实战:获取豆瓣电影top250的电影名字
1.获取url:打开网站按发f12,点击网络,刷新找到第一个截取url和User-Agent。
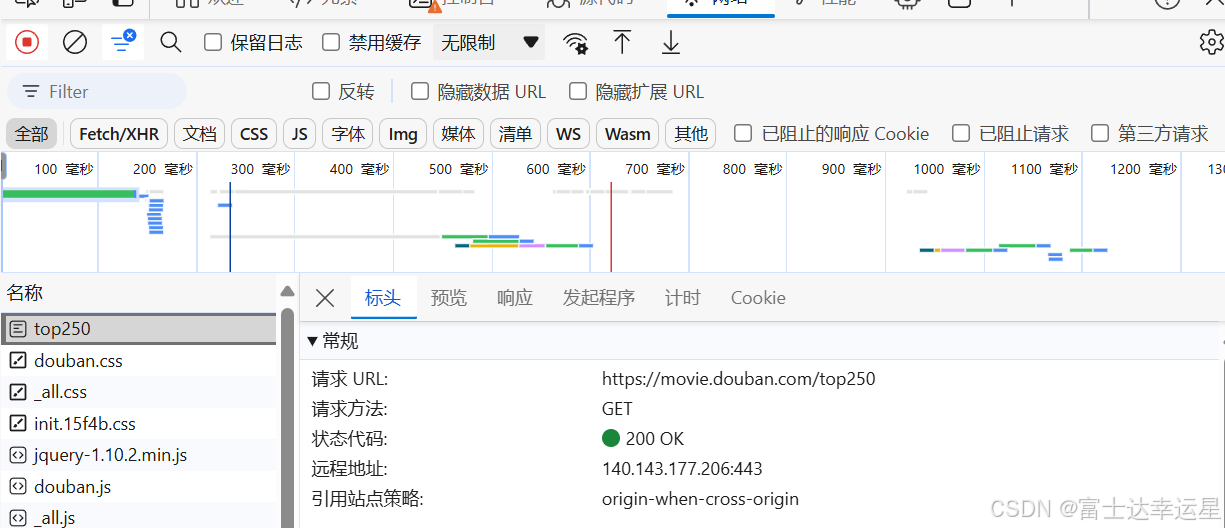
2.请求爬取数据
mport requests
import fake_useragent
from lxml import etree
import re
#UA
head = {
"User-Agent": fake_useragent.UserAgent().random
}#这里使用了fake_useragent,会自动生成一个user-agent
url = "https://movie.douban.com/top250"
response = requests.get(url, headers=head)2.定位想要的数据(其他数据也可以,同样找地址)

在元素中定位(列表一般都是有序的,所以只用定位一个例子)

response = requests.get(url, headers=head)
res_text = response.text
tree = etree.HTML(res_text)
#定位需要的数据
list_li=tree.xpath("//ol[@class='grid_view']/li")
for li in list_li:
movie_name="".join(li.xpath(".//span[@class='title'][1]/text()"))我们进入下一个页面,发现下一个页面多了start=25的参数,可判断下下个页面是start=50,以此类推,可以通过遍历访问每一个页面。
https://movie.douban.com/top250?start=25&filter=for i in range(0, 250, 25):
url = f"https://movie.douban.com/top250?start={i}&filter="修改url
3.输出并储存:
# 打开一个文件写入数据
fp = open("./doubanFilm.txt", "w", encoding="utf8")
fp.write(movie_name+"\n")
print(movie_name)
fp.close()总结:将每一步整合:
import requests
import fake_useragent
from lxml import etree
#UA
head = {
"User-Agent": fake_useragent.UserAgent().random
}
# 打开一个文件写入数据
fp = open("./doubanFilm.txt", "w", encoding="utf8")
for i in range(0, 250, 25):
url = f"https://movie.douban.com/top250?start={i}&filter="
response = requests.get(url, headers=head)
res_text = response.text
tree = etree.HTML(res_text)
#定位需要的数据
list_li=tree.xpath("//ol[@class='grid_view']/li")
for li in list_li:
movie_name="".join(li.xpath(".//span[@class='title'][1]/text()"))
fp.write(movie_name+"\n")
print(movie_name)
fp.close()运行:

运行成功,想要其他的数据也是可行的,只需找到需要的地址,以一个为例即可,每个的规律相同
爬虫重在仔细,耐心。