一、从表设计方向上:
在设计表时,遵循设计范式,尽量使用一对一、一对多,当出现多对多时,尽量使用中间表来存储(在同一个项目中,如果有多种多对多的场景,可以考虑将所有多对多的中间关系存储在一张表中,达到减少表数量的目的)。
二、从 SQL 语句方向上:
1. 慢查询日志中是否有记录:
慢查询日志中,会记录所有时间大于设定值的操作(执行耗时超过 long_query_time 预设时间的SQL);包括DML、DQL、向binlog记录的SQL信息(binlog可用于数据恢复和主从同步用),都会被记载
查看慢日志是否开启,记录文件名或表名。(文件位置一般在 /var/lib/mysql/… )
mysql> show variables like 'slow_query%';
+---------------------+------------------+
| Variable_name | Value |
+---------------------+------------------+
| slow_query_log | ON |
| slow_query_log_file | centos7-slow.log |
+---------------------+------------------+
查看慢查询时间界限, 秒:
mysql> select @@long_query_time;
+-------------------+
| @@long_query_time |
+-------------------+
| 3.000000 |
+-------------------+
-
开启慢查询日志功能:set global slow_query_log=ON;
-
设置慢查询时间界限:set global long_query_time=3;
注意:设置完成后需要断开当前会话,重新连接一次,才会查询到更新
哪些SQL能被MySQL慢日志记录?
-
不会记录 MySQL 中的管理维护命令,除非明确设置 log_slow_admin_statements=1;
-
会记录 执行时间超过 long_query_time 的 SQL,注意:不包括等待锁的时间
-
会记录参数 log_queries_not_using_indexes 设置为1,且SQL没有用到索引,同时没有超过 log_throttle_queries_not_using_indexes 参数的设定。
-
会记录 查询的行数超过 min_examined_row_limit 的 SQL
-
不会记录 QC_Hit 为 true 的所有类型
对于慢日志,可以使用 mysqldumpslow 工具去查找、分析SQL,如访问次数最多的n条日志等。
2. explain分析sql执行计划:
确定存在慢 Sql 日志后,分析 Sql 执行情况。
explain 中的字段及对应的含义
key:表明这次查找中所用到的索引

rows:指这次查找数据所扫描的大概行数,并不是一个准确的值(可以分析count(*)的语句来查看)。
type:效率升序:all < index < range < ref < eq_ref < const < system
-
all:全表扫描(需要优化)
-
index:按照索引顺序的全表扫描(需要优化)
-
range:有范围的索引扫描
-
ref:触发联合索引最左原则,该列不为主键和unique
-
eq_ref:对已经建立索引列进行 = 操作的时候,eq_ref会被使用到。比较值可以使用一个常量也可以是一个表达式。这个表达示可以是其他的表的行。
-
const:用主键或唯一索引做了查询条件,结果集中只返回一条数据
-
system:表中只有一条数据的情况
filtered(Percentage of rows filtered by table condition): 通过表条件过滤后剩下数据所占的百分比
extra:本次查询使用的索引等一些额外信息
2.1 导致索引失效的情况:
-
不满足组合索引的最左匹配原则
-
字段类型隐式转换(eg:当表的字段类型位char,查询的时候字段赋值的是非字符串类型)、
-
like以%开头(%出现在字符串后面可以使用到索引)、
-
索引列是计算或者函数的一部分(eg: … salary*22>11000(salary是索引列),这种将不使用索引)、
-
使用普通索引时,如果扫描行数较多,MySQL 将放弃普通索引,使用全表扫描方式。参考案例
-
覆盖索引失效,回表查询。
2.2 使用了索引,但覆盖索引失效导致查询变慢的情况:
什么是覆盖索引?
如果查询时,通过二级索引完全匹配到了需要的数据,那么他不会去找聚簇索引,直接返回数据;如果通过二级索引没找到对应的数据,那么它会去走聚簇索引,回表查询数据。简单的讲:SQL只通过二级索引就可以返回查找的数据,而不需要通过二级索引找到聚簇索引之后,再回表查找对应的数据。
在下面的 limit 测试用例中,就有一条 extra 为 Using where; Using filesort;该查询中 ORDER BY 的字段没有索引,所以使用到了 Using filesort,便是覆盖索引失效导致查询变慢的一种情况,此时按情况考虑为 ORDER BY 的字段添加索引。
3. 索引的构建与选择
如果在经过前面的分析后,需要添加索引提高效率,那么我们开始选择建立索引。
3.1 前缀索引
是什么?可以达到什么目的?
MySQL 前缀索引是为字符串列的一部,创建一个区分度高、空间占用小的索引,可以提高对表数据的查找和一定程度上的插入速度。
为字符串列添加一个前缀:alter table tablename add index key_name(field_name(length))
带来了那些问题?
与覆盖索引相比,如果满足了覆盖索引的条件,那么 MySQL 将不会执行回表查数据操作。但如果使用了前缀索引,那么就一定有回表操作,去进行完整的对比。
实际业务中的考虑与选择
情况1:当一个字符串字段比较长,它的前n位区分度已经比较高了,那么可以对该字段建立前缀索引
情况2:当一个字符串字段的前n位区分度不高,但后面面m位区分度高时,可以将字段反转后再入库,索引建立时使用前缀索引。
情况3:当有一个很长的字符串需要做索引时,不建议直接在该字符串上建立索引,而是对该字符串的 hash 值作为它的索引列。
3.2 唯一索引与普通索引的选择
当我们的业务中,一个字段需要保证唯一时,加唯一索引,优先考虑业务。(Q:)但当一个字段即可以使用唯一索引,也可以选择普通索引时,如何选择?
(A:)还是需要根据不同的业务来讨论。如果该表涉及的业务 读多写少,或写入后短时间内会读取 ,那么使用唯一索引;如果涉及到业务写多读少,或写入后长时间内都不会去读取,那么使用普通索引,如账单类、日志类的业务模块。
理由:
其中涉及到了change buffer 知识点, InooDB 会将更新操作缓存在 change buffer 中,便不需要从磁盘中读入这个数据页。下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作,来保证数据的一致性。
change buffer 是 buffer pool 中的一部分,有两个重要的参数
- innodb_change_buffer_max_size:表示 Change Buffer 最大大小占 Buffer Pool 的百分比,默认为 25%,最大可以设置为 50%。
- innodb_change_buffering:用来控制对哪些操作启用 Change Buffer 功能,默认是:all,对所有修改操作使用 Change Buffer 。
更多知识细节参考1
下图是 InnoDB 在更新数据时的一个流程图。
了解了相关的知识点后,回到最开始的问题。
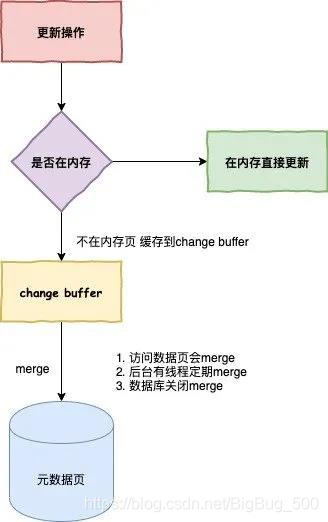
在我们对一个唯一索引的字段做更新操作时,要先判断表中的数据与当前的数据是否违反唯一性约束,而这必须要将数据页读入内存才能判断,就没必要使用 change buffer 了。这也是为什么唯一索引适合 读多写少,或写入后短时间内会读取 的业务场景了。
而对于普通索引,数据的更新操作可以用 change buffer 来记录,而不用把对应的数据页读取到内存中,且短时间内不会读取修改数据的数据页(即数据页在做merge之前,change buffer记录的变更越多),实现提高数据库的操作效率。
4. 表锁、行锁等待时间的优化
如果在 DB 的慢日志中,没有发现需要的 SQL ,那么就需要考虑,这条 Sql 是不是有等待锁的情况。
show status like ‘%lock%’;可以查看DB中,关于各种锁的等待时间。
行锁(InnoDB中)的优化:
-
在所有需要加锁的 SQL 中,尽量使用到索引,避免行级锁上升为表及锁
-
在使用索引的范围加锁时,尽量缩小范围,来避免间隙锁锁住范围后,无法对该范围内的数据进行加锁操作
-
在业务允许的情况下,缩小事务范围,减少事务的锁定数据范围和时间
-
在事务中,为避免死锁的出现,可以采用一次性锁定需要的数据、所有事务中按一定的顺序锁定数据、对于容易产生死锁的业务,可以使用表锁来解决等。
案例
关于limit(offset,rows)调优的测试:
limit用于返回结果集中偏移量(offset,从0开始)到rows行(多少行的)的数据。
当表中数据较多时,offset越大,查询效率越低,优化方案如下:
-
在业务允许的情况下限制页数
-
使用索引来避免limit对全表的扫描(需要注意的是,自增id的主键不一定连续,即结果集行数与id不相对应)
EXPLAIN
select * from test_xs WHERE bjdm LIKE '2%' ORDER BY user_xh limit 67000,10
-----------exlain分析结果表
1 SIMPLE test_xs ALL bjdm_index 67642 Using where; Using filesort
优化:
---------------------------------------------------------------------
方法1:此处sso_id(主键)的获取,可通过前台的数据结果集来得到
EXPLAIN
select * from test_xs WHERE bjdm LIKE '2%' AND sso_id>67000 ORDER BY user_xh limit 10
----------exlain分析结果表
1 SIMPLE test_xs index PRIMARY,bjdm_index user_xh_index 767 303 Using where
---------------------------------------------------------------------
方法二:通过offset来得到对应行的id
EXPLAIN
select * from test_xs WHERE bjdm LIKE '2%' AND sso_id>(SELECT sso_id FROM test_xs LIMIT 10,1) ORDER BY user_xh limit 10
---------exlain分析结果表
1 PRIMARY test_xs index PRIMARY,bjdm_index user_xh_index 767 20 Using where
2 SUBQUERY test_xs index bjdm_index 36 67642 Using index
优化器放弃辅助索引
场景:
如下所示,complete_time 为 datetime 类型,建立了辅助索引。两条 SQL 语句的查询时间不同,语句1使用辅助索引,语句2辅助索引失效。
语句1:
explain SELECT * FROM `pay_bill_alipay` WHERE `complete_time` between '2020-10-20 00:00:00' and '2020-10-26 10:35:35'
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE pay_bill_alipay range complete_time_index complete_time_index 5 NULL 29342 Using index condition
语句2:
explain SELECT * FROM `pay_bill_alipay` WHERE `complete_time` between '2020-10-20 00:00:00' and '2020-10-26 10:35:38'
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE pay_bill_alipay ALL complete_time_index NULL NULL NULL 162453 Using where
占比统计情况:
全表 语句1 语句2
实际行/占比 374157 14422/0.04 14423/0.04
扫描行/占比 374157 29342/0.078 162453/0.434
优化方案:
-
SQL 层面:通过条件,转移使用到其他索引。比如上述的 SQL 中,就可以根据时间,来确定一个表主键的范围,进而减少 SQL 扫描的行数
-
索引层面:优化器之所以放弃使用辅助索引,是根据传统机械硬盘的特性决定的,如果 DB 使用的是固态硬盘,可以考虑 force index(index_name) 强制指定索引,可参考 优化器不使用索引及解决方案。