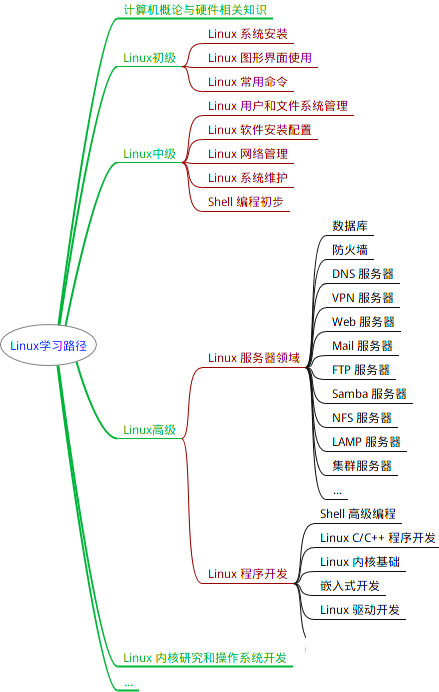
最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
| — | — | — |
| 操作 | 示例 | 含义解析 |
| 输出文本 | sed ‘1p’ a.txt 或 sed -n ‘p’ a.txt | 输出所有行,等同于cat a.txt |
| sed -n ‘1p’ a.txt | 输出第1行 |
| sed -n ‘4p’ a.txt | 输出第4行 |
| sed -n ‘
p
′
a
.
t
x
t
∣
输出最后一行
∣
∣
s
e
d
−
n
′
5
,
p' a.txt | 输出最后一行 | | sed -n '5,
p′ a.txt∣输出最后一行∣∣sed −n ′5,p’ a.txt | 从第5行输出到最后一行 |
| sed -n ‘4,7p’ a.txt | 输出第4~7行 |
| sed -n ‘4,+10p’ a.txt | 输出第4行及其后的10行内容,共11行 |
| sed -n '2p**;5p;7p’ a.txt sed -n '{2p;5p;7p}’ a.txt | 输出第2,5,7行 用分号来隔离多个操作(如果有定址条件,则应该使用{ }括起来) |
| sed -n ‘/a/p’ a.txt | |
| sed -n ‘/A/p’ a.txt | |
| sed -n ‘/^id/p’ a.txt | 列出以id开头的行: |
| sed -n ‘/a/p;/r/p’ a.txt | |
| sed -n ‘/local
/
p
′
a
.
t
x
t
∣
输出以
l
o
c
a
l
结尾的行
∣
∣
∗
∗
s
e
d
−
n
′
p
;
n
′
a
.
t
x
t
∗
∗
∣
输出奇数行,
n
表示读入下一行文本(隔行)
n
e
x
t
∣
∣
∗
∗
s
e
d
−
n
′
n
;
p
′
a
.
t
x
t
∗
∗
∣
输出偶数行,
n
表示读入下一行文本(隔行)
∣
∣
∗
∗
s
e
d
−
n
′
/p' a.txt | 输出以local结尾的行 | | **sed -n 'p;n' a.txt** | 输出奇数行,n表示读入下一行文本(隔行)next | | **sed -n 'n;p' a.txt** | 输出偶数行,n表示读入下一行文本(隔行) | | **sed -n '
/p′ a.txt∣输出以local结尾的行∣∣∗∗sed −n ′p;n′ a.txt∗∗∣输出奇数行,n表示读入下一行文本(隔行)next∣∣∗∗sed −n ′n;p′ a.txt∗∗∣输出偶数行,n表示读入下一行文本(隔行)∣∣∗∗sed −n ′=’ a.txt | 输出文件的行数, wc -l返回行数及文件名 |
| 删除文本 | sed -i ‘d’ a.txt | 删除所有 |
| sed -i ‘KaTeX parse error: Expected group after '^' at position 41: …| sed -i '/**^̲/d’ a.txt | 删除所有空行 |
| sed -i ‘1d’ a.txt | 删除第1行 |
| sed -i ‘2,5d’ a.txt | 删除第2~5行 |
| sed -i “
v
a
r
1
,
{var1},
var1,{var2}d” filename # 这里引号必须为双引号 | 删除shell变量表示的行号(配合for等语句使用) |
| sed -i ‘5d;7d;9d’ a.txt | 删除第5、7、9行 |
| sed -i ‘/init/d;/bin/d’ a.txt | 删除所有包含“init”及“bin”的行 |
| sed -i ‘/[0-9]/d’ a.txt | |
| sed -i ‘/^#/d’ a.txt | |
| sed -i ‘/^s/d’ a.txt | |
| sed -i ‘/^s/d’ a.txt | 直接删除 |
| sed -i ‘/^install/d’ a.txt | 删除以install开头的行 |
| sed -i ‘/xml/d’ a.txt | 删除所有包含xml的行,只作输出,不更改原文件,若需要更改,应添加选项-i |
| sed -i ‘/xml/!d’ a.txt等效于 sed -n ‘/xml/p’ a.txt | 删除不包含xml的行,!符号表示取反 |
| 替换文本 | sed ‘s/xml/XML/’ a.txt | 将每行中第1个xml替换为XML |
| sed ‘4s/xml/XML/’ a.txt | 将第4行中的xml替换为XML |
| sed ‘s/xml/XML/3’ a.txt | 将每行中第3个xml替换为XML,只作输出,不更改原文件(若需要更改,应添加选项-i) |
| sed ‘2s/xml/XML/3’ a.txt | 将第2行中第3个xml替换为XML,只作输出,不更改原文件(若需要更改,应添加选项-i) |
| sed ‘s/xml/XML/g’ a.txt | 将所有的xml都替换为XML |
| sed ‘s/xml//g’ a.txt | 将所有的xml都删除(替换为空串) |
| sed ‘s/doc/&s/g’ a.txt | 将所有的doc都替换为docs,&代表查找串 |
| sed -i ‘4,7s/^/#/’ a.txt | 将第4~7行注释掉**(行首加#号)** |
| sed -i ‘3,5s/^#//’ a.txt | 解除文件第3~5行的注释**(去掉开头的 # )** |
| sed ‘s/**^#**an/an/’ a.txt | 解除以#an开头的行的注释(去除行首的#号) |
| sed ‘s/xml|XML|e//g’ a.txt | 删除所有的“xml”、所有的“XML”、所有的字母e,或者的关系用转义方式 | 来表示 |
五、综合运用
1)删除文件中每行的第二个、最后一个字符
分两次替换操作,第一次替换掉第2个字符,第二次替换掉最后一个字符:
# sed ‘s/.//2;s/.$//’ nssw.txt
2)将文件中每行的第一个、第二个字符互换
每行文本拆分为“第1个字符”、“第2个字符”、“剩下的所有字符”三个部分,然后通过替换操作重排顺序为“2-1-3”:# sed -r ‘s/^(.)(.)(.*)/\2\1\3/’ nssw.txt
3)将第一个字符与最后一字符对调:sed -r “s/^(.)( .*)(.)$/\3\2\1/” nssw.txt
将第一个字符与最后一字符对调:sed -r “s/^(.)(.)(.*)(.)(.)$/\1\4\3\2\5/” nssw.txt
4)删除文件中所有的数字、行首的空格
因原文件内没有数字,行首也没有空格,这里稍作做一点处理,生成一个新测试文件:
# sed ‘s/o/o7/;s/l/l4/;3,5s/^/ /’ nssw.txt > nssw2.txt
# cat nssw2.txt
以nssw2.txt文件为例,删除所有数字、行首空格的操作如下:
# sed -r ‘s/[0-9]//g;s/^( )+//’ nssw2.txt
5)为文件中每个大写字母添加括号:
# sed ‘s/[A-Z]/(&)/g’ nssw.txt //使用“&”可调用s替换操作中的整个查找串
或者 # sed -r “s/([A-Z])/(\1)/g” nssw.txt
示例:修改默认运行级别
# sed -i ‘/^id:/s/3/5/’ /etc/inittab //将默认运行级别修改为5
# grep “^id:” /etc/inittab //确认修改结果
示例:修改IP地址(网段):修改IP地址的网段部分,主机地址不变。
直接修改网卡eth0的配置文件,检查原有的配置内容:
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=192.168.4.4
若希望将IP地址192.168.4.4修改为172.16.16.4,则应该定位到“IPADDR”所在的行,执行相应的替换(仅测试,尚未修改):
# sed ‘/^IPADDR/s/192.168.4.4/172.16.16.4/’ \
/etc/sysconfig/network-scripts/ifcfg-eth0 | grep “^IPADDR”
要求只修改网段地址时,可以利用扩展正则表达式的 \1、\2、……等调用,分别对应此前第1个、第2个、…… 以 ()包围的表达式所匹配的内容。
所以上述操作可以改为如下(启用扩展匹配应添加 -r 选项):
# sed -r -i ‘/^IPADDR/s/192.168.4.(.*)/172.16.16.\1/’ \
/etc/sysconfig/network-scripts/ifcfg-eth0
确认修改结果:# grep “^IPADDR” /etc/sysconfig/network-scripts/ifcfg-eth0
示例:调整httpd服务配置,更改网站根目录
由于需要替换的字符串中有 / ,为了避免与sed替换操作的分隔混淆,可以使用其他字符作为替换分隔,比如可改用“s#old#new#”的方式实现替换:
# sed -i ‘s#/var/www/html#/opt/wwwroot#’ \
/etc/httpd/conf/httpd.conf
# grep “^DocumentRoot” /etc/httpd/conf/httpd.conf
DocumentRoot “/opt/wwwroot”
示例:修改/etc/hosts :sed -i ‘1a 1.1.1.1 域名’ /etc/hosts
示例:装配匿名FTP服务
通过yum安装vsftpd软件包;修改vsftpd服务配置,开启匿名上传;调整/var/ftp/pub目录权限,允许ftp写入;启动vsftpd服务,并设置开机自运行
1)任务需求及思路分析
vsftpd服务的安装、改目录权限、起服务等操作可以直接写在脚本中。
修改vsftpd.conf配置的工作可以使用sed命令,根据默认配置,只需要定位到以#anon开头的行,去掉开头的注释即可。
2)根据实现思路编写脚本文件
#!/bin/bash
yum -y install vsftpd //安装vsftpd软件
cp /etc/vsftpd/vsftpd.conf{,.bak} //备份默认的配置文件
sed -i “/#anon/s/#//” /etc/vsftpd/vsftpd.conf //修改服务配置
chown ftp /var/ftp/pub //调整目录权限
/etc/init.d/vsftpd restart //启动服务
chkconfig vsftpd on //设为自动运行
# chmod +x anonftp.sh
3)验证、测试脚本
运行脚本anonftp.sh:
# ./anonftp.sh
使用ftp登录服务,测试是否可以上传:
# ftp localhost //本机访问测试
……
Name (localhost:root): ftp //匿名登录
……
ftp> cd pub //切换到 pub/ 目录
……
ftp> put install.log //上传当前目录下的install.log 文件
……
ftp> quit //断开FTP连接
查看/var/ftp/pub新上传的文件:# ls -lh /var/ftp/pub/
示例:clone-vm7脚本
#!/bin/bash
# exit code:
# 65 -> user input nothing
# 66 -> user input is not a number
# 67 -> user input out of range
# 68 -> vm disk image exists
IMG_DIR=/var/lib/libvirt/images
BASEVM=rh7_template
ROOM=sed -n "1p" /etc/hostname | sed -r 's/(room)([0-9]{1,})(.\*)/\2/'
if [ $ROOM -le 9 ];then
ROOM=0$ROOM
fi
IP=sed -n "1p" /etc/hostname | sed -r 's/(.\*)([0-9]+)(.\*)/\2/'
read -p "Enter VM number: " VMNUM
if [ $VMNUM -le 9 ];then
VMNUM=0$VMNUM
fi
if [ -z “${VMNUM}” ]; then
echo “You must input a number.”
exit 65
elif [ ( e c h o (echo (echo {VMNUM}*1 | bc) = 0 ]; then
echo “You must input a number.”
exit 66
elif [ V M N U M − l t 1 − o {VMNUM} -lt 1 -o VMNUM −lt 1 −o {VMNUM} -gt 99 ]; then
echo “Input out of range”
exit 67
fi
NEWVM=rh7_node${VMNUM}
if [ -e I M G _ D I R / IMG\_DIR/ IMG_DIR/{NEWVM}.img ]; then
echo “File exists.”
exit 68
fi
echo -en “Creating Virtual Machine disk image…\t”
qemu-img create -f qcow2 -b I M G _ D I R / . IMG\_DIR/. IMG_DIR/.{BASEVM}.img I M G _ D I R / IMG\_DIR/ IMG_DIR/{NEWVM}.img &> /dev/null
echo -e “\e[32;1m[OK]\e[0m”
#virsh dumpxml ${BASEVM} > /tmp/myvm.xml
cat /var/lib/libvirt/images/.rhel7.xml > /tmp/myvm.xml
sed -i “/ B A S E V M / s / {BASEVM}/s/ BASEVM/s/{BASEVM}/${NEWVM}/” /tmp/myvm.xml
sed -i “/uuid/s/.*</uuid>/$(uuidgen)</uuid>/” /tmp/myvm.xml
sed -i “/ B A S E V M i ˙ m g / s / {BASEVM}\.img/s/ BASEVMi˙mg/s/{BASEVM}/${NEWVM}/” /tmp/myvm.xml
sed -i “/mac /s/a1/${ROOM}/” /tmp/myvm.xml
sed -i “/mac /s/a2/${IP}/” /tmp/myvm.xml
sed -i “/mac /s/a3/${VMNUM}/” /tmp/myvm.xml
sed -i “/mac /s/b1/${ROOM}/” /tmp/myvm.xml
sed -i “/mac /s/b2/${IP}/” /tmp/myvm.xml
sed -i “/mac /s/b3/${VMNUM}/” /tmp/myvm.xml
sed -i “/mac /s/c1/${ROOM}/” /tmp/myvm.xml
sed -i “/mac /s/c2/${IP}/” /tmp/myvm.xml
sed -i “/mac /s/c3/${VMNUM}/” /tmp/myvm.xml
sed -i “/mac /s/d1/${ROOM}/” /tmp/myvm.xml
sed -i “/mac /s/d2/${IP}/” /tmp/myvm.xml
sed -i “/mac /s/d3/${VMNUM}/” /tmp/myvm.xml
echo -en “Defining new virtual machine…\t\t”
virsh define /tmp/myvm.xml &> /dev/null
echo -e “\e[32;1m[OK]\e[0m”
文件导入导出操作
基本动作:r动作应结合-i选项才会存入,否则只输出
W动作以覆盖的方式另存为新文件
| 操作符 | 用途 | 指令示例 | 指令解析 |
| r | 读取文件 | 3r b.txt | 在第3行下方插入文件b.txt |
| 4,7r b.txt | 在第4~7每一行后插入文件b.txt | ||
| w | 保存到文件 | 3w c.txt | 将第3行另存为文件c.txt |
| 4,7w c.txt | 将第4~7行另存为文件c.txt |
sed -n ‘/^XX/w d.txt’ reg.txt 与sed -n ‘/^XX/p d.txt’ reg.txt > d.txt操作效果相同
sed复制剪切
模式空间:存放当前处理的行,将处理结果输出
若当前行不符合处理条件,则原样输出
处理完当前行再读入下一行来处理
保持空间:作用类似于“剪贴板”
默认存放一个空行(换行符\n)
基本动作:
复制:H:模式空间—[追加]—>保持空间
h:模式空间—[覆盖]—>保持空间
粘贴:G:保持空间—[追加]—>模式空间
g:保持空间—[覆盖]—>模式空间
示例:把第1-3行复制到文件末尾:sed ‘1,3H;$G’a.txt
改用’1h;2,3H;$G’可避免出现空行 (出现空行的原因是保持空间内默认已有一个空行)
示例:把第2行复制第4行:# sed ‘2H;4G’ a.txt 追加出现空行
# sed ‘2h;4G’ a.txt 不要空行
示例:把第1行剪切到文件末尾:sed ‘1h,1d;$G’a.txt
把第1-2行剪切到文件末尾:sed ‘1h;2H;1,2d;$G’a.txt
sed流控制
!取反操作 ——根据定址条件取反
示例:把/etc/passwd中能登录的用户及其密码(/etc/shadow)提取出来
找到使用bash作登录Shell的本地用户;列出这些用户的shadow密码记录
按每行“用户名 --> 密码记录”保存到getupwd.log
基本思路如下:
1.先用sed工具取出登录Shell为/bin/bash的用户记录,保存为临时文件/tmp/urec.tmp,并计算记录数量
2.再结合while循环遍历取得的账号记录,逐行进行处理
3.针对每一行用户记录,采用掐头去尾的方式获得用户名、密码字串
4.按照指定格式追加到/tmp/getuupwd.log文件
5.结束循环后删除临时文件,报告分析结果
示例:列出不使用bash的用户帐号记录:
# sed -n ‘/bash$/!p’ /etc/passwd
# sed -n ‘/bash$/s/:.*//p’ /etc/passwd
# sed -n ‘/:/bin/bash$/w /tmp/urec.tmp’ /etc/passwd
方法一:
#/bin/bash
/tmp/getupwd.log ## 创建空文件
sed -n ‘/:/bin/bash$/w /tmp/urec.tmp’ /etc/passwd ## 提取符合条件的账号记录
UNUM=$(egrep -c ‘.’ /tmp/urec.tmp) ## 取得记录个数
while [ i : = 1 − l e {i:=1} -le i:=1 −le UNUM ] ## 从第1行开始,遍历账号记录
do
UREC= ( s e d − n " (sed -n " (sed −n "{i}p" /tmp/urec.tmp) ## 取指定行数的记录
NAME=${UREC%%😗} ## 截取用户名(记录去尾)
PREC=KaTeX parse error: Expected group after '^' at position 11: (sed -n "/^̲NAME:/p" /etc/shadow) ## 查找与用户名对应的密码记录
PASS=${PREC#*:} ## 掐头
PASS=${PASS%%😗} ## 去尾,只留下密码记录
echo “ N A M E − − > NAME --> NAME −−> PASS” >> /tmp/getupwd.log ## 保存结果
let i++ ## 自增1,转下一次循环
done
/bin/rm -rf /tmp/urec.tmp ## 删除临时文件
echo “用户分析完毕,请查阅文件 /tmp/getupwd.log” ## 完成后提示
# chmod +x ./getupwd.sh
步骤二:测试、验证执行结果 # ./getupwd.sh
用户分析完毕,请查阅文件 # less /tmp/getupwd.log
方法二:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!