节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
合集在这里:《大模型面试宝典》(2024版) 正式发布!
本文将从 Retrieval 的本质、Retrieval 的原理、Retrieval 的应用三个方面,带您一文搞懂 LangChain 的 Retrieval 模块。
面试准备
一、Retrieval 的本质
Retrieval 是什么?
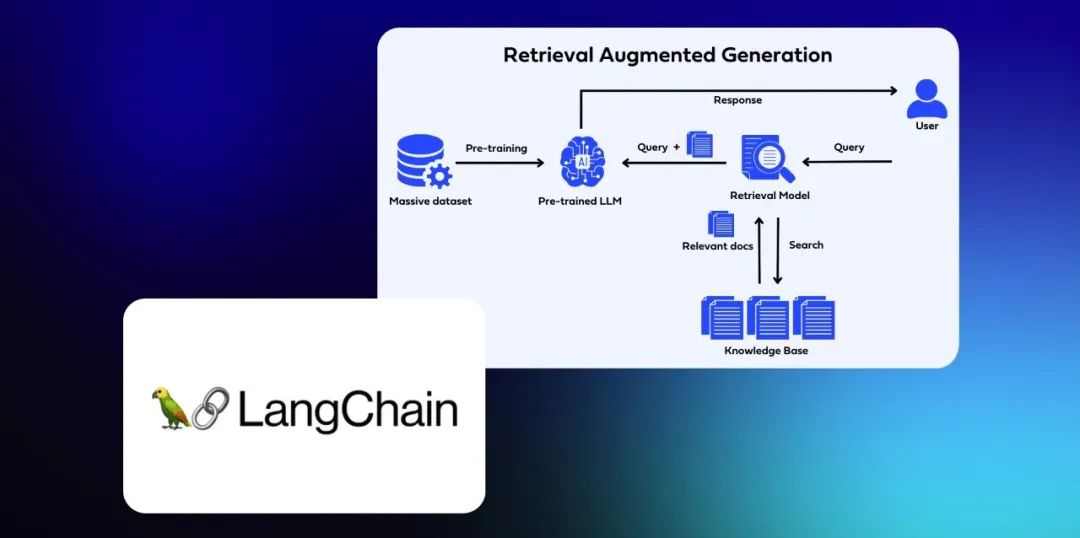
LangChain通过其Retrieval(检索)组件,简化了检索增强生成(RAG)过程中外部数据的检索与管理,为大型语言模型(LLM)应用高效地提供了用户特定的数据。
-
高效检索:快速准确地从大量数据中检索出相关信息。
-
灵活集成:适应不同数据源和数据格式的检索需求。
-
可扩展性:能够应对不断增长的数据量和查询负载。
Retrieval 由几个部分组成。
-
Document loaders:负责从各种数据源加载数据,并将其格式化为“文档”(包含文本和相关元数据)。
-
Text Splitters:用于对加载的文档进行转换,以适应应用程序的需求。
-
Text embedding models:用于将文本转换为向量表示,这使得可以在向量空间中进行语义搜索等操作。
-
Vector stores:负责存储嵌入向量,并执行向量搜索。
-
Retrievers:是一个接口,它根据非结构化查询返回文档。
-
Indexing:索引API允许您从任何数据源加载并保持文档与向量存储的同步。
Retrieval 能干什么?
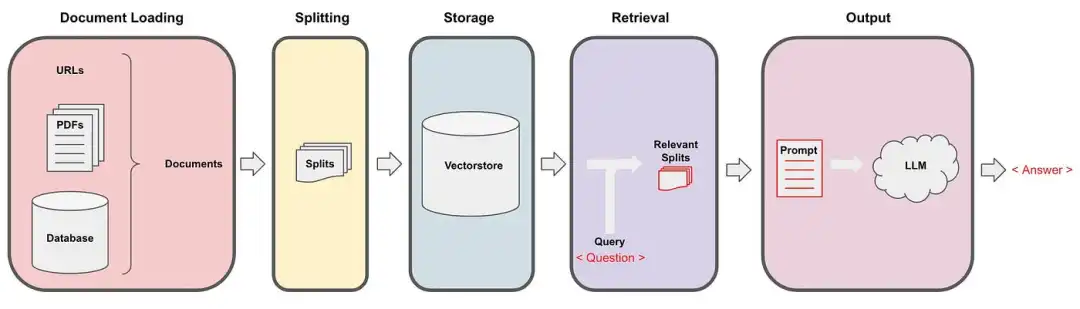
Retrieval 能够高效地处理用户查询并从多个数据源中检索相关信息。
LangChain 的数据索引是一个将原始数据转化为可高效检索格式的过程。
-
数据提取:从各类数据源中收集并整理出关键信息。
-
向量化(Embedding):将文本数据转换为数值向量,以捕获其语义信息。
-
创建索引:使用向量构建高效索引结构,支持快速查询和检索。
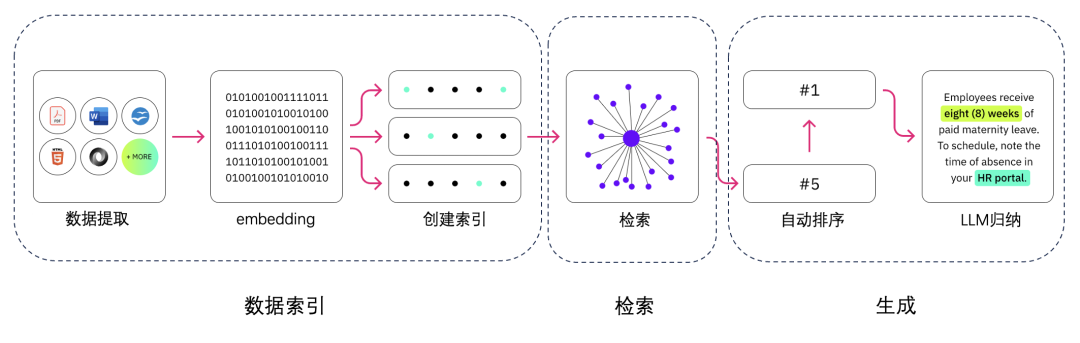
许多大型语言模型(LLM)应用需要用户特定的数据,这些数据并不是模型训练集的一部分。实现这一点的主要方法是通过检索增强生成(RAG)。
检索增强生成(RAG)的工作流程,从用户的查询开始,经过向量数据库的检索,到提示填充,最后生成回应。
-
检索(Retrieval):
-
目的:从大量文档或知识库中检索与用户查询或任务最相关的信息。
-
方法:使用信息检索技术,如倒排索引、向量搜索(如基于BERT的句向量搜索)或密集向量检索等,来查找与用户输入最相似的文档或段落。
-
输出:一组与用户查询高度相关的文档或段落。
-
-
增强(Augmentation):
-
目的:将检索到的信息有效地整合到生成过程中,以丰富模型的输出。
-
方法:可以通过多种方式实现增强,包括简单的拼接、注意力机制(如交叉注意力)、记忆网络或更复杂的融合策略。
-
输出:一个结合了原始输入和检索到的信息的增强表示,用于后续的生成步骤。
-
-
生成(Generation):
-
目的:基于增强后的信息,生成符合用户意图和查询条件的自然语言输出。
-
方法:使用条件语言模型(如Transformer架构中的解码器)来生成文本。生成过程可以是自回归的(即逐个词或逐个标记地生成文本),也可以是其他生成策略。
-
输出:最终生成的文本,它结合了用户特定的数据和模型的生成能力。
-
二、Retrieval 的原理
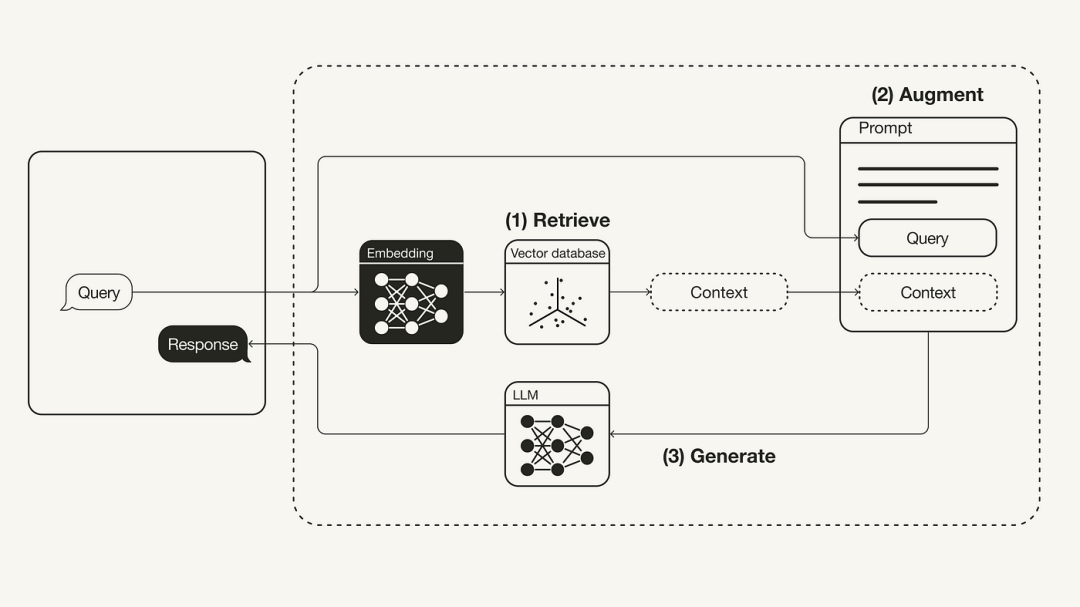
Retrieval 的工作流程:从指定来源获取并读取文档,经过预处理和向量化后,将文档存储并索引化,最终根据用户查询进行高效搜索并返回相关结果。
Retrieval 流程包含以下六个核心步骤:
-
Source(来源)
- 关键词:获取,表示从各种来源获取文档或数据。
-
Load(加载)
- 关键词:读取,代表从来源中加载并读取文档或数据的过程。
-
Transform(转换)
- 关键词:预处理,表示对加载的文档或数据进行清洗、格式化和转换,以适应后续步骤。
-
Embed(嵌入)
- 关键词:向量化,代表将文档或数据转换为向量表示,以捕捉其语义信息。
-
Store(存储)
- 关键词:索引化,表示将嵌入后的向量存储在数据库中,并建立索引以优化检索性能。
-
Retrieve(检索)
- 关键词:搜索,代表根据用户查询从存储的向量数据库中检索相关文档或数据的过程。
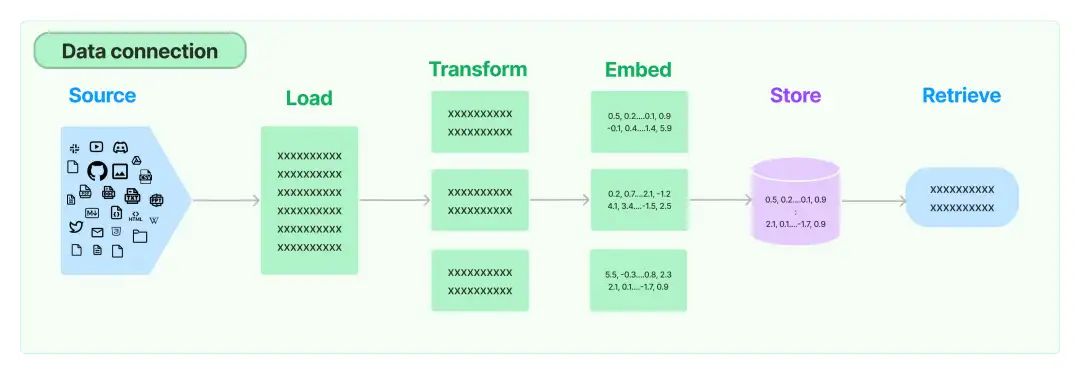
Retrieval 的核心组件:Retrieval的六个核心组件共同协作,实现文档的高效加载、精确拆分、语义嵌入、向量存储、智能检索及优化索引,为各类应用场景提供强大且灵活的文档处理与检索能力。
LangChain 文档检索和处理组成部分:
一、文档加载 (Document Loaders)
-
功能:从多种来源加载文档。
-
特性:支持100+加载器,与AirByte、Unstructured等集成。
-
应用:加载HTML、PDF、代码等,来源包括私有S3桶、公共网站等。
二、文本拆分 (Text Splitting)
-
功能:将大文档拆分为小片段,以便更精确地检索相关内容。
-
特性:提供多种拆分算法,优化特定文档类型(如代码、Markdown)。
三、文本嵌入模型 (Text Embedding Models)
-
功能:为文档创建语义嵌入,以快速找到相似文本。
-
特性:支持25+嵌入提供商和方法,包括开源和专有API。
-
优点:标准接口,方便模型切换。
四、向量存储 (Vector Stores)
-
功能:高效存储和搜索文档嵌入。
-
特性:支持50+向量存储解决方案,包括开源和云托管选项。
-
优点:标准接口,轻松切换存储方案。
五、检索器 (Retrievers)
-
功能:从数据库中检索文档。
-
特性:支持多种检索算法,包括语义搜索和高级算法(如父文档检索器、自查询检索器、集成检索器)。
-
应用:提高检索性能和准确性。
六、索引 (Indexing)
-
功能:将数据源同步到向量存储,避免重复和冗余。
-
特性:LangChain索引API,优化存储和检索过程。
-
优点:节省时间和成本,改善搜索结果质量。
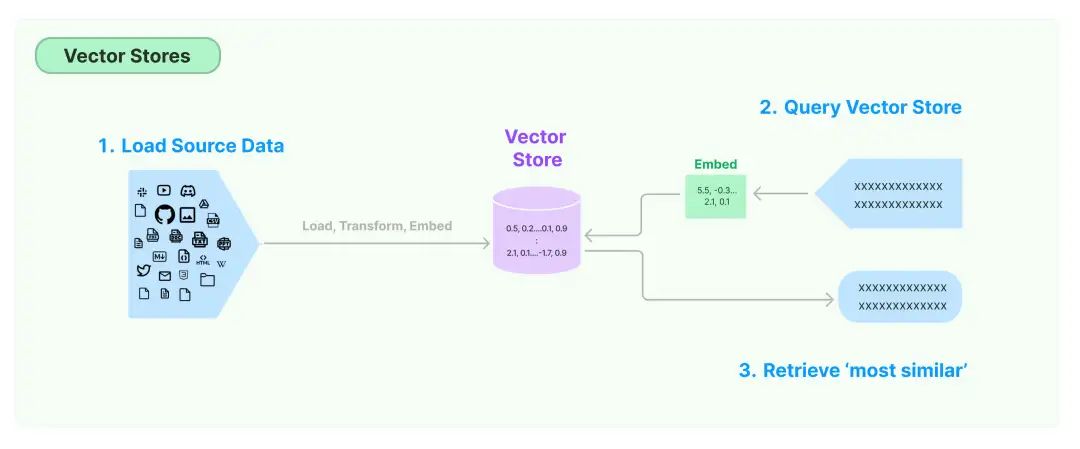
三、Retrieval 的应用
LangChain使用RAG技术构建问答(Q&A)聊天机器人的介绍和说明,包括其架构、组件以及一些构建和使用这些应用程序的指南。
架构:问答(Q&A)聊天机器人的架构通常包括两个主要部分:索引和检索与生成。
一、索引:
数据加载:首先,需要从各种源加载数据。这些数据可以是文本文件、数据库、网页等。加载数据的过程需要使用适当的加载器(如DocumentLoaders),以便将数据以适合后续处理的形式读入系统。
数据拆分:加载后的数据通常需要被拆分成较小的块或段落。这是因为大型文档难以直接搜索,并且可能无法适应模型的有限上下文窗口。拆分可以使用文本拆分器(Text Splitters)完成,它们将文档分割成更易于管理和搜索的小块。
存储与索引:拆分后的数据需要存储在可以高效检索的地方。通常,这涉及使用向量存储(VectorStore)和嵌入模型(Embeddings)。向量存储允许将数据表示为高维空间中的点,而嵌入模型则用于将这些点映射到向量空间中,以便进行相似性搜索和检索。
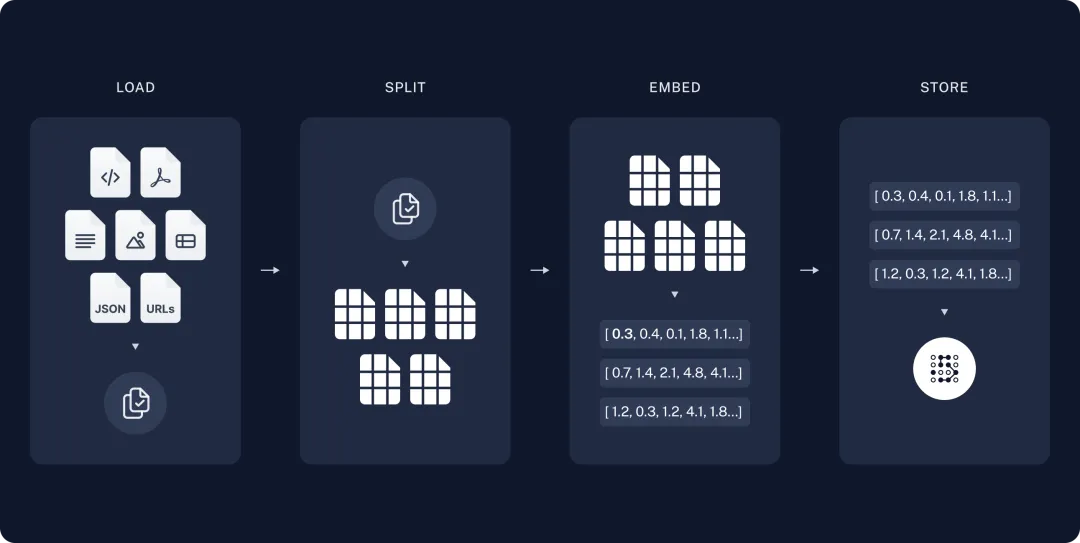
二、检索与生成:
检索:当用户输入问题时,系统需要检索与问题最相关的数据块。这通常通过使用检索器(Retriever)完成,它根据用户输入和存储在向量存储中的数据之间的相似性来检索最相关的数据。
生成:检索到的数据被传递给一个聊天模型(ChatModel)或大型语言模型(LLM),该模型使用问题和检索到的数据作为输入来生成答案。模型使用适当的提示(Prompt)来指导生成过程,以确保产生的回答与问题和检索到的数据相关。
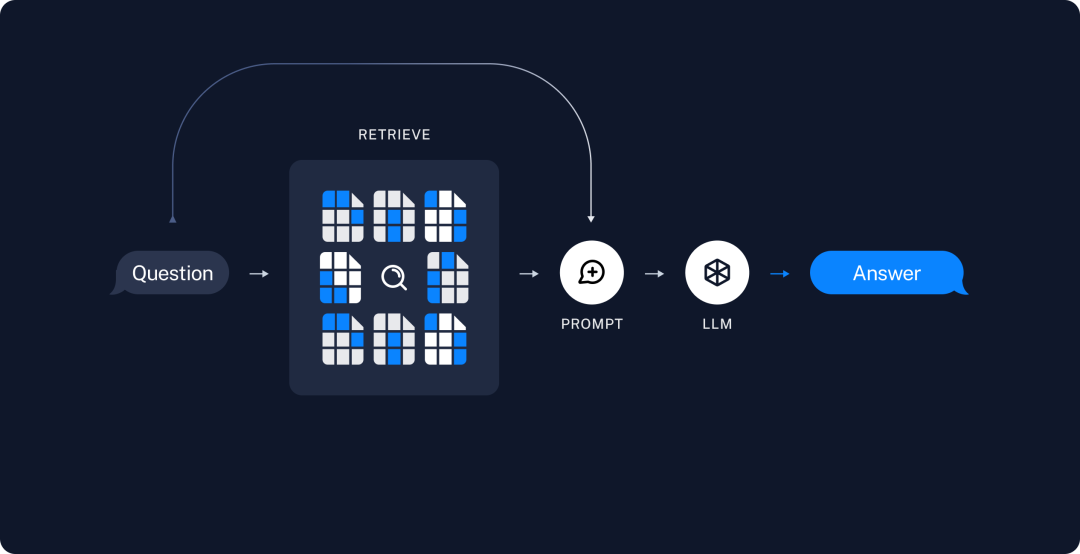
组件:问答Q&A)聊天机器人的关键组件包括:
-
DocumentLoaders:用于从各种源加载数据的组件。
-
Text Splitters:将大型文档拆分为较小块的组件。
-
VectorStore 和 Embeddings:用于存储和索引拆分后的数据,并支持相似性搜索和检索的组件。
-
Retriever:根据用户输入检索最相关数据块的组件。
-
ChatModel / LLM:使用检索到的数据和用户问题生成答案的模型。
构建和使用指南
-
快速入门:建议从快速入门指南开始,以了解如何设置和使用问答聊天机器人的基本功能。这通常涉及安装必要的库、配置索引和检索组件以及运行示例代码。
-
返回源文档:了解如何在生成答案时返回使用的源文档。这对于提供答案的上下文和验证答案的准确性非常有用。
-
流式处理:学习如何流式传输最终答案以及中间步骤。这对于处理大型数据集或需要逐步构建答案的复杂查询特别有用。
-
添加聊天历史:了解如何将聊天历史添加到问答应用程序中。这可以提高用户体验,允许用户在对话中引用先前的问题和答案。
-
每个用户的检索:如果每个用户都有自己的私有数据,需要了解如何为每个用户执行独立的检索操作。这涉及在索引和检索过程中考虑用户身份和权限。
-
使用代理:了解如何使用代理来增强问答功能。代理可以提供额外的上下文、执行更复杂的任务或与其他系统进行交互。
-
使用本地模型:对于需要更高性能或隐私要求的应用程序,了解如何使用本地模型进行问答操作。这涉及在本地环境中部署和运行模型,而不是依赖于云服务或外部API。