第九章 用户自己建立数据类型
1.结构体
定义:由不同类型数据组成的组合型数据结构,例如:一个人的基本信息(结构体)包括名字(字符)、性别(字符)、年龄(int)、籍贯(字符);
形式:
struct 结构体名{
char name[20];
char sex;
int age;
……};---------------------------->一定要注意这里有一个分号
结构体里面的成员也可以是另一个结构体;
struct student{
char name[20];
char sex;
int age;
struct Date birthday;//结构体
};
定义一个结构体变量:
version1:定义结构体变量后 (结构体类型名) 结构体变量名,例如:
struct Student student1,student2;
初始化:student1={"zhang san",'m',25,{2000,2,13}};
version 2:在声明类型的同时定义变量,例如:
struct student{
char name[20];
char sex;
int age;
struct Date birthday;//结构体
} student1={"zhang san",'m',25,{2000,2,13}},student2;//初始化
引用结构体成员:结构体变量名.成员名,例如:
student1.age=25;
练习:输出两个学生中成绩更高的人的信息
#include <stdio.h>
struct Student{
char name[20];
char id[5];
int score;
};
int main() {
struct Student student1,student2;
scanf("%s %s %d",student1.id,student1.name,&student1.score);
scanf("%s %s %d",student2.id,student2.name,&student2.score);
if (student1.score>student2.score) {
printf("Student 1 (%s) with ID: %s has higher total score.\n", student1.name, student1.id);
printf("score:%d", student1.score);
} else if (student1.score<student2.score) {
printf("Student 2 (%s) with ID: %s has higher total score.\n", student2.name, student2.id);
printf("score:%d", student2.score);
} else {
printf("Both students have the same total score.\n");
}
return 0;
}结构体数组
struct student{
char name[20];
char sex;
int age;
}students[5]
练习:将学生成绩由大到小排列输出
#include <stdio.h>
struct Student{
char id[10];
char name[10];
int score;
}students[3]={{"zhangsan","111",56},{"lisi","112",78},{"wanger","113",23}};
int main() {
struct Student temp;
for (int i = 0; i < 2; i++)
{
for (int j = i+1;j<3 ; j++)
{
if (students[i].score<students[j].score)
{
temp=students[i];
students[i]=students[j];
students[j]=temp;
}
}
}
for (int i = 0; i < 3; i++)
{
printf("%s %s %d\n",students[i].id,students[i].name,students[i].score);
}
return 0;
}结构体指针、结构体变量指针作函数参数
综合练习:输出平均成绩最高的学生
#include <stdio.h>
#include <stdlib.h>
struct Scores{
int math;
int English;
int physics;
};
struct Student{
char name[20];
char id[10];
struct Scores subject;
float average;
};
void input(struct Student students[],int n){
for (int i = 0; i < n; i++)
{
scanf("%s %s %d %d %d",students[i].name,students[i].id,&students[i].subject.math,&students[i].subject.English,&students[i].subject.physics);
students[i].average=(students[i].subject.math+students[i].subject.English+students[i].subject.physics)/3;
}
}
struct Student find_max(struct Student std[],int n){
int max=std[0].average,k=0;
for (int i = 0; i < n; i++)
{
if (std[i].average>max)
{
max=std[i].average;
k=i;
}
}
return std[k];
}
void print(struct Student students){
printf("%s %s %d %d %d",students.name,students.id,students.subject.math,students.subject.English,students.subject.physics);
}
int main() {
int n=0;
printf("输入学生个数:\n");
scanf("%d",&n);
struct Student*students=malloc(n*sizeof(struct Student)),*p=students;
printf("输入学生信息:\n");
input(p,n);
struct Student std;
std=find_max(p,n);
printf("平均成绩最高的学生是\n");
print(std);
return 0;
}
结构体指针调用成员的方式:p->name;
2.链表
之前数组部分我们知道数组元素的地址是连续的,而且在不明确输入数据数量时,需要数组容量足够大才能存下所有数据,这会浪费内存。而链表是逻辑上的连续而内存并不连续,想要添加数据就立即分配内存,存数再连接。链表通过指针从上一块数据指到下一块,像锁链一般串联数据块。
静态链表示例:
#include <stdio.h>
struct Student{
char name[20];
char id[10];
int score;
struct Student*next;
};
int main() {
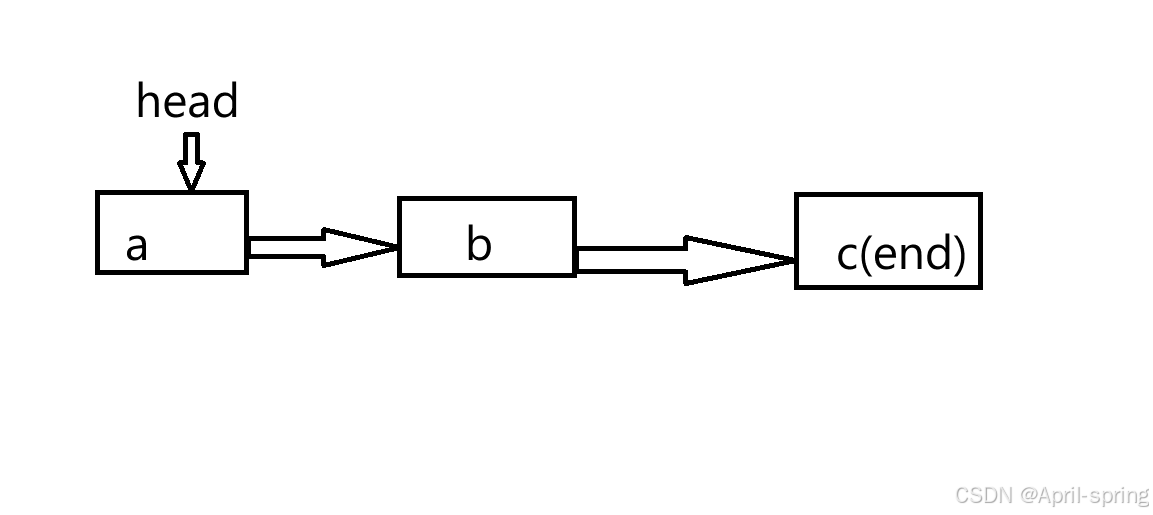
struct Student a={"zhangsan","111",78,NULL},b={"lisi","112",89,NULL},c={"wanger","113",34,NULL};
struct Student *head=&a;
a.next=&b;
b.next=&c;
c.next=NULL;
struct Student *p=head;
while (p!=NULL)
{
printf("%s %s %d\n",p->id,p->name,p->score);
p=p->next;
}
return 0;
}
【注意】结构体里面的next是存放下一个结构体地址的指针变量;
初始化将指针设置为空(null)防止野指针使其他数据被改变;
链表有头指针(head),这里面没有数据只是存放了a的地址;
头指针是链表中非常重要的一个概念,以下是链表需要头指针的几个原因:
1.访问链表:头指针是链表的入口点,它指向链表的第一个节点。通过头指针,我们可以访问链表中的所有节点。如果没有头指针,我们就无法直接访问链表,也就无法对链表进行操作。
2.链表操作:在链表的各种操作(如插入、删除、遍历等)中,头指针起着关键作用。例如,在插入新节点时,我们可能需要将新节点插入到链表的头部;在删除节点时,我们可能需要找到并删除头节点。如果没有头指针,这些操作将变得非常困难。
3.链表表示:头指针是链表的标识,它表示链表的存在。即使链表为空(即没有任何节点),头指针仍然存在,表示这是一个空链表。如果没有头指针,我们就无法区分一个空链表和一个不存在的链表。
4.内存管理:在动态分配内存的情况下,头指针可以用来管理链表的内存。例如,当我们需要释放整个链表时,可以从头指针开始,逐个释放每个节点的内存。如果没有头指针,我们就无法遍历并释放链表中的所有节点。
5.链表类型:在某些情况下,链表可能需要支持多种操作,如查找、排序等。头指针可以方便地实现这些操作,因为它提供了链表的起始点。
6.代码可读性:使用头指针可以使链表操作的代码更加清晰和易于理解。通过头指针,我们可以直观地表示链表的开始和结束,以及链表中的各种操作。
总之,头指针是链表的重要组成部分,它提供了链表的访问入口,支持链表的各种操作,并有助于链表的内存管理。没有头指针,链表将变得难以使用和操作。
动态链表
主要练习内容包括:建立链表、移动节点、交换节点、删除节点、增加节点、输出链表;
#include <stdio.h>
#include <stdlib.h>
struct num{
int number;
struct num*next;
};
struct num* create(){
struct num*head=NULL,*p1=NULL,*p2=NULL;
int num=0;
scanf("%d",&num);
while (num!=0)
{
p1=malloc(sizeof(struct num));
p1->number=num;
if (head==NULL)
{
head=p1;
}
else{
p2->next=p1;
}
p2=p1;
scanf("%d",&num);
}
p2->next=NULL;
return head;
}
void print(struct num*head){
struct num*p=head;
while (p!=NULL)
{
printf("%d ",p->number);
p=p->next;
}
}
void delete_list(struct num*head){
struct num*p=head,*temp=NULL;
while (p!=NULL)
{
temp=p;
p=p->next;
free(temp);//free 函数传入的参数是指向被分配内存块的指针
}
}
struct num* delete_part(struct num*head,int pos,int n){
//删除第一个节点
struct num*temp,*p=head;
if (pos==1)
{
temp=head;
head=head->next;
free(temp);
}
//删除末尾节点
else if (pos==n)
{
while (p->next->next!=NULL)
{
p=p->next;
}
temp=p->next->next;
p->next=NULL;
free(temp);
}
//删除中间节点
else{
for (int i = 0; i < pos-2; i++)
{
p=p->next;
}
temp=p->next;
p->next=p->next->next;
free(temp);
}
return head;
}
struct num*add_part(struct num*head,struct num*one,int pos,int n){
struct num*p=head;
//头部加入
if (pos==1)
{
one->next=head;
head=one;
}
//尾部加入
else if(pos==n){
while (p->next!=NULL)
{
p=p->next;
}
p->next=one;
}
//中间加入
else{
for (int i = 0; i < pos-2; i++)
{
p=p->next;
}
one->next=p->next;
p->next=one;
}
return head;
}
struct num* move(struct num* head, int f, int to,int n) {
struct num* from = head;
struct num* p = head;
struct num* temp = NULL;
struct num*trail=head;
if(to<=n){
for (int i = 0; i < to - 1 ; i++) {
p = p->next;
}
for (int i = 0; i < f - 1 ; i++) {
temp = from;
from = from->next;
}
// 从链表中移除需要移动的节点
if (temp != NULL) {
temp->next = from->next;
}
if (temp==NULL)//移动第一个节点
{
head=head->next;
from->next=NULL;
}
// 将移动的节点插入到目标位置
if (p->next==NULL)//插入到最后一位
{
p->next=from;
}
else{
from->next = p->next;
p->next = from;
}
}
else{
for (int i = 0; i < f - 1 ; i++) {
temp = from;
from = from->next;
}
// 从链表中移除需要移动的节点
if (temp != NULL) {
temp->next = from->next;
}
if (temp==NULL)//移动第一个节点
{
head=head->next;
}
while (trail->next!=NULL)
{
trail=trail->next;
}
trail->next=from;
from->next=NULL;
}
return head;
}
struct num*swap1(struct num*head,int from,int to){
/*交换最简单的方法是直接交换数据swap1(当数据很少的时候),
struct num temp;
temp=*p1;
*p1=*p2;
*p2=temp;这种形式就不能用在链表,结构体内部有指针类型数据的时候不支持这样做
当然也可以交换节点swap2*/
struct num*p1=head,*p2=head;
for (int i = 0; i < from-1; i++)
{
p1=p1->next;
}
for (int i = 0; i < to-1; i++)
{
p2=p2->next;
}
int temp;
temp=p1->number;
p1->number=p2->number;
p2->number=temp;
return head;
}
struct num*swap2(struct num*head,int from,int to){
//交换时数值不越界
struct num*pre1=NULL,*cur1=head,*pre2=NULL,*cur2=head;
for (int i = 0; i < from-1; i++)
{
pre1=cur1;
cur1=cur1->next;
}
for (int i = 0; i < to-1; i++)
{
pre2=cur2;
cur2=cur2->next;
}
if(pre1!=NULL){
if (cur2->next==NULL)
{
pre1->next=cur2;
cur2->next=cur1->next;
pre1->next=cur1;
cur1->next=NULL;
}
else{pre1->next=cur1->next;
cur1->next=cur2->next;
pre2->next=cur1;
cur2->next=pre1->next;
pre1->next=cur2;}
}else{
if (cur2->next==NULL)
{
pre2->next=NULL;
head=head->next;
cur1->next=NULL;
cur2->next=head;
head=cur2;
pre2->next=cur1;
}else{
head=head->next;
cur1->next=cur2->next;
pre2->next=cur1;
cur2->next=head;
head=cur2;}
}
return head;
}
int main() {
struct num*head;
head=create();
//struct num one={7,NULL};
//head=add_part(head,&one,3,4);
//head=delete_part(head,1,6);
//head=move(head,1,7,6);
//head=swap1(head,1,6);
head=swap2(head,1,6);
print(head);
delete_list(head);
return 0;
}
以上是链表操作的全部展示;
3.共用体
C语言中的共用体(union)是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。共用体可以包含多个不同类型的成员,但是在任意时刻只能使用其中一个成员。这意味着所有共用体成员共享相同的内存空间。
形式:
union 共用体名{
成员表列
};
示例:
#include <stdio.h>
// 定义一个共用体类型
union Data {
int i;
float f;
char str[20];
};
int main() {
// 创建共用体变量
union Data data;
// 给共用体的不同成员赋值,并打印结果
// 注意:在给一个成员赋值后,其他成员的值可能会变得未定义
data.i = 10; // 存储一个整数
printf("data.i : %d\n", data.i);
data.f = 220.5; // 存储一个浮点数
printf("data.f : %f\n", data.f);
// 打印前一个整数值,此时它可能已经被覆盖
// printf("data.i : %d\n", data.i); // 这将是一个未定义的值
// 存储一个字符串
sprintf(data.str, "%s", "C Programming");
printf("data.str : %s\n", data.str);
// 打印浮点数值,此时它可能已经被覆盖
// printf("data.f : %f\n", data.f); // 这将是一个未定义的值
return 0;
}在这个例子中,我们定义了一个名为 Data 的共用体类型,它包含一个整数 i、一个浮点数 f 和一个字符数组 str。然后,我们创建了一个 Data 类型的变量 data,并分别给其成员赋值。每次赋值后,我们打印出相应成员的值。由于共用体的所有成员共享相同的内存空间,所以在给一个成员赋值后,其他成员的值可能会被覆盖,变成未定义的值。因此,在访问共用体的成员之前,确保已经给该成员赋了新值。在结构体中使用共用体方式 结构体名.共用体名.成员;
4.枚举类型
C语言中的枚举(enumeration)是一种数据类型,它允许为整型常量赋予有意义的名称。枚举是一组命名的整数常量的集合,这些常量通常被称为枚举的成员。枚举提供了一种清晰的方式来处理一组有限的、相关的值。
形式:enum 枚举名{
枚举元素列表
};
示例:
#include <stdio.h>
// 定义一个枚举类型,表示一周的天数
enum Weekday {
Sunday, // 默认从0开始,Sunday = 0
Monday, // Monday = 1
Tuesday, // Tuesday = 2
Wednesday, // Wednesday = 3
Thursday, // Thursday = 4
Friday, // Friday = 5
Saturday // Saturday = 6
};
int main() {
// 使用枚举类型
enum Weekday today = Tuesday;
printf("Today is %d, which is %s.\n", today, today == Sunday ? "Sunday" :
today == Monday ? "Monday" :
today == Tuesday ? "Tuesday" :
today == Wednesday ? "Wednesday" :
today == Thursday ? "Thursday" :
today == Friday ? "Friday" : "Saturday");
// 遍历枚举类型
enum Weekday day;
for (day = Sunday; day <= Saturday; day++) {
printf("%d: %s\n", day, day == Sunday ? "Sunday" :
day == Monday ? "Monday" :
day == Tuesday ? "Tuesday" :
day == Wednesday ? "Wednesday" :
day == Thursday ? "Thursday" :
day == Friday ? "Friday" : "Saturday");
}
return 0;
}在这个例子中,我们定义了一个名为 Weekday 的枚举类型,它包含了一周的七天。然后,我们声明了一个 Weekday 类型的变量 today 并给它赋值为 Tuesday,接着打印出 today 对应的数值和名称。
此外,我们还使用了一个 for 循环来遍历 Weekday 枚举的所有成员,并打印出每个成员的数值和名称。注意这里打印数据的时候使用了条件运算符,它的作用是判断类似(today == Monday ?)的条件是否成立,成立就确定day,不成立就继续判断下一个条件;
5.typedef使用
在C语言中,typedef 是一个关键字,用于为数据类型定义一个新的名称,这个过程称为“类型定义”。使用 typedef 可以简化复杂类型的使用,增加代码的可读性,并且使得类型名称更加直观。以下是 typedef 的一些常见用法:
基本用法(定义别名,简化代码)
typedef unsigned int uint; // 将unsigned int定义为uint
uint myVar = 10; // 使用新类型uint指针类型
typedef int* pInt; // 将int*定义为pInt
pInt ptr = &someInt; // 使用新类型pInt结构体
typedef struct {
int x;
int y;
} Point; // 将struct定义为Point类型
Point pt; // 使用新类型Point函数指针
typedef int (*FuncPtr)(int, int); // 将函数指针类型定义为FuncPtr
FuncPtr func = myFunction; // 使用新类型FuncPtr枚举
typedef enum {
Red,
Green,
Blue
} Color; // 将枚举定义为Color类型
Color col = Green; // 使用新类型Color类型定义组合
typedef struct _Node {
int data;
struct _Node* next;
} Node; // 定义Node类型,内部包含一个指向自身类型的指针
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode != NULL) {
newNode->data = data;
newNode->next = NULL;
}
return newNode;
}第十章 文件操作
在vscode的程序中实现对文件的操作,例如:创立文件、编写文本、读取文件,不用去资源管理器就能进行的操作。
绝对路径(Absolute Path)
绝对路径是从根目录开始的完整路径,它指定了从根目录到目标文件或目录的确切位置。在Windows系统中,绝对路径以盘符开始(例如,C:\),后跟文件或目录的完整名称。
特点:
包含从根目录到目标的完整路径。
不依赖当前工作目录,总是指向同一位置。
通常比较长,包含多个目录层级。
示例:
C:\Users\Username\Documents\example.txt
相对路径(Relative Path)
相对路径是相对于当前工作目录的路径。它指定了从当前目录到目标文件或目录的相对位置。相对路径不包含盘符,只包含从当前位置到目标的路径。
特点:
依赖于当前工作目录,不同的工作目录下可能指向不同的位置。
通常比较短,因为它省略了到达当前目录的路径部分。
使用.表示当前目录,..表示上一级目录。
示例:
假设当前工作目录是C:\Users\Username\Documents,则相对路径example.txt或./example.txt指向的是C:\Users\Username\Documents\example.txt。
【对于文件的操作集中于打开与关闭文件、编写文本文件、二进制文件、读取文件】
文件名:
打开文件使用fopen函数------>fopen(文件名,使用方式)
打开文件之前要定义一个指向文件的指针变量:
FILE *fp;
fp=fopen("文件名","调用方式:r\w\a\rb\wb\ab\r+\w+\a+.....");
使用文件指针可以避免一直使用路径这个麻烦;
在C语言中,当使用 fopen 函数打开文件时,需要指定一个模式字符串,这个字符串决定了文件被打开的模式。以下是一些常见的文件打开模式及其含义:
-
"r"(只读模式)
-
打开一个存在的文件用于读取。如果文件不存在,打开操作失败。
-
例子:
FILE *fp = fopen("file.txt", "r");
-
-
"w"(写入模式)
-
打开一个文件用于写入。如果文件存在,它会被截断为零长度,即原有内容会被清空;如果文件不存在,创建新文件。
-
例子:
FILE *fp = fopen("file.txt", "w");
-
-
"a"(追加模式)
-
打开一个文件用于追加。如果文件存在,写入的数据会被追加到文件末尾;如果文件不存在,创建新文件。
-
例子:
FILE *fp = fopen("file.txt", "a");
-
-
"r+"(读写模式)
-
打开一个存在的文件用于读写。文件必须存在,否则打开操作失败。
-
例子:
FILE *fp = fopen("file.txt", "r+");
-
-
"w+"(读写字模式)
-
打开一个文件用于读写。如果文件存在,它会被截断为零长度;如果文件不存在,创建新文件。
-
例子:
FILE *fp = fopen("file.txt", "w+");
-
-
"a+"(读写追加模式)
-
打开一个文件用于读写。写入的数据会被追加到文件末尾。如果文件不存在,创建新文件。
-
例子:
FILE *fp = fopen("file.txt", "a+");
-
-
"b"(二进制模式)
-
在"r"、"w"、"a"、"r+"、"w+"、"a+"后面添加"b",表示以二进制模式打开文件,这在Windows系统中是必要的,因为Windows区分文本文件和二进制文件。
-
例子:
FILE *fp = fopen("file.txt", "rb");(二进制读模式)
-
-
"t"(文本模式)
-
在"r"、"w"、"a"、"r+"、"w+"、"a+"后面添加"t",表示以文本模式打开文件,这在Windows系统中是默认模式,用于处理换行符等文本文件特性。
-
例子:
FILE *fp = fopen("file.txt", "rt");(文本读模式)
-
-
"e"(易编辑模式)
-
在"r"、"w"、"a"、"r+"、"w+"、"a+"后面添加"e",表示以易编辑模式打开文件,这在某些系统上可以提高文件的编辑性能。
-
例子:
FILE *fp = fopen("file.txt", "re");(易编辑读模式)
-
-
"x"(独占创建模式)
-
在"w"、"w+"后面添加"x",表示如果文件已存在,则打开操作失败;如果文件不存在,则创建新文件。
-
例子:
FILE *fp = fopen("file.txt", "wx");(独占创建写入模式)
-
这些模式可以组合使用,以满足不同的文件操作需求。在不同的操作系统和编译器中,这些模式的行为可能会有所不同,特别是在处理二进制文件和文本文件时。
以下是一些常见的文件调用方式的总结:
-
打开文件(fopen)
-
使用
fopen函数打开文件,并返回一个FILE指针。 -
语法:
FILE *fopen(const char *filename, const char *mode); -
filename是要打开的文件的名称,mode是打开文件的模式(如 "r" 读模式,"w" 写模式,"a" 追加模式等)。
-
-
关闭文件(fclose)
-
使用
fclose函数关闭一个已经打开的文件。 -
语法:
int fclose(FILE *stream); -
stream是指向FILE结构的指针,该结构标识了要关闭的文件。
-
-
读取字符(fgetc 和 getc)
-
fgetc从文件中读取一个字符,getc是fgetc的宏定义。 -
语法:
int fgetc(FILE *stream); -
返回读取的字符,如果到达文件末尾或发生错误,返回
EOF。
-
-
写入字符(fputc 和 putc)
-
fputc向文件写入一个字符,putc是fputc的宏定义。 -
语法:
int fputc(int c, FILE *stream); -
返回写入的字符,如果写入失败,返回
EOF。
-
-
读取字符串(fgets)
-
从文件中读取字符串,直到遇到换行符或文件末尾。
-
语法:
char *fgets(char *str, int num, FILE *stream); -
str是存储读取内容的字符串,num是最多读取的字符数,stream是文件指针。
-
-
写入字符串(fputs)
-
向文件写入字符串。
-
语法:
int fputs(const char *str, FILE *stream); -
str是要写入的字符串,stream是文件指针。
-
-
写入数据块(fwrite)
-
向文件写入数据块。
-
语法:
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream); -
ptr是指向数据的指针,size是每个数据项的大小,nmemb是数据项的数量,stream是文件指针。
-
-
读取数据块(fread)
-
从文件读取数据块。
-
语法:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); -
ptr是存储读取数据的指针,size是每个数据项的大小,nmemb是数据项的数量,stream是文件指针。
-
-
检查文件结束(feof)
-
检查是否到达文件末尾。
-
语法:
int feof(FILE *stream); -
如果到达文件末尾,返回非零值,否则返回零。
-
-
文件定位(fseek)
-
移动文件内部的读写位置指示器。
-
语法:
int fseek(FILE *stream, long int offset, int whence); -
stream是文件指针,offset是移动的字节数,whence是位置基准(SEEK_SET、SEEK_CUR、SEEK_END)。
-
-
获取文件位置(ftell)
-
获取当前文件的读写位置指示器。
-
语法:
long int ftell(FILE *stream); -
返回当前位置的偏移量。
-
-
重置文件位置(rewind)
-
将文件的读写位置指示器重置到文件开始。
-
语法:
void rewind(FILE *stream); -
相当于
fseek(stream, 0L, SEEK_SET)。
-
-
获取和设置文件位置(fgetpos 和 fsetpos)
-
用于处理大文件的定位。
-
fgetpos获取当前文件位置,fsetpos设置文件位置。 -
语法:
int fgetpos(FILE* stream, fpos_t* pos); int fsetpos(FILE* stream, const fpos_t* pos);。
-
这些函数提供了在C语言中进行文件操作的基本工具,允许程序读取和写入文件数据。
【示例程序在博客资源中】