web浏览器中的javascript
- 客户端javascript
- 在html里嵌入javascript
- javascript程序的执行
- 兼容性和互用性
- 可访问性
- 安全性
- 客户端框架
- 开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】

window对象
-
计时器
-
浏览器定位和导航
-
浏览历史
-
浏览器和屏幕信息
-
对话框
-
错误处理
-
作为window对象属性的文档元素
1) 给出N 个小写英文字母串,以及Q 个询问,即询问某两个串的最长公共前缀的长度是多少. 解决方案:
首先对所有的串建立其对应的字母树。此时发现,对于两个串的最长公共前缀的长度即它们所在结点的公共祖先个数,于是,问题就转化为了离线(Offline)的最近公共祖先(Least Common Ancestor,简称LCA)问题。
而最近公共祖先问题同样是一个经典问题,可以用下面几种方法:
1. 利用并查集(Disjoint Set),可以采用经典的Tarjan 算法;
2. 求出字母树的欧拉序列(Euler Sequence )后,就可以转为经典的最小值查询(Range Minimum Query,简称RMQ)问题了;
3. 排序
Trie树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
举例:给你N 个互不相同的仅由一个单词构成的英文名,让你将它们按字典序从小到大排序输出。
4. 作为其他数据结构和算法的辅助结构
如后缀树,AC自动机等。
举例
下面以字典树的构建与单词查找为例。
TrieTreeNode.java
package cn.edu.ujn.trieTree;
public class TrieTreeNode {
int nCount; //记录该字符出现次数
char ch; //记录该字符
TrieTreeNode[] child; // 记录子节点
final int MAX_SIZE = 26;
public TrieTreeNode() {
nCount=1;
child = new TrieTreeNode[MAX_SIZE];
}
}
TrieTree.java
package cn.edu.ujn.trieTree;
public class TrieTree {
//字典树的插入和构建
public void createTrie(TrieTreeNode node,String str){
if (str == null || str.length() == 0) {
return;
}
char[] letters = str.toCharArray();
for (int i = 0; i < letters.length; i++) {
int pos = letters[i] - 'a'; // 用相对于a字母的值作为下标索引,也隐式地记录了该字母的值
if (node.child[pos] == null) {
node.child[pos] = new TrieTreeNode();
}else {
node.child[pos].nCount++;
}
node.ch = letters[i];
node = node.child[pos];
}
}
//字典树的查找
public int findCount(TrieTreeNode node,String str){
if (str == null || str.length() == 0) {
return -1;
}
char[] letters = str.toCharArray();
for (int i = 0; i < letters.length; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
return 0;
}else {
node = node.child[pos];
}
}
return node.nCount;
}
}
Test.java
package cn.edu.ujn.trieTree;
public class Test {
public static void main(String[] args) {
/**
* Problem Description 老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计
* 出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
*/
String[] strs = { "banana", "band", "bee", "absolute", "acm" };
String[] prefix = { "ba", "b", "band", "abc" };
TrieTree tree = new TrieTree();
TrieTreeNode root = new TrieTreeNode();
for (String s : strs) {
tree.createTrie(root, s);
}
// tree.printAllWords();
for (String pre : prefix) {
int num = tree.findCount(root, pre);
System.out.println(pre + " " + num);
}
}
}
小结
看过上面的代码,是否发现这个代码有什么问题呢?尽管这个实现方式查找的效率很高,时间复杂度是O(m),m是要查找的单词中包含的字母的个数。但是确浪费大量存放空指针的存储空间。因为不可能每个节点的子节点都包含26个字母的。所以对于这个问题,字典树存在的意义是解决快速搜索的问题,所以采取以空间换时间的作法也毋庸置疑。
Trie树占用内存较大,例如:处理最大长度为20、全部为小写字母的一组字符串,则可能需要 2620 个节点来保存数据。而这样的树实际上稀疏的十分厉害,可以采用左儿子右兄弟的方式来改善,也可以采用需要多少子节点则添加多少子节点来解决(不要类似网上的示例,每个节点初始化时就申请一个长度为26的数组)。
Wiki上提到了采用三数组Trie(Tripple-Array Trie)和二数组Trie(Double-Array Trie)来解决该问题,此外还有压缩等方式来缓解该问题。
示例优化
TrieTreeNode.java
package cn.edu.ujn.trieTreeMap;
import java.util.HashMap;
import java.util.Map;
public class TrieNode {
int nCount; //记录该字符出现次数
Map<Character, TrieNode> childdren; // 记录子节点
public TrieNode() {
nCount = 1;
childdren = new HashMap<Character, TrieNode>();
}
}
TrieTree.java
package cn.edu.ujn.trieTreeMap;
// 利用Map动态创建节点
public class TrieTree {
// 字典树的插入和构建
public void insert(TrieNode node, String word) {
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.childdren.containsKey(c)) {
node.childdren.put(c, new TrieNode());
}else{
node.childdren.get(c).nCount++;
}
node = node.childdren.get(c);
}
}
// 字典树的查找
public int search(TrieNode node, String word) {
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.childdren.containsKey(c)) {
return 0;
}
node = node.childdren.get(c);
}
return node.nCount;
}
}
Test.java
package cn.edu.ujn.trieTreeMap;
public class Test {
public static void main(String[] args) {
/**
* Problem Description 老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计
* 出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
*/
String[] strs = { "banana", "band", "bee", "absolute", "acm" };
String[] prefix = { "ba", "b", "band", "abc" };
TrieTree tree = new TrieTree();
TrieNode node = new TrieNode();
for (String s : strs) {
tree.insert(node, s);
}
// tree.printAllWords();
for (String pre : prefix) {
int num = tree.search(node, pre);
System.out.println(pre + " " + num);
}
}
}
计算结果如下:

经过以上方法的改进,可避免冗余节点的存在。将字典树的优势进一步放大。当然,也可以使用左儿子右兄弟的形式创建字典树。此方法后续介绍~
文件读入
package cn.edu.ujn.trieTreeMap;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class Test {
public static void main(String[] args) {
/**
* Problem Description 老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计
* 出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
*/
String[] strs = { "banana", "band", "bee", "absolute", "acm" };
String[] prefix = { "网易", "软件", "band", "abc" };
TrieTree tree = new TrieTree();
TrieNode node = new TrieNode();
BufferedReader br = null;
try {
File file= new File("C://Users//SHQ//Desktop//Offer.txt");
//读取语料库words.txt
br = new BufferedReader(new InputStreamReader(new FileInputStream(file.getAbsolutePath()),"GBK"));
String word="";
## Vue 面试题
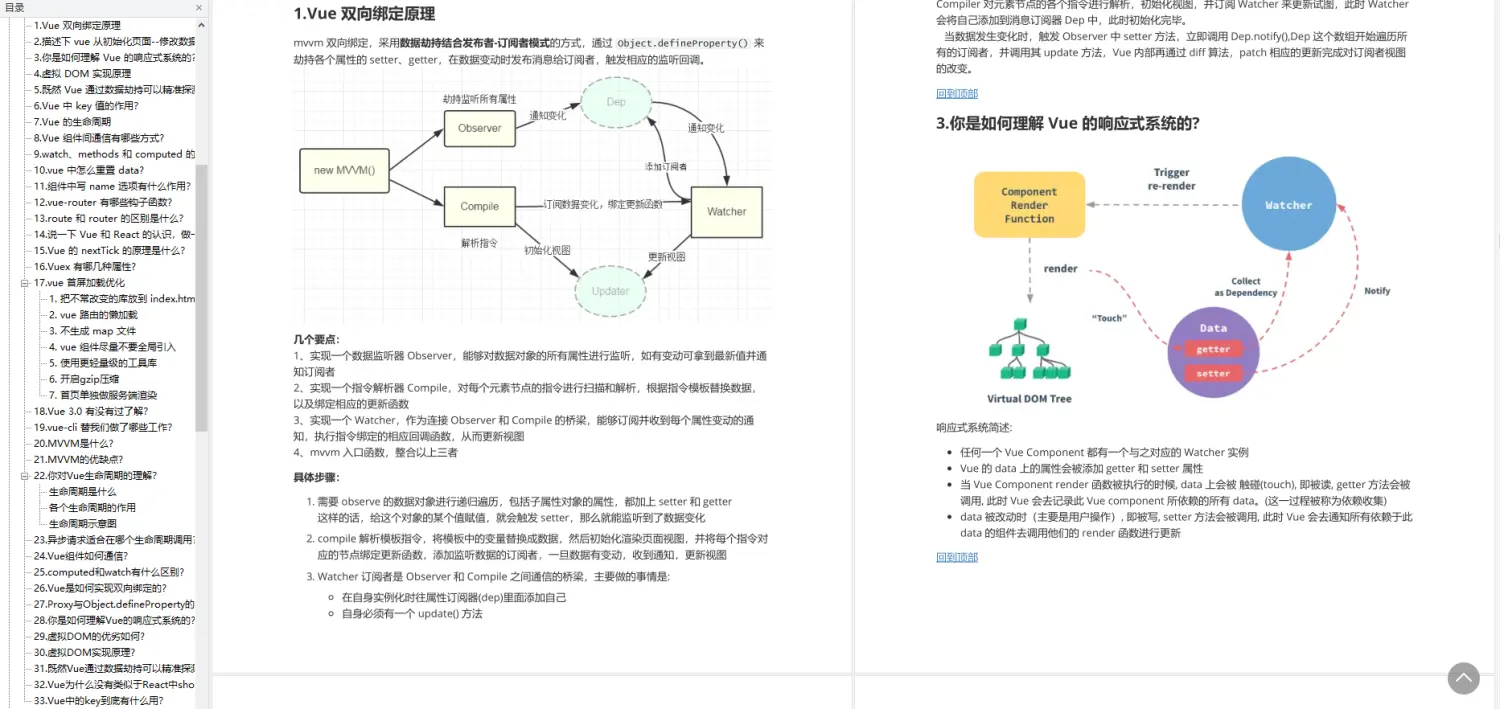
1.Vue 双向绑定原理
2.描述下 vue 从初始化页面–修改数据–刷新页面 UI 的过程?
3.你是如何理解 Vue 的响应式系统的?
4.虚拟 DOM 实现原理
5.既然 Vue 通过数据劫持可以精准探测数据变化,为什么还需要虚拟 DOM 进行 diff 检测差异?
6.Vue 中 key 值的作用?
7.Vue 的生命周期
8.Vue 组件间通信有哪些方式?
9.watch、methods 和 computed 的区别?
10.vue 中怎么重置 data?
11.组件中写 name 选项有什么作用?
12.vue-router 有哪些钩子函数?
13.route 和 router 的区别是什么?
14.说一下 Vue 和 React 的认识,做一个简单的对比
15.Vue 的 nextTick 的原理是什么?
16.Vuex 有哪几种属性?
17.vue 首屏加载优化
18.Vue 3.0 有没有过了解?
19.vue-cli 替我们做了哪些工作?
**[如果你觉得对你有帮助,可以戳这里获取:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
11.组件中写 name 选项有什么作用?
12.vue-router 有哪些钩子函数?
13.route 和 router 的区别是什么?
14.说一下 Vue 和 React 的认识,做一个简单的对比
15.Vue 的 nextTick 的原理是什么?
16.Vuex 有哪几种属性?
17.vue 首屏加载优化
18.Vue 3.0 有没有过了解?
19.vue-cli 替我们做了哪些工作?
[外链图片转存中...(img-zgo5gB1T-1715886291406)]
**[如果你觉得对你有帮助,可以戳这里获取:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**