索引的作用
类似于一本书中的目录,通过索引可以快速定位到数据具体的物理存储位置,起到优化查询的作用
索引的分类
B树 默认使用的索引类型(原型:平衡二叉树算法)

B*树
BTREE索引算法演变
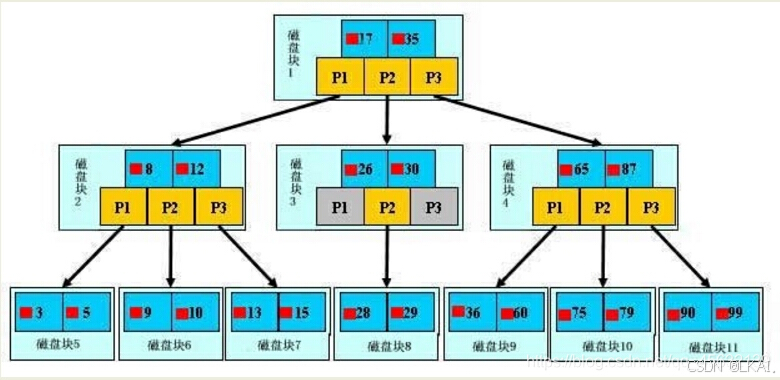
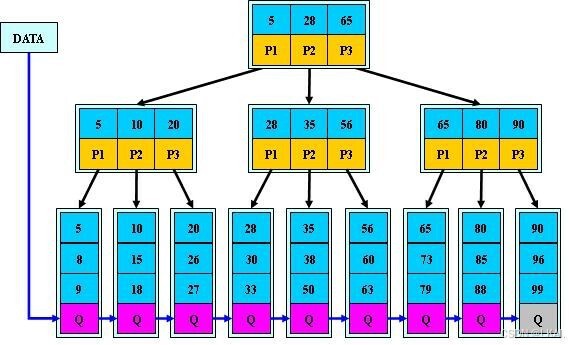
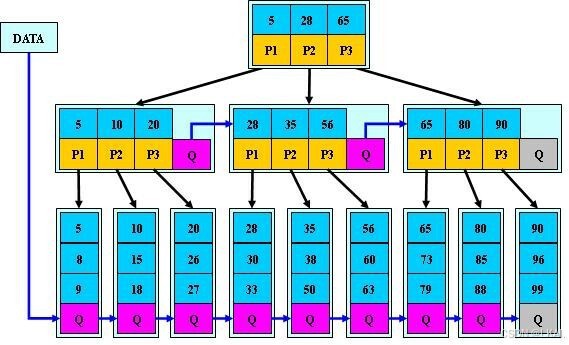
Btree索引功能上的分类
- 聚集索引(唯一性)
- MySQL会自动选择主键作为聚集索引列,没有主键会选择唯一键,如果都没有会生成隐藏的
- MySQL进行存储数据时,会按照聚集索引列值的顺序,有序存储数据行0
- 聚集索引直接将原表数据页,作为叶子节点,然后提取聚集索引列向上生成枝和根
索引的顺序和表中内容的顺序是一致的(书的主目录),如果设置ID列为主键,那么这一列会自动成为聚集索引,而且是唯一索引
- 非聚集索引
索引的顺序和表中内容的顺序是不一致的(类似书的附录)
- 辅助索引(多个)
- 提取索引列的所有值,进行排序
- 将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点
- 在叶子节点中的值,都会对应存储主键ID
- 聚集索引和辅助索引的区别
- 表中任何一个列都可以创建辅助索引,在你有需要的时候,只要名字不同即可
- 在一张表中,聚集索引只能有一个,一般是主键
- 辅助索引叶子节点只存储索引列的有序值+聚集索引列值
- 聚集索引叶子节点存储的时有序的整行数据
- MySQL的表数据存储是聚集索引组织表,辅助索引查询表
注:MySQL的查询过程就是通过辅助索引找到主键索引的id号,再通过主键索引查数据行
辅助索引细分
- 单列辅助索引
- 联合索引(覆盖索引)
- 唯一索引
索引树高度
索引树高度应当越低越好,一般维持在3-4最佳
- 数据行数较多
分区:partition用的比较少
分片:分布式架构
- 字段长度
业务允许,尽量选择字符长度短的列作为索引列
业务不允许,采用前缀索引
- 数据类型
int
char 和 varchar
enum
datetime
profiles
show profile 和 show profiles 命令用于展示SQL语句的资源使用情况,包括CPU的使用,CPU上下文切换,IO等待,内存使用等,这个命令对于分析某个SQL的性能瓶颈非常有帮助,借助于show profile的输出信息,能让我们知道一个SQL在哪个阶段耗时最长,消耗资源最多,从而为SQL优化,提高SQL性能提供重要的依据。
show profiles展示的是简要的耗时信息,如果想了解某个SQL的具体耗时情况,执行show profile 查看。
使用show profile之前,先启用profiling, profiling是session级变量,session关闭,该session的profiling信息也会丢失。
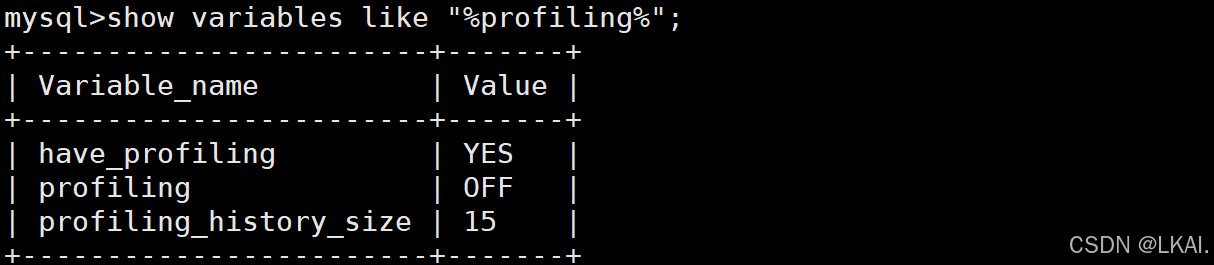
查看profiling状态:
show variables like "%profiling%";
开启profiling:
set profiling = 1;

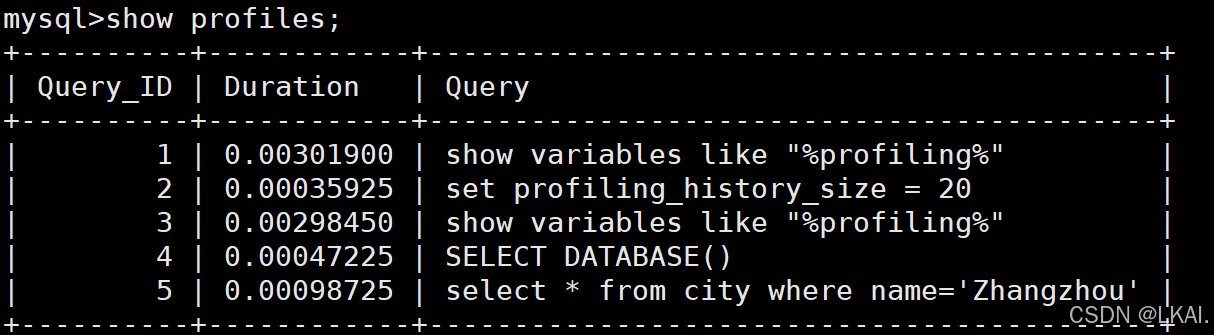
开启profiling之后,执行几条SQL,然后执行 show profiles 展示最近执行的多个SQL的执行耗时情况,具体能收集多少个SQL,由参数 profiling_history_size 决定,默认值为15,最大值为100。如果设置为0,等同于关闭profiling。
设置收集SQL数量:
set profiling_history_size = 20;
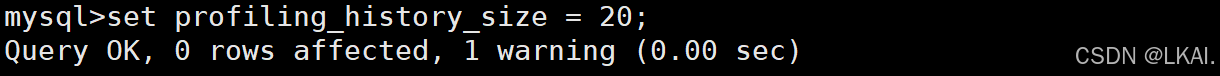
测试:
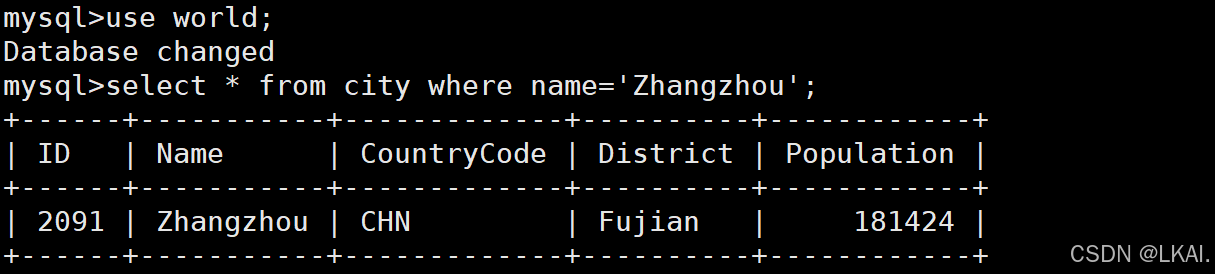
use world;
select * from city where name='Zhangzhou';
show profiles;
- show profile type 选项
all:显示所有的性能开销信息
block io:显示块 IO 相关的开销信息
context switches: 上下文切换相关开销
cpu:显示 CPU 相关的信息
ipc:显示发送和接收相关的开销信息
memory:显示内存相关的开销信息
page faults:显示页面错误相关开销信息
source:显示和 Source_function、Source_file、Source_line 相关的开销信息
swaps:显示交换次数的相关信息
查看query_id为2的cpu,block io
show profile cpu,block io for query 2;
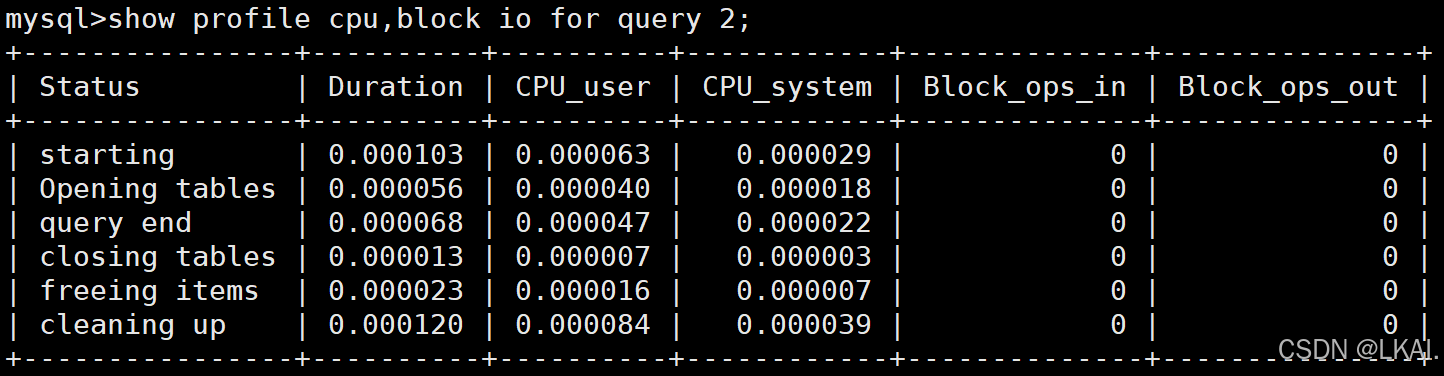
返回结果列字段含义:
Status:sql 语句执行的状态
Duration:sql 执行过程中每一个步骤的耗时
CPU_user:当前用户占有的 cpu
CPU_system:系统占有的 cpu
Block_ops_in:I/O 输入
Block_ops_out:I/O 输出
索引的命令操作
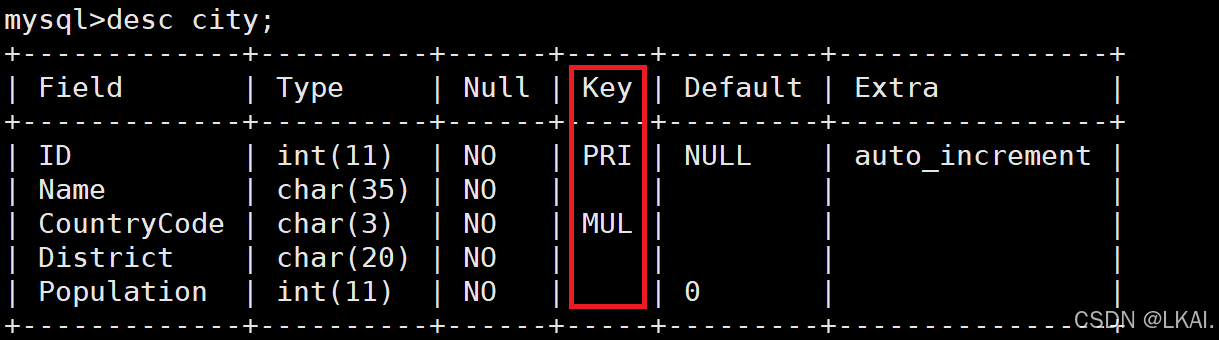
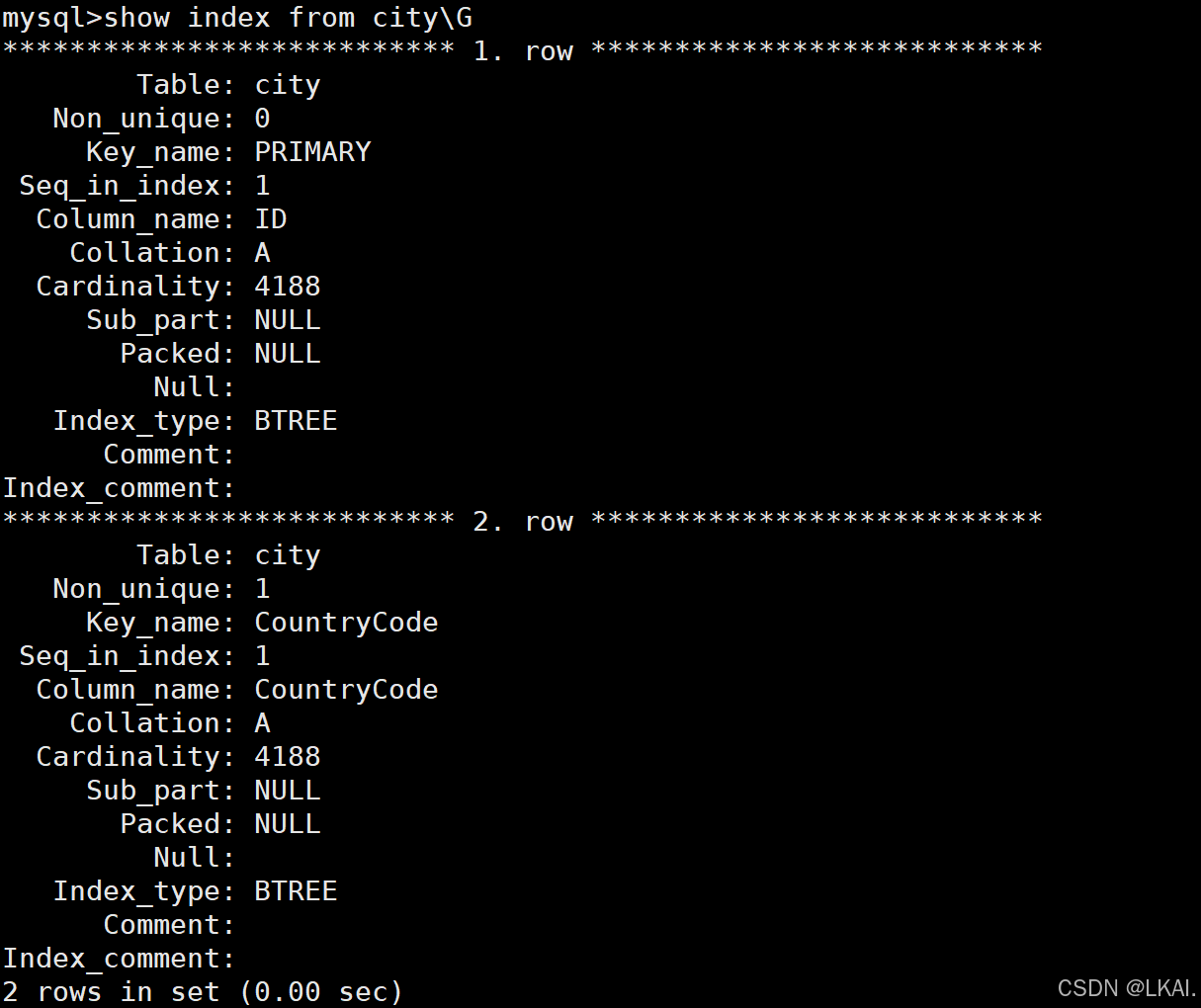
- 查询索引
PRI ——主键索引
MUL ——辅助索引
UNI ——唯一索引
desc city;
show index from city;

行转列显示:
show index from city\G
- 创建索引
单列的辅助索引:
alter table city add index idx_name(name);

多列的联合索引:
alter table city add index idx_c_p(countrycode,population);
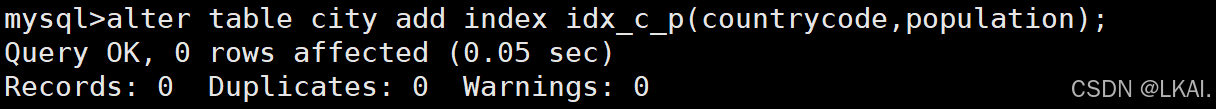
唯一索引(列内容必须唯一,查询速度最快):
语法:alter table 表名 add unique index 索引名称(列名);
前缀索引:
alter table city add index idx_dis(district(5));

- 删除索引
alter table city drop index idx_name;

alter table city drop index idx_c_p;

alter table city drop index idx_dis;

压力测试
进入world数据库导入t100w.sql表
source t100w.sql
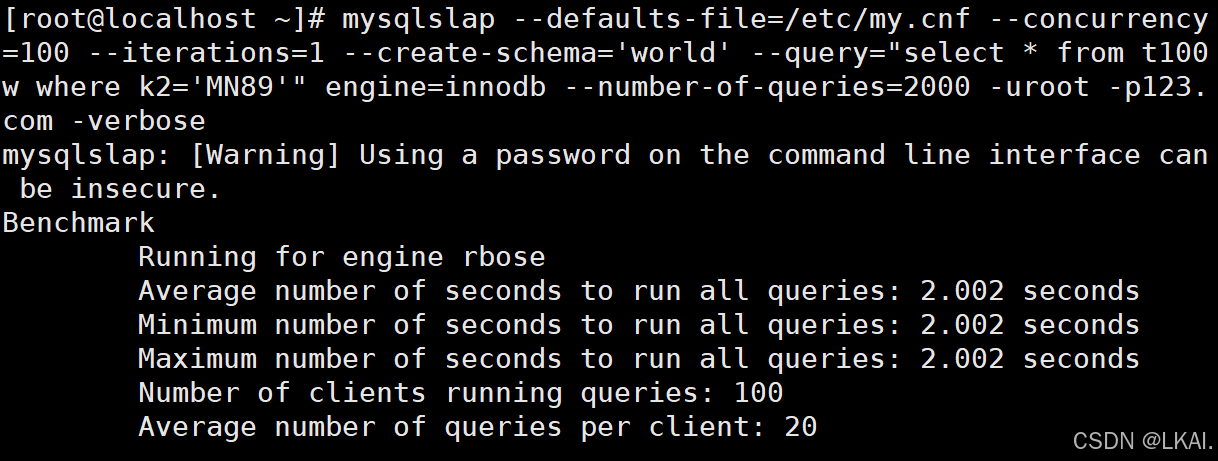
未优化测试:
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='world' --query="select * from t100w where k2='MN89'" engine=innodb --number-of-queries=2000 -uroot -p123.com -verbose

优化:
创建索引
alter table t100w add index idx_k2(k2);

优化后测试:
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='world' --query="select * from t100w where k2='MN89'" engine=innodb --number-of-queries=2000 -uroot -p123.com -verbose
执行计划分析
- 作用
做查询结果的分析,便于管理判断语句的执行效率。
- 获取执行
desc select * from t100w where k2='MN89';

返回结果列字段含义:
partitions:是否分区
type:ref等值索引(K2='MN89')
possible_key:可能会用到的索引
key:使用的索引
key_len:索引的长度
ref:const(传递给主键)
rows:查出的行281
filtered:表预计扫描了281条记录,其中100%满足条件
- 分析执行计划
desc select * from t100w where k1='Hd';

查询类型为ALL(全表扫描)
索引扫描:
index全索引扫描
range范围
ref等值
eq_ref联合等值(多表查询)
const(system)主键等值
NULL没有索引
创建索引:
alter table city add index idx_c_p(countrycode,population);
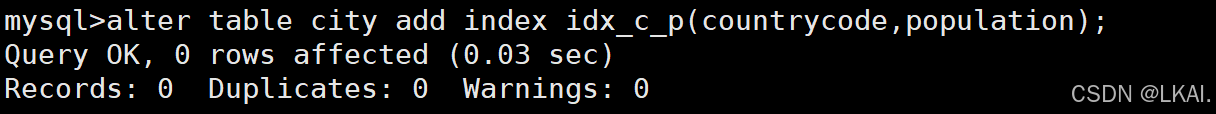
全索引扫描(index):
desc select countrycode from city;

范围扫描(>、<、>=、<=、and、or、between、in、like)(range):
desc select countrycode from city where countrycode='CHN' and population>5000000;

desc select * from city where id>2000;

desc select * from city where countrycode like 'CH%';

对于辅助索引来讲,!= 和not in等语句是不走索引的
对于主键索引列来讲,!= 和not in等语句是走range
%在前不走任何索引
————————————
desc select * from city where countrycode='CHN' or countrycode='USA';

desc select * from city where countrycode in ('CHN','USA');

一般改写为union all
desc select * from city where countrycode='CHN' union all select * from city where countrycode='USA';

辅助索引等值查询(ref):
desc select * from city where countrycode='CHN' union all select * from city where countrycode='USA';

联合等值查询(eq_ref):
desc select b.name,a.name,a.population from city as a join country as b on a.countrycode=b.code where a.population<100;

主键或唯一键等值查询(const):
desc select * from city where id=100;
