文章来源
paper: https://arxiv.org/abs/2103.16553
Motivation
目标是基于语言的大规模图像和视频数据集的搜索。即给定某个语句,从大量图像检索库中找到与该语句描述最相似的图像。
对于这个任务,采用单独将文本和视觉映射到联合嵌入空间的方法,即对偶编码器,可以应用到较大的检索规模数据中,其采用了近似最近邻搜索的方法。另一种使用交叉注意的视觉-文本转换器的方法可以显著提高联合嵌入的准确性,但由于测试时每个样本所需的交叉注意机制的计算成本价高,这种方法在实践中通常不适用于大规模检索。作者的这项工作结合了两者的优点。
做出以下三个贡献。
首先,为基于transfomer的模型配备了一个新的细粒度交叉关注体系结构,在保持可伸缩性的同时显著提高检索准确性。
其次,介绍了一种通用的方法,通过蒸馏和重新排序,将快速双编码器模型与慢但准确的基于transfomer的模型相结合。
最后,作者在Flickr30K图像数据集上验证了方法的可行性,推理速度提高了几个数量级,同时具有与STOA相竞争的结果。作者还将该方法扩展到视频领域,提高了VATEX数据集的性能。
Method
目的:训练一个模型在输入图像
x
x
x和文本描述
y
y
y之间输出相似度得分。
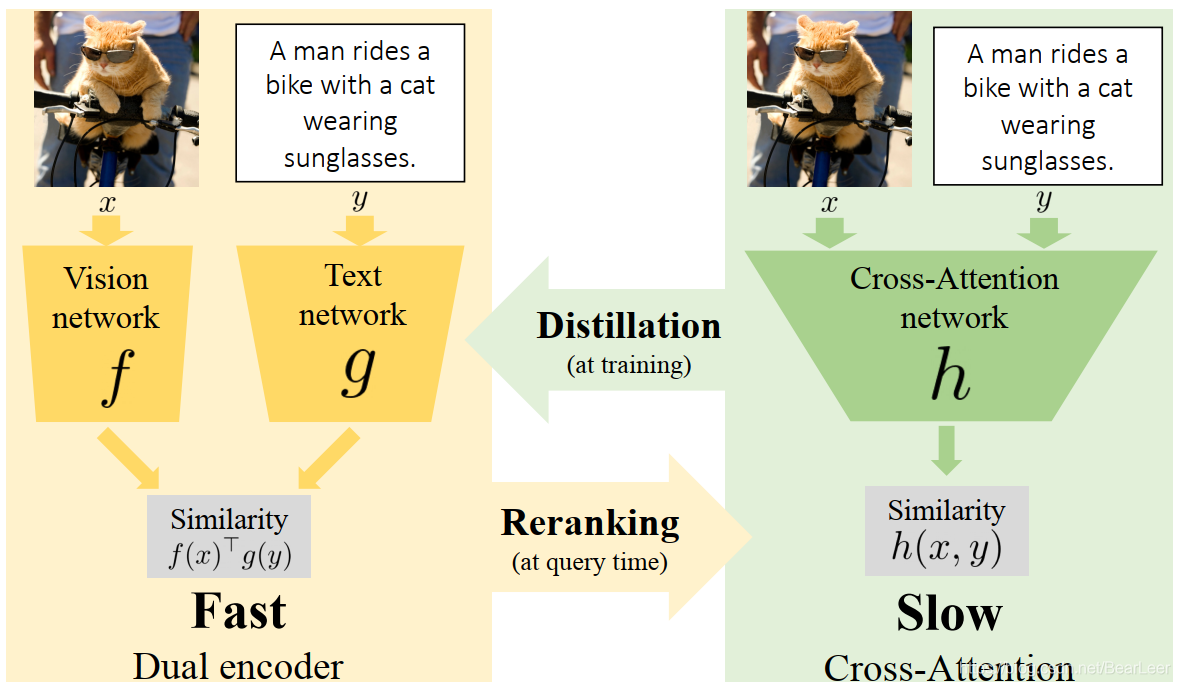
1 Fast Model (Dual encoder)
由提取的modality-specific embedding构成: f ( x ) ∈ R d f(x) \in \mathbb R^d f(x)∈Rd作为图像, g ( y ) ∈ R d g(y) \in \mathbb R^d g(y)∈Rd 作为文本。该模型的方法是计算 x x x和 y y y之间的相似度,采用了单个点积的形式计算得分: f ( x ) T g ( y ) f(x)^Tg(y) f(x)Tg(y)。【计算量小】
2 Slow Model (cross-attention) :
采用了复杂的模态合并方法计算相似度得分 h ( x , y ) = A ( ϕ ( x ) , y ) h(x,y)=A(\phi(x),y) h(x,y)=A(ϕ(x),y)。
其中 ϕ \phi ϕ代表视觉信息的encoder(例如CNN), A A A是一个计算二者相似度的网络,其使用了cross-attention。
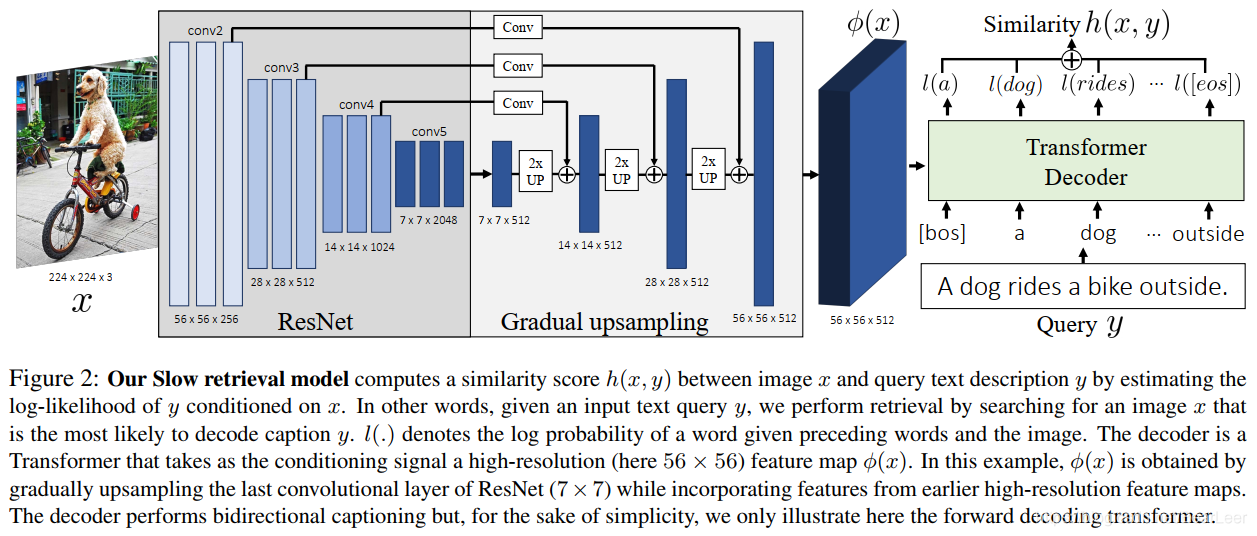
2.1 slow retrieval model
作者对该模型提出了2点创新:提出一个网络架构逐步精细化上采样图像特征从而得到fine-gradined visual-text cross-attention。此外,作者采用了captioning loss去训练该模型,并且和其他loss做对比讨论该loss的优势。
(1) 提出的网络架构执行方案如下:假设输入图像 x ∈ R 224 × 224 x \in \mathbb R^{224 \times 224} x∈R224×224,其通过ResNet-50后得到输出特征图 R 7 ∗ 7 \mathbb R^{7*7} R7∗7,紧接着将其扁平化得到49个向量。仅有49个向量作为transformer的输入会失去很多有价值的fine-grained的视觉信息,于是作者在最后一个卷积输出的特征上逐步采用了上采样操作,并和之前降采样操作的特征做融合,如上图所示。
(2) Bi-directional captioning objective for retrieval
之前的text-vision工作大都依赖cross-modal image-text matching loss,作者在此工作中采用了captioning model。
具体方法:
设计了cross-attention modula A最为Transformer decoders,采用了
ϕ
(
x
)
\phi (x)
ϕ(x)作为编码状态。每个encoder由一个masked text self-attention,cross-attention层(将文本信息附加到视觉特征上),以及一个feed forward层构成。设输入text为
y
=
[
y
1
,
.
.
.
,
y
L
]
y = [y^1,...,y^L]
y=[y1,...,yL],L代表语句中的单词个数。最后,模型h用来计算图像和文本(x,y)之间的相似度得分:
h
(
x
,
y
)
=
h
f
w
d
(
x
,
y
)
+
h
b
w
d
(
x
,
y
)
h(x,y)=h_{fwd}(x,y)+h_{bwd}(x,y)
h(x,y)=hfwd(x,y)+hbwd(x,y)
其中,
h
f
w
d
(
x
,
y
)
h_{fwd}(x,y)
hfwd(x,y)代表前向似然函数,
h
b
w
d
(
x
,
y
)
h_{bwd}(x,y)
hbwd(x,y)代表后向似然函数。
h
f
w
d
(
x
,
y
)
=
∑
l
=
1
L
l
o
g
(
p
(
y
l
∣
y
l
−
1
,
.
.
.
,
y
1
,
ϕ
(
x
)
;
θ
f
w
d
)
)
h_{fwd}(x,y) = \sum_{l=1}^L log(p(y^l|y^{l-1},...,y^1,\phi(x);\theta_{fwd}))
hfwd(x,y)=l=1∑Llog(p(yl∣yl−1,...,y1,ϕ(x);θfwd))
h
b
w
d
(
x
,
y
)
=
∑
l
=
1
L
l
o
g
(
p
(
y
1
∣
y
2
,
.
.
.
,
y
l
,
ϕ
(
x
)
;
θ
f
w
d
)
)
h_{bwd}(x,y) = \sum_{l=1}^L log(p(y^1|y^{2},...,y^{l},\phi(x);\theta_{fwd}))
hbwd(x,y)=l=1∑Llog(p(y1∣y2,...,yl,ϕ(x);θfwd))
最后,前向和反向transformer模型通过最小化
L
C
A
=
−
∑
i
=
1
n
h
(
x
i
,
y
i
)
\mathcal L_{CA}=-\sum_{i=1}^n h(x_i,y_i)
LCA=−∑i=1nh(xi,yi)训练得到,n代表标注的图像和文本pairs
(
x
i
,
y
i
)
i
∈
[
1
,
n
]
{(x_i,y_i)}_{i \in [1,n]}
(xi,yi)i∈[1,n]数目。
2.2 Thinking Faster and better for retrieval
作者在这节中介绍了2件事:首先,将Slow cross-attention模型的知识蒸馏到一个快速对偶编码器(dual encoder)模型中,该模型可以被有效地索引。其次,通过重新排序机制将Fast 对哦i编码器模型与Slow cross-attention 模型相结合。
(1)Fast indexable dual encoder models.
在dual encoder中,目的是学习
f
(
x
)
f(x)
f(x)和
g
(
y
)
g(y)
g(y)两个embedding,计算他们的相似度得分
f
(
x
)
T
g
(
y
)
f(x)^Tg(y)
f(x)Tg(y)。学习的目标是使相关的图像和文本由较高的相似度,不相关的具有较低的相似度。于是作者采用了标准的噪声对比估计NCE目标函数:
N
i
\mathcal N_i
Ni代表负样本集合;图像编码
f
f
f代表globally pooled output of a CNN;文本编码
g
g
g要么是bag-of-words表示,要么是BERT 编码表示。
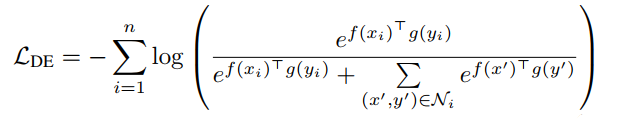
(2)Fast indexable dual encoder models
为了将cross-attetion 模型的知识蒸馏到dual encoder中,作者引进了新的loss实现。
难点:由于该任务没有一个小规模的有效类别数目,故很难直接将在分类模型上的蒸馏方法应用。
解决方案:
给定image-text pair
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),作者采样了有限的pairs子集
B
i
=
{
(
x
i
,
y
i
)
}
∪
{
(
x
,
y
i
)
∣
x
≠
x
i
}
\mathcal B_i= \{(x_i,y_i)\} \cup \{(x,y_i) | x \ne x_i\}
Bi={(xi,yi)}∪{(x,yi)∣x=xi}在相同的文本
y
i
y_i
yi下,但是具有不同的图像
x
x
x。
通过"Slow" teacher model
h
(
x
,
y
)
h(x,y)
h(x,y)在子集
B
i
\mathcal B_i
Bi,可以得到概率分布测量:
此外,可以得到一个相似的分类在"Fase" studeng model上,将
h
(
x
,
y
)
h(x,y)
h(x,y)替换为
f
(
x
)
T
g
(
y
)
f(x)^Tg(y)
f(x)Tg(y)可得到:
有了上面的分布后,紧接着采样蒸馏损失去计算teacher 分布
p
(
B
i
)
p(\mathcal B_i)
p(Bi)和student 分布
q
(
B
i
)
q(\mathcal B_i)
q(Bi):
其中,
H
\mathcal H
H代表在两个分布间的交叉熵损失。最后,与标准的蒸馏方法类似,作者将蒸馏损失和DE损失进行加权得到最终的目标函数,
α
\alpha
α代表加权因子:
(3)Fast indexable dual encoder models
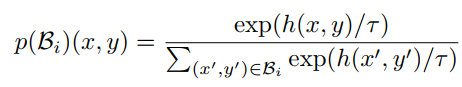
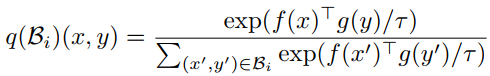
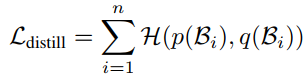
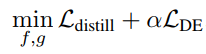
作者发现仅仅采用蒸馏方法难以复现"Slow"模型的性能,因为蒸馏方法最终采用的是"Fast"模型。于是作者做了2步操作以缓解该问题,仅在推理期间使用。
第一步:采用蒸馏过的“Fast”模型得到具有最高相似度的多个图像子集(选择TOP K);
第二步:在第一步的自己上采用了"Slow"模型re-rank这些候选图像,通过下述公式重新re-rank:
其中,
β
\beta
β代表加权因子的超参数。
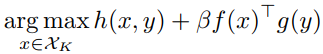
结论
给出一个text内容后,从大量图像检索库中找出最相似的图像,即是该文章的工作。
考虑到直接采用transformer方法从cross-attention 角度计算相似度得分计算量较大,另外,直接采用计算量小的相似度计算方法往往性能不佳。于是作者提出了蒸馏学习的方法,用性能强的cross-attention transformer方法作为teacher,教导性能较差的dual encoder (student)学习,训练的损失采用了蒸馏损失和dual ecoder损失的加权。
另外,作者训练时应该是先pre-train h ( x , y ) h(x,y) h(x,y),然后将pre-trained的模型用到后续的蒸馏模型,对蒸馏模型进行训练。