an electric current. 单位时间内某种完整波形的重复次数,例如电流。
The ratio of the number of times an event occurs in a series of trials of a chance experiment to the number of trials of the experiment performed. 一系列实验中偶然现象次数与所做的一系列实验的次数的比率。
时钟周期,是一个时间的量,时钟周期通常为一个机器周期,为计算机硬件运行指令的时间单位。
频率和周期的关系是互为倒数。更小的时钟周期就意味着更高的工作频率。
频率用“f”表示,其相应的单位有:Hz(赫hertz)、kHz(千赫kilohertz)、MHz(兆赫megahertz)、GHz(吉赫gigahertz)。其中1GHz=1000MHz,1MHz=1000kHz,1kHz=1000Hz。周期用“t”表示,计算脉冲信号周期的时间单位及相应的换算关系是:s(秒)、ms(毫秒millisecond)、μs(微秒microsecond)、ns(纳秒nanosecond),其中:1s=1000ms,1 ms=1000μs,1μs=1000ns。
基带(baseband)和宽[频]带(broadband)
基带(baseband)
In communications, the frequency range of the information bearing signals prior to combination with carrier wave by modulation.
在通信技术中,未经调制使之和载波结合之前,携带信息的信号所占有的频率范围。
宽[频]带(broadband)
In communications, a frequency band having a bandwidth greater than a voice-grade channel (4kHz), that divisible into several narrower bands so that different kinds of transmissions such as voice, video, and data transmission can occur at the same time, and therefore capable of higher-speed data transmission.
在通信技术中,一种比音频信道(4kHz)更宽的频带。它可划分成几条较窄的频带,以使 不同类型的传输,如音频、视频及数据传输,可在其上同时进行,因此具有较高速的数据 传输能力。
基带是一种传输方式。在该方式中,电压脉冲直接加到电缆,并且使用电缆的整个信号频率范围。基带与宽带传输相比较,宽带传输中,来自多条信道的无线信号调制到不同的“载波”频率上,带宽被划分为不同信道,每信道上的频率范围一定。
LocalTalk及以太网都是基带网络,一次仅传输一个信号,电缆上信号电平的改变表示数字值0或者1。使用电缆的整个带宽建立起两个系统间的通信对话,然后两个系统轮流传送,在此期间,共享电缆的其它系统不能传送。
基带传输系统中的直流信号往往由于电阻、电容等因素而衰减。另外马达、荧光灯等电子设备产生的外部电磁干扰也会加快信号的衰减。传输率越高,信号就越容易被衰减。为此,以太网等建网标准规定了网络电缆类型、电缆屏蔽、电缆距离、传输率以及在大部分环境中提供相对无差错服务的有关细节。
信噪比(Signal to Noise Ratio)
信噪比又称为讯噪比,英文全称是(the Signal to Noise ratio),通常以S/N表示。一般检测此项指标以重放信号的额定输出功率(S)与无信号输入时系统噪声输出功率(N)的对数比值分贝(dB)来表示。
信噪比,即SNR(Signal to Noise Ratio)又称为讯噪比,即放大器的输出信号的电压与同时输出的噪声电压的比,常常用分贝数表示。设备的信噪比越高表明它产生的杂音越少。一般来说,信噪比越大,说明混在信号里的噪声越小,声音回放的音质量越高,否则相反。信噪比一般不应该低于 70dB,高保真音箱的信噪比应达到110dB以上。
分贝(decibel,缩写 dB)
A unit used to express relative difference in power or intensity, usually between two acoustic or electric signals, equal to ten times the common logarithm of the ratio of the two levels.
分贝:通常表示两个声音信号或电力信号在功率或强度方面的相对差别的单位,相当于两个水平的比率的常用对数的十倍(10 log10S/N)。
射频(RF)
=Radio Frequency 射频, 无线电频率
表示可以辐射到空间的电磁频率,频率范围从10KHz~30GHz之间。
射频是指发射频率,因为有些信号本身可能不太适合直接发射出去(频率非法,或信号本身条件不允许)。所以要将信号调制,调制器本身需要一个适合的震荡信号,将原信号加在上面,这个震荡信号叫载波,调制后的载波就包含了原信号的信息,发射出去就叫电波。所以,射频信号就是经过调制的,拥有一定发射频率的电波。
无线电频率,声音频率与红上频率之间的电磁波频率,可用于无线电和电视发射中。
无线电频率范围
A frequency in the range within which radio waves may be transmitted, from about 10 kilocycles per second to about 300,000 megacycles per second. The radio frequency groups are: very low frequency (vlf), 10 to 30 kilohertz; low frequency (lf), 30 to 300 kilohertz; medium frequency (mf), 300 to 3,000 kilohertz; high frequency (hf), 3,000 to 30,000 kilohertz; very high frequency (vhf), 30 to 300 megahertz; ultrahigh frequency (uhf), 300 to 3,000 megahertz; superhigh frequency (shf), 3,000 to 30,000 megahertz; extremely high frequency (ehf), 30,000 to 300,000 megahertz.
无线电频率范围:无线电波可以被传送的频率范围,从约每秒10千周至约每秒300,000兆周。射频分类为:甚低频(vlf),10至30千赫;低频(lf),30至300千赫;中频(mf),300至3,000千赫;高频(hf),3,000至30,000千赫;甚高频(vhf),30至300兆赫;很高频(vhf),300至3,000兆赫;特高频(shf),3,000至30,000兆赫;超高频(elf),30,000至300,000兆赫。
carrier wave (载波)
n.(名词)
An electromagnetic wave that can be modulated, as in frequency, amplitude, or phase, to transmit speech, music, images, or other signals.
载波:一种如可在频率、调幅或相位方面被调制以传输语言、音乐、图象或其它信号的电磁波。
Synchronization (同步) 与asynchronization (异步)
synchronous【修】同步
1. The process of adjusting the corresponding significant instants of two signals to obtain the desired phase relationship between these instants.
调整两个信号相应的有效瞬间,以使它们之间满足所需相位关系的过程。
2. The processof maintaining common timing and coordination between two or more operations, events or processes.
使两个或多个操作、事件或过程之间维持共同时基和协调一致的过程。
asynchronous【修】异步的
1. Without regular time relationship;unexpected or unpredictable with respect to the execution of a program's instructions.
没有规则的时间关系,对程序指令的执行是无法预料或不可预测的。
2. Having a variable time interval between successive bits, characters or events. In data transmission, this is limited to a variable time interval between characters, and is often known as start-stop transmission.
在时间上相邻的两位、两个字符或两个事件间的时间间隔是不规则的。在数据转输中,仅 指相邻字符间的时间间隔不规则。这种传输方式通常称起止式传输。
同步传输和异步传输的含义是什么?
按传输的数据单元与数据单元之间的时间间隔是固定的还是可变的划分。
所谓异步传输是指字符与字符(一个字符结束到下一个字符开始)之间的时间间隔是可变的,并不需要严格地限制它们的时间关系。
所谓同步传输是指数据块与数据块之间的时间间隔是固定的,必须严格地规定它们的时间关系。
1.异步传输
通常,异步传输是以字符为传输单位,每个字符都要附加 1 位起始位和 1 位停止位,以标记一个字符的开始和结束,并以此实现数据传输同步。所谓异步传输是指字符与字符(一个字符结束到下一个字符开始)之间的时间间隔是可变的,并不需要严格地限制它们的时间关系。起始位对应于二进制值 0,以低电平表示,占用 1 位宽度。停止位对应于二进制值 1,以高电平表示,占用 1~2 位宽度。一个字符占用 5~8位,具体取决于数据所采用的字符集。例如,电报码字符为 5 位、ASCII码字符为 7 位、汉字码则为8 位。此外,还要附加 1 位奇偶校验位,可以选择奇校验或偶校验方式对该字符实施简单的差错控制。发送端与接收端除了采用相同的数据格式(字符的位数、停止位的位数、有无校验位及校验方式等)外,还应当采用相同的传输速率。典型的速率有:9 600 b/s、19.2kb/s、56kb/s等。
异步传输又称为起止式异步通信方式,其优点是简单、可靠,适用于面向字符的、低速的异步通信场合。例如,计算机与Modem之间的通信就是采用这种方式。它的缺点是通信开销大,每传输一个字符都要额外附加2~3位,通信效率比较低。例如,在使用Modem上网时,普遍感觉速度很慢,除了传输速率低之外,与通信开销大、通信效率低也密切相关。
2. 同步传输
通常,同步传输是以数据块为传输单位。每个数据块的头部和尾部都要附加一个特殊的字符或比特序列,标记一个数据块的开始和结束,一般还要附加一个校验序列(如16位或32位CRC校验码),以便对数据块进行差错控制。所谓同步传输是指数据块与数据块之间的时间间隔是固定的,必须严格地规定它们的时间关系。
时分多路复用技术分成同步和异步两种。
STDM(同步时分多路复用器)把多路器轮转一周的时间,分成若干时间片(time slice)。所有终端都分别对应一个固定的时间片,分时共享一条传输线。其缺点是以静态方式把信道分配给每个终端,即使某终端并无信息发送。
ATDM(异步时分多路复用器)有选择地分配时间片,根据终端有无信息发送,信息量大小和优先级别动态分配时间片(这就是为什么ATM有带宽按需分配的优点),当终端有信息发送并申请到时间片时,终端以极高频率周期性地插入53byte的ATM信元,直至数据发送完毕或时间片到。所发送的ATM信所发送的ATM信元根据标记(VPI,VCI)沿不同路径或相同路径路由到目的地址。ATM的核心技术是异步时分多路复用。
ATM(异步传输模式)技术中“异步”的含义,可随时插入ATM信元。
ATM采用异步时分复方式(即统计复用),将来自不同信息源的信元汇集到一起,在缓冲器内排队,队列中的信元根据到达的先后按优先等级逐个输出到传输线路上,形成首尾相接的信元流。具有同样标志的信元在传输线上并不对应着某个固定的时隙,也不是按周期出现的。异步时分复用使ATM具有很大的灵活性,任何业务都按实际信息量来占用资源,使网络资源得到最大限度的利用。此外,不论业务源的性质有多么不同(如速率高低、突发性大小、质量和实时性要求如何),网络都按同样的模式来处理,真正做到完全的业务综合。 ATM是异步转移模式的英文缩写。ITU对ATM的定义是:ATM是一种传输模式。在这种传输(转移)模式中,信息被组织成“信元”,来自某用户信息的各个信元不需要周期性地出现。
对于软件上,同步是指一个进程/线程执行一个操作后,等待另一个进程/线程的动作后在继续,如同两个进程按一定规则,你等等我我等等你一起走;异步是说一个进程作了一个操作后,不用等待另一进程的结果就继续向下进行,两个进程的事件上没有同步的关系。 所以socket同步传送,程序返回就知道传完了,异步送和收的动作可能相差很久,需要队列、缓冲区等方式先将数据保留。
Socket编程中,采用同步控制方法,优点: 结构清晰,编程简单,执行一个通讯过程相当于执行一个函数调用,简单易用。通常采用有限等待方式。即:发送一个数据后,一直等待对方回应,直到超时为止。 缺点:在这断时间里,该线程处于阻塞状态,界面失去响应。 采用异步控制方法,优点: 程序效率很高。 缺点:结构不清晰,编程相对复杂,一般需要自已处理发送队列,收到回应后,需要查询发送队列,将处理结果通知发送者(可以采用回调函数方式)。
ODBC2.0访问数据库时,有同步执行模式与异步执行模式之分。
所谓同步执行模式,是指语句在同步执行模式下,将始终保持对程序流的控制,直至程序结束。例如查询操作,客户机上的应用程序在向服务器发出查询操作的指令后,将一直等待服务器将查询结果返回客户机端后,才继续进行下一步操作。
所谓异步执行模式,是指语句在异步执行模式下,各语句执行结束的顺序与语句执行开始的顺序并不一定相同。例如查询操作,客户机上的应用程序在向服务器发出了查询操作的指令后,将立刻执行查询语句的下一条语句,而不需要等到服务器将查询结果返回客户机端后,才继续进行下一步操作。
占位符(placeholder)
顾名思义,占位符(placeholder)就是先占住一个固定的位置,等着用实际添加的内容替换它。
出于安全的原因,用于屏蔽或隐藏另一个字符的字符。例如,当用户键入密码时,在屏幕上会用星号替代每一个被键入的字符。
接口(interface)和端口(port)
Interface 接口
- A device or equipment making possible interoperation between two systems, for example, a hardware component or a common storage register. 能够使两个系统之间相互运行的一种设备或装置。例如一种硬件部件或一种公共的 存储寄存器。
2. A shared logical boundary between two software components. An interactive development tool, for example, is a user friendly interface between a system software and an application software. 两种软件之间的一种共享逻辑界面。例如,一个交互开发工具是系统软件和应用软件之间的友好接口。
Port 端口
An interface by which data enters or leaves a functional unit. 数据进出某功能部件的一种接口。
在软件中,端口是一个软件标识,被客户程序或服务进程用来发送和接收信息。一个端口对应一个16比特的数。在建立与特定的主机或服务的连接时用到。服务进程通常使用一个固定的端口,例如,SMTP使用25。
在讲计算机组成原理时,接口指用来连接设备的控制电路,又称为“接口电路”比如说I/O接口。端口是用于存放数据、控制、状态信息的寄存器。可以由CPU的IN或OUT指令来读写的寄存器。
从硬件的层面,端口就是计算机上的物理接口,用于接插其他设备。计算机硬件常见的接口你都可以在机箱背后看到,包括键盘鼠标的圆口SP2接口,打印机的LPT接口(也叫并行接口),还有搂主说的COM接口(串行接口,过去也用来接鼠标,现在个人电脑上用处不大,但是在银行和商场的电脑上广泛用到,通常都用来接一些输入输出设备,比如条码扫描仪等),此外还有音频接口,网卡接口(RJ45口),显示器接口,1394接口,当然还有搂主问的USB接口。USB本质上和COM,LPT一样都是输入输出的接口,但是它提供更高的传输带宽,和更好的扩展性,所以现在基本上大部分外设都是通过USB与计算机联接。
从软件的层面上,也有端口这个概念。软件的端口是各个软件之间进行数据交换用的,比如WINDOWS就预留了很多端口供不同的软件调用。网络通讯中,面向连接服务和无连接服务的通信协议端口,是一种抽 象的软件结构,包括一些数据结构和I/O(基本输入输出)缓冲区,端口是一个整数,代表着不同服务和应用,或者说用来区分某种类型的应用。
因特网上最流行的协议是TCP/IP协议,TCP/IP体系结构是分层的。需要说明的是,TCP/IP协议在网络接口层是无连接的(数据包只管往网上发,如何传输和到达以及是否到达由网络设备来管理)。端口是应用层和运输层的接口。应用程序要调用相应的服务,就要使用特定的端口,端口号为16位。一旦谈“端口”,就已经到了传输层。协议里面低于1024的端口都有确切的定义,它们对应着因特网上常见的一些服务。这些常见的服务可以划分为使用TCP端口(面向连接如打电话)和使用UDP端口(无连接如写信)两种。
使用TCP端口常见的有:
ftp:定义了文件传输协议,使用21端口。常说某某主机开了 ftp服务便是文件传输服务。下载文件,上传主页,都要用到ftp服务。
telnet:你上BBS吗?以前的BBS是纯字符界面的,支持BBS的服务器将23端口打开,对外提供服务。其实Telnet的真正意思是远程登陆:用户可以以自己的身份远程连接到主机上。
smtp:定义了简单邮件传送协议。现在很多邮件服务器都用的是这个协议,用于发送邮件。服务器开放的是25端口。
http:这可是大家用得最多的协议了——超文本传送协议。上网浏览网页就需要用到它,那么提供网页资源的主机就得打开其80端口以提供服务。我们常说“提供www服务”、“Web服务器”就是这个意思。
pop3:和smtp对应,pop3用于接收邮件。通常情况下,pop3协议所用的是110端口。在263等免费邮箱中,几乎都有pop3收信功能。也就是说,只要你有相应的使用pop3协议的程序(例如Foxmail或Outlook),不需要从Web方式登陆进邮箱界面,即可以收信。
使用UDP端口常见的有:
DNS:域名解析服务。因特网上的每一台计算机都有一个网络地址与之对应,这个地址就是我们常说的IP地址,它以纯数字的形式表示。然而这却不便记忆,于是出现了域名。访问主机的时候只需要知道域名,域名和IP地址之间的变换由DNS服务器来完成。DNS用的是53端口。
snmp:简单网络管理协议,使用161端口,是用来管理网络设备的。由于网络设备很多,无连接的服务就体现出其优势。
聊天软件Oicq:Oicq的程序既接受服务,又提供服务,这样两个聊天的人才是平等的。oicq用的是无连接的协议,其服务器使用8000端口,侦听是否有信息到来;客户端使用4000端口,向外发送信息。如果上述两个端口正在使用(有很多人同时和几个好友聊天),就顺序往上加。
透明的(transparent)
Pertaining to a process, or procedure, invoked by a user without the latter being aware of its existence.
用于修饰或说明一种进程或过程,它允许用户调用它,而用户并不用知道它的存在。
日常生活中常说,“处理事情不要有暗箱操作,整个处理流程要公开透明”,这里这个“透明”的含义是: 对相关人员要完全公开。透明,指光线能够通过的,比如玻璃、清水等等。到了近代科学中,为了解释比较抽象的科技概念,将这个词做了一些引申,指从使用者角度来看可以忽略的事物,这些事务多数是一些逻辑概念上的通讯协议。比如,TCP/IP 协议在我们访问一个网站时就可以看成是透明的,GSM/CDMA 协议在我们使用手机时可以看成时透明的,有线电视协议在我们看电视时可以看成是透明的……这样,我们就比较容易理解透明了。
计算机中提到的“透明”的含义是: 对用户而言,这个处理过程是感觉不到的,不可见的、隐藏的。计算机书籍中其含义正好和日常生活中的相左。
Heap (堆)和stack ([堆]栈)
堆(heap)和栈(stack)是不同的,内存中堆和栈的含义和数据结构中的堆和栈含义也不同。
在数据结构这门学科中,堆是一种特殊的树形数据结构,通常是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。栈实际上就是满足先进后出的性质的数据结构。
在编程编程语言中,把内存划分成两种:一种是堆(heap)内存,一种是栈(stack)内存,两者在使用上是有区别的。
stack [堆]栈
Generally, a block of successive memory locations that are accessible from one end of a lastin/firstout(LIFO) basis. The stack is coordinated with a stack pointer that keeps track of storage and retrieval of each byte or word of information in the stack. A stack may be any block of successive information locations in a read/write memory. 通常情况下,一种连续的存储单元区,从一端按后进先出的原则可对这些单元进行存取。栈和一个栈指针配合工作,栈指针随时指示要存取的每个字或字节信息在栈中的位置。栈可以是读写存储器 中任意的地址连续的存储单元块。
在数据结构这门学科中,指两种数据结构堆(heap)和栈(stack,[堆]栈):
堆(heap),一种数据结构,是一种经过排序的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。由于堆的这个特性,常用来实现优先队列,并用于一些图论算法中。
[堆]栈(stack),一种特殊的数据结构,只允许在一端进行操作,按照后进先出(LIFO, Last In First Out)的原理操作。栈使用两种基本操作:推入(push)加入数据和弹出(pop)输出数据,
在程序语言【C/C++】中:
一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap)— 由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)— 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。
4、文字常量区 — 常量字符串就是放在这里的,程序结束后由系统释放 。
5、程序代码区 — 存放函数体的二进制代码。
stack ([堆]栈):
由系统自动分配,由编译器自动分配释放。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap (堆):
由程序员分配释放,需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
在程序语言【Java】中:
在Java里 Heap和Stack分别存储数据的不同:
Heap(堆) Stack(栈)
JVM中的功能 内存数据区 内存指令区
存储数据 对象实例(1) 基本数据类型,指令代码,
常量,对象的引用地址(2)
Java 的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量(int, short, long, byte, float, double, boolean, char)和对象句柄。
可见,垃圾回收GC是针对堆Heap的,而栈因为本身是FILO - first in, last out. 先进后出,能够自动释放。 这样就能明白到new创建的,都是放到堆Heap!
Rights 、permissions 、Privileges
privilege(权限,特权);permissions(权限,许可);Right(权限,权利)。在计算机文档中,当用来描述控制资源访问时,有时都译为“权限”,其含义近似,通常不刻意区分,但它们还是有差别的,如:
Microsoft(微软)操作系统中,权利Rights(用户权利User Rights):适用于系统级的策略任务,是整体性(系统级别)的定义,如关闭计算机系统,添加设备、数据备份和恢复等。通常权利存放在SAM数据库中。权限permissions(访问权限Access permissions):适合于具体的对象。它用来规定什么用户以何种方式访问对象,通常与资源一起存放。如授权用户对目录、文件、打印机的访问权限等。
在Windows操作系统中,权限和权利代表不同的内容。权限(Permission)代表一个用户对文件、文件夹、打印机等系统资源的访问能力;而权利(Right)代表用户对系统进行设置的能力。
有两种类型的用户权利:特权,如备份文件和目录的权利、是否允许用户安装或加载驱动程序等;另一种是登录权利,如登录到本地系统的权利、从网络访问计算机等。
权限还可分为文件夹共享权限和文件/文件访问权限
共享权限仅应用于通过网络访问资源的用户,不会应用到在本地登录的用户。本地登录的用户的访问权限,可在NTFS上使用访问控制来设置权限(NTFS文件系统上的文件/文件访问权限),不过在FAT和FAT32格式上的文件就不具有这种配置功能了。而且所设置的共享权限将应用于共享资源中所有的文件和文件夹。
共享权限的配置是保护FAT和FAT32卷上的网络资源的惟一方法,因为NTFS权限在 FAT或FAT32卷上不可用。但它可指定允许通过网络访问共享资源的最大用户数目,这是 NTFS中的文件/文件夹访问权限所没有的。
Control (控件)和Component (组件)
一般把Control翻译成控件,把Component翻译成组件或构件。
控件就是具有用户界面的组件。如按钮、列表框、编辑框。
在软件行话中,组件这个术语指任何可复用的对象或任何可与其它对象交互的代码体。组件不需要显示任何信息或用户界面。组件可能实现科学计算,收集性能数据。
Delphi的书中更习惯使用Component,而VB、VC的书中习惯于使用Control这个词。
VB中,部件(Component)一般是指控件(Control),一般是ocx文件。其实就是VB其它的控件,使用OCX前需要先注册控件。控件(Control)是由控件部件(control component),即 .ocx 文件提供的对象。一个控件部件(.ocx 文件)可以提供多种类型的控件。控件实例不能单独存在。它必须放在一个容器对象上,例如 Visual Basic 窗体。把控件实例挂接到容器上的过程叫做定位。
Adding a Component to a Visual Basic Project ?
1.On the Project menu, click Components.
2.Click to select the check box next to the component you want to add. If the component is not listed, locate the .dll or .ocx file using Browse.
3.Click OK.
在vs.net中创建用户控件和组件有什么区别?
用户控件继承自:System.Windows.Forms.UserControl
组件继承自:System.ComponentModel.Component
前者是“可视化继承”,后者更灵活。
attribute 和property
很多文献(包括Windows简体中文版操作系统)都将这个两个词不加区分地翻译为“属性”。 这样不妥当。
这两个词的混淆由来已久。混淆的主要原因就是大多数中文译本里既把Attribute译为“属性”,也把Property译为“属性”。其实,这两个词所表达的不是一个层面上的东西。
Property属于面向对象理论范畴。在使用面向对象思想编程的时候,我们常常需要对客观事物进行抽象,再把抽象出来的结果封装成类,类中用来表示事物状态的成员就是Property。比如我要写一个模拟赛车的游戏,那么必不可少的就是对现实汽车的抽象。现实中的汽车身上会带有很多数据,但在游戏中我可能只关心它的长度、宽度、高度、重量、速度等有限的几个数据,同时,我还会把汽车“加速”、“减速”等一些行为也提取出来并用算法模拟——这个过程就是抽象(结果是Car这个类)。显然,Car.Length、Car.Height、Car.Speed等表达的是汽车当前处在一个什么状态,而Car.Accelerate()、Car.Break()表达的是汽车能做什么。因此,Car.Length、Car.Height、Car.Speed就是Property的典型代表,将Property译为“属性”也很贴切。总结一句话就是:Property(属性)是针对对象而言的。
Attribute则是编程语言文法层面的东西。比如我有两个同类的语法元素A和B,为了表示A与B不完全相同或者A与B在用法上有些区别,这时候我就要针对A和B加一些Attribute了。也就是说,Attribute只于语言层面上的东西相关——与抽象出来的对象没什么关系。因为Attribute是为了表示“区分”的,所以我喜欢把它译为“特征”。C#中的Attribute就是这种应用的典型例子——我们可以为一个类添加Attribute,这个类的类成员中有很多Property——显然Attribute只是用来影响类在程序中的用法而Property则对应着抽象对象身上的性状,它们根本不是一个层面上的东西。
习惯上,英文中把标签式语言中表示一个标签特征的“名称-值”对称为Attribute。如果恰好我们又是用一种标签语言在进行面向对象编程,这时候两个概念就有可能混淆在一起了。实际上,使用能够进行面向对象编程的标签式语言只是把标签与对象做了一个映射,同时把标签的Attribute与对象的Property也做了一个映射——针对标签,我们还是叫Attribute,针对对象,我们还是叫Property,仍然不是一个层面上的东西。而且,标签的Attribute与对象的Property也不是完全映射的,往往是一个标签所具有的Attribute多于它所代表的对象的Property。
因为XAML是用来在UI上绘制控件的,而控件本身就是面向对象抽象的产物,所以XAML标签的Attribute里有就一大部分是与控件对象的Property互相对应的。当然,这还意味着XAML标签还有一些属性并不对应控件对象的Property。
美国传统词典(双解)解释:
property--A characteristic attribute possessed by all members of a class. 固有的属性被某类物质的全体成员所拥有的特色。
attribute--A quality or characteristic inherent in or ascribed to someone or something." 品质、属性、特征内在的属性或特征,或归结为某人某物的属性或特征"
就是说,property指“全体”的特性,而attribute指“个体” 的特征。描述控件对象的特性一般用property。
A property is a typed element that represents an attribute of a class.
property是一个有类型的元素(typed element),它代表了一个类中的一个属性(Attribute)。
在Microsoft(微软)操作系统中定义如下:
attribute
用于文件,指出文件是否为只读、隐藏、准备存档(备份)、压缩或加密,以及是否应索引文件内容以便加速文件搜索的信息。
在 Active Directory 中,是指对象地特征和对象可以包含的信息类型。对于每个对象类别,该架构定义一个类别实例必须具有什么属性以及该类别实例可能具有哪些其他属性。
Property,Properties
对象或设备类别的特征或参数。例如,Microsoft Word 文件的属性,包括“大小”、“创建时间”和“字符数”。
关系表中属性( Attribute):关系表中的一个列称为关系 的一个属性,即元组的一个数据项。属性有属性名、属性类型、属性值域和属性值之分。属性名在表中是唯一的。
是Attribute,还是Property?有时是个麻烦。
Attribute和Property都可以翻译成“属性”,有的地方用Attribute表示“属性”,有的地方又在用Property,初学者常常在这两个单词间“迷失”,甚至认为二者没有区别,是一样的。可是Attribute不等于Property。二者之间到底有何区别?
我们从OOA/OOD(Object Oriented Analysis / Object Oriented Design,面向对象分析与设计)说起。在OOA/OOD中的使用Attribute表示属性,指对象(Object)的特征(Feature)。我们在一些编程语言(如C#、Delhpi等)中遇到的“属性”一词,为何是Property,而不是Attribute呢?
为了理解这一点,我们把C++拽进来看看。OOA/OOD中的Attribute在C++中称为Member Variable(成员变量),慢慢开始明白了吧。C++中的Member Variable在C#中可以继续延用,但有了一个新的称呼:Field(字段)。看一个简单的C#示例:
public class Student { // Student类
private string name; // C#和Java中称为Field(字段),C++中称为Member Variable(成员变量),OOA/OOD中称为Attribute(属性)
}
我们整理出下表,可以看到同样的概念在OOA/OOD、C++和C#中的不同称呼:
| Description | OOA/OOD | C++ | .NET(C#) /Delphi |
| Feature | Attribute | Member Variable | Field |
更全面的表:
| Description | OOA/OOD | C++ | Java/C# | python | JavaScript | PHP |
| Feature(特征) 【刻画或描述Object的特征 / Class中的变量、常量】 | Attribute | Member Variable /data member | Field | data attribute /variable | Property / field | Property |
| Operation(操作) 【Object提供的服务或操作 / Class中的函数】 | Method | Member Function | Method | Method | Method | Method |
【在面向对象编程语言中,通常可以将 attribute 翻译为“属性”,而将 property 翻译为“属性”或者“特性”,具体取决于上下文和语境。在 Web 开发中,attribute 通常指 HTML 元素的属性,而 property 则更多指 DOM 元素的属性。在 JavaScript 中,将 Property 译为属性、attribute 译为特性是比较常见的做法。
编程语言中的Class、Object、Property、attribute、field、Method、Event https://blog.csdn.net/cnds123/article/details/106031884】
C++中将Attribute称为Member Variable,将Method称为Member Function,其实还是很贴切的。从本质上说,确实是在声明变量、定义函数。后来者(C#等)可能觉得这样的称呼不够OO(Object Oriented,面向对象),于是做了些改变。Method延用OOA/OOD的称呼不用说,但将Attribute称作Field,总觉得欠妥。因为DB(Database,数据库)中有Field的概念,也译作“字段”,实在是容易混淆。
现在我们可以把OOA/OOD中提到的属性(Attribute)同C#中提到的属性(Property)区分开来。继续上面的示例:
public class Student { // Student类
private string name; // C#中称为Field(字段),C++中称为Member Variable(成员变量),OOA/OOD中称为Attribute(属性)
public string Name { // C#中称为Property(属性)
get {
return name;
}
set {
name = value;
}
}
}
我们顺便看看private和public:Property本质上是一对get/set方法,可以进行访问控制,因而可以设置为public;而按照OOA/OOD原则,Attribute不能设为public,而要设为private。
C#中确实也有Attribute,把它译作“特性”似乎更好些,在不少的.NET/C#书籍中看到有把Attribute译成“属性”的,这样一来,老鸟倒是可以通过语境判断出来不是在说Property,初学者恐怕一下子就跌进云里雾里了。
在Web编程中也常见到Attribute和Property混用的情况。html的attribute、css的Property和JavaScript的Property,许多资料中都翻译为“属性”。
用VS创建一个ASP.NET应用程序,如果在代码视图添加控件:
<asp:TextBox id=”txtName” text=”Hello” runat=”server” />
此时TextBox控件中的id、text和runat都称为Attribute,这是延用了HTML中对属性(Attribute)的称呼。
如果是在设计视图中拖放控件,然后在属性(Properties)窗口中设置ID或Text,此时又会将ID或Text称为Property。因为控件在服务器上是作为控件类(Control Class)实现,使得可以用编程的方式来访问控件。那么属性必然是Class中的Property。
document和file
这两个词,大陆和港台地区翻译正好相反:
file 文件(大陆) 档案/档(港台)
document 文档(大陆) 文件(港台)
document 文档;文档,经过整理、分类、归档的书面性文件,正式的文书。侧重于公文, 文献。
1)A medium and the information recorded on it that generally has permanence and that can be read by man or machine.
一种数据媒体和记录在媒体上的信息的集合体,通常可以永久保存并可供人或机器所阅读。
2)文件的另一种称呼,一般将WORD,EXCEL等文字编辑软件产生的文件叫做文档。
File 文件;file 是文件,档案(包括书面文件和其它格式的文件.)
1)一个完整的、有名称的信息集合(数据集合)。
2)A named set of records stored or processed as a unit.
一种经过命名可作为一个单位进行存储或处理的若干记录的集合。
3)以名称在计算机上存储的信息集合。文件通常具有三/四个字母的文件扩展名,用于指示文件类型。
File 要比Document 涵盖的范围大。只有在实际语境里才具有清晰的意义:
You cannot save a document with the same name as another open document. Try saving with a different file name.
不能将文件保存为与其他打开的文档同名的文件。请用其他文件名保存。
在Microsoft(微软)操作系统中定义如下:
Document文档
任何自包含的工作都是由应用程序创建的,并且(如果保存在磁盘上)给予可以检索的唯一的文件名。
电脑中文件和文档区别
文件是一个完整的、有名称的信息集合。例如,程序、程序所使用的一组数据或用户创建的文档。文件是基本存储单位,它使计算机能够区分不同的信息组。文件是数据集合,用户可以对这些数据进行检索、更改、删除、保存或发送到一个输出设备(例如,打印机或电子邮件程序)。电脑中文件的定义就很宽泛,凡是存储数据的基本上都可以称为文件,电脑中的文件可以是文档、程序、快捷方式和设备。
文档是用来存储文字、数据格式的资料,可以赋予文件名保存在磁盘。一般指由文字处理软件产生的文件,如文本文档(.TXT),写字板文档(.rtf),WORD文档(.DOC)。
Catalog 、Directory、contents和folder
Catalog 、Directory这两个词在一般英汉词典中都有“目录”义项,但汉语“目录”有“书刊上列出的篇章名目(多放在正文前)”这一含义,其对应的英语词却是contents。
directory是指电话簿,商行名录,人名地址录。
catalog是指图书馆卡片式检索目录,商品等的目录(一览表)。
A list or itemized display, as of titles, course offerings, or articles for exhibition or sale, usually including descriptive information or illustrations
一览表:名单或逐条列记的陈列,如题目、课程或者供展览或出售的物品,通常包括描述性的信息或插图。
card catalog 图书馆里的卡片目录(等于card catalogue)。
在计算机科学中,有下列含义:
Catalog 编录;分类;目录
用于“索引服务”,所有索引信息的集合,并存储用于文件系统目录的特殊组的属性。
DBMS编目(DBMS catalog),也有人称为数据字典(data dictionary)或系统目录(system catalog)
数据库系统中不仅包含数据库本身,还包含数据结构和约束的完整定义或描述。这个定义存储在DBMS编目(DBMS catalog)中,其中包含诸如每个文件的结构、每个数据项的类型和存储格式以及数据的各种约束等信息。存储在此编目中的信息我们称之为元数据(meta-data),元数据描述数据库的结构(描述数据库数据的组织方式,比如一个数据库、表的创建者信息、创建时间信息、所属表空间信息、用户访问权限信息,表的记录总数、列名及其类型等信息)。
作为分析阶段的工具,数据字典(Data Dictionary)是关于数据的信息的集合,也就是对数据流图中包含的所有元素的定义的集合,数据字典通常包括四类条目:数据流、数据项、数据存储、基本加工。数据项是组成数据流和数据存储的最小元素。
Directory 目录,索引簿
- 存储在磁盘上的文件名及其它目录的索引,是存储装置中文件的组织结构,也称为文件夹(folder)。
- 由相应数据项的标识符和说明构成的一种表或由控制程序使用的一种索引。
folder 文件夹
用于图形用户界面中的程序和文件的容器,在屏幕上由一个文件文件夹的图形图像(图标)表示。文件夹是在磁盘上组织程序和文档的一种手段,并且既可包含文件,也可包含其他文件夹。
目录其实是DOS时代的说法,在WINDOWS下应当称为文件夹。文件夹是目录的形象化说法。
一个目录中还可以包含有目录,前者就是父目录,后者就是子目录了!
根目录指每个分区(或光盘、软盘)的最上一级目录,它的特点是它没有父目录了。
backup、copy和replication、replica
backup n.替代物; 备用品。
copy n.复制本, 副本;vt. & vi. 复制; 抄写。
replication n.复制。
Replica n.复制品, 副本。
Backup 备份;[后备品]
1. Pertaining to a system, device, file, or facility that can be used in the event of a malfunction or loss of data.
作为形容词用来修饰系统、装置、文件或设备,表示在发生故障或数据丢失时可替代使用。
2. 存储在非易失性存储介质上的数据集合,这些数据用来进行原始数据丢失或者不可访问条件下的数据恢复。为了保证恢复时备份的可用性,备份必须一致性状态下通过拷贝原始数据来实现。
copy复制,拷贝
1.To read data from a source, leaving the source data unchanged, and to write the same data elsewhere in a physical form that may differ from that of the source, e.g., to copy a deck of punched cards onto a magnetic tape. The degree of editing that may be carried out at the same time depends upon the circumstances in which the copying is performed.
从数据源中读出数据,源数据保持不变,然后将该数据以某一种物理形式写到另一处。该物理 形式和源数据的形式可以不同。例如,将一组穿孔卡片的数据复制到磁带上。复制的同时可 以进行编辑,其程度取决于实现复制的环境。
2.In word processing, the reproduction of selected recorded text from storage or from a recording medium to another recording medium. 在字(词)处理技术中,从存储器或从某一记录媒体把选定的记录文本复制到另一记录媒体上。
3. 也称拷贝,指将文件从一处拷贝一份完全一样的到另一处,而原来的一份依然保留。
Replication [同步]复制
1.将数据从数据存储区或文件系统复制到多个计算机来同步数据的过程。Active Directory 在给定域的域控制器之间提供目录多主机复制。每个域控制器上目录的副本都是可写的。这就允许对给定域的任意副本进行更新。该复制服务会将这些变化自动从给定的副本(Replica)复制到其他副本。
2.在数据库中Replication,指保证两个数据库的完全同步的过程。用于分布式数据库。将数据和数据库对象从一个数据库复制和分发到另一个数据库,然后在数据库间进行同步,以维持一致性。
3. 复制是将一组数据通过网络从一个数据源拷贝到多个数据源的技术。 使数据分布式的存放多个数据备份。也称为同步复制,使数据库两个或更多副本可以交换数据或被复制对象的更新的过程。
replica 副本
由同步复制(Synchronous Replication)产生的,属于一个副本集并且可与该集合中其他副本同步的一个数据库副本。在一个副本中对复制的表的数据所做的更改会发送并应用到其他副本。
注意,英文replica 和copy都有“复制品”的含义,许多文档将它们都翻译为副本,作为术语是有差别的,备份(backup)的数据库副本(copy)与复制(同步复制 replication)的数据库副本(复本 replica)含义不同,前者形成相互独立的副本(copy),后者形成相关联的副本(复本 replica),副本之间可以同步。replica 有相同的标识符(ID),Copy会有不同的标识符,要进行复制(Replication),必须要有相同的标识符,即Replica ID相同的数据库才能进行复制。
在分布处理等环境下,要将数据的复制品置于异地的服务器上,并使其处于可用状态。这种过程一般称为 Replication 。为了防止出现故障而进行的数据复制称为备份( Backup)而不是 Replication 。
point-to-point和end-to-end
End-to-End 简单字面解释为 “端对端”。
Point-to-Point 简单字面解释为 “点对点”。
End-to-End、Point-to-Point、Peer-to-Peer、Host-to-Host
如果要翻译成中文, 可能会相同或类似, 重点应该从他要表达的意义去了解:
End 有末端, 最底层的意思, 例如 End User, End-to-End 是指最末端的两者间。
Point-to-Point 翻译成 "点对点" , 但 Point 则是指某个点, 可以看成网络上任一个装置 (Server, Client , PC, Gateway ....)。
Peer-to-Peer 翻译成 "对等" , 但 Peer 有身份对等的意思, 像 Client/Server 是主从式架构, 身分不对等。
Host 是主机, Host-to-Host 是主机对主机。TCP/IP中的主机对主机层(Host-to-Host Layer),又称传输层。
主机到主机层(Host-to-Host layer)功能类似OSI模型的传输(Transport)层,它定义了建立应用程序传输服务的协议。它处理问题例如建立可靠的端到端(end-to-end)的通信连接并保证无差错(error-free)的数据传送。它处理数据包的排序和维护数据的完整性。
P2P是peer-to-peer的缩写,peer在英语里有"(地位、能力等)同等者"、"同事"和"伙伴"等意义。P2P一种解释是peer-to-peer。而peer在英语里是“(地位、能力等)同等者”、“同事”和“伙伴”的意思。这样一来,P2P也就可以理解为"伙伴对伙伴"的意思,或称为对等联网。目前人们认为其在加强网络上人的交流、文件交换、分布计算等方面大有前途。而另一种解释是,P2P就是一种思想,有着改变整个互联网基础的潜能的思想。客观讲,单从技术角度而言,P2P并未激发出任何重大的创新,而更多的是改变了人们对因特网的理解与认识。正是由于这个原因,IBM早就宣称P2P不是一个技术概念,而是一个社会和经济现象。
点对点和端对端
点对点是针对网络中传输的两端设备间的关系而言的。点对点系统指的是发送端把数据传给与它直接相连的设备,这台设备在合适的时候又把数据传给与之直接相连的下一台设备,通过一台一台直接相连的设备,把数据传到接收端。
点对点传输的优点是发送端设备送出数据后,它的任务已经完成,不需要参与整个传输过程,这样不会浪费发送端设备的资源。另外,即使接收端设备关机或故障,点对点传输也可以采用存储转发技术进行缓冲。点对点传输的缺点是发送端发出数据后,不知道接收端能否收到或何时能收到数据。
端对端是针对网络中传输的两端设备间的关系而言的。端对端传输指的是在数据传输前,经过各种各样的交换设备,在两端设备问建立一条链路,就象它们是直接相连的一样,链路建立后,发送端就可以发送数据,直至数据发送完毕,接收端确认接收成功。
端对端传输的优点是链路建立后,发送端知道接收设备一定能收到,而且经过中间交换设备时不需要进行存储转发,因此传输延迟小。
端对端传输的缺点是直到接收端收到数据为止,发送端的设备一直要参与传输。如果整个传输的延迟很长,那么对发送端的设备造成很大的浪费。端对端传输的另.一个缺点是如果接收设备关机或故障,那么端对端传输不可能实现。
在一个网络系统的不同分层中,可能用到端对端传输,也可能用到点对点传输。如Internet网,IP及以下各层采用点对点传输,4层以上采用端对端传输。
路由器中IP软件利用路由表(保存在路由器中)决定数据报发送的下一站,要选择一条路径时,IP软件将目的地址(数据报携带的IP地址)的网络前缀(网络号部分)与路由表中的每一项比较来查到匹配项。
数据传输的可靠性是通过数据链路层和网络层的点对点和传输层的端对端保证的。点对点是基于MAC地址或者IP地址,是指一个设备发数据给另外一个设备,这些设备是指直连设备包括网卡,路由器,交换机。端对端是网络连接,应用程序之间的远程通信。端对端不需要知道底层是如何传输的,是一条逻辑链路。
端到端与点到点是针对网络中传输的两端设备间的关系而言的。端到端传输指的是在数据传输前,经过各种各样的交换设备,在两端设备问建立一条链路,就像它们是直接相连的一样,链路建立后,发送端就可以发送数据,直至数据发送完毕,接收端确认接收成功。点到点系统指的是发送端把数据传给与它直接相连的设备,这台设备在合适的时候又把数据传给与之直接相连的下一台设备,通过一台一台直接相连的设备,把数据传到接收端。端到端传输的优点是链路建立后,发送端知道接收设备一定能收到,而且经过中间交换设备时不需要进行存储转发,因此传输延迟小。端到端传输的缺点是直到接收端收到数据为止,发送端的设备一直要参与传输。如果整个传输的延迟很长,那么对发送端的设备造成很大的浪费。端到端传输的另.一个缺点是如果接收设备关机或故障,那么端到端传输不可能实现。点到点传输的优点是发送端设备送出数据后,它的任务已经完成,不需要参与整个传输过程,这样不会浪费发送端设备的资源。另外,即使接收端设备关机或故障,点到点传输也可以采用存储转发技术进行缓冲。点到点传输的缺点是发送端发出数据后,不知道接收端能否收到或何时能收到数据。在一个网络系统的不同分层中,可能用到端到端传输,也可能用到点到点传输。如Internet网,IP及以下各层采用点到点传输,IP层以上采用端到端传输。
P2PⅠ模式(Peer-to-Peer,伙伴对伙伴型)
P2PⅠ应区别于P2PⅡ模式(点对点),虽然P2PⅡ也保持了平等关系,但它缺乏“伙伴关系”的利益共赢。P2PⅠ依据B2B模式进一步理顺平行关系,在确立伙伴关系后所建立的系统对等。在现实中P2PⅠ的耦合松紧度不尽相同,需要内部决策系统参与协调,以策略性决策指令量度并区别内部的与外部的伙伴关系,分门别类地提供对伙伴的配送服务。而作为伙伴的一方,也需要密切配合,以支持系统与业务的统一目标。在内容集成平台的远程异地应用中,依据不同的运营平台和不同的销售策略,或是集成运营商建立异地伙伴的P2PⅠ配送机制,同时兼有内容批发或内容资产增值的附加作用。为保证P2PⅠ的持久性,还需要在信息的兼容性上有所预处理,建立版权保护的销售分帐结算体系,既防止版权流失,又保证传播效率和利益共享,持久维系B2B的内容配送与消费服务。
E2E模式(End-to-End,端到端型)与P2PⅡ模式(Point-to-Point,点对点型)
E2E与P2PⅡ是系统模式化的附属模式,虽然二者都是建立在业务系统中,既非单元制的一个设备,也非孤立存在的一个组件,但二者区别很明显,前者是针对某一个特定系统,存在于这个系统的始端到终端,而后者既存在一个系统中,也存在多个系统中,既可能指2个端点间,也可能指2个节点间,还可能指2个系统的接口间,并有混合出现的可能。例如,一个新媒体业务,就是一个E2E的F2F服务,而多个新媒体业务间相间模式的对象服务,就是P2PⅡ模式。由于多种业务和多型模式的存在,P2PⅡ表现形态要比E2E复杂得多,应用也要多得多,问题是跳出实体支路的特征,在业务流程上加以区分。比如新媒体的内容配送,就可能同时存在E2E与P2PⅡ模式,那么,若实现了业务的双向交互,E2E就是主型,若非双向交互业务,则P2PⅡ为主型。又如DMC的内容网是P2PⅡ型,而它的配送网却是E2E型。因此,需要在总体服务目标的指引下,理顺新媒体业务流程,在BPR规范下,有选择地由内向外应用E2E与P2PⅡ的2种模式。
passive和active
passive【修】无源的;被动的;
In electronics, pertaining to an equipment incapable of amplification or power generation.
在电子技术中,用来修饰或说明不能进行放大或产生能量的设备。
active【修】有源的;主动的
无源音箱(Passive Speaker)又称为“被动式音箱”。无源音箱即是我们通常采用的,内部不带功放电路的普通音箱。无源音箱虽不带放大器,但常常带有分频网络和阻抗补偿电路等。
有源音箱(Active Speaker)又称为“主动式音箱”。通常是指带有功率放大器的音箱,如多媒体电脑音箱、有源超低音箱,以及一些新型的家庭影院有源音箱等。有源音箱由于内置了功放电路,使用者不必考虑与放大器匹配的问题,同时也便于用较低电平的音频信号直接驱动。
主动元器件和被动元器件,单地讲就是需能(电)源的器件叫有源器件,无需能(电)源的器件就是无源器件。有源器件一般用来信号放大、变换等,无源器件用来进行信号传输,或者通过方向性进行“信号放大”。 容、阻、感都是无源器件,又叫被动元器件.无源器件不实施控制并不要求任何输入器件就可完成自身的功能----就是不智能。电阻、电容、电感、连接器等都是无源的。而有源器件能控制电压或电流,或在电路中创造转换的动作--它是智能的。二极管、三极管、IC、晶振、传感器都是有源的。又叫主动元器件。
有源HUB与无源HUB的区别就在于有源HUB能对信号放大或再生,这样它就延长了两台主机间的有效传输距离;无源HUB不对信号做任何的处理,对介质的传输距离没有扩展,并且对信号有一定的影响。连接在这种HUB上的每台计算机,都能收到来自同一HUB上所有其它电脑发出的信号。
Connection、link和 join
辨析:link (up) with,connect with 及 join (…to) 与 adjoin to、 link (up) with = connect with 与……相连接:通常“水域”相连用link (up) with,“车辆 (道路,交通)”相连用connect with、 join (…to) 指直接连接(两个以上的东西) adjoin to 与……毗邻 There the irrigation canal links up with the reservoir. 这条灌溉渠道在那儿与水库连接起来。The trolley bus connects here with a bus for the airfield. 这辆无轨电车在这儿衔接去机场的公共汽车。The new highway has joined our commune to the city. 这条新高速公路把我们的公社与城市连接起来了。The cotton field adjoins to the rice field. 棉田与稻田相接。
join vt. vi. 表示用(线,绳子,桥梁等)将两个或两个分离的事物或两点联结,联合。侧重把原来不相连接的物紧密地连接在一起,但仍可再分开。也指把分散的人或几个部分的人联合起来,或加入到某团体中去。He joined the two pieces of wood with a nail. 他用钉子将两块木版钉在一起。
connect: 指两事物在某一点上相连接,但彼此又保持独立。A railway connects Oxford and Reading. 牛津和瑞丁之间有一条铁路相连。 Mr. Y has been connected with this firm since 1950. Y先生从1950年起就一直在此公司做事。
link"链接"请注意,是"链"接,不是"连"接;link: 指连环式的连接,或用接合物或其它方式连接,还可指一事物与另一事物的联系或关系。The common interest between China and the U.S.A links the two nations. 中美间的共同利益将两国人民紧密相连。
ralate着重于"关联";relate: 指人与人有亲戚或婚烟关系;也指人或物之间尚存的实际或假想的联系。
attach着重与"附属与" ;attach: 指把局部连接在整体上,小的接在大的上面,活动的接在固定的上面。
unite"联合" ;unite: 指联合、团结、结合在一起,构成一个整体。
connection 连接
An association established between functional units for conveying information.
为传送信息在各功能单元之间建立起来的一种联系。
link链接;链路;
1. In computer programming, the part of a computer program, in some casesa single instruction or an address, which passes control and parameters between separate portions of the computer program.
计算机程序设计中,用于在程序的不同部分之间传递控制权和参数的程序部分,某些情况下,它是一条指令或一个地址。
2. In DECnet or SNA network, a communications path between two nodes.
在DECnet或SNA网络中,两个节点之间的一种通信路径。
join 联结,连[联]接
In relational databases, an operator in relational algebra.A join operation on two relations which share a common data item type produces a combined relation with attributes specified in the join operation.
在关系数据库中,关系代数用的一种运算符。对共享一个公共数据项类型的两种关系, 连接操作产生一种复合的关系,该关系具有连接操作中规定的属性。
连接(connection)表示的是一个客户端需要访问数据库实例时必须建立的一个通讯通道。
链接(link)是指两个数据库之间的访问,如果数据库A建立了到数据库B的链接,那么数据库A的用户就可以通过这个链接来访问数据库B。
在网页中,链接(link)指当我们把鼠标放到一个文字上的时候,能够变成小手,而且当我们点一下的时候,能够出现另外一个网页。
联接jion,结合(在一起),联系的比较紧密。 Full Jion(完全联接). 先按右联接比较字段值,再按左联接比较字段值。不列入重复记录.
链接link,重点是“链”,意即一环扣一环,是多点、多面的相互关联。
连接connection,主要用线连,形成通路。如宽带连接(Broadband Connection)
说明,join有人翻译为联接,有人翻译为连接,有人翻译为链接,本人倾向采用联接,在Access中一般译为联接。
link有人翻译为链接,有人翻译为连接,本人倾向采用链接;connection有人翻译为连接,有人翻译为链接,本人倾向采用连接。
在计算机编程和数据库领域,除非特别强调或作为关键字用,join和link,connection和link可以互换,少见苛意区分。
在“多对多”关系中,两个表中任意一个表中的记录在另一个表中部具有多个匹配的记录。对于多对多关系的两个表,数据库管理系统不提供直接支持,需要建立一个中间表用以间接地关联这两个表,这个中间表称为联接表(junction table) 或 链接表(linking table),即是说,多对多关系不能直接定义,对这种类型的关系必须添加一个联接表(连接表junction table),转化为两个“一对多”关系,联接表为“多”方。联接表(junction table)尽管可以包含较多的字段,但实际只需要包含多对多关系的两个表中的主键字段,根据“外键”定义,这些在其它表中作为“主键”的字段,在联接表作为“外键”的字段。
主键(primary key)是被挑选出来一个字段或多个字段,作为表的行的惟一标识。一个表只有一个主关键字。
在一个关系中是主键,放置在另一个关系中,被称为另一个关系的外键(Foreign Key)。外键用于表示两个关系之间的联系。以另一个关系的外键作为主键的表被称为主表,具有此外键的表被称为主表的从表。
A junction table, sometimes also known as a "Bridge Table", "Join Table", "Map Table", or "Link Table", is a table that contains common fields from two tables. It is on the many side of a one-to-many relationship with the other two tables.
junction table有时也称为“Bridge Table” , “Join Table” , “Map Table” ,或“Link Table” ,是一个包含两个表的公用字段的表,它是与其它两个表构成的“一对多”关系的“多”边。
公用字段,也称为相关字段,或匹配字段,在两个表中一般相同,也可不同,但要求是相同或相容的数据类型。
在Access数据库中,链接 (link)(表),指在其他程序与数据之间建立连接的操作,使用户既可以在原程序中,又可以在 Access 中查看和编辑数据。
链接表 (linked table) ,指存储在已打开数据库之外的文件中的表,Access 可通过它访问记录。您可以在链接表中添加、删除和编辑记录,但不能更改其结构。
Field和Domain
Domain(域):在关系数据库中,一个或多个属性的取值范围 [ 或字段的数据类型 ]。如:大于0小于150的正整数,长度小于25的字符串集合等等。在关系数据库中,Domain(域)是一组约束,用于限制取值,包括数据类型、长度、格式、唯一性、是否为空(null)等,可以通过数据类型和约束(constraint)来定义域。
Domain还是 Windows 网络操作系统的逻辑组织单元,也是Internet的逻辑组织单元。
Field(字段):数据模型中数据的最小单位,描述实体的属性。
在 java 和C#语言类中字段(field)指类的成员变量。表示与对象或类相关联的变量。
java中的field
class A{
private int a; //private field
protected double b; //protected field
public String c; //public field
A d; //default access field
public static Object e; //public static field
}
field,字段;域
1. In a data base, the smallest unit of data that can be referred to. 在数据库中,可被访问的最小数据单位。
2. 在.NET中,表示与对象或类相关联的变量。
domain,域;定义域
1. The set of values that an independent variable can have.
自变量可取值的范围或集合。
2. 在关系数据库中,域(Domain)是属性值的集合,如:大于0小于150的正整数,长度小于25的字符串集合等等。
3. The network resources that are under the control of one or more associated host processors. 在一台或多台相关联的主机控制下的网络资源。
Domain域
Domain是Windows网络中独立运行的单位,域之间相互访问则需要建立信任关系(即Trust Relation)。信任关系是连接在域与域之间的桥梁。
在Internet上,域名是上网单位和个人在网络上的重要标识。域名(Domain Name),是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称。例如优酷的域名是youku.com。
构成部分网络并共享一个通用目录数据库的一组计算机。一个域作为一个单元来管理,并且带有共同的规则和过程。每个域有一个唯一的名称。
Active Directory 域是一个由 Windows 网络的管理员定义的计算机的集合。这些计算机共享公用目录数据库、安全策略以及与其他域的安全关系。Active Directory 域提供了对由该域的管理员维护的集中用户帐户和组帐户的访问。Active Directory 林由一个或多个域组成,每个域都可以跨越一个以上的物理位置。
DNS 域是 DNS 名称空间中的任意一个树或子树。尽管 DNS 域的名称通常与 Active Directory 域对应,但不要混淆 DNS 域和 Active Directory 域。
数据库中的域(Domain):属性的取值范围,如性别的男女,在数据表中,列为域。
Relationship和relation
relation关系;[关系式]
1. In assembler programming, the comparison of two expressions to see if the value of one is equal to, less than, or greater than the value of the other.
在汇编语言程序设计中,对两个表达式进行的一种比较(结果),看其中一个表达式的值是否等于、小于或大于另一个表达式的值。
2. 在数据库指表。从本质上说,关系是一个包含行和列的二维表或数组。
relationship
关系;联系
1.实体或属性间的内在关系。在数据库中指不同表之间的数据彼此联系的方法。数据库实体之间的relationship有:一对一、一对多、多对多。
2. 事物之间相互作用、相互影响的状态,人和人或人和事物之间某种性质的联系
实体(Entity):客观存在并可相互区别的事物称之为实体。实体可以是具体的人、事、物,也可以是抽象的概念或联系。数据库中表示描述的现实世界中的对象或概念。同型实体的集合称为实体集(Entity Set)。
relationship和relation通常都翻译为关系,但在数据库中两者含义不同。relationship [关系;联系;关联],在数据库中指不同表之间的数据彼此联系的方法。数据库实体之间的relationship有:一对一、一对多、多对多。relation[关系],在数据库指表,从本质上说,关系是一个包含行和列的二维表或数组。应根据语境区别理解。
请注意,在英语国家讲数据库的英语文献中,relation有时指“表”,有时指两表之间的relationship。指两表之间的relationship时也常用link[链接]。
引用(reference)、参照[引用]关系(Referencing Relation)、被参照[被引用]关系(Referenced Relation)
引用(reference)
①允许一个程序选择另外一个程序的对象,通过设置对那个程序对象库的引用您可以在您的代码中使用它。
②引用就是某一变量(目标)的一个别名,对引用的操作与对变量直接操作完全一样。
③用在函数中作为参数,可以改变作为参数变量的值,而普通参数是拷贝值,不改变原参数。
④在Excel中引用的作用在于标识工作表上的单元格或单元格区域,并指明公式中所使用的数据的位置。通过引用,可以在公式中使用工作表不同部分的数据,或者在多个公式中使用同一单元格的数值。还可以引用同一工作簿不同工作表的单元格、不同工作簿的单元格、甚至其它应用程序中的数据。关于引用有两种表示的方法,即A1 和 R1C1 引用样式。
主键(primary key)是被挑选出来一个列或多个列,作为表的行的惟一标识。一个表只有一个主关键字。[有些人也将“键”称作“码”,都指key]
外键(foreign key) 是列或列的组合,其值与同一个表或另一个表中的主键或唯一键(指建立了唯一约束(unique)的一列或一组列)相匹配。[列也叫字段]
两表之间的关系不要求必须使用主表(父表)的主键(primary key),你可以使用主表中的具有唯一约束或唯一索引(唯一值索引)的列来建立关系,但是使用主表的主键是大家都已经接受的常用标准。外键是子表(从表)中的列,不一定和主表的主键列同名,但是,外键列的数据类型必须和主键的数据类型相同或相容。外键的值可以是空(Null),但建议在没有特别原因的情况下,不要让外键为空。主表和子表可以是同一个表,这实际上是表中的一列(的取值)约束同一表中的另一列(的取值),称为自引用完整性,这种情况比较少见。
参照[引用]关系(Referencing Relation)、子表、从表、外键表(foreign key table)、参照[引用]表(Referencing Table)、相关表(Related Table)、外表(foreign table),这些是同一术语的不同叫法。
被参照[被引用]关系(Referenced Relation)、父表、主表、主键表(primary key table)、被参照[被引用]表(Referenced Table),这些是同一术语的不同叫法。
参见下表:
| 专业名称 | 别称 | ACCESS中叫法 | SQL Server中叫法 |
| 参照[引用]关系(Referencing Relation) 外键所在的关系 | 子表 从表 外键表 参照[引用]表(Referencing Table) | 相关表(related table)[注1] | 外键表(foreign key table) 外表(foreign table)[注2] |
| 被参照[被引用]关系(Referenced Relation) | 父表 主表 主键表 被参照[被引用]表(Referenced Table) | 主表(primary table) | 主表(primary table) 主键表(primary key table) |
[注1] 相关表(related table)具有多义,如在Access数据库的“编辑关系”对话框中,指的是子表,在ADOX联机帮助部分,RelatedTable 属性 (ADOX)中,却指的是父表。应根据语境区别对待。
又,在 Microsoft Access SQL 联机帮助部分,如 CONSTRAINT 子句中,外表(foreign table)实际指的是主表,而不是子表,有点另类:
CONSTRAINT constraint_name
{PRIMARY KEY (pk_field1[, pk_field2[, ...]]) |
UNIQUE (unique1[, unique2[, ...]]) |
NOT NULL (notnull1[, notnull2[, ...]]) |
FOREIGN KEY [NO INDEX] (ref_field1[, ref_field2[, ...]])
REFERENCES foreign_table
[(fk_field1[, fk_field2[, ...]])] |
[ON UPDATE {CASCADE | SET NULL}]
[ON DELETE {CASCADE | SET NULL}]}
其中,foreign_table容易让人产生误解的: foreign table——外表,而外表一般指从表,但在此却作主表使用。
[注2] 外表 (foreign table) 一般指包含外键的表,又叫外键表。
外键其作用是实施参照完整性(referential integrity):用主表中相关列的值域约束从表的外键取值——[从表中添加或修改记录时,]从表中的外键的取值应在主表的相关列的值的范围内,换句话说,保证不会出现孤儿(orphan)记录,即子记录不会没有父记录。
注意,主表和子表可以是同一个表,这实际上是表中的一列(的取值)约束同一表中的另一列(的取值),称为自引用完整性。
pattern、mode、model和Schema
pattern
n.模式;样品;典范
模式(Pattern)是解决某一类问题的方法论。你把解决某类问题的方法总结归纳到理论高度,那就是模式。就是从不断重复出现的事件中发现和抽象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可能存在某种模式。模式(Pattern)是一种指导,在一个良好的指导下,有助于你完成任务,有助于你作出一个优良的设计方案,达到事半功倍的效果。而且会得到解决问题的最佳办法。
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。
Mode 模式;方式
login security mode 登录安全模式;Mixed Mode 混合模式
Model 模型;模特儿
- A general, often pictorial, representation of a system under study.
对正在研究的系统的一种通用表示法。通常用图形表示。
- A schematic description of a system, theory, or phenomenon that accounts for its known or inferred properties and may be used for further study of its characteristics。
模式,图解:系统、理论或现象的图解性的描述,用来描绘其已知的或推测性质的特性,也可能用于深入研究它们的特点。
模型(model) 是指对于某个实际问题或客观事物、规律进行抽象后的一种形式化表达方式。 表现为文字、图表、公式,或实体模型。
模型(Model)是现实世界的抽象。
数据模型(Data Model)是数据特征的抽象,是数据库管理的教学形式框架。数据模型所描述的内容包括三个部分:数据结构、数据操作、数据约束。
数据模型一般多指在设计和建立数据库时,对现实世界数据特征的抽象描述。
数学模型(Mathematical Model),是根据对研究对象所观察到的现象及实践经验,归结成的一套反映其内部因素数量关系的数学公式、逻辑准则和具体算法。用以描述和研究客观现象的运动规律。
概念数据模型(Conceptual Data Model),常用实体—联系[关系](Entity-Relationship)模型表示。
E-R模型也称为E-R图。
E-R模型的构成成分是实体集(entity set)、属性(attribute)或叫特性(property) 、联系(Relationship),说明如下:
(1)实体集用矩形框表示,矩形框内写上实体名。
(2)实体的属性用椭圆框表示,框内写上属性名,并用无向边与其实体集相连。
(3)联系用菱形框表示,联系以适当的含义命名,名字写在菱形框中,用无向连线将参加联系的实体矩形框分别与菱形框相连,并在连线上标明联系的类型,即1—1、1—M或M—M。
联系也可以有属性,如“学生”和“课程”两个实体集之间有选课联系,选课联系有一个成绩属性。注意“成绩”属性不是学生的属性,它是与选课直接相联系的,因为只有知道了哪一个学生和哪一门课程才会有成绩。
一般而言,一个实体集不能既无主键又无外键。在E—R 图中, 处于叶子部位的实体集, 可以定义主键,也可以不定义主键(因为它无子孙), 但必须要有外键(因为它有父亲)。主键与外键的配对,表示表之间的联结(连接)关系。主码(主键)和外部码(外部键)一起提供了表示关系间联系的手段。在关系的基础上可以实施的数据参照完整性。
Schema,模式,架构
The set of statements, expressed in data definition language, that completely describe the structure of a data base.
一组以数据定义语言来表达的语句集,该语句集完整地描述了数据库的结构。
架构,数据库架构是一个独立于数据库用户的非重复命名空间,您可以将架构视为对象的容器。一个对象只能属于一个架构。
模式(schema)是数据库中全体数据的逻辑结构和特征的描述,它仅仅涉及到型(type)的描述,不涉及到具体的值。 模式的一个具体值称为模式的一个实例(instance)。 同一个模式可以有很多实例。模式是相对稳定的,而实例是相对变动的。模式反映的是数据的结构及其关系,而实例反映的是数据库某一时刻的状态。
模式(schema):
A complete logical view of the database.
一个数据库完整的逻辑视图。
All database objects owned by a single database user.
一个数据库用户所拥有的所有数据库对象。
Relational Schema(关系模式),带有关系约束(constraint,限制, 约束)的一组关系。
Data schema
数据模式, 数据架构
A data schema , especially a data subschema in a relational data system
关系数据系统中的数据模式,特别是子模式。
由模式可以延伸出内模式,外模式,外模式对应于各个用户的视图,内模式是模式在计算机中的内部实现。
模式相当于数据结构中的逻辑结构描述,内模式相当于数据结构的物理实现。
数据库系统的三级模式是对数据的三个抽象级别,它把数据的具体组织留给DBMS管理,使用户能逻辑地抽象地处理数据,而不必关心数据在计算机中的具体表示方式与存储方式。
逻辑模式,简称模式(Schema) ;外模式(External Schema),也称子模式( Subschema)或用户模式;内模式(Internal Schema) 。
数据库的模式(Schema)以某一种数据模型(Data model)为基础,统一综合地考虑了所有用户的需求,并将这些需求有机地结合成一个逻辑整体。模式实际上是数据库数据在逻辑级上的视图。数据模型,从概念层次对系统特征的描述,数据模式是结合DBMS对数据模型的进一步描述,定义模式时不仅要定义数据的逻辑结构,例如数据记录由哪些数据项构成,数据项的名字、类型、取值范围等,而且要定义数据之间的联系,定义与数据有关的安全性、完整性要求,但仅仅涉及到型(Type)的描述,不涉及到具体的值(Value)。DBMS提供数据定义语言(DDL),来严格地定义模式(Schema)。
SQL Server中的schema(模式,架构),是形成单个命名空间的数据库实体的集合。命名空间是一个集合,其中每个元素的名称都是唯一的。在这里,我们可以将架构看成一个存放数据库中对象的一个容器。数据库对象(表、视图、存储过程,触发器等)按照一定的标准,存放在不同的架构里。一个对象只能属于一个架构。
数据库就是一个数据的大仓库,而里面创建了很多schema,分别放着不同的数据库对象(包括表),而不同的schema有不同的权限,于是,不同的用户就有不同的访问权限来访问某个schema里的数据库对象。
用户和schema(构架)的关系是多对多的——一个架构可以对应多个用户,一个用户也可以对应多个架构。
数据库(database)和schema(架构)关系是一对多的关系。
在数据模型(Data model)
模型,特别是具体模型,人们并不陌生。一张地图,一组建筑设计沙盘, 一架精致的航模飞机都是具体的模型。一眼望去,就会使人联想到真实生活中的事物。模型是现实世界特征的模拟和抽象。数据模型(Data Model)也是一种模型,它是现实世界数据特征的抽象。在数据库中,数据模型指关于怎样组织数据、怎样用数据组织映射企业信息结构的一种描述。
根据模型应用的不同目的,可以将这些模型划分为两类,它们分属于两个不同的层次。第一类模型是概念模型,贴近现实世界,也称信息模型,它是按用户的观点来对数据和信息建模,主要用于数据库设计。另一类模型是数据模型,贴近及其世界,由数据库管理系统(DBMS)支持,主要包括网状模型、 层次模型、关系模型等,它是按计算机系统的观点对数据建模,主要用于DBMS的实现。
在数据模型中有“型” (Type)和“值”(Value)的概念。型是指对某一类数据的结构和属性的说明,值是型的一个具体赋值。例如:学生记录定义 为(学号,姓名,性别,系别,年龄,籍贯〉这样的记录型,而(900201,李 明,男,计算机,22,江苏)则是该记录型的一个记录值。
Type(型;类型),作为一个集体或种类的人或事物的共通点——共同拥有的总体特征或结构。
关系数据库的型,也称为关系数据库模式,是对关系数据库的描述,包括若干域的定义,及在这些域上定义的若干关系模式。
关系模式是对关系的描述,一般表示为:关系名称(属性1,属性2,属性3...,属性n)。
关系模型要求关系必须是规范化的。
模式(Schema)是数据库中全体数据的逻辑结构和特征的描述,它仅仅涉及到型的描述,不涉及到具体的值。模式的一个具体值称为模式的一个实例 (Instance)。同一个模式可以有很多实例。模式是相对稳定的,而实例是相对变动的,因为数据库中的数据是在不断更新的。模式反映的是数据的结构及其联系,而实例反映的是数据库某一时刻的状态。
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。它是数据库系统模式结构的中间层,既不涉及数据的物理存储细节和硬件环境,也与具体的应用程序,与所使用的应用开发工具及 高级程序设计语言(如C,COBOL,FORTRAN)无关。
模式实际上是数据库数据在逻辑级上的视图。一个数据库只有一个模式。数据库模式以某一种数据模型为基础,统一综合地考虑了所有用户的需求,并将这些需求有机地结合成一个逻辑整体。定义模式时不仅要定义数据的逻辑结构,例如数据记录由哪些数据项构成,数据项的名字、类型、取值范围等,而且要定义数据之间的联系,定义与数据有关的安全性、完整性要求。
关系数据库中,关系模式(Relation Schema)是型(Type),关系是值。关系是关系模式在某一时刻的状态或内容。关系模式是静态的、稳定的, 而关系是动态的、随时间不断变化的,因为关系操作在不断地更新着数据库中的数据。但在实际当中,人们常常把关系模式和关系都称为关系,这不难从上下文中加以区别。
关系可以有三种类型:基本关系(通常又称为基本表或基表)、查询表和视图表。基本表是实际存在的表,它是实际存储数据的逻辑表示。查询表是查询结果对应的表。视图表是由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据。
视图是从一个或儿个基本表导出的表。它本身不独立存储在数据库中,即数据库中只存放视图的定义而不存放视图对应的数据,这些数据仍存放在导出视图的基本表中,因此视图是一个虚表。视图在概念上与基本表等同,用户可以在视图上再定义视图。
关系的描述称为关系模式(Relation Schema)。关系模式是对关系的描述,它可以形式化地表示为:
R (U, D, dom, F)
其中R为关系名,U为组成该关系的属性名集合,D为属性组U中属性所来自的域,dom为属性向域的映象集合,F为属性间数据的依赖关系集合。 属性向域的映象,即说明它们分别出自哪个域。
关系模式通常可以简记为 R (U) 或R (A1,A2,…, An)
其中R为关系名, A1, A2,…, An为属性名。而域名及属性向域的映象常常 直接说明为属性的类型、长度。
关系数据库中,关系模式是型,关系是值。关系是关系模式在某一时刻的状态或内容。关系模式是静态的、稳定的, 而关系是动态的、随时间不断变化的,因为关系操作在不断地更新着数据库中的数据。但在实际当中,人们常常把关系模式和关系都称为关系,这不难从上下文中加以区别。
数据库设计中心是如何设计数据的逻辑结构,关系数据库设计时,数据建模设计常用实现技术是实体/联系模型(E-R模型),在此基础上确定需要哪些关系模式(有些文献称为关系变量),以及关系模式中应含有哪些属性和关系模式之间的联系等。规范化主要用来验证设计结果——关系模式是否存在异常。数据建模(有时称为语义建模)是数据库设计的一个蓝图。现实情况不是如此简单,至今,数据库设计尽管有一些科学理论可以应用,但远非成熟和全面,这使数据库设计更像一门艺术而非一门科学。
另外,数据库理论和技术中,存在许多不一致的术语,这从侧面反应了数据库领域发展现状远非理想和成熟。
实体(Entity)、实体集(Entity Set)、实体类型(Entity Type)和实体实例(Entity instance)
学习数据库知识时,应了解,现实中,人们时常混用下面这些术语(每一行作为同义词使用):
| 关系理论中称谓 | 概念模型(如E-R模型)中的称谓 | ISO SQL标准或一般表格中称谓 | 传统称谓(源自传统的数据处理) |
| 关系(Relation) | 实体集(Entity Set) 或 实体(Entity)[注] | 表(Table) | 文件(File) |
| 属性(Attribute) | 属性(Attribute) | 列(Column) | 字段(Field) |
| 元组(Tuple) | 实体(Entity)或 实体实例(Entity instance) [注] | 行(Row) | 记录(Record) |
[注]一些文献中的“实体”(Entity)含有集合义等同于另一些文献中的“实体集”(Entity Set),含有个体义的“实体”称为“实体实例”(Entity instance)。实体实例(Entity instance)是实体类型的一个实例,对应于数据表中的一个记录。
关系的描述称为关系模式(Relation Schema)。关系模式通常可以简记为:R(A1, A2, …, An)。其中R为关系名,A1, A2, …, An为属性名。
关系(Relation)是笛卡尔积的有限子集,形象地说是一个二维表,表的每行对应一个元组(Tuple),表的每列对应一个域。由于域(domain)可以相同,为了加以区分,必须对每列起一个名字,称为属性(Attribute)。规范化的关系简称为范式(Normal Form)。
实体集(Entity Set)是具体相同类型及相同性质实体的集合。可以用实体类型来刻画实体集。实体类型(实体型Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,…},用实体名及其属性名集合来抽象和刻画同类实体。“患者”实体(或 实体实例)为(201301020005,李牧,男,28,…)。
快照(Snapshot) 和动态集(Dynaset)
记录集(set)本身是从指定数据库中检索到的数据的集合。它可以包括完整的数据库表,也可以包括表的行和列的子集。这些行和列通过在记录集中定义的数据库查询进行检索。数据库查询是用结构化查询语言 (SQL) 编写的。而 SQL 是一种简单的、可用来在数据库中检索、添加和删除数据的语言。注: Microsoft ASP.NET 将记录集称为“数据集”。
记录集主要分为快照(Snapshot) 和动态集(Dynaset)两种,这两种记录集的不同表现在它们对别的应用改变数据源记录采取了不同的处理方法。记录集(Recordset)是通过数据库查询从数据库中提取的信息的子集(在 ASP.NET 中,记录集称为数据集)。数据库查询由搜索条件组成,后者定义记录集中包含的内容。
快照型记录集提供了对数据的静态视图。快照是个很形象的术语,就好象对数据源的某些记录照了一张照片一样。当别的用户改变了记录时(包括修改、添加和删除),快照中的记录不受影响,也就是说,快照不反映别的用户对数据源记录的改变。直到调用了Requery重新查询后,快照才会反映变化。对于象产生报告或执行计算这样的不希望中途变动的工作,快照是很有用的。需要指出的是,快照的这种静态特性是相对于别的用户而言的,它会正确反映由本身用户对记录的修改和删除,但对于新添加的记录直到调用Requery后才能反映到快照中。动态集提供了数据的动态视图,当别的用户修改或删除了记录集中的记录时,会在动态集中反映出来:当滚动到修改过的记录时对其所作的修改会立即反映到动态集中,当记录被删除时,会跳过记录集中的删除部分。对于其它用户添加的记录,直到调用Requery时,才会在动态集中反映出来。本身应用程序对记录的修改、添加和删除会反映在动态集中。当数据必须反应动态变化的时侯,使用动态集是最适合的。例如,在一个火车票联网售票系统中,显然应该用动态集随时反映出共享数据的变化。
类(Class)与类型(Type)
1: 类型的概念
类型刻划了一组值及其上可施行的操作,可理解为值集和操作集构成的二元组。
类型的概念与值的概念相对立,前者是程序中的概念,后者则是程序运行时的概念,两者通过标识值的语言成分(例如,变量、表达式等)联系起来。
比如变量v说明为具有类型T,类型T所刻划的值集为{v1,v2,…vn,…},则变量v运行时能取且只能取某个vi为值。由此可见,类型规定了具有该类型的变量或表达式的取值范围。
2: 类与类型
A: 共性
在对象式语言中,“值”为对象(或对象指引,但本质上仍为对象)。所以,对象式语言中的类型刻划了一组对象及其上可施行的操作。类型所刻划的对象称为类型的实例。类也刻划了一组对象。
两者的共性在于二者均刻划了一组对象及其上的操作(在前面关于类的讨论中,并未强调类刻划对象上的操作这一事实),所以,既可以说对象是类型的实例,也可以 说对象是类的实例,类型和类在与对象的关系上是相同的。不过,类型欲刻划一组对象及其上的操作,必须借助于类,因为类是达到这种目的的唯一设施。由此可 见,类型是以类为基础的,是通过类来定义的,这体现了二者的联系。
B: 区别
◇作用不同
类是程序的构造单位,是描述一组对象及其上操作的唯一语言成分,故其作用主要是具体描述这组对象,提供运行时创建这些对象的“模板”。例如,基于类间的继承关系的派生类定义设施就反映了类在描述对象方面的作用。
类型则是标志变量或表达式取值范围的一种语言成分,其作用主要是对这些变量或表达式运行时的取值进行约束。例如,对赋值语句左部的变量和右部的表达式的类型匹配检查就反映了类型的约束作用。
◇与对象联系的紧密程序不同
类描述对象的具体形式和其上可施行的具体操作,且强调所描述的一组对象的共性,因而,与具体对象联系较密切,而与对象集的大小则联系较少。
类型强调所描述的一组对象的范围和可施行操作的范围,与对象集的大小联系较密切,而与其中具体对象则联系较少。
◇并不是所有类都可直接作为类型使用
类是类型的基础,类型靠类来定义,有些类可直接作为类型来使用,在这种意义下,我们也可称这些类是类型。
但是,也有一些类不能直接作为类型来使用,这是因为,从类型的约束作用来看,类型强调所刻划的对象的确定性,即对象范围的确定性。因此,只有所描述的对象的范围确定的类才可直接用作类型。
《Java编程思想》第二版中文版 22页(相应英文版33页)
虽然我们在面向对象程序设计过程中,实际所做的是建立新的数据型别(data type),但是几乎所有面向对象的程序语言都使用class这个关键词来表示type,所以当你看到型别(type)一词时,请想成是类class,反之亦然。
某些人对此还是有所区别,他们认为type决定了接口,而class则是接口的一个特定实现品。
《设计模式》(Design pattern)中文版 第10页
对象声明的每一个操作指定操作名、作为参数的对象和返回值,这就是所谓的操作的型构( signature )。对象操作所定义的所有操作型构的集合被称为该对象的接口( interface )。对象接口描述了该对象所能接受的全部请求的集合,任何匹配对象接口中型构的请求都可以发送给该对象。
类型(type) 是用来标识特定接口的一个名字。如果一个对象接受“ Window”接口所定义的所有操作请求,那么我们就说该对象具有“ Window”类型。一个对象可以有许多类型,并且不同的对象可以共享同一个类型。对象接口的某部分可以用某个类型来刻画,而其他部分则可用其他类型刻画。两个类型相同的对象只需要共享它们的部分接口。接口可以包含其他接口作为子集。当一个类型的接口包含另一个类型的接口时,我们就说它是另一个类型的子类型( subtype ),另一个类型称之为它的超类型( supertype )。我们常说子类型继承了它的超类型的接口。
Empty、null
Empty,专用于 Variant 变量,表示未赋值。Variant 变量是合并了多种数据类型的组合变量。Empty 表示全部清空的状态。
Null,常见的有三种情况:
1 与指针有关的变量。
当指针值为 0 时,就是 Null。例如一个字符串,实际上由指针和缓冲区组成,当指针是 0 的时候,就是还没有分配缓冲区,此时它就是 Null。
2 数据库字段
未赋值的状态就是 Null。
3 对象变量
未实例化的状态就是 Null。这个其实有点类似指针的情况。
Empty 和 Null 都不是真实的值,而是状态。所以判断它们时,用 If x Is Null Then 或 If IsNull(x) Then 的形式,而不可 If x = Null Then。
Empty 和 Null 的一个区别是,包含 Empty 的变量参加运算时,被当作 0 或空字符串来处理。而 Null 将使结果也成为 Null, Null 通过表达式“传播”;如果表达式的部分之值为 Null,那么整个表达式的值也为 Null。
Null 值与零长度字符串的区别
本主题中的信息仅适用于 Microsoft Access 数据库 (.mdb)。
Null 表示未设置数据,不需要输入任何内容。
"" 表示有数据,数据为一个零长度字符串,输入零长度字符串的方法是键入两个彼此之间没有空格的双引号 ("")。
“必填字段”(Required)属性设置为“是”, 表示不允许 NULL
“允许空字符串”(Allow zero length)属性设置“是” ,表示允许 ""(零长度字符串,空字符串)
关于null值的进一步说明:
null值是sql语言,乃至整个关系模型中最诡异的东西之一。它是什么?它代表一切不可知的,未知的,未定义的东西。它不是0,更不是空格或空字符串。它不是信息,因为它不代表任何信息;但它也是信息,它告诉我们这里没有信息。
一般情况下我们查询空值或者非空值的时候,用的是is null/is not null,而很少用=/<>。若想用=/<>时,需要注意什么?
在SQL2000中Null值的比较运算有两种规则。一种是ANSI SQL(SQL-92)规定的Null值的比较取值结果都为False,既Null=Null取值也是False。另一种不准循ANSI SQL标准,即Null=Null为True。
以一张表T的查询为例。表T存在下面的数据:
RowId Data
--------------
1 'test'
2 Null
3 'test1'
按照ANSI SQL标准,下面的两个查询(Query)都不返回任何行:
查询1:select * from T where Data=null
查询2:select * from T where Data<>null
而按照非ANSI SQL标准,查询1将返回第二行,查询2返回1、3行。
ANSI SQL标准中取得Null值的行需要用下面的查询:
select * from T where Data is null
反之则用is not null。由此可见非ANSI SQL标准中Data=Null等同于Data Is Null,Data<>Null等同于Data Is Not Null。
控制采用那一种规则,需要使用命令SET ANSI_NULLS [ON/OFF]。ON值采用ANSI SQL标准,OFF值采用非标准模式。另外SET ANSI_DEFAULTS [ON/OFF]命令也可以实现标准的切换,只是这个命令控制的是一组符合SQL-92标准的设置,其中就包括Null值的标准。
null 与任何值运算都为null,如:
10 + NULL = NULL
模式(modal)和无模式(modeless)
显示一个模式(模态,modal)窗体时,除非我们将模式窗体关闭才会使得其他窗体处于活动状态。而无模式(非模态,modeless)的窗体显示的时候允许切换到其他活动的窗体。
模式对话框不返回的话是无法切换到调用窗口的,无模式的可以。对话框一般是模式(modal)的。
对话框(或窗口)一般分为两种类型:模态(modal)与非模态(modeless)类型。所谓模态对话框(或窗口),就是指除非关闭,否则用户的鼠标焦点或者输入光标将一直停留在其上的对话框(或窗口)。非模态对话框(或窗口)则不会强制此种特性,用户可以在当前对话框(或窗口)和其他对话框(或窗口)间进行切换。
早绑定(Early binding)和 晚绑定(Late Binding)
绑定的英文词是BINDING,其含义1)是将两个或多个实体强制性的关联在一起。2)在编程语言中,指在对象和其类型间建立关联的过程。
在编程语言中,分为早绑定(Early binding)和 晚绑定(Late Binding)
早绑定 是指在对象实例化之前,定义对象的属性和方法,这样编译器或解释程序就能够提前转换机器代码。
晚绑定 是指在编译器或者解释程序在运行前,,不知道对象的类型,在程序运行的时候才检查对象是否支持运行的方法和属性。
一般来说,早绑定的效率更好一些,晚绑定更灵活。
早绑定(Early binding)是指我们的代码通过直接调用对象的方法来直接与对象进行交互。由于编译器事先知道对象的数据类型,它可以直接编译出调用对象方法的代码。早绑定还允许 IDE通过使用智能感知(IntelliSense)来帮助我们进行开发工作;它还能够使编译器确保我们所调用的 方法确实存在,以及我们确实提供了恰当的参数值。
晚绑定(Late Binding)是指我们的代码在运行时动态地与对象进行交互。这提供了很大的灵活性,因为我们的代码不必知道它所交互的对象的具体类型,只要这个对象提供了我们需要调 用的方法就可以了。由于IDE和编译器无法知道对象的具体类型,也就无法进行智能感知和编译期间语法检查;但是,相较而言,却得到了空前的灵活性。
有人说C#和Java是早绑定的,javascript,python是迟绑定的,其实这个说法并不全对, 一方面,C#和Java是强类型的,在变量声明的时候就说明了类型,从这里来讲当然是早绑定的,于是我们才能在IDE中享受代码提示带来的方便,因为集成开发环境(IDE)通过你的申明就能知道你的对象是什么类型,具有什么方法和属性,然后提示给你,同时编译的时候也可以帮你检查许多类型转换的错误。另一方面,无论C#和Java在实现他们很重要的一个功能:多态的时候,都是用晚绑定,比如你的父类中定义了virtual的方法,那么这个方法可能会在你的子类中重载,具体你用什么子类,是变量申明时所不知道的,在C++编译器会在编译的时候为这些类加上一个指针,指针指向一个虚表,虚表中存在着真实的函数,这个是就是一个晚绑定了。
焦点(Focus)和插入点(Insertion point)
焦点(Focus),平行光透过放大镜后的光线的汇聚点,延伸为:热门的就是焦点,众心所向之事物人物也是焦点。
在编程语言中,具有输入焦点的,如果是窗口,其标题(title)就是蓝色的,不然就是灰色的 。如果是输入框(如文本框),就是有光标在闪烁的那个,也就是可以马上输入文字的那个。如果是按钮就是有虚框的那个,你按下回车,就相当于按了这个按钮。
如何判断窗体中某个控件是否获得焦点?
在VBA、VB、vb.net中通过 窗体对象.ActiveControl.name来判断,ActiveControl就是获得焦点的控件。
插入点(Insertion point)是新的文字、表格或图形等对象的插入位置,显示为一条闪烁的竖条"∣"。光标位置是鼠标指向的当前位置。插入点是录入者选择确定的位置。在光标当前位置单击一下就会显示一条闪烁的竖条"∣",这就是插入点。
超线程(Hyper-Threading)和多核(MultiCore)
CPU(中央处理单元,Central Processing Unit),简称为处理器(processor),它负责整个系统指令的执行,数学与逻辑的运算,数据的存储与传送,以及对内对外输入与输出的控制。CPU就是中央处理器,一般说的处理器是指它, 但处理器还有GPU等,能执行独立的计算能力的都算处理器。
“超线程(Hyper-Threading,简称“HT”)”技术。超线程技术就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。采用超线程及时可在同一时间里,应用程序可以使用芯片的不同部分。虽然单线程芯片在任一时刻只能够对一条指令进行操作。而超线程技术可以使芯片同时进行多线程处理,使芯片性能得到提升。超线程的P4处理器需要多加入一个Logical CPU Pointer(逻辑处理单元),因此新一代的P4 HT的die的面积比以往的P4增大了5%。而其余部分如ALU(整数运算单元)、FPU(浮点运算单元)、L2 Cache(二级缓存)则保持不变,这些部分是被分享的。虽然采用超线程技术能同时执行两个线程,但它并不象两个真正的CPU那样,每个CPU都具有独立的资源。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两颗CPU的性能。
英特尔P4 超线程有两个运行模式,Single Task Mode(单任务模式)及Multi Task Mode(多任务模式),当程序不支持Multi-Processing(多处理器作业)时,系统会停止其中一个逻辑CPU的运行,把资源集中于单个逻辑CPU中,让单线程程序不会因其中一个逻辑CPU闲置而减低性能,但由于被停止运行的逻辑CPU还是会等待工作,占用一定的资源,因此Hyper-Threading CPU运行Single Task Mode程序模式时,有可能达不到不带超线程功能的CPU性能,但性能差距不会太大。也就是说,当运行单线程运用软件时,超线程技术甚至会降低系统性能,尤其在多线程操作系统运行单线程软件时容易出现此问题。
多核(MultiCore)
早在十多年前,IBM、Sun与HP就已经设计出了双核处理器,比如IBM于2001年推出的基于双核的POWER4处理器和Sun的UltraSPARC芯片,不过由于RISC架构的服务器价格高、应用面窄,没有引起广泛的注意。直到Intel和AMD相继推出自己的双核处理器后,X86领域才算是有了自己的多核架构。
多核与单核的区别在于,前者可以让程序真正地“同时”执行,而不是多个进程轮流使用CPU,从而给用户造成“多个程序正在同时执行”的假象。为了充分发挥每一个核的效用,应用程序需要多个线程同时运行来保持CPU核的忙碌。要在多核系统上构建良好的应用程序,需要方便地、相对便宜地创建线程,这非常重要。如果创建线程的开销比线程完成工作的开销还要大,那么并发将变得毫无意义。
多核处理器指两个或多个独立运行的内核集成于同一个处理器上面
双核处理器 =一个处理器上包含2个内核
多核处理器 = 一个处理器上包含2个或多个内核
Dual Core
This term refers to integrated circuit (IC) chips that contain two complete physical computer processors (cores) in the same IC package. Typically, this means that two identical processors are manufactured so they reside side-by-side on the same die. It is also possible to (vertically) stack two separate processor die and place them in the same IC package. Each of the physical processor cores has its own resources (architectural state, registers, execution units, etc.). The multiple cores on-die may or may not share several layers of the on-die cache.
双核心
这个词是指集成电路( IC )芯片,包含两个完整的物理计算机处理器(核心)在同一IC封装。通常情况下,这意味着两个相同的处理器并排制作在同一晶粒(die),也可能两个单独的处理器晶元(垂直)叠放在同一个IC封装。每个物理处理器核心都有自己的资源(架构状态architectural state,寄存器registers, 执行单元execution units等) 。多核心芯片可能会或不会共享数级晶粒内缓存。
Chip multiprocessing is a soon-to-be commercialized technique in CPU design that combines two or more processor cores on a single piece of silicon (called a die) to enhance computing performance over servers with single or multiple discrete CPUs. It also known as“on-chip multiprocessing”or“multiple-processor system-on-a-chip.”
芯片多处理是CPU设计中即将商品化的技术,它把两个或更多的处理器内核做在一个硅片(称作die)上,以增强计算性能,使之超过拥有单个或多个分立CPU的服务器。它也称为“芯片上多处理”或“单芯片多处理器系统”。
当前市场上的大多数操作系统,包括 Windows、Linux、及UNIX 操作系统的最新版本,都支持多处理器,且将多核系统作为多处理器系统处理。
对于应用开发人员而言,为利用多核处理器编写应用的方法等同于为当前的多处理器系统编写应用的方法。
超线程(HT)技术以模拟两个处理器(创建两个虚拟处理器)为基础。采用超线程(HT)技术意味着程序员必须明白,尽管两个线程可立即运行,并且每个线程都能访问所有硬件,但实际上只有一组计算资源可以利用。为了从超线程(HT)技术中获得最大优势,分配给每个线程的任务要尽可能不同,以确保尽可能减少处理器资源上的冲突。
并发(concurrent)、并行(parallel)、分布(distributed)
并发与并行是两个既相似而又不相同的概念:并发性,又称共行性,是指能处理多个同时性活动的能力;并行是指同时发生的两个并发事件,具有并发的含义,而并发则不一定并行,也亦是说并发事件之间不一定要同一时刻发生。
在程序设计中,因并发和并行程序设计技术基本相同,不刻意区分并发和并行。
并发(concurrent)的实质是一个物理CPU(也可以多个物理CPU)在若干道程序之间多路复用,并发性是对有限物理资源强制实行多用户共享。实现并发技术的关键之一是如何对系统内的多个活动(进程)进行切换。在单个cpu上,并发实际上在同一时间间隔内交替运行,是宏观上的同时执行。
并行(parallel)指的是两个或两个以上的事件或活动在同一时刻发生。在多道程序环境下,并行使多个活动(进程)同一时刻可在不同CPU上同时执行。
“并行”是指无论从微观还是宏观,二者都是一起执行的,就好像两个人各拿一把铁锨在挖坑,一小时后,每人一个大坑。“并发”在微观上不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行,从宏观外来看,好像是这些进程都在执行,这就好像两个人用同一把铁锨,轮流挖坑,一小时后,两个人各挖一个小一点的坑,要想挖两个大一点得坑,一定会用两个小时。从以上本质不难看出,“并发”执行,在多个进程存在资源冲突时,并没有从根本提高执行效率。
并行(parallel)、并发(concurrent)和分布(distributed),它们近似相通的地方是,都是描述计算机硬件和软件组成的系统体系结构,以达到同一时间处理多项任务的目的。不同的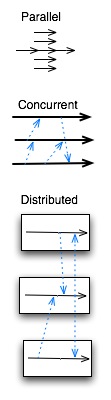
并行(Parallel),或曰并行代码,或曰并行系统都是讨论有关如何使用现有系统,通过任务分片(breaking into pieces)技术使得所有的任务都可以同时运行,以期提高运行速度。所以假设你要执行某项复杂的任务:将执行A,B和C三个过程。A和B为C的运行分别进行准备,但是A,B之间不会相互干预。现在你可以先执行A,直到它执行完毕,然后执行B,等待B执行完毕,然后再去执行C。或者你有多余的CPU,你可以同时执行A和B,当它们执行完毕以后,执行C。当你编写一个在同一时间内运行多个程序片段以达到提升运行速度的程序时,你所做的就是并行。
并发(Concurrency)讨论关于系统存在多个子部分,其中每个部分设计的明确目的是为能够响应在同一时间内发生的事件,并不是为了提高运行速度,但却是系统功能不可或缺的一部分。科技博客(ScienceBlogs)的服务器端系统(The backend system)处理着大量的并发,因为它被设计为能支持成千上万的访问者同时阅读网页内容,也允许我们同时撰写和发布新文章而不会影响服务器系统的正常运行。如果对于系统来说在同一时间内支持大量事件同时发生是必须的功能,它所做的就是并发。
分布(Distribution)讨论关于由多个物理设备通过网络连接组成的系统。它是一项基础性研究,目的在于研究如何组织构建依据需要拆分后位于各个不同实际位置,不同通信限定条件物理设备的系统。如果你有一个特别设计来在大量不同的物理硬件上同时运行各自程序的系统,但是它们某些情况下也是单独的系统,这就是分布式系统。
仿真 emulation 模拟 simulation
模拟(Simulation):用机器语言程序解释另一机器的机器指令实现软件移植的方法称为模拟。进行模拟工作的机器称为宿主机(Host Machine),被模拟的机器称为虚拟机(Virtual Machine)
仿真(Emulation):用微程序直接解释另一机器的机器指令实现软件移植的方法称为仿真。进行仿真工作的机器称为宿主机(Host Machine),被仿真的机器则称为目标机(Target Machine)。
模拟(Simulation)即选取一个物理的或抽象的系统的某些行为特征,用另一系统来表示它们的过程。模拟技术的高级阶段称为仿真(Emulation)、系统仿真,即用一数据处理系统来全部或部分地模拟某一数据处理系统,以致于模仿的系统能想被模仿的系统一样接受同样的数据、执行同样的程序、获得同样的结果。
模拟(Emulation)是试图模仿一个设备的内部设计;仿真(Simulation)是试图模仿一个设备的功能。
simulation是模拟出原系统的一个抽象模型,而不需要真的去做真实系统要做的事情。因此它其实不具备真实系统的功能,只是当某一功能执行时,通常不必输出功能执行的结果,只是在simulator中记录下由此引发的状态变化。因此它通常用于设计初期的模型验证。如,飞行模拟器或电子电路模拟器simulators
emulation则更进一步,要真正地去做所有真实系统能做的事情,只不过做的“过程”不同,它一般用于处理兼容性问题和在资源有限的条件下完成系统原型的实现。
caption、title、Heading、Header
caption、Title与Heading,都具有“标题”意思:caption一般指(附于插图、漫画或海报上的)标题或简短说明 ;Title一般指整体的,如书名文章名;Heading一般指组成部分的,如章节的标题。
title(标题):1)在计算机文档中,一个窗口的最上面条形区域——标题栏(title bar)——上的文字。标题栏(title bar)位于一个窗口(window)的顶部条形区域,最右边是控制框(control box),最左边有“最小化 最大化 关闭 ”按钮。2)ACCESS数据库的窗体、报表、数据访问页(DAP)中标题栏(title bar)之下页眉(page header )之上的占位符,它实际是一个标签(label)控件,可以在此输入标题(title)文字。ACCESS数据库的数据访问页(DAP)技术现已被放弃。
标题栏(title bar)位于一个窗口(window)的顶部条形区域,最右边是控制框(control box),最左边有“最小化 最大化 关闭 ”按钮。
HTML中<title>显示在浏览器的标题栏。
caption:在VB、VBA里,许多控件对象具有Caption 属性,用以在控件上显示的内容。命令按钮(commandbutton)控件,你可以在caption上给它赋值"按钮",它将显示出"按钮"两个字。ACCESS数据库中Field对象的caption属性(也就是标题)属性是用来设置数据字段的标题的,在正常的数据库设计中为了保持维护的便利性,许多开发者都将字段名(name)与标题(caption)做了分别设置,标题往往比字段名更友好,更能说明字段的用途。ACCESS数据库的窗体、报表caption属性用于设置窗体、报表的标题,即出现在标题栏(title bar)中。
heading:(页首或章节开头的)标题;(讲话或作品各章节的)主题。HTML有六个不同的级别的Heading,<h1> 级别最高,而 <h6> 级别最低。
Header:1. 页眉,文字处理或打印要出现在页的顶部的文本。如Report Header 报表页眉;Page Header 页眉。2. 标头,一种信息结构之前,标识所遵循,如通讯、 磁盘上的文件、 一组在数据库或可执行程序中的记录中的字节的块的信息。 3.一个或多个行在程序中标识和描述人读者程序、 功能或遵循的程序。
其它含义
caption,说明;(电影或电视的)字幕 ;(法律文件等的)提要、说明。
title,职称、职务 ;头衔。
label、tab、tag
label:n. 标签; 标记; v. 贴标签; 用标签表明;
tab:n. 1、[计]选项卡 ;标签 ;(待付的)账单。2、制表符,在键盘上是制表符键(跳格键)。vt. 使用制表键; 给…贴标签;
tag:n. 标签;标记; v. 给……贴标签,在……上做记号
label(标签)控件用于显示文本,是设计应用程序界面时经常要用到的控件之一,主要是用于显示其他控件名称,显示说明性文本、描述程序运行状态或标识程序运行的结果信息等等,响应程序的事件或跟踪程序运行的结果。它的文本是可以由程序代码改变的,但程序运行后不接受焦点,不能由用户改变。
Tab control(Tab控件),使用Tab控件能够将程序中的窗口或对话框的同一区域定义为多页(page),可以将其他控件放在页上。如果用过选项卡式(Tabbed Dialog)对话框,对此就有一定感性认识。
tag:
在 HTML 中,<label>标签(tag)表示用户界面中某个元素的说明。
在 HTML 中,tag 用来创建一个 element。HTML 元素的名称是在尖括号中使用的名称。
item和project
item和project都可翻译为“项目”
project工程、项目,指围绕着一个明确的目标或目的相互关联的活动;而item一般指分类或条款中的一项。
item指的是产品或条款方面所指的项目,(可分类或列举的)项目,比如,价格条款的第一个项目(即第一点)是什么。 把一些东西分类,每一类就是一个item。
project,1)项目是一个特殊的将被完成的有限任务,它是在一定时间内,满足一系列特定目标的多项相关工作的总称。2)在编程开发集成环境中,指模块的集合,在VB或VBA中翻译为工程。
Access Projects (Access 项目)是一种 Access 数据文件(.adp文件),它能通过 OLE DB 组件访问 Microsoft SQL Server 数据库。使用 Access 项目,可以像创建文件服务器应用程序那样,轻松地创建一个客户/服务器应用程序。
OLE DB:对多种类型的数据源(包括关系数据、邮件文件、纯文本和电子表格)提供有效的网络和 Internet 访问的组件数据库结构。
Visual Studio .NET 提供了两个容器:解决方案(solution)和项目(Project:工程,项目)。查看和管理这些容器及其关联项的界面是解决方案资源管理器(solution explorer),它作为集成开发环境(IDE) 的一部分提供。
一个解决方案由一个或多个项目(Project)组成。每个项目容器通常包含多个项(应用程序所需的引用、数据连接、文件夹和文件),有很多项是系统生成的。
项目(Project),通俗的说,一个项目可以就是你开发的一个软件。
standard 和criterion 、Criteria
都含“衡量人或事物的标准”的意思。
[辨析] standard: 标准,指法定的或一般公认的标准。规定的(或一致同意)的标准,规格。
criterion: (批评、判断等的)标准、准则,用以判断验证其他事物。俗称规范。
Criteria:criterion的复数,条件 准则。
standard的英语解释是a test or measure for qualities or for the required degree of excellence.
一种质量或等级检验、衡量标准。
criterion的英语解释是principle by which sth.is measured for value(衡量某事物价值的原则);an established rule or principle,on which a judgment is based(一种确立的规定或原则,据以做出判断)。
由此可见:前者指法定或一般公认的质量标准,后者指判断其他事物的标准。例句:
- Practice is the criterion by which truth is tested.(实践是检验真理的标准。)
②This product is not up to the standard.(该产品不符合标准。)
Orthogonality(正交性)
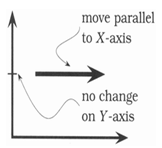
在计算技术中,该术语用于表示某种不相依赖性或是解耦性。如果两个或更多事物中的一个发生变化,不会影响其他事物,这些事物就是正交的。在设计良好的系统中,数据库代码与用户界面是正交的:你可以改动界面,而不影响数据库;更换数据库,而不用改动界面。
正交性是有助于使复杂设计也能紧凑的最重要特性之一。在纯粹的正交设计中,任何操作均无副作用;每一个动作(无论是API调用、宏调用还是语言运算)只改变一件事,不会影响其它。
标量(scalar)和向[矢]量(vector)
标量(scalar)
1、一种由单一的值来表征的(物理)量;不能再细分的单一值。
2、一个完全由其大小决定而没有方向的数量,如质量、长度或速度等。
3、 用于修饰或说明某种仅取单值的数据项,相反意义的“数组”则要取多个数据项。
向[矢]量(vector)
1. 通常由标量的一组有序集合表示的量。 如数组。一种存储结构。“中断向量表”连续存储的一组存储单元。
2. 一种具有大小和方向的量。一般来说,在物理学中称作矢量,在数学中称作向量。运算需要遵循矢量运算法则。
3. “矢量图”,它的特点是放大后图像不会失真。矢量图形是计算机图形学中用点、直线或者多边形等基于数学方程的几何图元表示图像。矢量图形与位图使用像素表示图像的方法有所不同。
literal
a. 逐字的, 字面上的, 文字的, 字母的
【计】 文字; 直接量; 字面量。
literal 就是字面的(照字面本义的)、文字的 意思。也就是说,某个数值就是他本身,不能变的意思。
也就是“字面常量”(literal constant:字面常量、文字常数)。字面常量 包括:整形常量,字符型常量,字符串常量。
比如,字面上3.0是一个双精度浮点数,"a"是一个字符。
不要将字面常量和符号常量混淆。符号常量指用名称表示的常量(有名常量)。在C语言中可用#define和const定义符号常量。如const int a = 10; 就定义了一个代表字面常量10的符号常量a。
c语言定义常量:
使用#define定义常量,格式:#define常量名 值
使用const定义常量,格式:const 类型名 常量名=值;
Graphics(图形)、image(图像)、Picture(图片)
Graphics(图形)是指由外部轮廓线条构成的矢量图。即由计算机绘制的直线、圆、矩形、曲线、图表等;而image(图像)是是由像素点阵构成的位图。
一、存储方式的区别:图形存储的是画图的函数;图像存储的则是像素的位置信息和颜色信息以及灰度信息,描述信息文件存储量较大。
二、缩放的区别:图形在进行缩放时不会失真,可以适应不同的分辨率;图像放大时会失真,可以看到整个图像是由很多像素组合而成的。
三、处理方式的区别:对图形,我们可以旋转、扭曲、拉伸等等;而对图像,我们可以进行对比度增强、边缘检测等等。
四、算法的区别:对图形,我们可以用几何算法来处理;对图像,我们可以用滤波、统计的算法。
五、适用场合
图形:描述轮廓不很复杂,色彩不是很丰富的对象,如:几何图形、工程图纸、CAD、3D造型软件等。
图像:表现含有大量细节(如明暗变化、场景复杂、轮廓色彩丰富)的对象,如:照片、绘图等,通过图像软件可进行复杂图像的处理以得到更清晰的图像或产生特殊效果。
六、编辑处理
图形:通常用Draw程序编辑,产生矢量图形,可对矢量图形及图元独立进行移动、缩放、旋转和扭曲等变换。主要参数是描述图元的位置、维数和形状的指令和参数。
图像:用图像处理软件(Paint、Brush、Photoshop等)对输入的图像进行编辑处理,主要是对位图文件及相应的调色板文件进行常规性的加工和编辑。但不能对某一部分控制变换。由于位图占用存储空间较大,一般要进行数据压缩。
图片(Picture)包括图形、图像。图形(Graph、Graphics)是矢量图,图像(Image)是位图(bitmap image)。
或者说,图片(Picture)分为像素图(pixel image)和矢量图(Vector graphics)两类。
像素图(pixel image)又称位图(bitmap image)、栅格图(raster image)或点阵图。照片就是像素图。像素图是由像素点的网格组成。每个像素(pixel)是一个具有特定颜色和灰度的小方块。像素图具有分辨率的概念。分辨率通常用dpi(dots per inch)表达。
矢量图(Vector graphics)使用直线和曲线描述图形和线条,构造组成图形的元素,包括点、线、多边形、圆弧等。矢量文件中的图形元素称为对象。每个对象都是一个自成一体的实体,它具有颜色、形状、轮廓、大小和屏幕位置等属性。
VB的PictureBox控件和Image控件
Picture(图片框)和Image(图像框)是Visual Basic中用来显示图形的两种基本控件,用于在窗体指定位置显示图形信息,它们支持多种格式的图形文件,包括位图文件(*.bmp,*.dib)、图标文件(*.ico)、光标文件(*.cur)、图元文件(*.wmf,*.emf),还有Internet 上流行的压缩位图格式的JPEG文件和GIF文件。
图片框和图像框在窗体上显示的方式基本相同,都可以装入图形文件。其主要区别是:image控件是一个轻量级的控件,占用系统资源很少,不能作为父控件,而且不能通过Print方法接受文本;PictureBox 控件包含了 Image 控件不具有的功能,例如:作为其它控件的容器的功能和支持图形方法(如绘图,打印)的功能。
具体而然:
图片框(Picture)和图像框(Image)都有属性Picture属性,设计时与运行时可读可写。设计时,在属性窗口为picture属性指定图形文件或把一个图片粘贴到图片框或图像框上;运行时,加载图片的方法较多:使用LoadPicture函数指定图片文件名;对象间图片属性的相互复制;从剪贴板对象获取图片(Clipboard);使用LoadResPicture函数,通过指定工程中.res资源文件中某一图片的资源号ID获得图片。
(1)图像框适用于静态图像,不具有绘图功能;图片框具有图像框控件所没有的画图属性和图形方法(Print、Line、Circle、Cls)。
(2)图片框具有容器功能;而图像框不具有。
(3)图像框具有Stretch属性,可以改变图像控件中图像的纵横比;而图片框中图像比例不可改变。
(4)图片框具有AutoSize属性;而图像框没有。
(5)图片框有AutoRedraw属性,决定是否重画由图形方法产生的图形,而图像框不具有。图片框的AutoRedraw属性默认值为False,这时由图形方法产生的图形为临时图形。临时图形可以被其他窗体覆盖后擦除,也可以使用Cls方法擦除,在其窗体变小或隐藏后图形得不到恢复。AutoRedraw属性设置为Ture后,由图形方法产生的图形或文本为持久图形。持久图形能在以上各种情况下自动重绘输出,也不能用Cls方法擦除,要擦除持久图形需重新设置BackColor属性。
别名(alias)
(1)在 SQL的语句中紧跟在AS后的标识符, 其作用是标识“列”的新名。
(2)在VB或VBA的 Declare 语句中紧跟在Alias后的标识符,其作用是用于标识“API函数”的原名。
SQL,可以为列名称和表名称指定别名(Alias)。别名使SQL更易阅读或书写。
使用表名称别名
假设我们有两个表分别是:"Persons" 和 "Product_Orders"。我们分别为它们指定别名 "p" 和 "po"。
现在,我们希望列出 "John Adams" 的所有定单。
我们可以使用下面的 SELECT 语句:
SELECT po.OrderID, p.LastName, p.FirstName
FROM Persons AS p, Product_Orders AS po
WHERE p.LastName='Adams' AND p.FirstName='John'
不使用别名的 SELECT 语句:
SELECT Product_Orders.OrderID, Persons.LastName, Persons.FirstName
FROM Persons, Product_Orders
WHERE Persons.LastName='Adams' AND Persons.FirstName='John'
使用列名别名
表 Persons:
| Id | LastName | FirstName | Address | City |
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
SQL:
SELECT LastName AS Family, FirstName AS Name
FROM Persons
结果:
| Family | Name |
| Adams | John |
| Bush | George |
| Carter | Thomas |
VB的 Declare 语句中,Alias关键字被用于记录DLL 函数的原型,可以使用其他名称重命名函数。
Declare 语句格式
Private | Public Declare Function | Sub name1 Lib "libName" [ Alias "name2" ] ( ByVal 参数1 As 数据类型 , ByVal 参数2 As 数据类型 ) As 数据类型
当DLL中的例程(过程或函数)名不符合VB或VBA中的规定,不能直接使用时,或想用一个简短的名字,就需要使用Alias "name2"。
如果使用 Alias 关键字,Alias 关键字的后面是DLL中的例程(过程或函数)的真实名称,而Function|Sub 关键字后面的名称,也就是你根据需要命名的名称,能作为调用名使用。如果没有使用Alias 关键字,Function|Sub 关键字的后面是是DLL中的例程(过程或函数)真实名称,作为调用名使用。
对于Declare 语句的Alias许多资料对此讲述模糊不明,请仔细理解之。
斜杠/和反斜杠\
在Unix/Linux操作系统的路径,网址、Url地址分隔采用正斜杠“/”,比如/home/hutaow。
DOS操作系统的命令,采用反斜杠\ 作为路径分隔符,斜杆/ 作为DOS命令提示符的参数标志。在Windows操作系统中,路径分隔采用反斜杠\(也可用斜杆/),比如C:\Windows\System。
通用命名约定 (UNC):一种对文件的命名约定,它提供了独立于机器的文件定位方式。UNC 名称使用 \\server\share\path\filename 这一语法格式,而不是指定驱动器符和路径。
统一资源定位符 (URL):一种地址,指定协议(如 HTTP 或 FTP)以及文件、目录、HTML 页、图像、程序等目标在本地或网络计算机上的位置,格式scheme://server/path/resource。
程序设计语言如C、C#等中,算术运算符/用来取商,表示除法,如5/2=2.5 ,反斜杠(\)和紧跟着它的那个字符构成转义字符,如 \n(表示换行)等。
人工智能(AI、Artificial Intelligence)、机器学习(machine learning)和深度学习(deep learning)
三者的关系如图:

人工智能是最早出现的,也是最大、最外侧的部分;其次是机器学习,稍晚一点;最内侧,是深度学习,当今人工智能大爆炸的核心驱动。
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括语音识别、图像识别、机器人、自然语言处理、智能搜索和专家系统等。
人工智能可以对人的意识、思维进行模拟。人工智能不是人的智能,但能像人那样思考,有可能超过人的智能。
机器学习(Machine Learning)是指用某些算法指导计算机利用已知数据得出适当的模型,并利用此模型对新的情境给出判断的过程。
机器学习的思想并不复杂,它仅仅是对人类生活中学习过程的一个模拟。而在这整个过程中,最关键的是数据。
任何通过数据训练的学习算法的相关研究都属于机器学习,包括很多已经发展多年的技术,比如线性回归(Linear Regression)、K均值(K-means,基于原型的目标函数聚类方法)、决策树(Decision Trees,运用概率分析的一种图解法)、随机森林(Random Forest,运用概率分析的一种图解法)、PCA(Principal Component Analysis,主成分分析)、SVM(Support Vector Machine,支持向量机)以及ANN(Artificial Neural Networks,人工神经网络)。
深度学习(Deep Learning)的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。