
论文链接:https://arxiv.org/pdf/2411.07975
github链接:https://github.com/deepseek-ai/Janus
亮点直击
统一多模态框架: 提出 JanusFlow,一个同时处理图像理解和文本到图像生成任务的统一模型,解决了任务分离带来的架构复杂性问题。
创新优化策略: 采用任务解耦和表示对齐两大关键策略,提高理解与生成任务的独立性与语义一致性。
卓越性能表现:在多模态理解与文本到图像生成基准测试中超越现有专用模型和统一模型,取得领先成绩。
紧凑高效的设计:仅用 1.3B 参数实现性能突破,展示出高效模型在多模态任务中的巨大潜力。
效果展示
文生图


多模态理解


总结速览
解决的问题
当前图像理解与生成任务通常由专门的模型完成,统一模型在性能和效率上仍然存在局限性,难以在两个领域中同时达到优异表现。
提出的方案
提出 JanusFlow 框架,采用极简架构,将自回归语言模型与rectified flow相结合,实现图像理解与生成的统一。
应用的技术
-
Rectified Flow:作为生成建模的先进方法,简化了在大语言模型框架中训练的复杂性。
-
理解与生成解码器的解耦:分别优化理解与生成任务的编码器。
-
表示对齐:在统一训练过程中对理解和生成的表示进行对齐,增强统一模型的表现力。
达到的效果
-
性能提升:在标准基准上显著优于现有的统一模型,并在各领域中表现出与专用模型媲美甚至更优的性能。
-
模型简化:无需复杂的架构修改,即可在统一框架内有效训练,提升效率和通用性。
JanusFlow
本节介绍 JanusFlow 的架构以及我们的训练策略。
背景
多模态大语言模型(MLLMs)
给定一个数据集 ,其中包含离散的 token 序列,每个序列可以表示为 ,大语言模型(LLMs)通过自回归方式对序列分布进行建模。
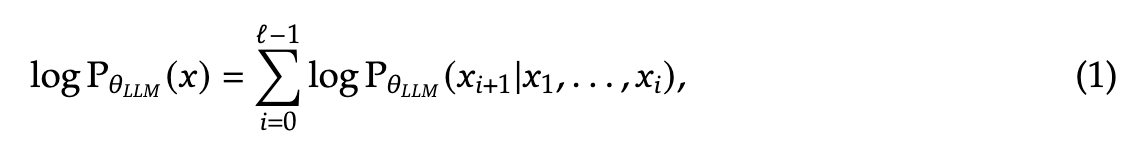
其中, 表示 LLM 的参数, 是序列长度。在经过大规模数据集的训练后,LLMs 展现出在各种任务中的泛化能力,并能够遵循多样化的指令。为了扩展这些模型以处理视觉输入,LLMs 会与视觉编码器结合。例如,LLaVA 通过投影层将 LLM 与预训练的 CLIP 图像编码器集成,将提取的图像特征转换为 LLM 可处理的联合嵌入空间(作为词嵌入)。借助大规模多模态数据集和日益强大的 LLMs,这种架构推动了能够解决多种视觉语言任务的先进多模态模型的发展。
Rectified Flow
对于一个包含连续 维数据点的数据集 ,其中 从未知的数据分布 中抽取,Rectified Flow [55, 60] 通过学习一个定义在时间 上的常微分方程(ODE)来建模数据分布:
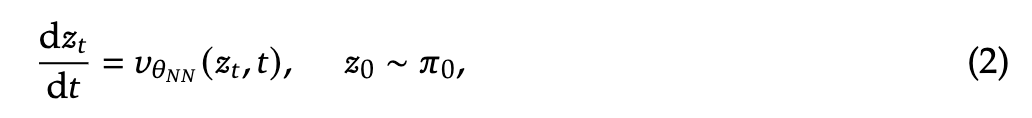
其中, 表示速度神经网络的参数, 是一个简单的分布,通常为标准高斯噪声 。通过最小化神经网络速度与从 到 的随机点之间线性路径方向的欧几里得距离来训练网络:
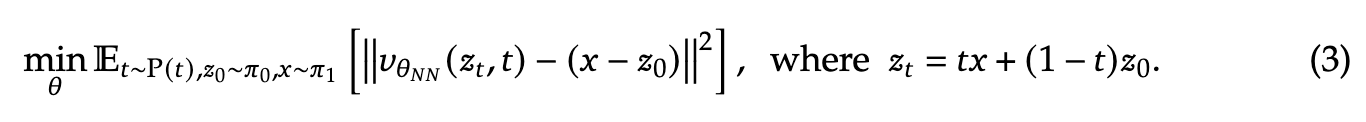
其中, 是定义在时间 上的分布。当网络具有足够的容量且目标函数被完美最小化时,最优速度场 将初始分布 映射为真实的数据分布 。更具体地说,对于 ,分布 满足分布 。尽管概念简单,Rectified Flow在各种生成建模任务中表现出色,包括文本到图像生成、音频生成 和生物结构生成。
多模态理解与生成的统一框架
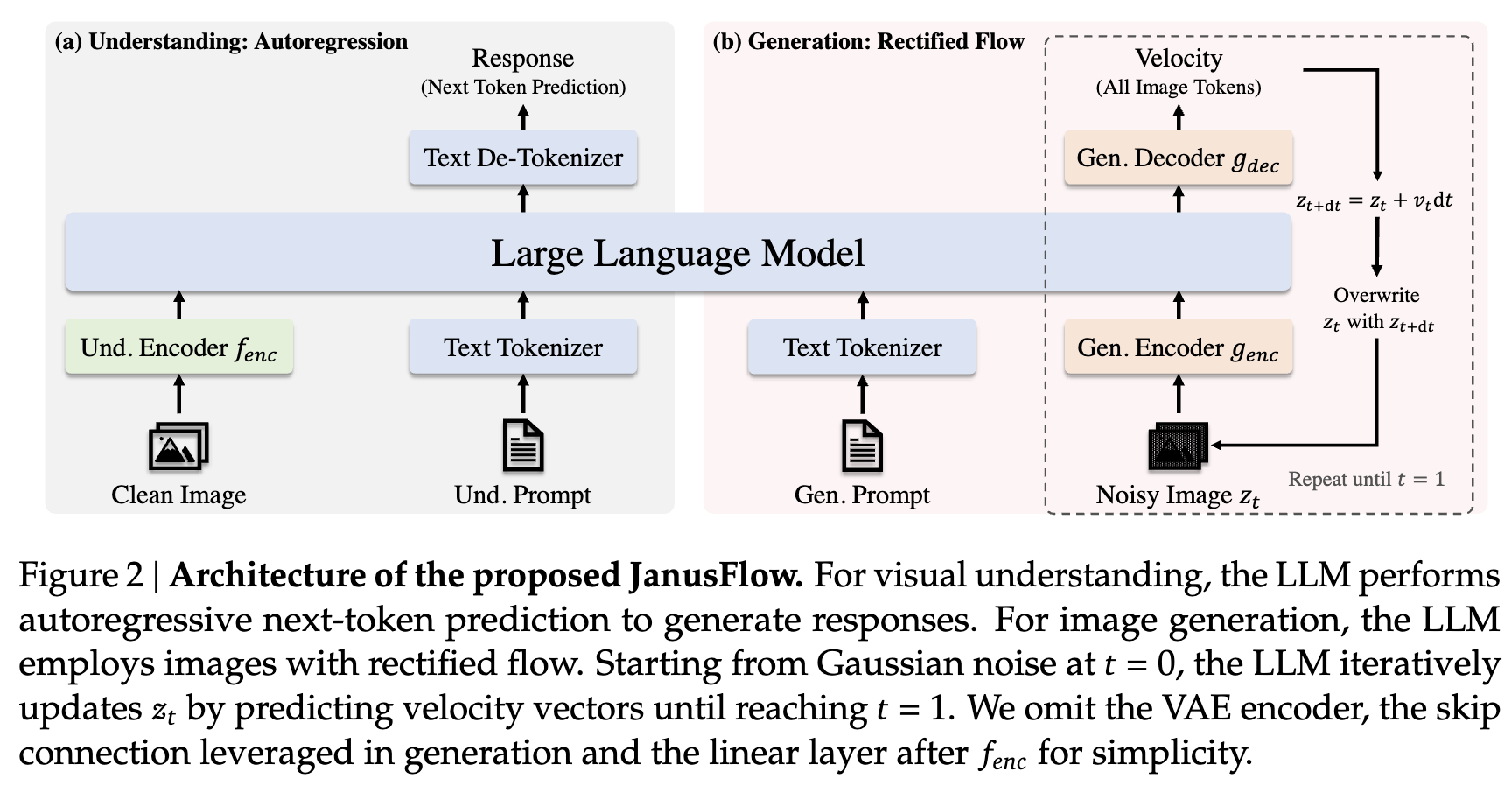
JanusFlow 提供了一个统一的框架,用于处理视觉理解和图像生成任务。以下概述了 JanusFlow 如何在单一 LLM 架构中处理这两类任务。
多模态理解
在多模态理解任务中,LLM 处理由交替出现的文本和图像数据组成的输入序列。文本被分割为离散的 token,每个 token 被转换为维度为 的嵌入向量。对于图像,图像编码器 将每个图像 编码为形状为 的特征图。该特征图被展平,并通过线性变换层投射为形状为 的嵌入序列。这里, 和 由图像编码器确定。
文本嵌入与图像嵌入连接形成输入序列,输入到 LLM 中,LLM 随后根据嵌入序列自回归地预测下一个 token。根据通用做法 [85, 93, 96],我们在图像前添加特殊 token |BOI|,在图像后添加特殊 token |EOI|,以帮助模型定位序列中的图像嵌入。
图像生成
在图像生成任务中,LLM 以文本序列 作为条件,利用Rectified Flow生成对应的图像。为提高计算效率,生成过程在使用预训练的 SDXL-VAE 的潜空间中完成。
生成过程从在潜空间中采样高斯噪声 开始,其形状为 ,然后通过生成编码器 处理为形状为 的嵌入序列。此序列与表示当前时间步 (初始时 )的时间嵌入连接,形成长度为 的序列。
不同于之前采用多种注意力屏蔽策略的研究 [96, 103],我们发现因果注意力已足够,因为初步实验表明替代屏蔽方案并未带来性能提升。LLM 输出与 对应的结果通过生成解码器 转换回潜空间,生成形状为 的速度向量。状态通过标准的欧拉求解器进行更新:

其中, 是用户定义的步长。我们用 替换输入中的 ,并重复该过程,直到得到 ,随后通过 VAE 解码器将其解码为最终图像。为了提高生成质量,在计算速度向量时,引入了无分类器指导(Classifier-Free Guidance,CFG)。
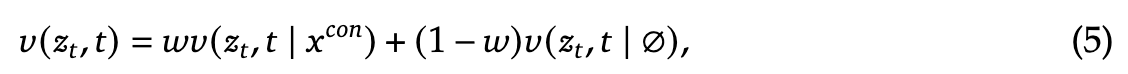
其中, 表示未结合文本条件推断的速度, 控制无分类器指导(CFG)的幅度。经验表明,增加 能够提高语义对齐度。与多模态理解类似,我们在序列中添加特殊标记 |BOI|,以指示图像生成的开始。
解耦两任务的编码器
先前将自回归生成与扩散模型统一在联合 LLM 训练框架中的方法为理解和生成任务使用相同的编码器( 和 )。例如,Zhou 等人在相同的 VAE 潜在空间中通过共享的 U-Net 或线性编码器完成这两项任务,而 Xie 等人利用 MAGVIT-v2将图像块编码为离散标记以同时处理两项任务。
然而,关于统一自回归模型的最新研究表明,这种共享编码器的设计在生成任务上表现次优,尤其是在通过向量量化标记进行自回归生成的模型中。借鉴这些发现,JanusFlow 采用了解耦编码器设计。具体而言,我们使用预训练的 SigLIP-Large-Patch/16 模型作为 ,以提取多模态理解的语义连续特征,而生成任务则使用从头初始化的独立 ConvNeXt 块 作为 和 ,因其效果优越。按照既定实践 [5, 14, 90],在 和 之间加入长跳跃连接。对照实验表明,这种解耦编码器设计显著提升了统一模型的性能。JanusFlow 的完整架构如下图 2 所示。
训练方案
如下图 3 所示,分三个阶段依次训练模型,具体如下。
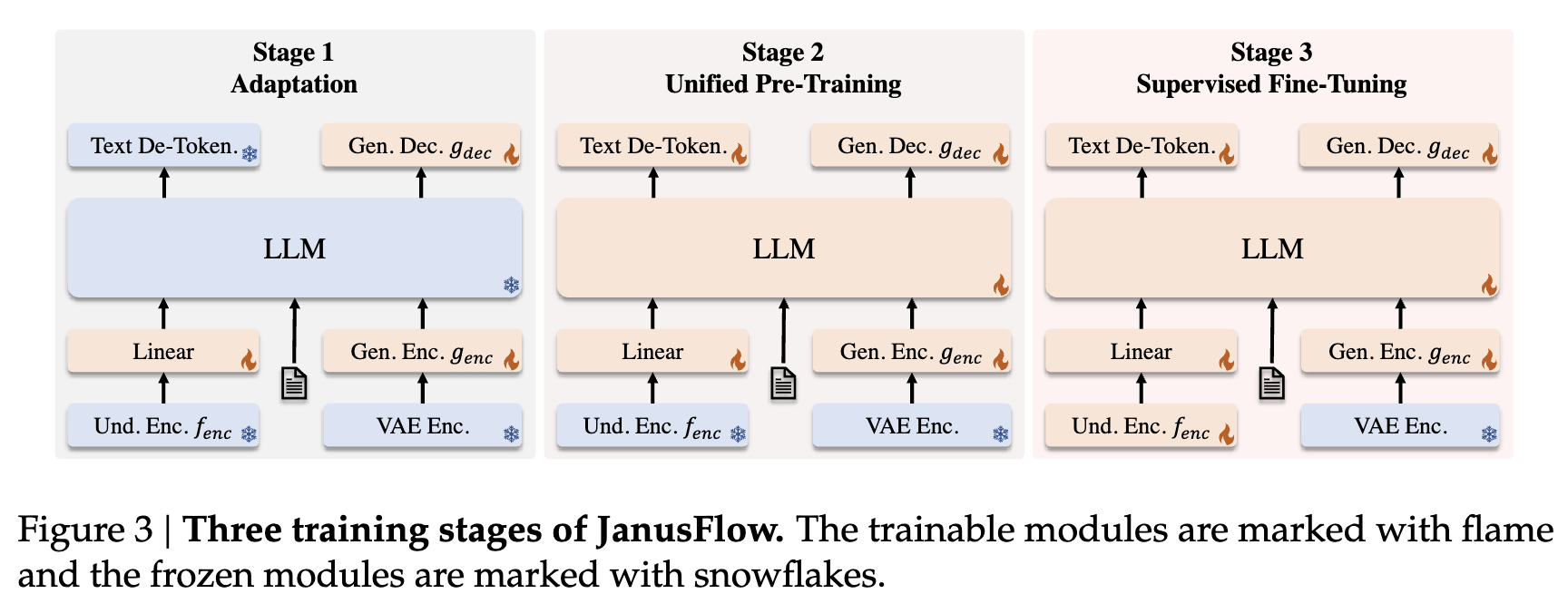
阶段 1:随机初始化组件的适配
在第一阶段,我们仅训练随机初始化的组件,包括线性层、生成编码器和生成解码器。这一阶段旨在使这些新模块与预训练的 LLM 和 SigLIP 编码器有效配合,实质上是为新引入的组件进行初始化。
阶段 2:统一预训练
在适配阶段之后,我们训练整个模型,但不包括视觉编码器,与先前方法一致 [57, 63]。训练数据包括三种类型:多模态理解、图像生成和仅文本数据。最初分配较高比例的多模态理解数据,以建立模型的理解能力。随后逐步增加图像生成数据的比例,以满足基于扩散模型的收敛需求。
阶段 3:监督微调(SFT) 最后阶段,使用指令调优数据对预训练模型进行微调,包括对话、任务特定的交流以及高质量的文本条件图像生成示例。在此阶段,还解冻 SigLIP 编码器参数。这一微调过程使模型能够有效响应用户指令,完成多模态理解和图像生成任务。
训练目标
训练 JanusFlow 涉及两种类型的数据:多模态理解数据和图像生成数据。这两种数据都包含两部分:“条件”和“响应”。“条件”指的是任务的提示(例如,在生成任务中是文本提示,在理解任务中是图像),而“响应”指的是两种任务的相应输出。数据可以格式化为 ,其中上标 表示“条件”, 表示“响应”。我们表示整个序列 的长度为 , 的长度为 , 的长度为 。我们用 来表示 JanusFlow 中所有可训练的参数集合,包括 LLM、、、 和线性变换层。
自回归目标
对于多模态理解任务, 仅包含文本标记。JanusFlow 采用最大似然原则进行训练,
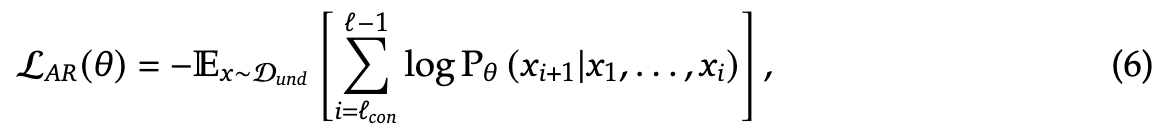
其中期望是对多模态理解数据集 中所有 对进行计算,仅对 中的标记计算损失。
Rectified Flow目标:对于图像生成任务, 包含文本标记,而 是对应的图像。JanusFlow 通过Rectified Flow目标进行训练。
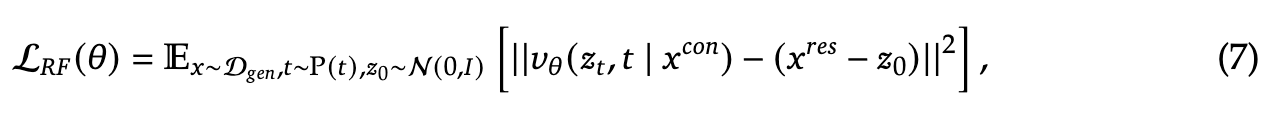
其中 。遵循 Stable Diffusion 3,将时间分布 设置为对数正态分布。为了启用 CFG 推理,在训练中随机丢弃 10% 的文本提示。
表示对齐正则化:近期的研究 [99] 显示,跨diffusion transformers 和语义视觉编码器对齐中间表示能够增强扩散模型的泛化能力。解耦视觉编码器设计能够有效地将这种对齐实现为正则化项。具体来说,对于生成任务,将理解编码器 中的特征与 LLM 的中间特征对齐。
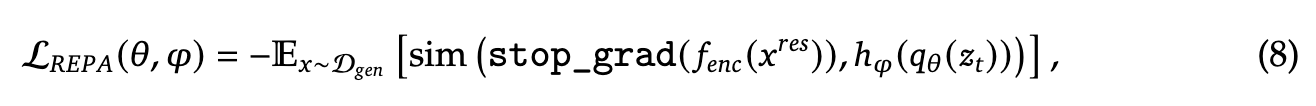
其中 表示给定输入 的中间 LLM 表示, 是一个小型可训练 MLP,将 投影到维度 。函数 计算嵌入之间逐元素余弦相似度的均值。在计算损失之前,我们将 重塑为 。为了简化实现,我们故意调整了 和 的配置,以确保 且 。 的梯度不会通过理解编码器反向传播。这个对齐损失帮助 LLM 的内部特征空间(给定噪声输入 )与理解编码器的语义特征空间对齐,从而在推理过程中生成图像时,能够提高从新的随机噪声和文本条件生成图像的质量。
总结:所有三个目标在各个训练阶段都被应用。多模态理解任务使用 ,而图像生成任务则使用组合损失 。
实验
研究者们进行了一系列实验,以评估 JanusFlow 在多模态理解和生成任务中的能力。首先,我们描述了我们的实验设置和实现细节。然后,展示了在多模态理解和图像生成的标准基准上的结果。最后,进行了一些消融实验,以验证关键设计选择。
实验设置和实现细节
本文的框架基于 DeepSeek-LLM(1.3B)的增强版。LLM 由 24 个变换器块组成,支持序列长度为 4,096。在本文的模型中,理解和生成任务都使用分辨率为 384 的图像。
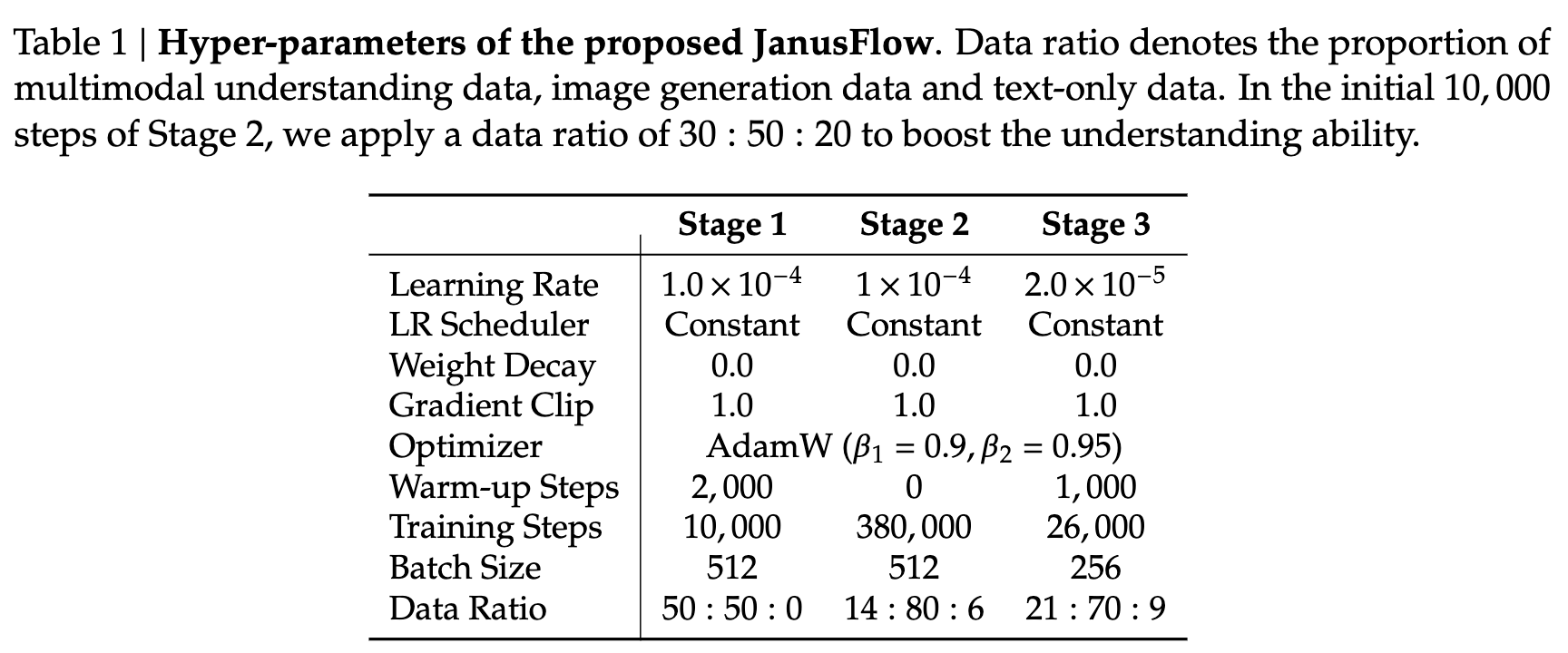
对于多模态理解,使用 SigLIP-Large-Patch/16 作为 。对于图像生成,利用预训练的 SDXL-VAE 作为其潜在空间。生成编码器 包括一个 2×2 的 Patchify 层,后跟两个 ConvNeXt 块和一个线性层。生成解码器 由两个 ConvNeXt 块、一个像素重排层(用于上采样特征图)和一个线性层组成。我们的 SigLIP 编码器包含约 300M 个参数。 和 是轻量级模块,总参数量约为 70M。下表 1 详细列出了每个训练阶段的超参数。在对齐正则化中,我们使用第 6 个块之后的 LLM 特征作为 ,并使用一个三层 MLP 作为 。使用指数移动平均(EMA)方法,比例为 0.99,以确保训练的稳定性。
对于数据预处理,分别处理理解和生成数据。对于理解任务,通过将长边调整为目标大小,并将图像填充为正方形来保持所有图像信息。对于生成任务,将短边调整为目标大小,并应用随机方形裁剪,以避免填充伪影。在训练过程中,为提高训练效率,将多个序列打包成一个长度为 4,096 的单一序列。
实现基于 HAI-LLM 平台,使用 PyTorch。训练是在 NVIDIA A100 GPU 上进行的,每个模型需要约 1,600 A100 GPU 天。
训练数据设置
遵循 Janus 构建训练数据。每个训练阶段的数据配置如下。
阶段 1 和阶段 2 的数据
本文框架的前两个阶段使用三种类型的数据:多模态理解数据、图像生成数据和仅文本数据。
-
多模态理解数据。此类数据包含几个子类别:
-
(a) 图像描述数据。结合了来自 [20, 41, 50, 51, 53, 79] 的描述数据集,并使用开源多模态理解模型为来自 [16, 43] 的图像生成附加描述。数据遵循模板格式,例如:“<image>生成此图片的描述。<caption>”。
-
(b) 图表和表格。直接采用来自 DeepSeek-VL 训练数据的图表和表格数据。
-
(c) 任务数据。使用 ShareGPT4V 数据,以促进预训练期间的基本问答能力,数据结构为:“<image><question><answer>”。
-
(d) 交替文本-图像数据。此子类别来源于 [42, 81]。
-
-
图像生成数据。图像生成数据集结合了来自 [16, 21, 41, 43, 67, 69, 79, 82] 的高质量图像和 200 万个内部数据。我们使用多模态理解模型增强它们,生成机器生成的描述。筛选了来自 [16, 79] 的图像,按纵横比和美学评分进行过滤,保留约 20% 的原始数据集。25% 的数据包含单句描述,这类数据帮助模型能够处理简短的提示。所有数据点格式为:“<prompt><image>”。
-
仅文本数据。直接使用 DeepSeek-LLM的文本语料库。
阶段 3 的数据 SFT 阶段同样使用三种类型的数据:
-
多模态指令数据。利用来自 [29, 33, 35, 47, 64, 78] 的指令调优数据集。
-
图像生成数据。将来自 [16, 79, 82] 的高质量文本-图像对重新格式化为指令格式:“User:<user prompt>\n\n Assistant:<image>”。
-
仅文本数据。直接合并了来自 [47] 的仅文本数据。
评估设置
图像生成
使用视觉质量和语义准确性指标来评估生成的图像。对于视觉质量评估,采用 Fréchet Inception DistanceFID)指标,并计算 30,000 张生成图像与其对应的来自 MJHQ 数据集的参考图像之间的 FID。FID 的计算遵循 GigaGAN的实现。为了评估语义准确性,使用两个专门的框架:GenEval和 DPG-Bench。这些框架旨在评估生成的图像是否准确包含了输入提示中指定的对象和关系,从而提供广泛的生成能力评估。
多模态理解 通过一系列多样化的视觉-语言基准测试来评估 JanusFlow 的多模态理解能力,这些基准测试涉及一般的理解能力,包括 POPE、MME、MMBench、SEEDBench、VQAv2、GQA、MM-Vet 和 MMMU。
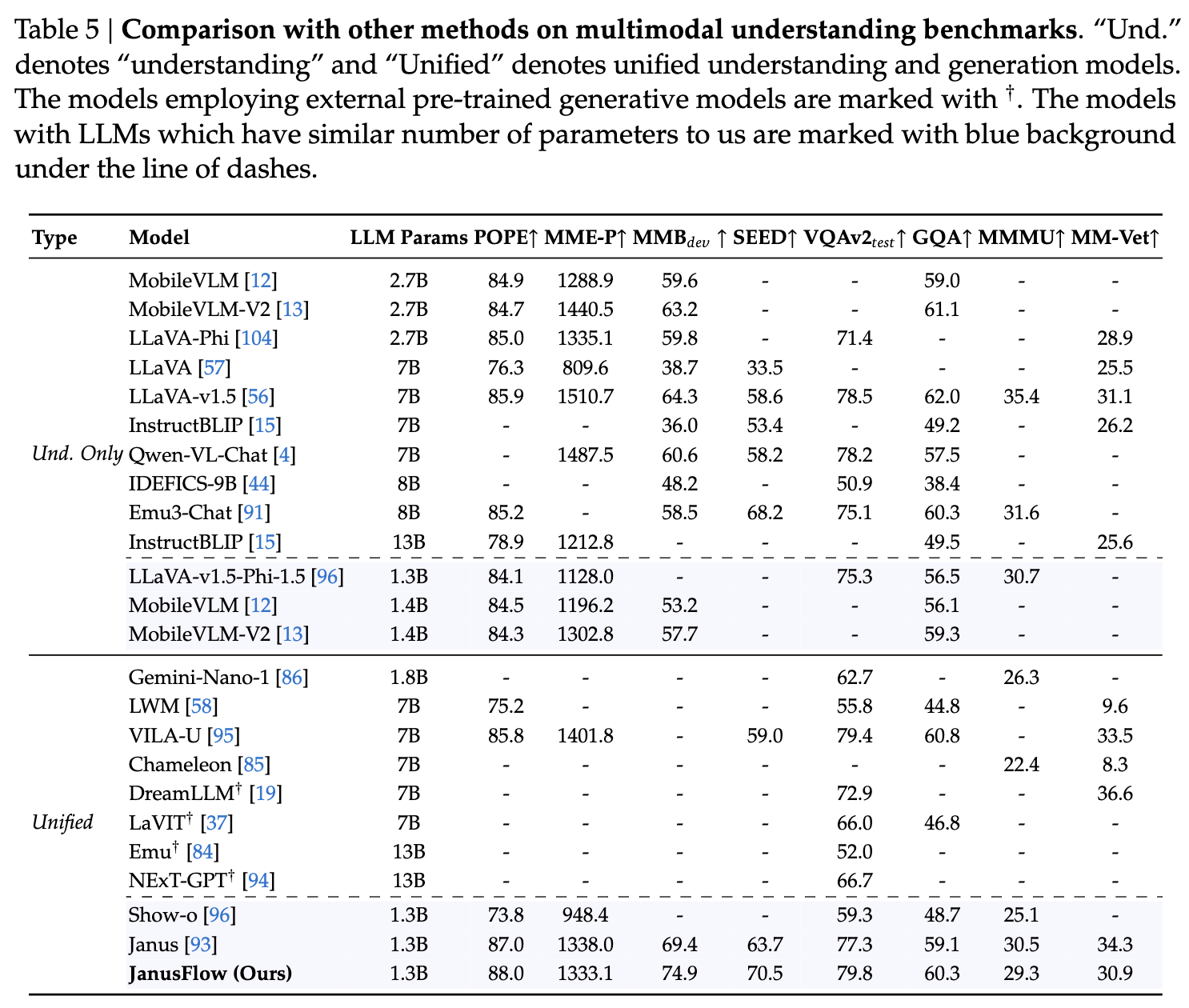
定量结果
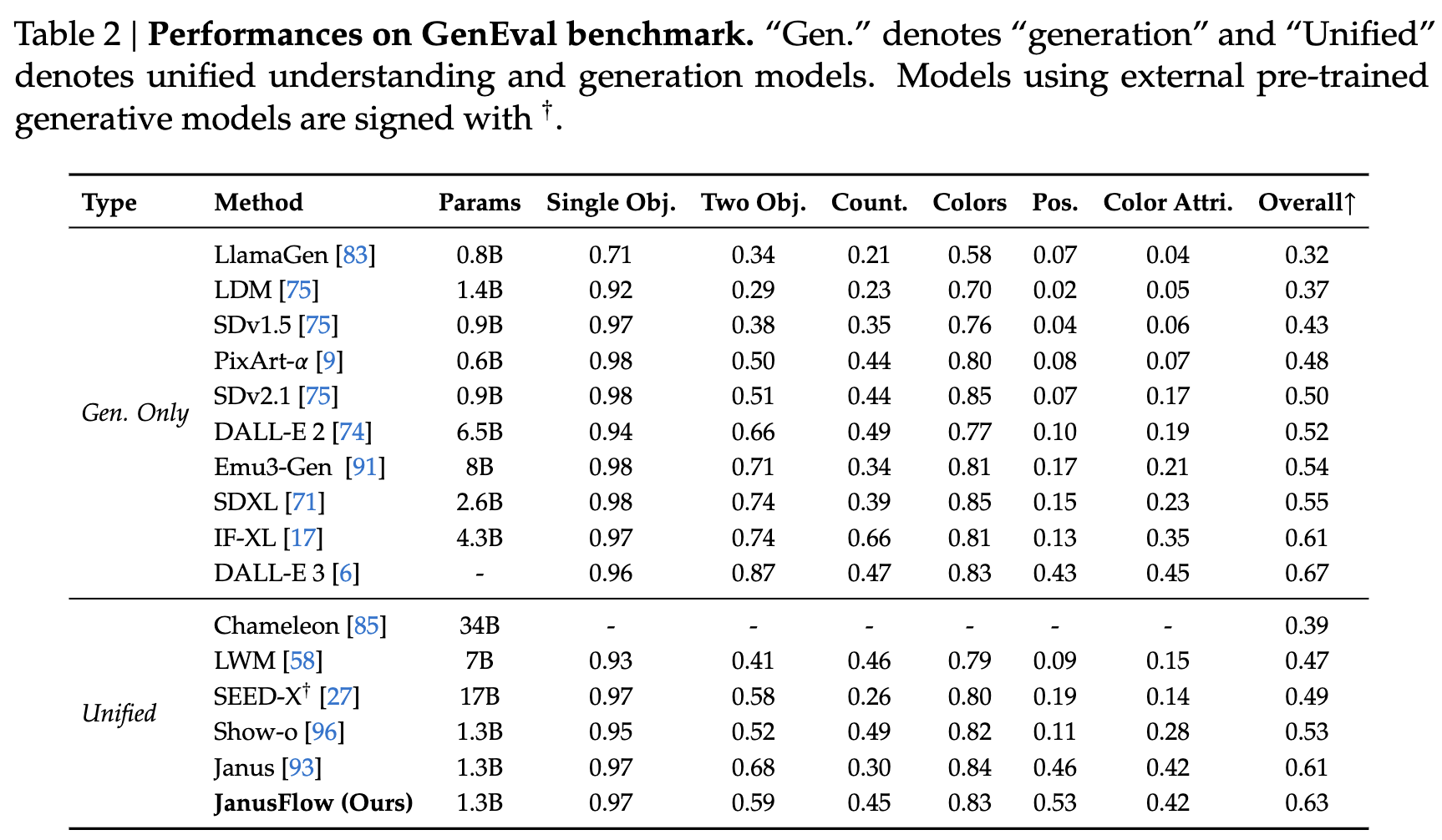
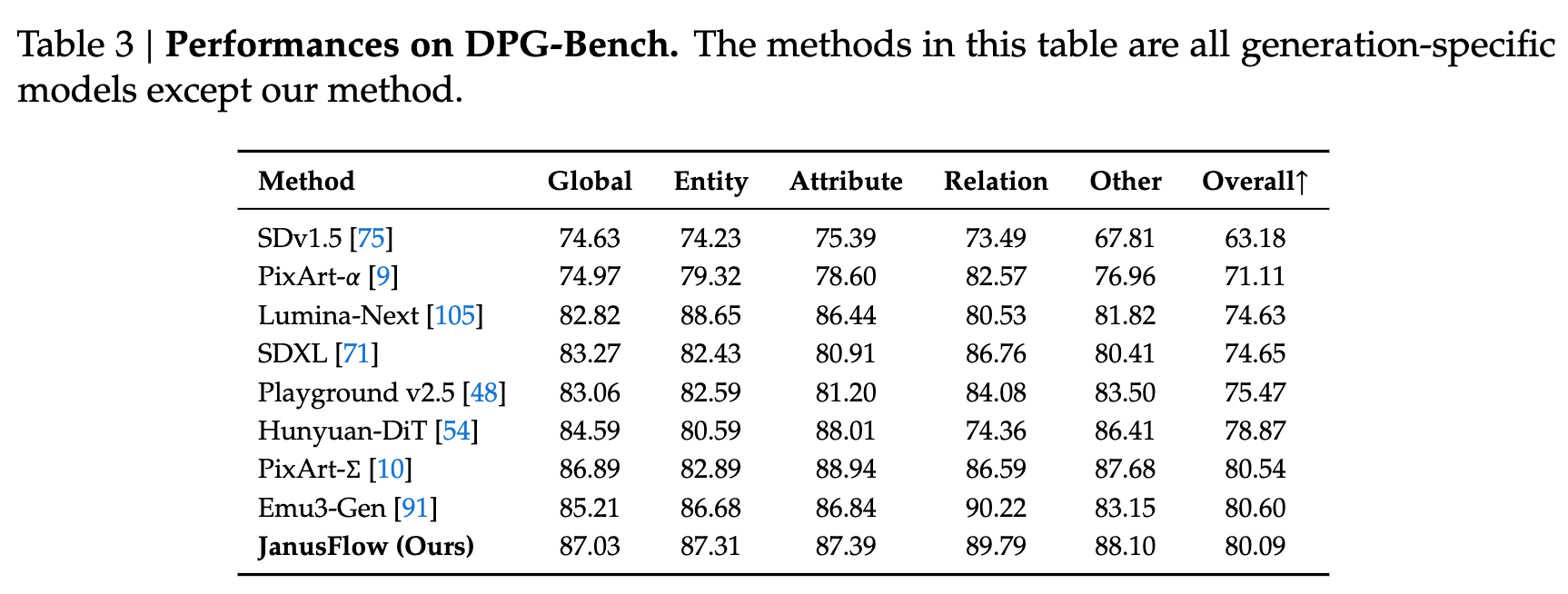
图像生成性能 本文报告了在 GenEval、DPG-Bench 和 MJHQ FID-30k 上的性能。在下表 2 中,给出了 GenEval 的比较,包括所有子任务的分数和总体分数。JanusFlow 在总体得分上达到了 0.63,超过了之前的统一框架以及多个生成特定模型,包括 SDXL 和 DALL-E 2。在下表 3 中,展示了 DPG-Bench 上的结果及其相应的比较。需要注意的是,表 3 中的所有方法都是生成特定模型,除了本文的模型之外。GenEval 和 DPG-Bench 上的结果展示了本文模型的指令跟随能力。
在下表 4 中给出了 MJHQ FID-30k 的比较。计算 FID 的图像是通过 CFG 因子 𝑤 = 2 和采样步数 30 生成的。对 CFG 因子和采样步数进行了扫频。本文的方法在所有 1.3B LLM 模型中表现最好。结果证明,Rectified Flow能够改善生成图像的质量,优于自回归模型,如 Janus。

多模态理解性能
在下表 5 中展示了我们的方法与其他方法的比较,包括理解特定模型和统一的理解与生成模型。我们的模型在所有具有相似参数数量的模型中达到了最佳性能,甚至超过了多个规模更大的理解特定方法。我们的结果表明,我们的方法协调了自回归 LLM 和Rectified Flow,在理解和生成任务中都取得了令人满意的表现。
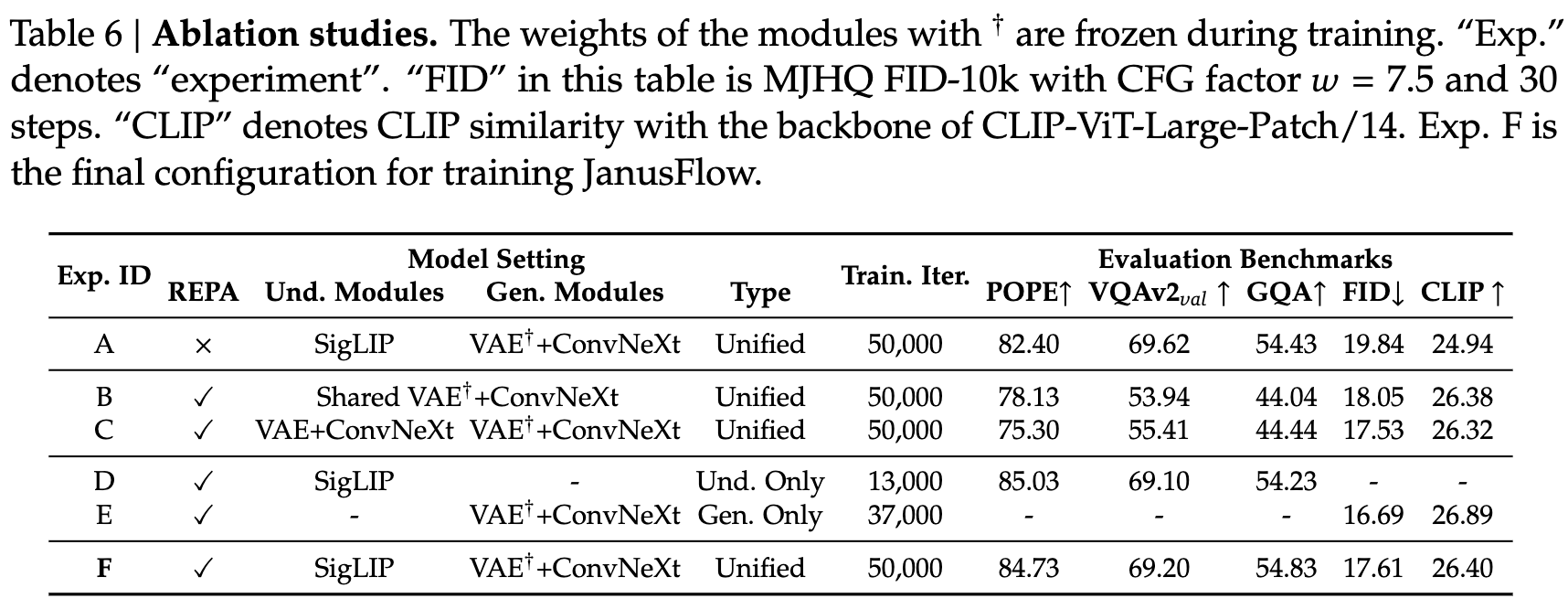
消融研究
本文进行了全面的消融研究,以验证关键设计选择的有效性。为了提高计算效率,所有消融实验均在 256 × 256 分辨率的图像上进行。除理解-only 和生成-only 变体外,所有模型均在我们的统一预训练数据集上训练了 50,000 次迭代,而理解-only 和生成-only 变体则根据其在预训练阶段的数据比例进行了相应较少的训练迭代。这些消融研究的定量结果见下表 6。
表示对齐的影响
Exp. A 和 F 之间的比较展示了在训练过程中加入表示对齐正则化的显著益处。具体来说,采用表示对齐训练的模型在 MJHQ 数据集上的 FID 分数显著较低,且 CLIP 分数较高,表明图像质量和语义对齐均得到了同步提升。值得注意的是,本文的架构与 [99] 中研究的先前工作 [65, 70] 有所不同,因为我们结合了 LLM 并在 和 之间增加了一个跳跃连接。在修改后的架构中,表示对齐的有效性表明它具有广泛的适用性和跨不同网络结构的泛化能力。
视觉编码器解耦的影响 通过 Exp. B、C 和 F 之间的比较验证了使用强大预训练视觉编码器在多模态理解中的有效性。在 Exp. B 中,采用类似 Transfusion 的设计,在 SDXL-VAE 潜在空间中为理解和生成编码器实现了共享的 ConvNeXt 块。Exp. C 则使用独立的编码器,架构和初始化参数相同,但进行了独立训练。不同配置之间的性能差异验证了在改进我们统一模型能力方面解耦视觉编码器的必要性。此外,Exp. C 和 F 中的优越结果突出了利用预训练语义视觉编码器进行多模态理解任务的好处。
与理解/生成-only 模型的公平比较
为了建立有意义的基准,评估了在相同条件下训练的任务特定模型——使用相同的预训练数据集、基础设施和超参数。Exp. D 和 E 代表了这些专门的模型,它们使用与统一模型相匹配的数据量进行了训练,如前面表 6 所示。Exp. F 与这些任务特定基线之间的最小性能差距表明,本文的统一框架成功地将理解和生成能力集成在一起,且不会在任何任务的性能上造成显著的妥协。
定性结果
本文展示了 JanusFlow 方法在图像生成和理解任务上的定性评估。下图 1(b) 和图 4 展示了 JanusFlow 在图像生成方面的能力。这些结果展示了我们生成的图像在视觉质量上的优越性,并且证明了我们的框架能够忠实地执行各种指令。


在多模态理解方面,下图 5 展示了示例对话,展示了我们的模型在不同场景下的理解能力。这些互动展示了模型在自然语言对话中理解和推理视觉内容的能力。

结论
本文提出了 JanusFlow,一种成功地将自回归模型和Rectified Flow模型融合的统一框架,适用于多模态理解和生成任务。广泛的实验表明,这种统一方法在性能上与任务特定模型相当。成功整合这两种根本不同的模型架构,不仅解决了当前多模态学习中的挑战,还为未来训练统一模型的研究开辟了新的可能性。
参考文献
[1] JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation