1. ESMM
ESMM的全称是Entire Space Multi-task Model (ESMM),是阿里巴巴算法团队提出的多任务训练方法。其在信息检索、推荐系统、在线广告投放系统的CTR、CVR预估中广泛使用。以电商推荐系统为例,最大化场景商品交易总额(GMV)是平台的重要目标之一,而GMV可以拆解为流量×点击率×转化率×客单价,因此转化率是优化目标的重要因子之一; 从用户体验的角度来说转换率可以用来平衡用户的点击偏好与购买偏好。
传统的CVR预估任务,其存在如下问题:
- 样本选择偏差: 构建的训练样本集的分布采样与实际数据分布存在偏差;
- 稀疏数据: 点击样本占曝光样本的比例很小
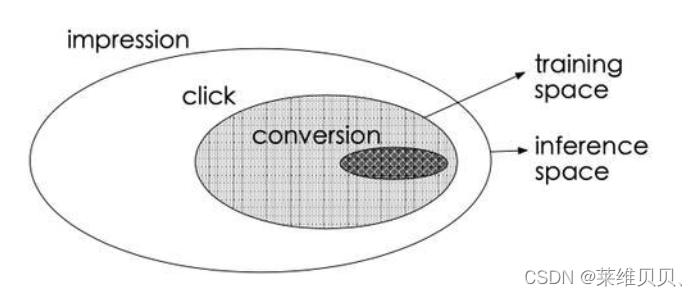
1.2 ESMM原理
ESMM模型利用用户行为序列数据在完整样本空间建模,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。另一方面,ESMM模型首次提出了利用学习CTR和CTCVR的辅助任务迂回学习CVR的思路
1.2.1 ESMM模型框架
CTR = 实际点击次数 / 展示量
CVR = 转化数 / 点击量
CTCVR = 转换数 / 曝光量。是预测item被点击,然后被转化的概率。
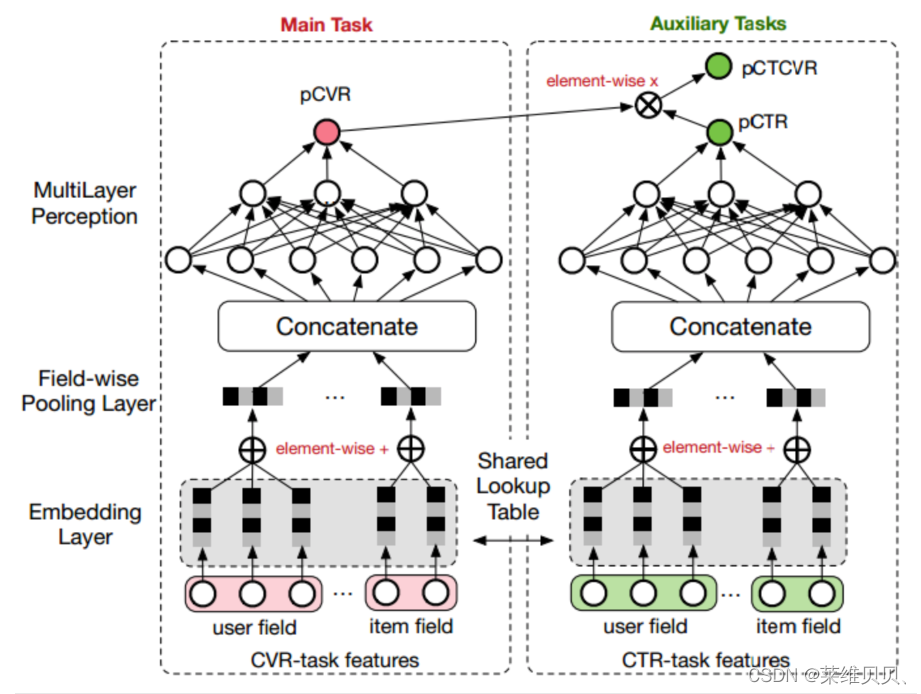
ESMM模型由两个子网络组成:
- 左边的子网络用来拟合pCVR
- 右边的子网络用来拟合pCTR,同时,两个子网络的输出相乘之后可以得到pCTCVR。因此,该网络结构共有三个子任务,分别用于输出pCTR、pCVR和pCTCVR。
其中x表示曝光,y表示点击,z表示转化
注意:
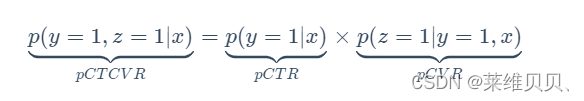
- 共享Embedding。 CVR-task和CTR-task使用相同的特征和特征embedding,即两者从Concatenate之后才学习各自独享的参数;
- 隐式学习pCVR。 这里pCVR 仅是网络中的一个variable,没有显示的监督信号。
CTCVR和CTR的label构造损失函数:
解决样本选择偏差: 在训练过程中,模型只需要预测pCTCVR和pCTR,即可更新参数,由于pCTCVR和pCTR的数据是基于完整样本空间提取的,故根据公式,可以解决pCVR的样本选择偏差。
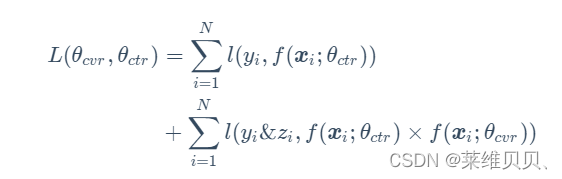
解决数据稀疏: 使用共享的embedding层,使得CVR子任务也能够从只展示没点击的样本中学习,可以缓解训练数据稀疏的问题。
1.3 ESMM模型的优化
- 模型优化:论文中,子任务独立的Tower网络是纯MLP模型,可以根据自身特点设置不一样的模型,例如使用DeepFM、DIN等
- 学习优化:引入动态加权的学习机制,优化loss
- 特征优化:可构建更长的序列依赖模型,例如美团AITM信用卡业务,用户转换过程是曝光->点击->申请->核卡->激活
1.4 ESMM代码
import torch
import torch.nn.functional as F
from torch_rechub.basic.layers import MLP, EmbeddingLayer
from tqdm import tqdm
class ESMM(torch.nn.Module):
def __init__(self, user_features, item_features, cvr_params, ctr_params):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.embedding = EmbeddingLayer(user_features + item_features