环境准备
1 三台安装Hadoop的虚拟机
2 flume的安装 参考flume的大数据集群安装
3 kafka 安装参考kafka集群
4 windows +ideal+mysql
项目思路
利用ideal产生实时的日志,利用log4j文件,将日志文件实时采集到flume上面,利用kafka来进行监听传输,通过sparkStreaming 对产生的日志文件进行计算,并且实时更新到我们的数据库当中。
实验环境启动配置
启动hdfs(先启动hdfs 才能启动flume):
[root@niit01 ~]# start-all.sh
启动zookeeper (启动zookeeper,才能启动kafka):
[root@niit01 zookeeper-3.4.5]# bin/zkServer.sh start
JMX enabled by default
Using config: /training/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper .already running as process 4368.
进入flume安装目录下的conf下配置flume
创建编辑example.conf
[root@niit01 conf]# vim example.conf
配置内容:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#a1.sources.r1.type = netcat
a1.sources.r1.type = avro
#flume接收的主机以及端口号
a1.sources.r1.bind = niit01
#a1.sources.r1.command=niit01
a1.sources.r1.port = 4444
# Describe the sink
#logger日志信息打印在控制台
# a1.sinks.k1.type =logger
# 指定Flume sink将日志信息连接kafka进行监听
#a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#kafka主题必须有 主机名还有容量
a1.sinks.k1.kafka.topic = test1
a1.sinks.k1.kafka.bootstrap.servers =niit01:9092
a1.sinks.k1.kafka.flumeBatchSize = 100
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.byteCapacityBufferPercentage= 20
a1.channels.c1.byteCapacity = 800000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
保存退出;
进入到kafka安装目录 创建:topic test1
bin/kafka-topics.sh --create --zookeeper niit01:2181 --replication-factor 1 --partitions 1 --topic test1
查看主题:
[root@niit01 kafka]# bin/kafka-topics.sh --list --zookeeper niit01:2181
环境配置完毕:
编写项目代码
导入log4j的环境变量
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.6.0</version>
</dependency>
创建编辑log4j日志文件,更改log4j的输出位置到flume的主机上
log4j.rootLogger = INFO,stdout,flume
# configure a class's logger to output to the flume appender
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
# shuchudaoflume
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname =niit01
log4j.appender.flume.Port = 4444
log4j.appender.flume.UnsafeMode = true
编写生成日志文件代码flumeLog:
package com.test;
import org.apache.log4j.Logger;
public class flumeLog {
private static Logger log = Logger.getLogger(log4j.class.getName());
public static void main(String[] args) throws InterruptedException {
testDataGen(1);
}
public static void testDataGen(int num) throws InterruptedException {
while (true) {
Thread.sleep(5000);
StringBuilder sb = new StringBuilder();
int n = num;
for (int i = 0; i < n; i++) {
String dateTime = timeGen();
sb.append(dateTime)
.append("_")
.append(userIdGen()) // 用户ID
.append("_")
.append(sessionIdGen()) // sessionId
.append("_")
.append(userIdGen()) // 页面ID
.append("_")
.append(dateTime + " " + timeStampGen())
.append("_");
if (i % 2 == 0) {
sb.append(keywordGen()); // 搜索关键字
} else {
sb.append("null"); // 搜索关键字
}
sb.append("_");
if (i % 3 == 0) {
sb.append(cIdGen()) // 点击品类ID
.append("_")
.append(productIdGen()); // 产品ID
} else {
sb.append("-1") // 点击品类ID
.append("_")
.append("-1");// 产品ID
}
sb.append("_");
if (i % 5 == 0) {
sb.append(orderIdsGen()) // 下单品类ID
.append("_")
.append(cIdGen()); // 产品ID
} else {
sb.append("null") // 下单品类ID
.append("_")
.append("null"); // 产品ID
}
sb.append("_");
if (i % 7 == 0) {
sb.append(orderIdsGen()) // 支付品类Ids
.append("_")
.append(cIdGen()); // 产品ids
} else {
sb.append("null") // 支付品类Ids
.append("_")
.append("null");// 产品ids
}
sb.append("_")
.append(cityIdsGen());// 城市Id
if (i <= n - 1) {
sb.append("\n");// 换行
}
}
log.info(sb.toString());
}
}
public static int cIdGen(){
return (int)(Math.random() * (1000 - 1) + 1);
}
public static int cityIdsGen(){
return (int)(Math.random() * (100 - 1) + 1);
}
public static int userIdGen() {
return (int)(Math.random() * (1000000 - 1) + 1);
}
//产生时间(年月日)
public static String timeGen() {
int year =(int) (Math.random() * (2021 - 2010 + 1) + 2010);
int month = (int)(Math.random() * (12 - 1 + 1) + 1);
int day= (int)(Math.random() * (31 - 1 + 1) + 1);
return year + "-" + month + "-" + day;
}
//随机型号
public static String keywordGen() {
String[] key={"手机", "电脑", "苹果", "小米", "联想", "华为"};
int r = (int)(Math.random() * (5) + 0);
String value = key[r];
return value;
}
//时间(时分秒)
public static String timeStampGen() {
int hour = (int)(Math.random() * (24 - 1 + 1) + 1);
int munite = (int)(Math.random() * (60 - 1 + 1) + 1);
int second = (int)(Math.random() * (60 - 1 + 1) + 1);
return hour + ":" + munite + ":" + second;
}
public static int productIdGen(){
return (int)(Math.random() * (10000000 - 100) + 100);
}
public static String orderIdsGen() {
int r = (int)(Math.random() * (10 - 2) + 2);
String ret = "";
for (int i=0;i<r;i++) {
if (i < r - 1) {
ret = ret + productIdGen() + ",";
}else if(i == r - 1){
ret += productIdGen();
}
}
return ret;
}
public static String sessionIdGen() {
int n = (int)(Math.random() * (1000000 - 1) + 1);
String str = "niit:"+n+(int)(Math.random()*123*Math.random()*1000);
return str;
}
}
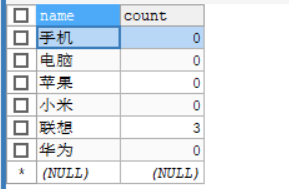
创建Word表
编写SparkStreaming
package com.pmany.streaming
import java.sql.DriverManager
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object Kafka {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KafkaTest")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
//建立检查点
streamingContext.checkpoint("hdfs://niit01:9000/spark/checkpoint")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "niit01:9092",//kafka 端口号
"key.deserializer" -> classOf[StringDeserializer],//key 与value的序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//连接kafka的主题
val topics = Array("test1")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//对kafka,进行处理
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
//对数据进行切分截取出index(5)访问的型号
val rdd1=mapDStream.map(lines=>{
val index=lines._2.split("_")
val keyword=index(5)
(keyword,1)
}
).reduceByKey(_+_)
//对数据进行聚合处理
val addWordFunction = (currentValues:Seq[Int],previousValueState:Option[Int])=>{
val currentCount = currentValues.sum
val previousCount = previousValueState.getOrElse(0)
Some(currentCount+previousCount)
}
val Result = rdd1.updateStateByKey(addWordFunction)
// 打印r
//更新数据库:
Result.foreachRDD(rdd=>{
rdd.foreach(data=>{
val url = "jdbc:mysql:///hadoop?useUnicode=true&characterEncoding=UTF-8"
val user = "root"
val password = "123456"
Class.forName("com.mysql.jdbc.Driver").newInstance()
val conn = DriverManager.getConnection(url, user, password)
val sql="update word set count=? where name=?"
val statement = conn.prepareStatement(sql)
statement.setString(2,data._1.toString)
statement.setInt(1,data._2.toInt)
statement.executeUpdate()
conn.close()
})
})
// 启动
streamingContext.start()
// 等待计算结束
streamingContext.awaitTermination()
}
}
启动测试
启动flume的conf
[root@niit01 kafka]# flume-ng agent -n a1 -c conf -f /training/flume/conf/example.conf -Dflume.root.logger=INFO,console
出现就是启动成功:
启动kafka

[root@niit01 kafka]# bin/kafka-server-start.sh -daemon config/server.properties
运行项目观察数据库的更新: