一 引言
2024年6月,智谱AI发布的GLM-4-9B系列开源模型,在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B和GLM-4-9B-Chat均表现出超越Llama-3-8B的卓越性能。并且,本代模型新增对26种语言的支持,涵盖日语、韩语、德语等。除此之外,智谱AI还推出了支持1M上下文长度的GLM-4-9B-Chat-1M模型和基于GLM-4-9B的多模态模型。以下为GLM-4-9B系列模型的具体评测结果。
- 对话模型典型任务

- 基座模型典型任务
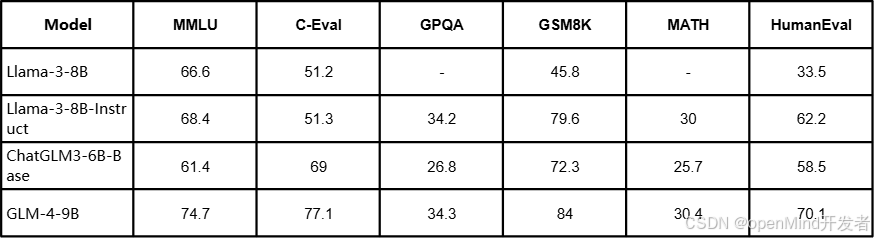
由于GLM-4-9B在预训练过程中加入了部分数学、推理和代码相关的instruction数据,所以将Llama-3-8B-Instruct也列入比较范围。
- 长文本
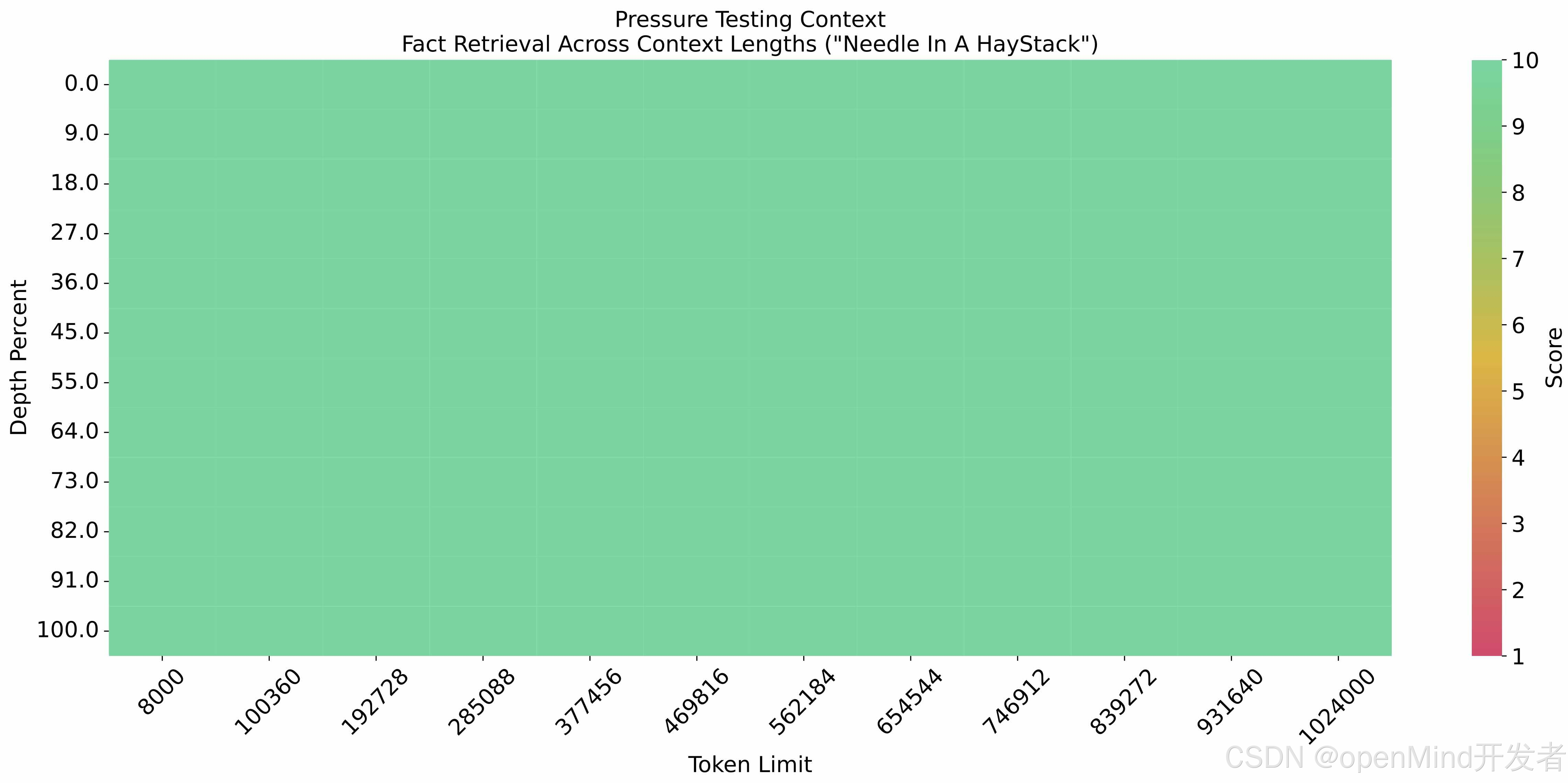
在1M的上下文长度下进行大海捞针实验,结果如下:
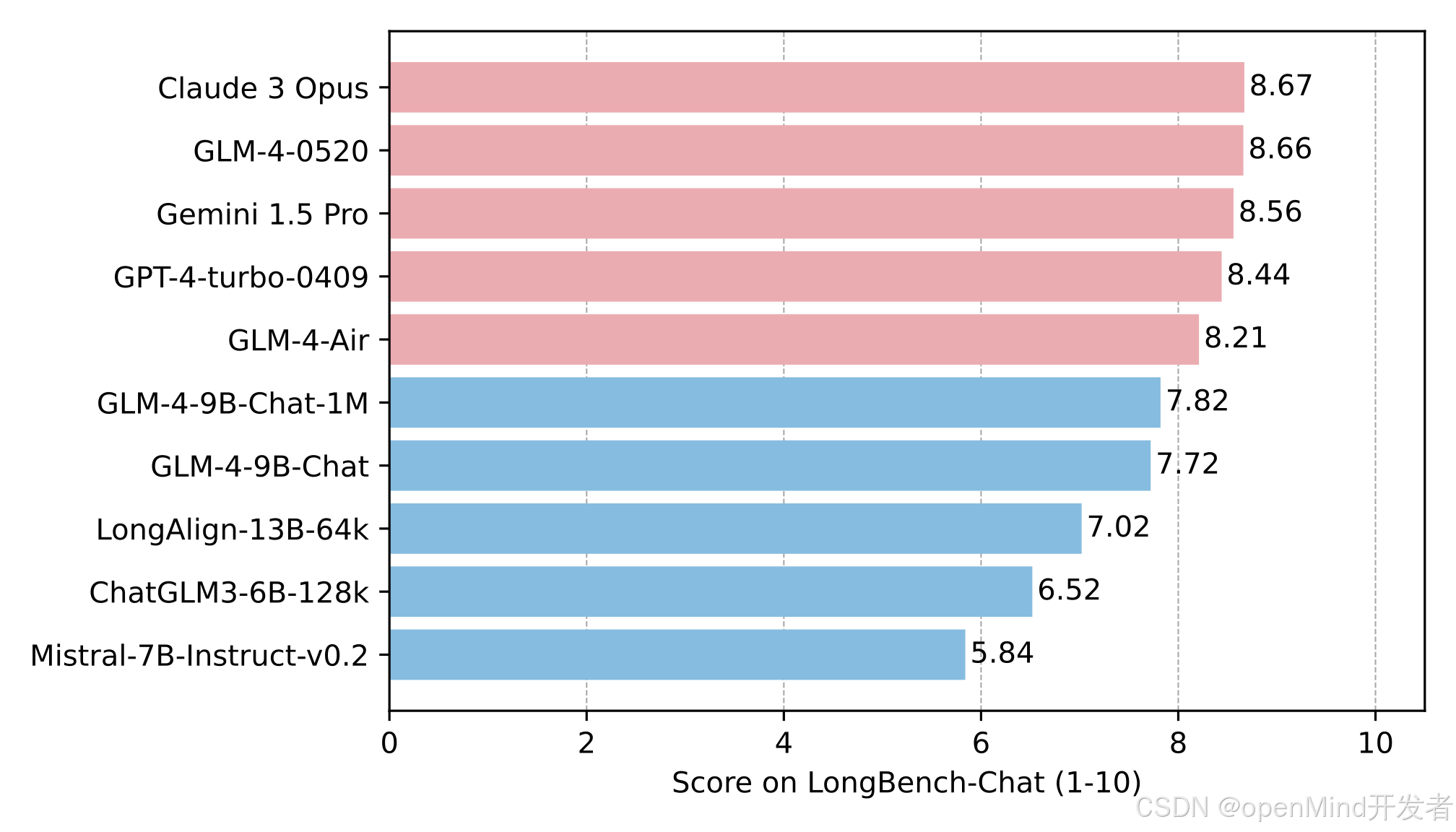
在LongBench-Chat上对长文本能力进行了进一步评测,结果如下:
二 环境准备
2.1 安装Ascend CANN Toolkit和Kernels
安装方法请参考安装教程或使用以下命令:
# 请替换URL为CANN版本和设备型号对应的URL
# 安装CANN Toolkit
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run
bash Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run --install
# 安装CANN Kernels
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run
bash Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run --install
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
2.2 安装openMind Hub Client和openMind Library
- 安装openMind Hub Client
pip install openmind_hub
- 安装openMind Library,并安装PyTorch框架及其依赖。
pip install openmind[pt]
更详细的安装信息请参考魔乐社区的环境安装章节。
2.3 安装LLaMa Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch-npu,metrics]"
三 模型链接和下载
GLM-4-9B模型系列由社区开发者在魔乐社区贡献,包括:
-
GLM-4-9B-Chat:https://modelers.cn/models/AI-Research/glm-4-9b
-
GLM-4-9B-Chat-1m:https://modelers.cn/models/AI-Research/glm-4-9b-chat-1m
通过Git从魔乐社区下载模型的repo,以GLM-4-9B-Chat为例:
# 首先保证已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://modelers.cn/AI-Research/glm-4-9b-chat.git
四 模型推理
用户可以使用openMind Library或者LLaMa Factory进行模型推理,以GLM-4-9B-Chat为例,具体如下:
- 使用openMind Library进行模型推理
新建推理脚本inference_glm4_9b_chat.py,推理脚本内容为:
import torch
from openmind import AutoModelForCausalLM, AutoTokenizer
device = "npu"
# 若模型已下载,可替换成模型本地路径
tokenizer = AutoTokenizer.from_pretrained("AI-Research/glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"AI-Research/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
执行推理脚本:
python inference_glm4_9b_chat.py
推理结果如下:

五 模型微调
我们使用单张昇腾NPU,基于LLaMa Factory框架,采用广告文案生成数据集进行Lora微调,让模型能够根据用户输入的商品关键字生成对应的广告文案。
5.1 数据集
广告文案数据集(AdvertiseGen)任务为根据输入(content)生成一段广告词(summary),分为训练集和验证集。其中,训练集大小为114K,验证集大小为1K。每个样本有content和summary两个键,分别保存商品关键字和商品文案。
以下是部分示例:
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
- 下载AdvertiseGen数据集
感谢社区开发者在魔乐社区贡献的AdvertiseGen数据集,使用Git将数据集下载至本地。
git lfs install
git clone https://modelers.cn/AI-Research/AdvertiseGen.git
- 数据预处理
下载完成后,需要将train.json和dev.json两个文件的数据处理成alpaca数据格式。因此,创建preprocess_adv_gen.py脚本,脚本内容具体如下:
import json
import argparse
import os
import stat
DEFAULT_FLAGS = os.O_WRONLY | os.O_CREAT
DEFAULT_MODES = stat.S_IWUSR | stat.S_IRUSR
def parse_args():
parse = argparse.ArgumentParser()
parse.add_argument("--data_path", type=str)
parse.add_argument("--save_path", type=str)
args = parse.parse_args()
return args
def read_data(data_path):
data = []
with open(data_path, "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
data.append(json.loads(line))
return data
def convert_to_alpaca_format(data):
results = []
for sample in data:
example = {}
example["instruction"] = sample["content"]
example["output"] = sample["summary"]
results.append(example)
return results
def save_data(data, save_path):
with os.fdopen(os.open(save_path, DEFAULT_FLAGS, DEFAULT_MODES), "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
if __name__ == "__main__":
args = parse_args()
data = read_data(args.data_path)
data = convert_to_alpaca_format(data)
save_data(data, args.save_path)
通过以下命令执行脚本,将数据预处理的结果分别存为adv_gen_train.json和adv_gen_dev.json。
# xxx为train,json和dev.json文件路径
python preprocess_adv_gen.py --data_path xxx --save_path ./adv_gen_train.json
python preprocess_adv_gen.py --data_path xxx --save_path ./adv_gen_dev.json
修改LLaMa Factory下的data/dataset_info.json文件,添加数据集描述:
"adv_gen_train": {
"file_name": "xxx", // 填写预处理完成的adv_gen_train.json文件路径
"columns": {
"prompt": "instruction",
"response": "output"
}
},
"adv_gen_dev": {
"file_name": "xxx", // 填写预处理完成的adv_gen_dev.json文件路径
"columns": {
"prompt": "instruction",
"response": "output"
}
},
以上为整个数据预处理流程,在配置文件中使用dataset: adv_gen_train, adv_gen_dev配置即可在微调中使用广告文案生成数据集。
5.2 微调
在LLaMa Factory路径下新建examples/train_lora/glm4_9b_chat_lora_sft.yaml微调配置文件,微调配置文件如下:
### model
model_name_or_path: xxx # 当前仅支持本地加载,填写GLM-4-9B-Chat本地权重路径
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
lora_rank: 8
lora_alpha: 32
lora_dropout: 0.1
### dataset
dataset: adv_gen_train
template: glm4
cutoff_len: 256
preprocessing_num_workers: 16
### output
output_dir: saves/glm4_9b_chat/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 16
gradient_accumulation_steps: 1
learning_rate: 5.0e-4
max_steps: 1000
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
通过下面的命令启动微调:
export ASCEND_RT_VISIBLE_DEVICES=0
llamafactory-cli train examples/train_lora/glm4_9b_chat_lora_sft.yaml
5.3 微调可视化
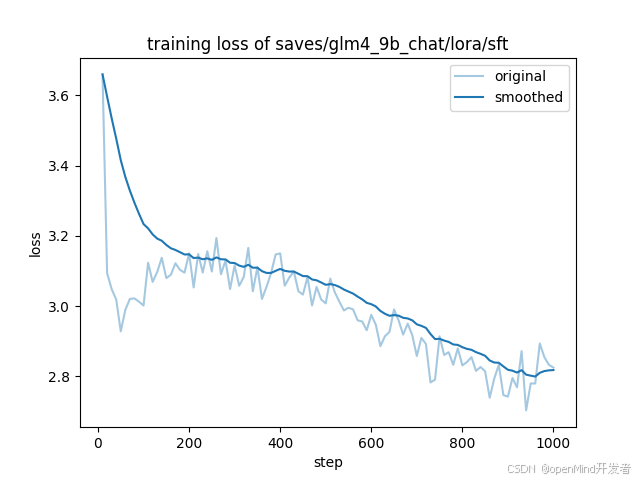
5.4 微调结果
- 评估
训练结束后,通过LLaMa Factory使用微调完成的权重在·adv_gen_dev.json·数据集上预测BLEU和ROUGE分数。在LLaMa Factory路径下新建·examples/train_lora/glm4_9b_chat_lora_predict.yaml·推理配置文件,配置文件内容如下:
### model
model_name_or_path: xxx # 当前仅支持本地加载,填写GLM-4-9B-Chat本地权重路径
adapter_name_or_path: saves/glm4_9b_chat/lora/sft/checkpoint-1000/
### method
stage: sft
do_predict: true
finetuning_type: lora
### dataset
eval_dataset: adv_gen_dev
template: glm4
cutoff_len: 256
preprocessing_num_workers: 16
### output
output_dir: saves/glm4_9b_chat/lora/predict
overwrite_output_dir: true
### eval
per_device_eval_batch_size: 128
predict_with_generate: true
通过下面的命令启动评估:
export ASCEND_RT_VISIBLE_DEVICES=0
llamafactory-cli train examples/train_lora/glm4_9b_chat_lora_predict.yaml
评估的结果为:
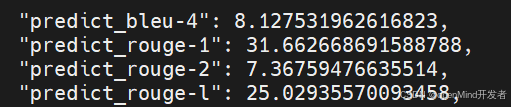
- 推理
微调结束后,在LLaMa Factory路径下新建examples/inference/glm4_9b_chat_lora_sft.yaml推理配置文件,配置文件内容为:
model_name_or_path: xxx # 当前仅支持本地加载,填写GLM-4-9B-Chat本地权重路径
adapter_name_or_path: saves/glm4_9b_chat/lora/sft/checkpoint-1000/
template: glm4
finetuning_type: lora
通过下面的命令启动推理:
llamafactory-cli chat examples/inference/glm4_9b_chat_lora_sft.yaml
-
训练前推理结果为:
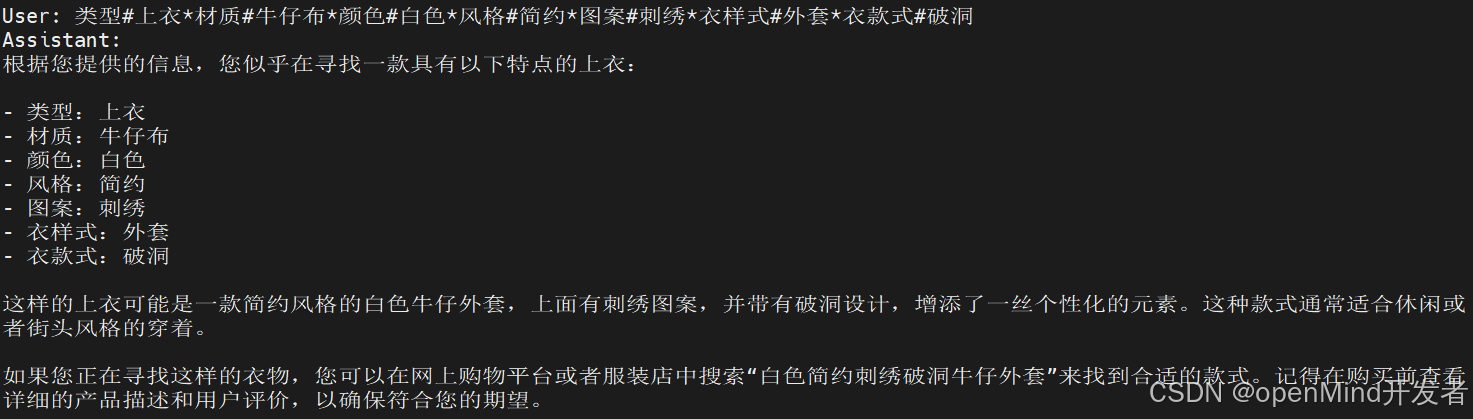
问题:类型#上衣材质#牛仔布颜色#白色风格#简约图案#刺绣衣样式#外套衣款式#破洞
-
训练后推理结果为:
-
问题1:类型#上衣材质#牛仔布颜色#白色风格#简约图案#刺绣衣样式#外套衣款式#破洞
-
问题2:类型#裤风格#英伦风格#简约
-
问题3:类型#裙裙下摆#弧形裙腰型#高腰裙长#半身裙裙款式#不规则*裙款式#收腰
-



六 总结
本次实践是在魔乐社区进行。朋友们可以试试,也欢迎分享你们的经验,一起交流:https://modelers.cn
如您在体验过程中遇到任何问题,欢迎访问魔乐社区的帮助中心(https://gitee.com/modelers/feedback),与其他用户交流和寻求支持。