前言
本文为10月1日计算机视觉基础学习笔记——Cuda 编程,分为三个章节:
- Week8 homework——Cifar 10 & Alexnet;
- GPU schema;
- Pycuda.
一、Week8 homework——Cifar 10 & Alexnet
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import matplotlib.pyplot as plt
# 定义超参数
BATCH_SIZE = 32
nEpochs = 16
numPrint = 1000
# cuda
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.247, 0.243, 0.261])])
# 加载数据集 (训练集和测试集)
trainset = torchvision.datasets.CIFAR10(root='./', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
# 定义神经网络
class AlexNet(nn.Module): # 训练 ALexNet
def __init__(self):
super(AlexNet, self).__init__()
# 五个卷积层
self.conv1 = nn.Sequential( # 输入 32 * 32 * 3
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1), # (32-3+2)/1+1 = 32
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (32-2)/2+1 = 16
)
self.conv2 = nn.Sequential( # 输入 16 * 16 * 6
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=1), # (16-3+2)/1+1 = 16
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (16-2)/2+1 = 8
)
self.conv3 = nn.Sequential( # 输入 8 * 8 * 16
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1), # (8-3+2)/1+1 = 8
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (8-2)/2+1 = 4
)
self.conv4 = nn.Sequential( # 输入 4 * 4 * 64
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1), # (4-3+2)/1+1 = 4
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (4-2)/2+1 = 2
)
self.conv5 = nn.Sequential( # 输入 2 * 2 * 128
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), # (2-3+2)/1+1 = 2
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (2-2)/2+1 = 1
) # 最后一层卷积层,输出 1 * 1 * 128
# 全连接层
self.dense = nn.Sequential(
nn.Linear(128, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = x.view(-1, 128)
x = self.dense(x)
return x
# 为每个优化器创建一个Net
net_SGD = AlexNet()
net_Momentum = AlexNet()
net_RMSprop = AlexNet()
net_Adam = AlexNet()
net_Adagrad = AlexNet()
net_Adadelta = AlexNet()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam, net_Adagrad, net_Adadelta]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=0.01)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=0.01, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=0.001, alpha=0.99)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=0.001, betas=(0.9, 0.99))
opt_Adagrad = torch.optim.Adagrad(net_Adagrad.parameters(), lr=0.01)
opt_Adadelta = torch.optim.Adadelta(net_Adadelta.parameters(), lr=0.01)
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam, opt_Adagrad, opt_Adadelta]
# 定义损失函数
loss_function = nn.CrossEntropyLoss() # 交叉熵损失
# 记录training时不同神经网络的loss值
losses_history = [[], [], [], [], [], []]
# 记录training时不同神经网络的top1Acc值
top1Acc_history = [[], [], [], [], [], []]
# 使用测试数据测试网络
def Accuracy():
correct = 0
total = 0
with torch.no_grad(): # 训练集中不需要反向传播
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 返回每一行中最大值的那个元素,且返回其索引
total += labels.size(0)
correct += (predicted == labels).sum().item()
return 100.0 * correct / total
optime = ['SGD', 'Momentum', 'RMSprop', 'Adam', 'Adagrad', 'Adadelta']
name_indx = 0
for net, opt, l_his, acc_his in zip(nets, optimizers, losses_history, top1Acc_history):
print('using ', optime[name_indx])
for epoch in range(nEpochs):
running_loss = 0.0
print('Epoch:', epoch + 1, 'Training...')
for i, data in enumerate(trainloader, 0):
inputs, labels = data # 取数据
inputs, labels = inputs.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
opt.zero_grad() # 将梯度置零
# 训练
net = net.to(device)
outputs = net(inputs)
loss = loss_function(outputs, labels).to(device)
loss.backward() # 反向传播
opt.step()
running_loss += loss.item()
if i % numPrint == 999: # 每 numPrint 张图片,打印一次
l_his.append(running_loss / numPrint)
print('epoch: %d\t batch: %d\t loss: %.6f' % (epoch + 1, i + 1, running_loss / numPrint))
running_loss = 0.0
top1Acc = Accuracy()
print('Accuracy of the network on the 10000 test images: %d %%' % top1Acc)
acc_his.append(top1Acc)
model_name = optime[name_indx] + '_model.pkl'
save_path = './' + model_name
torch.save(net, save_path)
name_indx += 1
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=optime[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 3))
plt.show()
for i, t_his in enumerate(top1Acc_history):
plt.plot(t_his, label=optime[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Top1Acc')
plt.ylim((0, 100))
plt.show()
二、GPU schema
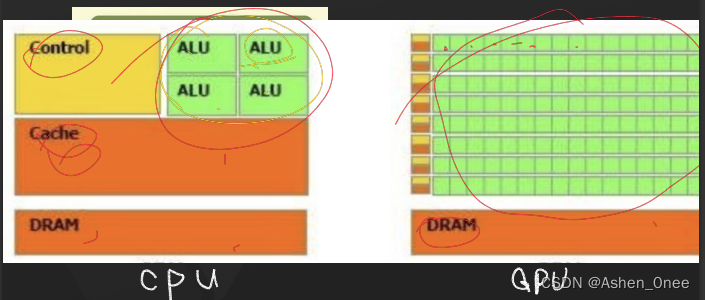
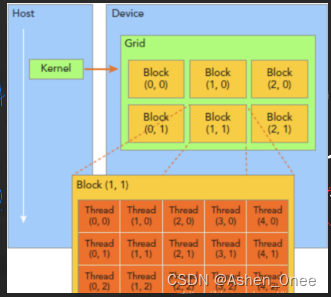
- cuda 中 threadidx、blockidx、blockDim、gridDim 的使用:
- threadidx:unit3 类型,表示一个线程的索引;
- blockidx:unit3 类型,表示一个线程块的索引,一个线程块中通常有多个线程;
- blockDim:dim3 类型,表示线程块的大小;
- gridDim:dim3 类型,表示网格的大小,一个网格中通常有多个线程块。
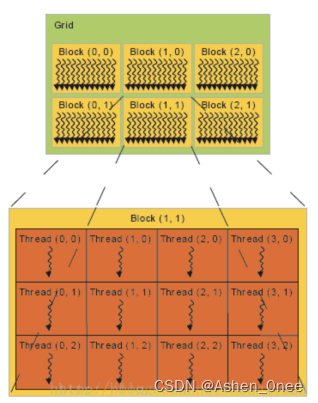
- 串行计算:
- 并行计算:
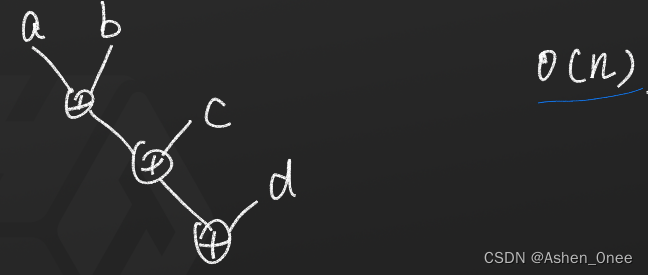
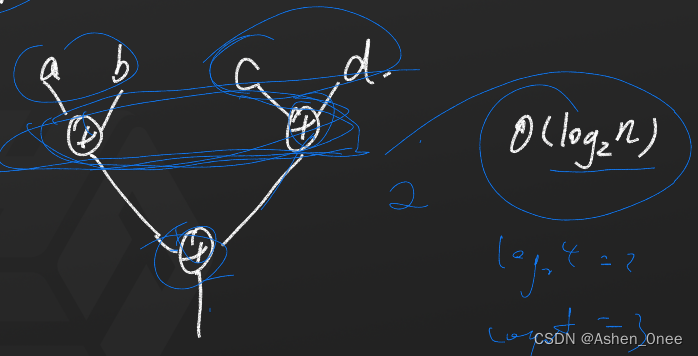
例:如果并行加
2
10
2^{10}
210 个数,则计算复杂度为:
l
o
g
2
2
10
=
10
log_22^{10} = 10
log2210=10。
三、Pycuda
- Example 1:
import pycuda.autoinit
import pycuda.gpuarray as gpuarray
import numpy
num = 4
A = numpy.random.rand(num)
B = numpy.random.rand(num)
A_GPU = gpuarray.to_gpu(A.astype(numpy.float32))
B_GPU = gpuarray.to_gpu(B.astype(numpy.float32))
C_GPU = A_GPU + B_GPU
C = C_GPU.get()
print('A=', A)
print('B=', B)
print('C=', C)
- Example 2:
import pycuda.autoinit
from pycuda.compiler import SourceModule
import pycuda.gpuarray as gpuarray
import numpy
import numpy as np
# 使用核函数
# threadIdx:计算线程
# 第n号线程将x[n]与y[n]相加后存入z[n]。
mod = SourceModule(r"""
void __global__ add(const float *x, const float *y, float *z)
{
const int n = threadIdx.x;
z[n] = x[n] + y[n];
}
""")
add = mod.get_function("add")
num = 4
A = numpy.random.rand(num)
B = numpy.random.rand(num)
C = numpy.zeros(num)
A_GPU = gpuarray.to_gpu(A.astype(numpy.float32))
B_GPU = gpuarray.to_gpu(B.astype(numpy.float32))
C_GPU = gpuarray.to_gpu(B.astype(numpy.float32))
# thread=num,block=(4,1,1),grid=1,
add(A_GPU, B_GPU, C_GPU, block=(num,1,1))
# get():把数据从gpu拿下来
C = C_GPU.get()
print('A=', A)
print('B=', B)
print('C=', C)
import pdb
pdb.set_trace()
from pycuda.scan import InclusiveScanKernel
from pycuda.reduction import ReductionKernel
#seq_gpu = gpuarray.to_gpu(seq)
sum_gpu = InclusiveScanKernel(np.int32, "a+b")
#print(sum_gpu(seq_gpu).get())
print(sum_gpu(C_GPU).get())
- Example 3:
import pycuda.autoinit
from pycuda.compiler import SourceModule
import pycuda.gpuarray as gpuarray
import numpy
mod = SourceModule(r"""
void __global__ add(const float *x, const float *y, float *z)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] + y[n];
}
void __global__ mul(const float *x, const float *y, float *z)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] * y[n];
}
""")
add = mod.get_function("add")
mul = mod.get_function("mul")
num = 6
# 一个bolck计算不完
A = numpy.random.rand(num)
B = numpy.random.rand(num)
C = numpy.zeros(num)
A_GPU = gpuarray.to_gpu(A.astype(numpy.float32))
B_GPU = gpuarray.to_gpu(B.astype(numpy.float32))
C_GPU = gpuarray.to_gpu(B.astype(numpy.float32))
#
add(A_GPU, B_GPU, C_GPU, grid=(2,), block=(4,1,1))
C = C_GPU.get()
print('A=', A)
print('B=', B)
print('C=', C)
print("*"*20)
mul(A_GPU, B_GPU, C_GPU, grid=(2,), block=(4,1,1))
C = C_GPU.get()
print('A=', A)
print('B=', B)
print('C=', C)