目录
一、按关键字排序查询
1、单字段排序
使用 select 语句可以将需要的数据从 mysql 数据库中查询出来,如果对查询的结果进行排序操作,可以使用 order by 语句完成排序,并且最终将排序后的结果返回给客户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
格式:select 字段1,字段2,…… from 表名 order by 字段 asc|desc;
#其中asc|desc
#asc:是按照升序进行排名的,是默认的排序方式,即asc可以省略
#desc:是按照降序的方式进行排序的
#当然 order by 前也可以使用 where 子句对查询结果进一步过滤部署环境:新建表,并插入表数据,方便进行查询
#登录mysql数据库
[root@localhost ~]#mysql -uroot -p123456
#进入cxc数据库
use cxc;
#新建表
create table info (id char(3) not null,name varchar(15) not null primary key,score decimal(4,2),address varchar(50) not null,hobbid char(3) not null);
#插入点表数据,来进行查询
insert into AAA values (1,'cxc','66','江苏南京',5);
insert into AAA values (2,'xyk','97','江苏徐州',3);
insert into AAA values (3,'xw','82','江苏泰州',2);
insert into AAA values (4,'jjg','45','江苏无锡',3);
insert into AAA values (5,'jhw','77','江苏宿迁',2);
insert into AAA values (6,'wjh','92','江苏南京',1);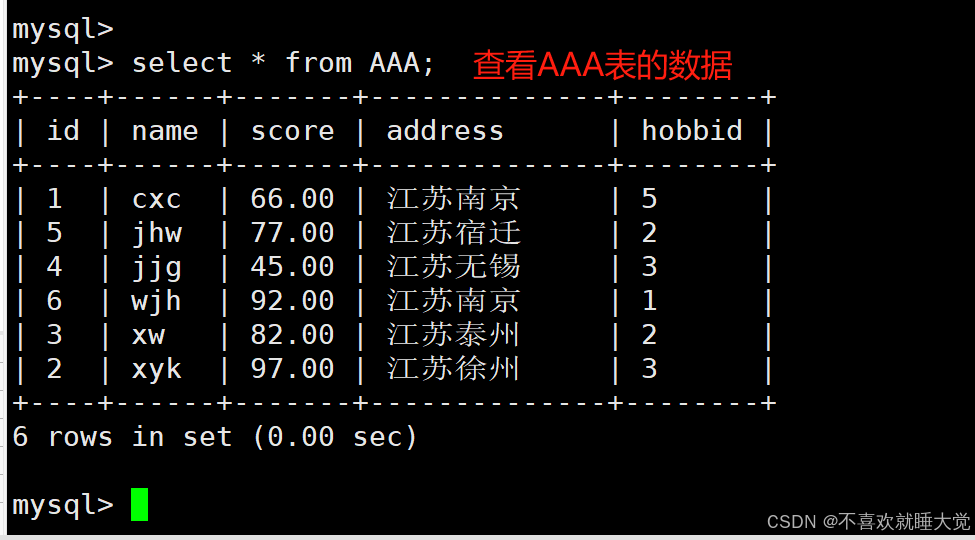
1.1、按某个字段升序排序
格式:select 字段1,字段2,…… from 表名 order by 字段 asc;
#asc:是按照升序进行排名的,是默认的排序方式,即asc可以省略例如:
select name,score from AAA order by score asc;
//按照分数升序排序,显示name和score的字段值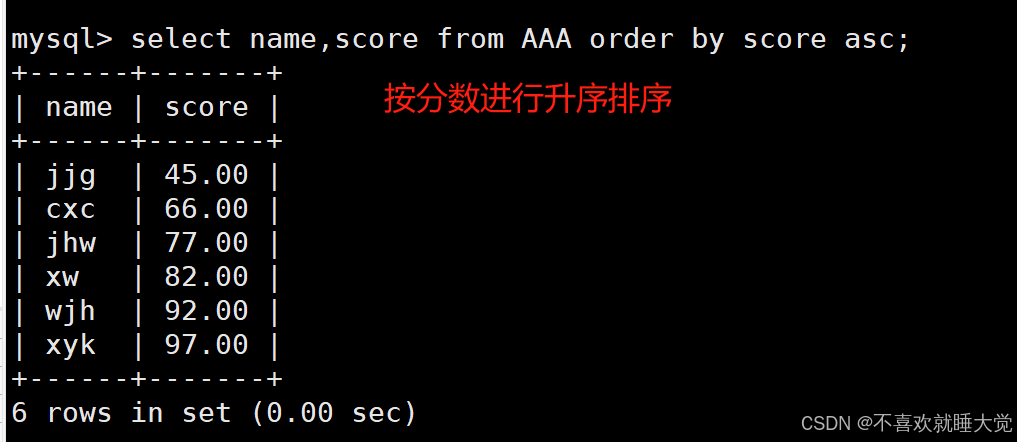
1.2、按某个字段升序降序
格式:select 字段1,字段2,…… from 表名 order by 字段 desc;
//desc:是按照降序的方式进行排序的例如:
select name,score from AAA order by score desc;
//按照分数降序排序,显示name和score的字段值
1.3、结合where进行条件过滤
select name,score,address from AAA where address='江苏南京' order by score;
//筛选地址为“江苏南京”的行数据,并按成绩进行升序排序,显示id,name、address字段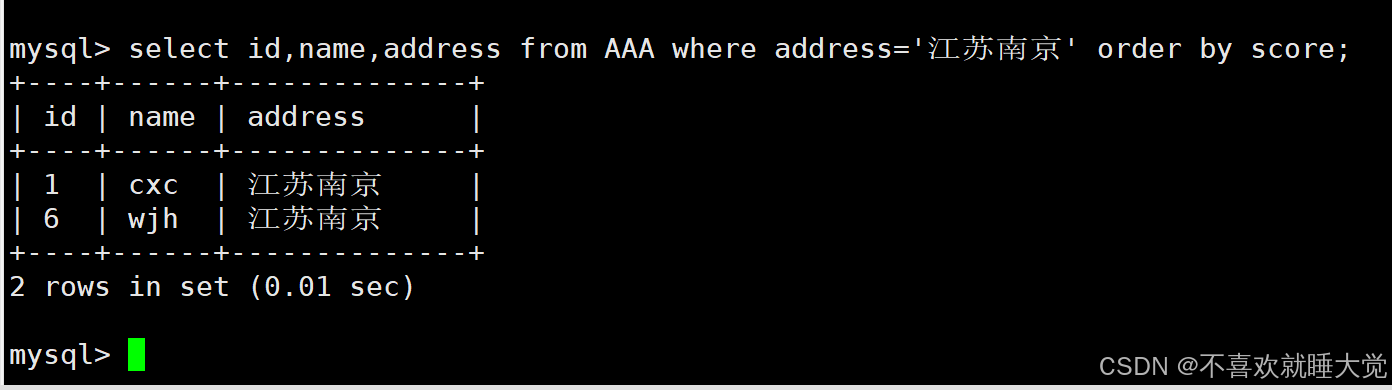
select name,score,hobbid from AAA where hobbid=3 order by score desc;
#筛选hobbid为3的行数据,并按成绩进行降序排序,显示name、score、hobbid字段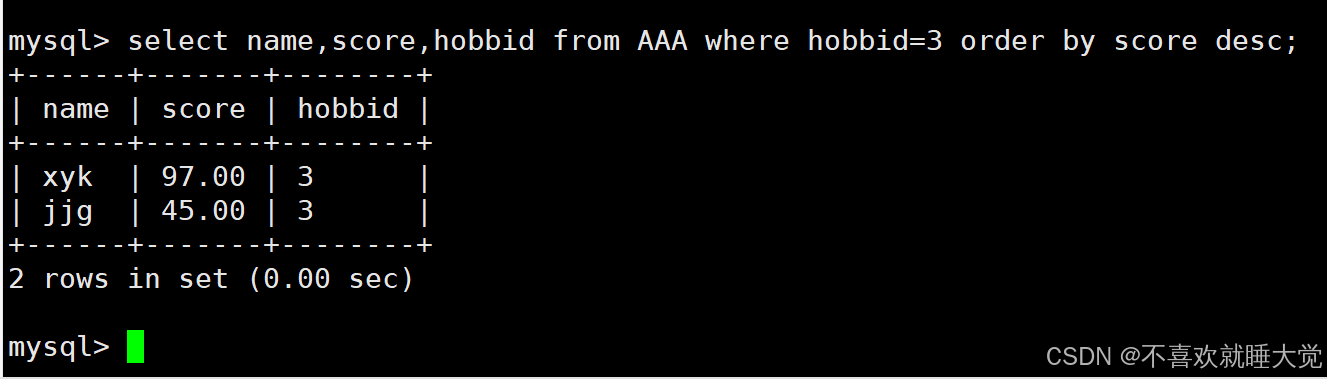
2、多字段排序
order by 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,order by 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定,但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义。
2.1、按多字段升序排序
格式:select 字段1,字段2,…… from 表名 order by 字段1 asc,字段2 asc,……;
#asc:是按照升序进行排名的,是默认的排序方式,即asc可以省略
#order by之后的第一个参数只有在出现相同值时,第二个字段才有意义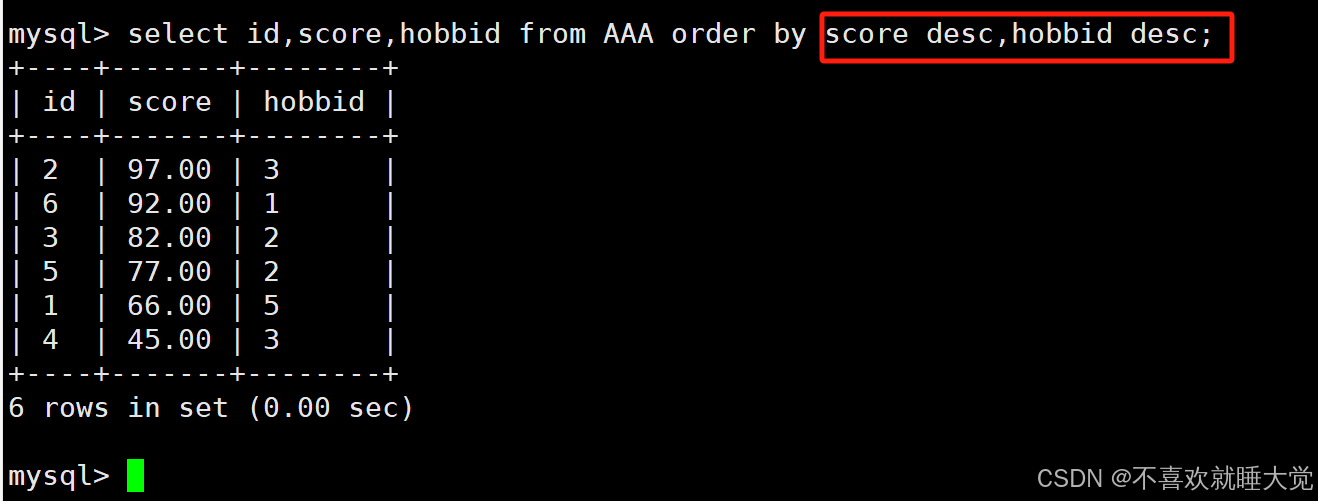
2.2、按多字段降序排序
格式:select 字段1,字段2,…… from 表名 order by 字段1 desc,字段2 desc,……;
#desc:是按照降序的方式进行排序的
#order by之后的第一个参数只有在出现相同值时,第二个字段才有意义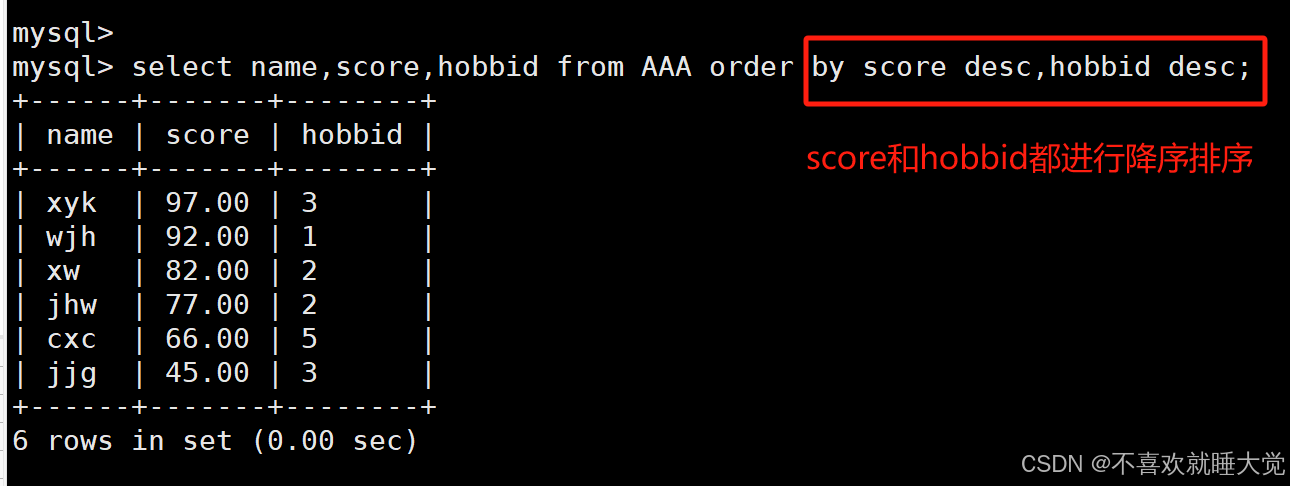
3、区间判断及查询不重复记录
3.1、区间判断
AND/OR:且/或的使用
格式:select 字段 from 表名 where 条件判断1 and/or 条件判断2例如:
#筛选分数大于70且分数小于等于95的记录
select * from AAA where score > 70 and score <= 95;
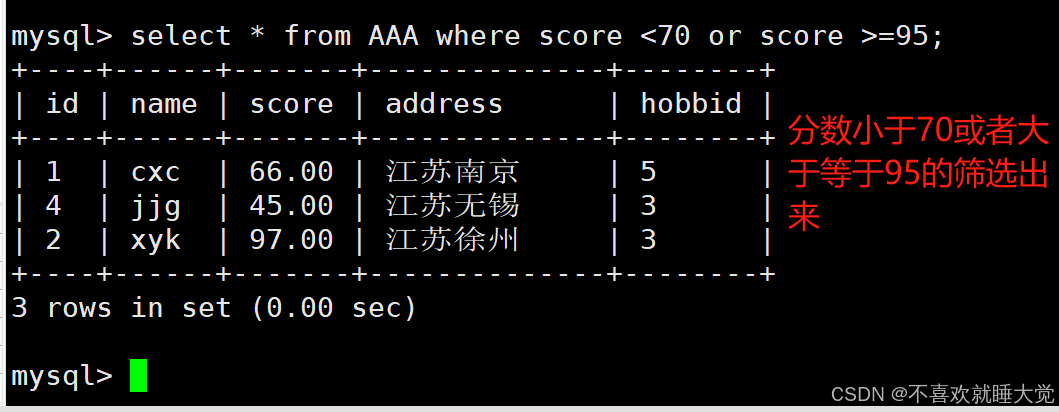
#筛选分数小于70,或者分数大于等于95的记录
select * from AAA where score < 70 or score >= 95;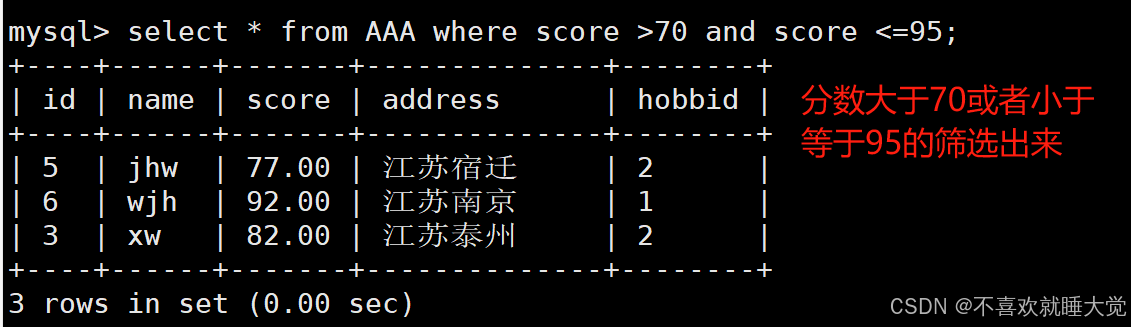
AND/OR嵌套使用
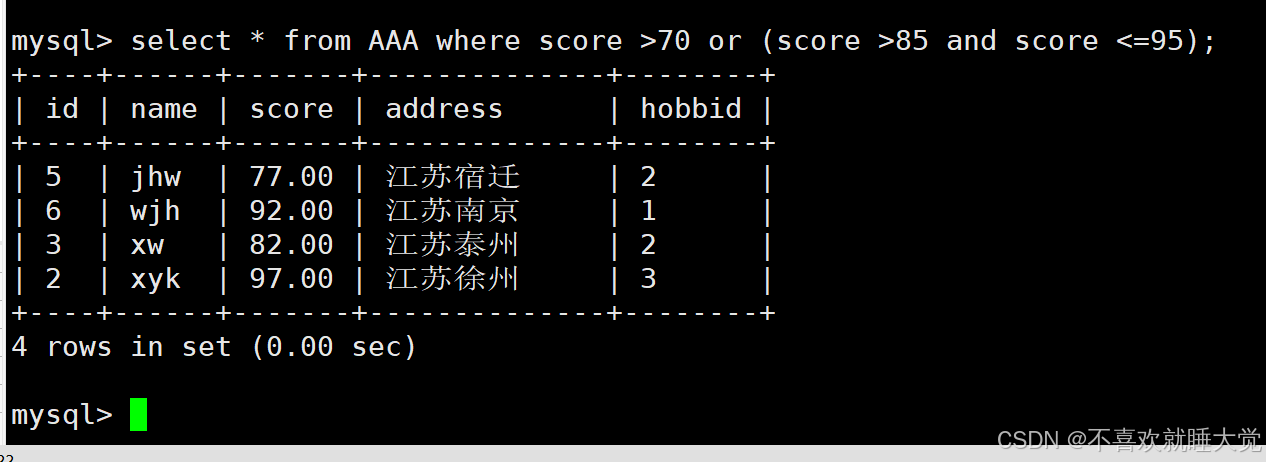
#筛选分数大于80,或者分数大于等于85且分数小于95的记录
select * from AAA where score > 80 or (score >= 85 and score < 95);
3.2、查询不重复记录
格式:select distinct 字段 from 表名﹔
#distinct:必须放在最开头
#distinct:只能使用需要去重的字段进行操作
#distinct:去重多个字段时,几个字段同时重复时才能被过滤,会默认按左边第一个字段为依据例如:
#去除hobbid字段重复的值
select distinct hobbid from AAA;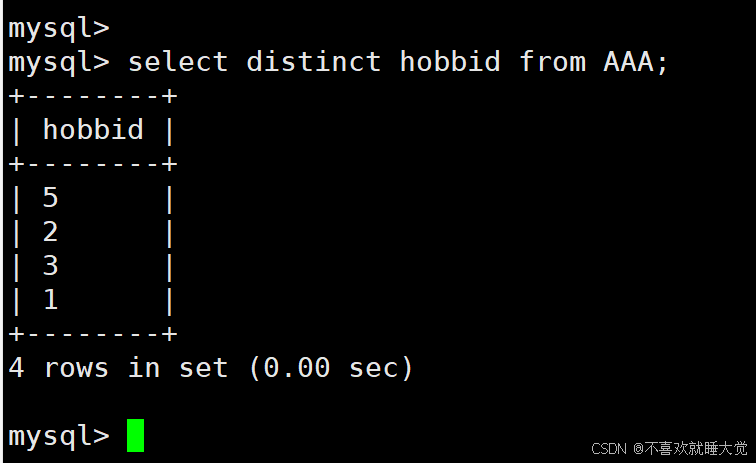
二、对结果进行分组查询
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
格式:select 字段1, 聚合函数(字段2) from 表名 (where 字段名 (匹配) 数值) group by 字段1;1、count聚合函数
案例一
按hobbid相同的分组,计算相同分数的学生个数(基于name个数进行计数)
select count(name),hobbid from AAA group by hobbid;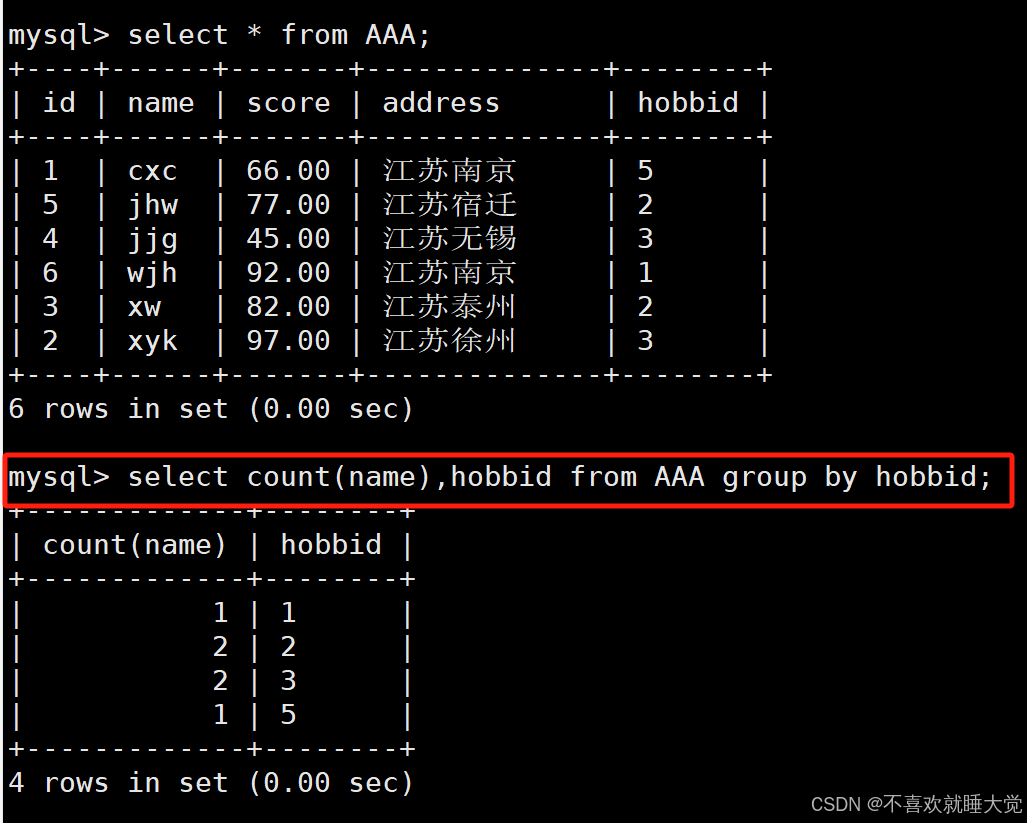
案例二
结合where语句,筛选分数大于等于80的分组,计算学生个数
#结合where,筛选分数大于等于80的分组,并计算各组学生的个数
select count(name),score from AAA where score >=80 group by score;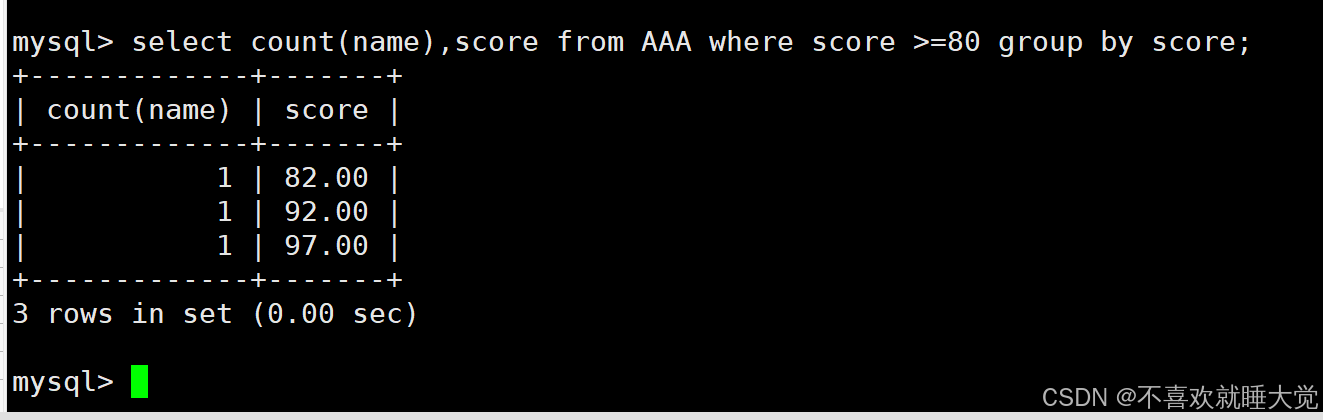
案例三
结合order by把计算出的学生个数按升序排列
#结合order by,筛选分数大于等于80的分组,并计算各组学生的个数,并且按学生个数升序排序
select count(name),score from AAA where score >=80 group by score oprder by count(name);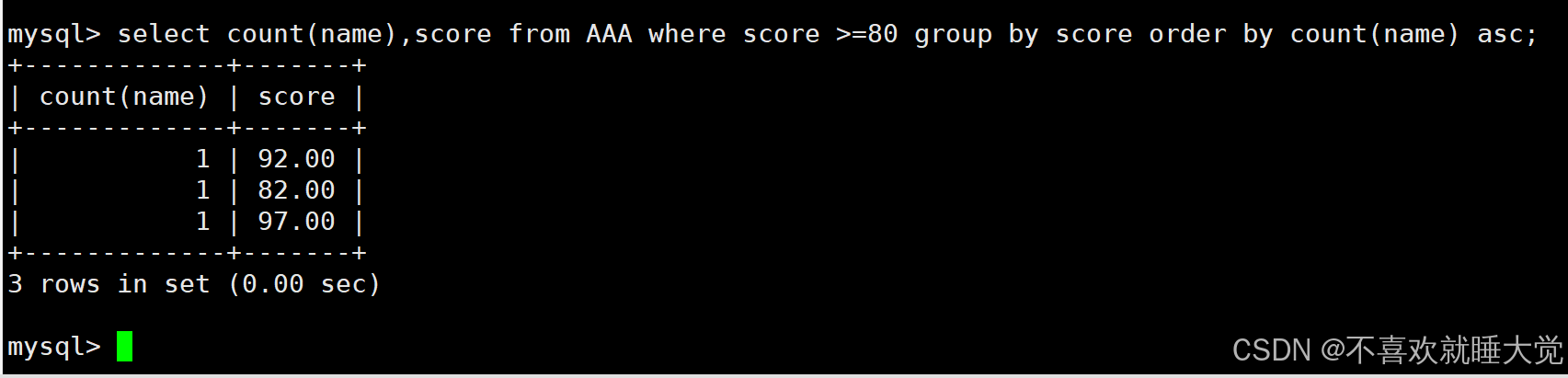
三、限制结果条目(limit)
- limit 限制输出的结果记录
- 在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
1、查询前n行记录
案例一:查询前4行记录
select * from AAA limit 4;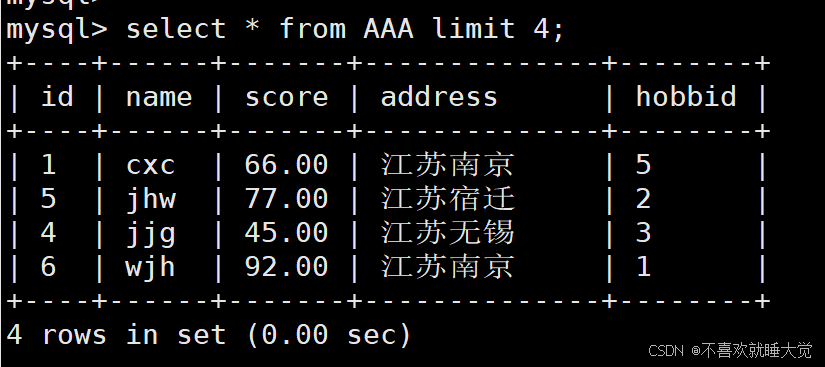
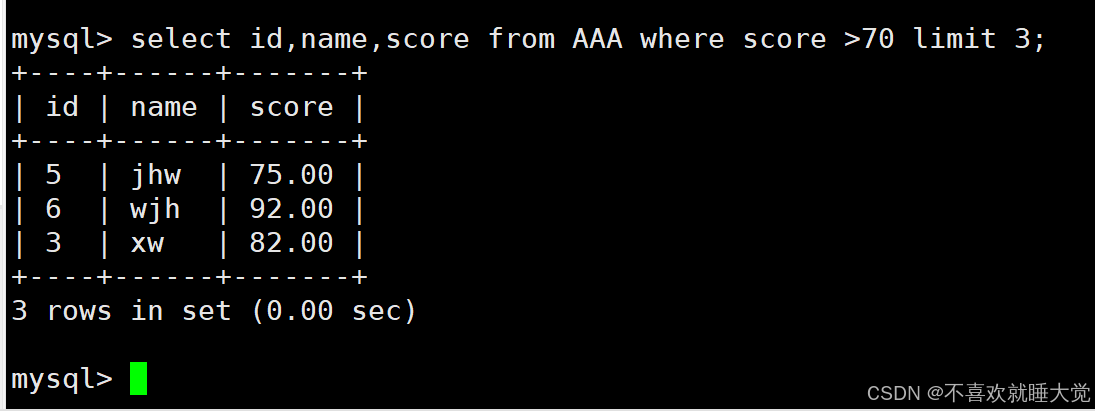
案例二:查询前3行,分数大于70的记录,显示id、name、score列
select id,name,score from AAA where score >70 limit 3;
2、查询前n行后m行记录
案例一:查询前3行后的2行记录
select * from AAA limit 3,2;
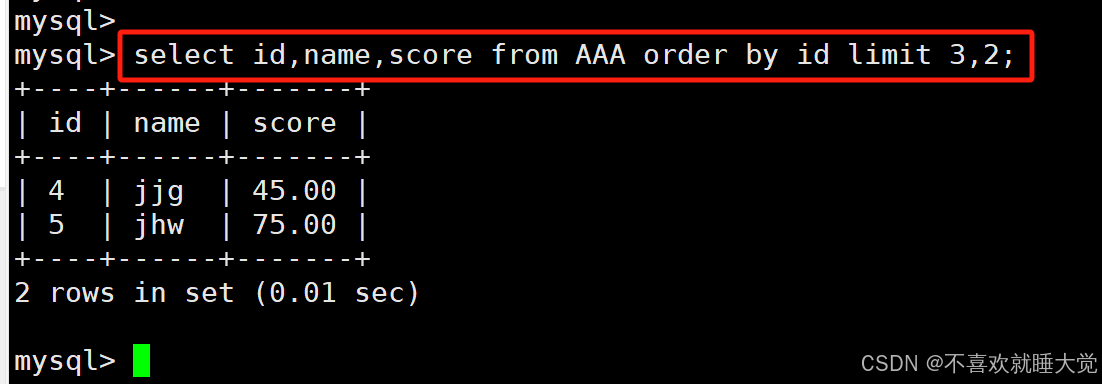
案例二:按id升序排序,查询前三行后两行记录,显示id、name、score列
select id,name,score from AAA order by id limit 3,2;
3、查询某个单独行的记录
#查询第一行记录
select * from info limit 1;
#查询第四行记录
select * from info limit 3,1;
#查询第五行记录
select * from info limit 4,1;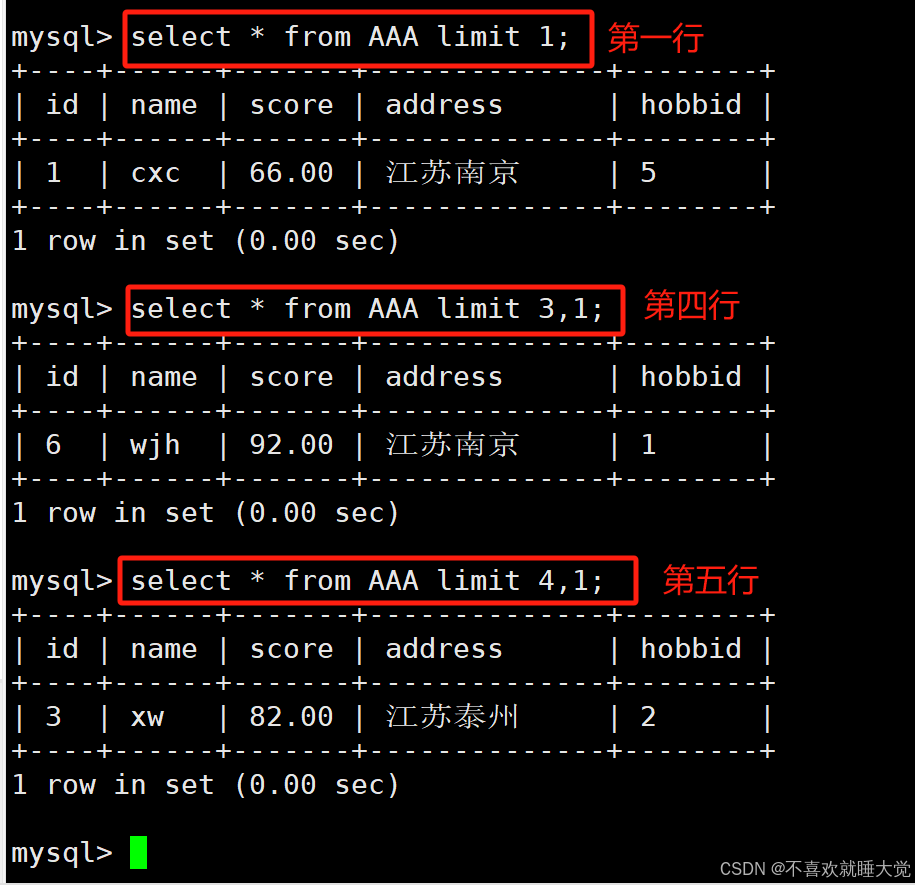
四、设置别名alias
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者 多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性
1、设置字段的别名
select 字段名 as 字段别名 from 表名;
#在使用 as 后,可以用 字段别名 代替 字段名,其中 as 语句是可选的。as 之后的别名,主要是为表内的列提供临时的名称,在查询过程中使用,库内实际的字段名是不会被改变的案例一: 查询整个表共有多少条数据,以number字段显示
select count(*) as number from AAA;
select count(*) number from AAA;
#加不加as都能设置字段别名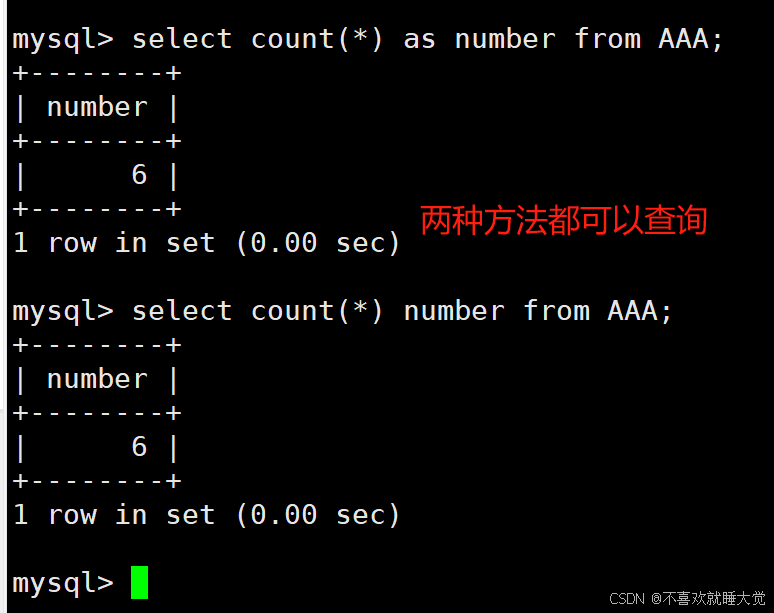
案例二:为查询结果的字段设置别名
select name 姓名,score 成绩,address 地址 from AAA;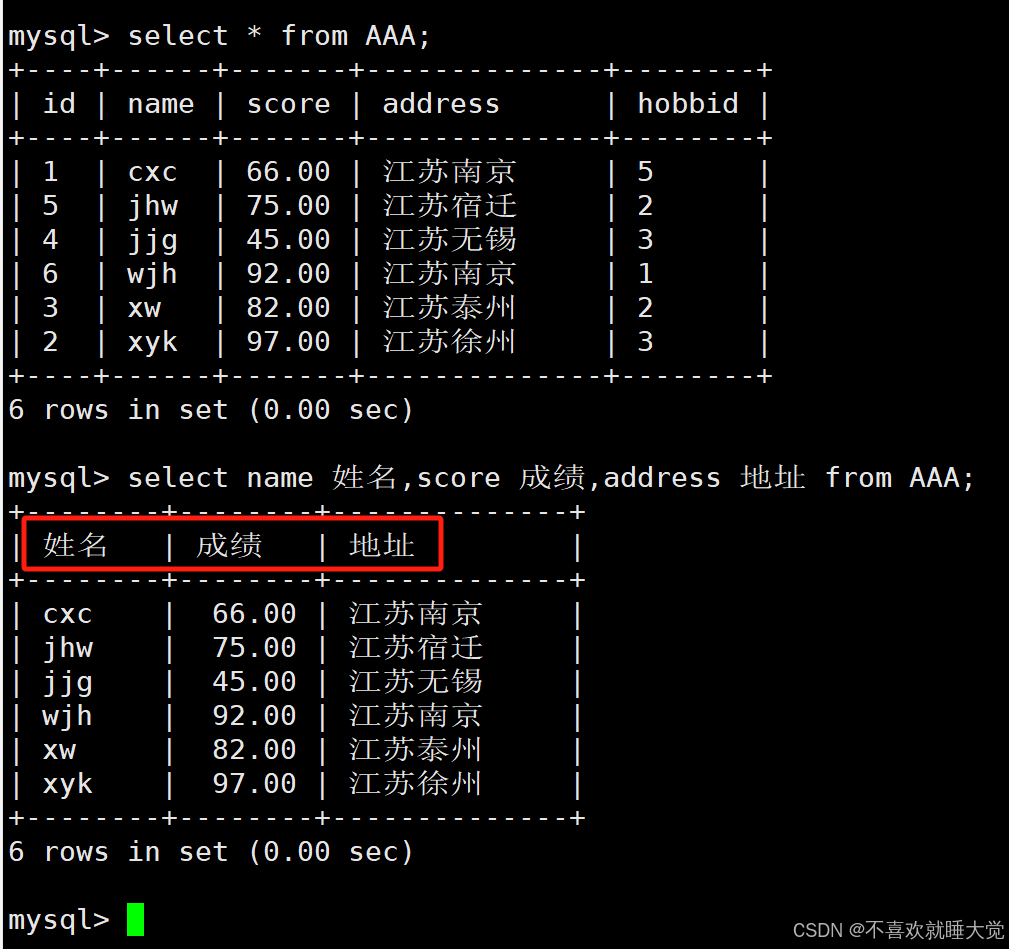
2、设置表的别名
select 字段 from 表名 as 表别名;
//在使用 as 后,可以用 表别名 代替 表名,其中 as 语句是可选的。as 之后的别名,主要是为表提供临时的名称,在查询过程中使用,库内实际的表名是不会被改变的select i.name 姓名,i.score 成绩,i.address 地址 from info as i;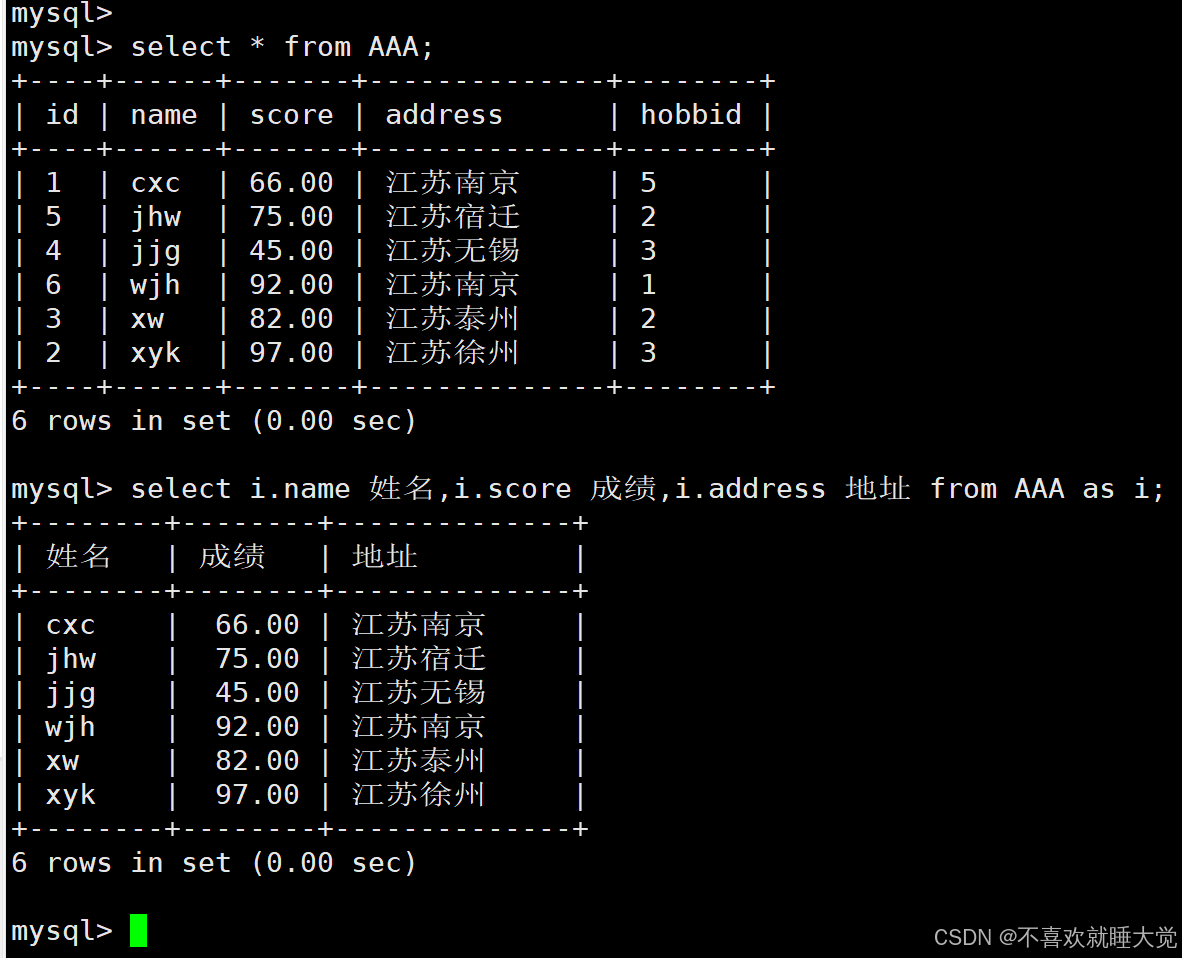
3、as作为连接语句的操作符
create table info2 as select * from info;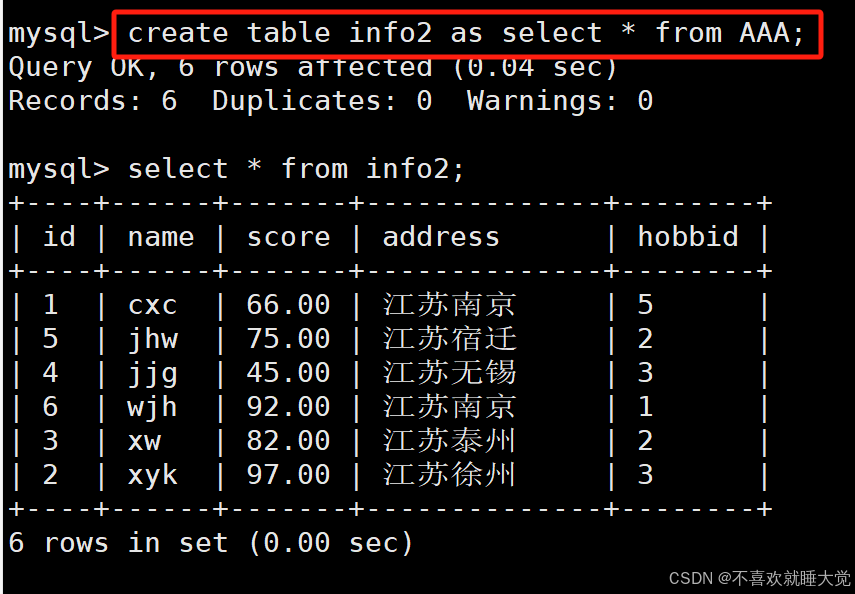
注:
此处AS起到的作用:
1、创建了一个新表info2并定义表结构,插入表数据(与info表相同)
2、但是”约束“没有被完全”复制“过来,但是如果原表设置了主键,那么附表的default字段会默认设置一个0
相似:和克隆、复制表结构相似 create table t1 (select * from info);
结合where语句来进行判断
create table info3 as select * from AAA where score >=70;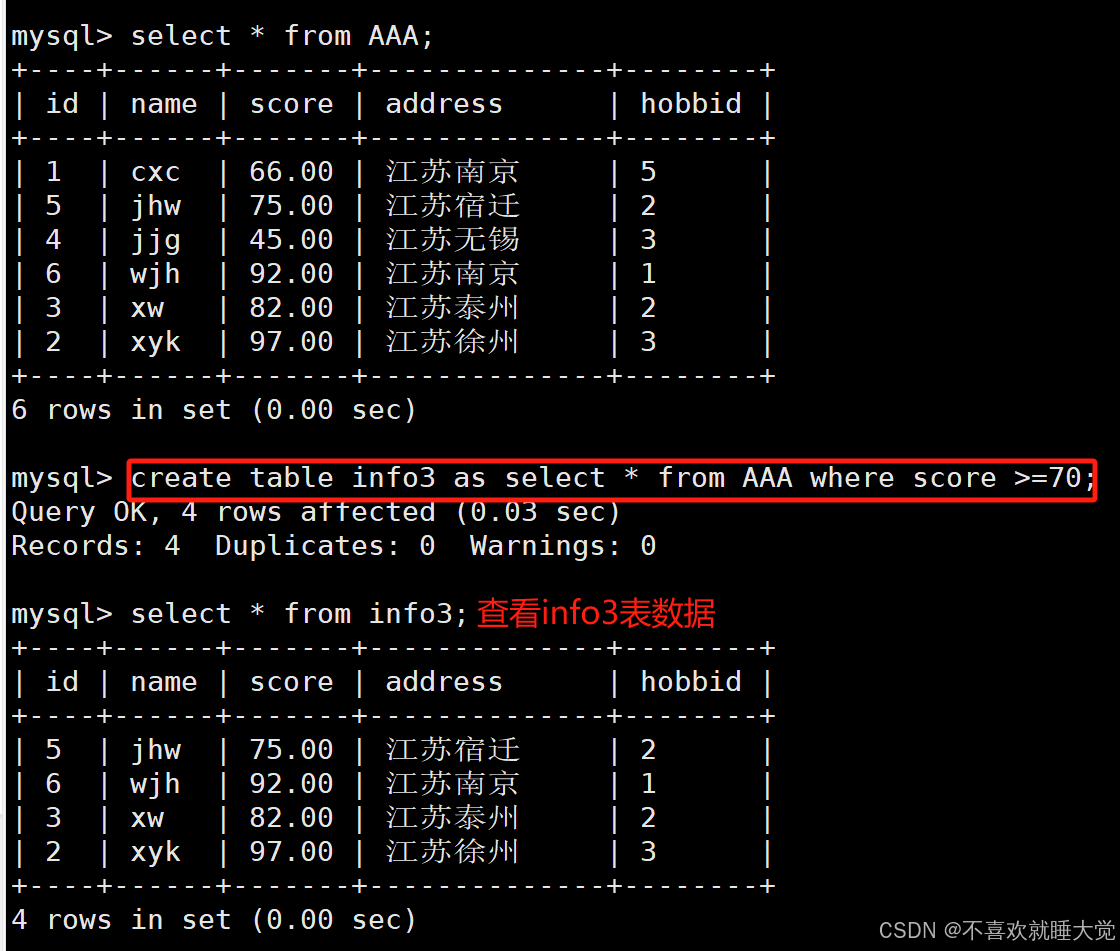
注:
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突
列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用
五、通配符like
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通常通配符都是跟 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
- %:百分号表示零个、一个或多个字符 *
- _:下划线表示单个字符
1、查询名字是c开头的记录
select 字段 from 表名 where 字段 like ‘确定字符%’;select id,name,score from AAA where name like 'c%';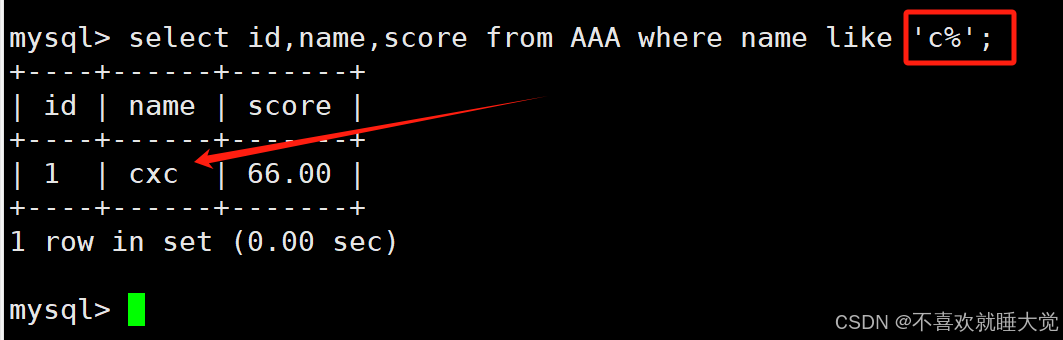
select id,name,score from AAA where name like 'x__';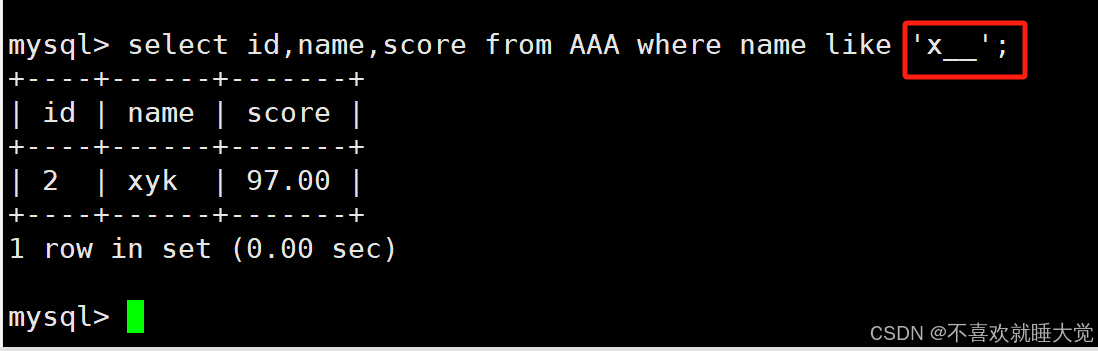
2、查询以某字符结尾的记录
select 字段 from 表名 where 字段 like ‘%确定字符’;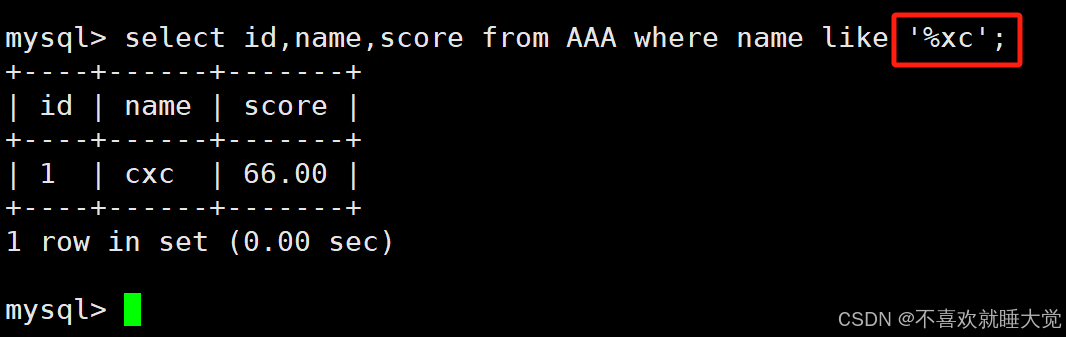
3、查询只要有某字符的记录
select 字段 from 表名 where 字段 like ‘%确定字符%’;select id,name,score from AAA where name like '%x%';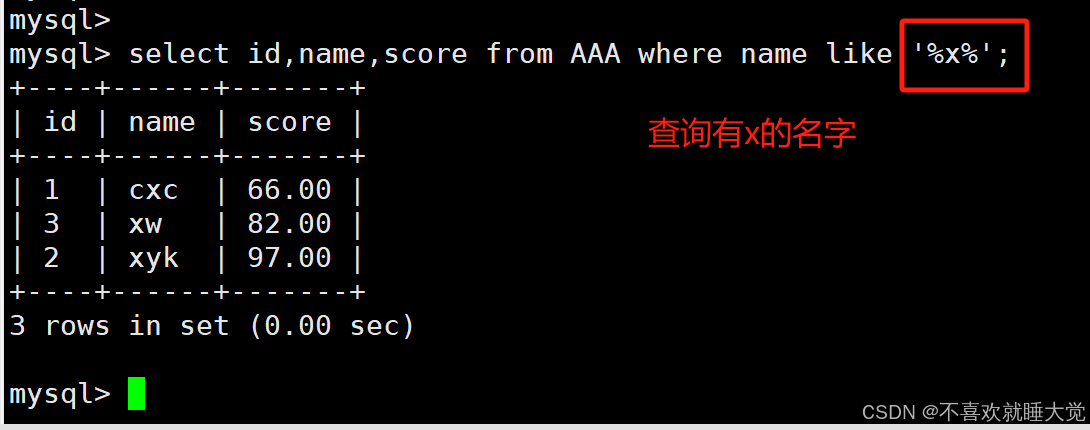
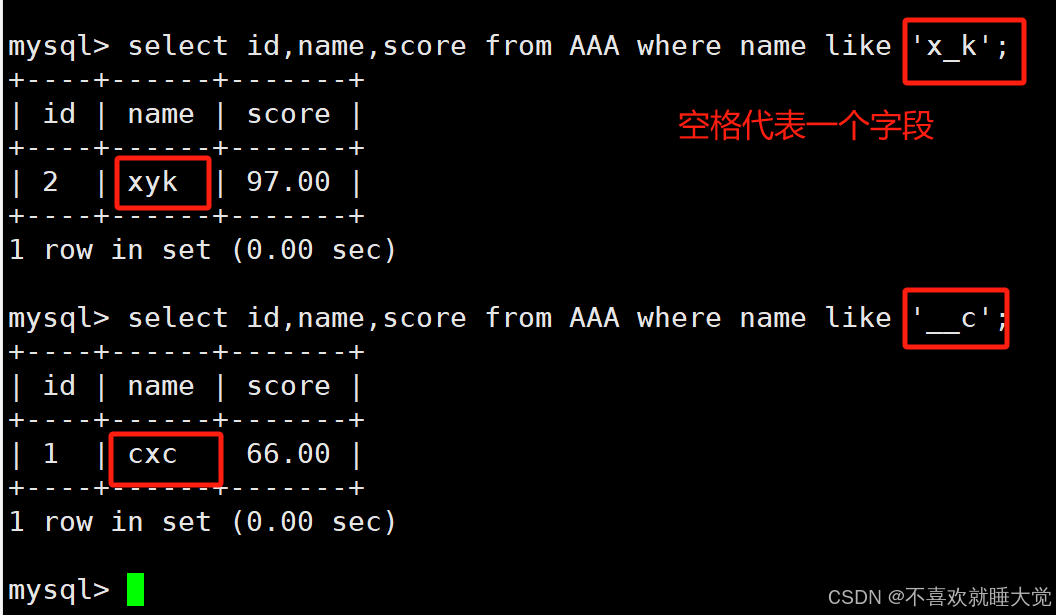
4、查询具体到任意单个字符的记录
select 字段 from 表名 where 字段 like ‘字符_字符__字符’;mysql> select id,name,score from AAA where name like 'x_k';
mysql> select id,name,score from AAA where name like '__c';
六、子查询
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语 句。子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一 步的查询过滤。
IN操作符概念
允许在where子句中指定一个值列表,然后从表中选择列值与这个列表中任何一个值相匹配的行。简而言之,IN可以在单个查询中对多个值进行条件匹配
也用来判断某个值是否在给定的结果集中,通常结合子查询来使用
<表达式> [not] in <子查询>
#当表达式与子查询返回的结果集中的某个值相等时,返回 true,否则返回 false
#若启用了 not 关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对
#多数情况下,子查询都是与 select 语句一起使用的1、select
1.1、单表查询
select name,score from AAA where id in (select id from AAA where score >80);
#主语句:select name,score from info where id;
#子语句(集合):select id from info where score >80;
#子语句中的sql语句是为了最后过滤出一个结果集,用于主语句的判断条件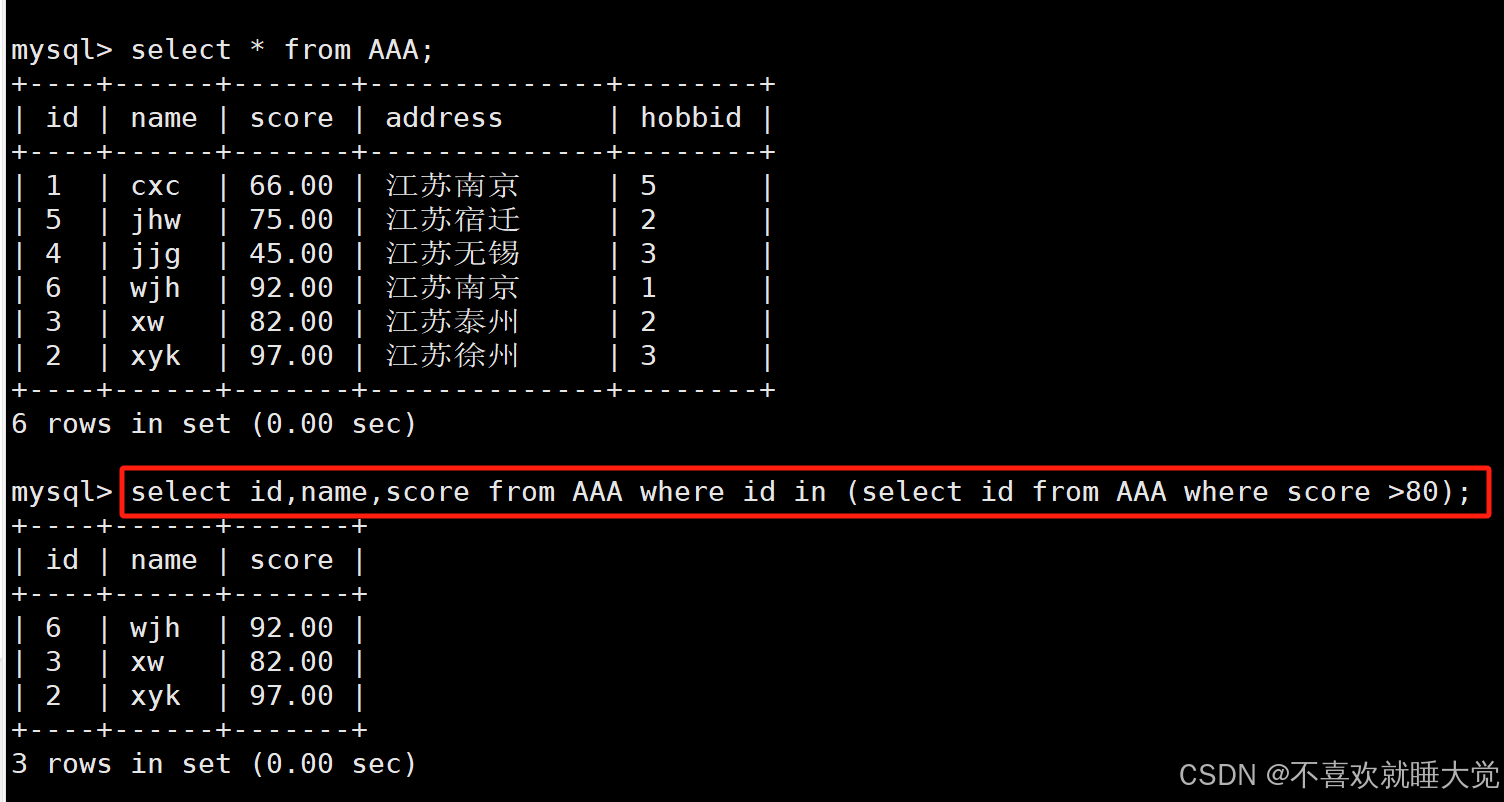
1.2、多表查询
select id,name,score from AAA where id in (select id from test);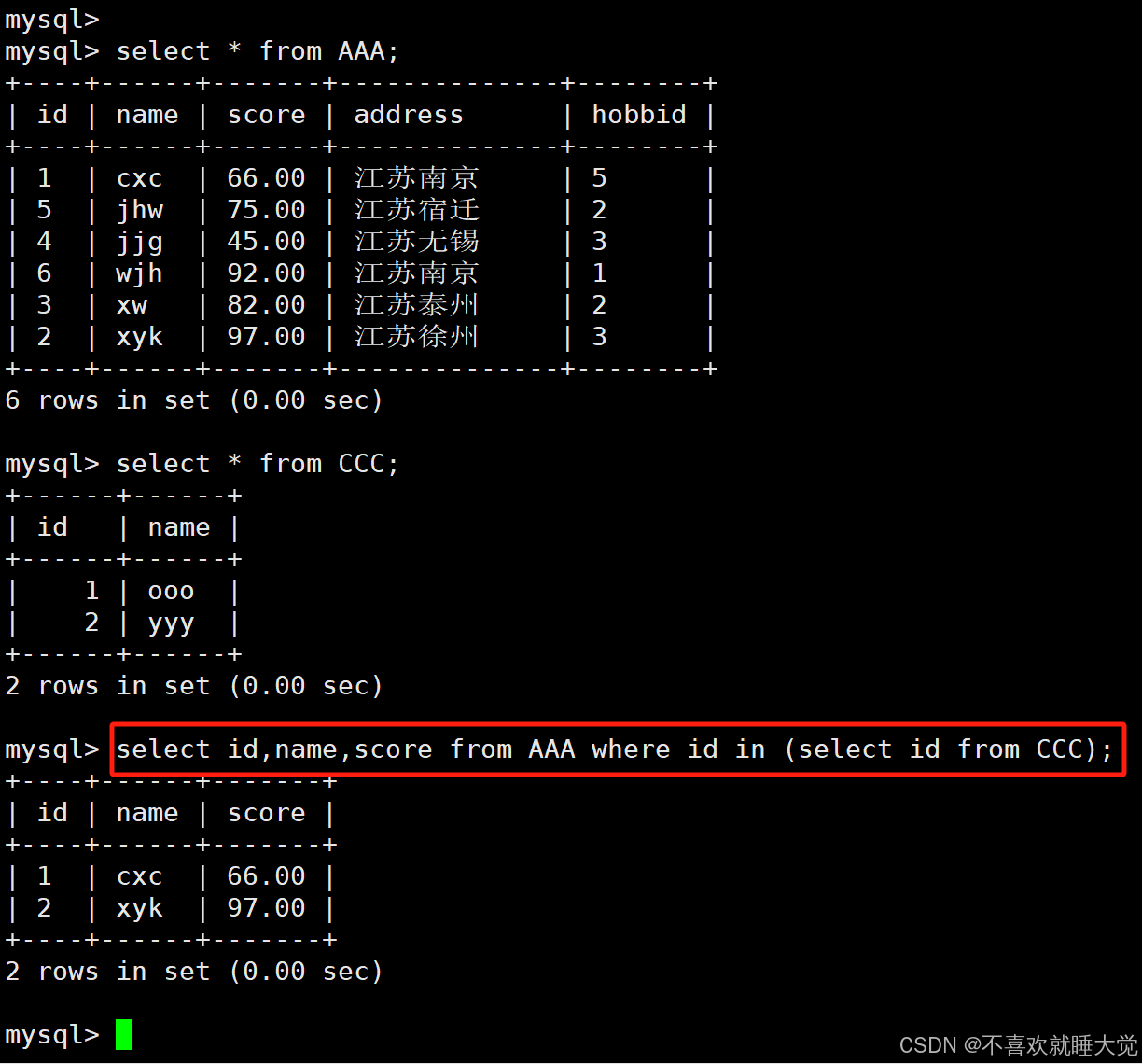
1.3、将子语句的结果取反not
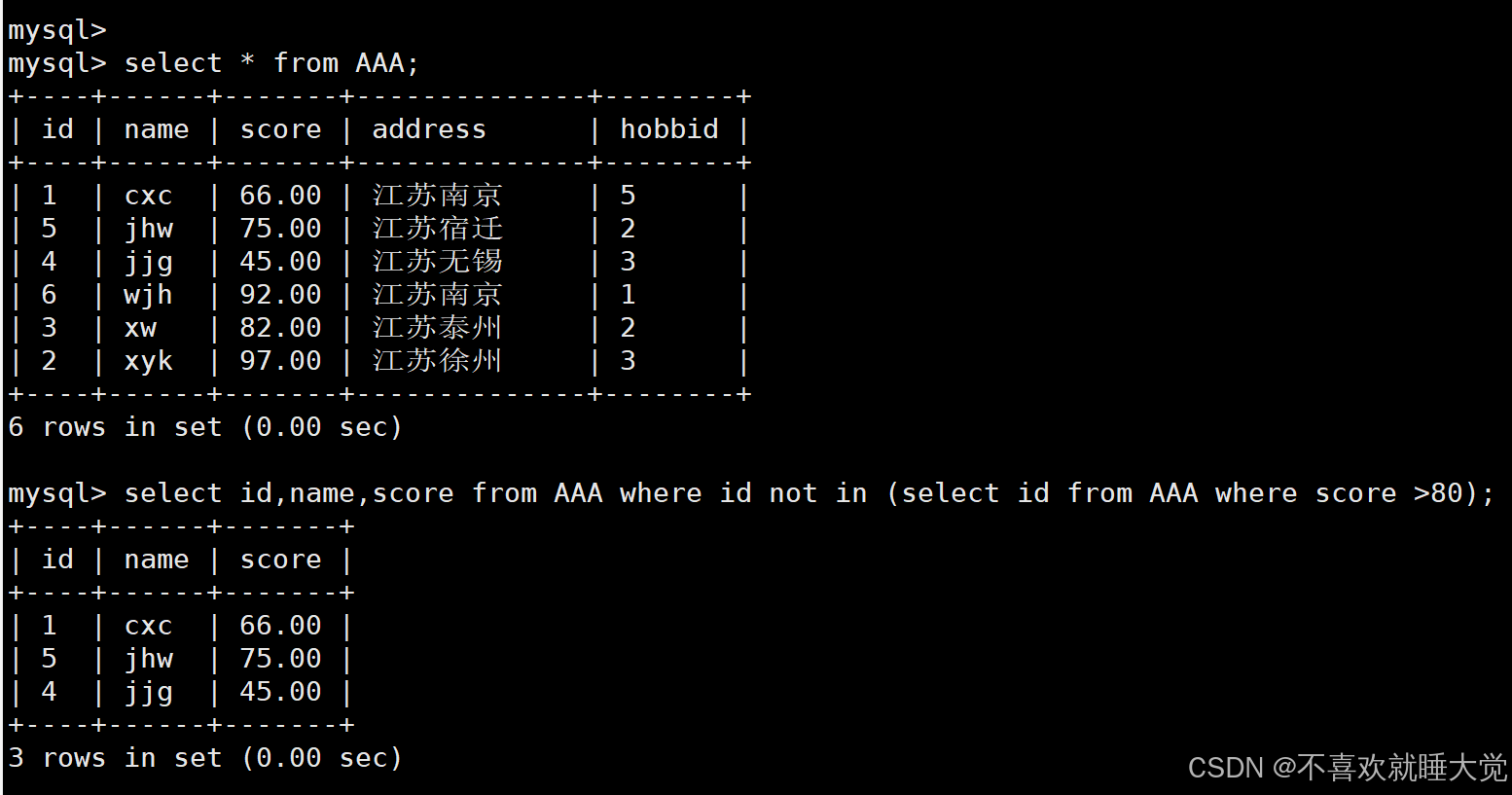
select id,name,score from AAA where id not in (select id from AAA where score >80);
2、insert
子查询还可以用在insert语句中,子查询的结果集可以通过insert语句插入到其它表中
insert into class select * from AAA where id in (select id from test);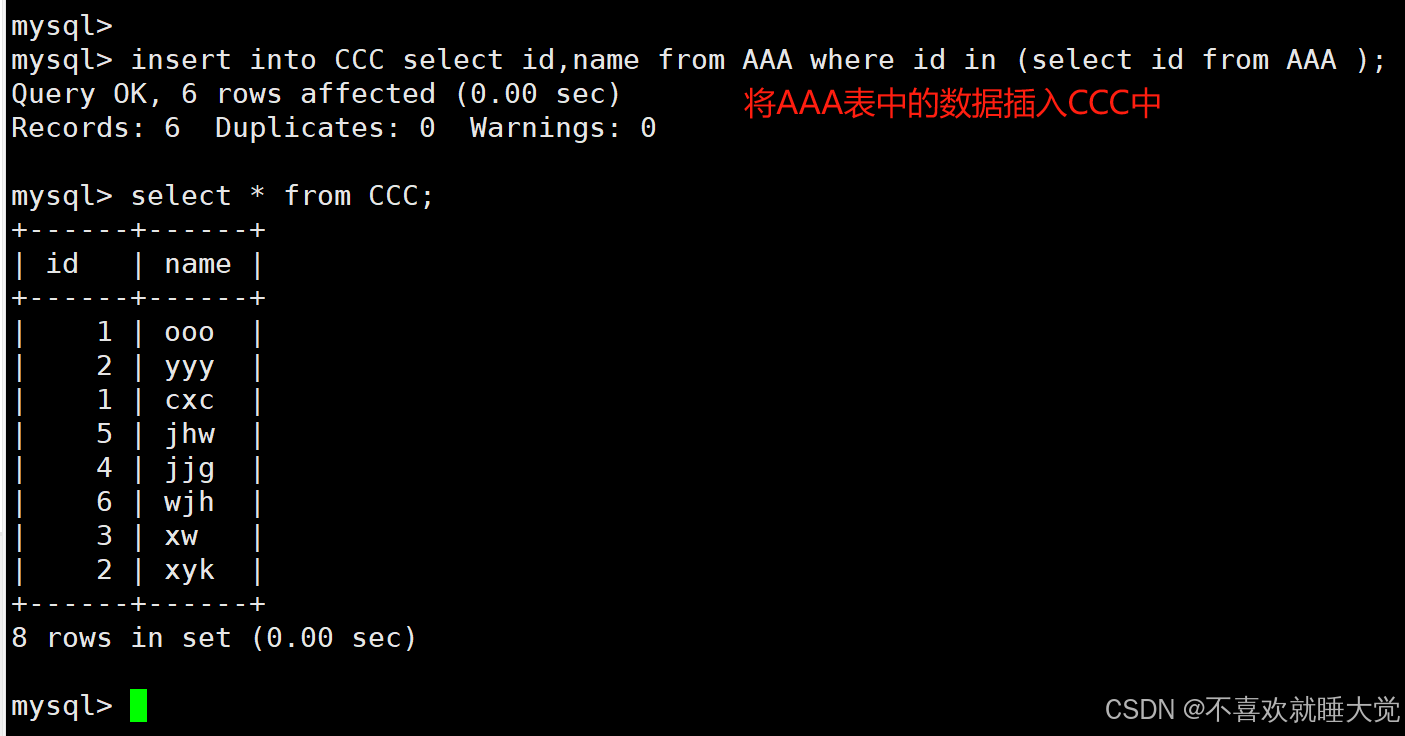
3、update
update语句也可以使用子查询,update内的子查询,在set更新内容时,可以是单独的一行一列,也可以是多行单列
#更新单行单列数据
update info set score=100 where id in (select id from AAA where id=2);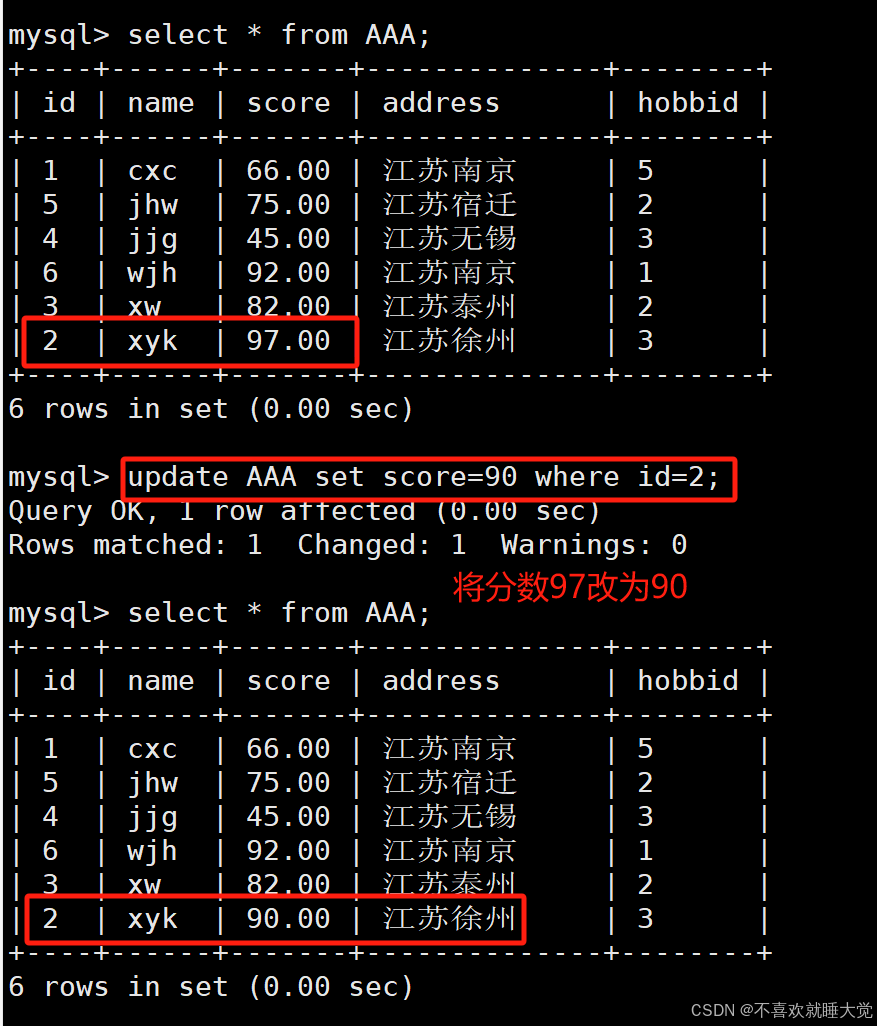
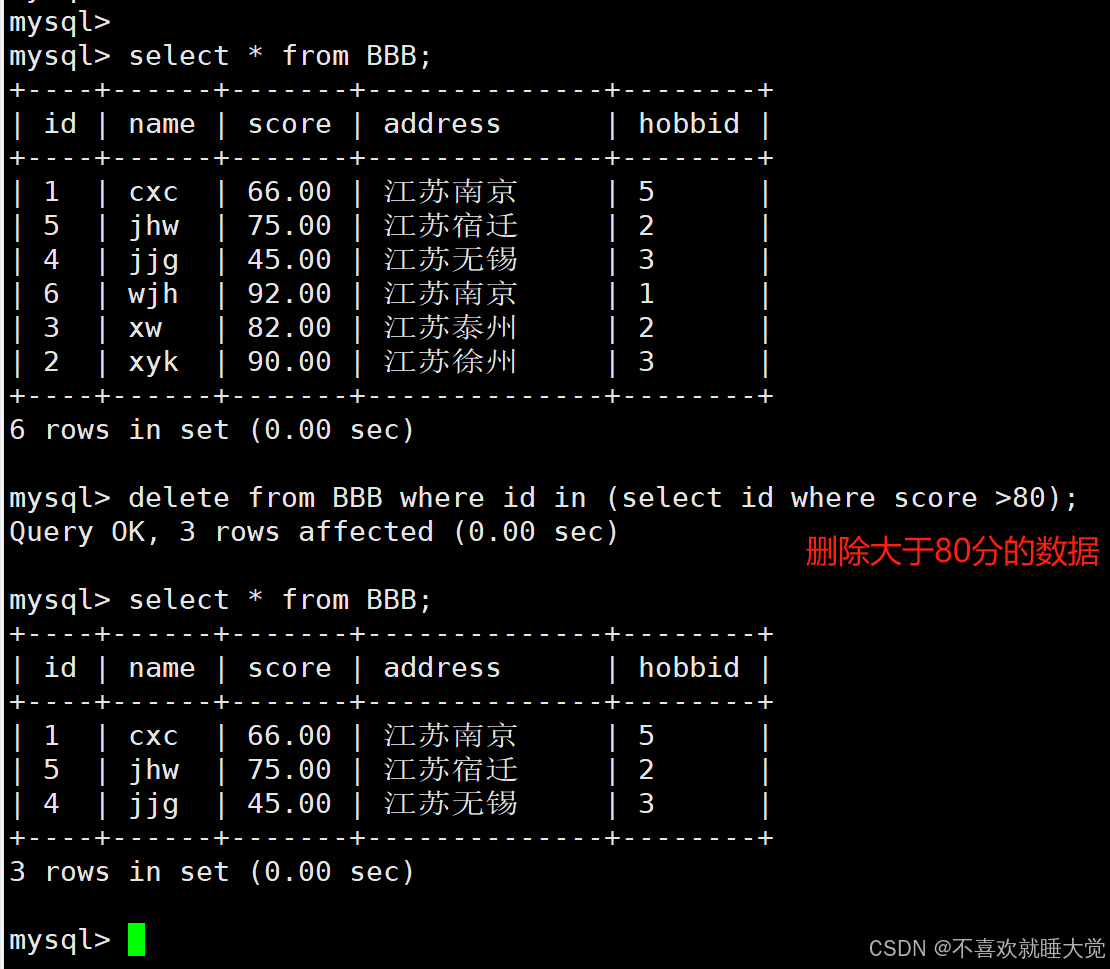
4、delete
使用子查询的delete语句允许根据另一个查询的结果来删除记录。这种方式特别有用于删除那些满足特定关联条件的行,而这些条件可能需要通过查询其他表来确定
delete from BBB where id in (select id where score >80);
5、exists
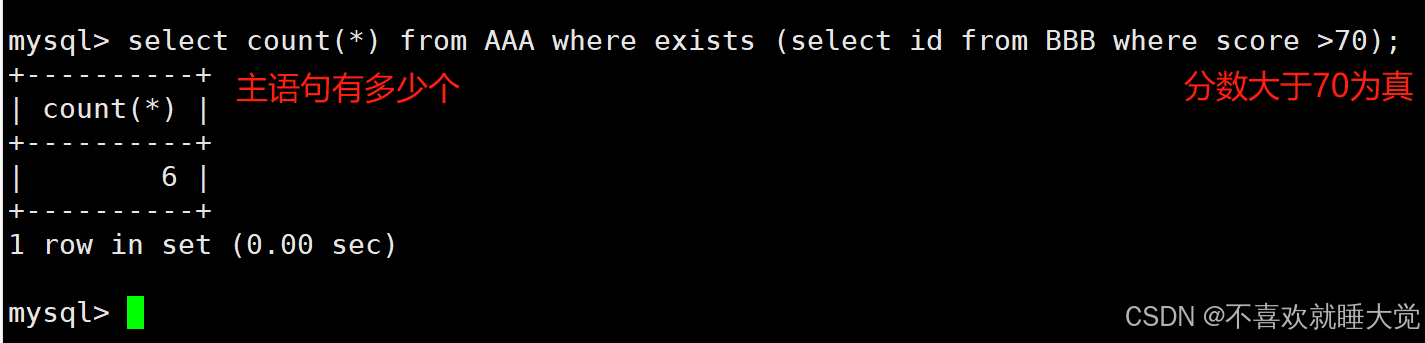
exists这个关键字在子查询时,主要用于判断子查询的结果集是否为空,如果不为空,则返回true,反之则返回false
在使用exists时,当子查询有结果时,不关心子查询的内容,执行主查询操作;当子查询没有结果时,则不执行主查询操作
#当子语句查询结果不为空时返回true,立即执行主语句
select count(*) from AAA where exists(select id from AAA where score>70);
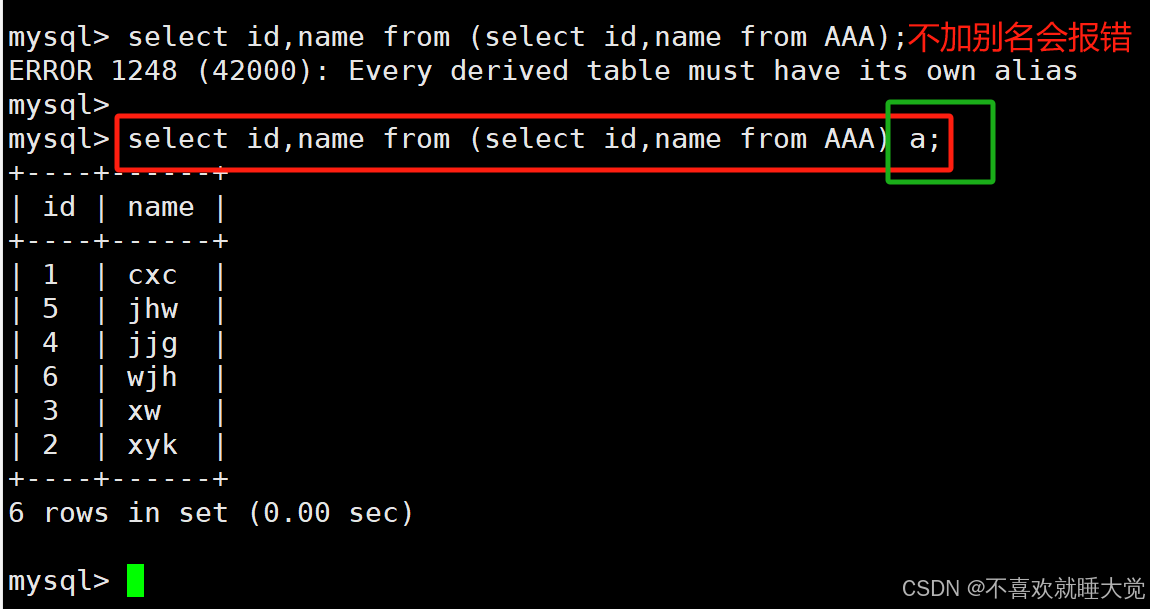
6、别名as
将结果集作为一张表进行查询的时候,需要用到别名
select id,name from (select id,name from AAA) a;
七、视图
1、视图的概念和作用
数据库中的虚拟表,不包含真实数据,只是映射;简化SQL语句,简化查询结果集、灵活查询,针对不同的用户呈现不同的结果集;只适合查询,不适合增删改。视图有表之后才能存在,它的内容都来自基本表,一个视图可对应一个或多个基本表。
2、视图和表的区别和联系
①、视图是已经编译好的sql语句。而表不是
②、视图没有实际的物理记录。而表有。show table status\G
③、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
④、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
⑤、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
⑥、视图的建立和删除只影响视图本身,不影响对应的基本表。(但是更新视图数据,是会影响到基本表的)
3、具体操作
#创建视图
create view 视图表名 as select * from 表名 where 条件;
#查看视图
select * from 视图表名;
#查看表和视图的状态信息
show table status\G;
#查看视图结构
desc 视图表名;
#修改视图
update 视图表名 set 字段=新值 where 条件判断;
#删除视图
drop view [if exists] 视图名;3.1、创建视图
#创建视图
create view 视图表名 as select * from 表名 where 条件;#单表创建视图
create view v_sc as select * from AAA where score >70;
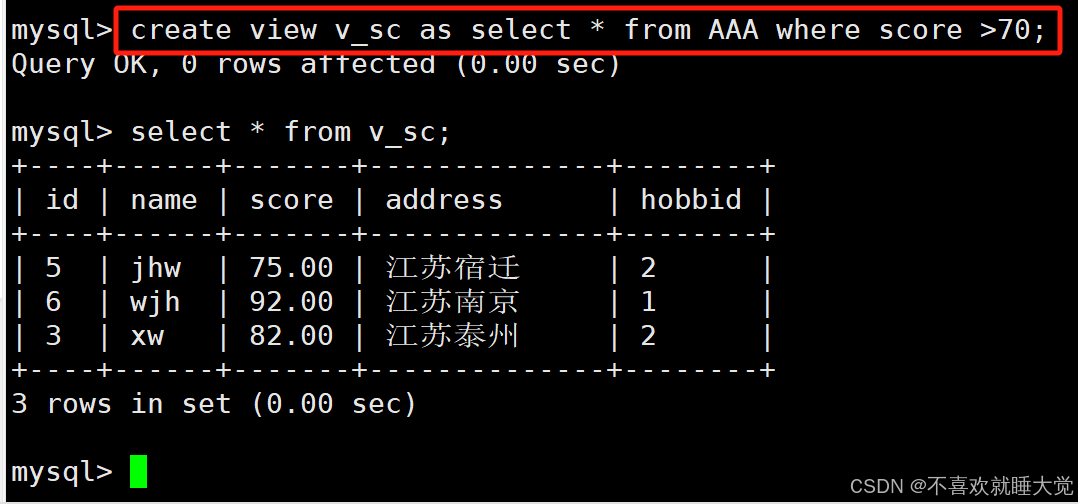
3.2、修改视图数据
格式:update 视图表名 set 字段=新值 where 条件判断;#修改视图数据
update v_score set score=60 where name='cxz';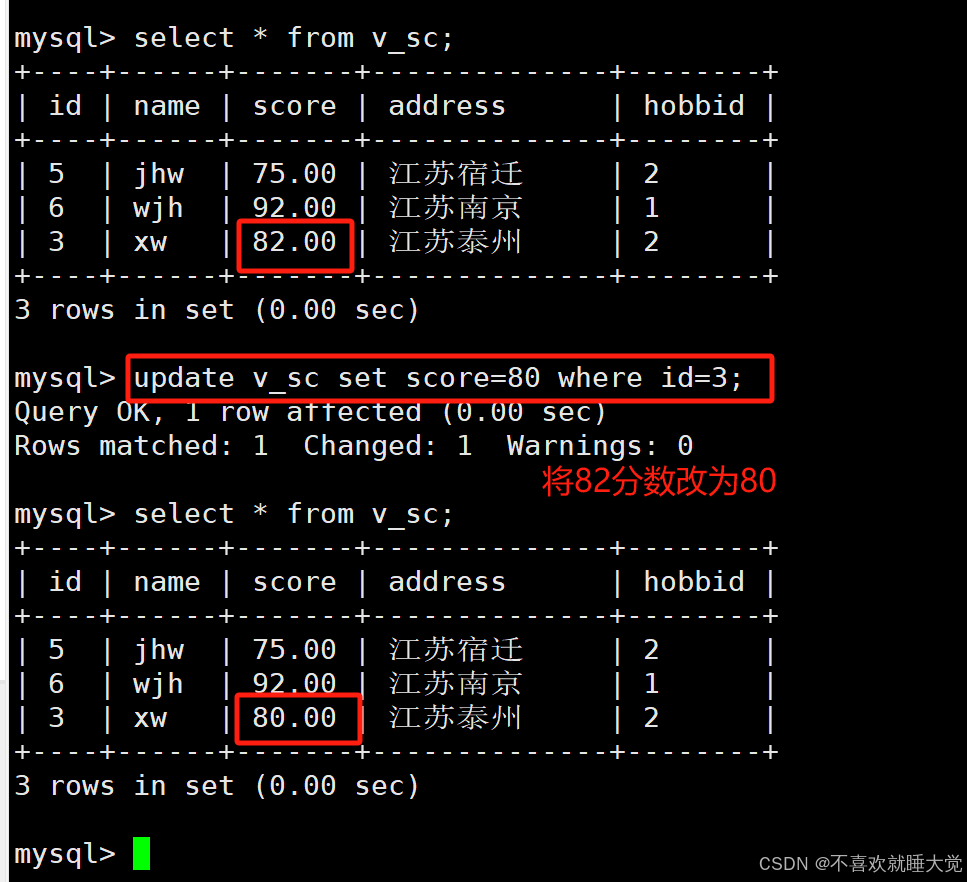
3.3、删除视图
格式:drop view [if exists] 视图名;drop view v_1;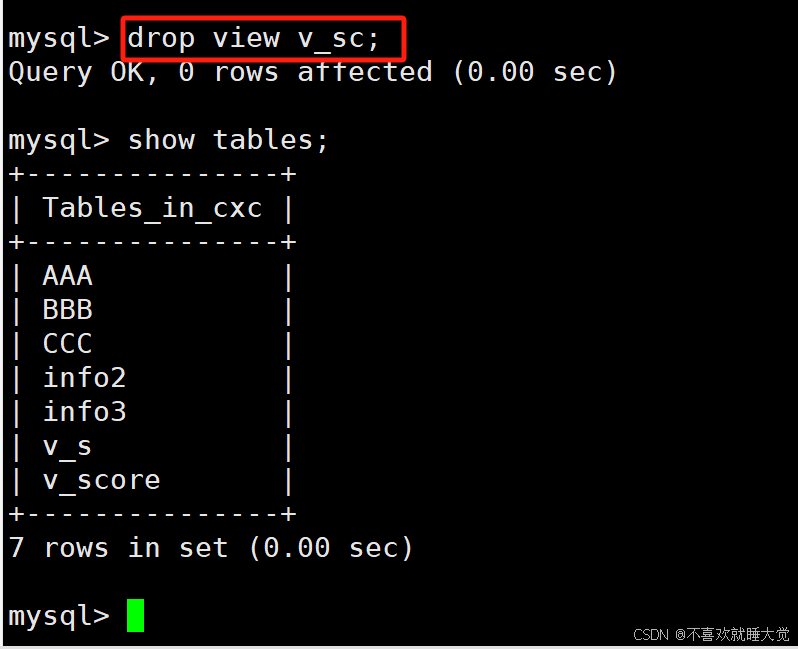
八、NULL值
在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失的值,也就是在表中该字段是没有值的。
如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。
如果在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。
NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有值的。在 SQL 语句中,使用 ls null 可以判断表内的某个字段是不是 NULL 值,相反的用 ls not null可以判断不是NULL值
NULL值与空值的区别:
- 空值长度为0,不占空间,NULL值的长度为null,占用空间
- ls null可判断是不是NULL值,却无法判断空值
- 空值使用"=“或者”<>"来处理(!=)
- count() 计算时,NULL会忽略,空值会加入计算
#查看null值、空值、abc字符串的字符长度
select length(null),length(''),length('123');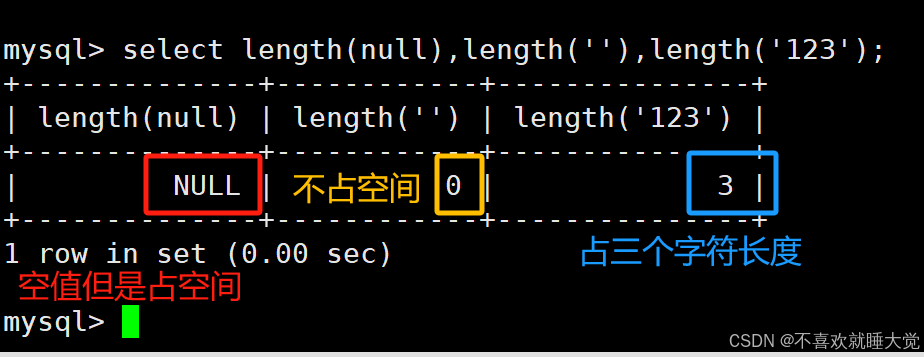
alter table BBB add length varchar(50);
alter table BBB add age varchar(50) not null;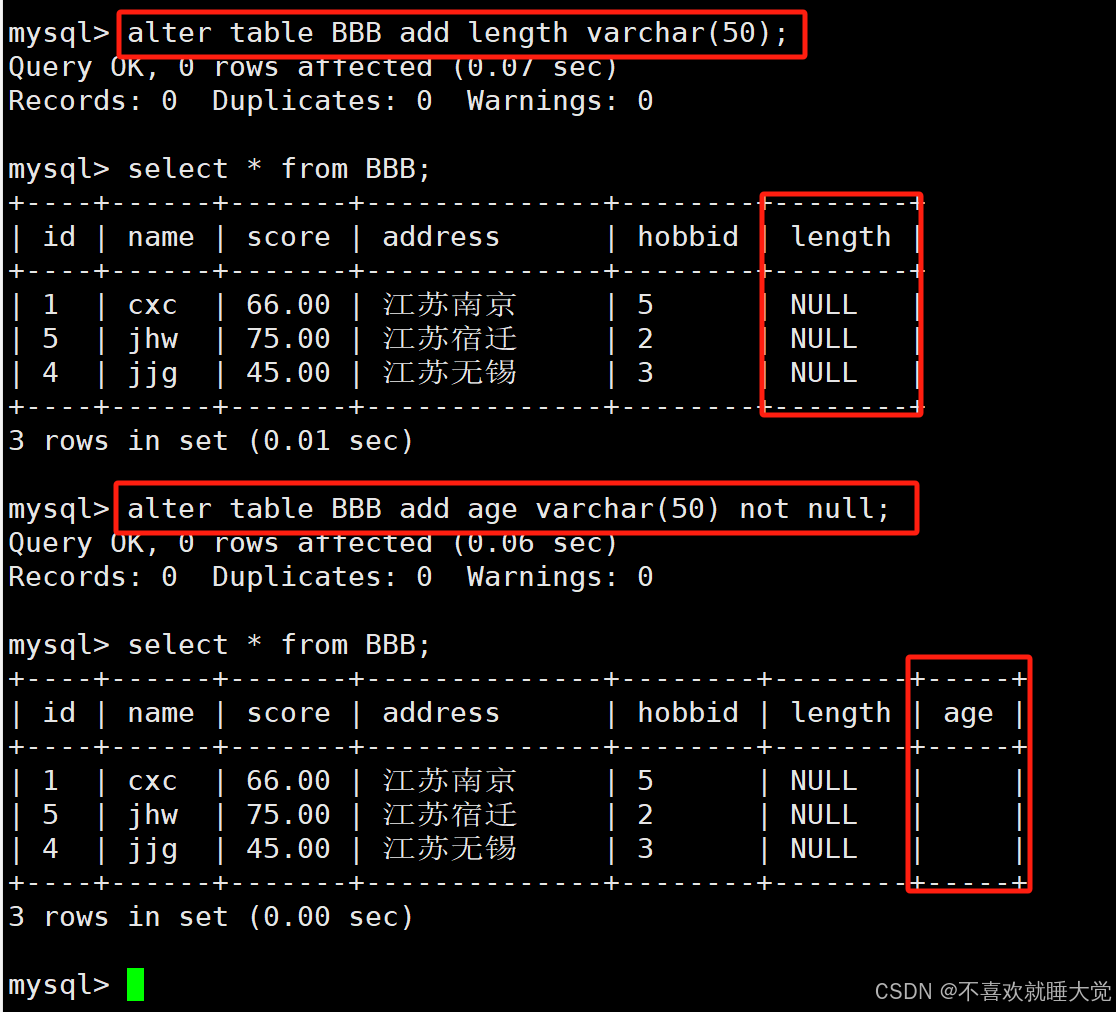
九、连接查询
在MySQL中,连接查询是一种用于检索数据的方法,它可以从一个以上的表中获取数据,并将它们关联起来。这种查询通常使用JOIN子句来实现
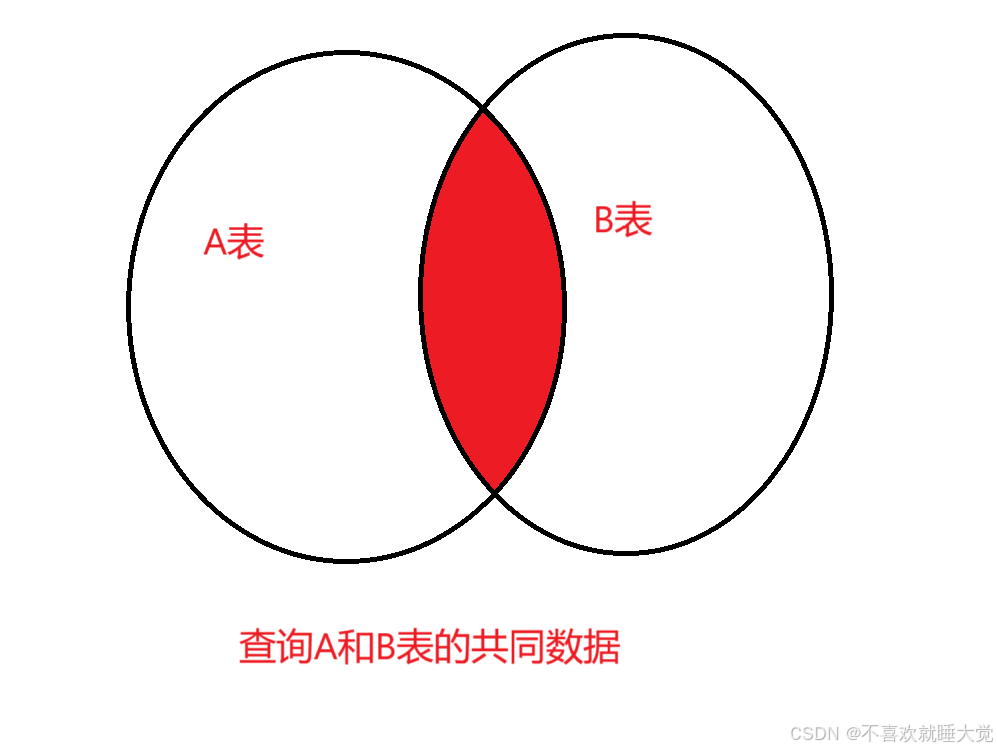
1、内连接
内连接就是两张或多张表中同时符合某种条件的数据记录的组合。
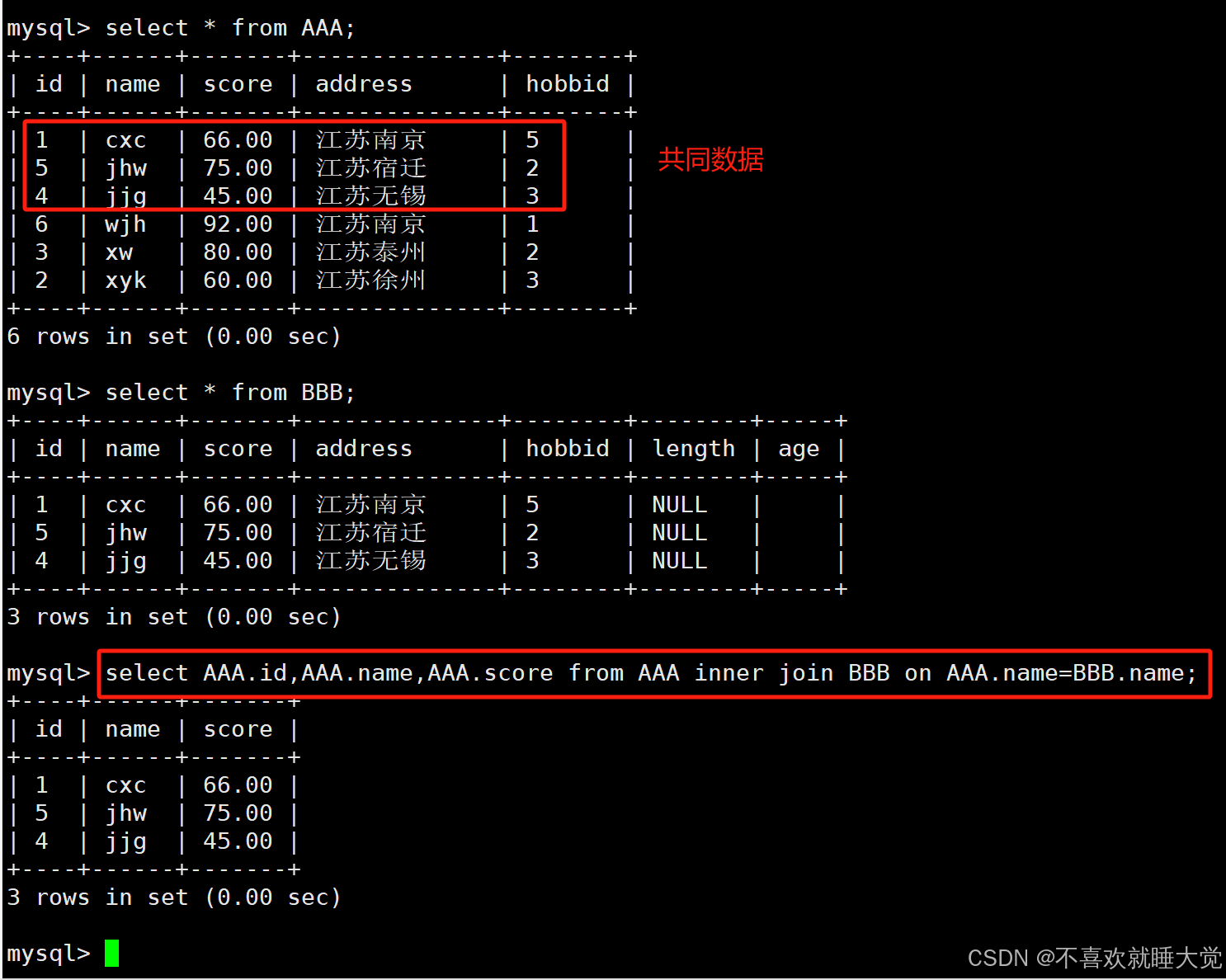
通常在 from 子句中使用关键字 inner join 来连接多张表,并使用 on 子句设置连接条件,内连接是系统默认的表连接,所以在 from 子句后可以省略 inner 关键字,只使用 关键字 join。同时有多个表时,也可以连续使用 inner join 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
格式:select 表1[2].字段1,表1[2].字段2,... from 表1 inner join 表2 on 表1.同名字段=表2.同名字段;select AAA.id,AAA.name,AAA.score from AAA inner join BBB on AAA.name=BBB.name;
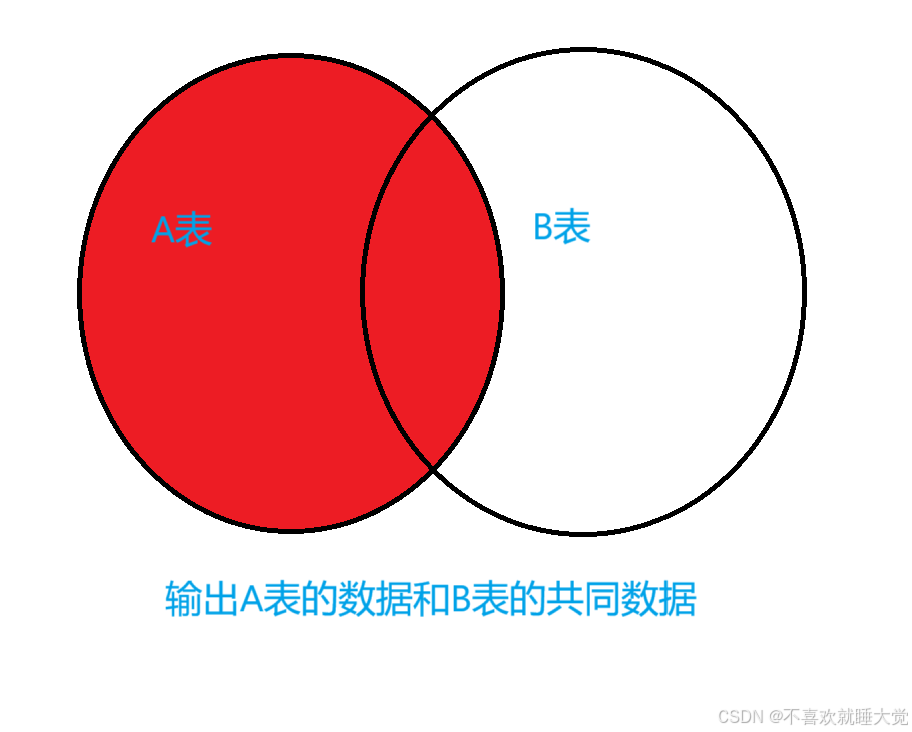
2、左连接
左连接也可以被称为左外连接,在 from 子句中使用 left join 或者 left outer join 关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行
格式:select * from 表1 left join 表2 on 表1.同名字段=表2.同名字段;select * from AAA left join BBB on AAA.name=BBB.name;
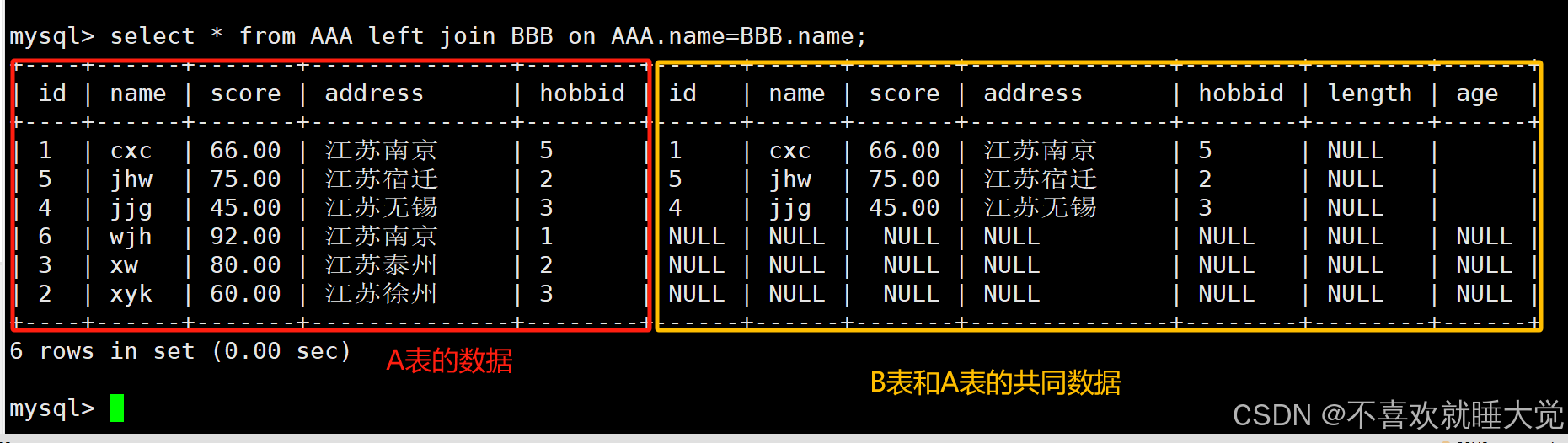
3、右连接
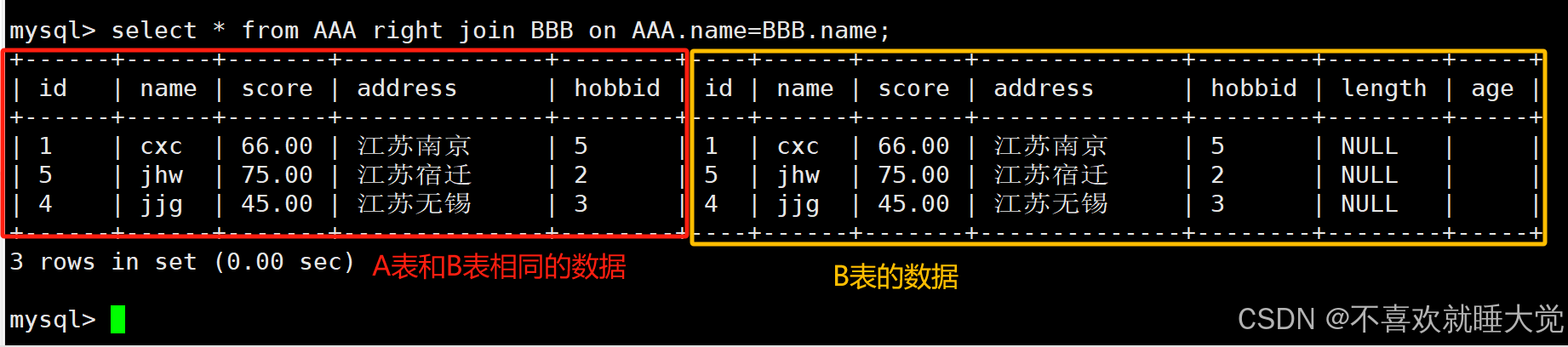
右连接也被称为右外连接,在 from子句中使用 right join 或者 right outer join 关键字来表示。右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配
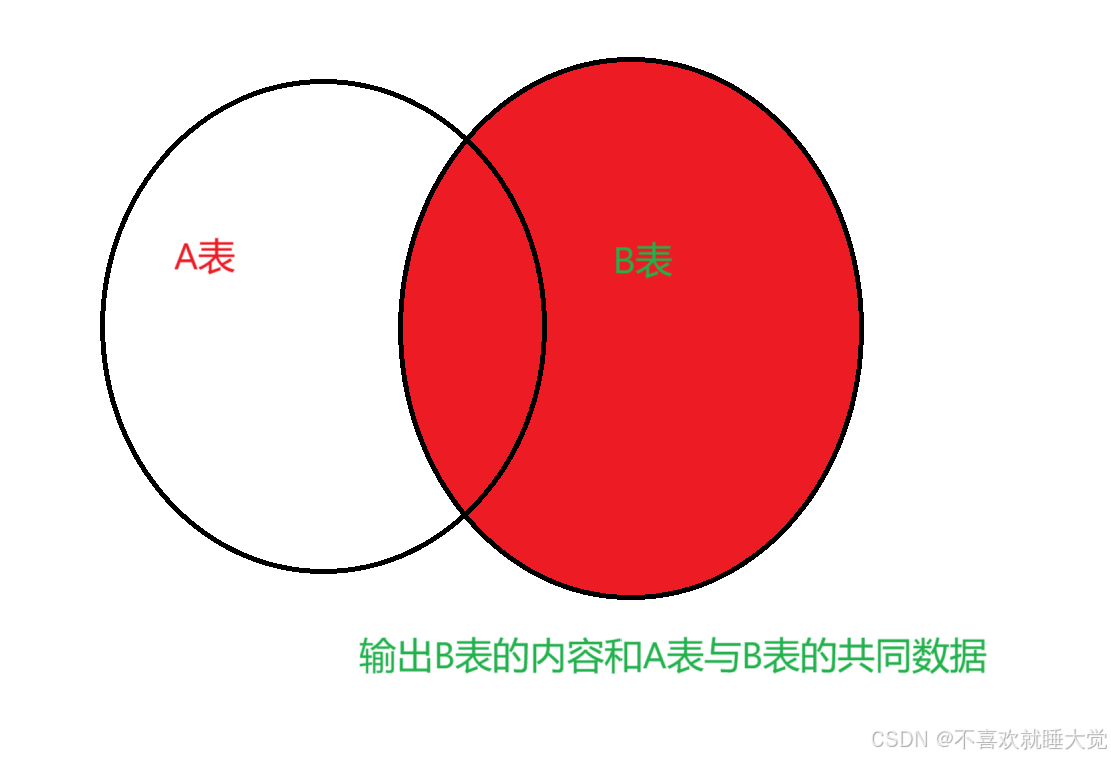
select * from 表1 right join 表2 on 表1.同名字段=表2.同名字段;select * from info right join web on info.name=web.name;