本人经过作者同意,公布了:BDCI2018供应链需求预测数据竞赛第一名的解决方案和代码。该方案利用赛题为运用平台积累最近1年多的商品数据预测45天后5周每周(week1~week5)的销量,为供应链提供数据基础,将能够为出海企业建立全球化供应链方案提供关键的技术支持。

赛题介绍
1.赛题名称
供应链需求预测
2.赛题网址:
https://www.datafountain.cn/competitions/313/details
3.赛题背景
主办方:中国计算机学会 & 执御
浙江执御信息技术有限公司是一家专注出海的跨境电商企业,利用移动互联网创新和大数据应用,助力中国制造升级,将中国和全球的优质品牌、设计、产品输送到“一带一路”沿线国家和地区。在电商产业链中,为提升用户物流服务体验,供应链协同将货品提前准备在全球各个市场的本地仓,可有效降低物流时间,极大提升用户体验。不同于国内电商物流情况,出海电商的产品生产和销售地区是全球化的,商品的采购,运输,海关质检等,整个商品准备链路需要更长的时间。在大数据和人工智能技术快速发展的新时代背景下,运用大数据分析和算法技术,精准预测远期的商品销售,为供应链提供数据基础,将能够为出海企业建立全球化供应链方案提供关键的技术支持。
4.赛题任务
供应链需求预测,对原问题做建模问题简化。考虑商品在制造,国际航运,海关清关,商品入仓的供应链过程,实际的产品准备时长不同。这里将问题简化,统一在45天内完成,供应链预测目标市场为沙特阿拉伯。赛题为运用平台积累最近1年多的商品数据预测45天后5周每周(week1~week5)的销量。
具体任务见赛题网址:
https://www.datafountain.cn/competitions/313/details
团队介绍
队名:你们偷塔,我来团
队员:张予琛、罗律、罗宾理、朱丹青、江洪水
张予琛,中南大学研究生在读、电投轮机赛亚军
罗律,中南大学研究生在读、电投轮机赛亚军
罗宾理,中南大学本科在读、2018 KDD CUPTOP1,也创造了最小年龄的该奖项的获得者记录、2018 IJCAI TOP3、工业AI智能制造全球top2、智慧中国杯,凤凰金融量化投资大赛top1、第十届英特尔杯特等奖和最具创意潜力奖、湖南省挑战杯金奖和全国铜奖。
团队成绩:1/1458 (最终排名)
赛题方案
1.赛题理解
此赛题为供应链需求预测,提供了执御平台一部分商品一年多的销售和其他相关日常数据,要求预测部分sku 45天后的五周内销量。首先,这是一个典型的时间序列回归问题。使用传统的时间序列回归方法进行预测应该能够起到一个还不错的效果,可以作为一个Baseline模型。进一步的,可以构建训练集,抽取一些与sku未来销量相关性高的特征来进行机器学习模型的训练,把这个问题看作一个回归问题使用机器学习的方法进行预测。
2.数据分析
在复赛中,总共提供了上百万个sku的2017年3月到2018年3月16的历史数据,要求预测其中十五万个sku在2018年5月1号开始的五周的每周销量。因为要预测的销量的时间单位是周,所以我们在历史数据中新增了一个用于表示当前时间距离2018年3月16日有多少周的列。图1是每周全部sku的总销量图,图中我们可以看出,在15周(也就是2017年11月左右)的时候,总销量出现了异常高峰,明显高于其他时期。我们推测这段时间应该是平台在搞大型促销活动,所以才会导致出现如此的异常销量高峰,在构建训练集和提取特征时应该注意避开这段时期或者进行平滑处理。通过对要进行预测的sku_id的分析,我们发现要求进行销量预测的sku都是在2018年3月有过销量的sku,也就是说此赛题是预测近期活跃sku的未来销量。于是,我们在构建训练集的时候,可以考虑模拟这种抽取近期活跃的sku的方式来构建线下训练集。
要求进行销量预测的时间的2018年5月起的五周,然后这个赛题的目标市场是在沙特阿拉伯。我们注意到,在这段时间内,有沙特阿拉伯的重要节日,开斋节。我们认为,平台在这段时间应该也会进行相应的促销活动,通过对平台活动数据的分析发现果然如此,所以这段时间的销量必然会有个起伏的过程,可以根据平台活动节奏适当对预测销量进行调整。
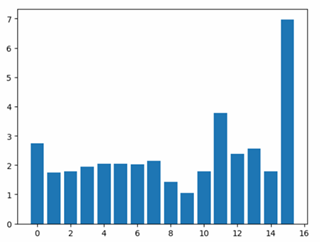
图1
3.特征工程
我们首先用时间序列加权回归的方法做了一个基础的模型,sku未来的销量肯定与历史销量有关,越是离得近的销量数据越有参考价值。所以我们选取了离2018年3月16日最近的八周的销量,分别赋以11,7,6,5,4,3,2,1的权重系数,然后求得平均值作为线上的预测结果。这个基础模型就已经能够在线上取得不错的分数了,后期我们将这个预测值加入到我们的机器学习模型中作为特征。
其他的特征方面,主要分为商品历史特征、整体活动特征以及时间序列特征。其中商品历史特征主要是商品每周销量/商品销量占品类的比例/商品价格等,在这些特征中主要提分点还是基于销量的特征。由于商品的促销等特征在预测时段的数据并未提供,所以这部分特征我们团队并没有做相关的挖掘,主要还是以历史销量为主。整体活动特征是marketing表中所述全场活动,对整体销量影响极大,这部分特征由于我们数据集构造并没有连续划窗,所以我们并没有直接将其放入特征中,而是对历史销量进行平滑,平滑掉全场大促的活动对模型的偏移。时间序列特征本质是规则,根据衰减情况把商品历史销量直接作为预测值,同时,在这部分特征里对历史销量运用卡尔曼平滑的方法,线上提分明显,并且线上线下都非常稳定。
4.模型选择
模型部分,我们团队一直采用的XGboost单模型,并未做其他的模型融合操作。单模型速度较快,工业应用价值高,并且更能体现特征的价值。而XGboost更是一个应用价值非常高的模型,可以进行分布式实现以及调用GPU进行加速,更有利于现实中的工业应用。
复现方法
1.代码和数据集
代码和数据集可以在百度云下载:
链接:https://pan.baidu.com/s/1yMd_t9MhzFMM0i78iy8nHg
提取码:rrxm
如果被和谐请回复“供应链预测”获取新网址。
备注:
作者曾在github公布过代码,与百度云一致:
https://github.com/luoda888/CCF2018-Top2-Demand-Forecast
经过我和作者的沟通,在百度云上增加了github里没有的数据集,如果要复现,建议到百度云下载数据集,需要查看更新请在github下载最新代码。
2.复现方法
复现环境:python3.6
将百度云下载的数据集压缩包解压到代码目录(数据在fusai_data目录),使用作者提供的简易执行代码一键运行:
-
python feature-1.py运行时间约30分钟即可复现跟比赛成绩相近的结果。
总结
本方案利用采用单模型进行预测,能取得良好的成绩并非依靠模型融合的方法。方法具有良好的可扩展性,可以拓展的场景有音乐流行趋势预测、金融序列预测、以及绝大部分效率预测问题。由于方案的简单以及可扩展性,适合真实场景应用,该方案最终获得综合评分第一名(线上成绩为第二,综合评分第一)。
分享是一种美德-感谢作者团队的开源分享,期待广大的机器学习爱好者开源自己的代码,为广大的初学者提供便利。

长按扫码撩海归