目录
网络访问层
网络实现的第一层,即网络访问层。该层主要负责在计算机之间传输信息,与网卡的设备驱动程序直接协作。
本次不会讲驱动程序的设计,而是介绍由各个网卡驱动程序提供、由网络实现代码使用的接口,它们提供了硬件的抽象视图。这里根据以太网帧来解释如何在“线上”(on the cable)表示数据,并描述接收到一个分组之后,将该分组传递到更高层之前,需要完成哪些步骤。这里还描述了与之相反的步骤,即分组产生之后,通过网络接口离开计算机之前,要执行的步骤。
网络设备的表示
在内核中,每个网络设备都表示为net_device 结构的一个实例。在分配并填充该结构的一个实例之后,必须用net/core/dev.c 中的register_netdev 函数将其注册到内核。该函数完成一些初始化任务,并将该设备注册到通用设备机制内。
数据结构
这些设备不是全局的,而是按命名空间进行管理的。每个命名空间(net 实例)中有如下3个机制可用。
- 所有的网络设备都保存在一个单链表中,表头为dev_base 。
- 按设备名散列。辅助函数dev_get_by_name(struct net *net, const char * name) 根据设备名在该散列表上查找网络设备。
- 按接口索引散列。辅助函数dev_get_by_index(struct net * net, int ifindex) 根据给定的接口索引查找net_device 实例。
//<netdevice.h>
struct net_device
{
char name[IFNAMSIZ];
/* 设备名散列链表的链表元素 */
struct hlist_node name_hlist;
/* I/O相关字段 */
unsigned long mem_end; /* 共享内存结束位置 */
unsigned long mem_start; /* 共享内存起始位置 */
unsigned long base_addr; /* 设备I/O地址 */unsigned int irq; /* 设备IRQ编号 */
unsigned long state;
struct list_head dev_list;
int (*init)(struct net_device *dev);
/* 接口索引。唯一的设备标识符*/
int ifindex;
struct net_device_stats* (*get_stats)(struct net_device *dev);
/* 硬件首部描述 */
const struct header_ops *header_ops;
unsigned short flags; /* 接口标志(按BSD方式)
*/
unsigned mtu; /* 接口MTU值
*/
unsigned short type; /* 接口硬件类型
*/
unsigned short hard_header_len; /* 硬件首部长度
*/
/* 接口地址信息。 */
unsigned char perm_addr[MAX_ADDR_LEN]; /* 持久硬件地址
*/
unsigned char addr_len; /* 硬件地址长度
*/
int promiscuity;
/* 协议相关指针 */
void *atalk_ptr; /* AppleTalk相关指针
*/
void *ip_ptr; /* IPv4相关数据
*/
void *dn_ptr; /* DECnet相关数据
*/
void *ip6_ptr; /* IPv6相关数据
*/
void *ec_ptr; /* Econet相关数据
*/
unsigned long last_rx; /* 上一次接收操作的时间
*/
unsigned long trans_start; /* 上一次发送操作的时间
(以jiffies为单位) *//* eth_type_trans()所用的接口地址信息 */
unsigned char dev_addr[MAX_ADDR_LEN]; /* 硬件地址,(在bcast成员之前,因为大多数分组都是单播) */
unsigned char broadcast[MAX_ADDR_LEN]; /* 硬件多播地址
*/
int (*hard_start_xmit) (struct sk_buff *skb,
struct net_device *dev);
/* 在设备与网络断开后调用*/
void (*uninit)(struct net_device *dev);
/* 在最后一个用户引用消失后调用*/
void (*destructor)(struct net_device *dev);
/* 指向接口服务例程的指针 */
int (*open)(struct net_device *dev);
int (*stop)(struct net_device *dev);
void (*set_multicast_list)(struct net_device *dev);
int (*set_mac_address)(struct net_device *dev, void *addr);
int (*do_ioctl)(struct net_device *dev,
struct ifreq *ifr, int cmd);
int (*set_config)(struct net_device *dev, struct ifmap *map);
int (*change_mtu)(struct net_device *dev, int new_mtu);
void (*tx_timeout) (struct net_device *dev);
int (*neigh_setup)(struct net_device *dev,
struct neigh_parms *);
/* 该设备所在的网络命名空间 */
struct net *nd_net;
/* class/net/name项 */
struct device dev;
... 网络设备的名称存储在name 中。它是一个字符串,末尾的数字用于区分同一类型的多个适配器(如系统有两个以太网卡)。例如,在使用ifconfig 设置参数时,会使用网卡的符号名。
在内核中,每个网卡都有唯一索引号,在注册时动态分配保存在ifindex 成员中。回想前文,我们知道内核提供了dev_get_by_name 和dev_get_by_index 函数,用于根据网卡的名称或索引号来查找其net_device 实例。
一些结构成员定义了与网络层和网络访问层相关的设备属性。
- mtu (maximum transfer unit,最大传输单位 )指定一个传输帧的最大长度。网络层的协议必须遵守该值的限制,可能需要将分组拆分为更小的单位。
- type 保存设备的硬件类型,它使用的是<if_arp.h> 中定义的常数。例如,ARPHRD_ETHER 和ARPHDR_IEEE802 分别表示10兆以太网和802.2以太网,ARPHRD_APPLETLK 表示AppleTalk,而ARPHRD_LOOPBACK 表示环回设备。
- dev_addr 存储设备的硬件地址(如以太网卡的MAC地址),而addr_len 指定该地址的长度。broadcast 是用于向附接的所有站点发送消息的广播地址。
- ip_ptr 、ip6_ptr 、atalk_ptr 等指针指向特定于协议的数据,通用代码不会操作这些数据。
net_device 结构的大多数成员都是函数指针,执行与网卡相关的典型任务。尽管不同适配器的实现各有不同,但调用的语法(和执行的任务)总是相同的。因而这些成员表示了与下一个协议层次的抽象接口。这些接口使得内核能够用同一组接口函数来访问所有的网卡,而网卡的驱动程序负责实现细节。在这里我就不一一介绍了。
注册网络设备
每个网络设备都按照如下过程注册。
- alloc_netdev 分配一个新的struct net_device 实例,一个特定于协议的函数用典型值填充该结构。
- 在struct net_device 填充完毕后,需要用register_netdev 或register_netdevice 注册。在设备注册时,内核会选择一个唯一的数字来代替%d 。例如,以太网设备可以指定eth%d ,而内核随后会创建设备eth0 、eth1 ……下图为register_netdevice流程图。
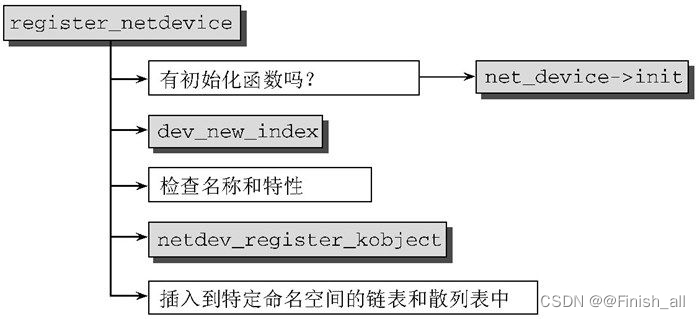
如果net_device->init 提供了特定于设备的初始化函数,那么内核在进一步处理之前,将先调用该函数。由dev_new_index 生成在所属命名空间中唯一标识该设备的接口索引。该索引保存在net_device->ifindex 中。netdev_register_kobject 将新设备添加到通用内核对象模型中。该函数还会创建sysfs项。最后,该设备集成到特定命名空间的链表中,以及以设备名和接口索引为散列键的两个散列表中。
接收分组
分组到达内核的时间是不可预测的。所有现代的设备驱动程序都使用中断来通知内核(或系统)有分组到达。网络驱动程序对特定于设备的中断设置了一个处理例程,因此每当该中断被引发时(即分组到达),内核都调用该处理程序,将数据从网卡传输到物理内存,或通知内核在一定时间后进行处理。几乎所有的网卡都支持DMA模式,能够自行将数据传输到物理内存。但这些数据仍然需要解释和处理,这在稍后进行。
传统方法
物理传输速度没那么高,一般采用传统方法。下图为分组穿透内核的路径。
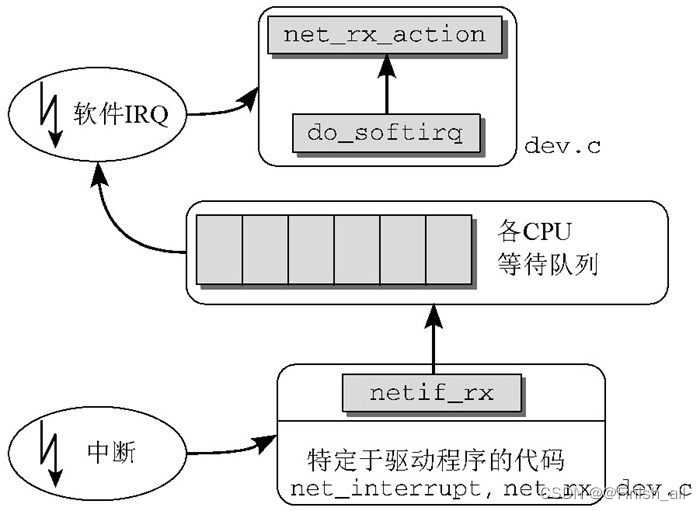
因为分组是在中断上下文中接收到的,所以处理例程只能执行一些基本的任务,避免系统(或当前CPU)的其他任务延迟太长时间。在中断上下文中,数据由3个短函数1处理,执行了下列任务。
- net_interrupt 是由设备驱动程序设置的中断处理程序。它将确定该中断是否真的是由接收到的分组引发的(也存在其他的可能性,例如,报告错误或确认某些适配器执行的传输任务)。如果确实如此,则控制将转移到net_rx 。
- net_rx 函数也是特定于网卡的,首先创建一个新的套接字缓冲区。分组的内容接下来从网卡传输到缓冲区(也就是进入了物理内存),然后使用内核源代码中针对各种传输类型的库函数来分析首部数据。这项分析将确定分组数据所使用的网络层协议,例如IP协议。
- 与上述两个方法不同,netif_rx 函数不是特定于网络驱动程序的,该函数位于net/core/dev.c。调用该函数,标志着控制由特定于网卡的代码转移到了网络层的通用接口部分。
为提高多处理器系统的性能,对每个CPU都会创建等待队列,支持分组的并行处理。不使用显式的锁机制来保护等待队列免受并发访问,因为每个CPU都只修改自身的队列,不会干扰其他CPU的工作。
net_rx_action 用作该软中断的处理程序。
如下图所示:
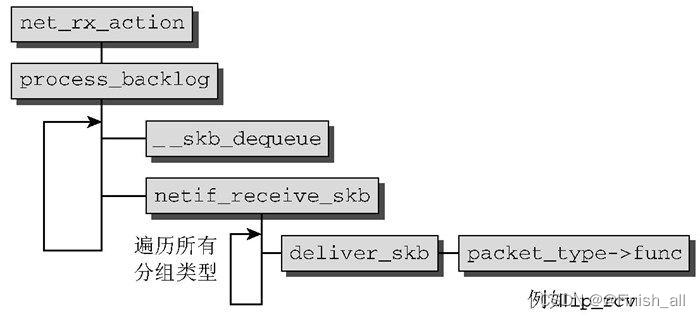
在一些准备任务之后,工作转移到process_backlog ,该函数在循环中执行下列步骤。为简化描述,假定循环一直进行,直至所有的待决分组都处理完成,不会被其他情况中断。
- __skb_dequeue 从等待队列移除一个套接字缓冲区,该缓冲区管理着一个接收到的分组。
- 由netif_receive_skb 函数分析分组类型,以便根据分组类型将分组传递给网络层的接收函数(即传递到网络系统的更高一层)。为此,该函数遍历所有可能负责当前分组类型的所有网络层函数,一一调用deliver_skb 。
接下来deliver_skb 函数使用一个特定于分组类型的处理程序func ,承担对分组的更高层(例如互联网络层)的处理。netif_receive_skb 也处理诸如桥接之类的专门特性,但讨论这些边角情况是不必要的,至少在平均水准的系统中,此类特性都属于边缘情况。所有用于从底层的网络访问层接收数据的网络层函数都注册在一个散列表中,通过全局数组ptype_base 实现。
新的协议通过dev_add_pack 增加。各个数组项的类型为struct packet_type ,定义如下:
struct packet_type {
__be16 type; /* 这实际上是htons(ether_type)的值。 */
struct net_device *dev; /* NULL在这里表示通配符 */
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *);
...
void *af_packet_priv;
struct list_head list;
};type 指定了协议的标识符,处理程序会使用该标识符。dev 将一个协议处理程序绑定到特定的网卡(NULL 指针表示该处理程序对系统中所有网络设备都有效)。func 是该结构的主要成员。它是一个指向网络层函数的指针,如果分组的类型适当,将其传递给该函数。其中一个处理程序就是ip_rcv ,用于基于IPv4的协议。netif_receive_skb 对给定的套接字缓冲区查找适当的处理程序,并调用其func 函数,将处理分组的职责委托给网络层,这是网络实现中更高的一层。
对高速接口的支持
如果设备不支持过高的传输率,那么此前讨论的旧式方法可以很好地将分组从网络设备传输到内核的更高层。每次一个以太网帧到达时,都使用一个IRQ来通知内核。这里暗含着“快”和“慢”的概念。 对低速设备来说,在下一个分组到达之前,IRQ的处理通常已经结束。由于下一个分组也通过IRQ通知,如果前一个分组的IRQ尚未处理完成,则会导致问题,高速设备通常就是这样。现代以太网卡的运作高达10 000 Mbit/s,如果使用旧式方法来驱动此类设备,将造成所谓的“中断风暴”。如果在分组等待处理时接收到新的IRQ,内核不会收到新的信息:在分组进入处理过程之前,内核是可以接收IRQ的,在分组的处理结束后,内核也可以接收IRQ,这些不过是“旧闻”而已。为解决该问题,NAPI使用了IRQ和轮询的组合。
假定某个网络适配器此前没有分组到达,但从现在开始,分组将以高频率频繁到达。这就是NAPI设备的情况,如下所述。
- 第一个分组将导致网络适配器发出IRQ。为防止进一步的分组导致发出更多的IRQ,驱动程序会关闭该适配器的Rx IRQ。并将该适配器放置到一个轮询表上。
- 只要适配器上还有分组需要处理,内核就一直对轮询表上的设备进行轮询。
- 重新启用Rx中断。
如果在新的分组到达时,旧的分组仍然处于处理过程中,工作不会因额外的中断而减速。虽然对设备驱动程序(和一般意义上的内核代码)来说轮询通常是一个很差的方法,但在这里该方法没有什么不利之处:在没有分组还需要处理时,将停止轮询,设备将回复到通常的IRQ驱动的运行方式。在没有中断支持的情况下,轮询空的接收队列将不必要地浪费时间,但NAPI并非如此。
NAPI的另一个优点是可以高效地丢弃分组。如果内核确信因为有很多其他工作需要处理,而导致无法处理任何新的分组,那么网络适配器可以直接丢弃分组,无须复制到内核。
只有设备满足如下两个条件时,才能实现NAPI方法。
- 设备必须能够保留多个接收的分组,例如保存到DMA环形缓冲区中。下文将该缓冲区称为Rx缓冲区。
- 该设备必须能够禁用用于分组接收的IRQ。而且,发送分组或其他可能通过IRQ进行的操作,都仍然必须是启用的。
如果系统中有多个设备,会怎么样呢?这是通过循环轮询各个设备来解决的。下图NAPI机制和循环轮询表概览,概述了这种情况。
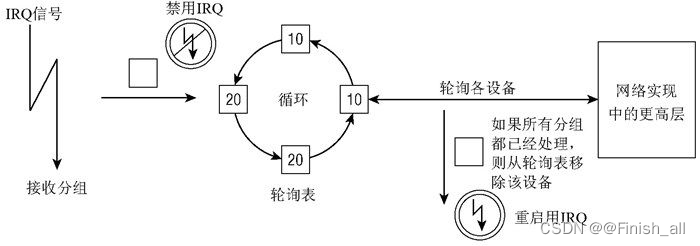
如果一个分组到达一个空的Rx缓冲区,则将相应的设备置于轮询表中。由于链表本身的性质,轮询表可以包含多个设备。
内核以循环方式处理链表上的所有设备:内核依次轮询各个设备,如果已经花费了一定的时间来处理某个设备,则选择下一个设备进行处理。此外,某个设备都带有一个相对权重,表示与轮询表中其他设备相比,该设备的相对重要性。较快的设备权重较大,较慢的设备权重较小。由于权重指定了在一个轮询的循环中处理多少分组,这确保了内核将更多地注意速度较快的设备。
发送分组
在网络层中特定于协议的函数通知网络访问层处理由套接字缓冲区定义的一个分组时,将发送完成的分组。
当信息从计算机发送出去时,必须注意哪些事项?除了特定协议需要完成的首部和校验和,以及由高层协议实例生成的数据之外,分组的路由是最重要的。(即使计算机只有一个网卡,内核仍然需要区分发送到外部目标的分组和针对环回接口的分组。)
因为该问题只能由更高层的协议实例决定(特别是,如果可以选择到预期目标的路由时),所以设备驱动程序假定高层协议已经做出了决策。因为该问题只能由更高层的协议实例决定(特别是,如果可以选择到预期目标的路由时),所以设备驱动程序假定高层协议已经做出了决策。
在分组可以发送到下一个正确的计算机之前(通常不同于目标计算机,因为除非存在直接的硬件链路,否则IP分组通常通过网关发送),必须确定接收方网卡的硬件地址。这是一个复杂的过程。此时,我们假定已经知道接收方的MAC地址。网络访问层的所需的另一个首部,通常由特定于协议的函数产生。
net/core/dev.c 中的dev_queue_xmit 用于将分组放置到发出分组的队列上。这里将忽略这个特定于设备的队列的实现,因为它并没有揭示什么网络层的运作机制。只要知道,在分组放置到等待队列上一定的时间之后,分组将发出即可。这是通过特定于适配器的函数hard_start_xmit 完成的,在每个net_device 结构中都以函数指针的形式出现,由硬件设备驱动程序实现。