目录
1. HIVE DDL
DDL也就是数据定义语言,在HIVE中DDL中的建表语句是重点,这直接决定是否能映射成功。
1.1 hive建表
建表语法树:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ... ]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT DELIMITED|SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value,...)]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)];注意建表时语法顺序要与语法树的顺序一致!
hive数据类型:
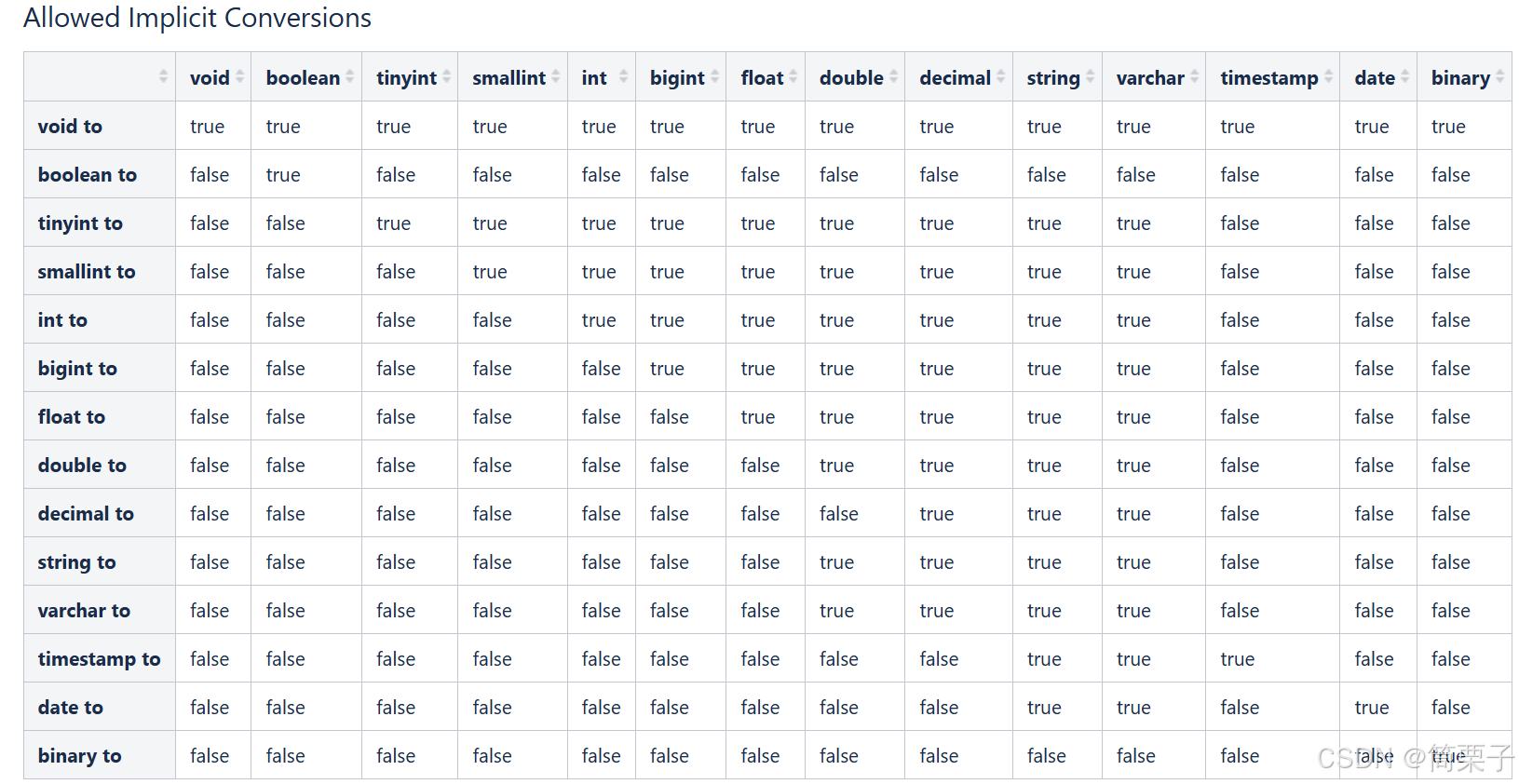
整体分为两类:原生数据类型和复杂数据类型。 原生数据类型包括:数值类型、时间日期类型、字符串类型、杂项数据类型; 复杂数据类型包括:array数组、map映射、struct结构、union联合体。在Hive中,英文字母大小写不敏感。复杂数据类型的使用通常需要和分隔符指定语法配合使用。如果定义的数据类型和文件不一致,hive会尝试隐式转换,但是不保证成功。
hive数据类型隐式转换表:
1.2 hive读写文件机制
Hive使用SerDe(Serializer、Deserializer)机制读写HDFS上文件。也就是序列化和反序列化。
hive读文件机制:
首先调用默认使用的InputFormat,返回一条一条kv键值对记录,默认一行对应一条记录。然后调用LazySimpleSerDe(默认)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
hive写文件机制:
首先调用LazySimpleSerDe(默认)的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS文件中。
在Hive的建表语句中,和SerDe相关的语法为ROW FORMAT DELIMITED | SERDE....这一行,ROW FORMAT DELIMITED 表示使用LazySimpleSerDe类进行序列化解析数据,ROW FORMAT SERDE 表示使用其他SerDe类进行序列化解析数据。
ROW FORMAT DELIMITED具体语法如下:
row format delimited
[fields terminated by char] -- 指定字段之间的分隔符
[collection items terminated by char] -- 指定集合元素之间的分隔符
[map keys terminated by char] -- 指定map类型kv之间的分隔符
[lines terminated by char] -- 指定换行符如果没有指定分隔符默认是'\001'。
location可以指定表储存路径。
1.3 内部表、外部表
默认创建的是内部表,如果想创建外部表可以使用关键字external
create external table ....删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。删除内部表时,它会删除数据以及表的元数据。
1.4 分区表
-
分区的作用:当Hive表的数据量很大且文件数量多时,为了避免查询时全表扫描,Hive支持根据特定字段对表进行分区。分区可以显著减少查询时需要扫描的数据量,提升查询效率。
-
分区字段的选择:分区的字段通常具有标识意义,常见的分区字段包括日期、地域、种类等。这些字段能够帮助将数据划分为逻辑上独立的部分。
-
分区的示例:例如,可以将一整年的数据按月份划分为12个分区(每个月一个分区)。这样,在查询时只需扫描特定月份的数据,而不必扫描全年的数据,从而减少查询时间。
-
分区的优势:通过分区,Hive能够避免全表扫描,提升查询性能,尤其是在处理大规模数据时,分区是一种非常有效的优化手段。
总结来说,分区是Hive中一种重要的数据管理技术,能够有效提升查询效率,尤其是在处理大数据量时。
分区表的建立和语法树中的partition by 这一行有关。
CREATE TABLE table_name (
....)
PARTITIONED BY (...);注意:分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上。
分区表数据的加载:
静态分区加载:指的是分区的字段值是由用户在加载数据的时候手动指定的。
load data [local] inpath ' ' into table tablename partition(分区字段='分区值'...);动态分区加载:指的是分区的字段值是基于查询结果自动推断出来的。核心语法是insert+select。
启用hive动态分区,需要在hive会话中设置两个参数:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
第一个参数表示开启动态分区功能,第二个参数指定动态分区的模式。分为nonstick非严格模式和strict严格模式。strict严格模式要求至少有一个分区为静态分区。
建立一个分区表
create table t1(
id int,
name string,
...
) partitioned by (dt string)
row format delimited
fields terminated by "\t";
动态插入数据:
insert into table t1 partition(dt) select t2.*, t2.date from t2;动态分区插入时,分区值是根据查询返回字段位置自动推断的。
通过建表语句中关于分区的相关语法可以发现,Hive支持多个分区字段:PARTITIONED BY (partition1 data_type, partition2 data_type,….)。
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。比如:把全国人口数据首先根据省进行分区,然后根据市进行划分,如果你需要甚至可以继续根据区县再划分,此时就是3分区表。
1.5 分桶表
分桶表(Bucketed Table)是Hive中的一种数据存储和优化技术,用于进一步细化数据的管理和查询性能。它是基于分区表的补充,可以在分区的基础上对数据进行更细粒度的划分。分桶是通过对表中某一列的哈希值进行计算,将数据分散到固定数量的桶(Bucket)中。默认规则是:hashfunc(分桶字段) % N bucket。每个桶是一个独立的文件,数据根据分桶字段的哈希值分配到对应的桶中。
示例:
CREATE TABLE bucketed_sorted_table (
id INT,
name STRING,
age INT
)
CLUSTERED BY (id) INTO 4 BUCKETS
SORTED BY (age DESC) INTO 4 BUCKETS;这里以 id 字段作为分桶字段,并将数据分散到 4 个桶中,每个桶内的数据会按照 age 字段降序排序。
在向分桶表插入数据时,需要使用 INSERT OVERWRITE 或 INSERT INTO 语句,并确保数据按分桶字段正确分布。
分桶作用:
-
提升查询性能:
分桶可以减少数据扫描的范围。例如,当对分桶字段进行查询时,Hive 可以直接定位到特定的桶,而不需要扫描整个表或分区。对于 JOIN 操作,如果两个表的分桶字段和桶数量相同,Hive 可以执行高效的 Map-Side Join(Map 端连接),避免 Shuffle 操作。 -
数据均匀分布:
分桶可以确保数据均匀分布到各个桶中,避免数据倾斜问题。 -
支持高效采样:
分桶表支持对数据进行高效采样(Sampling),例如只查询某个桶的数据,而不需要扫描整个表。
1.6 常用DDL语句
关于数据库:
--创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] -- 数据库的注释说明语句
[LOCATION hdfs_path] -- 指定数据库在HDFS存储位置,默认/user/hive/warehouse
[WITH DBPROPERTIES (property_name=property_value, ...)]; -- 用于指定一些数据库的属性配置
--描述数据库信息
DESCRIBE DATABASE/SCHEMA [EXTENDED] db_name; -- EXTENDED:用于显示更多信息。
--切换数据库
USE database_name;
--删除数据库
-- 默认行为是RESTRICT,这意味着仅在数据库为空时才删除它。要删除带有表的数据库,我们可以使用CASCADE。
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
--更改数据库属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
--更改数据库所有者
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
--更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;关于表:
--查询指定表的元数据信息
describe formatted [db_name.]table_name;
describe extended [db_name.]table_name;
-- 删除表,如果指定了PURGE,则表数据不会进入.Trash/Current目录,跳过垃圾桶直接被删除。
DROP TABLE [IF EXISTS] table_name [PURGE];
-- 清空表
TRUNCATE [TABLE] table_name;
--更改表名
ALTER TABLE table_name RENAME TO new_table_name;
--更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );
--更改SerDe属性
ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ... )];
ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',');
--移除SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );
--更改表的文件存储格式 该操作仅更改表元数据。现有数据的任何转换都必须在Hive之外进行。
ALTER TABLE table_name SET FILEFORMAT file_format;
--更改表的存储位置路径
ALTER TABLE table_name SET LOCATION "new location";有关分区表:
--1、增加分区
ALTER TABLE table_name ADD PARTITION (partition1=...,partition2=...) location 'path'
PARTITION (partition1=...,partition2...') location 'path';
--2、重命名分区
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
ALTER TABLE table_name PARTITION (dt='2008-08-09') RENAME TO PARTITION (dt='20080809');
--3、删除分区
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (partition1=...,partition2=...);
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (partition1=...,partition2=...) PURGE; --直接删除数据 不进垃圾桶
--4、修复分区
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
--5、修改分区
--更改分区文件存储格式
ALTER TABLE table_name PARTITION (partition1=...) SET FILEFORMAT file_format;
--更改分区位置
ALTER TABLE table_name PARTITION (partition1=...) SET LOCATION "new location";
2. HIVE DML
load加载数据:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]local表示是从本地文件系统加载数据到Hive的表中;如果没有local表示的是从HDFS文件系统加载数据到Hive表中;
insert + select:
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;多重插入,减少表扫描次数:
--多重插入
from student
insert overwrite table student_insert1
select num
insert overwrite table student_insert2
select name;
insert导出数据操作:
insert overwrite directory 'path' row format delimited fields terminated by ','
stored as orc
select * from table_name;