欢迎大家来到我的博客,给生活来点impetus!!
这一节我们学习双向链表(数据结构初阶)。

双向链表
链表的分类
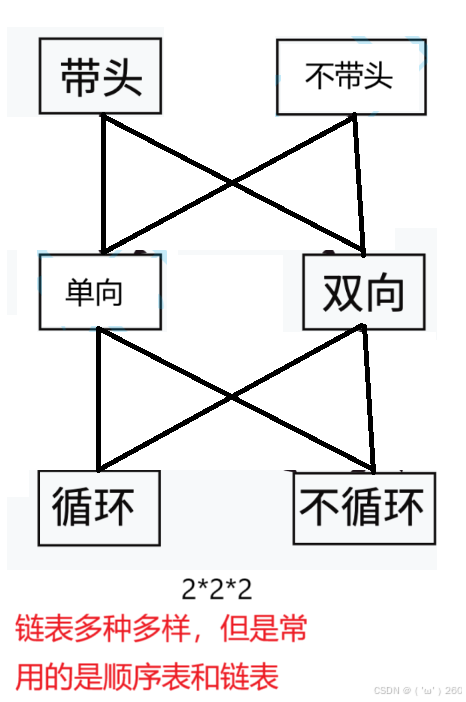
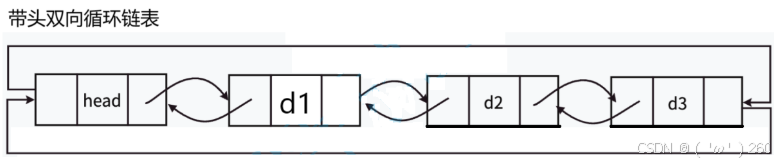
概念与结构
注意:这⾥的“带头”跟前⾯我们说的“头结点”是两个概念,实际前⾯的在单链表阶段称呼不严谨,但是为了同学们更好的理解就直接称为单链表的头结点。
带头链表⾥的头结点,实际为“哨兵位”,哨兵位结点不存储任何有效元素,只是站在这⾥“放哨的”。
单链表存储的数据都是有效的,事实上,他是不存在头结点的。
单链表为空时是NULL
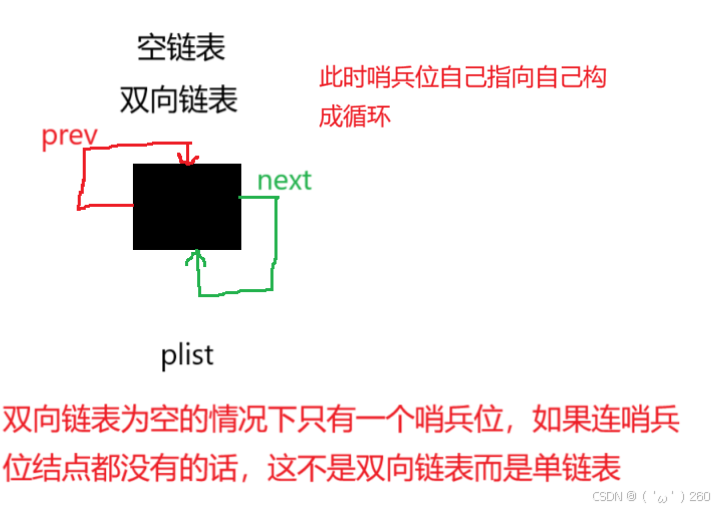
双向链表为空时此时表中仍然有哨兵位结点
当链表为NULL,双向链表如下图:
实现双向链表
定义链表结构
双向链表既要能够存储数据,又要存储下一个和上一个结构体的地址。
这样才能找到这个结构体。

链表打印
涉及链表打印,就一定涉及链表的遍历,双向链表的遍历与单链表存在区别。
下面画图演示过程:

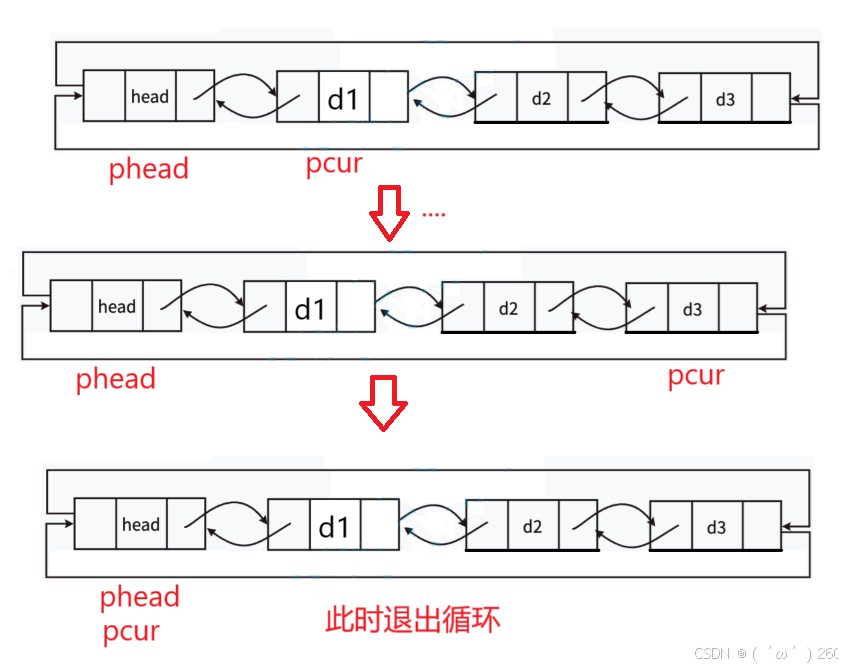
细节:1:判决条件 2:pcur的设立(phead的下一个结点)
判空
判空时在删除结点的时候十分有用。
可能你会问,和直接写while(pcur!=NULL)有区别吗?

在该处的双向链表中为空,此时表中有头结点,不为NULL,判空就得改变,
写为assert(!LTEmpty);
若写为while(pcur!=NULL),语句允许把双向链表把哨兵位删除,此时就不在是双向链表了
申请结点

细节:malloc函数开辟是否成功,注意需要判断。
初始化
初始化具有两种思路:
1:先开辟结点,再来改变指针指向,不返回。
2:开辟结点和改变指针指向一并完成,返回结点。
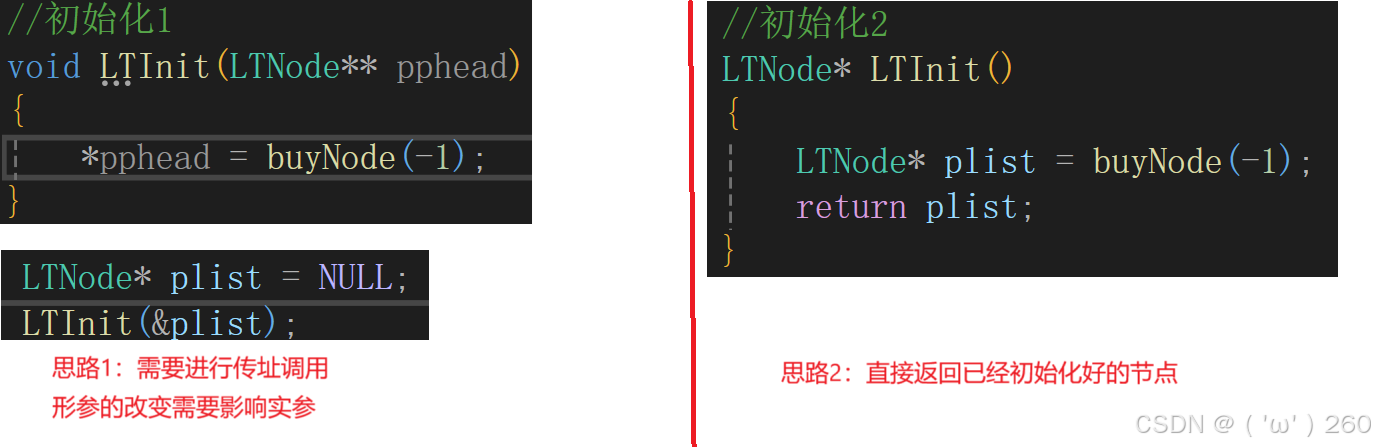
这里推荐使用第二种方法。
头插尾插
尾插
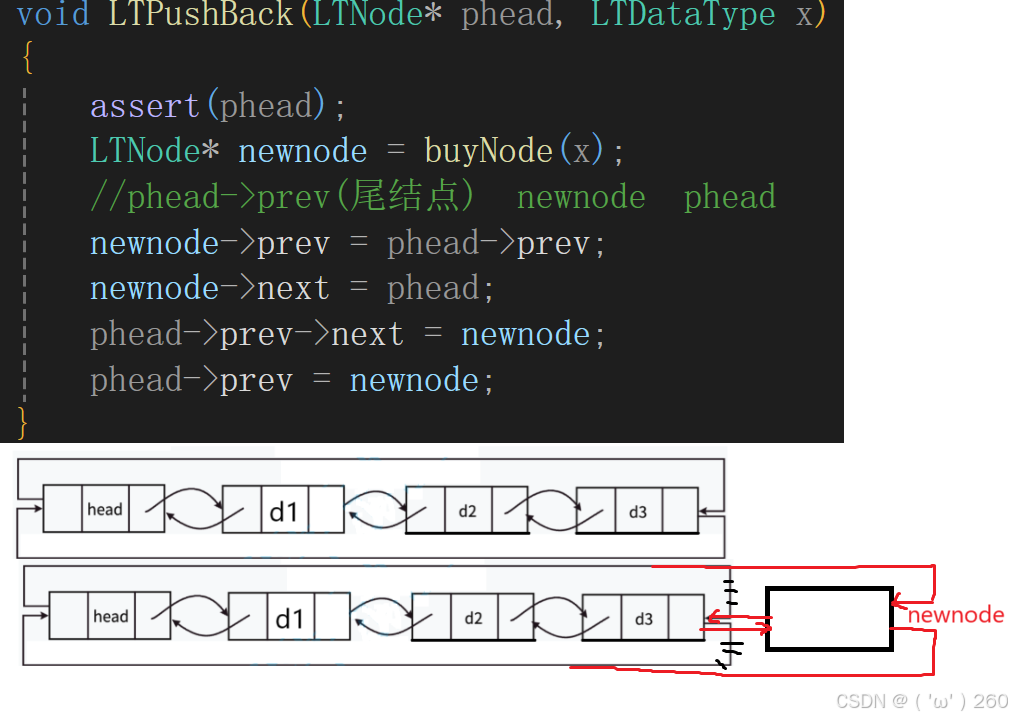
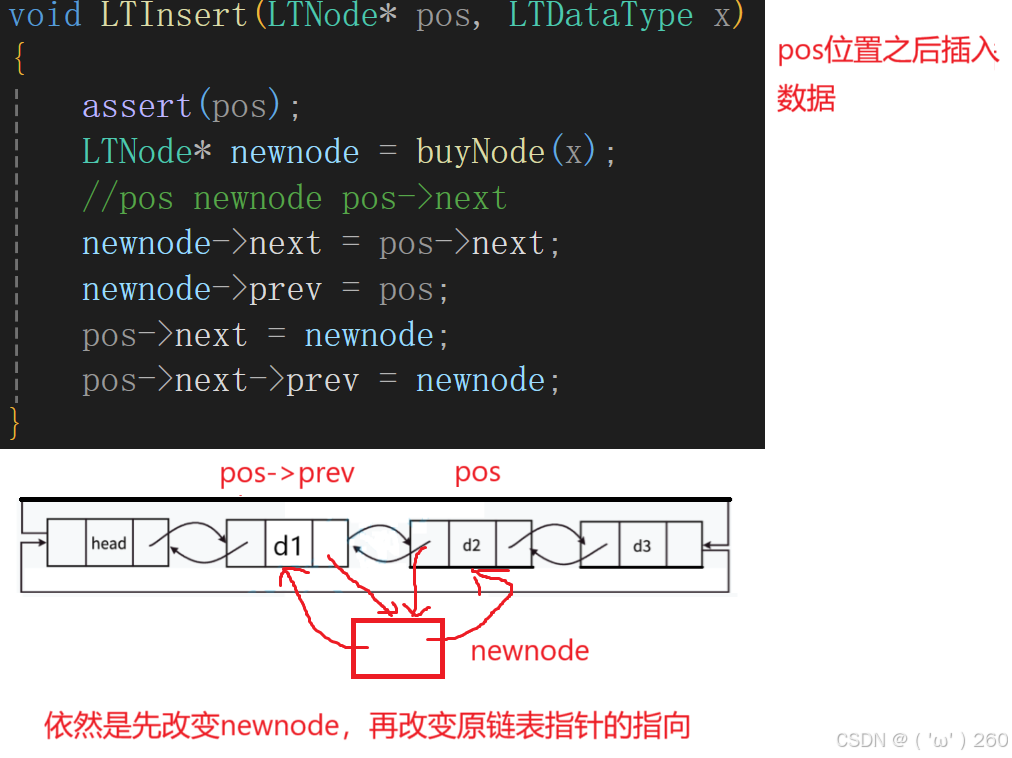
需要先修改newnode,再修改原链表。
头插
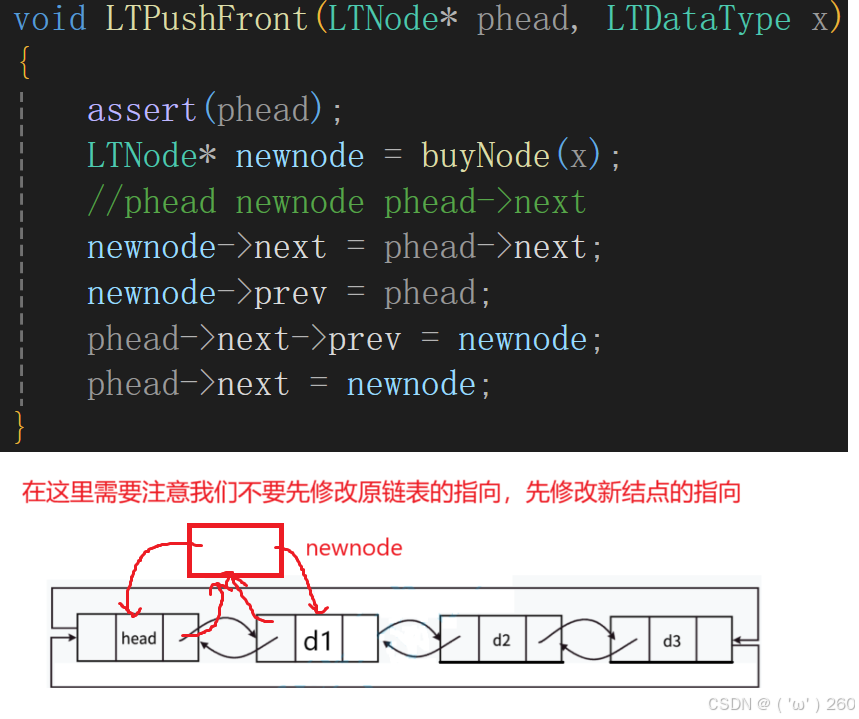
我们先修改newnode,再修改原链表。
通过对比发现,为什么头插是在phead结点后面插入,而不是在phead结点之前插入?
因为在phead结点之前插入,就等价于尾插了。
头删尾删
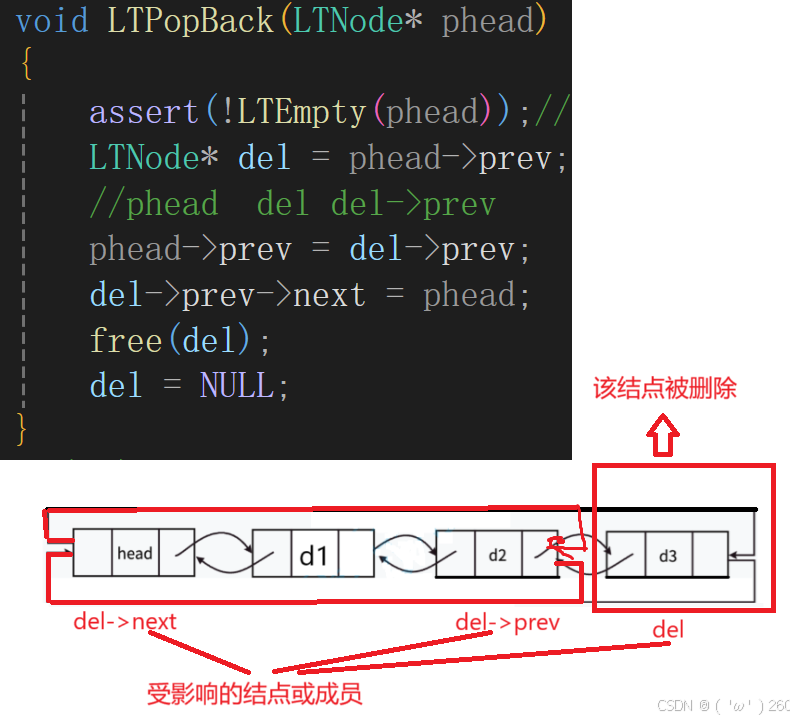
尾删
头删
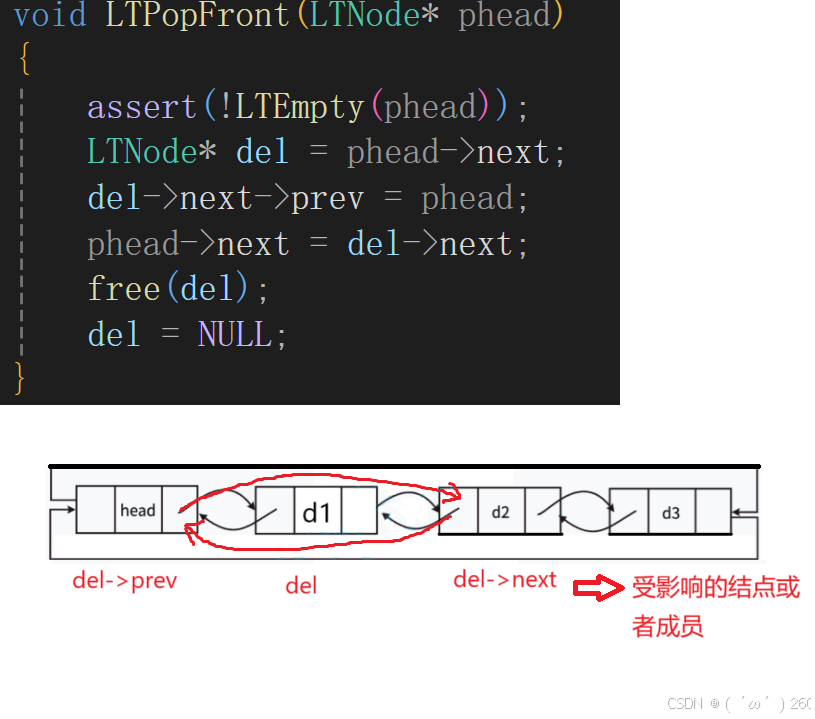
头删和尾删断言的内容不在是判断空,而是判断是不是哨兵结点。
前面我们已经说明,链表为空时为真,返回1,但是assert断言需要停止,就需要添加一个非(!)。不要被绕晕了。
查找
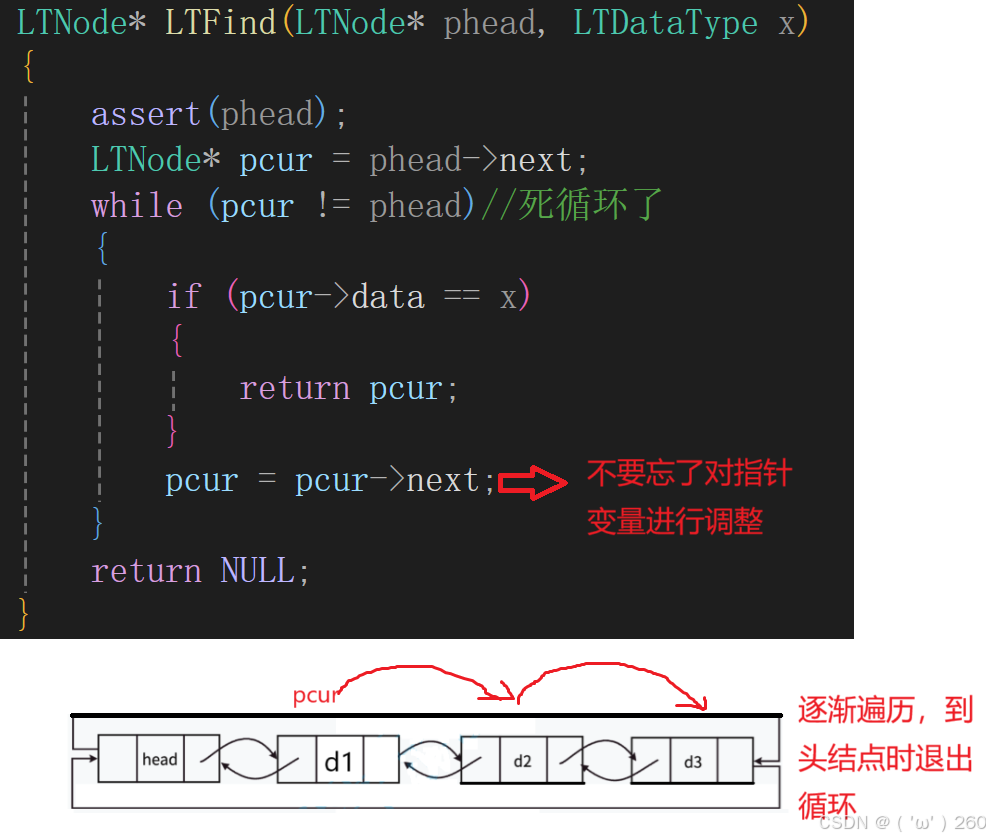
此处的查找为了给后面pos位置插入删除做铺垫,pos位置插入和删除就可以省去遍历的步骤了
指定位置插入和删除
pos之前插入数据与pos之后插入数据十分相同,如下:
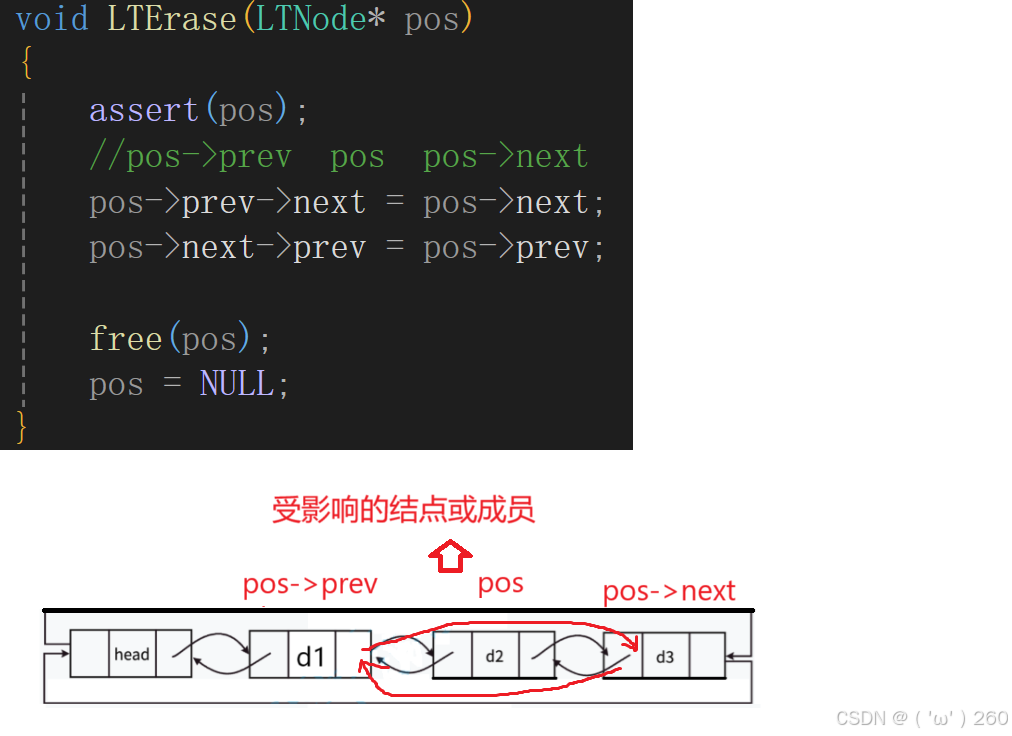
指定位置删除数据。

销毁链表
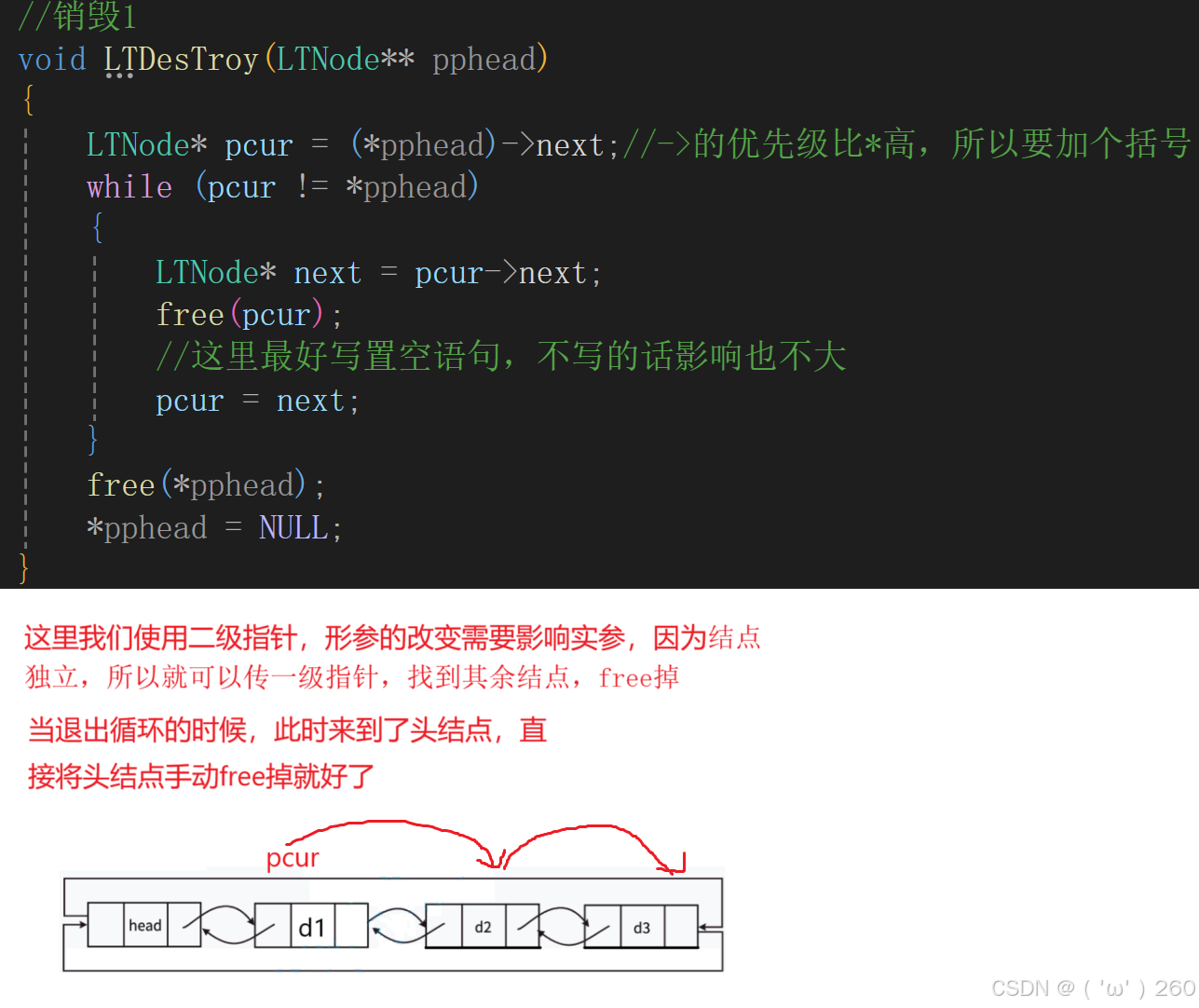
此时我们发现,前方都是一级指针,销毁是二级指针,为了保证接口一致性,我们改为一级指针,,font color = red>函数调用完成后,手动free。

最后我们来总结一下细节:
1:双向链表为空时,只有一个哨兵位
2:双向链表进行操作时传递的一定为一级指针,因为哨兵位不能改变
3:注意分析对结点操作时受影响的节点或成员
4:插入结点时一定要先对newnode的指针进行操作
5:头插是在哨兵位后面插入
6:遍历时注意pcur的起始位置与判决条件
7:销毁与删除的区别前者没有任何节点,后者一定有头结点
8:pos不可能为哨兵位,该结点存储数据无效
9:节点与数组不同的点:数组是连续的地址,结点的地址是不连续的
顺序表和链表的分析
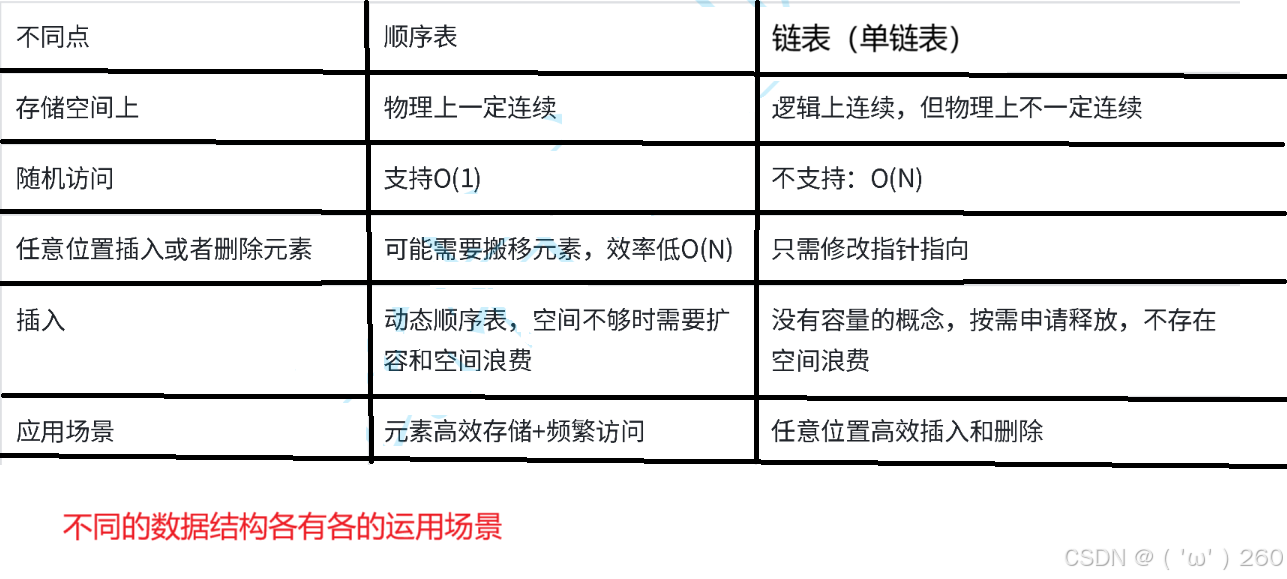
当只用用来存储数据,不用任意位置插入删除,会使用顺序表
当需要频繁修改结点,任意位置插入或删除,使用链表
结语
感谢大家阅读我的博客,欢迎大家有新的知识点向我补充,也欢迎大家纠正我的错误,路漫漫其修远兮,吾将上下而求索,加油!!陌生人!!!
