论文速读|Learning Multi-dimensional Human Preference for Text-to-Image Generation
论文信息:

简介:
本文讨论的是文本到图像生成领域中的一个关键问题,即如何准确评估由文本描述生成的图像质量。传统的评估方法主要依赖于统计指标,如Inception Score (IS)、Fréchet Inception Distance (FID)和CLIP Score等,但这些指标往往不能很好地代表人类的真实偏好。尽管有些工作尝试通过人工标注的图像来学习这些偏好,但它们通常将复杂的人类偏好简化为单一的总体评分,忽略了人类在评估图像时会从多个维度进行考量的事实。动机在于现有的文本到图像生成模型在创建高质量图像方面取得了显著进展,但在实际应用中往往未能与人类偏好对齐。此外,人类在评估图像时会从多个角度进行考量,例如图像的美观程度、与文本描述的一致性、细节的清晰度等,而单一维度的评估方法无法充分捕捉这种复杂性。因此,本文旨在通过构建一个多维度的人类偏好评分模型(MPS),来更好地评估和改进文本到图像的生成质量。
论文方法:
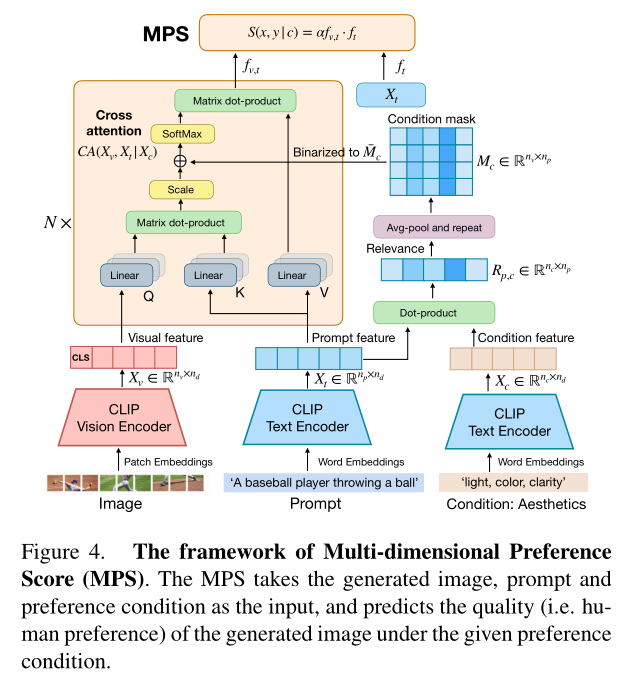
本文提出了一个名为多维偏好评分(Multi-dimensional Preference Score, MPS)的模型,该模型基于CLIP模型构建,并引入了一个偏好条件模块来学习不同的偏好。
MPS模型的训练基于多维人类偏好(Multi-dimensional Human Preference, MHP)数据集,该数据集包含了918,315个人类偏好选择,涵盖了607,541张由多种最新的文本到图像模型生成的图像,覆盖了美学、语义对齐、细节质量和总体评估四个维度。
MPS模型的工作流程如下:
1)使用CLIP模型从图像和文本中提取特征。
2)通过条件掩码(condition mask)来突出与特定偏好条件相关的文本部分,同时抑制不相关的部分。
3)将图像和文本的特征通过多模态交叉注意力层(multimodal cross-attention layer)融合。
4)使用融合后的特征来预测偏好分数。
MPS模型的关键创新在于条件掩码的使用,它允许模型在计算偏好分数时只关注与特定偏好条件相关的文本部分。这样,即使是在偏好之间相关性较弱的情况下,MPS模型也能够有效地预测多维度的人类偏好。通过在三个数据集上的性能比较,MPS模型在预测总体偏好和多维度偏好方面均优于现有方法,证明了其方法的有效性和泛化能力。
论文实验:
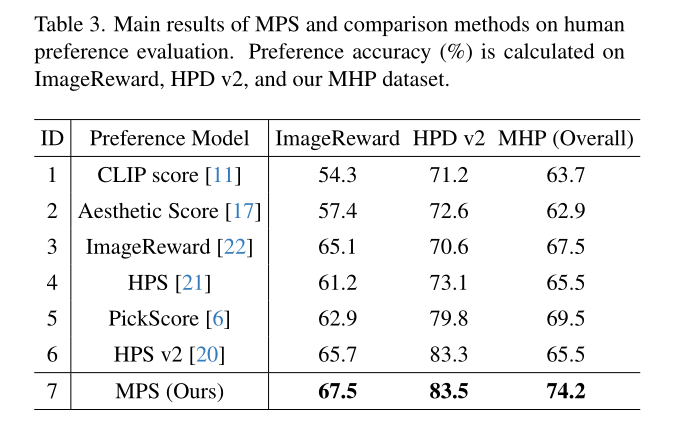
根据提供的Table 3,我们可以了解到论文中的实验部分主要关注于评估和比较不同方法在预测人类对文本到图像合成模型偏好的准确性。MPS在所有三个数据集上都展现出了比现有方法更高的准确率。在ImageReward数据集上,MPS的准确率为67.5%,高于其他所有方法。在HPD v2数据集上,MPS的准确率达到了83.5%,同样高于其他方法。在MHP数据集(总体)上,MPS的准确率为74.2%,表现优于其他方法。论文还比较了不同方法在预测多维度人类偏好方面的表现,这些维度包括总体、美学、语义对齐和细节。
论文链接:
https://arxiv.org/abs/2405.14705