注意:前缀和表示以nums[0]为起始位置,一直到遍历位置所有元素组成的数组之和;
寻找数组的中心下标
题目解析

算法原理
解法一 :暴力解法
在遍历到一个元素时,判断这个元素左右的元素之和是否相等即可;
每次遍历到一个元素,就要左边枚举一遍,右边枚举一遍;枚举一个元素的左右之和,时间复杂度为O(N),所以暴力解法 O(N^2);
解法二 : 使用前缀和数组
预处理前缀和数组和后缀和数组
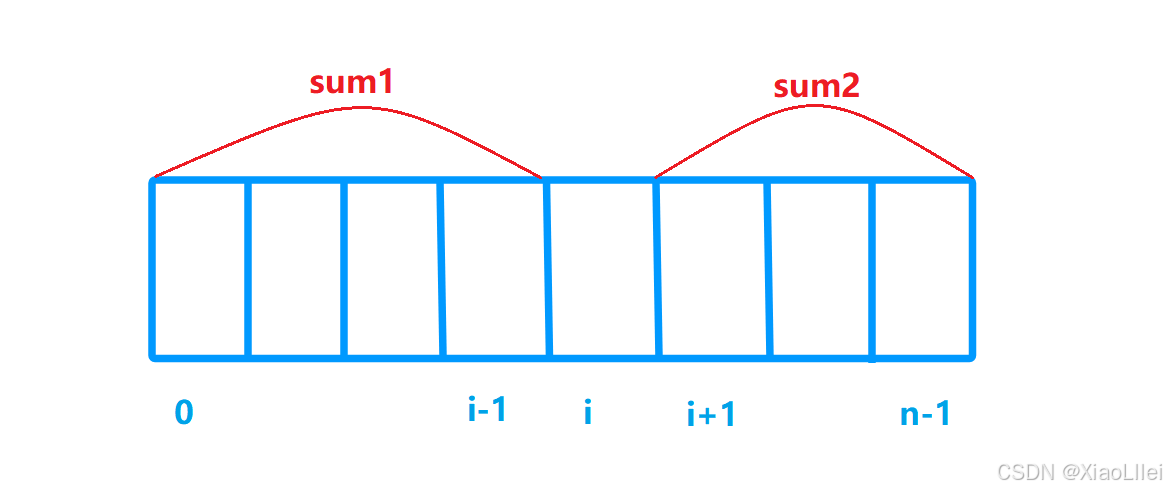
我们在求 [0, i -1] 和 [ i+1 , n - 1 ] 区间的元素之和,就是在求一段连续区间的和,这就可以利用前缀和的预处理;
注意:不要死记前缀和的 dp 公式,因为公式是适用于从下标为 1 的数组开始计数的,而当从下标为0的数组元素开始计数,就需要处理边界情况;
因为本题需要求前面区间的和与后面区间的和,所以我们可以调整一下前缀和数组的表达方式;
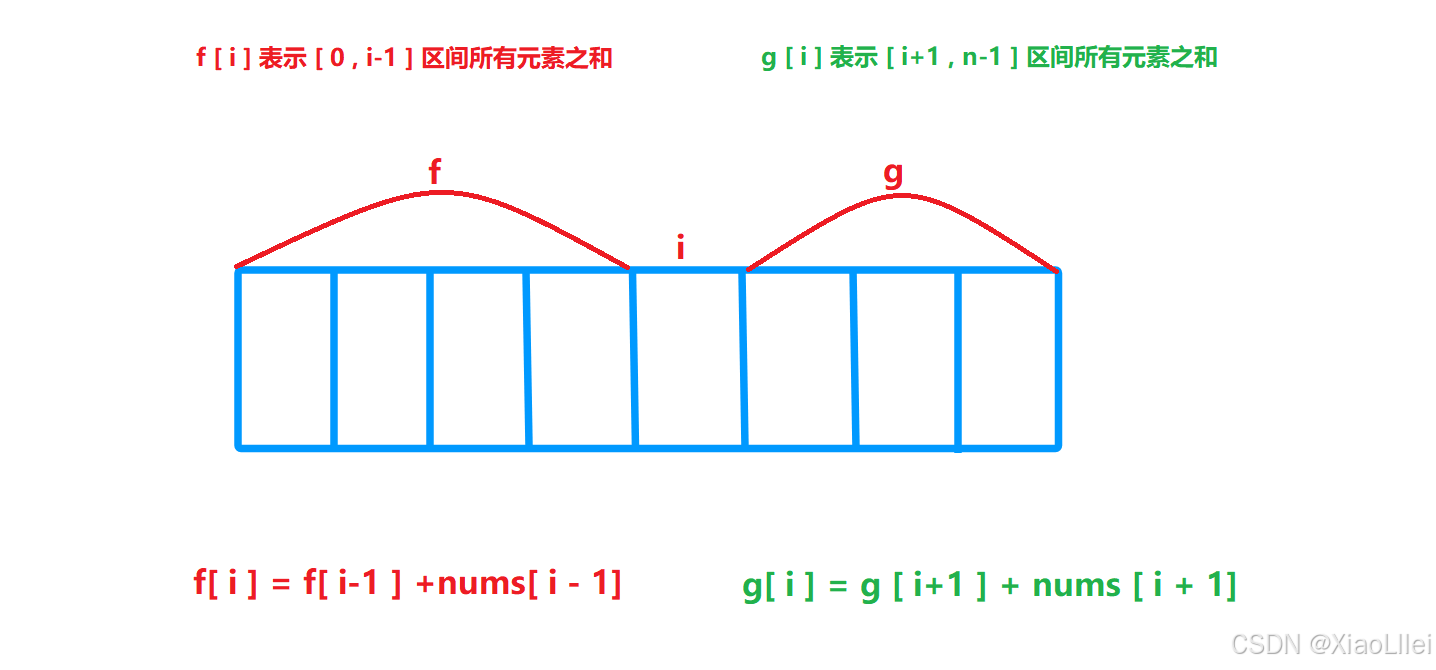
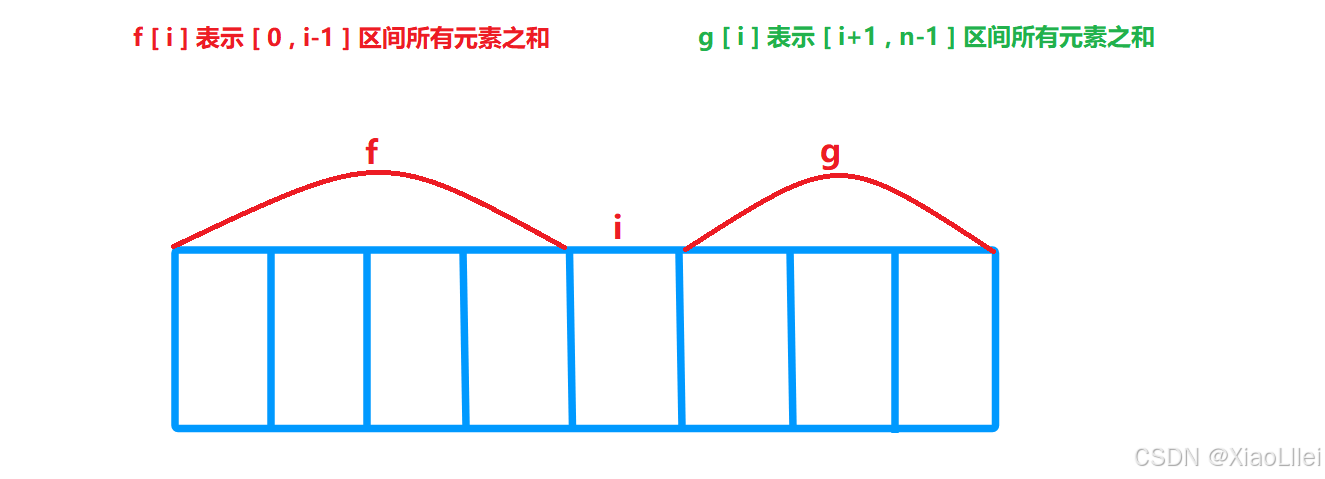
我们用 f 表示前缀和数组,g 表示后缀和数组:
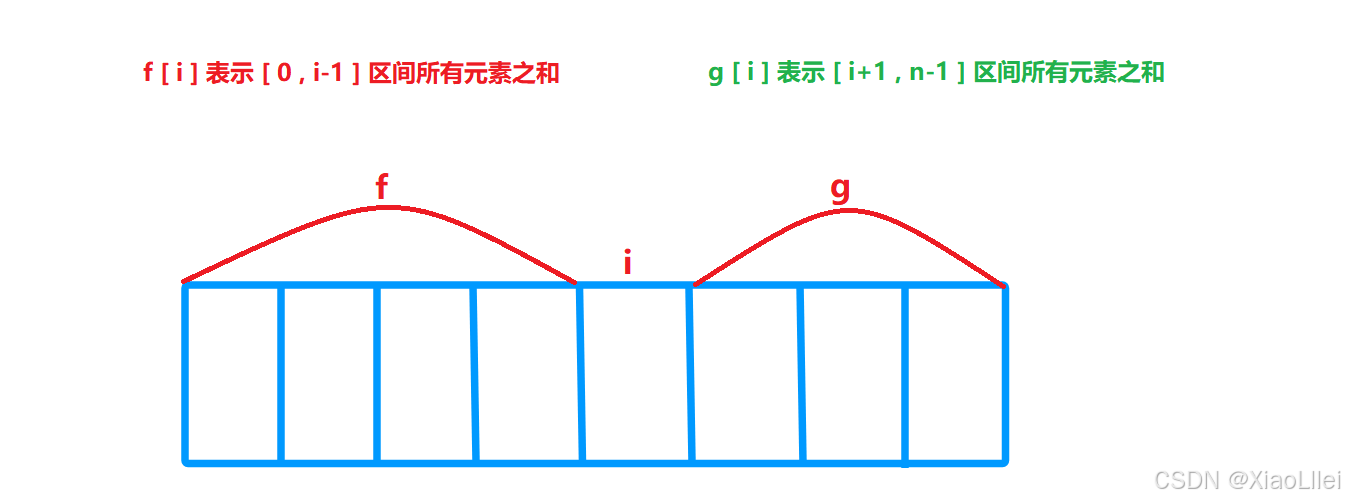
f [i] 表示 [ 0 , i -1 ]区间的元素之和,而前面的 dp[ i ] 表示的是 [ 1 , i ] 区间的元素之和,这题这样微调,是因为数组从 0 下标开始,且前缀和数组的元素 f[ i ],是不包括arr[ i ] 元素的求和值;
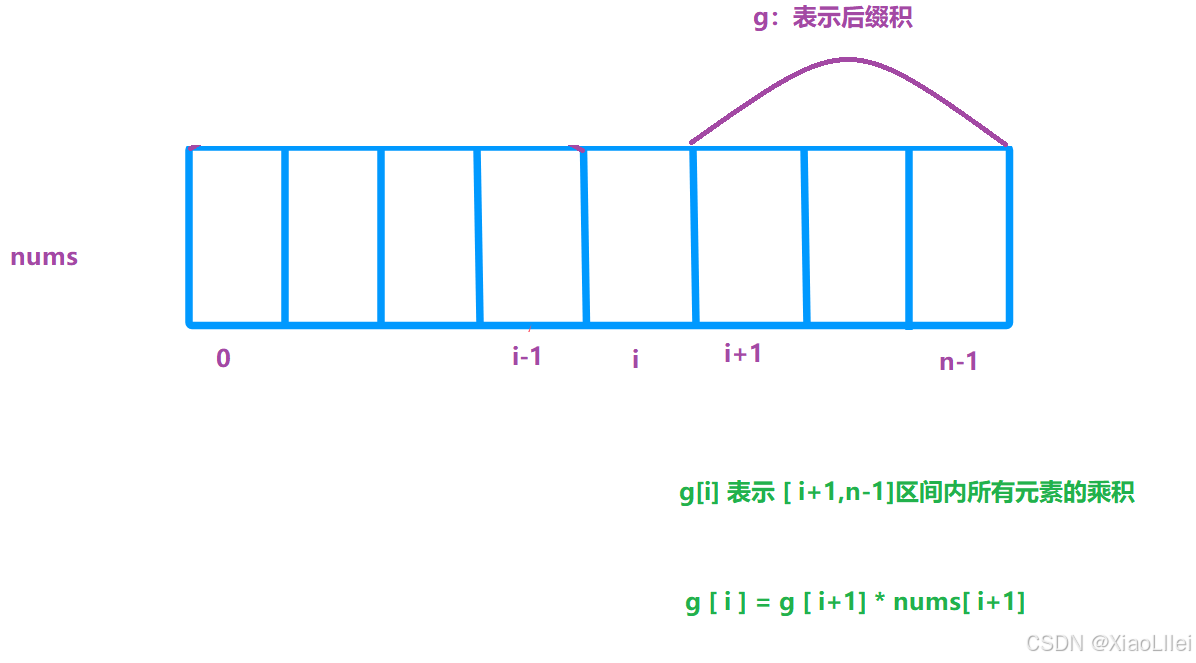
g [i] 表示 [ i+1 , n-1] 区间所有元素之和,之前是求[ i , n ] 区间的和,微调的原理同上;
递推公式:
使用前缀和数组和后缀和数组
我们可以在 [ 0 , n - 1 ] 区间,直接枚举预处理好的前缀和与后缀和数组,并且判断当前枚举的预处理数组元素 f [ i ] ,g[ i] 是否相等,相等返回最左边的中心下标,否则返回 -1;
处理细节问题
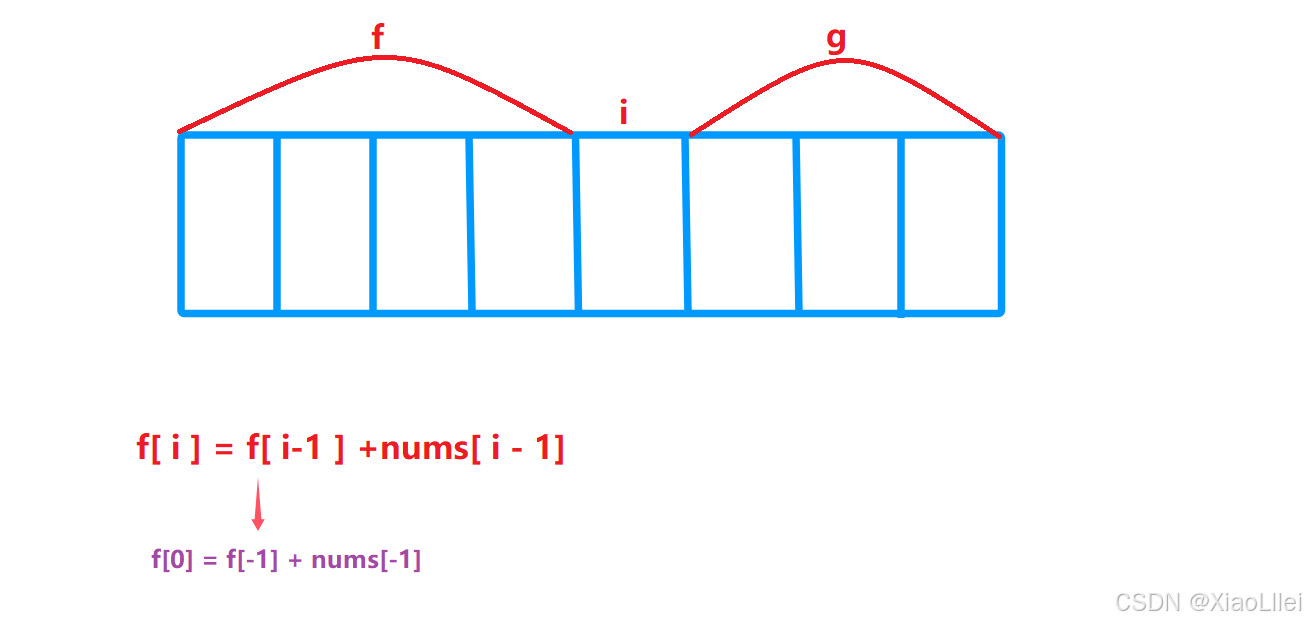
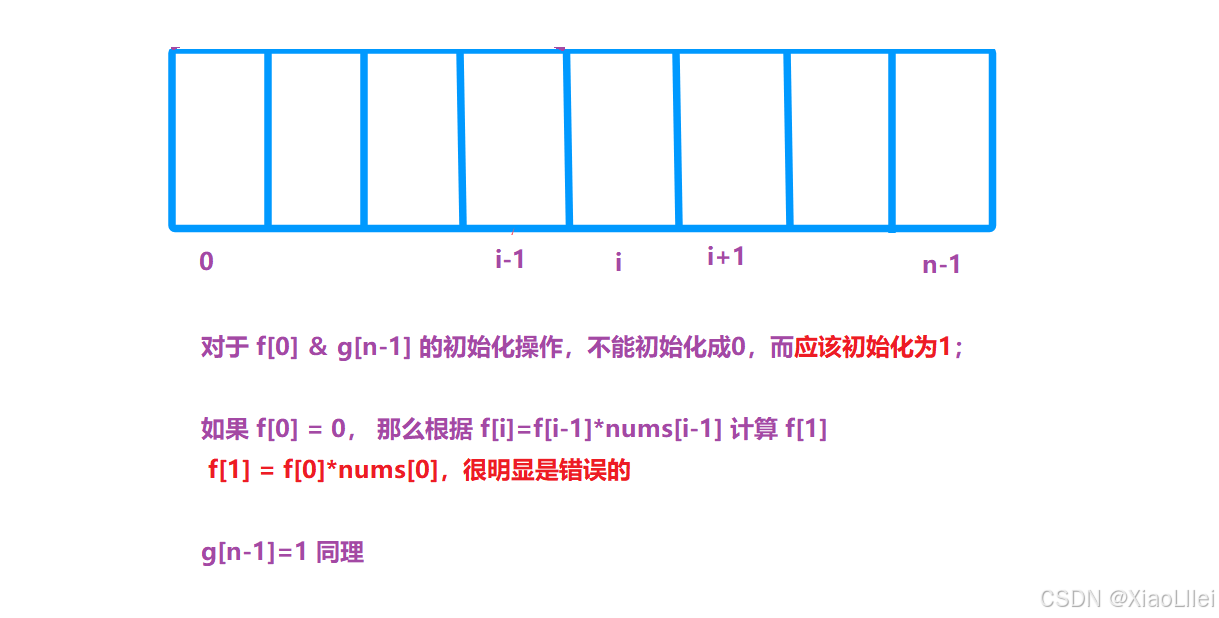
初始化问题
f ( 0 )
我们按照如上的方法去填 f[0] 时,会出现越界访问:
g ( 0 )
当 i = n-1 时,也会出现越界访问:
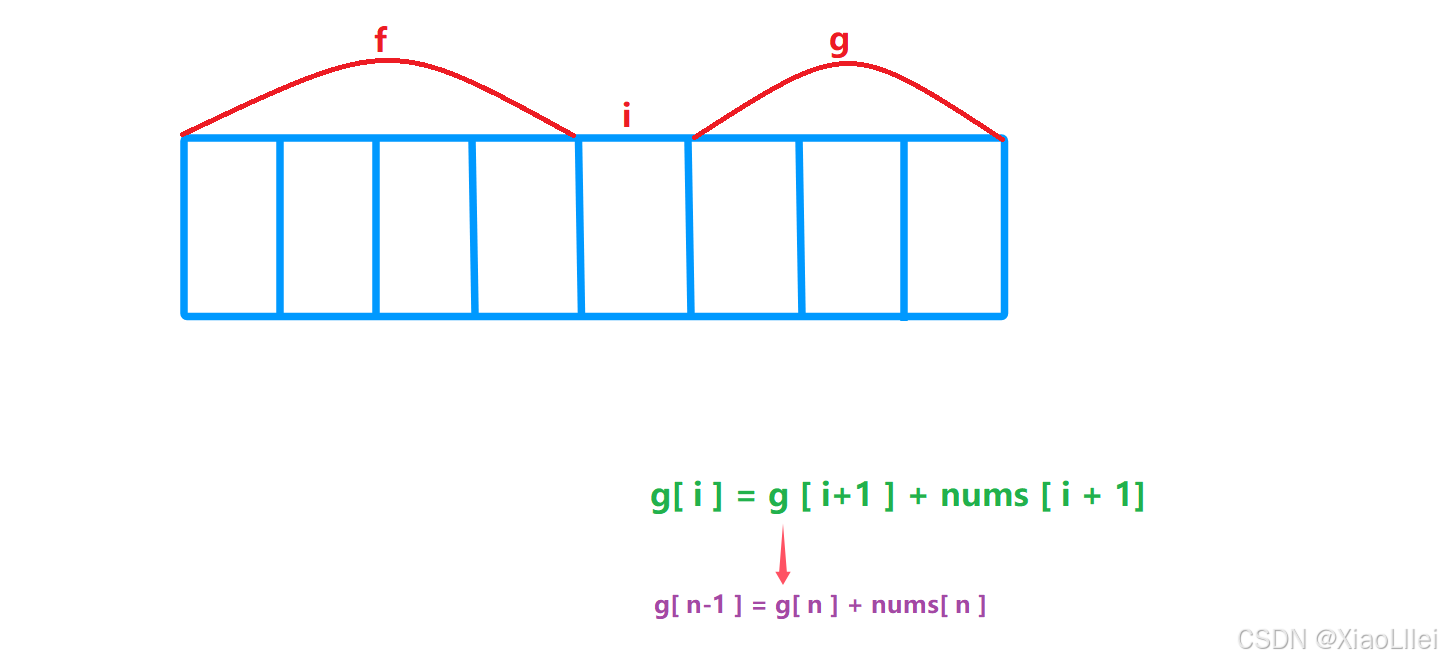
所以 g( n - 1 ) 同理也初始化为0;
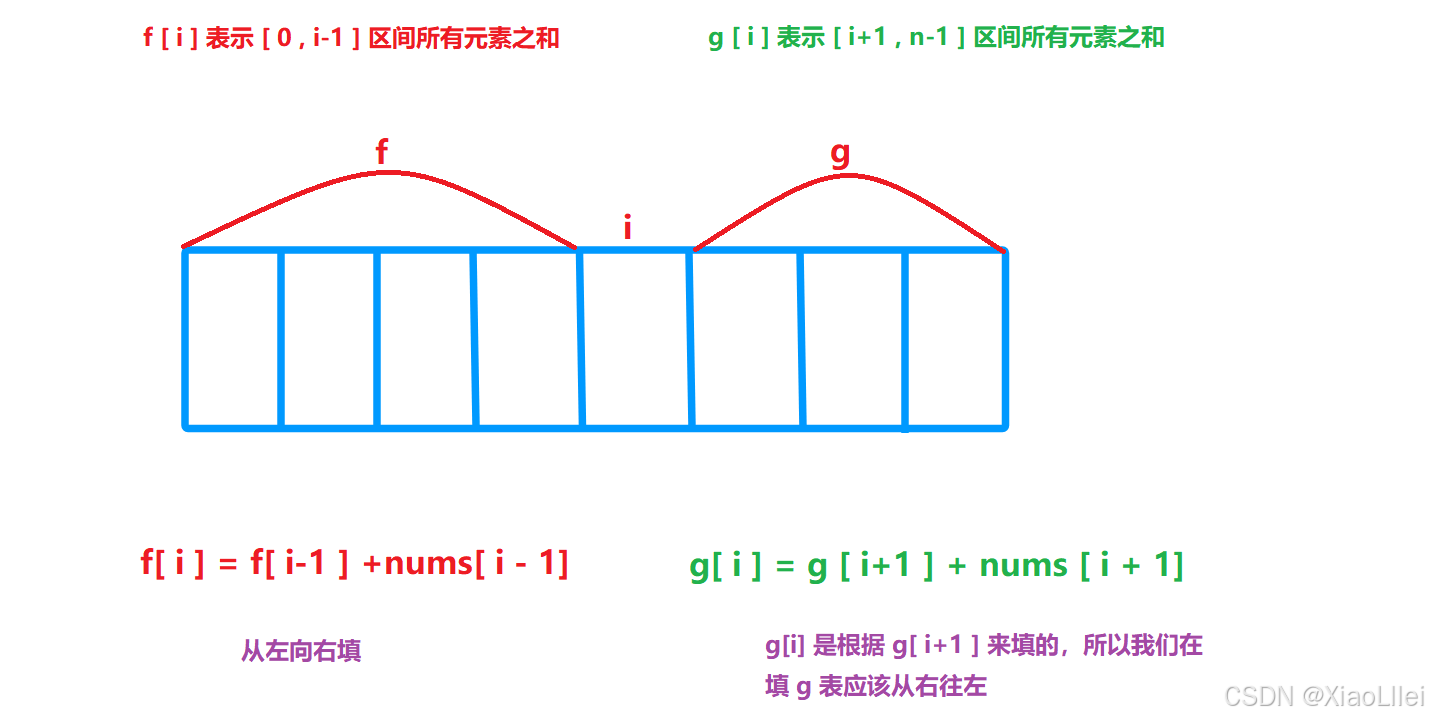
填表顺序
编写代码
除自身以外数组的乘积
题目解析

算法原理
解法一 :暴力解法
每遍历到一个数组元素,就计算一次这个数组中,除该元素外的所有元素的乘积,得到的结果返回对应下标的 answer 中;时间复杂度O(N^2);
解法二 : 使用前缀积数组
预处理前缀积数组&后缀积数组
我们可以先看 nums 数组其中一个位置 nums[i] :
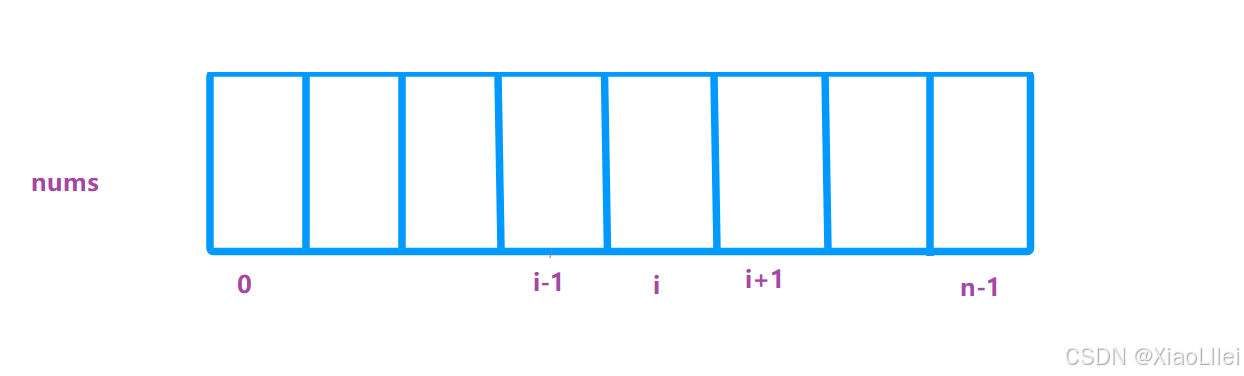
定义前缀积数组&后缀积数组:
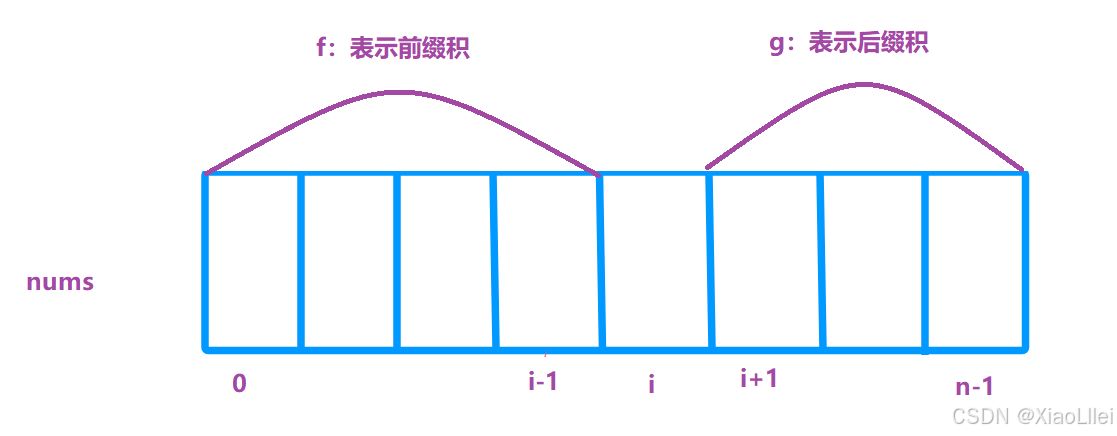
解析 f[ i ] & g[ i ]
f [ i ] 的含义&递推公式
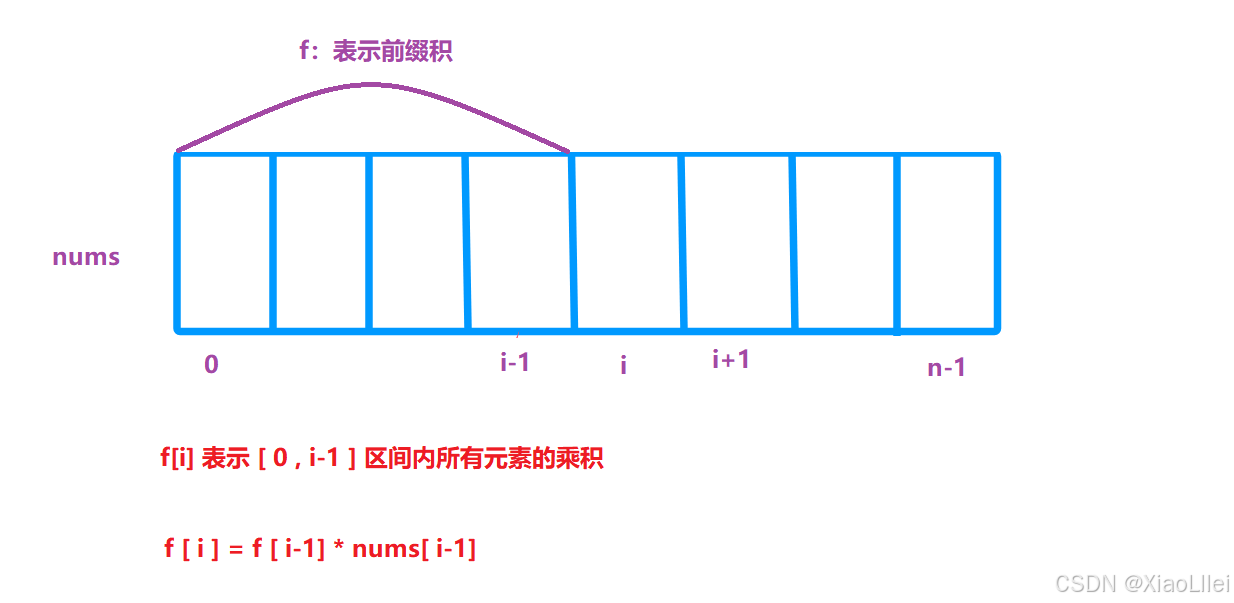
g [ i ] 的含义&递推公式
前缀和方法是典型的以空间换时间,预处理操作虽然多创建了一个数组,但是时间复杂度会得到质的提升;
使用前缀积数组&后缀积数组
创建一个与 nums 数组同等规模的数组 answer:
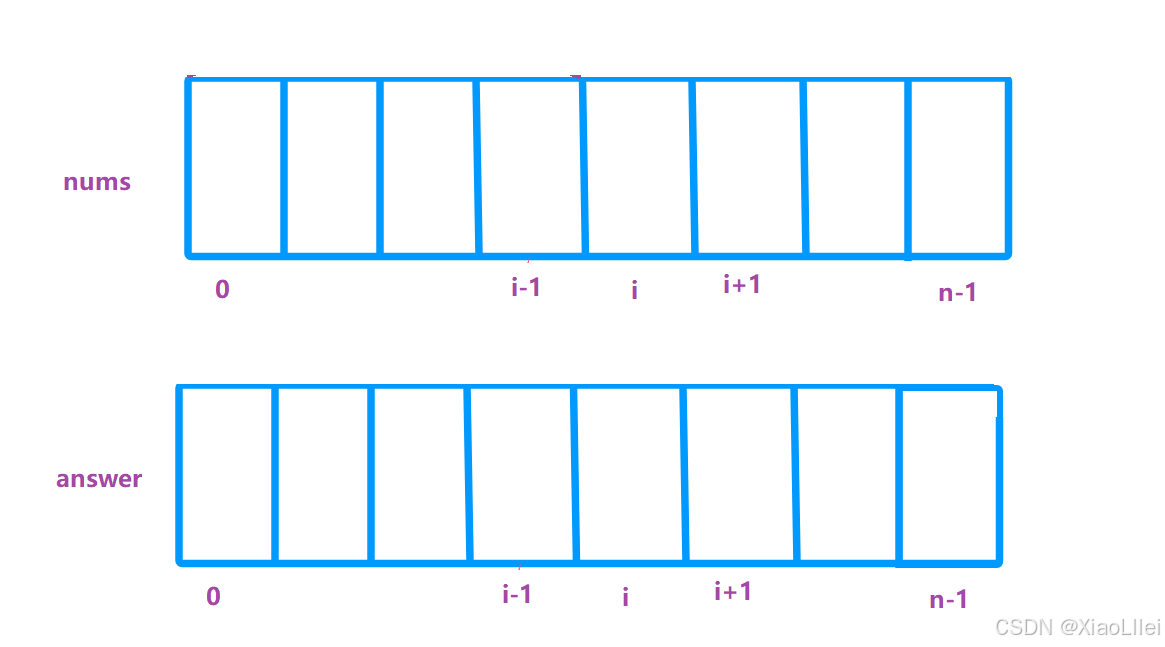
而在填 answer 时,只需要计算 answer [i] = f [i-1] * g [i+1] ;
处理细节问题
处理填 g[i] 时需要从后往前填外,还需要注意初始化问题:
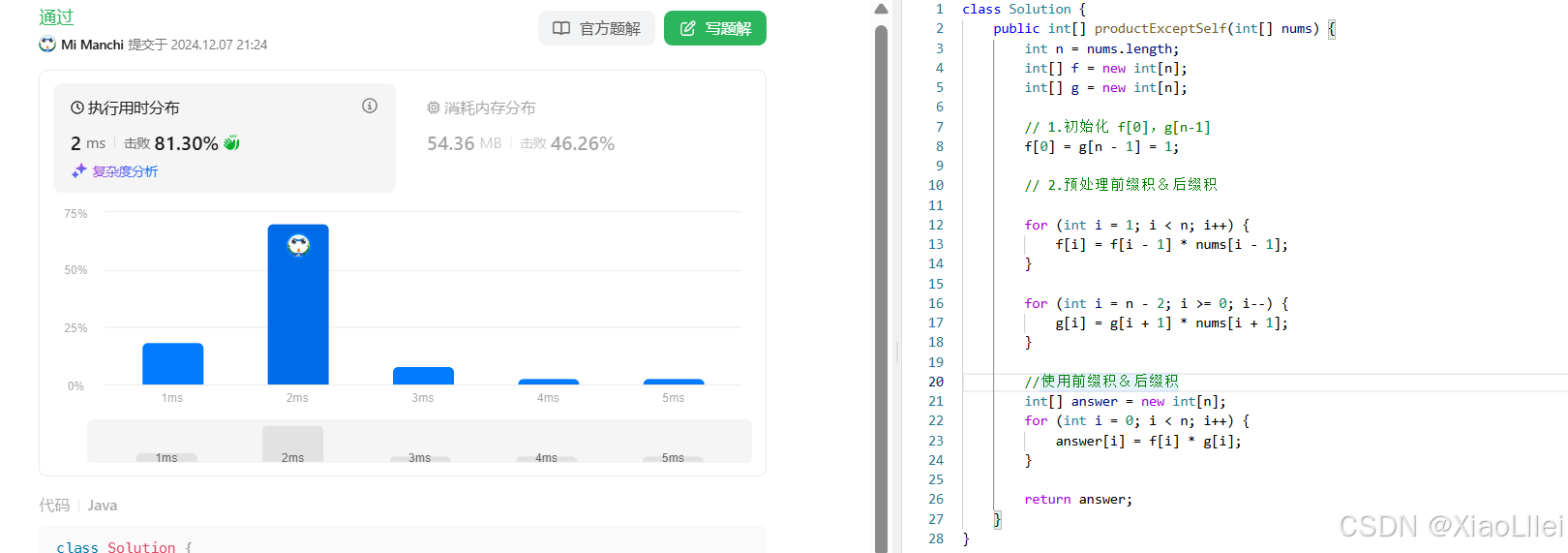
编写代码
和为K的子数组
题目解析

算法原理
解法一 :暴力解法
我们可以使用O(N^2) 的时间复杂度枚举出所有子数组:
当我们向后枚举到一个元素,使得和为k时,不能停止,也就需要向后继续枚举:
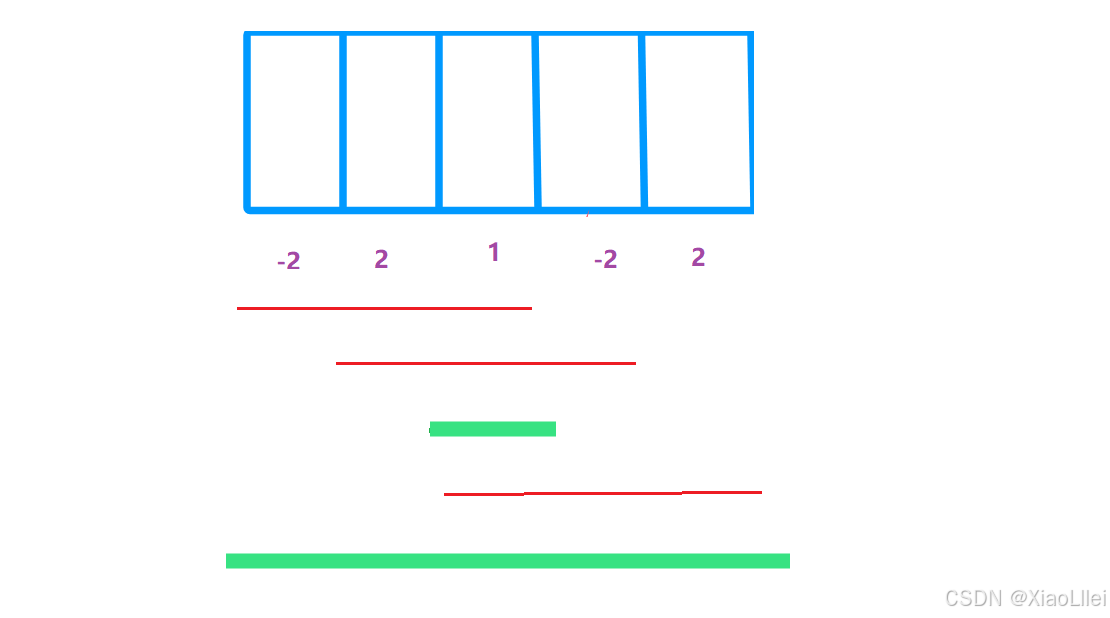
直到枚举完最后一个元素,此时起始下标的枚举才完成;所以这道题是不能用双指针(滑动窗口)来做优化的,因为这道题的不具备单调性, 每一个元素可正可负可为0,我们来模拟一下滑动窗口不能处理的情形:
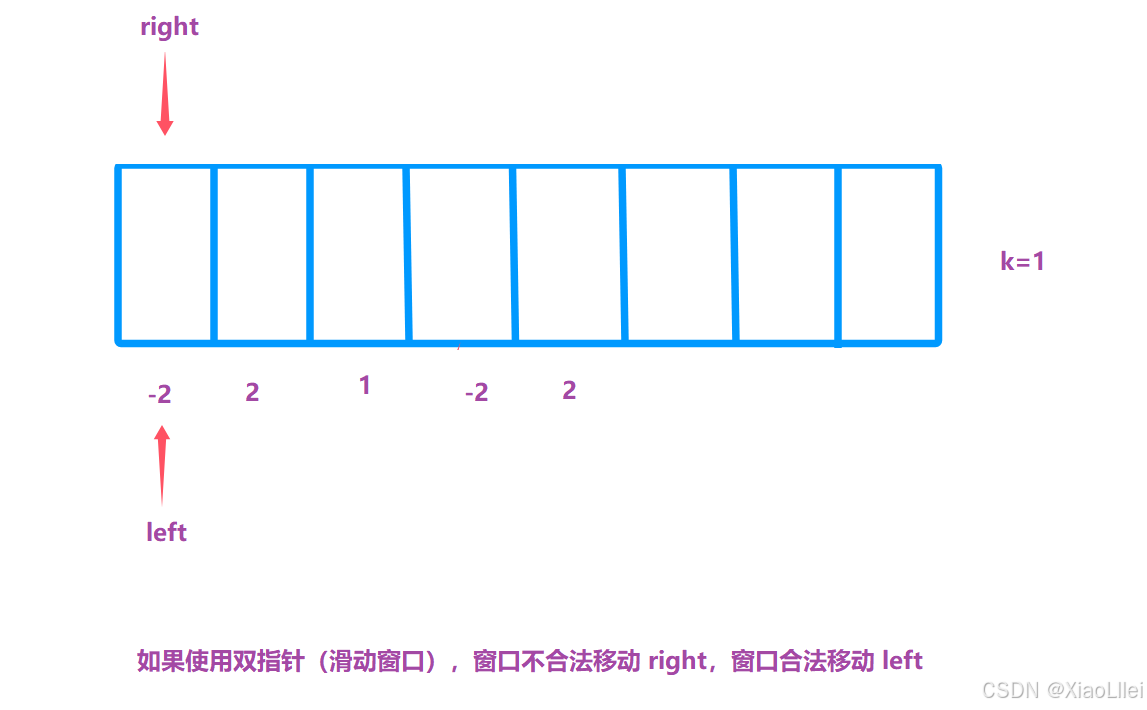
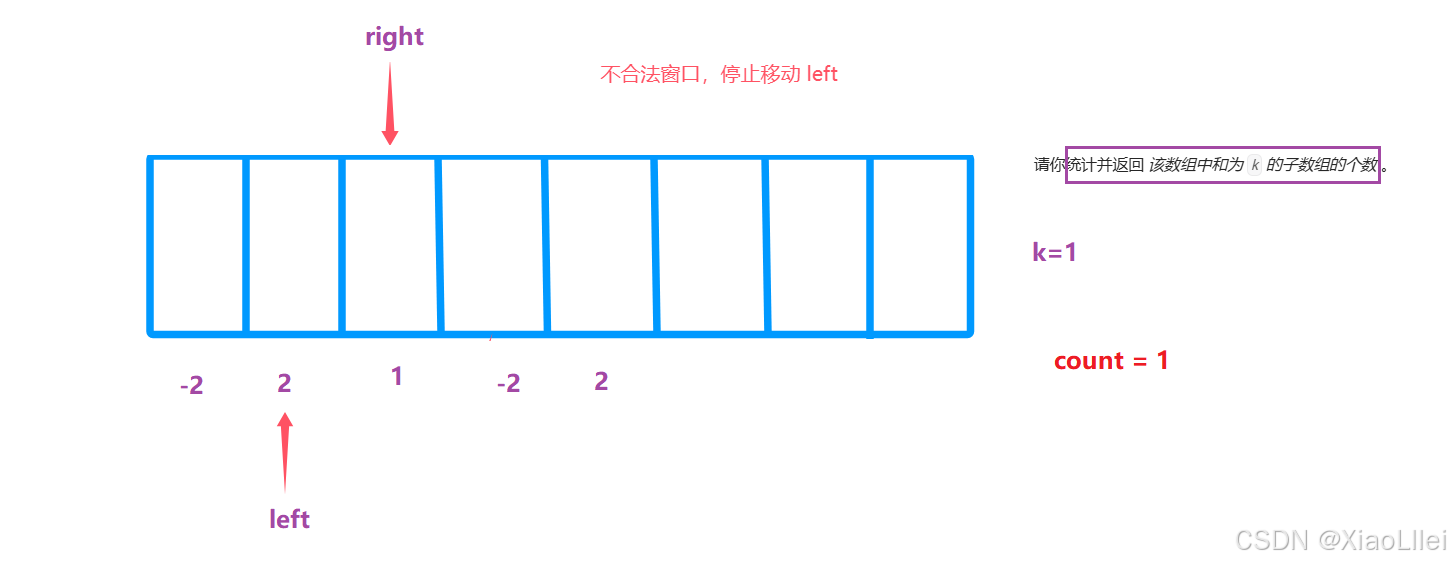
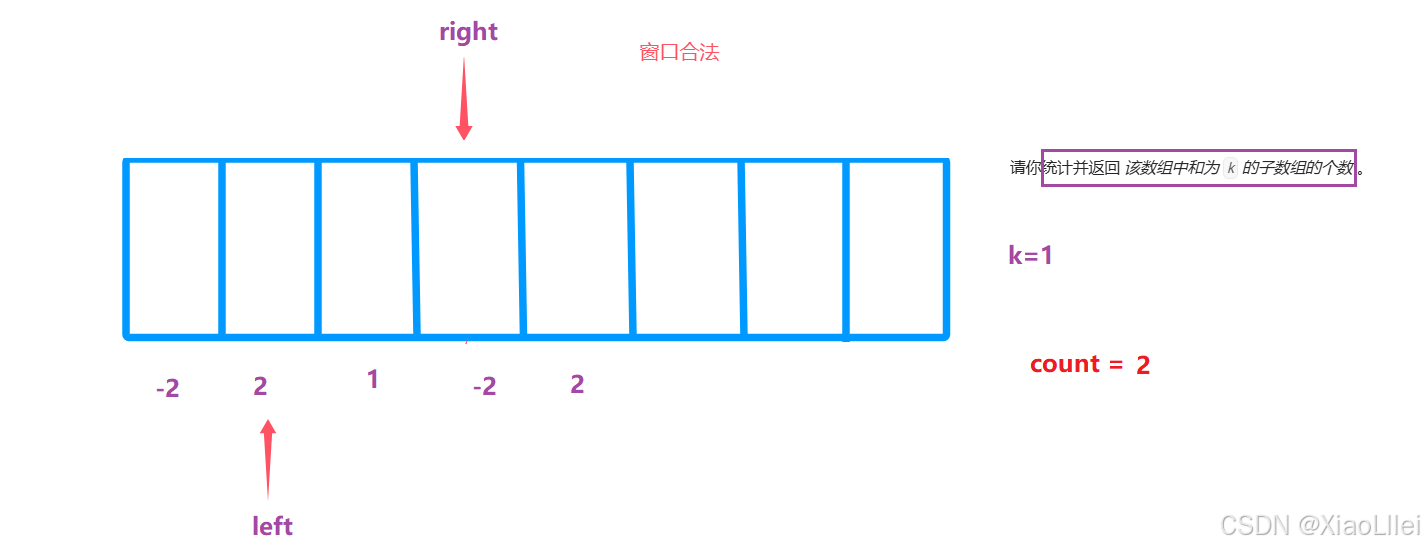
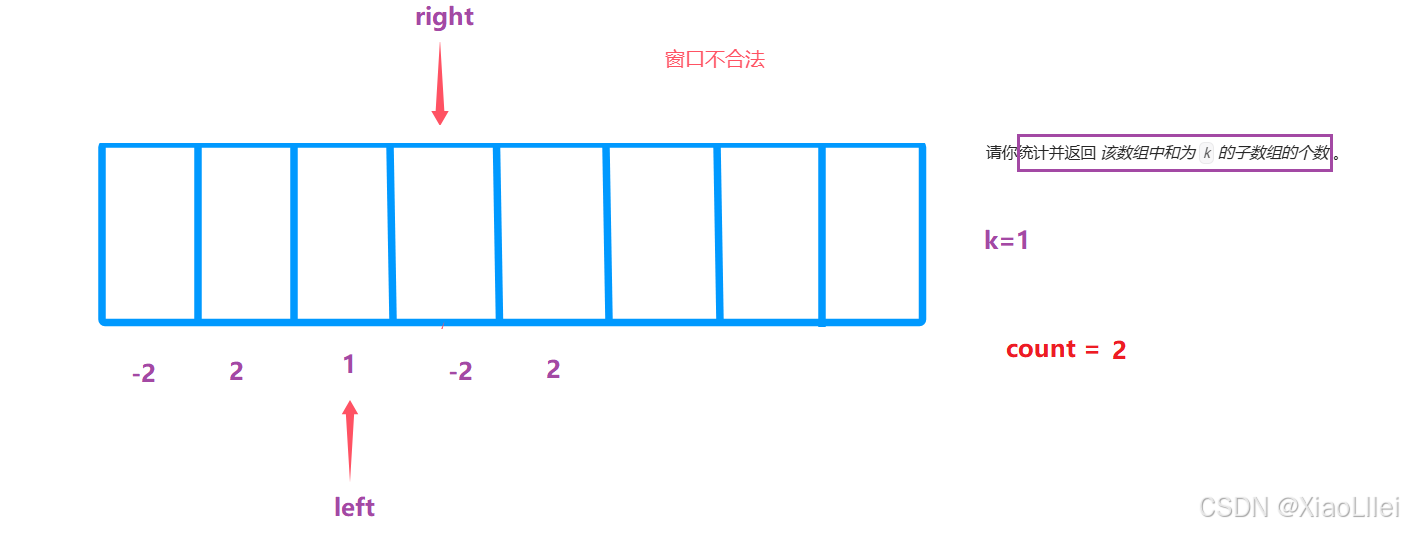
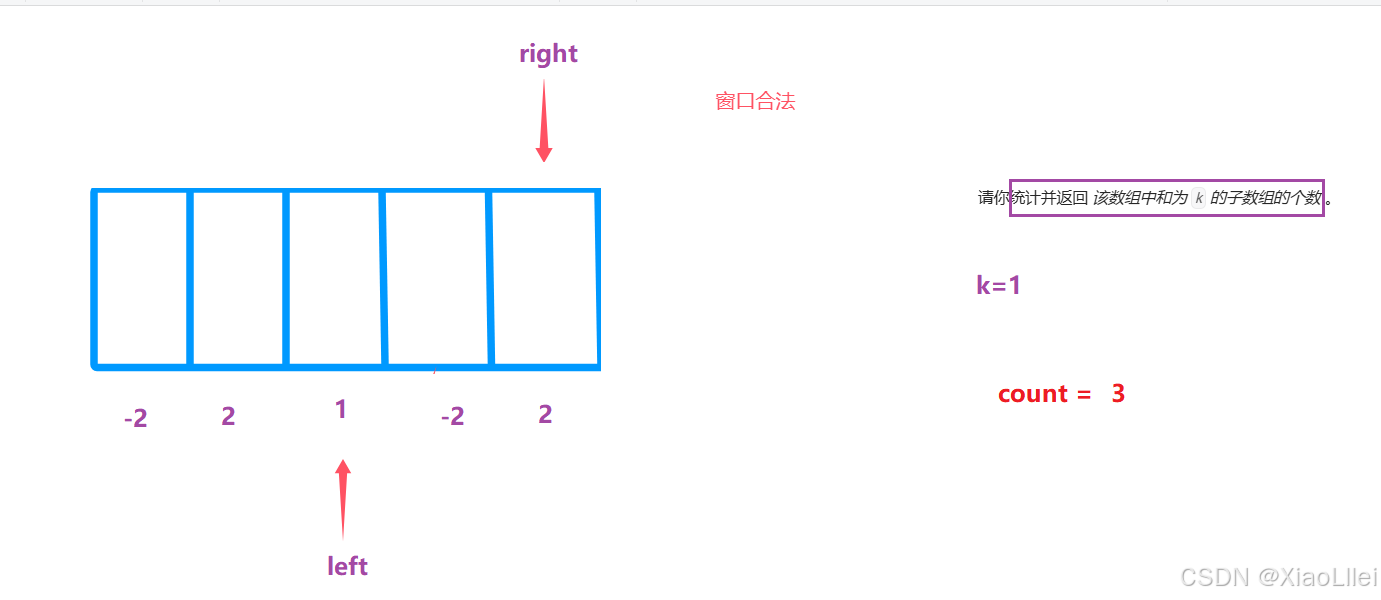
窗口刚开始不合法,移动 right:
窗口合法,移动 left,移动 left 后如果不合法,停止移动 left,改为移动 right:
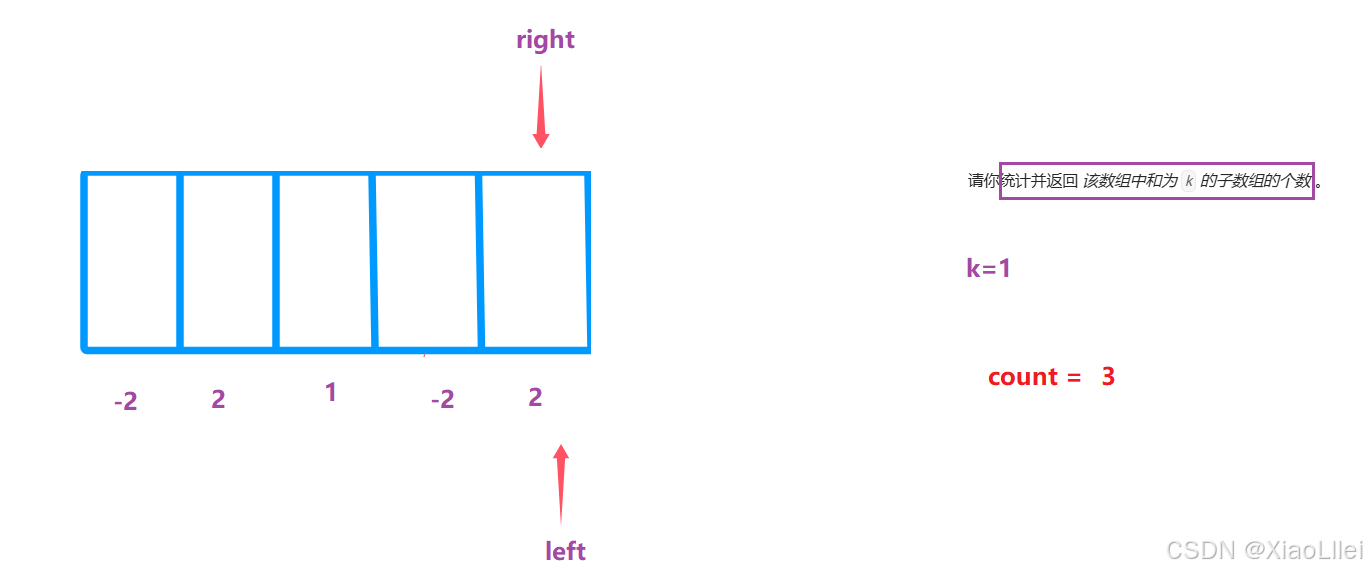
假设这个数组只有五个元素,并且 right < nums.length:
最终结果为3:
但是我们的预期情况: count=5,所以使用滑动窗口,必须保证单调性;每个元素的符号相同且不能为0,否则会遗漏一些子数组:
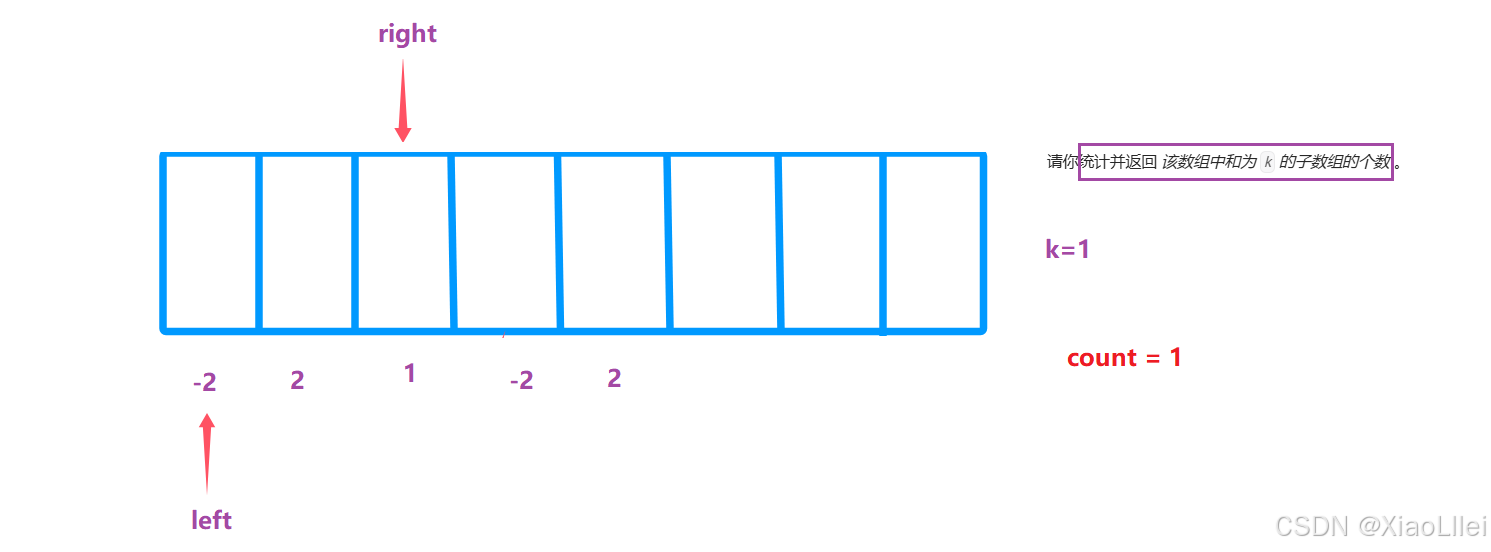
解法二 : 使用前缀和数组 + 哈希表
预处理前缀和数组
引入一个概念:以 i 位置为结尾的所有子数组;
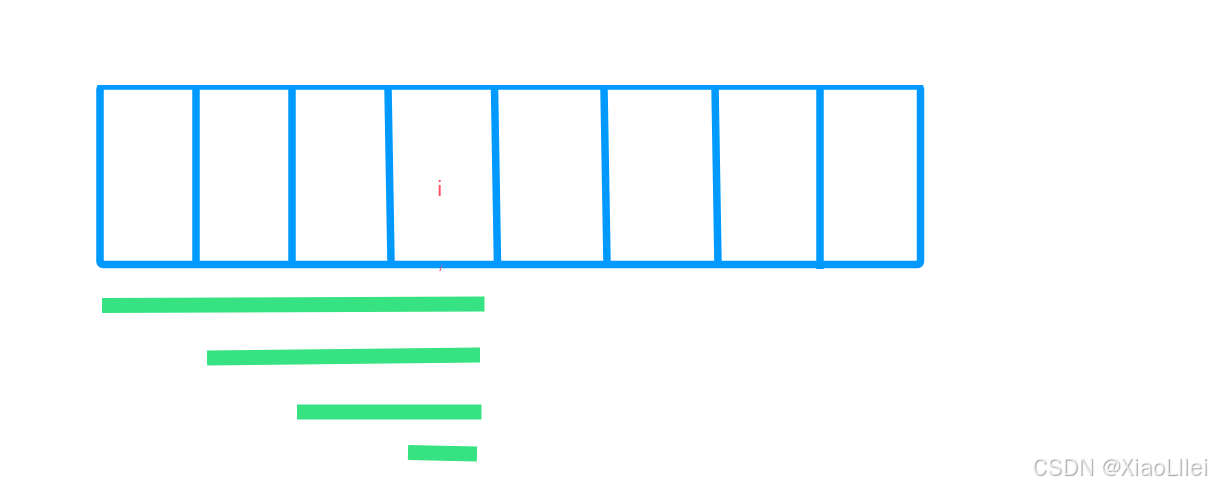
这个概念和暴力枚举相呼应,都是固定某一个位置,来枚举对应的情况 ;
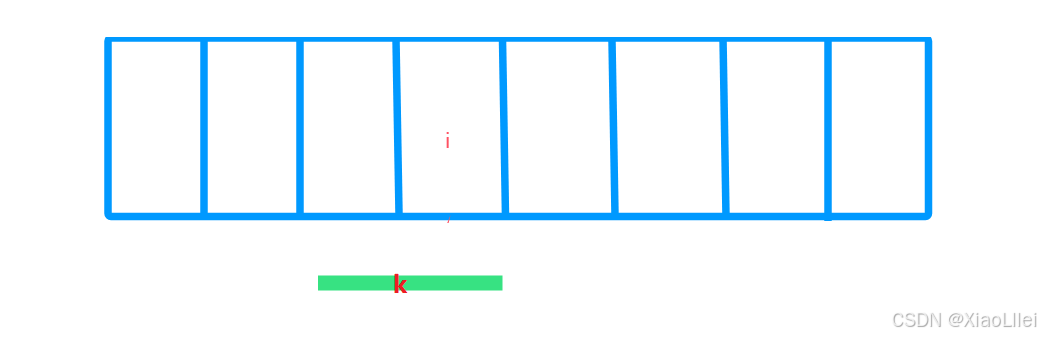
所以无论是固定一个开头,还是固定一个末尾,都是可以枚举出所有子数组的;但是,如果我们和暴力解法一样,枚举 i 之前所有子数组,并且找出和为 k 的子数组,那么时间复杂度也没有提高;
因此,我们引入前缀和:
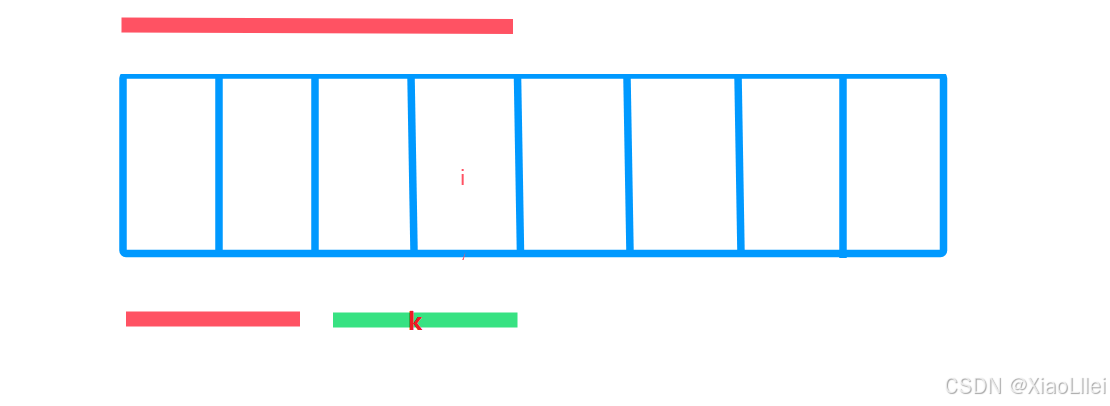
当枚举 i 位置时,其实我们已经知道以 i 位置为结尾的前缀和数组对应 i 位置的元素 sum[i] 是多少了:
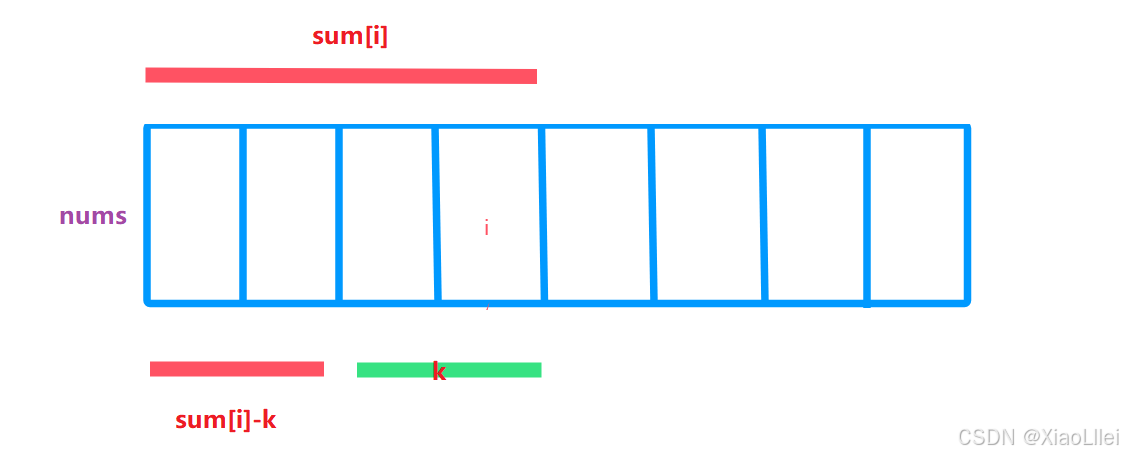
所以,我们只需要找到一段区间的前缀和,让这个区间的前缀和等于 sum[i] - k 即可;
所以问题就转化成:在 [ 0 , i-1 ] 区间内,有多少个前缀和为 sum[i] - k 的子数组;
但是,我们不能直接创建一个前缀和数组 sum ,然后直接在 sum 中找前缀和为 sum[i] - k 的子数组,这样的做复杂度不如暴力解法;
而哈希表用于快速查找某一个数,因此我们可以把前缀和塞入哈希表,然后把前缀和元素的出现个数,也放入哈希表中;
处理细节问题
1. 前缀和加入哈希表的时机
第一种时机
把前缀和数组一股脑算出来,然后放入哈希表中,然后从前往后遍历哈希表,找出 sum[i]-k 元素对应的 val;
这种做法其实是不行的,因为我们是要在 [ 0 , i - 1 ]区间内,找出值为 sum[i]-k 的前缀和元素;如果把前缀和数组一股脑算出来,再塞入哈希表,那么就会统计 i 位置之后的前缀和,此时从总体上看,就会计算重复;
第二个时机
在计算 sum[i] 之前,先别把前缀和元素塞入哈希表中,哈希表只保存 [ 0 , i - 1 ]区间的前缀和元素;在计算 sum[i] 时,才把 i 位置的前缀和元素塞入哈希表;
也就是每计算一个元素的前缀和,就塞入一次哈希表,而不是把所有前缀和数组的元素计算完毕,再一次性把这些元素塞入哈希表;
2. 不用真的创建一个前缀和数组
回忆我们前缀和数组元素的计算公式:
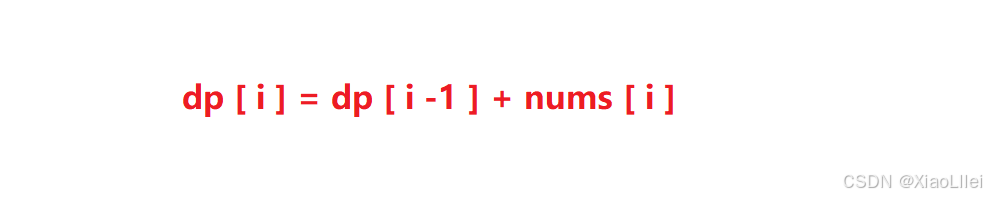
3. 如果整个前缀和等于 k 呢?
如果我们在计算 i 位置的前缀和数组,发现 i 位置的前缀和的所有子数组中,只有整个数组之和才等于 k;
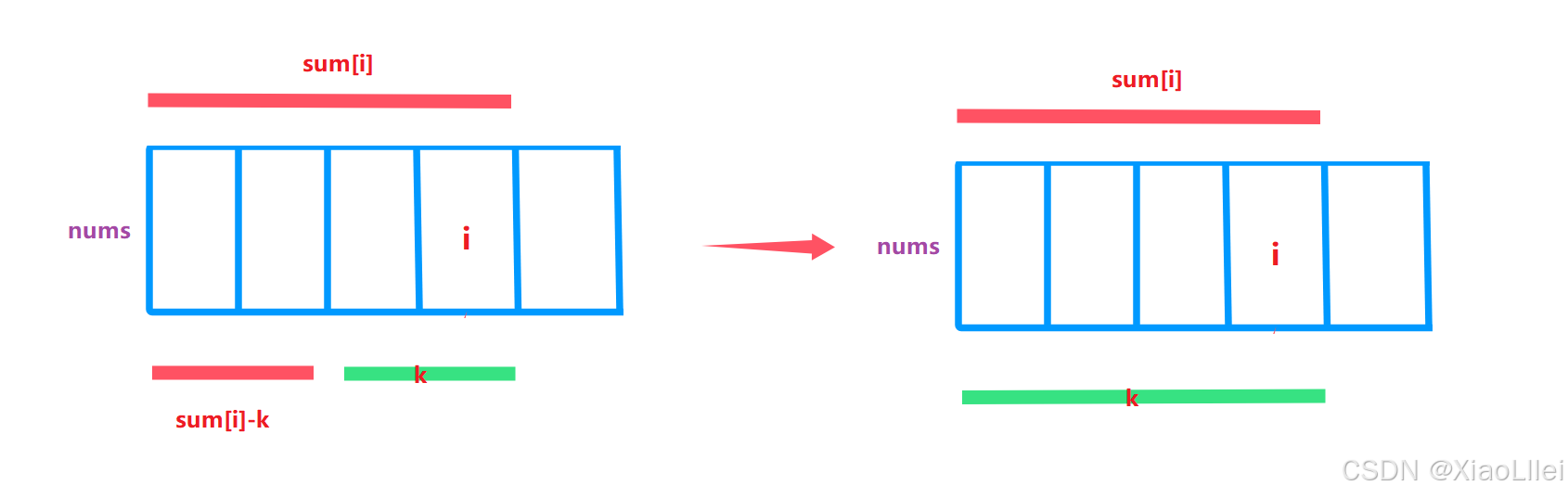
根据刚刚的类比转化,程序就会去 [ 0 , -1 ] 区间找和为 0 的前缀和数组,但是没有这个区间,我们该如何处理呢?

所以对于这种情况,我们需要在进行正式的处理哈希表之前,先初始化一个元素hash.put(0,1);
这样初始化,当在遍历 i 位置之前所有前缀和为 sum[i] - k 的元素时,如果发现有 [ 0 , i ]这个区间的前缀和数组也满足和等于sum[i] - k ,提前初始化 key = 0 的桶 val=1 ,就可以避免这种情况被忽略;
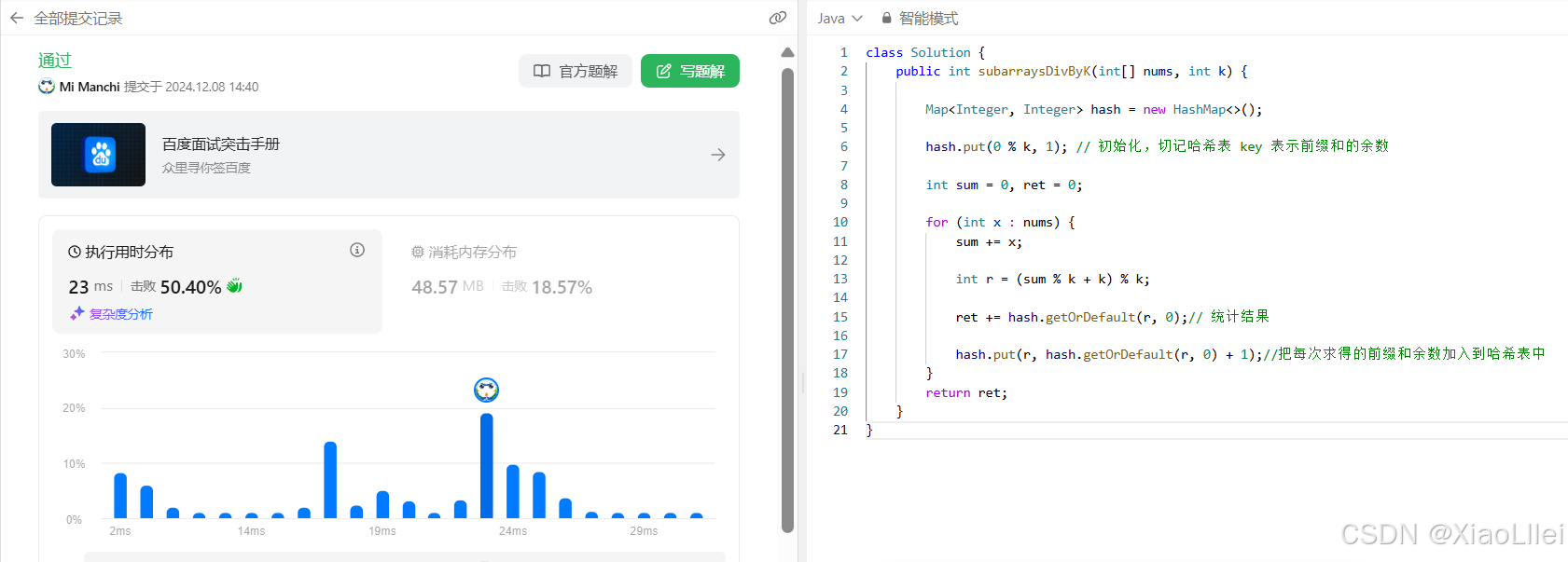
编写代码
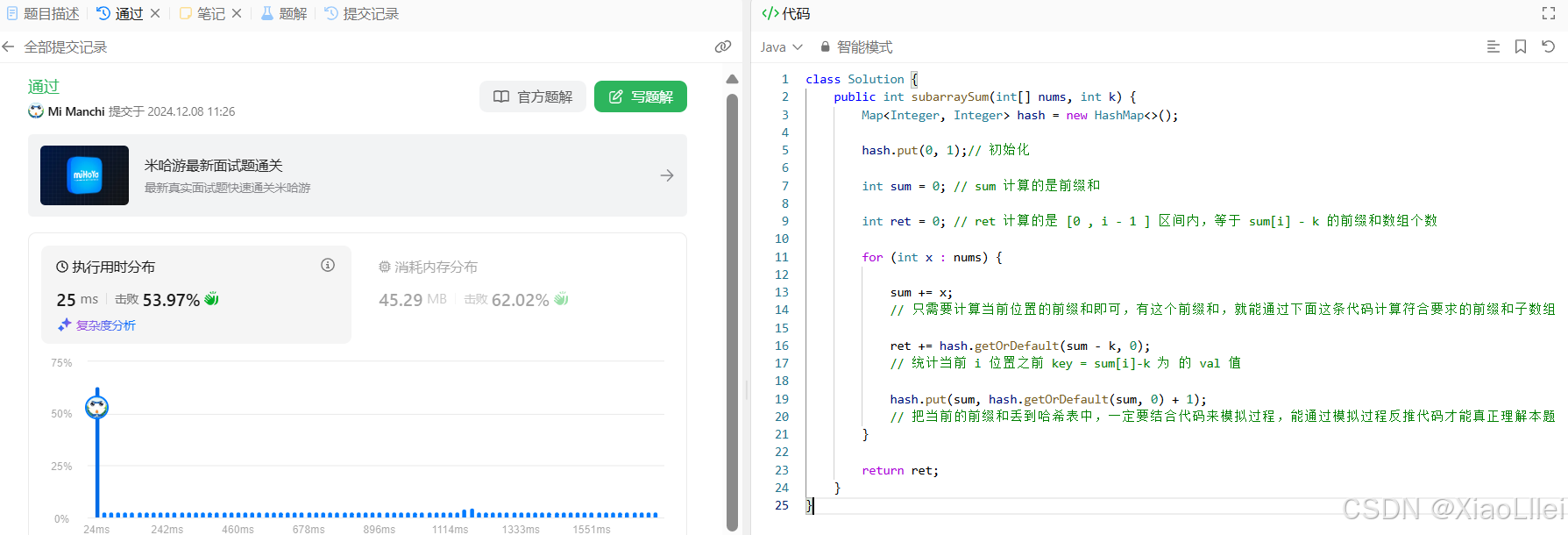
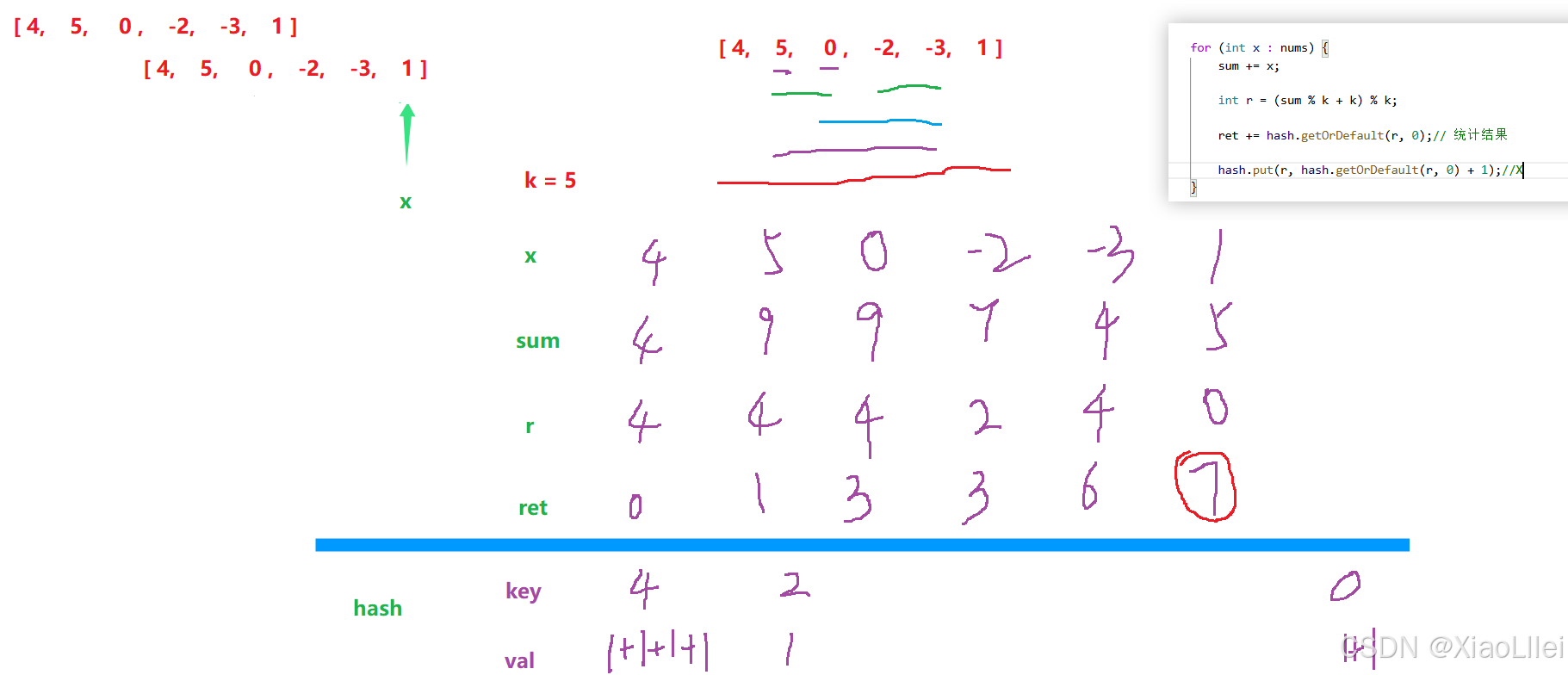
模拟一下上面代码的运行过程,会对这道题的算法原理有更深刻的理解,代码虽然简单,但是算法原理非常绕,需要结合算法原理,反复模拟代码运行过程,才能理解本题的思想:
和可被K整除的子数组
题目解析

算法原理
解法一 :暴力解法
暴力枚举出所有子数组,把所有子数组的和相加,再判断这些和中能被 k 整除的子数组;这道题的元素也就是可以<=0,不存在单调性,因此也不能使用滑动窗口解题;
补充知识
(1) 同余定理
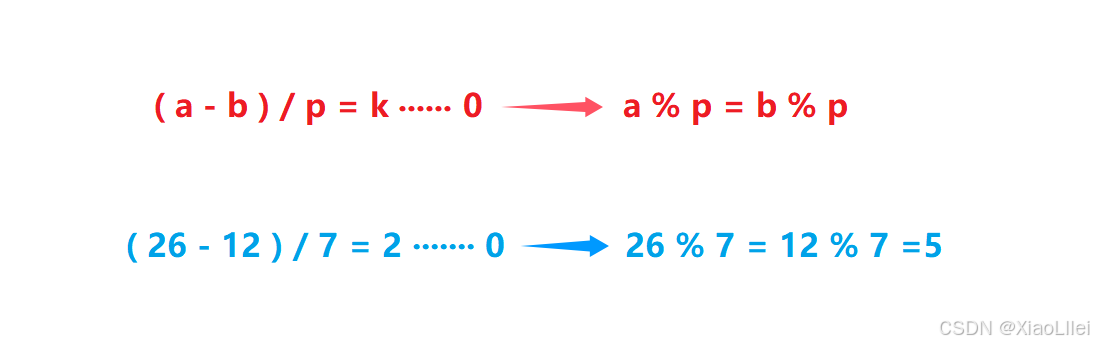
(2) java [ 负数 % 正数 ] 的结果以及修正
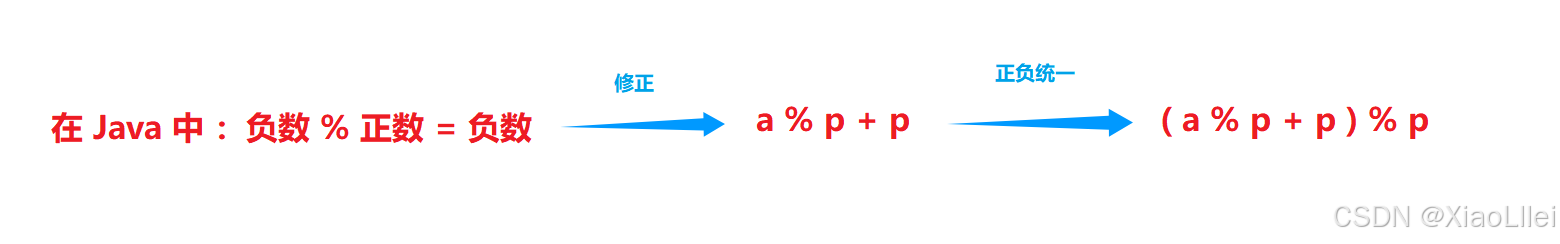
修正:
把对负数 % 出的最终负数结果修改成正数,如 a % p (a < 0 ,p > 0),得到的最终结果为负数,只需要再加一个 p 即可修正;
正负统一:
如果 a %p 时 a > 0 ,我们为了使用方便,依旧会对余数 + p,但是会造成误差,所以无论 a 是否为正数,都先修正,再把修正结果整体再 % p(注意,不是除以 p)
解法二 : 使用前缀和数组 + 哈希表
预处理前缀和数组
对于下面的绿色部分,就是我们要找的,在 [ 0 , i -1 ] 区域中的一个符合要求的子数组, 而符合要求的子数组,要满足元素之和 % k = 0:

通过对绿色部分子数组的表达式的进行进一步的转换,我们发现了下面这个条件:

而 sum % k = x % k,也可以反过来推出绿色部分元素之和 % k = 0;
所以,问题就转换成:求在 [ 0 , i -1 ] 区间内,找到有多少给前缀和 x 通过与 k 取余, x%k=sum%k,进而就能反推出绿色部分的子数组;
处理细节问题

为了保证蓝线部分两边的取模结果都为正数,需要对结果进行修正,并且正负统一;
所以问题最终转换成:在 [ 0 , i -1 ] 区间内,找到前缀和被 k 取模后(也就是前缀和除以k后,得到的余数结果),余数结果等于 (sum % k + k) %k 的所有子数组;
我们不需要真的去创建前缀和数组,而是定义一个变量,这个变量也不是用来存前缀和,而是存前缀和除以 k 后,得到的余数,并且在哈希表中的 key 也表示这个余数;
并且,把余数加入到哈希表中的时机,也是在遍历一个元素,就插入一次;
总结

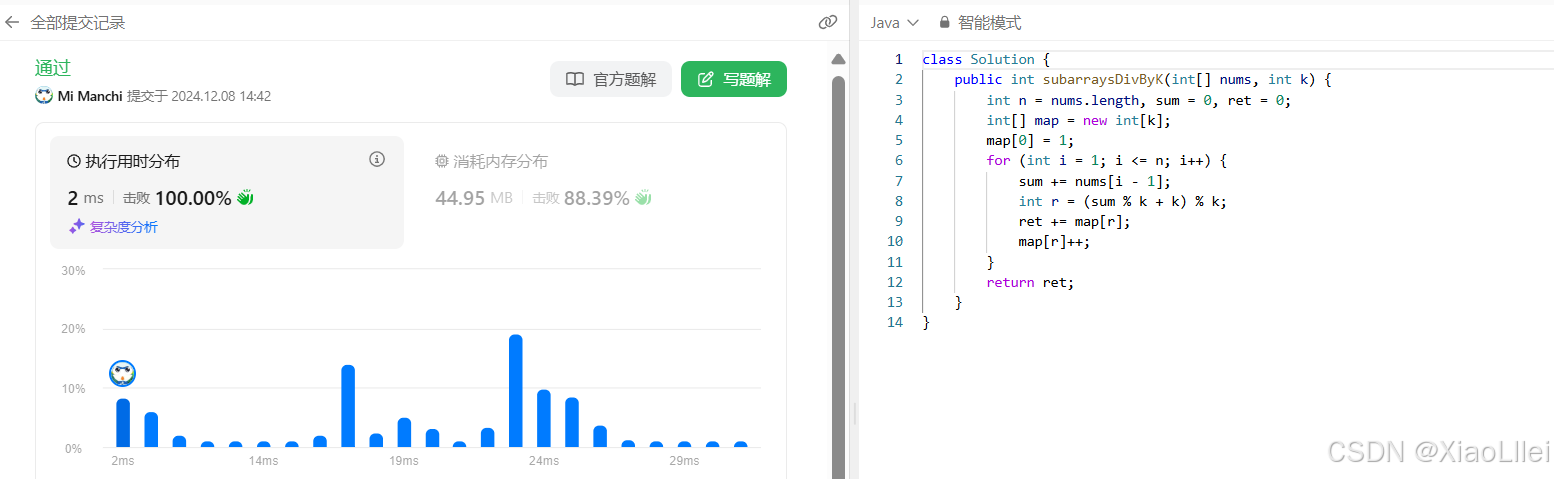
编写代码
用数组模拟哈希表
模拟代码实现过程:
连续数组
题目解析

算法原理
如果要统计 0 和 1 的个数,来求出相同数量的最长连续子数组,那么这道题还是有一定难度的;
解法 : 使用前缀和数组 + 子数组
处理细节问题
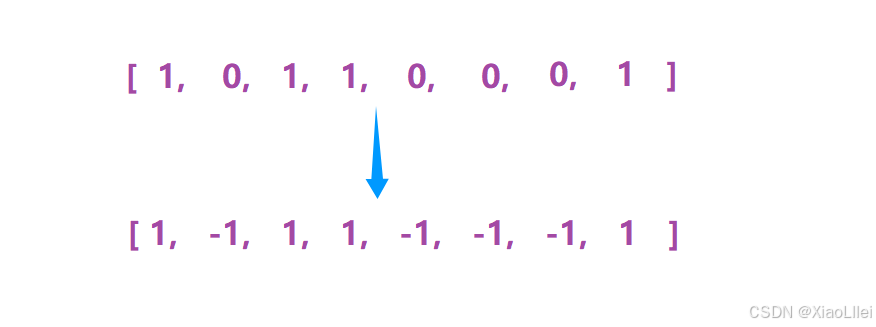
1. 哈希表中存什么?

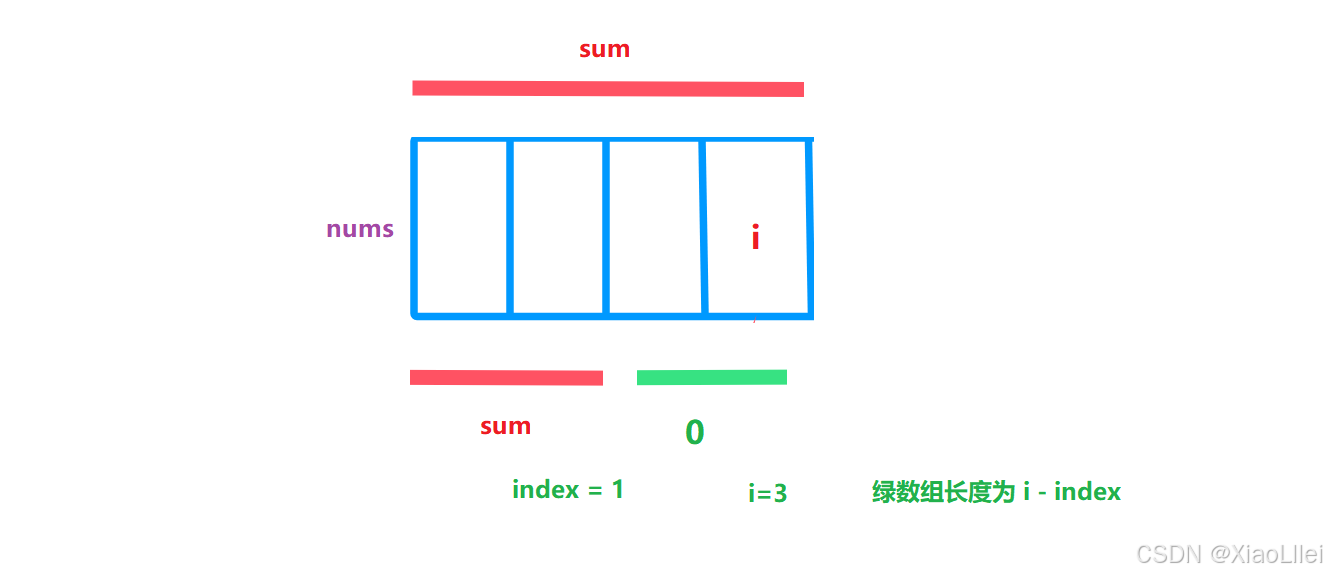
对于哈希表的 key 和 val 存的是什么,我们可以查看上图,如果要算绿色区域的数组,我们就要知道两段红色区域的数组之和,如果两端红数组之和相等,绿数组即为我们所求;
因此,我们需要下面的红数组的下标;
2. 什么时候存入哈希表?
当前 i 位置所绑定的前缀和要存入哈希表中,而当遍历完[0 , i -1 ] 区域所有符合要求的子数组,并且返回最长的子数组时,我们再把当前 i 位置所绑定的前缀和存入哈希表;
3. 如果有重复的 <sum , i > ,如何存 ?
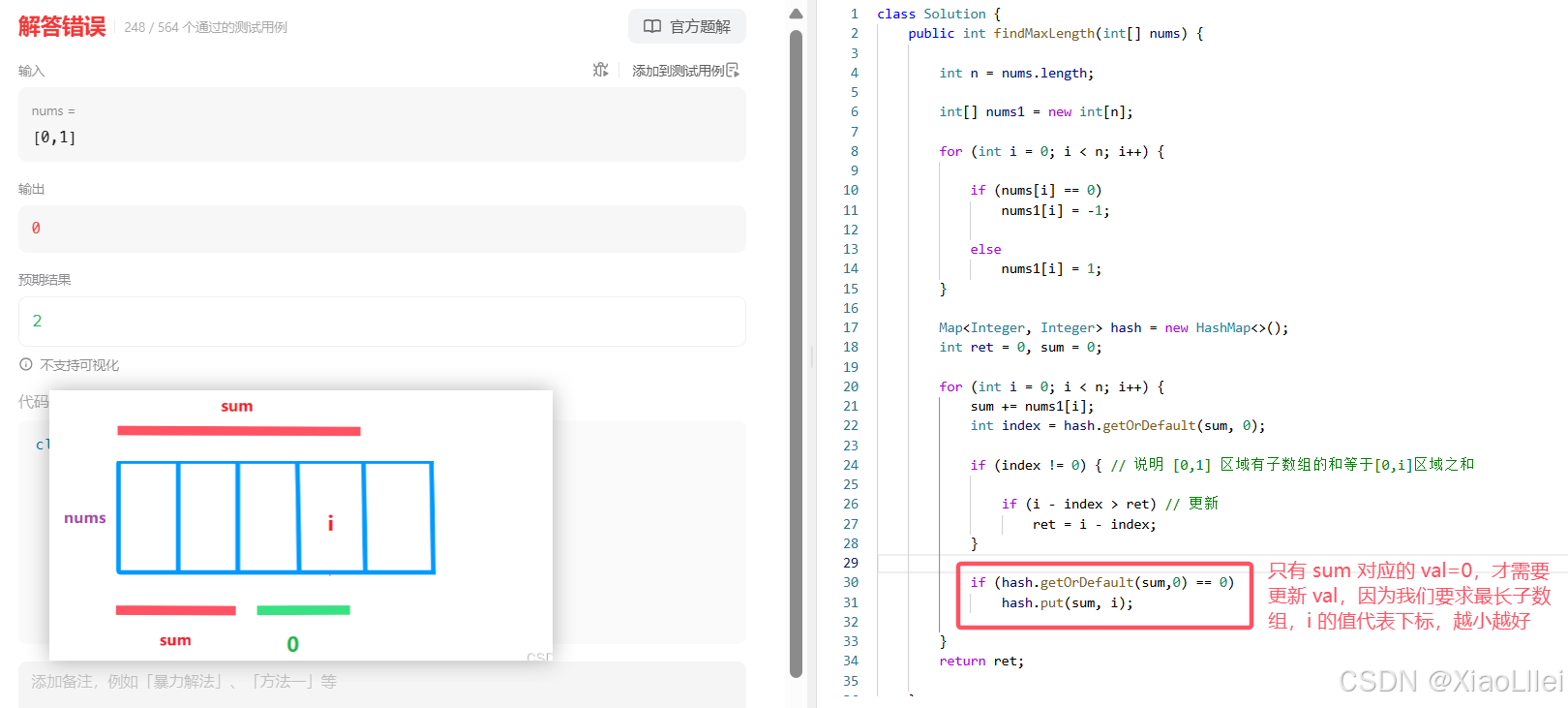
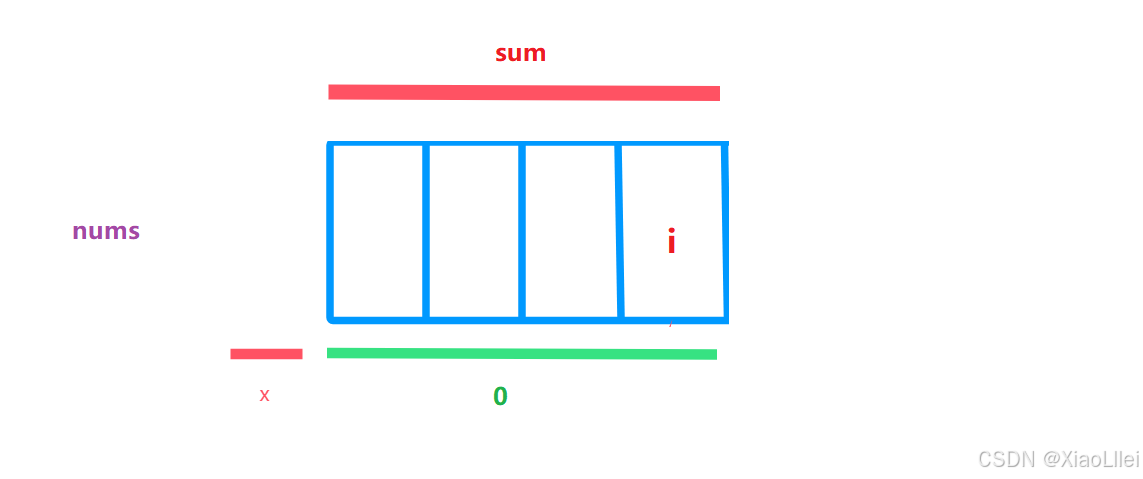
4. 默认的前缀和为 0 该如何存?
当我们发现整个数组的前缀和 sum=0,就需要在 [ 0 , -1 ] 区域初始化,但是没有这个区间,上面的报错,就是因为没有处理好初始化问题;
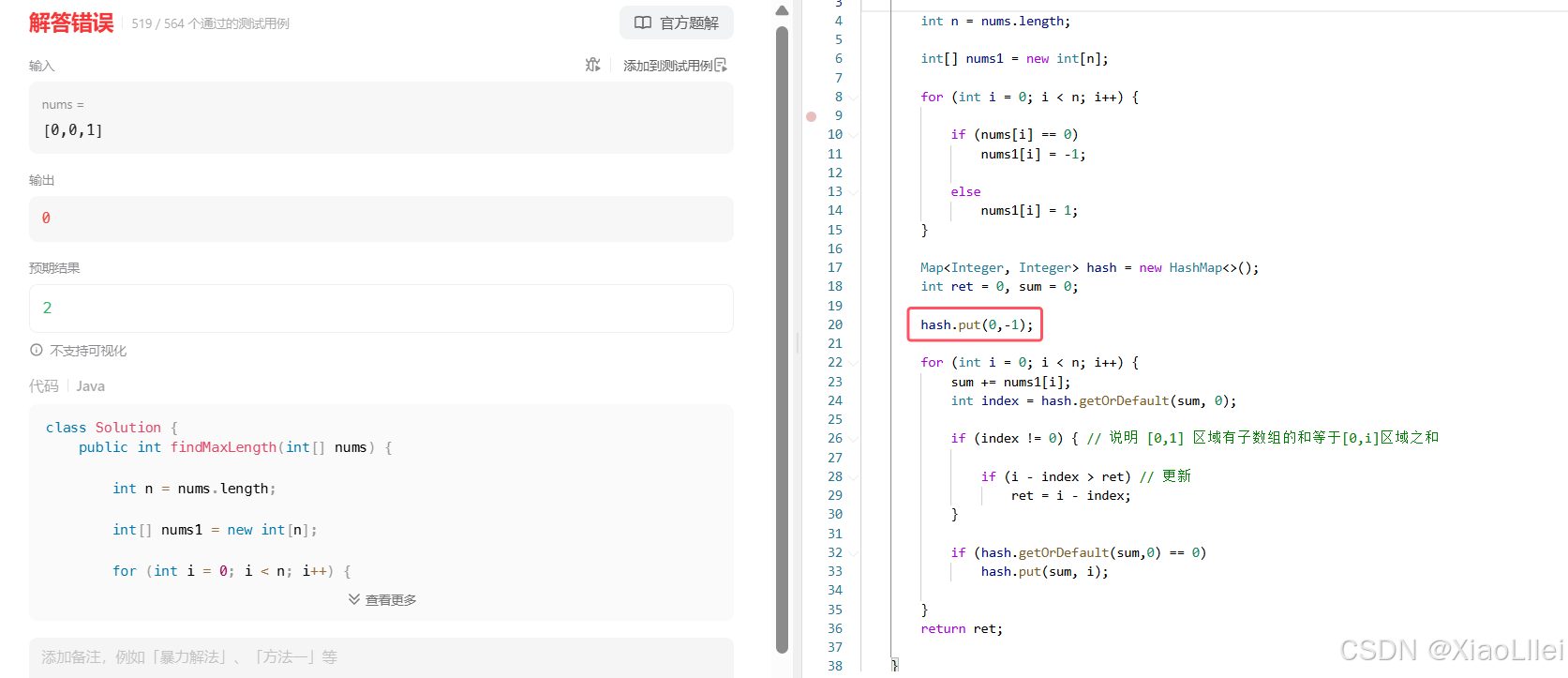
前面的题都是存 sum,以及sum 出现次数,但是这个题每个桶的类型是 < sum , index >,所以这道题 hash.put(0, -1);
5. 长度怎么算?
因为 sum 重复不会更新 index 对应的 val,
编写代码
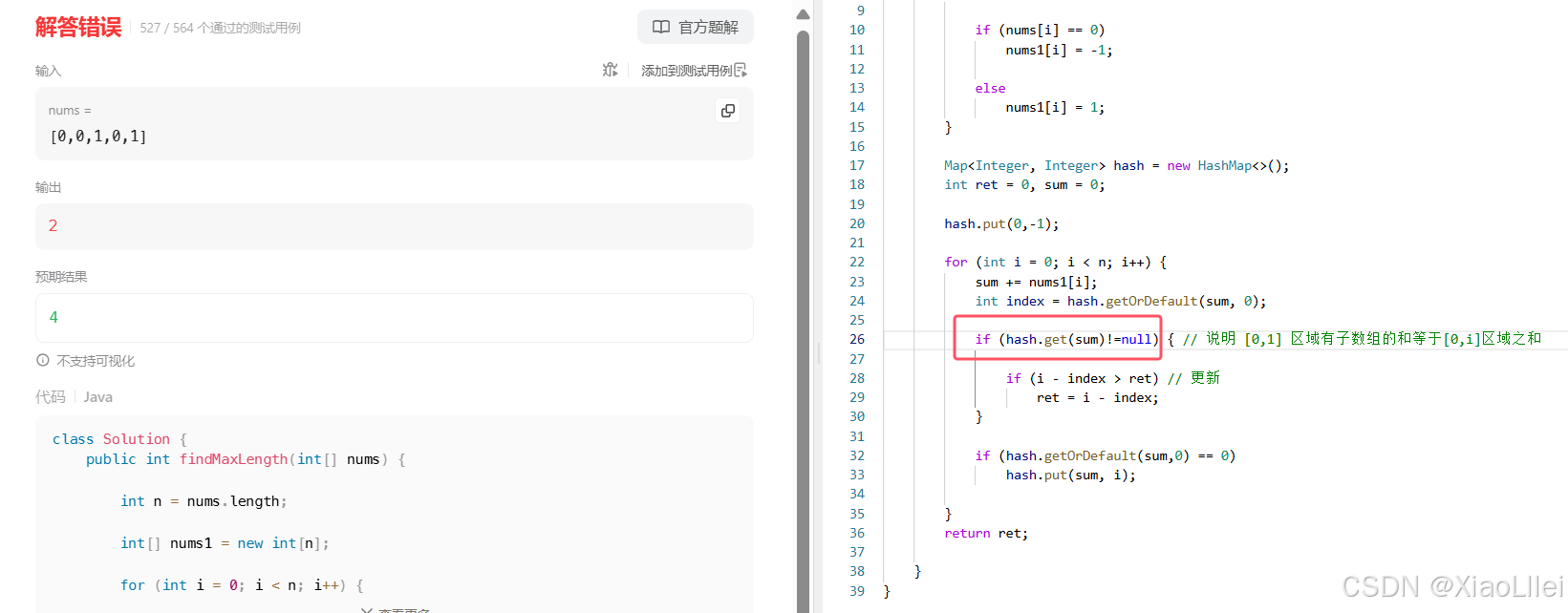
无论是使用三目运算符代替创建 -1 ,1数组,还是对于是否更新 ret ,以及更新的 ret 操作,都更简洁;
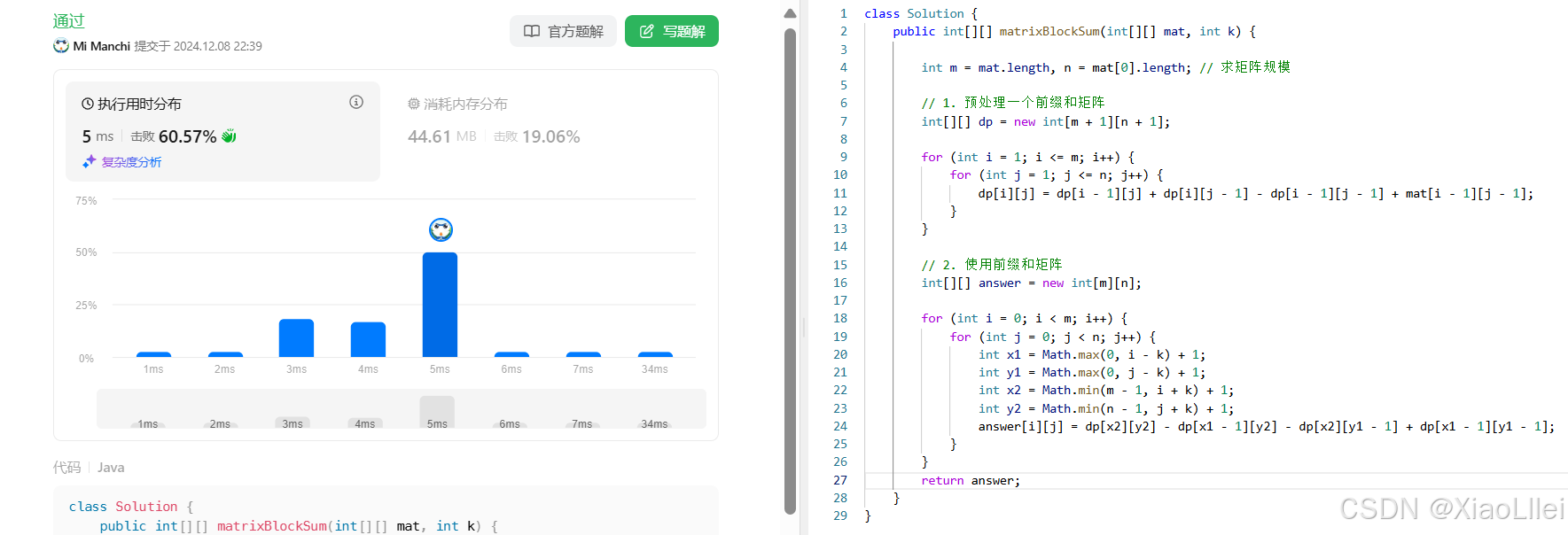
矩阵区域和
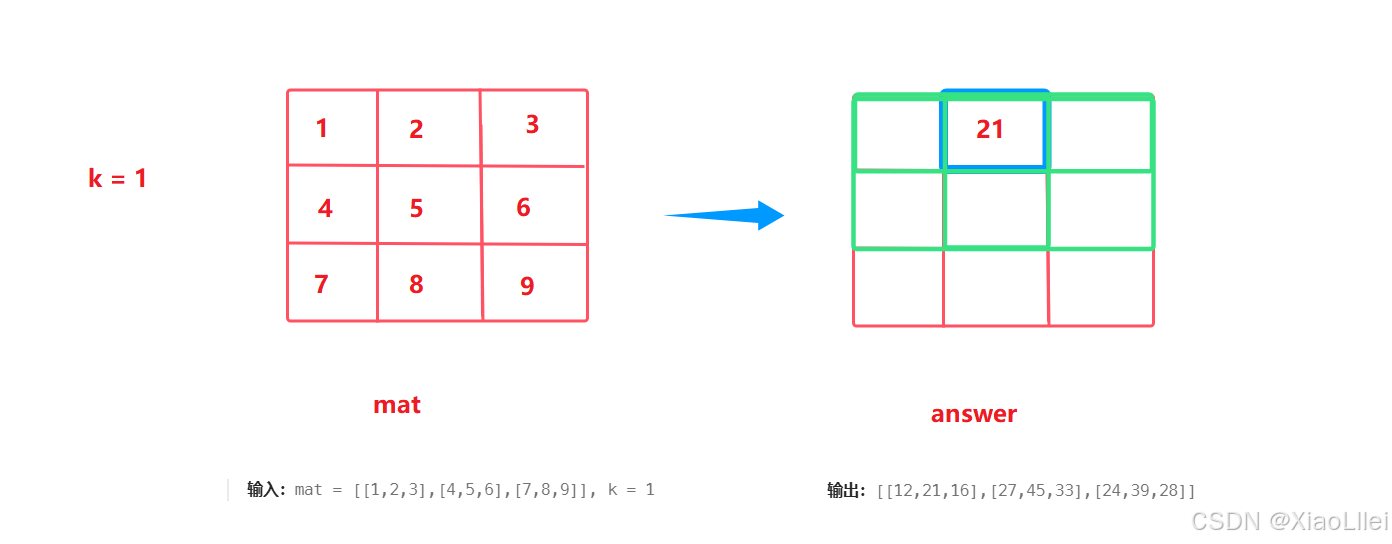
题目解析

我们演示示例一求answer矩阵的一个元素 answer[0][0]:
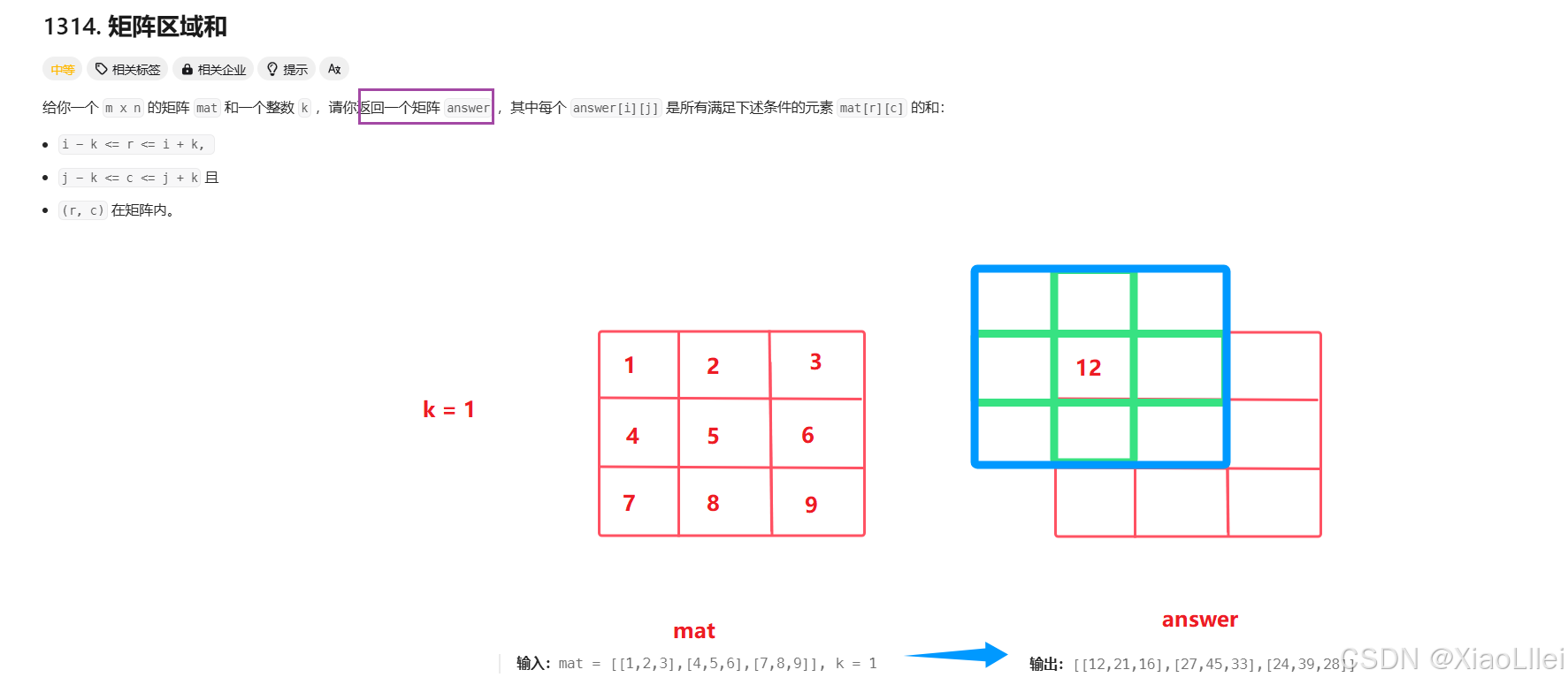
并且,如果扩展的矩阵超出原始边界,超出的元素格子都不考虑:
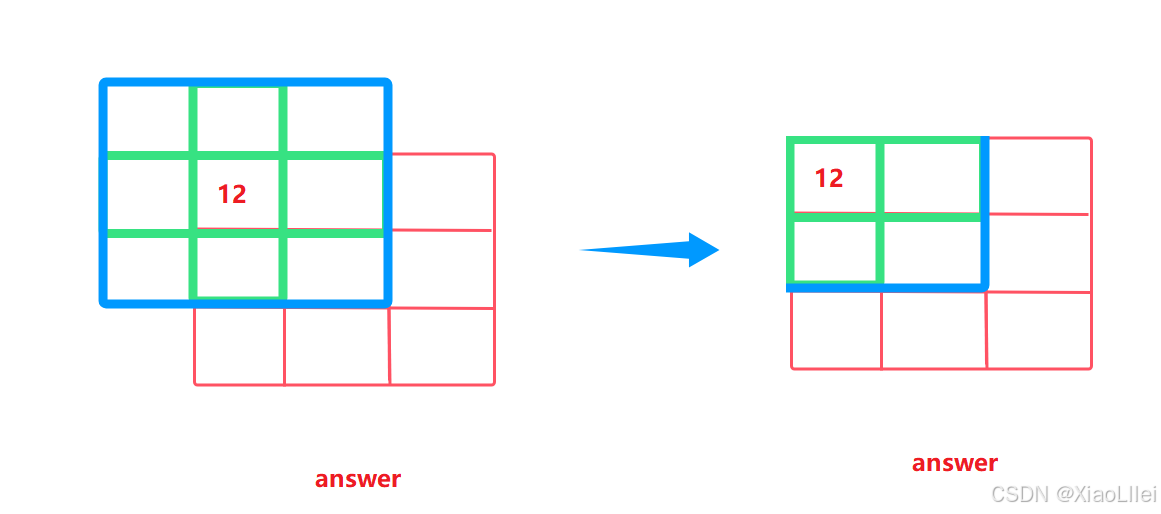
如果要求 answer[1][0],求法同理,扩展宽度根据 k 的值来决定:
算法原理
解法 : 使用二维前缀和
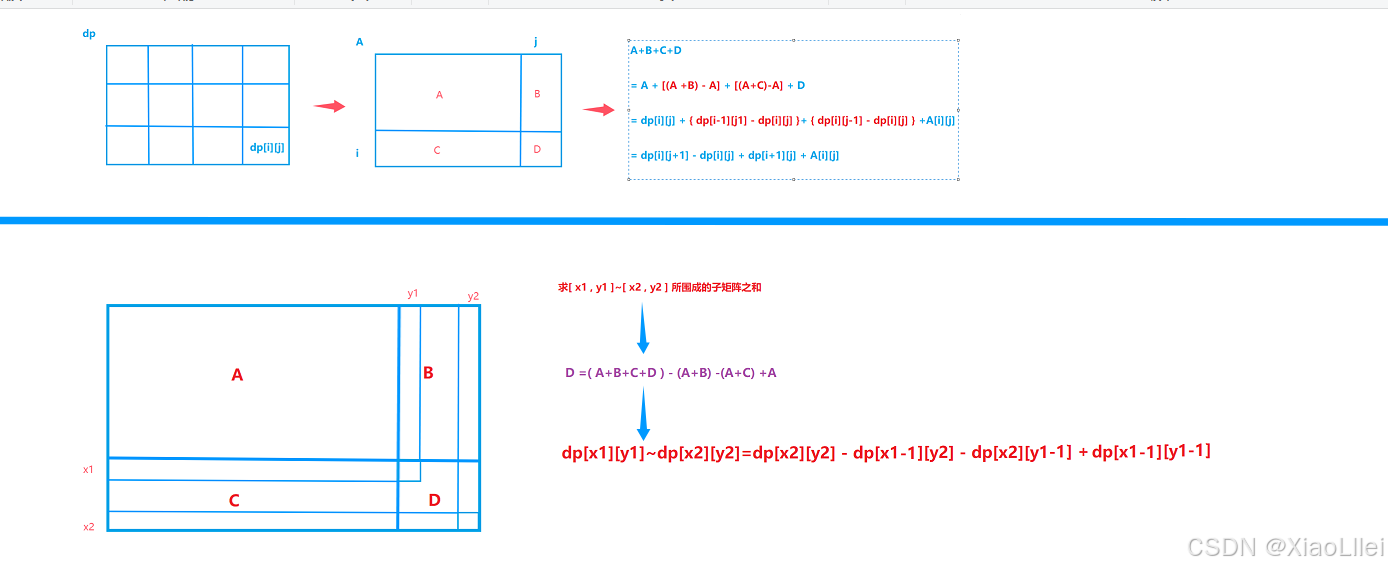
预处理前缀和数组
递推公式
回顾快速求出二维前缀和递推公式:
处理细节问题
(1) 处理边界情况
求 answer[i][j],我们需要知道它在 mat 矩阵表示的区域 ,并且通过坐标表达出 answer[i][j] 向外扩展 k 个区域得到的矩阵,在 mat 矩阵所对应的区域:
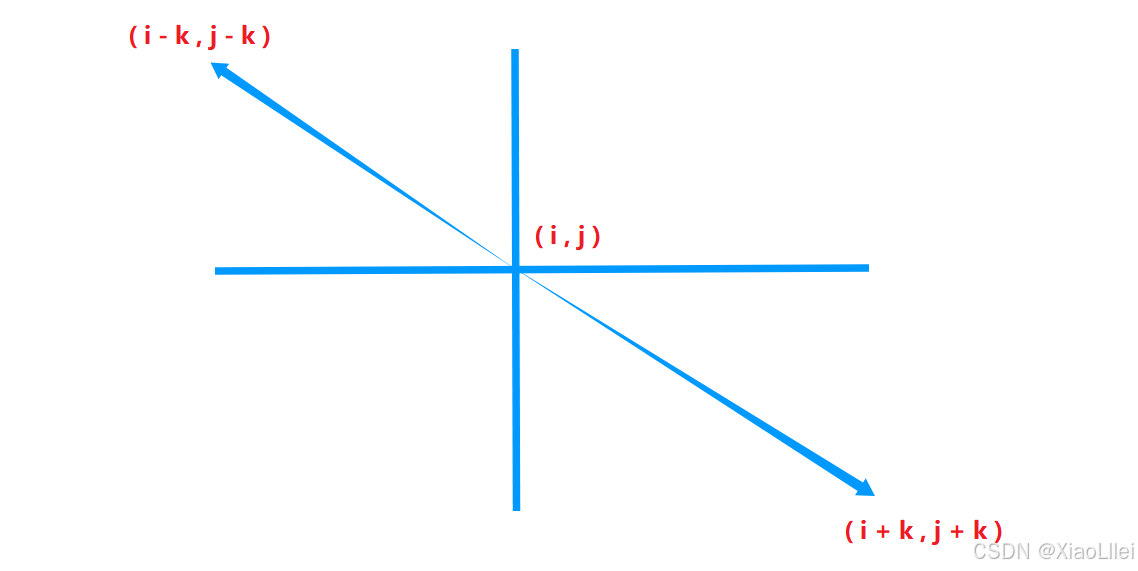
但是我们还需要处理可能出现的越界问题,设向上扩展的边界坐标 ( x1, y1 ),向下扩展的边界坐标为 (x2,y2):
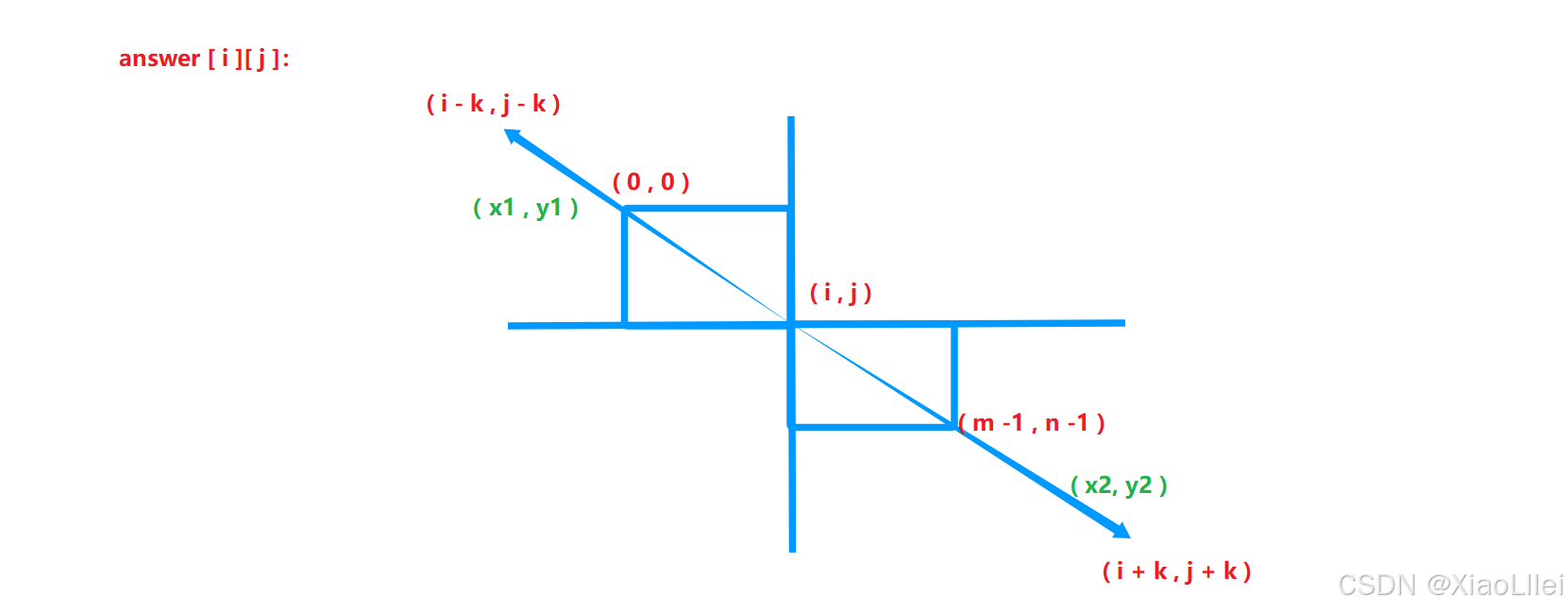
如果 answer[i][j] 在向外扩展的时候,越过了 mat 矩阵的原始边界,是需要收缩扩展范围至原始边界的,所以我们求扩展边界可以这样求:
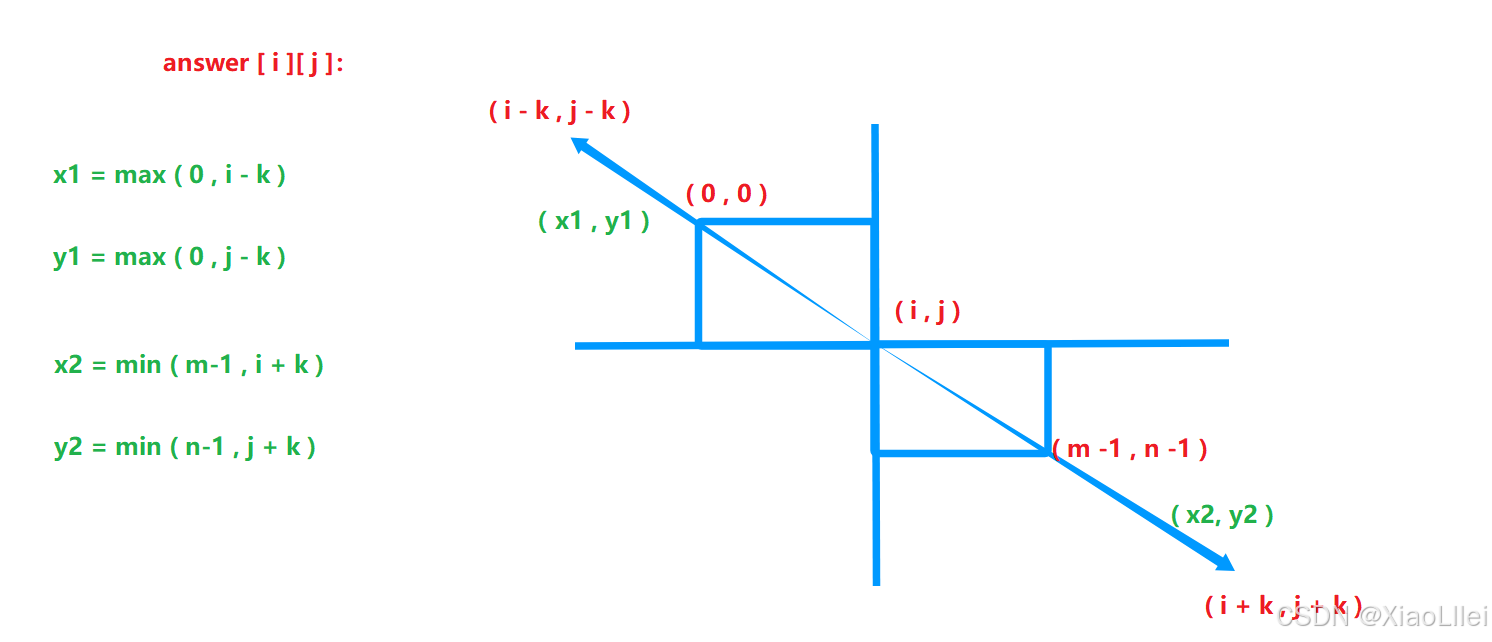
(2) 下标的映射关系
在学二维前缀和模板的时候,为了在预处理二维前缀和数组 dp 时,避免处理一些边界情况,方便初始化,我们是建立的矩阵是从 dp[1][1]~dp[m][n]计数的,但是这道题是 dp[0][0]~dp[m-1][n-1]计数的;
为了方便我们初始化,避免过度地把精力花在初始化问题和处理边界情况上,我们必须对 dp 数组多加一行,多加一列:
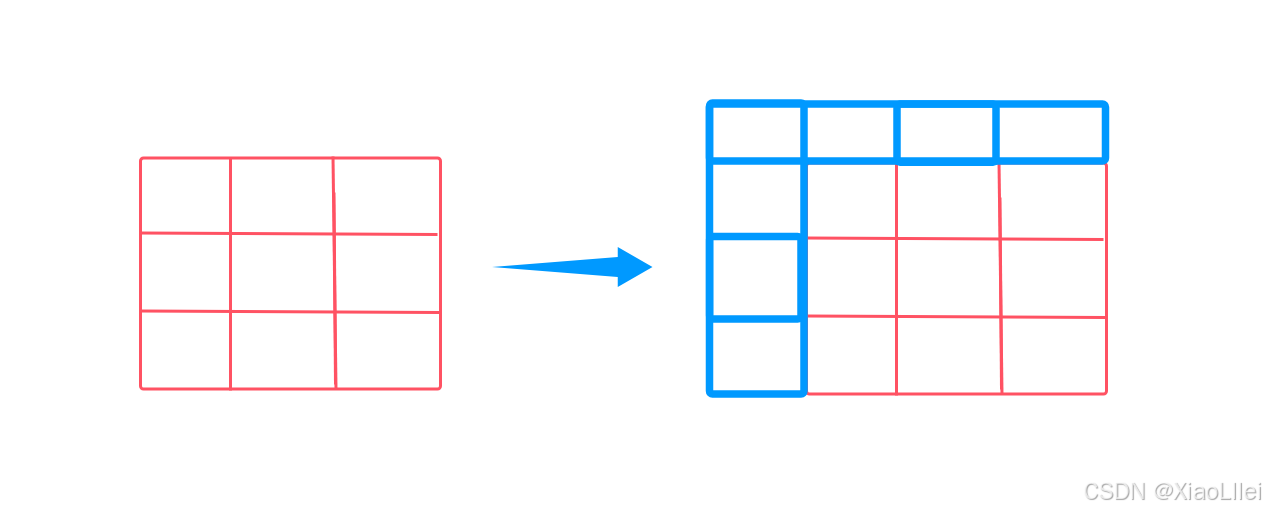
多加一行一列之和,我们是先根据 mat 来填 dp 表,再通过 dp 表填 answer,所以,在给 dp 表加上一行一列后,就会出现 mat 和 dp 的下标映射关系问题:
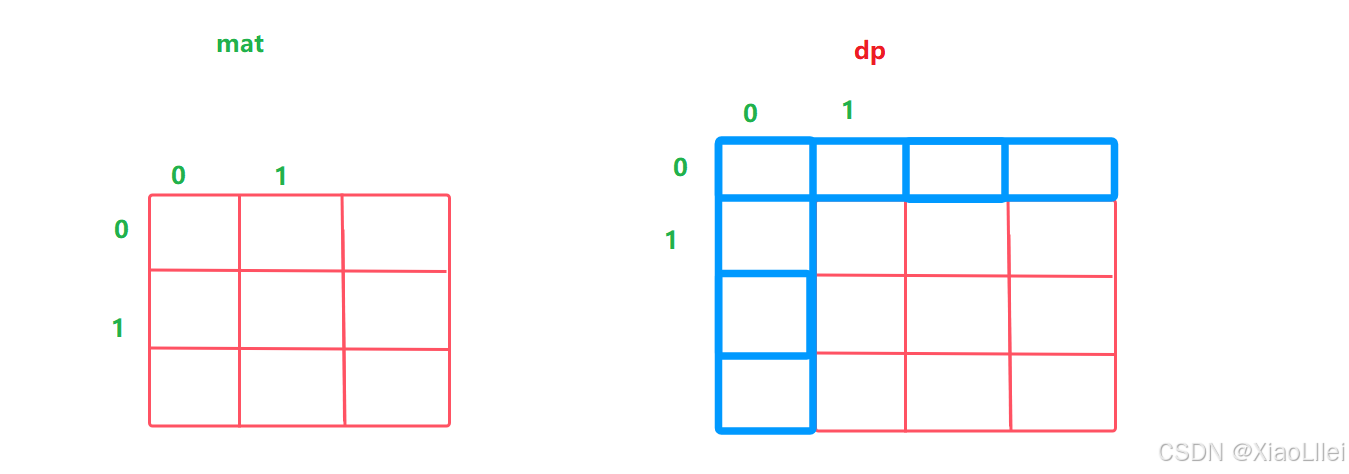
我们在求 dp[i][j] 时,在调整后,就变成找 mat[i-1][j-1] 对应的矩阵和,因此,我们的递推公式也会发送改变:

在通过 mat 填写好 dp 表之后,我们需要通过 dp 表来填写 answer ,所以 dp 与 answer 的下标映射关系为 dp [i][j] 对应 answer[i-1][j-1]
使用前缀和数组

编写代码