引言
根据 CAP 原理,分布式系统在Availability、Consistency、Partition Tolerance 上无法兼得,通常由于 PartitionTolerance 必须满足,所以 Consistency 和 Availability 难以同时成立。
PartitionTolerance:服务节点通信出现分区问题(既无法进行通信)后,分布式系统依然能继续服务
结论:
使用缓存的目的,是为了提高系统的响应速度,但缓存的引入却带来了数据一致性、可用性的问题。为了保证缓存与 DB 数据的“高”一致性,有多种实现方案,但每个方案中都有不同的缺陷,都无法保证真正的高可用性。
所以,如果要求数据在变更后,集群所有节点都必须100%一致,那么让所有节点使用同一个数据源,既不使用 DB 或不使用缓存,保证只有一个数据源,并使用索引或其他策略提高数据源操作效率,达到实现CP的效果。
对于数据 Consistency 要求稍微低一点的(既接受AP),才可以根据业务,选择如下适合业务的方案。
缓存+DB数据的 Consistency 保障方案
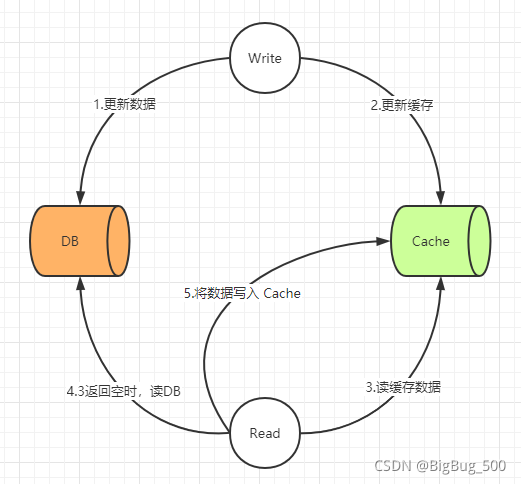
先更新数据库,后删除缓存
处理流程:
优点:
- 实现简单,保证了最终一致性,即 AP
缺点:
- 执行场景顺序:4 >> 1 >> 2 >> 5,那么 Cache 在过期之前,都是脏数据
- 执行场景顺序:4 >> 1 >> 5 >> 2,虽然最终是一致的,但在 5 >> 2 期间,Read 操作读取的数据都是和 DB 不一致的。
针对该方案下的问题,我们可以在 Read 时使用分布式读锁,在 Write 时分布式写锁,来避免上述的两个缺陷的点,但与此同时 引入了悲观锁 会损失掉一定的性能,但该方案下,极大程度的保证了数据的强一致性。
延时双删
如果不引入分布式锁,那么我们则可以考虑延时双删的策略,避免上述方案中 Cache 内脏数据的长时间存在。
项目架构如下:
细节介绍:
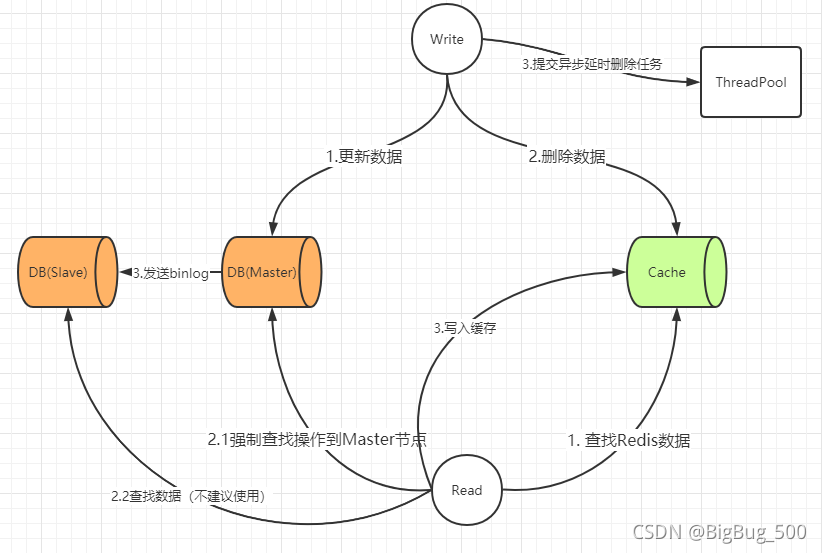
- Read 操作时,建议强制走主库,可以避免 DB 的主从延迟问题
- 在 Write 延期删除的时长设定时,可以设定为 Read 完整操作所需的时间
优点:
- 可以不使用分布式锁的情况下,保证最终一致性
缺点:
- 有代码侵入性
- 未考虑延时删除失败后的重试方案