小葳 | 智能进化论
2025年开年,凭借与顶尖模型相当的性能、极高的成本效益与开源模式,DeepSeek系列模型成为搅动全球AI行业的新星。DeepSeek应用上线仅20天,日活就突破了2000万,这让其超越ChatGPT成全球增长最快的AI应用。
DeepSeek的横空出世,并没有改变模型争霸的本质——顶尖模型不断刷新性能、成本、速度的极限,不断为全球头部大模型的比拼按下快进键。
在用户端,使用DeepSeek模型很简单,下载APP或在网页端直接使用就可以了。然而DeepSeek在企业端的应用,还需要跨越很多挑战。帮助企业解决DeepSeek在生产场景的应用,更像一场看不见硝烟的隐形战场。

过去一周,全球各大云计算厂商纷纷上线DeepSeek模型,通过更灵活、安全、稳定的云端部署方式,试图拉平DeepSeek与企业应用之间的鸿沟。比如,1月31日亚马逊云科技率先宣布DeepSeek-R1模型已在Amazon Bedrock Marketplace和Amazon SageMaker JumpStart全面上线,并提供四种部署方式。
由此看出,模型争霸只是表面,企业级AI真正的竞争在于工程化落地能力,而云服务商将成为关键推动者。
企业要真正用好DeepSeek,需要跨越哪些挑战?云端部署大模型又能带来哪些价值?我们不妨以亚马逊云科技对DeepSeek R1模型的支持为例,做个拆解。

工程化能力
从模型到企业应用的挑战
当AI大模型从消费者端走向产业战场,工程化能力成为决定胜负的关键壁垒。智能进化论认为,企业部署DeepSeek等顶尖模型时,需要跨越性能适配、成本悬崖和安全鸿沟三重挑战。
性能适配:从通用智能到垂直场景的最后一公里
模型性能的工程化考验首先体现在场景适配层面。以DeepSeek为例,其技术迭代速度已超越传统AI模型的演进周期。
从2014年12月推出的 DeepSeek-V3模型;到2025年1月20日发布的参数规模达6710亿的DeepSeek-R1、DeepSeek-R1-Zero模型,以及参数范围覆盖15亿至700亿的DeepSeek-R1-Distill系列模型;再到2025年1月27日最新发布的多模态模型Janus-Pro-7B,DeepSeek家族短时间内迅速壮大,企业如何根据不同类型、不同参数模型,完成场景最佳适配是挑战。
除了模型版本、尺寸管理难题,企业还面临不同智能体协同调度、根据自身私有数据进行定制优化等系统工程。
成本悬崖:从百万硬件到弹性算力的范式革命
AI模型本地化部署的成本门槛正在倒逼企业转向云端弹性架构。
如果要完整部署DeepSeek R1并实现完美推理和响应,需要如Amazon EC2 P5e性能级别的硬件和配套工具。以Amazon EC2 P5e的48xlarge型号为例,单个实例包含8颗H200 GPU,仅算力成本就需要至少上百万人民币。在算力之外,大模型要实现高阶水平的推理效果,所需的网络、数据存储成本亦不容小觑。
安全鸿沟:从传统安全到负责任AI的系统工程
安全可控是大模型在企业深度应用的首要原则。大模型安全已超越传统网络安全范畴,形成包含数据隐私、可信度、可解释性、伦理合规在内的立体安全体系。这一完整的安全体系,仅靠单一企业自身的力量很难实现。
02
三大优势
企业用好DeepSeek的路径拆解
针对上述工程化挑战,亚马逊云科技通过全栈式创新构建三大优势,为企业运用全球领先模型提供三大独特优势。
第一, 为企业级AI量身定制的云端基础设施
云是企业运用生成式AI最好的方式。
在基础设施层,亚马逊云科技提供从芯片、网络到开发平台在内的全栈创新。基于自研芯片Amazon Trainium2的EC2 Trn2实例,实现比同时期GPU实例性价比高30%-40%。第二代UltraCluster网络架构,支持超过20,000个GPU协同工作,带宽达10Pb/s,延迟低于10ms,可将模型训练时间缩短至少15%。
新一代Amazon SageMaker将快速SQL分析、PB级大数据处理、数据探索和集成、模型开发和训练以及生成式AI等功能一站式集成,非常适合进行高级定制、训练和部署模型的企业。
第二, 多样化的模型选择
目前,多模型混用已经成为企业使用生成式AI的主流方式。企业会根据不同的场景需求,根据不同的延迟、成本、微调能力、知识库协调能力、多模态支持能力等,对模型进行取舍。显然,强如DeepSeek也不是万能的。
“不会有一个模型一统天下”,也是亚马逊在技术发展历程上的洞察。
亚马逊CEO Andy Jassy在此前的演讲中表示:“就像数据库领域,探讨了10年,大家会使用各种各样的关系型数据库或者非关系型数据库。当我们让开发者自由选择他们想要使用的模型时,模型的多样性显而易见。我们一次又一次地学到同样的教训:永远不会有单一的工具能够统治世界。”
目前Amazon Bedrock平台已支持AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI、Luma AI和poolside等公司的领先模型。Amazon Bedrock Marketplace功能能够为客户提供100多个热门、新兴及专业模型,其中就包括DeepSeek-R1。

第三, 企业级AI工具全家桶
解决模型的工程化问题需要大量专业工具,亚马逊云科技提供的工具集全家桶几乎涵盖企业级AI创新的方方面面,包括四类:
优化效果、延迟和成本:如低延迟优化推理、模型蒸馏、提示词缓存等功能。以模型蒸馏功能为例,它能够将特定知识从功能强大的大模型转移到更小、更高效的模型,运行速度最快可提高500%,成本降低75%。
基于企业自有数据的定制优化:模型微调功能,知识库功能现已支持GraphRAG等图数据。Amazon Bedrock Data Automation功能可以从非结构数据中提取信息,并将其转换为结构化格式。
负责任AI的安全和审查:Amazon Bedrock和Amazon SageMaker中的企业级安全功能,保障企业数据不会与模型提供商共享,也不会被用于改进模型。Amazon Bedrock Guardrails功能提供自动推理检查功能,帮助企业识别生成内容的事实性错误,提升生成回答的准确性。
实现复杂功能的多智能体功能:Amazon Bedrock多智能体协作功能,使客户能够轻松地构建和协调专业智能体来执行复杂的工作流程,通过编排多个并行工作的智能体来加速任务。
03
极简部署
降低企业AI创新门槛
目前针对DeepSeek-R1模型的云端部署,亚马逊云科技提供以下4种方式:
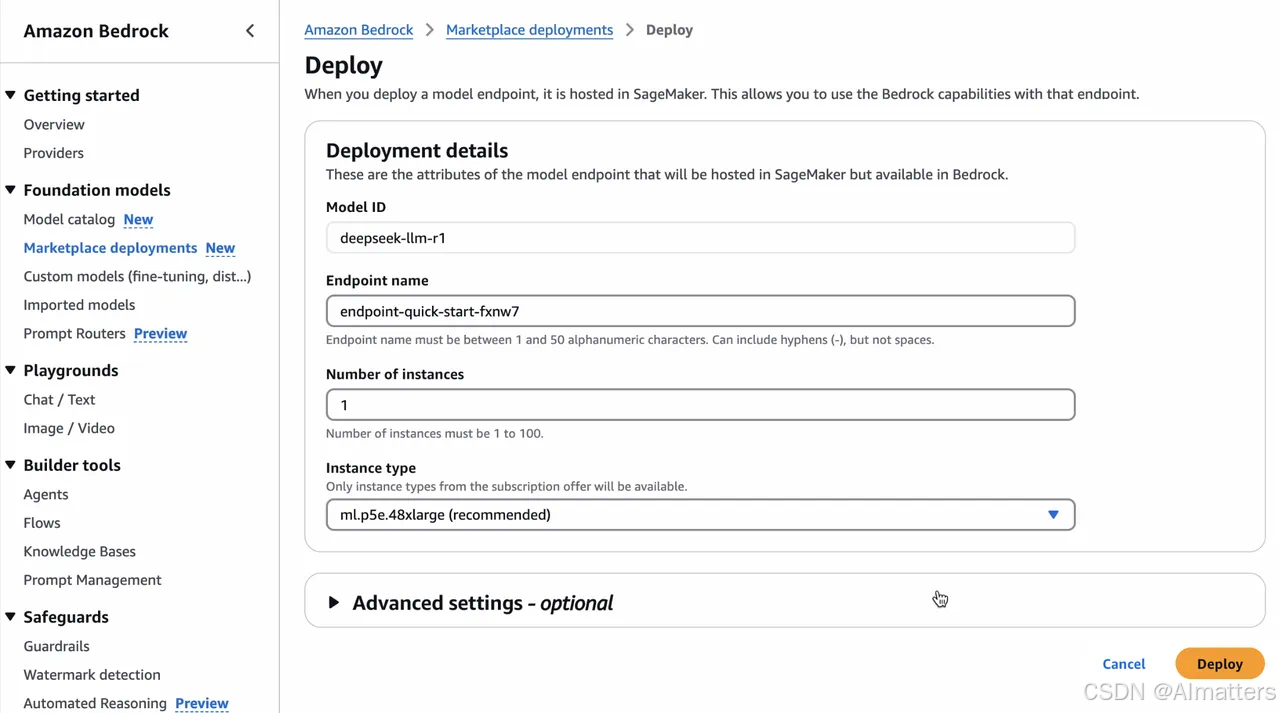
第一, 在Amazon Bedrock Marketplace部署DeepSeek-R1模型
通过Amazon Bedrock Marketplace部署DeepSeek-R1,可选实例包括EC2 P5e的48xlarge型号,单个实例包含8颗H200 GPU,以及3200Gbps的网络带宽,充分满足DeepSeek-R1的性能需求。
用户只需提供一个端点名称、选择实例数量、选择实例类型,就可以直接部署DeepSeek-R1模型。
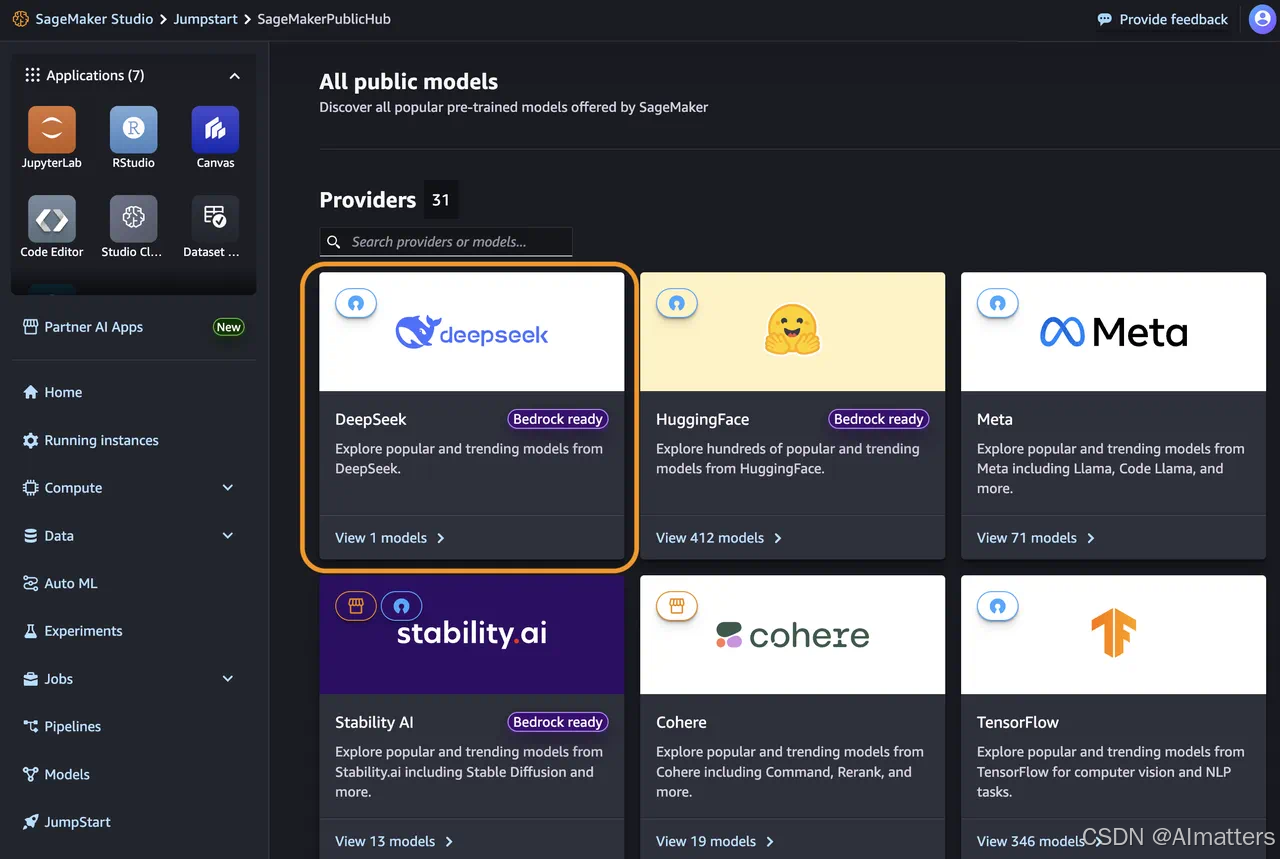
第二, 通过Amazon SageMaker JumpStart部署DeepSeek-R1模型
Amazon SageMaker JumpStart是一个机器学习中心,提供基础模型、内置算法以及预构建的机器学习解决方案,用户只需点击几次即可完成模型部署。
第三,利用Amazon Bedrock的自定义模型导入功能部署DeepSeek-R1-Distill模型
这种方式支持自定义导入参数规模在15亿到700亿之间的DeepSeek-R1-Distill Llama模型,可以利用6710亿参数的大型DeepSeek-R1模型,也可以蒸馏训练更小、更高效的模型。
第四, 使用Amazon Trainium和Amazon Inferentia部署DeepSeek-R1-Distill模型
此外,在价格方面,无论Amazon Bedrock Marketplace、Amazon SageMaker JumpStar以及Amazon EC2任何一种部署方式,用户仅需支付基于所选推理实例小时数的基础设施费用。
结语
在大模型争霸的时代浪潮下,DeepSeek 的异军突起与云服务商的深度赋能,共同勾勒出企业级 AI 应用的崭新蓝图。
基础模型性能的竞赛固然重要,但真正决定 AI 能否在企业应用场景开花结果的,是工程化落地能力与AI云服务的坚实支撑。
END
本文为「智能进化论」原创作品