


Retrieve 检索
示例
1. 构造数据
创建表结构
create table exam1(
id bigint,
name varchar(20) comment'同学姓名',
Chinesedecimal(3,1) comment '语文成绩',
Math decimal(3,1) comment '数学成绩',
English decimal(3,1) comment '英语成绩'
);插入测试数据
insert into exam1(id,name,Chinese,math,English) values
(1,'唐三藏',67,98,56),
(2,'孙悟空',87,78,77),
(3,'猪悟能',88,98,90),
(4,'曹孟德',82,84,67),
(5,'刘玄德',55,85,45),
(6,'孙权' ,70,73,78),
(7,'宋公明',75,65,30);2. Select
2.1 全列查询

select*from exam1;
+------+-----------+---------+------+---------+
| id | name | Chinese | Math | English |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+select *是一个很危险的操作:
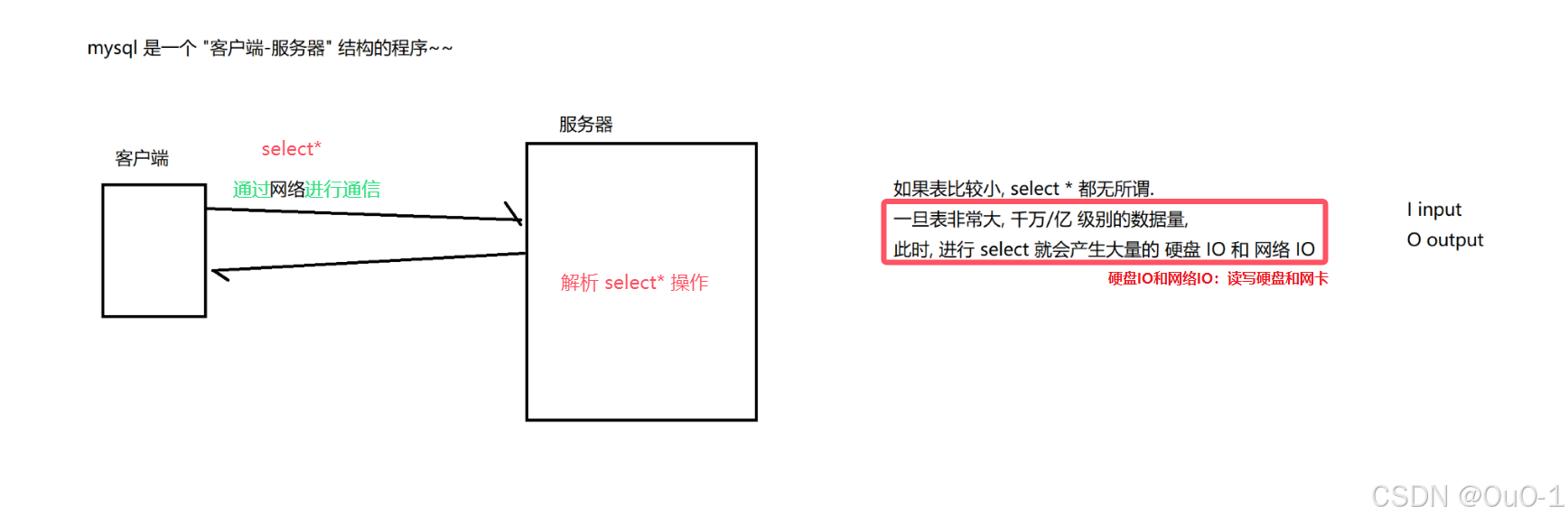
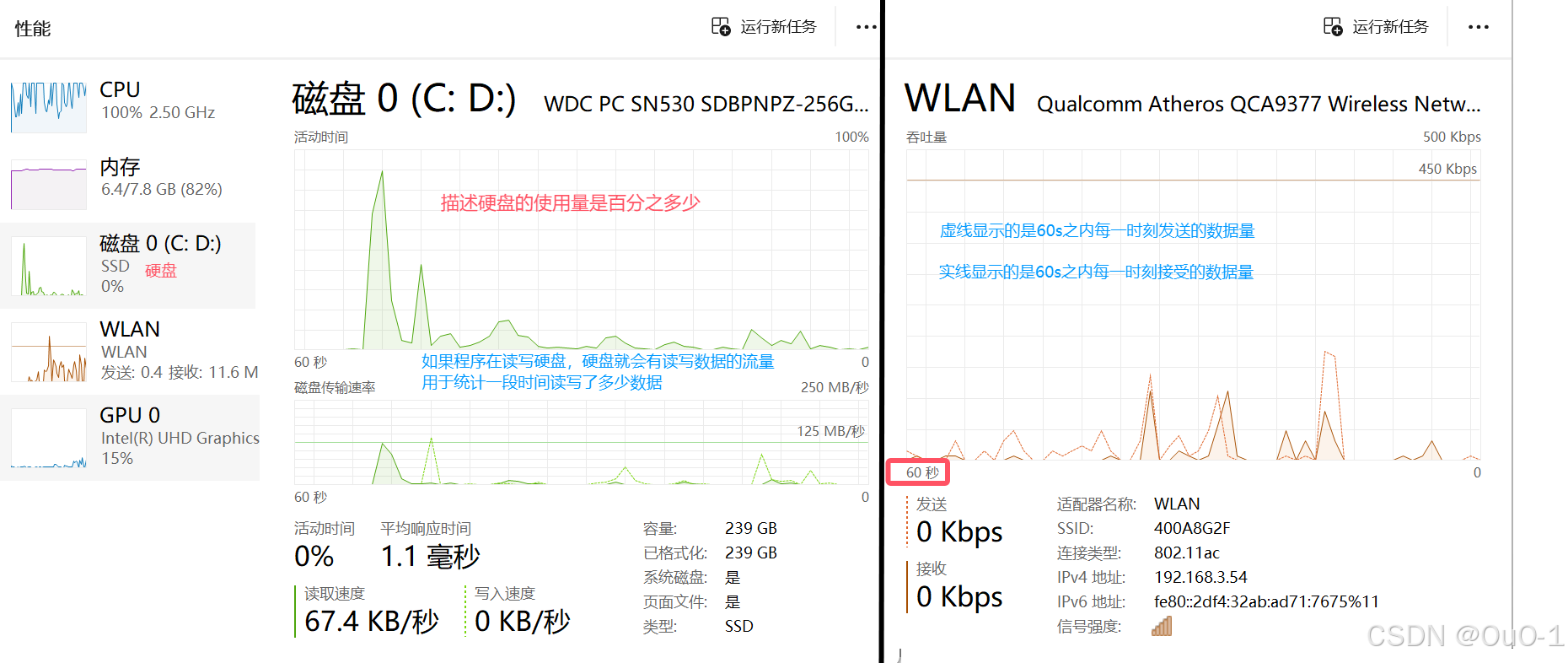
- 只要涉及到硬盘操作和网络操作,就会消耗一定的硬盘带宽和网络带宽;
- 意味着硬盘和网卡的读写速度都是存在上限的,一旦触发大规模的 select * 意味着很可能就把 硬盘/网卡带宽给吃满了(堵车);
- 其他的客户端尝试访问数据库,访问操作就无法正常进行了;
- 如果针对公司的生产环境进行select*,就很可能使其他的用户访问数据库的时候,出现访问失败的情况;
- 当前阶段,数据库中,没啥数据,select*就无所谓了;以后再工作中,尤其是"生产环境",一定要慎重!!

2.2 指定列查询
语法
select 列名, 列名...... from 表名;
select id , name , Chinese from exam1; # 查询指定列
select English, math, Chinese, name, id from exam1; # 按照指定的顺序查询mysql 是一个客户端-服务器结构的程序,如果使用 select* 会消耗大量的硬盘带宽和网络带宽,这些带宽往往是比较稀缺的资源;因此,使用指定列查询,得到的数据量就比全列查询要少很多,查询要查询的列即可,没有必要一次性查询所有列;

2.3 查询字段为表达式
把所有学生的语文成绩加10分
select name, Chinese + 10 from exam1;执行 select 就会遍历每一行,取出需要的列,把列代入到表达式中;
这样的结果,只是数据库查询过程中生成的临时表,数据库本体(数据库服务器硬盘上的数据)是没有任何改变的。
desc exam1;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | bigint | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| Chinese | decimal(3,1) | YES | | NULL | |
| Math | decimal(3,1) | YES | | NULL | |
| English | decimal(3,1) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
5 rows in set (0.01 sec)根据上述表结构我们可以发现, 如果Chinese +20,就意味着有些成绩的结果就会超出decimal(3,1) 类型约定的范围.
我们尝试一下查询 Chinese +20 操作,看看数据库查询超出类型范围会如何处理:
select name, Chinese + 20 from exam1;
+-----------+------------+
| name | Chinese+20 |
+-----------+------------+
| 唐三藏 | 87.0 |
| 孙悟空 | 107.0 |
| 猪悟能 | 108.0 |
| 曹孟德 | 102.0 |
| 刘玄德 | 75.0 |
| 孙权 | 90.0 |
| 宋公明 | 95.0 |
+-----------+------------+
7 rows in set (0.00 sec)可以看到,虽然这个结果已经超出了 decimal(3,1) 的范围,但是依旧是可以查询,并且查询结果是正确的;所以我们需要明确:
- decimal(3,1) 这样的表的类型,是针对硬盘上存储的数据进行制约的;
- 但是我们当前的查询操作,得到的表中的计算结果,是临时的表数据,不会影响硬盘上的数据;,就可以不受 decimal(3,1) 这样的类型的约束;
- 换句话说,临时表的数据会尽可能保证查询结果是完整正确的,优先级高于类型约束;
在一个表达式中,还可以引入多个列参与运算
-- 总成绩查询
select name , Chinese + math + English from exam1;注意:表达式查询只能针对列和列之间进行运算,行和行之间的运算,后面会介绍聚合查询 ;
2.4 为查询结果指定别名
为总分这一列指定别名
如果表达式简单,一眼就能看明白;但是如果表达式比较复杂,就没法直观观察了;此处就可以给表达式取别名(别名只是针对临时表的列名产生修改),此时别名就是查询结果的列名:
select 表达式 as 别名from 表名;select name , Chinese + math + English as total from exam1;
select name , Chinese + math + English total from exam1;2.5 结果去重查询
语法
select distinct 列名 from 表名;去重的意思,多个行的数据,如果出现相同的值,就会只保留一份
查询当前的数学成绩,并去除重复记录
-- 去重查询
mysql> select distinct math from exam1;

3 Where 条件查询
语法
select 列名 from 表名 where 条件;查询过程中,指定筛选条件,满足条件的记录就保留,不满足条件的就跳过.....
比较运算符
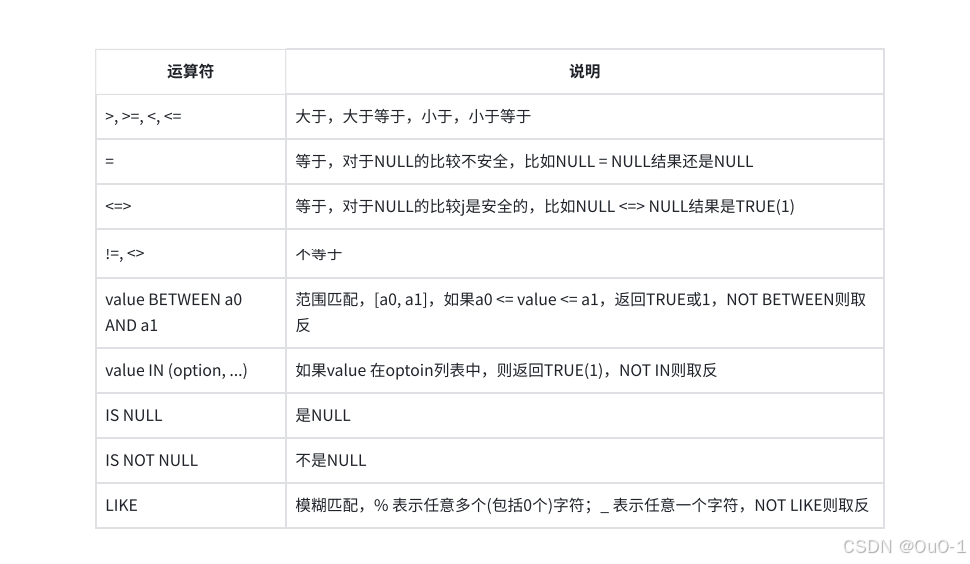
null 参与运算或者比较,得到的结果也是 null
mysql> insert into exam1 values(null, null , null, null, 90.0);
Query OK, 1 row affected (0.03 sec)
select* from exam1;
+------+-----------+---------+------+---------+
| id | name | Chinese | Math | English |
+------+-----------+---------+------+---------+
| NULL | NULL | NULL | NULL | 90.0 |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
select name, Chinese + math + English as total from exam1;
+-----------+-------+
| name | total |
+-----------+-------+
| NULL | NULL |
+-----------+-------+
8 rows in set (0.01 sec)
- null = null => null,此时的表达式的值是 null 的时候,条件就会判定为"不成立",也就相当于 false
- <=> 也是比较相等,能够针对 NULL 和 NULL 进行比较的.,NULL <=> NULL=> true

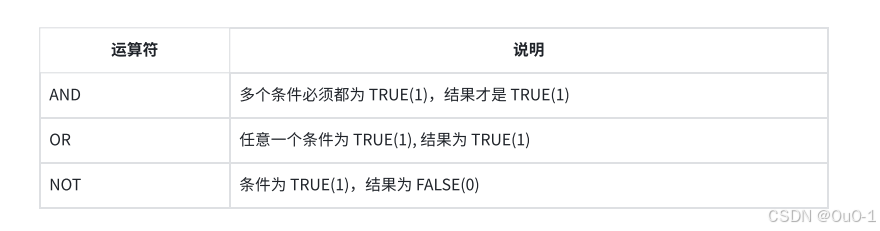
逻辑运算符
3.1 基本查询
遍历表的每个记录(每一行),把每一行的数据带入到条件中.
如果条件成立,这个记录就添加到结果集合中;如果不成立,就直接跳过.
查询英语不及格的同学及英语成绩
select name , English from exam1 where English < 60;查询语文成绩大于英语成绩的同学
select name ,Chinese, English from exam1 where Chinese > English;本次查询过程和刚刚一样,也是把每一条查询到的记录带入 where 后面的条件,把符合条件的记录添加到结果集,不满足条件的记录直接跳过;
别名无法作为 where 后面的条件
select name, Chinese + math + English as total from exam1 where total < 200;
ERROR 1054 (42S22): Unknown column 'total' in 'where clause'解析:这个错误其实是因为 SQL 语句执行顺序造成的:
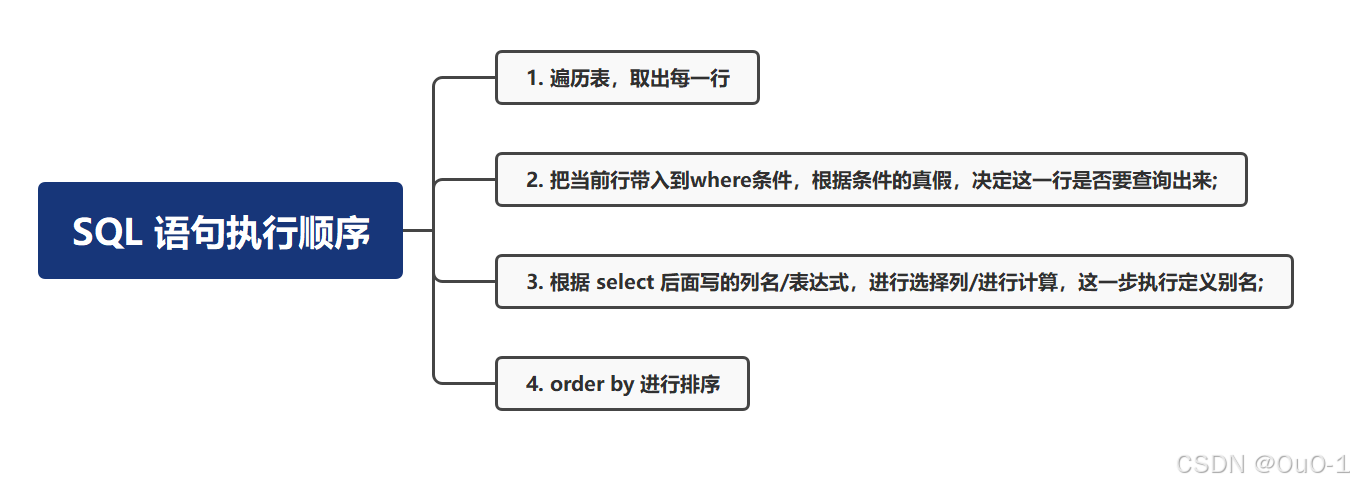
虽然 where 是写在 SQL 语句末尾,但是执行顺序是在定义别名之前的 ,因此在执行 where 条件时,如果条件中有别名,该别名是未被定义的;
3.2 AND和OR
查询语文成绩大于80分且英语成绩大于80分的同学
select name , Chinese , English from exam1 where Chinese > 80 and English > 80;
查询语文成绩大于80分或英语成绩大于80分的同学
select name , Chinese , English from exam1 where Chinese > 80 or English > 80;
注意:
and 和 or 同时出现会有优先级,但是如果表达式比较复杂,包含多组 and 和 or,就给需要先运算的部分加括号即可;
3.3 范围查询
查询语文成绩在[80,90]分的同学及语文成绩
select name, Chinese from exam1 where Chinese between 80 and 90;
查询数学成绩是58 或者59 或者 98 或者99 分的同学及数学成绩
select name, math from exam1 where math in(58, 59, 98, 99);总结
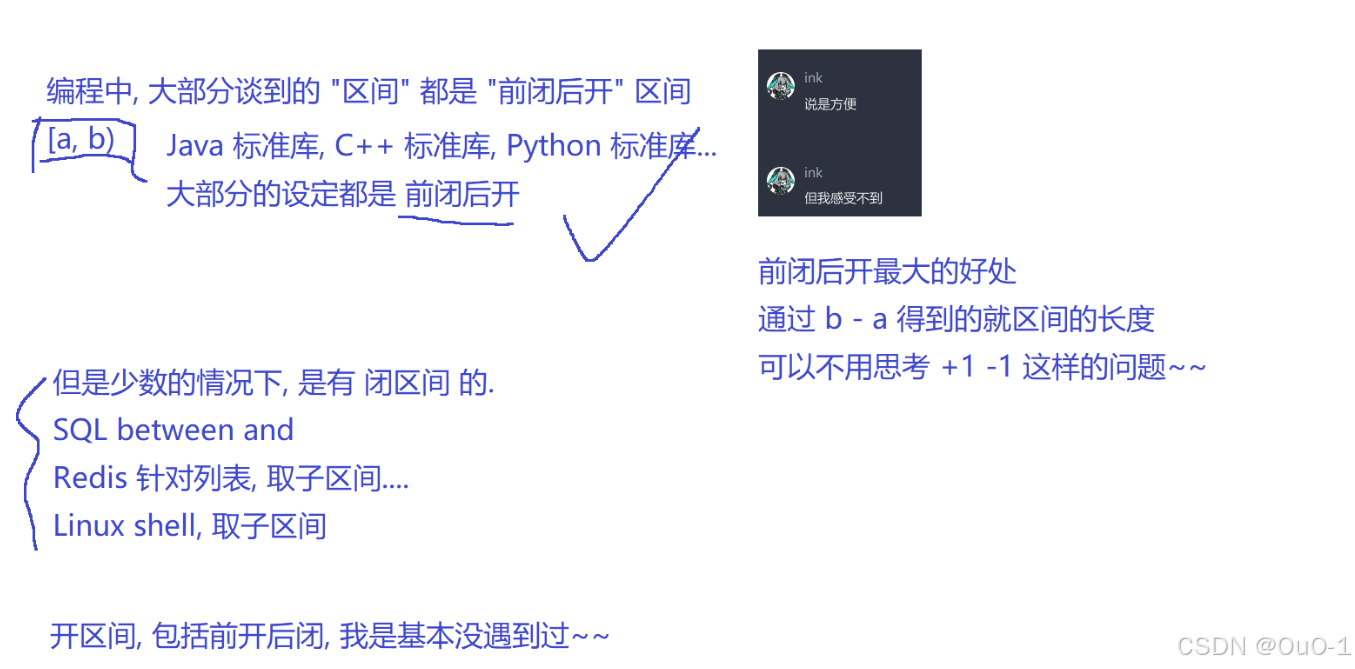
- 如果查询的区间是连续的,就使用 between....and;
- 如果查询的区间是离散的(某几个值),就使用 in() ;
3.4 模糊查询
不要求完全相等,只要满足一定的条件就可以了.

%匹配任意个数字符
-- 查询所有名字以孙开头的同学
select* from exam1 where name like '孙%';
-- 查询所有名字以孙结尾的同学
select* from exam1 where name like '%孙';
-- 查询所有名字有孙的同学
select* from exam1 where name like '%孙%';_匹配一个个数字符
select* from exam1 where name like '孙_'; -- 查询孙某
select* from exam1 where name like '孙__'; -- 查询孙某某想要查询名字中孙只在中间部分,不能在开头和结尾部分的需求,在数据库中实现有一定难度;
mysql 自带的模糊匹配功能相对比较弱;

3.5 NULL的查询
查询 id 为NULL的记录
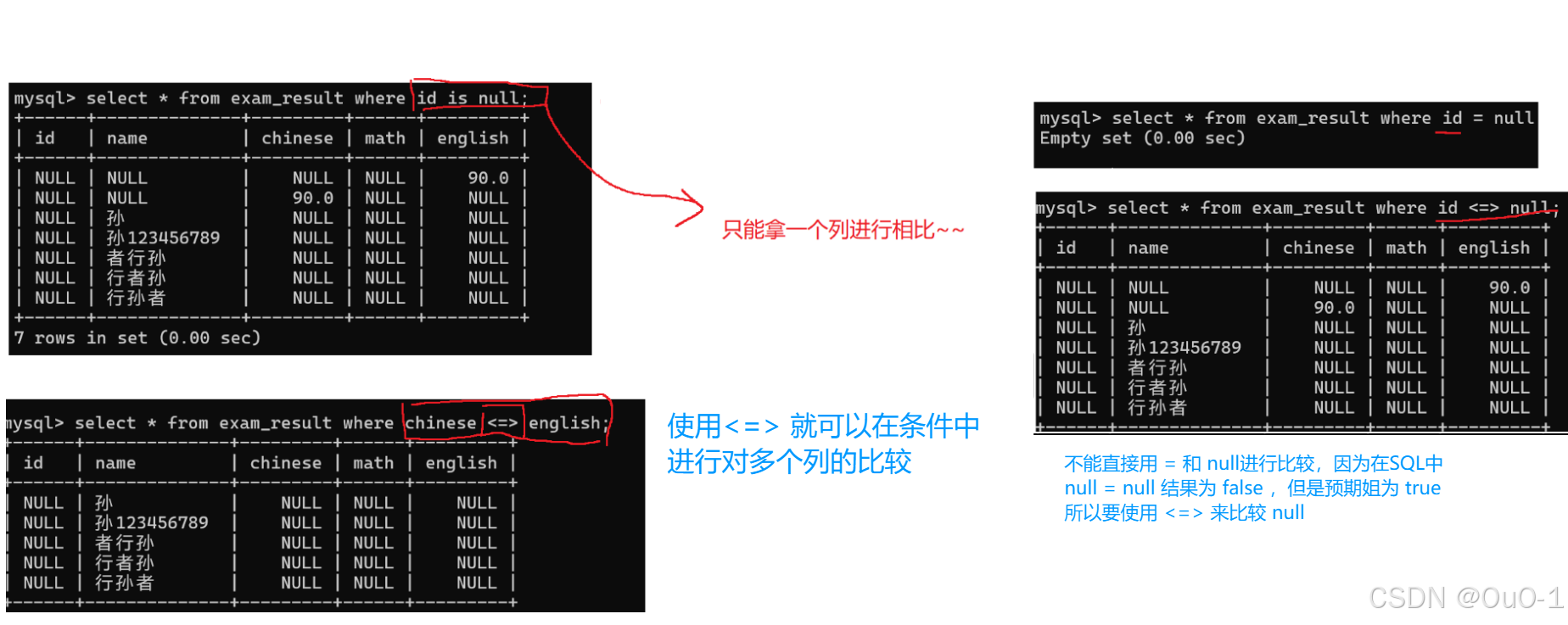
select* from exam1 where id <=> null ; -- 使用 <=> 判断 id 是否为 null
select* from exam1 where id is null; -- 使用 is 判断 id 是否为 null

4 Order by 排序
语法:
select 列名,列名.... from exam order by 列名 desc ; # 降序 (从高到低)
select 列名,列名.... from exam order by 列名 asc ; # 升序 (从低到高)
-- 注意:NULL被看做比任何值都小注意:
- 数据库不会对于查询得到的结果集的顺序,做出任何承诺(不一定会根据序号,插入顺序...等等因素来决定结果集的顺序)除非 sql 中包含 order by
- 如果不写 order,得到的结果的顺序是不可预期的.....写代码就不能依赖这样的顺序;
按语文成绩从低到高排序(不指定顺序,默认从低到高)
select* from exam1 order by Chinese;
+------+-----------+---------+------+---------+
| id | name | Chinese | Math | English |
+------+-----------+---------+------+---------+
| 5 | 刘玄德 | 55.0 | 85.0 | 45.0 |
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 2 | 孙悟空 | 87.0 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.0 | 90.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)对语文进行排序后,每一行的数据也会以语文成绩为基准进行排序;
查询同学各门成绩,依次按数学降序,英语升序,语文升序的方式显示
select name, math, English, Chinese from exam1 order by
math desc,
English asc,
Chinese asc;
+-----------+------+---------+---------+
| name | math | English | Chinese |
+-----------+------+---------+---------+
| 唐三藏 | 98.0 | 56.0 | 67.0 |
| 猪悟能 | 98.0 | 90.0 | 88.0 |
| 刘玄德 | 85.0 | 45.0 | 55.0 |
| 曹孟德 | 84.0 | 67.0 | 82.0 |
| 孙悟空 | 78.0 | 77.0 | 87.0 |
| 孙权 | 73.0 | 78.0 | 70.0 |
| 宋公明 | 65.0 | 30.0 | 75.0 |
+-----------+------+---------+---------+
7 rows in set (0.00 sec)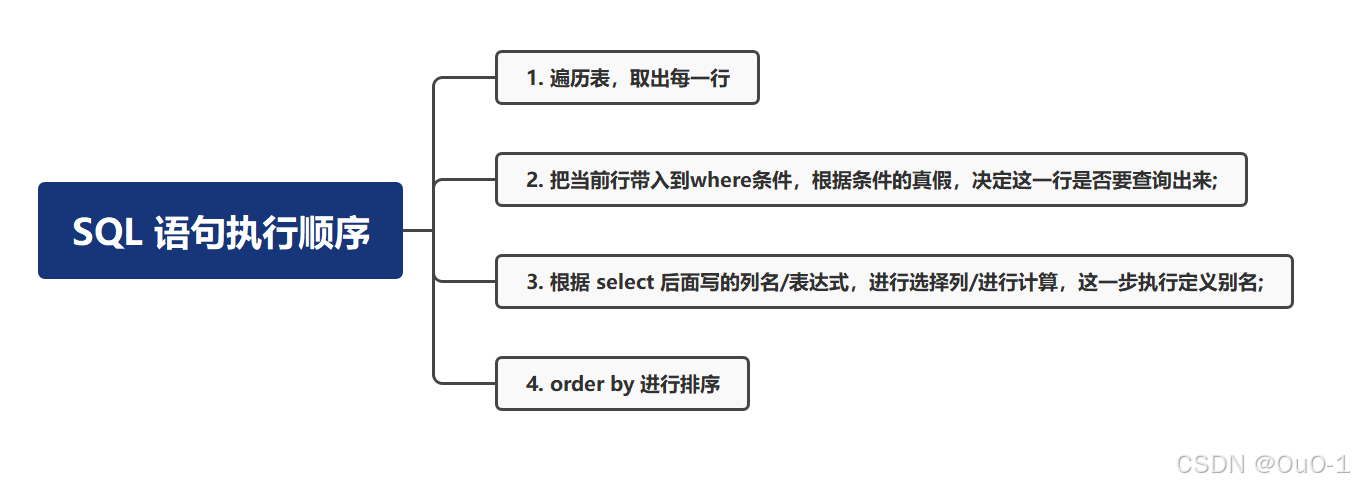
可以使用列的别名进行排序
select name, Chinese + Math + English as total from exam1 order by total desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 猪悟能 | 276.0 |
| 孙悟空 | 242.0 |
| 曹孟德 | 233.0 |
| 唐三藏 | 221.0 |
| 孙权 | 221.0 |
| 刘玄德 | 185.0 |
| 宋公明 | 170.0 |
| NULL | NULL |
+-----------+-------+
-- null 和任何数的计算结果都为 null
5 分页查询
- select *容易查询出太多的数据,导致机器挂掉;
- 通过指定列查询,虽然查到的结果是变少了很多,但是如果行数足够多的话,仍然是有可能会把机器搞出问题的;
- 此时更稳妥的做法,就是"分页查询",限制一次查询,最多能查到多少个记录;
5.1 查询第一页数据
select 列名 from 表名 limit num ;5.2 使用LIMIT子句进行分页查询
-- 起始下标为 0
-- 从0开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num;
-- 从 start 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT start, num;
-- 从 start 开始,筛选 num条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num OFFSET start;