[ 基本难度系数 ]:★★☆☆☆
一、程序编译过程
(1)、编写源程序(.c文件.cpp文件等),可否直接在ubuntu、开发板上运行起来

(2)、程序编译过程说明
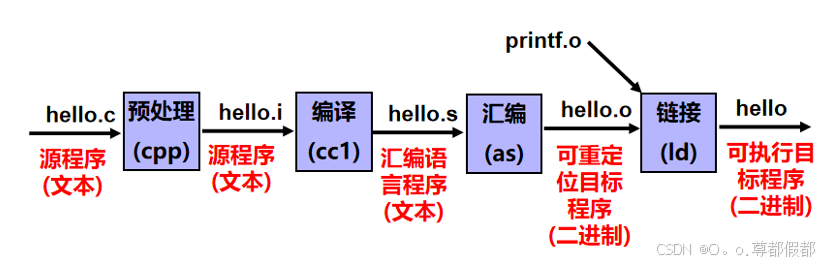
a、编译过程-预处理(cpp:Cpreprocesser:C的预处理器)
说明:预处理程序对源文件中以字符#开头的命令进行处理,例如:#include命
令后面的.h文件内容,嵌入到源程序文件中(对#做替换:头文件、宏,去掉注释,条件编译)
注意:预处理程序的输出结果还是一个源程序文件,以.i为扩展名
命令:
Ubuntu(x86-64):gcc hello.c -o hello.i -E
开发板(ARM): arm-linux-gcc hello.c -o hello.i -E现象(arm-linux-gcc编译,用Sublime Text 3打开):
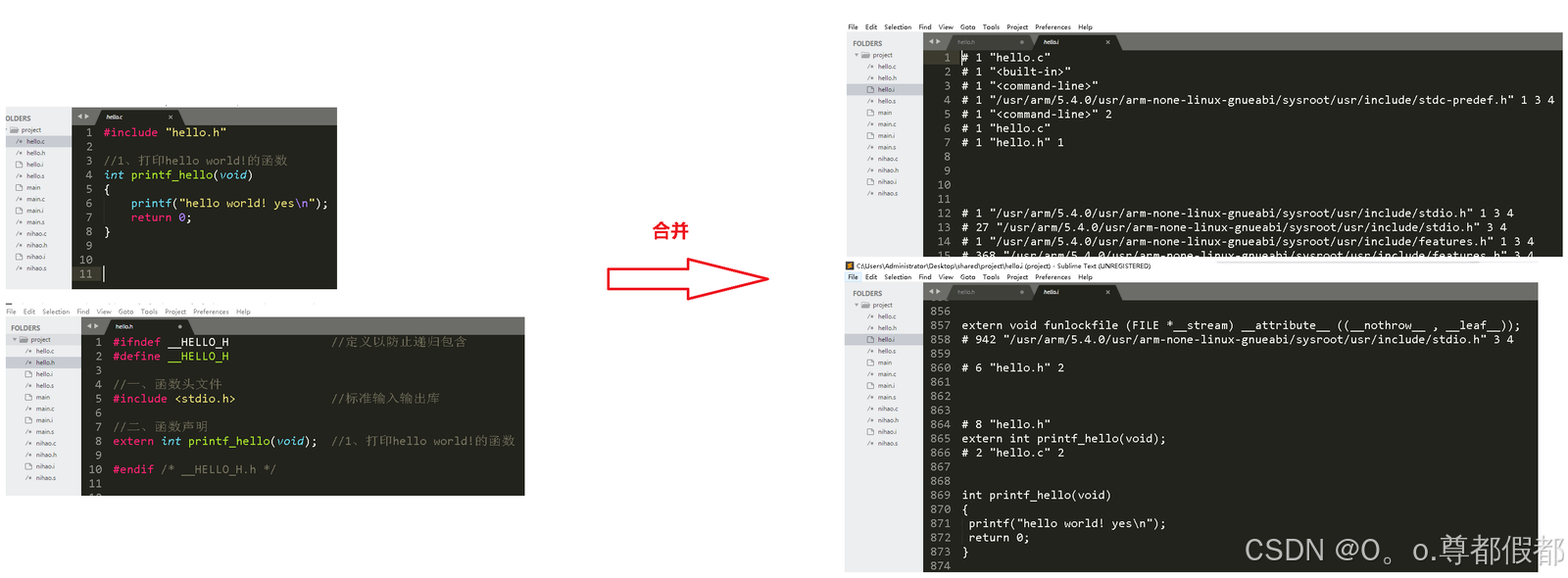
b、编译过程-编译(将C/C++源文件编译为汇编语言源文件)
说明:编译程序对预处理后的源程序进行编译,生成一个汇编语言
源程序文件,以.s为扩展名。
注意:汇编语言与处理器的体系架构有关
命令:
Ubuntu(x86-64): gcc hello.i -o hello.s -S
开发板(ARM): arm-linux-gcc hello.i -o hello.s -S现象(arm-linux-gcc编译,用Sublime Text 3打开):
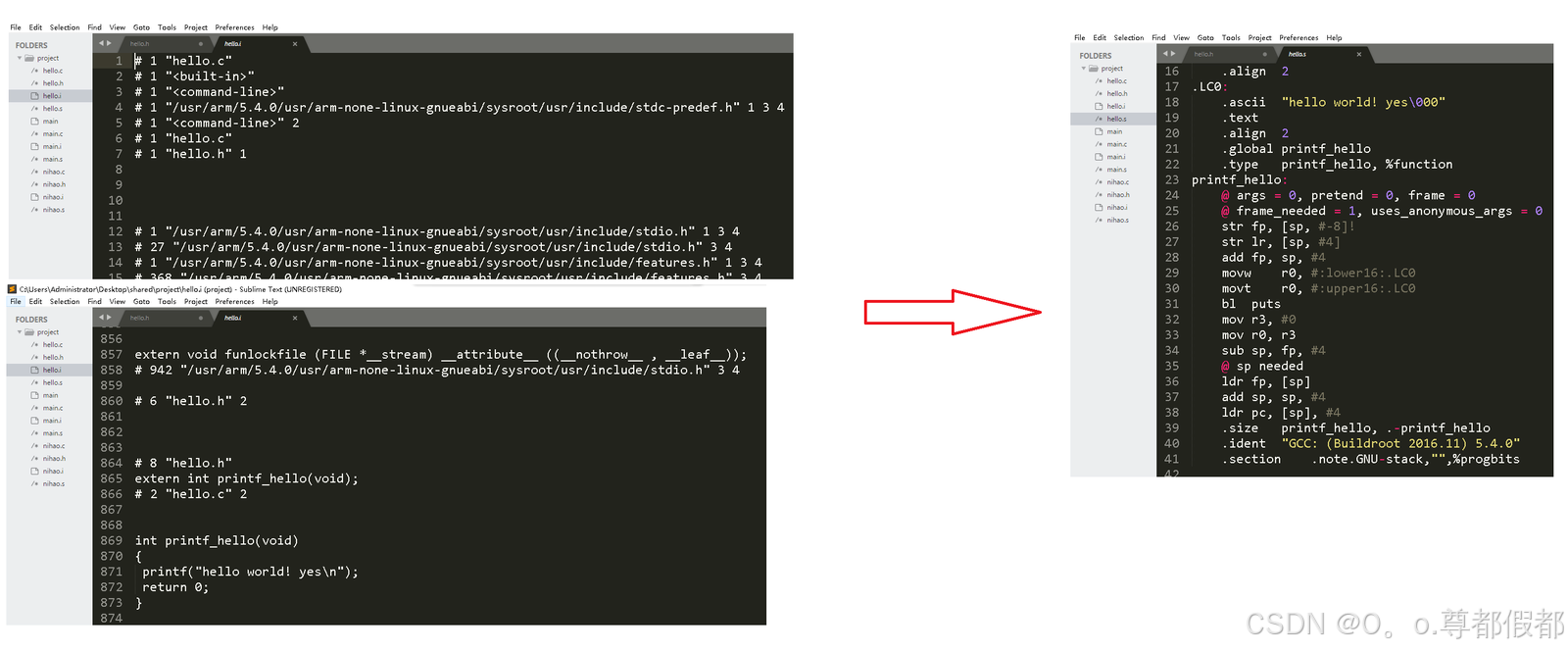
c、编译过程-汇编(as:assembly)
说明:汇编程序对汇编语言源程序进行汇编,生成一个可重定位目
标文件,以.o为扩展名,
注意:目标文件是一个二进制文件,其中的代码已经是机器指
令。代码、数据、或者其他信息使用二进制表示
命令:
Ubuntu(x86-64): gcc hello.s -o hello.o -c(注意:是小写c)
开发板(ARM): arm-linux-gcc hello.s -o hello.o -c(注意:是小写c)现象(arm-linux-gcc编译,用UltraEdit、Sublime Text 3打开):
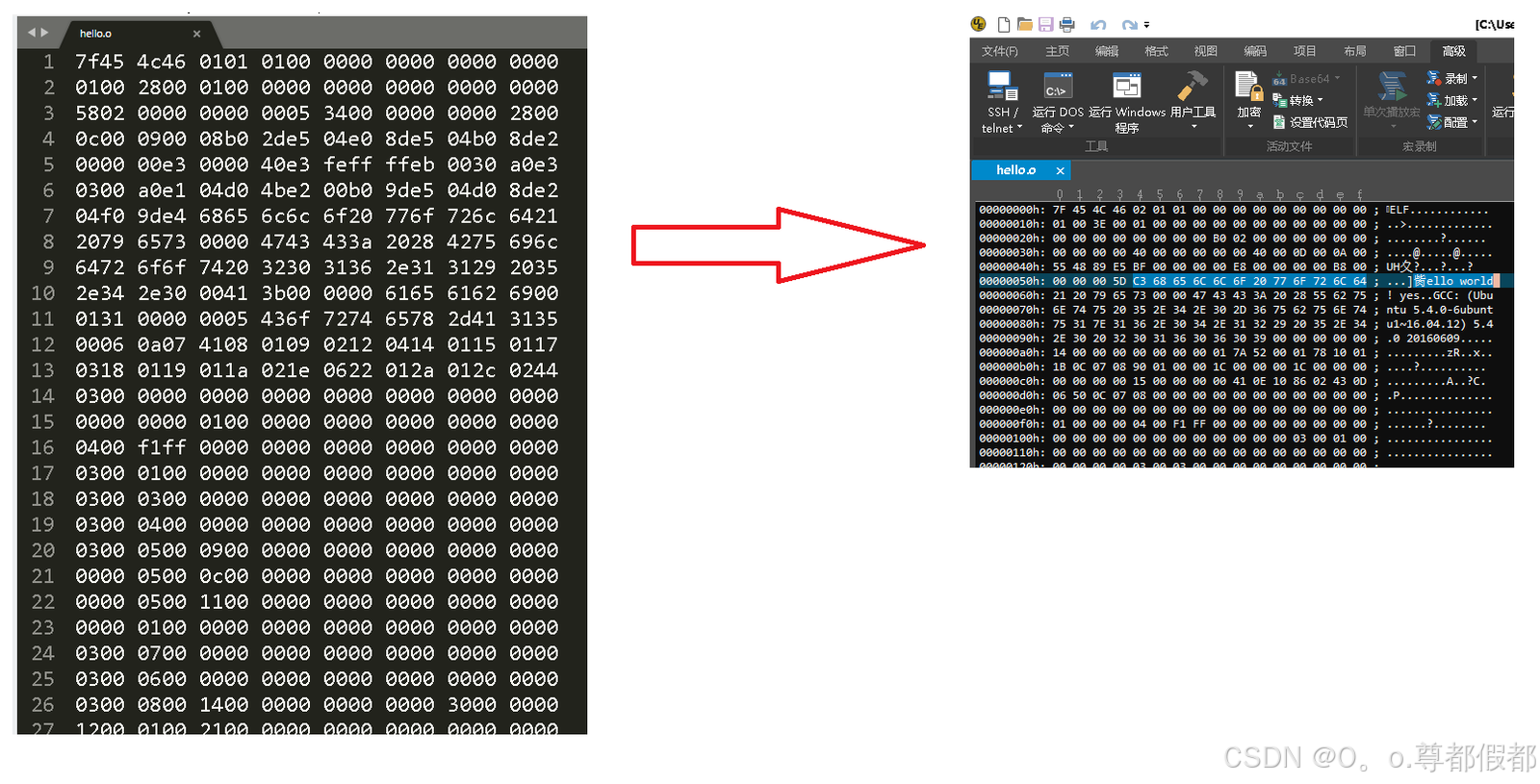
d、编译过程-链接
说明:链接程序将多个可重定位目标文件和函数库中的可重定位
目标文件合并
注意:成为一个可执行文件。可执行文件有elf、hex、bin等格式的。
命令:
Ubuntu(x86-64): gcc hello.o -o hello
开发板(ARM): arm-linux-gcc hello.o -o hello现象(arm-linux-gcc编译,用UltraEdit、Sublime Text 3打开):
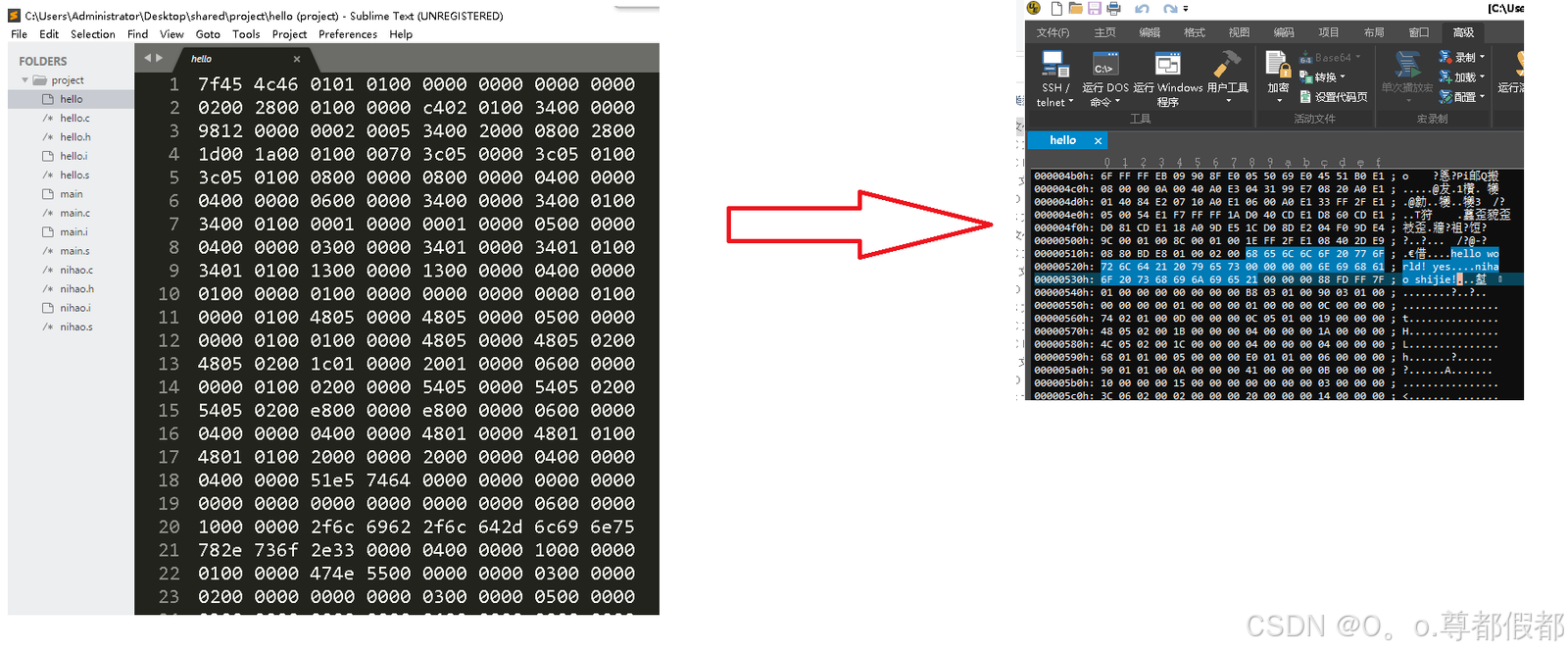
//注意:
1、如果想要和其他程序文件(如:main.c、nihao.c)进行编译,也需要和上述
步骤一致生成(main.o、nihao.o),因为这样后面更改程序时,只需要对其中
单个程序进行更改,而无需重新编译所有程序
二、预处理
(1)、预处理的说明
在C语言程序源码中,凡是以井号(#)开头的语句被称为预处理语句,这些语句严格意义上并不属于C语言语法的范畴,它们在编译的阶段统一由所谓预处理器(cpp)来处理。所谓预处理,顾名思义,指的是真正的C程序编译之前预先进行的一些处理步骤,这些预处理指令包括:
- 头文件:#include
- 定义宏:#define
- 取消宏:#undef
- 条件编译:#if、#ifdef、#ifndef、#else、#elif、#endif
- 显示错误:#error
- 修改当前文件名和行号:#line
- 向编译器传送特定指令:#progma(stm32)
- 基本语法:
- 一个逻辑行只能出现一条预处理指令,多个物理行需要用反斜杠(\)连接成一个逻辑行
- 说明:
- 预处理是整个编译全过程的第一步:预处理(预处理指令)- 编译(C语言、C++) - 汇编(汇编语言) - 链接(将各个.o的可链接文件,汇总成一个可执行文件)
- 示例: 可以通过如下编译选项来指定来限定编译器只进行预处理操作:
gcc example.c -o example.i -E(2)、宏的说明
1、宏的概念
宏(macro)实际上就是一段特定的字串,在源码中用以替换为指定的表达式。例如:
#define PI 3.14此处,PI 就是宏(宏一般习惯用大写字母表达,以区分于变量和函数,但这并不是语法规定,只是一种习惯),是一段特定的字串,这个字串在源码中出现时,将被替换为3.14。例如:
int main()
{
printf("圆周率: %f\n", PI);
// 此语句将被替换为:printf("圆周率: %f\n", 3.14);
}- 宏的作用:
- 使得程序更具可读性:字串单词一般比纯数字更容易让人理解其含义。
- 使得程序修改更易行:修改宏定义,即修改了所有该宏替换的表达式。
- 提高程序的运行效率:程序的执行不再需要进行切换而是就地展开。节省函数切换开销
2、无参宏
无参宏意味着使用宏的时候,无需指定任何参数,比如:
#define PI 3.14
#define SCREEN_SIZE 800*480*4
int main()
{
// 在代码中,可以随时使用以上无参宏,来替代其所代表的表达式:
printf("圆周率: %f\n", PI);
mmap(NULL, SCREEN_SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, ...);
}注意到,上述代码中,除了有自定义的宏,还有系统预定义的宏:
// 自定义宏:
#define PI 3.14
#define SCREEN_SIZE 800*480*4
// 系统预定义宏
#define NULL ((void *)0)
#define PROT_READ 0x1 /* Page can be read. */
#define PROT_WRITE 0x2 /* Page can be written. */
#define MAP_SHARED 0x01 /* Share changes. */宏的最基本特征是进行直接文本替换,以上代码被替换之后的结果是:
int main()
{
printf("圆周率: %f\n", 3.14);
mmap(((void *)0), 800*480*4, 0x1|0x2, 0x01, ...);
}3、带参宏
带参宏意味着宏定义可以携带“参数”,从形式上看跟函数很像,例如:
#define MAX(a, b) a>b ? a : b
#define MIN(a, b) a<b ? a : b以上的MAX(a,b) 和 MIN(a,b) 都是带参宏,不管是否带参,宏都遵循最初的规则,即宏是一段待替换的文本,例如在以下代码中,宏在预处理阶段都将被替换掉:
int main()
{
int x = 100, y = 200;
printf("最大值:%d\n", MAX(x, y));
printf("最小值:%d\n", MIN(x, y));
// 以上代码等价于:
// printf("最大值:%d\n", x>y ? x : y);
// printf("最小值:%d\n", x<y ? x : y);
}- 带参宏的特点:
-
- 直接文本替换,不做任何语法判断,更不做任何中间运算。
- 宏在编译的第一个阶段就被替换掉,运行中不存在宏。
- 宏将在所有出现它的地方展开,这一方面浪费了内存空间,另一方面有节约了切换时间。
解析:
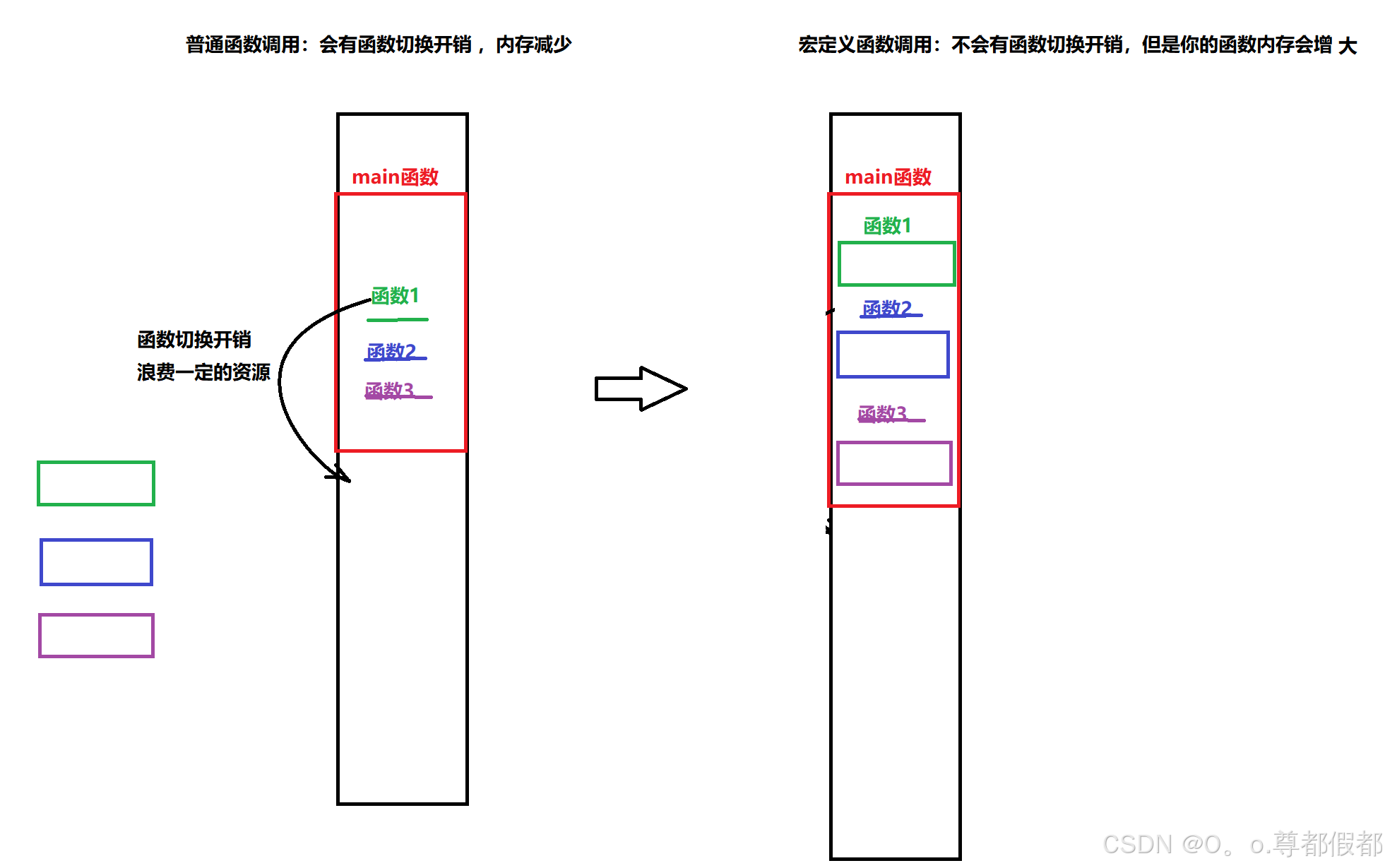
4、宏定义中的符号粘贴
有些时候,宏参数中的符号并非用来传递数据,而是用来形成多种不同的字串,例如在某些系统函数中,系统本身规范了函数接口的部分标准,形如:
void __zinitcall_service_1(void)
{
...
}
void __zinitcall_service_2(void)
{
...
}
void __zinitcall_feature_1(void)
{
...
}
void __zinitcall_feature_2(void)
{
...
}此时,若需要向用户提供一个方便整合字串的宏定义,可以这么写:
#define LAYER_INITCALL(layer, num) __zinitcall_##layer##_##num用户的调用如下:
LAYER_INITCALL(service, 1);
LAYER_INITCALL(service, 2);
LAYER_INITCALL(feature, 1);
LAYER_INITCALL(feature, 2);注意:
在书写非字符串的字串时(如上述例子),使用两边双井号来粘贴字串,并且要注意如果字串出现在最末尾,则最后的双井号必须去除,例如上述代码不可写成:
#define LAYER_INITCALL(num, layer) __zinitcall_##layer##_##num##但如果粘贴的字串并非出现在最末尾,则前后都必须加上双井号:
#define LAYER_INITCALL(num, layer) __zinitcall_##layer##_##num##end注意:
另外,如果字串本身拼接为字符串,那么只需要使用一个井号即可,比如:
#define domainName(a, b) "www." #a "." #b ".com"
int main()
{
printf("%s\n", domainName(yueqian, lab));
}执行打印如下:
gec@ubuntu:~$ ./a.out
www.yueqian.lab.com
gec@ubuntu:~$(3)、条件编译
1、无值宏定义
定义无参宏的时候,不一定需要带值,无值的宏定义经常在条件编译中作为判断条件出现,例如:
#define BIG_ENDIAN
#define __cplusplus- 形式:判断宏 MACRO 是否已被定义,据此决定其所包含的代码段是否要编译
// 单独判
#ifndef MACRO
...
#endif
// 二路分支
#ifndef MACRO
...
#else
...
#endif- 总结:
- #ifdef、#ifndef此种形式,判定的是宏是否已被定义,这不要求宏有值。
- #if 、#elif 这些形式,判定的是宏的值是否为真,这要求宏必须有值。
2、有值宏定义
- 概念:有条件的编译,通过控制某些宏的值,来决定编译哪段代码。
- 形式:
- 形式1:判断表达式 MACRO 是否为真,据此决定其所包含的代码段是否要编译
- 注意:#if形式条件编译需要有值宏
#define A 0
#define B 1
#define C 2
#if A
... // 如果 MACRO 为真,那么该段代码将被编译,否则被丢弃
#endif二路分支
// 二路分支
#if A
...
#elif B
...
#endif多路分支
// 多路分支
#if A
...
#elif B
...
#elif C
...
#endif3、条件编译的使用场景
a、控制调试语句:在程序中,用条件编译将调试语句包裹起来,通过gcc编译选项随意控制调试代码的启停状态。例如:
gcc example.c -o example -DMACRO以上语句中,-D意味着 Define,MACRO 是程序中用来控制调试语句的一个宏,如此一来就可以在完全不需要修改源代码的情况下,通过外部编译指令选项非常方便地控制调试信息的启停。
b、选择代码片段:在一些大型项目中(例如 Linux 内核),某个相同功能的模块往往有不同的实现,需要用户根据具体的情况来“配置”,这个所谓的配置的过程,就是对代码中不同的宏的选择的过程。
例如:
#define A 0 // 网卡1
#define B 1 // 网卡2 √
#define C 0 // 网卡3
// 多路分支
#if A
...
#elif B
...
#elif C
...
#endif - 示例代码:
#include <stdio.h>
#define A 0 // 网卡A
#define B 0 // 网卡B
#define C 1 // 网卡C
// 主函数
int main(int argc, char const *argv[])
{
// 1、无值宏定义判断(需要编译的时候,在编译语句末尾加入-DDEBUG, 即定义了这个宏定义)
int num = 100;
#ifdef DEBUG
num = 200; // 这里一般作为调试信息所用
printf("num = %d\n", num);
#endif
// 2、有值宏定义判断‘
#if A
printf("选择网卡A插入到linux驱动内核里面\n");
#elif B
printf("选择网卡B插入到linux驱动内核里面\n");
#elif C
printf("选择网卡C插入到linux驱动内核里面\n");
#endif
return 0;
}(4)、头文件
1、头文件的作用
通常,一个常规的C语言程序会包含多个源码文件(.c),当某些公共资源需要在各个源码文件中使用时,为了避免多次编写相同的代码,一般的做法是将这些大家都需要用到的公共资源放入头文件(.h)当中,然后在各个源码文件中直接包含即可。

2、头文件的格式
由于头文件包含指令 #include 的本质是复制粘贴,并且一个头文件中可以嵌套包含其他头文件,因此很容易出现一种情况是:头文件被重复包含。
- 使用条件编译,解决头文件重复包含的问题,格式如下:
#ifndef _HEADNAME_H
#define _HEADNAME_H
...
... (头文件正文)
...
#endif其中,HEADNAME一般取头文件名称的大写
3、头文件的内容
- 头文件中所存放的内容,就是各个源码文件的彼此可见的公共资源,包括:
- 全局变量的声明。
- 普通函数的声明。
- 静态函数的定义。
- 宏定义。
- 结构体、联合体、枚举的定义。
- 枚举常量列表的定义。
- 其他头文件。
- 示例代码:
// head.h
extern int global; // 1,全局变量的声明
extern void f1(); // 2,普通函数的声明
static void f2() // 3,静态函数的定义
{
...
}
#define MAX(a, b) ((a)>(b)?(a):(b)) // 4,宏定义
struct node // 5,结构体的定义
{
...
};
union attr // 6,联合体的定义
{
...
};
#include <unistd.h> // 7,其他头文件
#include <string.h>
#include <stdint.h>- 特别说明:
-
- 全局变量、普通函数的定义一般出现在某个源文件(*.c *.cpp)中,其他的源文件想要使用都需要进行声明,因此一般放在头文件中更方便。
- 静态函数、宏定义、结构体、联合体的定义都只能在其所在的文件可见,因此如果多个源文件都需要使用的话,放到头文件中定义是最方便,也是最安全的选择。
4、头文件的使用
头文件编写好了之后,就可以被各个所需要的源码文件包含了,包含头文件的语句就是如下预处理指令:
// main.c
#include "head.h" // 包含自定义的头文件
#include <stdio.h> // 包含系统预定义的文件
int main()
{
...
}可以看到,在源码文件中包含指定的头文件有两种不同的形式:
- 使用双引号:在指定位置 + 系统标准路径搜索 head.h
- 使用尖括号:在系统标准路径搜索 stdio.h
一个简易示例
由于自定义的头文件一般放在源码文件的周围,因此需要在编译的时候通过特定的选项来指定位置,而系统头文件都统一放在标准路径下,一般无需指定位置。
假设在源码文件 main.c 中,包含了两个头文件:head.h 和 stdio.h ,由于他们一个是自定义头文件,一个是系统标准头文件,前者放在项目 project/inc 路径下,后者存放于系统头文件标准路径下(一般位于 /usr/include),因此对于这个程序的编译指令应写作:
gec@ubuntu:~/pro$ gcc main.c -o main -I /home/gec/pro/inc其中,/home/gec/pro/inc 是自定义头文件 head.h 所在的路径
- 语法要点:
- 预处理指令 #include 的本质是复制粘贴:将指定头文件的内容复制到源码文件中。
- 系统标准头文件路径可以通过编译选项 -v 来获知,比如:
gec@ubuntu:~/pro$ gcc main.c -I /home/gec/pro/inc -v
... ...
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/7/include
/usr/local/include
/usr/lib/gcc/x86_64-linux-gnu/7/include-fixed
/usr/include/x86_64-linux-gnu
/usr/include
... ...[ 课堂课后实验 ]:
【1】、实验1:(带参宏的副作用)
分析以下宏定义语句,找出问题并解决
#include <stdio.h>
#define MAX(A, B) A>B?A:B
// 主函数
int main(int argc, char const *argv[])
{
int x = 100;
int y = 200;
printf("两个数中,最大的数为:%d\n", MAX(x, y==200?888:999));
return 0;
}解析:
带参宏的副作用:
由于宏仅仅做文本替换,中间不涉及任何语法检查、类型匹配、数值运算,因此用起来相对函数要麻烦很多。例如:
#define MAX(a, b) a>b ? a : b
int main()
{
int x = 100, y = 200;
printf("最大值:%d\n", MAX(x, y==200?888:999));
}直观上看,无论 y 的取值是多少,表达式 y==200?888:999 的值一定比 x 要大,但由于宏定义仅仅是文本替换,中间不涉及任何运算,因此等价于:
printf("最大值:%d\n", x>y==200?888:999 ? x : y==200?888:999);可见,带参宏的参数不能像函数参数那样视为一个整体,整个宏定义也不能视为一个单一的数据,事实上,不管是宏参数还是宏本身,都应被视为一个字串,或者一个表达式,或者一段文本,因此最基本的原则是:
- 将宏定义中所有能用括号括起来的部分,都括起来,比如:
#define MAX(a, b) ((a)>(b) ? (a) : (b))- 替换为:
printf("最大值:%d\n", ((x)>(y==200?888:999) ? (x) : (y==200?888:999)));【2】、实验2:(头文件格式)
某头文件中有以下语句,解释其作用。
#ifndef _SOME_HEADER_H_
#define _SOME_HEADER_H_
… …
#endif【3】、实验3:(C语言工程模板)
1、写一下该C语言工程的使用方法(记录在ReadMe.md中):
a、工程文档结构组成(可以使用tree命名查看,需要安装sudo apt install tree)
b、是什么
c、怎么用
2、使用gif动图工具,记录你使用这个工程时的过程(或者说功能演示)
【4】、实验4:(笔试题)
题目一:
对于一个频繁使用的短小函数,在C语言中应用什么实现
题目二:
带参宏与带参函数的区别(至少说出5点)?
题目三:
用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题)
题目四:
用宏定义写出swap(x,y),即交换两数。
题目五:
已知一个数组table,用一个宏定义,求出数据的元素个数。