A Surname Classification System based on MLP
基于MLP的姓氏分类系统
This notebook serves as my learning journey into the Multilayer Perceptron (MLP), which is a fundamental type of Feedforward Neural Network. Throughout this article, I will be undertaking the following tasks and documenting my learning process:
-
Master the Application of Multi-layer Perceptron in Multi-class Classification:
- Using the example of “Surname Classification with Multi-layer Perceptron” to understand the practical implementation.
-
Understand the Impact of Different Neural Network Layers:
- Analyzing how each type of neural network layer affects the size and shape of the data tensors it processes.
-
Experiment with the SurnameClassifier Model:
- Introducing dropout into the model and observing the changes in the results.
In addition to these tasks, I will also attempt to explain some of the challenges I encountered and clarify the underlying principles as best as I can. Even though my English is not such good, I choose English to be my article’s language, so that I can improve my English.
0 说明
本博客最开始作为笔者一次课程实验的汇报成果而开始写作,能力和精力实在有限,文章质量欠佳,后续笔者会更新更加实用有料的博客,欢迎关注。各位大佬轻喷。博客使用英文写作,原因一笔者最近在学习英语,希望创造一些练习的机会;原因二是在课程实验实施的环境中,使用中文模式无法使用一些快捷键。在完成实验的前提下,我还尽我所能阐述了必要原理,并黏贴了一些我所参考或推荐的网址。下面,正文开始!
1 Look into MLP
1.1 Perceptron (which we learnt in Lab1)
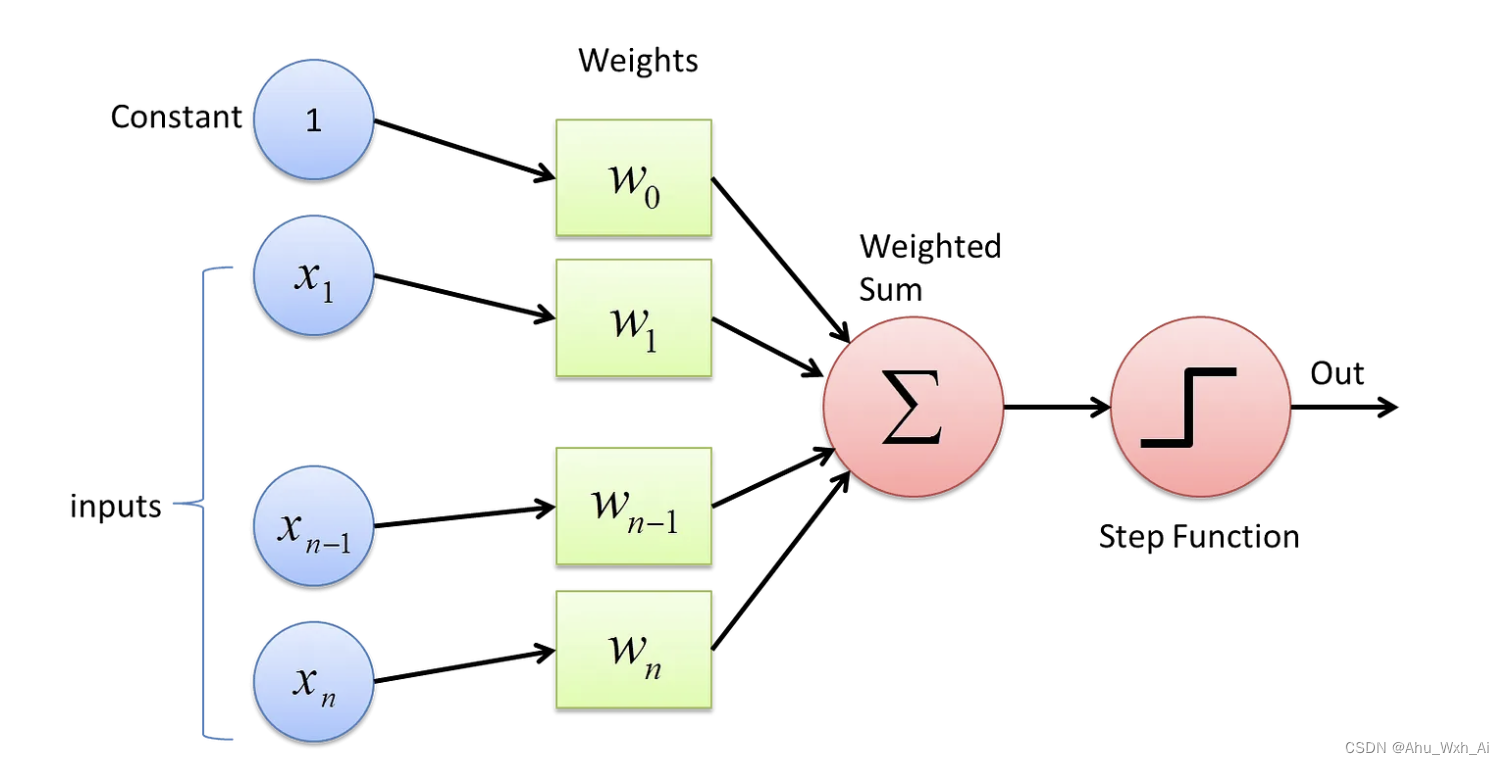
The perceptron is a fundamental building block of neural networks. It’s a type of artificial neuron that can perform binary classifications. The perceptron takes a set of inputs, applies weights to them, sums them up, and passes the result through an activation function to produce an output.
Here’s a simple diagram of a perceptron:
x1 ---- w1
\
x2 ---- w2
\
x3 ---- w3 ----> Σ (sum) ----> Activation Function ----> Output
/
... ----
/
xn ---- wn
1.2 How a Perceptron Works
- Inputs: Each input ( x 1 , x 2 , . . . , x n ) ( x_1, x_2, ..., x_n) (x1,x2,...,xn) represents a feature of the data.
- Weights: Each input has an associated weight ( w 1 , w 2 , . . . , w n ) ( w_1, w_2, ..., w_n) (w1,w2,...,wn). These weights are learned during the training process.
- Summation: The perceptron computes a weighted sum of the inputs:
z = ∑ i = 1 n w i x i + b z = \sum_{i=1}^{n} w_i x_i + b z=i=1∑nwixi+b
where $ b $ is the bias term. - Activation Function: The summation result $ z $ is then passed through an activation function & f &. For a simple perceptron, a common choice is the step function:
f ( x ) = { 1 if z ≥ 0 0 if z < 0 f(x)= \begin{cases} 1 & \text{if } z \ge 0 \\ 0 & \text{if } z < 0 \end{cases} f(x)={10if z≥0if z<0
The activation function determines the perceptron’s output, which is typically binary (0 or 1).
It can be mathematically represented as:
y ^ = f ( ∑ i = 1 n w i x i + b ) \hat{y} = f\left(\sum_{i=1}^{n} w_i x_i + b\right) y^=f(i=1∑nwixi+b)
where y ^ \hat{y} y^ is the predicted output, $ x_i $ are the input features, $ w_i$are the weights, $ b $ is the bias term and $ f $ is the activation function.
Consider a simple binary classification problem where we want to determine if an email is spam (1) or not spam (0). The perceptron takes features of the email as inputs (e.g., presence of certain keywords, length of the email, etc.), computes the weighted sum, applies the activation function, and produces the output: spam or not spam. Of course, due to the structure is to simple, the result may not be such good. There’s a article by Medium which’s far more good than my arcticle, and this is its link: https://towardsdatascience.com/what-the-hell-is-perceptron-626217814f53
1.3 Drawbacks of the Perceptron
While the perceptron is a fundamental concept in neural networks, it has some significant limitations:
-
Linear Separability: The perceptron can only solve problems that are linearly separable. This means it can only classify data points that can be separated by a straight line (in two dimensions), a plane (in three dimensions), or a hyperplane (in higher dimensions). For example, the XOR problem, which is not linearly separable, cannot be solved by a single perceptron.
-
Limited Expressiveness: Because it only involves a single layer of computation, a single-layer perceptron cannot capture complex patterns or relationships in the data. It lacks the ability to learn higher-order features.
1.4 How MLP Solves These Drawbacks
The Multilayer Perceptron (MLP), also known as a Feedforward Neural Network, addresses these drawbacks by introducing multiple layers of neurons. Here’s how MLP overcomes the limitations of a single-layer perceptron:
-
Non-linear Activation Functions: MLPs use non-linear activation functions (such as ReLU, sigmoid, or tanh) in hidden layers. These non-linearities allow the network to learn complex, non-linear relationships between the input and output.
-
Multiple Layers (Hidden Layers): By stacking multiple layers of neurons (hidden layers) between the input and output layers, MLPs can learn hierarchical representations of the data. Each layer captures different levels of abstraction:
- First Layer: Captures simple patterns or features.
- Subsequent Layers: Combine these simple patterns to capture more complex features.
-
Universal Approximation: An MLP with at least one hidden layer and non-linear activation functions can approximate any continuous function to any desired degree of accuracy, given sufficient neurons in the hidden layer. This is known as the Universal Approximation Theorem.
1.5 Architecture of an MLP
An MLP consists of an input layer, one or more hidden layers, and an output layer:
Input Layer --> Hidden Layer(s) --> Output Layer
x1 x2 h1 h2 h3 y1 y2
\ / \ / / \ /
h1 h1 h2 ... h1 h2 ...
/ \ / / \ / /
o1 o2 o1 o2 o3 o1 o2
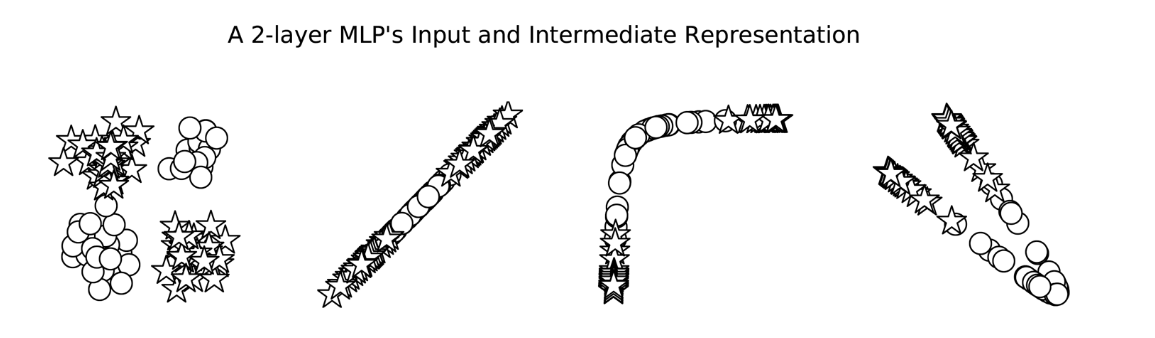
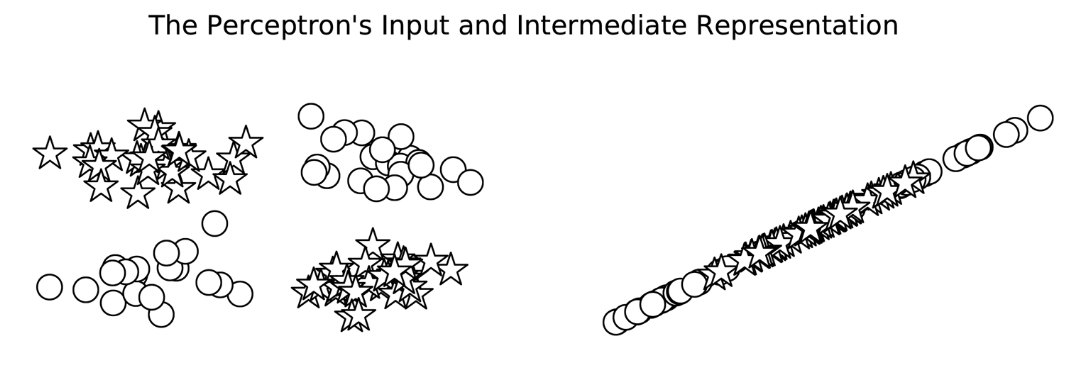
The XOR problem is a classic example that a single-layer perceptron cannot solve because the data points are not linearly separable. However, an MLP with one hidden layer can solve the XOR problem.
While the perceptron is limited to solving only linearly separable problems, the MLP overcomes these limitations through its layered architecture and non-linear activation functions. This allows MLPs to learn and approximate complex, non-linear functions, making them much more powerful and versatile for a wide range of classification and regression tasks.
For instance, MLP model can solve the problems below whereas Percertron can’t.

2 Implementing MLPs in PyTorch
This section serves as a guide to getting started with MLP using PyTorch, a machine learning library based on the Torch library. PyTorch is widely recognized as one of the two most popular machine learning libraries, alongside TensorFlow. It offers free and open-source software released under the modified BSD license. According to our professor, PyTorch is currently prevailing in the field. In this part, I will focus more on providing code examples rather than extensive explanations.
# import package
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(intermediate)
if apply_softmax:
output = F.softmax(output, dim=1)
return output
Let’s take a example:
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
Through the output, we can tell the MLP implemention by PuTorch consists of 2 fully connected layers: the first layer takes a 3-dimensional input and produces a 100-dimensional output, while the second layer takes this 100-dimensional input and generates a 4-dimensional output, representing the number of classification classes.
import torch # dl
def describe(x):
"""
This function is used to describe tensor
"""
print("Type: {}".format(x.type()))
print("Shape/size: {}".format(x.shape))
print("Values: \n{}".format(x))
x_input = torch.rand(batch_size, input_dim)
describe(x_input)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 3])
Values:
tensor([[0.4838, 0.0619, 0.5794],
[0.9018, 0.9110, 0.3688]])
Let’s put the tensor x into our MLP model and see what’ll happen.
y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[-0.3002, -0.0441, -0.0726, -0.1772],
[-0.3877, 0.1662, 0.0653, 0.0621]], grad_fn=<AddmmBackward>)
We can conclude:
MLPs are linear layers that transform tensors into other tensors. Nonlinearities are incorporated between each pair of linear layers to introduce nonlinearity and enable the model to deform the vector space. In a classification scenario, this deformation should result in linear separability among classes. Alternatively, an MLP’s outputs can be interpreted as probabilities using a softmax function; however, it is not advisable to combine softmax with a specific loss function due to potential exploitation of advanced mathematical/computational shortcuts.
3 Our Project:Surname Classification with a MLP
In this section the MLP model will be implemented to predict an individual’s nationality based on their surname using The Surname Dataset.
3.1 About The Surname Dataset
The Surname dataset, which collects 10,000 surnames from 18 different countries, collected by the authors from different sources of names on the Internet. The first feature is that it is rather unbalanced. The second feature is that there is a valid and intuitive relationship between nationality and last name orthography. Some spelling variants are very strongly linked to the country of origin.
First, we will munging the dataset.
import collections
import numpy as np
import pandas as pd
import re
from argparse import Namespace
args = Namespace(
raw_dataset_csv="surnames.csv",
train_proportion=0.7,
val_proportion=0.15,
test_proportion=0.15,
output_munged_csv="surnames_with_splits.csv",
seed=1337
)
# Read raw data
surnames = pd.read_csv(args.raw_dataset_csv, header=0)
surnames.head()
| surname | nationality | |
|---|---|---|
| 0 | Woodford | English |
| 1 | Coté | French |
| 2 | Kore | English |
| 3 | Koury | Arabic |
| 4 | Lebzak | Russian |
The raw data’s header is shown above.
# Unique classes
set(surnames.nationality)
{'Arabic',
'Chinese',
'Czech',
'Dutch',
'English',
'French',
'German',
'Greek',
'Irish',
'Italian',
'Japanese',
'Korean',
'Polish',
'Portuguese',
'Russian',
'Scottish',
'Spanish',
'Vietnamese'}
The countries/regions are shown above.
# Splitting train by nationality
# Create dict
by_nationality = collections.defaultdict(list)
for _, row in surnames.iterrows():
by_nationality[row.nationality].append(row.to_dict())
# Create split data
final_list = []
np.random.seed(args.seed)
for _, item_list in sorted(by_nationality.items()):
np.random.shuffle(item_list)
n = len(item_list)
n_train = int(args.train_proportion*n)
n_val = int(args.val_proportion*n)
n_test = int(args.test_proportion*n)
# Give data point a split attribute
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:]:
item['split'] = 'test'
# Add to final list
final_list.extend(item_list)
# Write split data to file
final_surnames = pd.DataFrame(final_list)
final_surnames.split.value_counts()
train 7680
test 1660
val 1640
Name: split, dtype: int64
# Write munged data to CSV
final_surnames.to_csv(args.output_munged_csv, index=False)
Now we have got the splited dataset by Nationality.
3.2 Vocabulary, Vectorizer, and DataLoader
To classify surnames using characters, we convert surname strings into vectorized minibatches using a vocabulary, a vectorizer, and a DataLoader.
3.2.1 The Vocabulary Class
The Vocabulary class is a utility for handling text data in NLP tasks. It manages the mapping between tokens and indices, handles unknown tokens, and supports serialization and deserialization for saving and loading the vocabulary. This class is essential for converting text data into a numerical format suitable for machine learning models.
# import package
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook
class Vocabulary(object):
"""Class to process text and extract vocabulary for mapping"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): a pre-existing map of tokens to indices
add_unk (bool): a flag that indicates whether to add the UNK token
unk_token (str): the UNK token to add into the Vocabulary
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
""" returns a dictionary that can be serialized """
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
""" instantiates the Vocabulary from a serialized dictionary """
return cls(**contents)
def add_token(self, token):
"""Update mapping dicts based on the token.
Args:
token (str): the item to add into the Vocabulary
Returns:
index (int): the integer corresponding to the token
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""Add a list of tokens into the Vocabulary
Args:
tokens (list): a list of string tokens
Returns:
indices (list): a list of indices corresponding to the tokens
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""Retrieve the index associated with the token
or the UNK index if token isn't present.
Args:
token (str): the token to look up
Returns:
index (int): the index corresponding to the token
Notes:
`unk_index` needs to be >=0 (having been added into the Vocabulary)
for the UNK functionality
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""Return the token associated with the index
Args:
index (int): the index to look up
Returns:
token (str): the token corresponding to the index
Raises:
KeyError: if the index is not in the Vocabulary
"""
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
3.2.2 THE SURNAME VECTORIZER
The SurnameVectorizer class is designed to handle the conversion of surnames and nationalities into numerical formats suitable for machine learning models. It coordinates two Vocabulary instances:
- One for converting surname characters into indices.
- One for converting nationalities into indices.
The vectorize method converts surnames into one-hot encoded vectors, making them ready for model input. The class methods from_dataframe and from_serializable provide ways to create a SurnameVectorizer from a pandas DataFrame and a serialized dictionary, respectively. The to_serializable method allows the SurnameVectorizer to be easily saved and loaded.
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab):
"""
Args:
surname_vocab (Vocabulary): maps characters to integers
nationality_vocab (Vocabulary): maps nationalities to integers
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot (np.ndarray): a collapsed one-hot encoding
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab)
def to_serializable(self):
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable()}
3.3 Load the dataset
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
Args:
surname_df (pandas.DataFrame): the dataset
vectorizer (SurnameVectorizer): vectorizer instatiated from dataset
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""Load dataset and the corresponding vectorizer.
Used in the case in the vectorizer has been cached for re-use
Args:
surname_csv (str): location of the dataset
vectorizer_filepath (str): location of the saved vectorizer
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""a static method for loading the vectorizer from file
Args:
vectorizer_filepath (str): the location of the serialized vectorizer
Returns:
an instance of SurnameVectorizer
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
"""saves the vectorizer to disk using json
Args:
vectorizer_filepath (str): the location to save the vectorizer
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
""" returns the vectorizer """
return self._vectorizer
def set_split(self, split="train"):
""" selects the splits in the dataset using a column in the dataframe """
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dictionary holding the data point's:
features (x_surname)
label (y_nationality)
"""
row = self._target_df.iloc[index]
surname_vector = \
self._vectorizer.vectorize(row.surname)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_vector,
'y_nationality': nationality_index}
def get_num_batches(self, batch_size):
"""Given a batch size, return the number of batches in the dataset
Args:
batch_size (int)
Returns:
number of batches in the dataset
"""
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
A generator function which wraps the PyTorch DataLoader. It will
ensure each tensor is on the write device location.
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
3.4 The Model: Surname Classifier
In this Section, I will design a MLP network, to do the classification work above.
class SurnameClassifier(nn.Module):
""" A 2-layer Multilayer Perceptron for classifying surnames """
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate_vector = F.relu(self.fc1(x_in))
prediction_vector = self.fc2(intermediate_vector)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
def make_train_state(args):
return {'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'learning_rate': args.learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': args.model_state_file}
def update_train_state(args, model, train_state):
"""Handle the training state updates.
Components:
- Early Stopping: Prevent overfitting.
- Model Checkpoint: Model is saved if the model is better
:param args: main arguments
:param model: model to train
:param train_state: a dictionary representing the training state values
:returns:
a new train_state
"""
# Save one model at least
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# Save model if performance improved
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# If loss worsened
if loss_t >= train_state['early_stopping_best_val']:
# Update step
train_state['early_stopping_step'] += 1
# Loss decreased
else:
# Save the best model
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# Reset early stopping step
train_state['early_stopping_step'] = 0
# Stop early ?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
def compute_accuracy(y_pred, y_target):
_, y_pred_indices = y_pred.max(dim=1)
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
def set_seed_everywhere(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
args = Namespace(
# Data and path information
surname_csv="=surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="surname_mlp",
# Model hyper parameters
hidden_dim=300,
# Training hyper parameters
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# Set seed for reproducibility
set_seed_everywhere(args.seed, args.cuda)
# handle dirs
handle_dirs(args.save_dir)
Expanded filepaths:
surname_mlp/vectorizer.json
surname_mlp/model.pth
Using CUDA: False
It’s clear that we don’t have any GPU to use.
args = Namespace(
# Data and path information
surname_csv="surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/surname_mlp",
# Model hyper parameters
hidden_dim=300,
# Training hyper parameters
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# Set seed for reproducibility
set_seed_everywhere(args.seed, args.cuda)
# handle dirs
handle_dirs(args.save_dir)
Expanded filepaths:
model_storage/ch4/surname_mlp/vectorizer.json
model_storage/ch4/surname_mlp/model.pth
Using CUDA: False
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))
classifier = classifier.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# Iterate over training dataset
# setup: batch generator, set loss and acc to 0, set train mode on
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# the training routine is these 5 steps:
# --------------------------------------
# step 1. zero the gradients
optimizer.zero_grad()
# step 2. compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# step 4. use loss to produce gradients
loss.backward()
# step 5. use optimizer to take gradient step
optimizer.step()
# -----------------------------------------
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# update bar
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# Iterate over val dataset
# setup: batch generator, set loss and acc to 0; set eval mode on
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:27: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
HBox(children=(FloatProgress(value=0.0, description='training routine', style=ProgressStyle(description_width=…
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:33: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
HBox(children=(FloatProgress(value=0.0, description='split=train', max=120.0, style=ProgressStyle(description_…
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:38: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
HBox(children=(FloatProgress(value=0.0, description='split=val', max=25.0, style=ProgressStyle(description_wid…
# compute the loss & accuracy on the test set using the best available model
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))
Test loss: 1.819154896736145;
Test Accuracy: 46.68749999999999
In the next part, I will use this trained model to do the inference work.
def predict_nationality(surname, classifier, vectorizer):
"""Predict the nationality from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
Returns:
a dictionary with the most likely nationality and its probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).view(1, -1)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.to("cpu")
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
Enter a surname to classify: McMahan
McMahan -> Irish (p=0.41)
As we input McMahan as a surname, the output of the model is Irish (p=0.41),which indicates the probability that MaMahan is an Irish surname is 0.41.
vectorizer.nationality_vocab.lookup_index(8)
'Irish'
def predict_topk_nationality(name, classifier, vectorizer, k=5):
vectorized_name = vectorizer.vectorize(name)
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
prediction_vector = classifier(vectorized_name, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# returned size is 1,k
probability_values = probability_values.detach().numpy()[0]
indices = indices.detach().numpy()[0]
results = []
for prob_value, index in zip(probability_values, indices):
nationality = vectorizer.nationality_vocab.lookup_index(index)
results.append({'nationality': nationality,
'probability': prob_value})
return results
new_surname = input("Enter a surname to classify: ")
classifier = classifier.to("cpu")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
Enter a surname to classify: McMahan
How many of the top predictions to see? 5
Top 5 predictions:
===================
McMahan -> Irish (p=0.41)
McMahan -> Scottish (p=0.25)
McMahan -> Czech (p=0.08)
McMahan -> Vietnamese (p=0.06)
McMahan -> German (p=0.05)
This is the model’s Top-K inference. The output consists of five nationalities with its probablity.
3.5 Regularizing MLPs: Weight Regularization and Structural Regularization (or Dropout)
Now, we have implemented a MLP model using The Surname Dataset, the model seem can predict an individual’s nationality based on their surname at some point. Wheares the accuracy is not so good.
In this part, we’ll regularizing the MLPs, including weight regularization and structural regularization. And we can also introduce Dropout to the MLPs.
First, what is Dropout in MLPs?
To put it simply, Dropout is a regularization technique used in the training of neural networks, including Multi-Layer Perceptrons (MLPs), to prevent overfitting. It works by randomly “dropping out” a subset of neurons during each training iteration.
-
Random Neuron Deactivation:
- During each training iteration, a fraction of neurons in each layer (except the output layer) are randomly selected and temporarily removed from the network. The probability of dropping a neuron is a hyperparameter typically denoted as ( p ) (dropout rate). For instance, if ( p = 0.5 ), then each neuron has a 50% chance of being dropped during a given iteration.
-
Training Phase:
- While training the network, dropout is applied independently to each layer. This means that each forward and backward pass uses a different subset of the network, effectively training different “thinned” versions of the network.
- Neurons that are dropped do not contribute to the forward pass (i.e., they do not participate in the computation of the output) and do not participate in the backward pass (i.e., they do not contribute to the gradient calculation).
-
Testing Phase:
- During testing, dropout is not applied. Instead, all neurons are active, but their outputs are scaled down by a factor of ( 1 - p ) to account for the increased number of active neurons compared to the training phase. This scaling ensures that the expected output at test time matches the expected output during training.
There are many Benefits of Dropout.
-
Reduces Overfitting:
- By randomly deactivating neurons during training, dropout prevents the network from becoming too reliant on any particular neurons, encouraging it to learn more robust features and representations. This randomness forces the network to be more generalized rather than memorizing the training data.
-
Improves Generalization:
- The network becomes less sensitive to the specific weights of individual neurons since different subsets of neurons are used during each training iteration. This helps the model generalize better to unseen data.
Here’s a brief overview of how dropout is typically implemented in an MLPs, which is our modelz:
-
During Training:
- For each layer, a binary mask (vector of 0s and 1s) is generated, where each element of the mask is 0 with probability ( p ) and 1 with probability ( 1 - p ).
- The activations of the layer are element-wise multiplied by this mask, effectively dropping out the corresponding neurons.
-
During Testing:
- All neurons are active, but the outputs of the neurons are scaled down by multiplying by ( 1 - p ). This scaling ensures that the sum of the neuron activations remains approximately the same as during training.
When we implement Dropout, we should consider this terms below:
- Hyperparameter Tuning: The dropout rate ( p ) is a hyperparameter that typically requires tuning. Common values range from 0.2 to 0.5.
- Performance: Dropout can increase the training time due to the randomization process and the need to perform multiple forward and backward passes with different network configurations.
- Network Architecture: Dropout is generally more beneficial for deeper networks with many parameters, where the risk of overfitting is higher.
In conclusion,Dropout is a powerful and widely used technique to improve the robustness and generalization ability of neural networks, particularly in deep learning models. By randomly deactivating neurons during training, dropout reduces overfitting and encourages the network to learn more generalized patterns, leading to better performance on unseen data.
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(F.dropout(intermediate, p=0.5))
if apply_softmax:
output = F.softmax(output, dim=1)
return output
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(F.dropout(intermediate, p=0.5))
if apply_softmax:
output = F.softmax(output, dim=1)
return output
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[-0.0696, -0.1185, 0.1770, 0.1714],
[-0.2222, 0.5156, 0.2825, -0.1982]], grad_fn=<AddmmBackward>)
4 Surname Classification with Convolutional Neural Networks
In the first part of this experiment, we delve into MLPs, neural networks built from a sequence of linear layers and nonlinear functions. MLPS are not the best tool for exploiting sequential patterns. For example, in the last name dataset, the last name can have segments (of different lengths), These segments can reveal quite a bit of information about their country of origin (such as “O” in “O 'Neill”, “opoulos” in “Antonopoulos”, “sawa” in “Nagasawa” or “Zh” in “Zhu”). These segments can be of variable length and the challenge is to capture them without explicitly encoding them.
In this section, we introduce convolutional neural networks (CNNS), a type of neural network that is well suited for detecting spatial substructures (and therefore creating meaningful spatial substructures). CNNs achieve this by scanning the input data tensor using a small number of weights. With this scanning, they produce output tensors that represent substructure detection (or non-detection).
In the rest of this section, we first describe how CNNS work and the issues that should be considered when designing CNNS. We delve into CNN hyperparameters with the goal of providing intuitive behavior and the impact of these hyperparameters on the output. Finally, we illustrate the mechanism of CNNs step by step through several simple examples. In “Example: Classifying Last Names with CNNS”, we’ll dive into a broader example.
Here is an exmaple of 2D convolution.
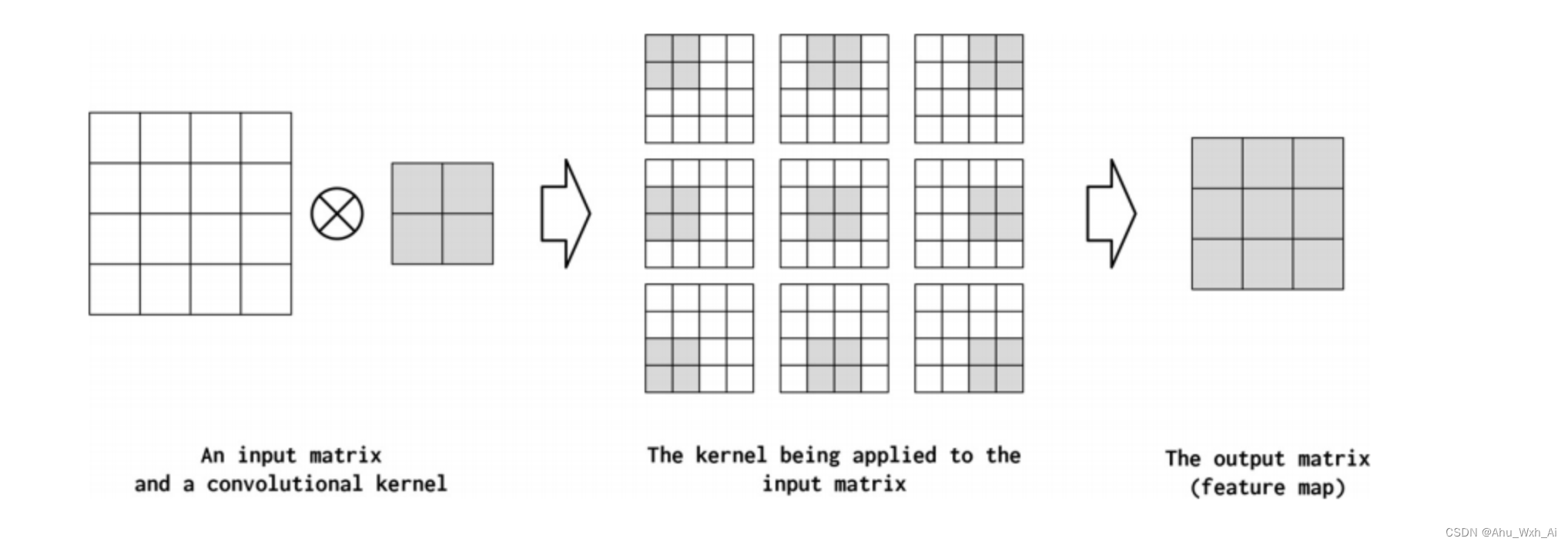
Informally, channels are the feature dimensions along each point in the input. For example, in the image, each pixel in the image corresponding to the RGB component has three channels. A similar concept can be adopted for text data when using convolutions. Conceptually, if the “pixels” in a text document are words, the number of channels is the size of the vocabulary. If we think about convolutions of characters more fine-grained, the number of channels is the size of the character set (which in this case happens to be the vocabulary). In the PyTorch convolution implementation, the number of input channels is the in_channels parameter. The convolution operation can produce multiple channels in the output (out_channels). You can think of this as a convolution operator “mapping” the input feature dimension to the output feature dimension. In the pictures below illustrate this concept.
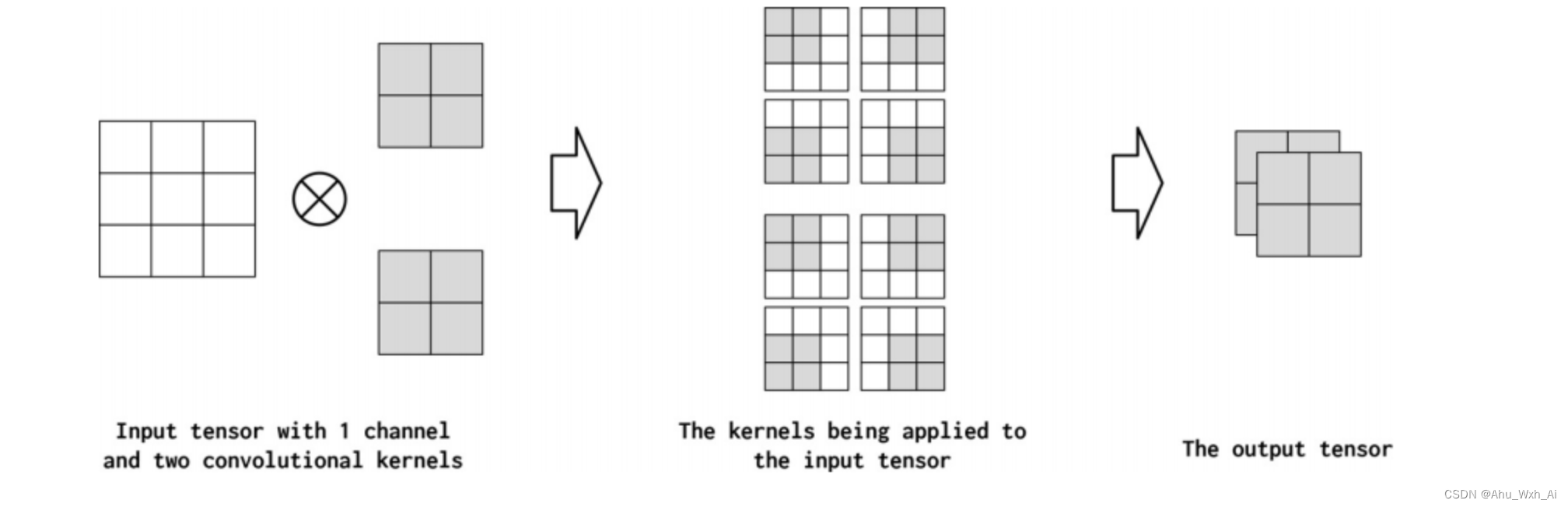
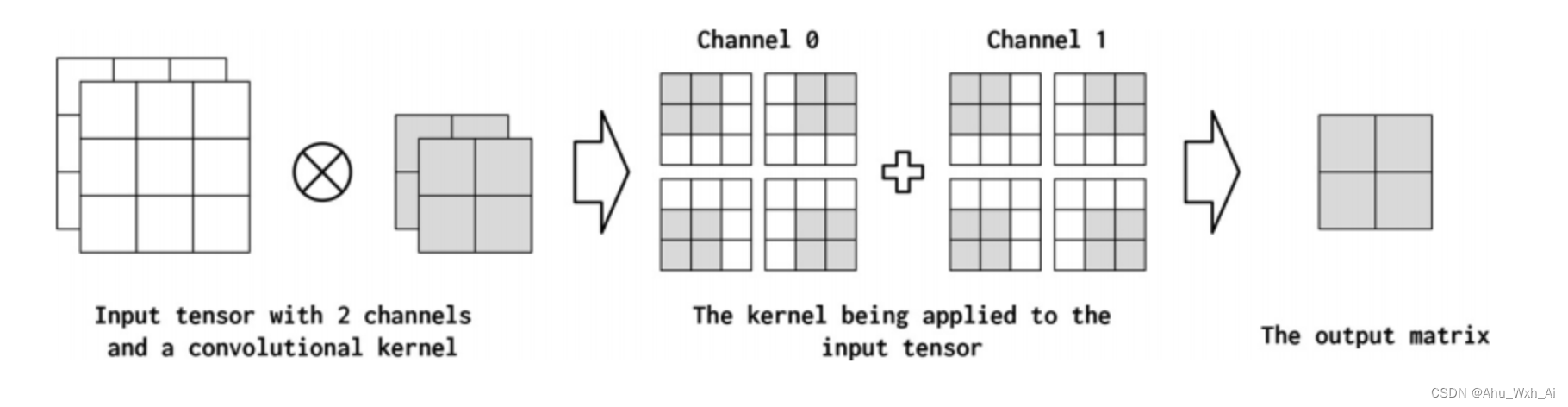
4.1 Implementation CNNs
In this section, we leverage the concepts introduced in the previous section with an end-to-end example. In general, the goal of neural network design is to find a hyperparameter configuration that can accomplish the task. We again consider the now-familiar last name classification task introduced in “Example: Last Name Classification with Multi-layer Perceptrons”, but we will use CNNs instead of MLPS. We still need to apply a final linear layer, which will learn to create prediction vectors from feature vectors created by a series of convolutional layers. This means that the goal is to determine the convolutional layer configuration that results in the desired feature vector. All CNN applications work like this: first there is a set of convolutional layers, which extract a feature map and then use it as input for upstream processing. In classification, upstream processing almost always applies linear (or fc) layers.
The implementation in this course walks through design decisions to construct a feature vector. We first construct an artificial data tensor that reflects the shape of the actual data. The size of the data tensor is three-dimensional -this is the minimum batch size for vectorizing text data. If you use a onehot vector for each character in a sequence of characters, then the sequence of onehot vectors is a matrix, and the mini-batch of onehot matrices is a 3D tensor. Using the terminology of convolutions, the size of each onehot(usually the size of the vocabulary) is the number of “input channels” and the length of the character sequence is the “width”.
In Example 4-14, the first step in constructing the feature vectors is to apply an instance of PyTorch’s Conv1d class to the 3D data tensor. By checking the size of the output, you can tell how much the tensor is reduced. It is recommended to refer to Figure 4-9 to visually explain why the output tensor is shrinking.
batch_size = 2
one_hot_size = 10
sequence_width = 7
data = torch.randn(batch_size, one_hot_size, sequence_width)
conv1 = nn.Conv1d(in_channels=one_hot_size, out_channels=16, kernel_size=3)
intermediate1 = conv1(data)
print(data.size())
print(intermediate1.size())
torch.Size([2, 10, 7])
torch.Size([2, 16, 5])
conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3)
conv3 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3)
intermediate2 = conv2(intermediate1)
intermediate3 = conv3(intermediate2)
print(intermediate2.size())
print(intermediate3.size())
torch.Size([2, 32, 3])
torch.Size([2, 64, 1])
y_output = intermediate3.squeeze()
print(y_output.size())
torch.Size([2, 64])
intermediate2.mean(dim=0).mean(dim=1).sum()
tensor(0.3635, grad_fn=<SumBackward0>)
# Method 2 of reducing to feature vectors
print(intermediate1.view(batch_size, -1).size())
# Method 3 of reducing to feature vectors
print(torch.mean(intermediate1, dim=2).size())
# print(torch.max(intermediate1, dim=2).size())
# print(torch.sum(intermediate1, dim=2).size())
torch.Size([2, 80])
torch.Size([2, 16])
4.2 Load Data
class SurnameDataset(Dataset):
# ... existing implementation from Section 4.2
def __getitem__(self, index):
row = self._target_df.iloc[index]
surname_matrix = \
self._vectorizer.vectorize(row.surname, self._max_seq_length)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_matrix,
'y_nationality': nationality_index}
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot_matrix (np.ndarray): a matrix of one-hot vectors
"""
one_hot_matrix_size = (len(self.character_vocab), self.max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.character_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
character_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
max_surname_length = 0
for index, row in surname_df.iterrows():
max_surname_length = max(max_surname_length, len(row.surname))
for letter in row.surname:
character_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(character_vocab, nationality_vocab, max_surname_length)
4.3 Model Define
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): size of the incoming feature vector
num_classes (int): size of the output prediction vector
num_channels (int): constant channel size to use throughout network
"""
super(SurnameClassifier, self).__init__()
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_surname (torch.Tensor): an input data tensor.
x_surname.shape should be (batch, initial_num_channels,
max_surname_length)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, num_classes)
"""
features = self.convnet(x_surname).squeeze(dim=2)
prediction_vector = self.fc(features)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
args = Namespace(
# Data and Path information
surname_csv="data/surnames/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/cnn",
# Model hyper parameters
hidden_dim=100,
num_channels=256,
# Training hyper parameters
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1,
# Runtime omitted for space ...
)
def predict_nationality(surname, classifier, vectorizer):
"""Predict the nationality from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
Returns:
a dictionary with the most likely nationality and its probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
conv1 = nn.Conv1d(in_channels=one_hot_size, out_channels=16, kernel_size=3)
conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3)
conv3 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3)
conv1_bn = nn.BatchNorm1d(num_features=16)
conv2_bn = nn.BatchNorm1d(num_features=32)
intermediate1 = conv1_bn(F.relu(conv1(data)))
intermediate2 = conv2_bn(F.relu(conv2(intermediate1)))
intermediate3 = conv3(intermediate2)
print(intermediate1.size())
print(intermediate2.size())
print(intermediate3.size())
torch.Size([2, 16, 5])
torch.Size([2, 32, 3])
torch.Size([2, 64, 1])
4.4 Classifying Surnames with a Convolutional Neural Network
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook
class Vocabulary(object):
"""Class to process text and extract vocabulary for mapping"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): a pre-existing map of tokens to indices
add_unk (bool): a flag that indicates whether to add the UNK token
unk_token (str): the UNK token to add into the Vocabulary
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
""" returns a dictionary that can be serialized """
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
""" instantiates the Vocabulary from a serialized dictionary """
return cls(**contents)
def add_token(self, token):
"""Update mapping dicts based on the token.
Args:
token (str): the item to add into the Vocabulary
Returns:
index (int): the integer corresponding to the token
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""Add a list of tokens into the Vocabulary
Args:
tokens (list): a list of string tokens
Returns:
indices (list): a list of indices corresponding to the tokens
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""Retrieve the index associated with the token
or the UNK index if token isn't present.
Args:
token (str): the token to look up
Returns:
index (int): the index corresponding to the token
Notes:
`unk_index` needs to be >=0 (having been added into the Vocabulary)
for the UNK functionality
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""Return the token associated with the index
Args:
index (int): the index to look up
Returns:
token (str): the token corresponding to the index
Raises:
KeyError: if the index is not in the Vocabulary
"""
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab, max_surname_length):
"""
Args:
surname_vocab (Vocabulary): maps characters to integers
nationality_vocab (Vocabulary): maps nationalities to integers
max_surname_length (int): the length of the longest surname
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
self._max_surname_length = max_surname_length
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot_matrix (np.ndarray): a matrix of one-hot vectors
"""
one_hot_matrix_size = (len(self.surname_vocab), self._max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.surname_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
max_surname_length = 0
for index, row in surname_df.iterrows():
max_surname_length = max(max_surname_length, len(row.surname))
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab, max_surname_length)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab,
max_surname_length=contents['max_surname_length'])
def to_serializable(self):
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable(),
'max_surname_length': self._max_surname_length}
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
Args:
name_df (pandas.DataFrame): the dataset
vectorizer (SurnameVectorizer): vectorizer instatiated from dataset
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""Load dataset and the corresponding vectorizer.
Used in the case in the vectorizer has been cached for re-use
Args:
surname_csv (str): location of the dataset
vectorizer_filepath (str): location of the saved vectorizer
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""a static method for loading the vectorizer from file
Args:
vectorizer_filepath (str): the location of the serialized vectorizer
Returns:
an instance of SurnameDataset
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
"""saves the vectorizer to disk using json
Args:
vectorizer_filepath (str): the location to save the vectorizer
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
""" returns the vectorizer """
return self._vectorizer
def set_split(self, split="train"):
""" selects the splits in the dataset using a column in the dataframe """
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dictionary holding the data point's features (x_data) and label (y_target)
"""
row = self._target_df.iloc[index]
surname_matrix = \
self._vectorizer.vectorize(row.surname)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_matrix,
'y_nationality': nationality_index}
def get_num_batches(self, batch_size):
"""Given a batch size, return the number of batches in the dataset
Args:
batch_size (int)
Returns:
number of batches in the dataset
"""
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
A generator function which wraps the PyTorch DataLoader. It will
ensure each tensor is on the write device location.
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): size of the incoming feature vector
num_classes (int): size of the output prediction vector
num_channels (int): constant channel size to use throughout network
"""
super(SurnameClassifier, self).__init__()
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_surname (torch.Tensor): an input data tensor.
x_surname.shape should be (batch, initial_num_channels, max_surname_length)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, num_classes)
"""
features = self.convnet(x_surname).squeeze(dim=2)
prediction_vector = self.fc(features)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
def make_train_state(args):
return {'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'learning_rate': args.learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': args.model_state_file}
def update_train_state(args, model, train_state):
"""Handle the training state updates.
Components:
- Early Stopping: Prevent overfitting.
- Model Checkpoint: Model is saved if the model is better
:param args: main arguments
:param model: model to train
:param train_state: a dictionary representing the training state values
:returns:
a new train_state
"""
# Save one model at least
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# Save model if performance improved
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# If loss worsened
if loss_t >= train_state['early_stopping_best_val']:
# Update step
train_state['early_stopping_step'] += 1
# Loss decreased
else:
# Save the best model
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# Reset early stopping step
train_state['early_stopping_step'] = 0
# Stop early ?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
def compute_accuracy(y_pred, y_target):
y_pred_indices = y_pred.max(dim=1)[1]
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
args = Namespace(
# Data and Path information
surname_csv="surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/cnn",
# Model hyper parameters
hidden_dim=100,
num_channels=256,
# Training hyper parameters
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
catch_keyboard_interrupt=True
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
def set_seed_everywhere(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
# Set seed for reproducibility
set_seed_everywhere(args.seed, args.cuda)
# handle dirs
handle_dirs(args.save_dir)
Expanded filepaths:
model_storage/ch4/cnn/vectorizer.json
model_storage/ch4/cnn/model.pth
Using CUDA: False
if args.reload_from_files:
# training from a checkpoint
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# create dataset and vectorizer
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(initial_num_channels=len(vectorizer.surname_vocab),
num_classes=len(vectorizer.nationality_vocab),
num_channels=args.num_channels)
classifer = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(weight=dataset.class_weights)
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# Iterate over training dataset
# setup: batch generator, set loss and acc to 0, set train mode on
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# the training routine is these 5 steps:
# --------------------------------------
# step 1. zero the gradients
optimizer.zero_grad()
# step 2. compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# step 4. use loss to produce gradients
loss.backward()
# step 5. use optimizer to take gradient step
optimizer.step()
# -----------------------------------------
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# update bar
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# Iterate over val dataset
# setup: batch generator, set loss and acc to 0; set eval mode on
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:3: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
This is separate from the ipykernel package so we can avoid doing imports until
HBox(children=(FloatProgress(value=0.0, description='training routine', style=ProgressStyle(description_width=…
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:9: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
if __name__ == '__main__':
HBox(children=(FloatProgress(value=0.0, description='split=train', max=60.0, style=ProgressStyle(description_w…
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:14: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
HBox(children=(FloatProgress(value=0.0, description='split=val', max=12.0, style=ProgressStyle(description_wid…
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))
Test loss: 1.9216371824343998;
Test Accuracy: 60.7421875
We can see that the test accuracy is higher than MLPs. Next, We will use the CNN model to do the inference
def predict_nationality(surname, classifier, vectorizer):
"""Predict the nationality from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
Returns:
a dictionary with the most likely nationality and its probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
Enter a surname to classify: McMahan
McMahan -> Irish (p=1.00)
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
def predict_topk_nationality(surname, classifier, vectorizer, k=5):
"""Predict the top K nationalities from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
k (int): the number of top nationalities to return
Returns:
list of dictionaries, each dictionary is a nationality and a probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(dim=0)
prediction_vector = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# returned size is 1,k
probability_values = probability_values[0].detach().numpy()
indices = indices[0].detach().numpy()
results = []
for kth_index in range(k):
nationality = vectorizer.nationality_vocab.lookup_index(indices[kth_index])
probability_value = probability_values[kth_index]
results.append({'nationality': nationality,
'probability': probability_value})
return results
new_surname = input("Enter a surname to classify: ")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
Enter a surname to classify: McMahan
McMahan -> Irish (p=1.00)
Enter a surname to classify: McMahan
How many of the top predictions to see? 5
Top 5 predictions:
===================
McMahan -> Irish (p=1.00)
McMahan -> English (p=0.00)
McMahan -> Russian (p=0.00)
McMahan -> Scottish (p=0.00)
McMahan -> Czech (p=0.00)
5 总结
鉴于英文水平一般,总结好好用中文写,作为本次实验和作业的一个句号。通过这次实验任务,我学习了如何使用多层感知器(MLP)进行姓氏分类,并探索不同类型的神经网络层对数据张量大小和形状的影响,其中主要是多层感知机网络和卷积神经网络。此外,还尝试在模型中添加了dropout层,观察它对分类结果的影响。
在使用使用多层感知器进行姓氏分类时候,以一个简单的姓氏分类任务为例,使用PyTorch实现了一个多层感知器模型。首先,我们准备好姓氏分类的数据集。然后定义一个简单的多层感知器模型,用于姓氏分类。下面是网络的举例:
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 假设输入维度为10,隐藏层维度为50,输出维度为类别数量(假设为5)
input_dim = 10
hidden_dim = 50
output_dim = 5
model = SurnameClassifier(input_dim, hidden_dim, output_dim)
然后进行训练模型:
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for surnames, labels in train_loader:
# 假设输入数据已经被预处理成固定维度的张量
surnames = torch.randn(len(surnames), input_dim)
labels = torch.tensor(labels)
optimizer.zero_grad()
outputs = model(surnames)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}')
关于神经网络层对张量大小和形状的影响
在多层感知器中,线性层(全连接层)会改变输入张量的形状。可以如下面代码的输出展示会更为直观。
import torch
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
class SurnameDataset(Dataset):
def __init__(self, surnames, labels):
self.surnames = surnames
self.labels = labels
self.label_encoder = LabelEncoder()
self.encoded_labels = self.label_encoder.fit_transform(labels)
def __len__(self):
return len(self.surnames)
def __getitem__(self, idx):
return self.surnames[idx], self.encoded_labels[idx]
# 假设我们有姓氏数据和对应的标签
surnames = ["Smith", "Johnson", "Williams", "Brown", "Jones"]
labels = ["English", "English", "English", "English", "English"]
dataset = SurnameDataset(surnames, labels)
train_data, test_data = train_test_split(dataset, test_size=0.2, random_state=42)
train_loader = DataLoader(train_data, batch_size=2, shuffle=True)
test_loader = DataLoader(test_data, batch_size=2, shuffle=False)
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 假设输入维度为10,隐藏层维度为50,输出维度为类别数量(假设为5)
input_dim = 10
hidden_dim = 50
output_dim = 5
model = SurnameClassifier(input_dim, hidden_dim, output_dim)
# 假设输入维度为10,隐藏层维度为50,输出维度为类别数量(假设为5)
input_dim = 10
hidden_dim = 50
output_dim = 5
x = torch.randn(2, input_dim) # 一个batch中有2个样本,每个样本的维度为input_dim
print(f'Input shape: {x.shape}')
x = F.relu(model.fc1(x))
print(f'After first layer: {x.shape}')
x = model.fc2(x)
print(f'After second layer: {x.shape}')
Input shape: torch.Size([2, 10])
After first layer: torch.Size([2, 50])
After second layer: torch.Size([2, 5])
在MLP中,我们还在模型中添加Dropout层,并观察其对结果的影响。
通过这几个任务,我掌握了如何使用多层感知器进行分类,并了解来了不同神经网络层对张量大小和形状的影响。还了解了Dropout层如何帮助减少过拟合,提高模型的泛化能力。