在学习宽字节注入之前需要先简单了解一些编码
在学习宽字节注入时,要先了解各种编码。eg:二进制,十进制,十六进制,url编码,ascll码,GB2312--GBK编码,utf8编码,unicode万国码
ascll码表之前以了解过,主要简单介绍以下三种编码
URL编码(也叫百分号编码):
①将需要进行编码的字符替换:为其对应的编码形式,使用 "%" 其后跟随两位的十六进制数来替换非 ASCII 字符。
②对于URL中的保留字符,也需要进行编码。
③URL 不能包含空格,通常使用加号(+)或 %20 替代空格。
④其他字符出现在 URL 之中都必须转义,规则是根据操作系统的默认编码,将每个字节转为百分号(%)加上两个大写的十六进制字。
UTF-8编码
UTF-8是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无需或只进行少部分修改后,便可继续使用。
基本特征
UCS字符U+0000到U+007F(ASCII)被编码为字节0x00到0x7F(ASCII兼容)。这意味着只包含7位ASCII字符的文件在ASCII和UTF-8两种编码方式下是一样的。
所有大于0x007F的UCS字符被编码为一个有多个字节的串,每个字节都有标记位集。
因此,ASCII字节(0x00-0x7F)不可能作为任何其他字符的一部分。表示非ASCII字符的多字节串的第一个字节总是在0xC0到0XFD的范围里,并指出这个字符包含多少个字节。多字节串的其余字节都在0x80到0xBF范围里。这使得重新同步非常容易,并使编码无国界,且很少受丢失字节的影响。
UTF8分成单字节、双字节、三字节、四字节模式。
UTF-8编码字符理论上可以最多到4个字节长,然而16位BMP字符最多只用到3字节长, UCS-4字节串的排列顺序是预定的,字节0xFE和0xFF在UTF-8编码中从未用到。
编码字节数
UTF-8使用1~4字节为每个字符编码:
·一个US-ASCIl字符只需1字节编码(Unicode范围由U+0000~U+007F)。
·带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等字母则需要2字节编码(Unicode范围由U+0080~U+07FF)。
·其他语言的字符(包括中日韩文字、东南亚文字、中东文字等)包含了大部分常用字,使用3字节编码。
·其他极少使用的语言字符使用4字节编码。
字符集
UTF-8编码规则:如果只有一个字节则取值为0x00-0x7F。其余字节按长度进行以下拓展:
UTF-8由4种编码方式实现,即UTF8-1/UTF8-2/UTF8-3/UTF8-4
其中:
UTF8, 16进制编码表
UTF8-1
0x00-0x7F
UTF8-2
0xC2-0xDF 0x80-0xBF
UTF8-3
0xE0 0xA0-0xBF 0x80-0xBF
0xE1-0xEC 0x80-0xBF 0x80-0xBF
0xED 0x80-0x9F 0x80-0xBF
0xEE-0xEF 0x80-0xBF 0x80-0xBF
UTF8-4
0xF0 0x90-0xBF 0x80-0xBF 0x80-0xBF
0xF1-0xF3 0x80-0xBF 0x80-0xBF 0x80-0xBF
0xF4 0x80-0x8F 0x80-0xBF 0x80-0xBF
每种编码可能有多个编码范围,每个编码范围间,以空格作为每个字节的分隔符。UTF8-3的第一个编码,其第一个字节取值必须为0xE0,第二个字节范围为0xA0-0xBF,第三个字节为0x80-0xBF
Unicode(统一码、万国码)
Unicode编码是一种字符编码规范,旨在为世界上每一种文字系统的每一个字符分配一个唯一的整数编号,从而避免任何冲突。Unicode编码规则的核心在于其分配机制和编码格式。
Unicode编码规则的核心概念
①码点(Code Point):每个字符都被分配一个唯一的码点,格式为U+[XX]XXXX,范围从U+0000到U+10FFFF,足以容纳超过100万个字符。
②字符平面:Unicode采用分组的方式存储字符,每个组称为一个平面,每个平面能容纳65536个字符。
Unicode编码的分配机制
Unicode通过两个主要的编码格式来存储字符:
UTF-16:这是Unicode的缺省编码格式,每个字符占用16位(两个字节)。对于一些扩展字符,UTF-16使用一对代用字符进行编码,高位代用字符在U+D800到U+DBFF之间,低位代用字符在U+DC00到U+DFFF之间。
UTF-8:这是一种变长的编码格式,适用于面向字节基于ASCII的应用程序和文件系统。UTF-8可以将Unicode字符转换为变长的ASCII安全的字节字符串,非补充字符最多占用3个字节,补充字符最多占用4个字节。
下面我们进入正题
一、宽字节注入原理
宽字节注入是一种SQL注入攻击方式。在数据库使用GBK等宽字节编码(且必须是GBK编码时才可以用宽字节注入,其他不行)时,一个汉字占两个字节。
在PHP中,当开启 magic_quotes_gpc (该函数会对特殊字符转义)后,输入的单引号 ' 前自动加上转义符' \' ,从而让单引号‘失效。
攻击者利用宽字节编码特性,通过输入特定字节序列,让转义符号 \ 与后面字节组成一个汉字,从而使单引号 ' 能发挥SQL注入作用,达到恶意攻击目的。
eg:
一个登录验证的SQL语句为select * from users where username='$username' and password='$password' 。
正常情况下,若用户的输入包含单引号会被转义。
但攻击者在用户名输入框输入 %df' or 1=1# (这里 %df 在GBK编码下与转义字符 \ 组成一个汉字),SQL语句就会变成 select * from users where username='汉字' or 1=1# and password='$password' ,这样就绕过了原本基于用户名的验证,使攻击者可能成功登录系统。
现在先简单了解其原理,在下面实例中会详细介绍说明
到这里我们需要来简单了解一下转义函数
转义函数

主要了解在php中用的两个转义函数
① addslashes() 函数
主要用于在某些字符前添加反斜杠 \ 。
主要作用是对字符串进行转义。当处理要插入数据库中的数据时,例如用户输入的数据可能包含单引号 ' 、双引号 " 、反斜杠 \ 和 NULL 字符(这四个字符在SQL语句中有特殊含义),使用 addslashes() 函数转义这些字符,能够避免这些字符破坏SQL语句的语法结构,从而降低SQL注入攻击的风险。
eg:原始字符串 I'm a "user" ,经过 addslashes() 函数处理后会变为 I\'m a \"user\" ,这样在SQL语句中使用这个转义后的字符串,就不会因为特殊字符而导致语法错误或被恶意利用。
不过需要注意的是, addslashes() 函数只是简单的转义,并不能完全确保安全,最好结合数据库提供的预处理语句来增强安全性。
②mysql_real_escape_string() 函数
此函数也是用于对SQL语句中的特殊字符进行转义,这些特殊字符包括单引号 ' 、双引号 " 、反斜杠 \ 和 NULL 字符等。它考虑了当前使用的字符集,会正确地转义可能导致SQL注入攻击的字符。
例如,当用户输入的数据包含SQL语句的特殊字符(如一个包含单引号的用户名 O'Connor ),如果直接将这个数据用于构建SQL查询语句,就可能会破坏SQL语句的语法结构,引发SQL注入。
使用 mysql_real_escape_string() 函数,就能把这些特殊字符进行转义,转义后的字符串可以安全地用于SQL查询(如insert 、 update 等操作),大大降低了SQL注入攻击的风险。
不过,使用预处理语句(我们还没有学习到,后续可以再进行了解)是更安全的做法, mysql_real_escape_string() 函数是在无法使用预处理语句等更高级安全措施时的一种补充手段。
二、宽字节注入实例
在这里先将宽字节注入和字符型注入进行对比来分析一下
当是字符型注入时,用xx' or 1=1这样的注入语句进行测试时,就注入成功,查询出来在pikachu数据库中的所有用户的相关信息(如下图)

而当是宽字节注入时,也是用xx' or 1=1#这样的注入语句进行测试查询,却显示“您输入的username不存在,请重新输入”(如下图)

此时我们需要分析宽字节注入的脚本语言进而来分析它用xx' or 1=1#注入失败的原因
依然是在资源管理器中找到宽字节注入的脚本语言进行分析
先对这里的查询过程进行简单介绍(如下图)
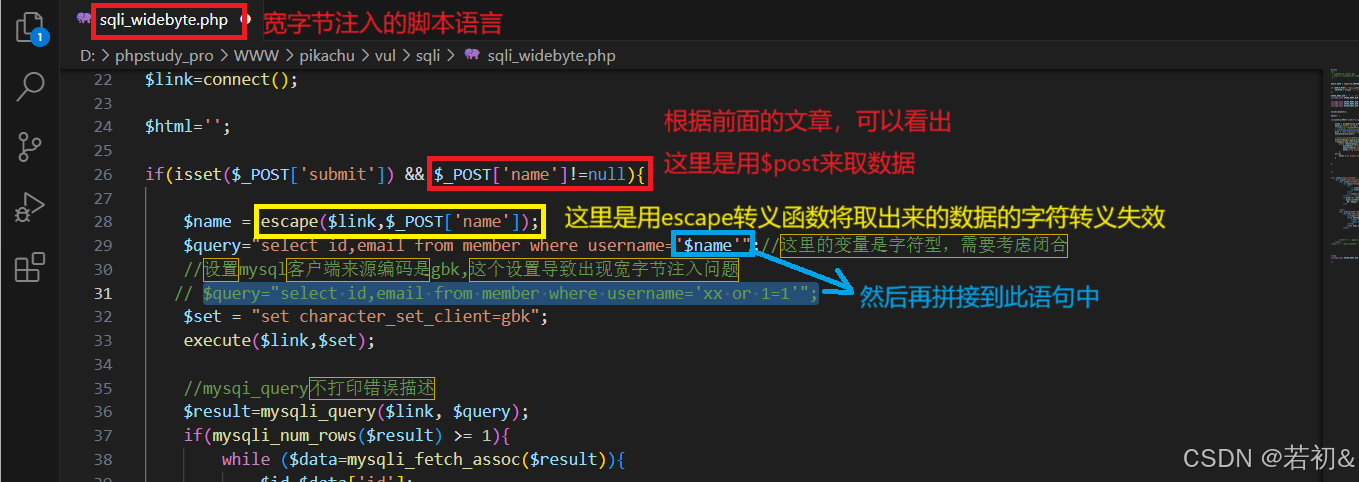
我们接着上面宽字节注入时,用xx' or 1=1#进行查询测试来解释
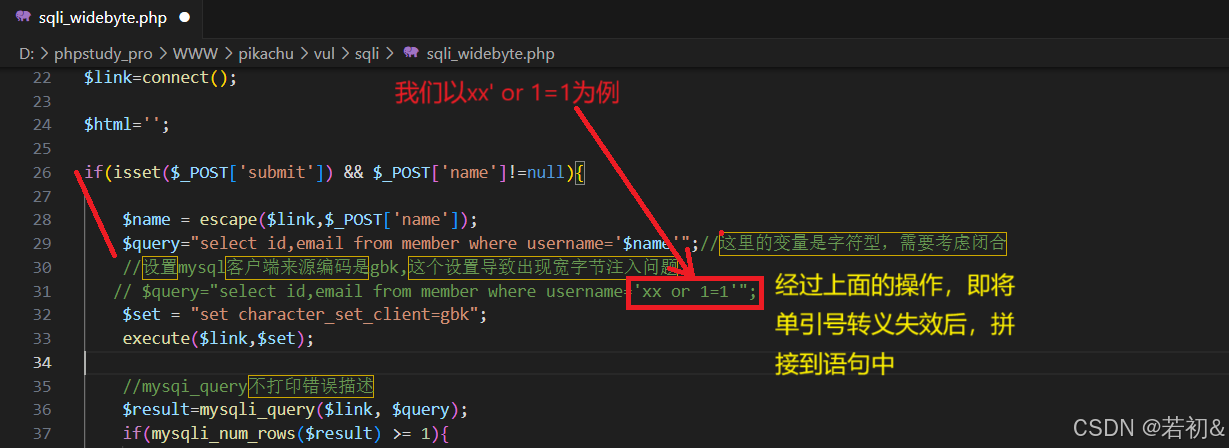
由$query="select id,email from member where username='xx or 1=1'";这个语句中的单引号闭合情况可以看出在这里其执行的命令是在数据库里查询用户名为xx or 1=1#的信息,并不是原来输入的xx' or 1=1#时的执行逻辑(即or 后面的1=1永远为真,数据库里面的数据信息都符合,所以它呈现出来所有用户的信息!前面的字符型注入用xx' or 1=1#进行查询测试时就是如此!),而数据库里没有用户名为xx' or 1=1#的信息,所以它显示“您输入的username不存在,请重新输入”。
要想对其他有引号闭合问题导致的SQL注入进行同样的转义防护,措施(这个措施对数值型的注入,即没有引号闭合问题的没有作用)如下
我们找到php的配置文件
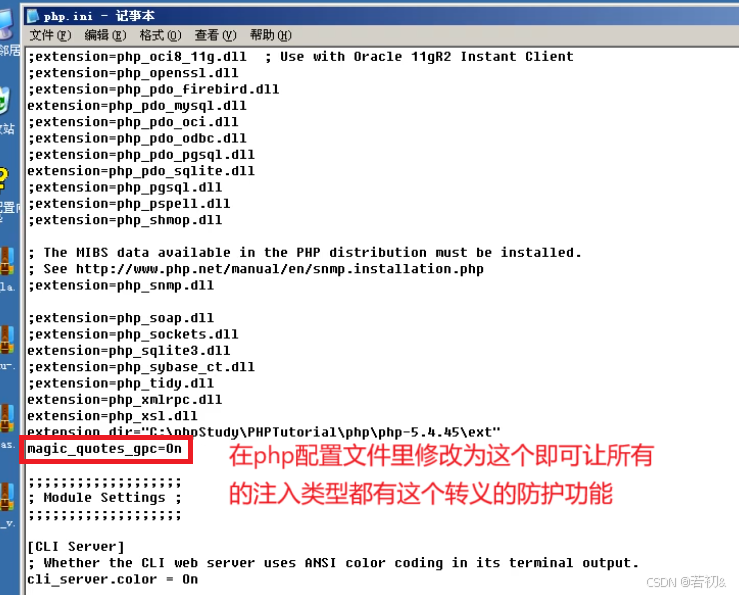
即使是前面解释的字符型注入用xx' or1=1#来进行查询测试,查询出了所有用户的信息,而在修改了配置文件后在这里xx后面的单引号会被转义失效,从而改变了注入语句原有的执行逻辑(如下图):
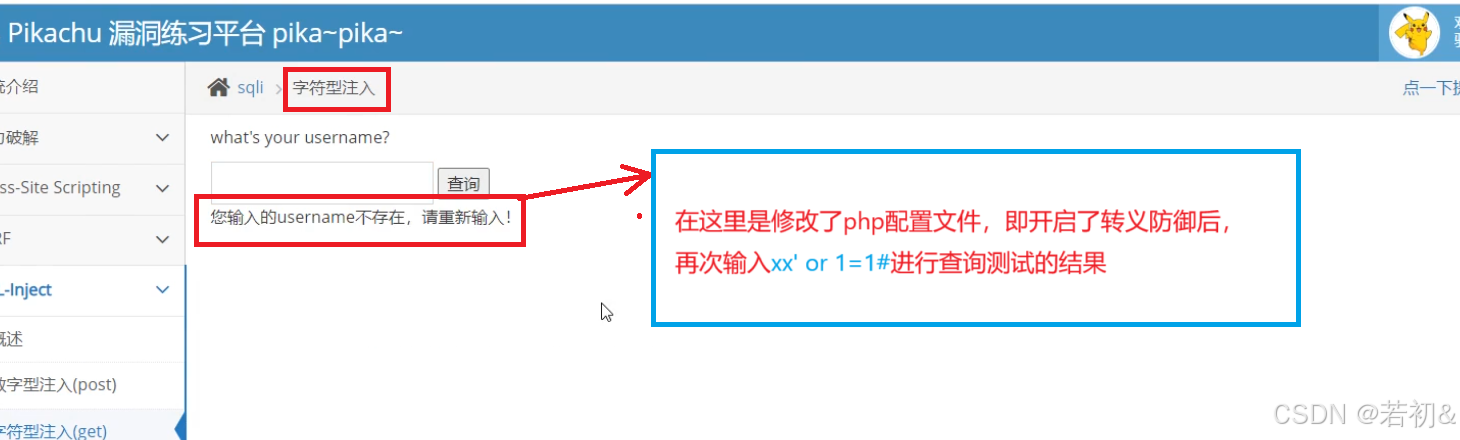
既然有了转义防护,那么我们要想进行成功注入,就需要绕过(即不使用单引号)或使用宽字节注入
我们在xx' or 1=1#的单引号前面加上%df,让它和用escape()转义函数在单引号’前面加上的反斜杠/两者结合,组成了一个汉字,从而让反斜杠/失去转义的功能,仍让输入的注入语句保有原来的执行逻辑
组成的汉字如下(df是一个十六进制数,5c即代表单引号‘,在这里df与5c组合成了一个汉字)
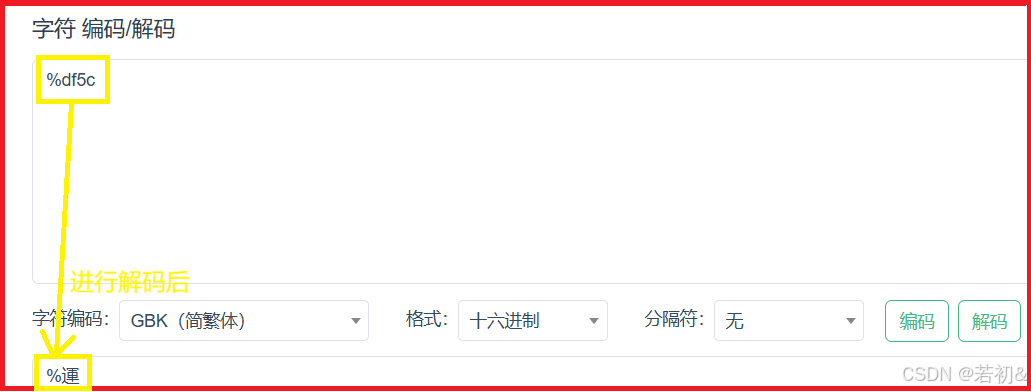
我们还是在用户框里输入xx' or 1=1#来进行测试查询,进行抓包,如下图所示
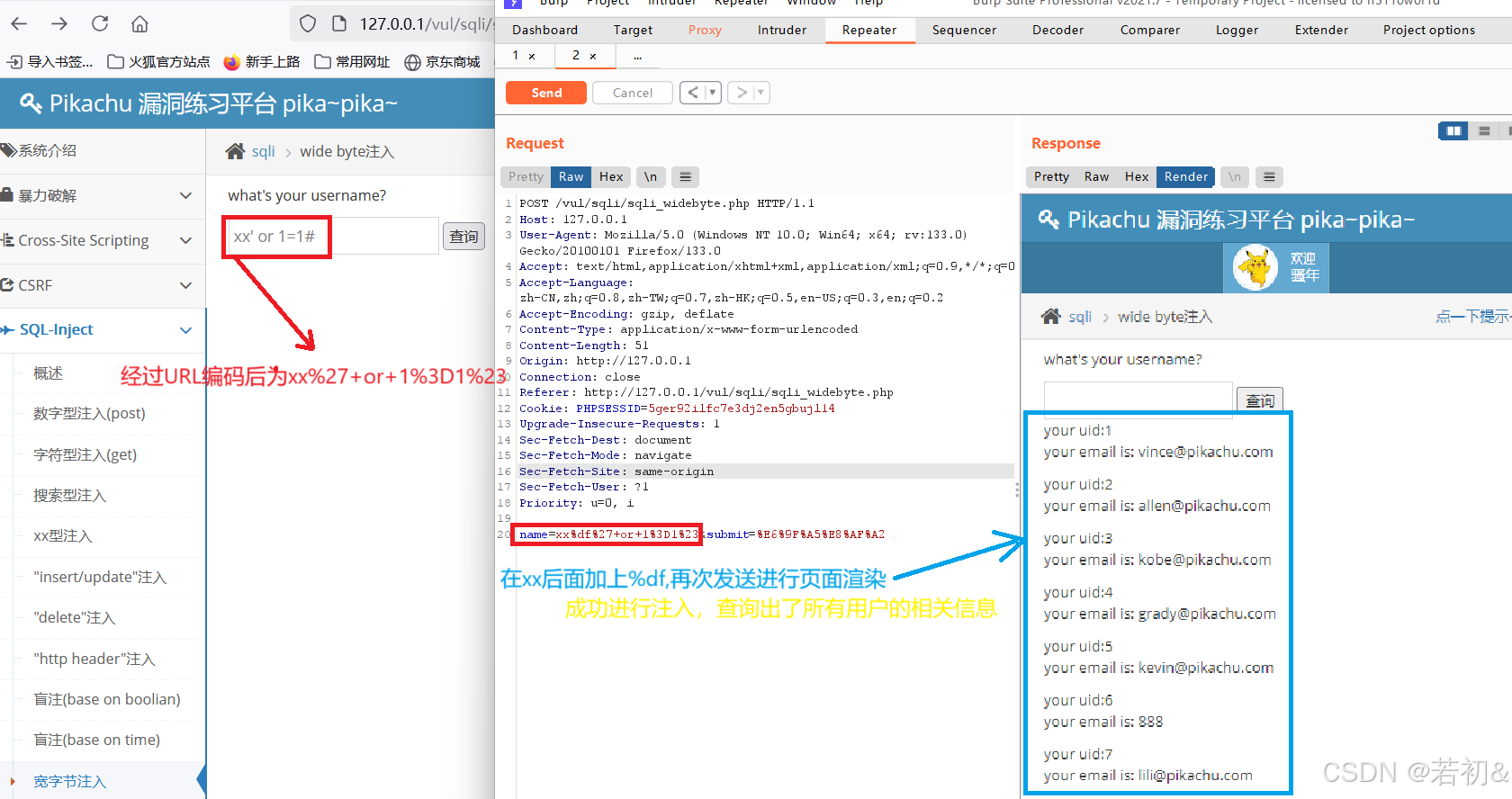
修改后的注入语句拼接到原脚本语言中,单引号正常闭合为'xx汉字' or 1=1#
即$query="select id,email from member where username='xx汉字' or 1=1#";
如下图(修改后的脚本语言)
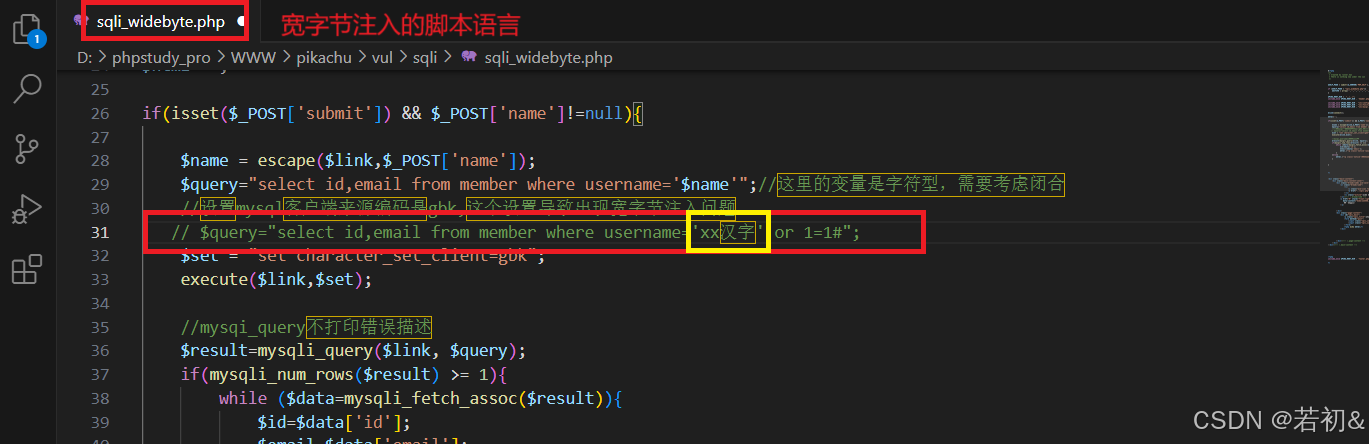
那么在这里or 后面的1=1条件永远为真(对于中间为or的只要有一边为真,那么全为真),数据库里面的数据信息都符合,所以它呈现出来所有用户的信息!
三、宽字节注入的防范
1.统一使用正确的字符编码
整个应用系统尽量采用UTF - 8编码,这种编码方式对字节的处理比较规范,不易出现宽字节注入的问题。
2.对用户输入进行严格过滤和转义
① 在接收用户输入数据的入口点,如表单提交、URL参数等位置,使用函数对特殊字符进行过滤,如撇号(')、双引号(")、分号(;)等可能用于SQL注入的字符。例如,在PHP中可以使用 addslashes 函数(不过此函数也有局限性)。
②更好的是使用参数化查询(也叫预处理语句)。现在还未见到,等学习到会再详细介绍!
以上为个人在学习时的总结,如有错误,欢迎大家前来评论指正哦!!!