目录
2.在prometheus中配置alertmanager的地址信息。
(5)目前磁盘没有达到10%, 我们这里配合下触发这个报警规则(注意此操作在node01被监控端操作)
Prometheus告警简介:
Prometheus 会一直盯着我们设定的各种指标和数据,就好像是在站岗放哨。当这些指标的数据达到了我们事先规定的某个不太好的状态,比如服务器负载过高、某个服务出错等等,它就会发出警报。
这些警报会被送到一个叫 Alertmanager 的地方,它就像是个“警报管理员”,会把这些警报整理好,按照我们要求的方式,比如发邮件、在系统里弹窗等,告诉相关的人,让大家知道出问题啦,需要赶紧去处理。这样我们就能及时发现和应对可能出现的各种状况
Alertmanager概述:
在Prometheus的报警系统中,是分为两个部分的, 规则是配置在prometheus中的, prometheus组件完成报警推送给alertmanager的, alertmanager然后管理这些报警信息,包括静默、抑制、聚合和通过电子邮件、on-call通知系统和聊天平台等方法发送通知。
下载Alertmanager源码包
方法一:
Linux服务器直接下载:
[root@prometheus ~]# wget -O /usr/src/alertmanager-0.27.0.linux-amd64.tar.gz https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-amd64.tar.gz
方法二:
使用浏览器下载然后上传至服务器的/usr/src目录下(下载速度会快一些)
1.安装和部署Alertmanager
(1)解包
[root@prometheus src]# tar xf alertmanager-0.27.0.linux-amd64.tar.gz
[root@prometheus src]# mv alertmanager-0.27.0.linux-amd64 /usr/local/prometheus/alertmanager
(2)制作alertmanager服务启动文件
[root@prometheus ~]# vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
After=network.target
[Service]
Restart=no-failure
WorkingDirectory=/usr/local/prometheus/alertmanager
ExecStart=/usr/local/prometheus/alertmanager/alertmanager
[Install]
WantedBy=multi-user.target-------------------------------------------------------------------------------
重新加载服务启动文件
[root@prometheus ~]# systemctl daemon-reload
(3)启动并设置开机自启
[root@prometheus ~]# systemctl start alertmanager
[root@prometheus ~]# systemctl enable alertmanager
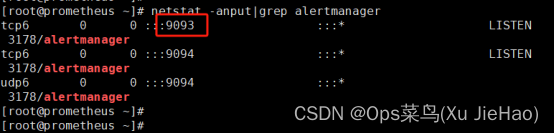
(4)查看alertmanager默认进程号
[root@prometheus ~]# netstat -anput|grep alertmanager
2.在prometheus中配置alertmanager的地址信息。
部署完毕alertmanager, 需要告知prometheus告警信息推送的位置, 通过如下配置即可完成。相对比较简单。
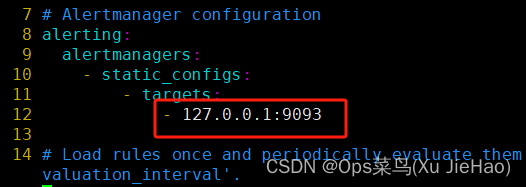
[root@prometheus ~]# vim /usr/local/prometheus/prometheus.yml
###alertmanager安装在哪个服务器就在Prometheus文件中写哪个ip地址
12 - 127.0.0.1:9093
(2)重启Prometheus服务
[root@prometheus ~]# systemctl restart prometheus
3.在prometheus中设置报警规则
为了能先走通流程,这里的报警规则先弄一个简单一点的
[root@prometheus ~]# mkdir /usr/local/prometheus/rules
[root@prometheus ~]# vim /usr/local/prometheus/prometheus.yml
15 rule_files:
16 - "rules/*.yml"
17 #- "second_rules.yml"

(2)设置告警规则
[root@prometheus ~]# vim /usr/local/prometheus/rules/disk.yml
groups:
- name: node-alert
rules:
- alert: disk-full
expr: (1-(node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"})) * 100 > 10
for: 1m
labels:
serverity: page
annotations:
summary: "{{ $labels.instance }} disk full "
description: "{{ $labels.instance }} disk > {{ $value }} "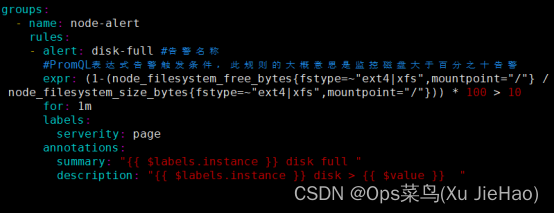
解释:
Alert: 告警规则的名称
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
summary描述告警的概要信息
description用于描述告警的详细信息。同时Alertmanager的UI也会根据这两个标签值,显示告警信息。
(3)重启prometheus服务
[root@prometheus ~]# systemctl restart prometheus
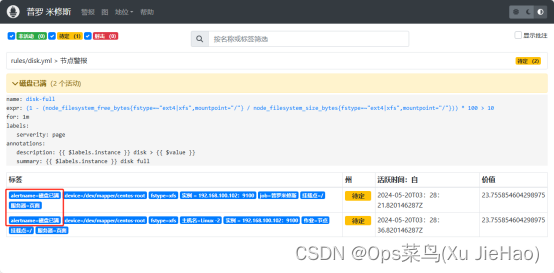
(4)可以在web界面看到如下信息

(5)目前磁盘没有达到10%, 我们这里配合下触发这个报警规则(注意此操作在node01被监控端操作)
[root@node01 ~]# df -h|grep "/$"

#手工生成一个大文件(10G)
[root@node01 ~]# dd if=/dev/zero of=/opt/bigfile bs=1M count=10000
##查看是否在前台告警
4.在alertmanager配置接受者信息等
上面的消息信息已经从prometheus推送给alertmanager了, 我们已经可以在alertmanager的web管理界面看到对应的报警信息,但是我们还没有配置如何让alertmanager把这些信息推送我们的社交软件上面去。
由于邮件系统大家用的比较多,这里就是用qq邮箱进行后续试验。
(1)进入alertmanager的主配进行更改
[root@prometheus ~]# vim /usr/local/prometheus/alertmanager/alertmanager.yml
注意:标红的地方一定要填自己的,格式一定要与文档一直检查清楚,不然后续会报错
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]' ##qq邮箱号
smtp_auth_username: '[email protected]' ###qq邮箱号
smtp_auth_password: 'uajwuvyxlfoisdbh' ###邮箱授权码
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
email_configs:
- send_resolved: true
to: 135257182[email protected]
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
(2)重启使其生效
[root@prometheus ~]# systemctl restart alertmanager
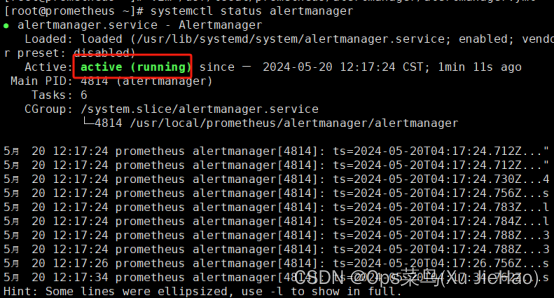
(3)查看是否启动成功
[root@prometheus ~]# systemctl status alertmanager
##如果失败则要认真检查刚才更改的alertmanager主配置文件格式
5.验证:
此操作在node01被监控端
(1)查看磁盘使用率
[root@node01 ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 50G 3.9G 47G 8% /
(2)清空10G文件再次生成
[root@node01 ~]# >/opt/bigfile
[root@node01 ~]# dd if=/dev/zero of=/opt/bigfile bs=1M count=10000 &
(3)查看是否收到告警信息
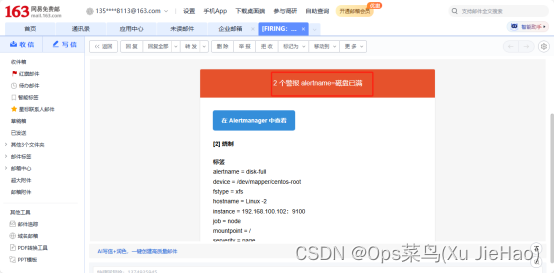
注意: 如果调试过程中有问题, 请查看/var/log/message信息,获取alertmanager发送邮件的错误信息。