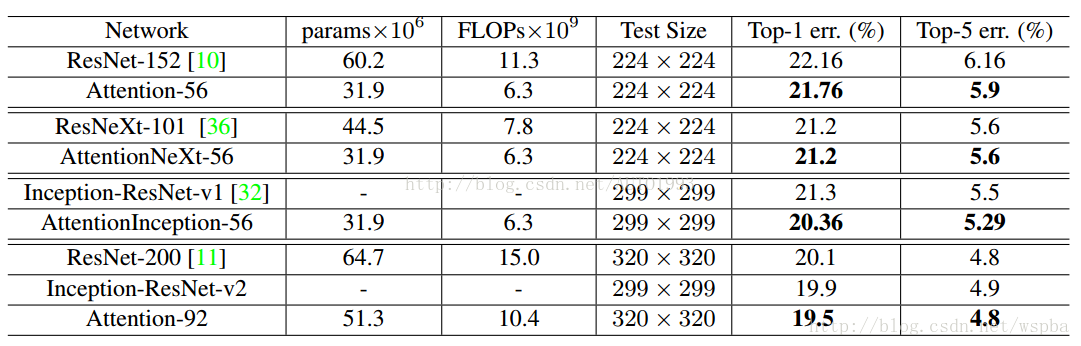
阅读笔记(paper+code):Residual Attention Network for Image Classification
代码链接:https://github.com/fwang91/residual-attention-network
深度学习中的attention,源自于人脑的注意力机制,当人的大脑接受到外部信息,如视觉信息、听觉信息时,往往不会对全部信息进行处理和理解,而只会将注意力集中在部分显著或者感兴趣的信息上,这样有助于滤除不重要的信息,而提升信息处理的效率。最早将Attention利用在图像处理上的出发点是,希望通过一个类似于人脑注意力的机制,只利用一个很小的感受野去处理图像中Attention的部分,降低了计算的维度。而后来慢慢的,有人发现其实卷积神经网络自带Attention的功能,比方说在分类任务中,高层的feature map所激活的pixel也恰好集中在与分类任务相关的区域,也就是salience map,常被用在图像检测和分割上。那么如何利用Attention来提升模型在分类任务上的性能呢?本文提供了一种新的思路。
首先看作者所说本文的三大贡献:
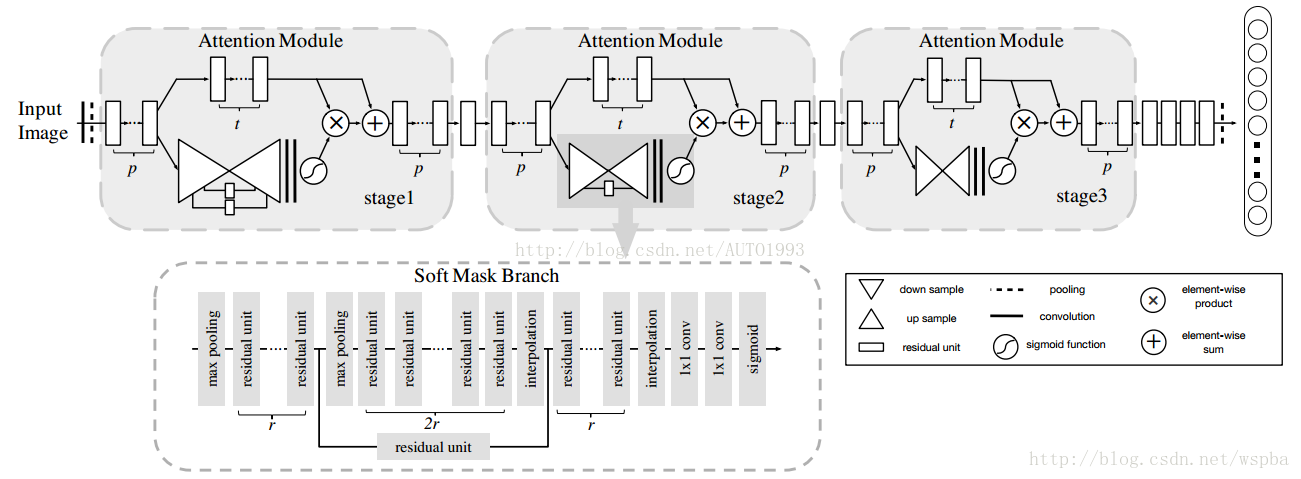
1.提出了一种可堆叠的网络结构。与ResNet中的Residual Block类似,本文所提出的网络结构也是通过一个Residual Attention Module的结构进行堆叠,可使网络模型能够很容易的达到很深的层次。
2.提出了一种基于Attention的残差学习方式。与ResNet也一样,本文做提出的模型也是通过一种残差的方式,使得非常深的模型能够容易的优化和学习,并且具有非常好的性能。
3.Bottom-up Top-down的前向Attention机制。其他利用Attention的网络,往往需要在原有网络的基础上新增一个分支来提取Attention,并进行单独的训练,而本文提出的模型能够就在一个前向过程中就提取模型的Attention,使得模型训练更加简单。
从上面前两点依然发现本文所提出的方法和ResNet没多大的区别,但是把1、2、3点融合起来,就成了本文的一个亮点,请看:
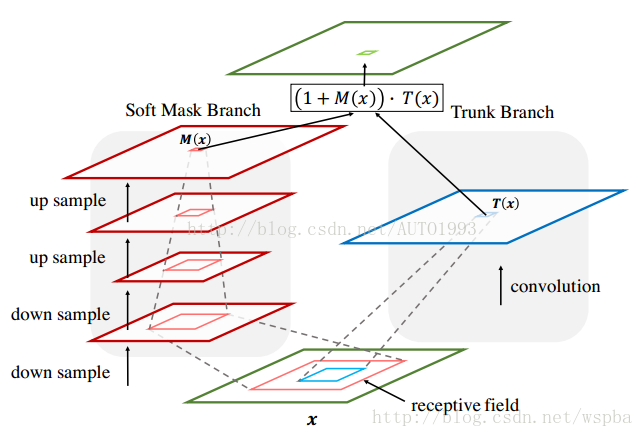
上图基本上可以囊括本位的绝大部分内容,对于某一层的输出featuremap,也就是下一层的输入,对于一个普通的网络,只有右半部分,也就是TrunkBranch,作者在这个基础上增加了左半部分:Soft Mask Branch——一个Bottom-up Top-down的结构。
Bottom-up Top-down的结构首先通过一系列的卷基和pooling,逐渐提取高层特征并增大模型的感受野,之前说过高层特征中所激活的Pixel能够反映Attention所在的区域,于是再通过相同数量的up sample将feature map的尺寸放大到与原始输入一样大(这里的upsample通过deconvolution来实现,可以利用bilinear interpolation 也可以利用deconvolution自己来学习参数,可参考FCN中的deconvolution使用方式),这样就将Attention的区域对应到输入的每一个pixel上,我们称之为Attention map。Bottom-up Top-down这种encoder-decoder的结构在图像分割中用的比较多,如FCN,也正好是利用了这种结构相当于一个weakly-supervised的定位任务的学习。