参考论文:SG-Nav:Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
0 前言
基于现成的视觉基础模型VFMs和大语言模型LLM构建了无需任何训练的零样本物体巡航框架SG-Nav。
通过VLMs将机器人对场景的观测构建为在线的3D场景图,并以prompt LLM使其充分理解图结构信息,从而进行机器人探索的预测
LLM+Zero-shot
一、研究背景
(1)视觉导航
目标:让机器人能在环境中自由探索或按指定路线移动,以找到特定物体
目标导航和视觉语言导航
目标导航细分为基于图像、文本和简单物体类别的三种形式。视觉语言导航则通过一系列具体指令指导机器人行动。
(2)视觉导航分类
(3)零样本物体目标导航
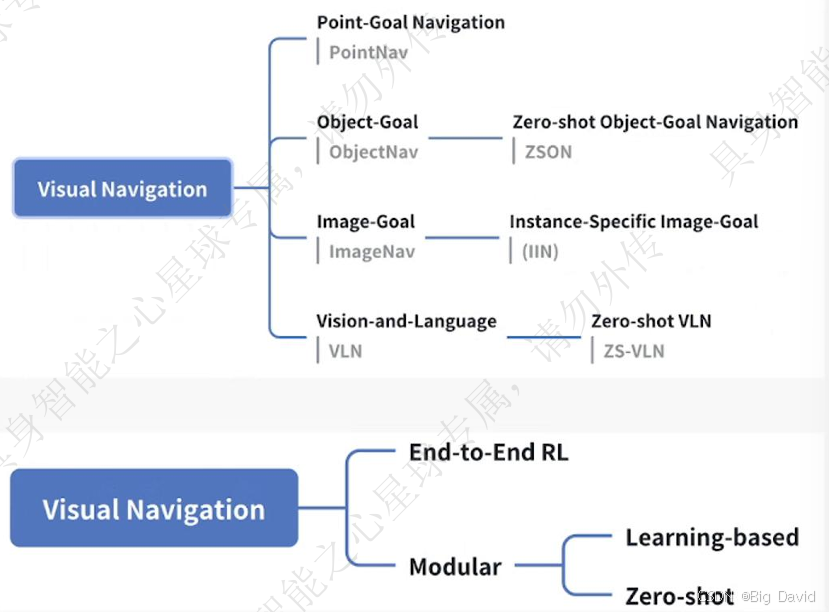
要求机器人不经训练部署到全新环境和全新物体类别
二、相关工作
(1)SemEXP:模块化物体目标导航
(2)PONI:基于边界的物体目标导航
(3)ESC:将LLM引入零样本物体目标导航
三、方法设计
(1)研究动机:建立3D场景图,利用LLM的常识推理能力完成物体导航
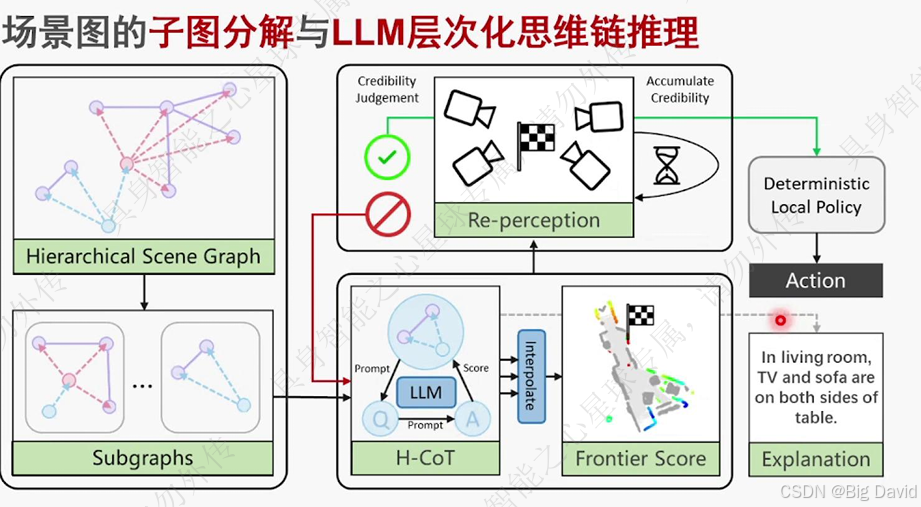
(2)框架概述
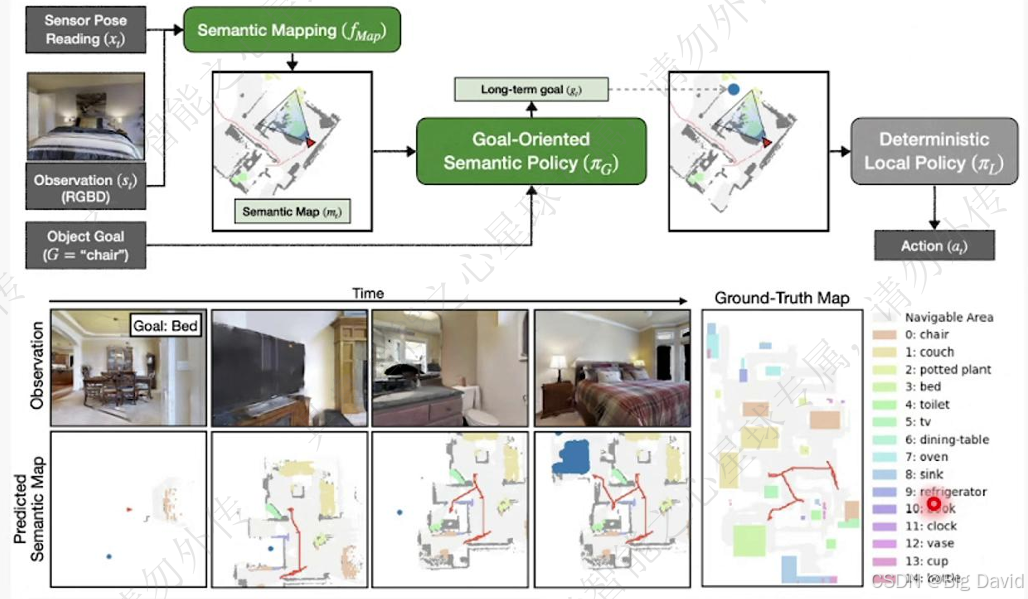
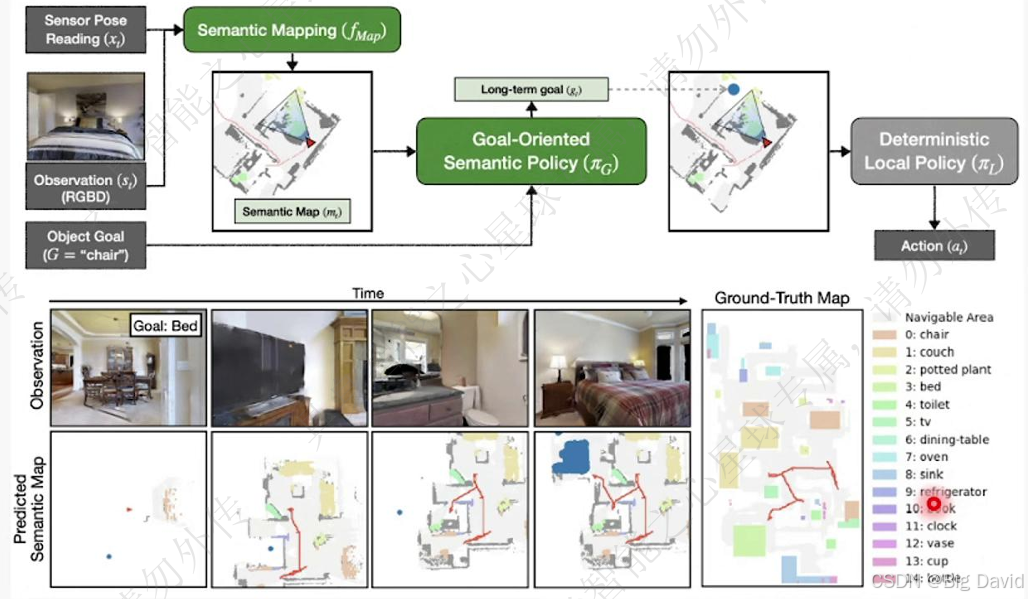
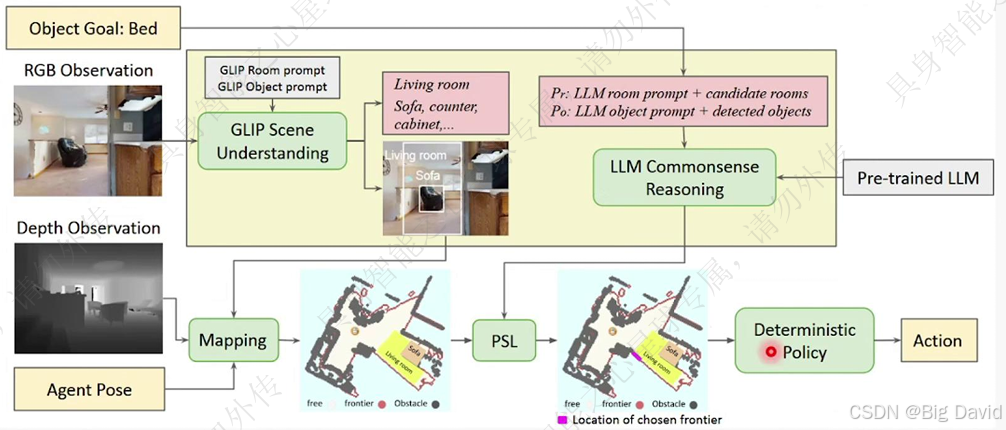
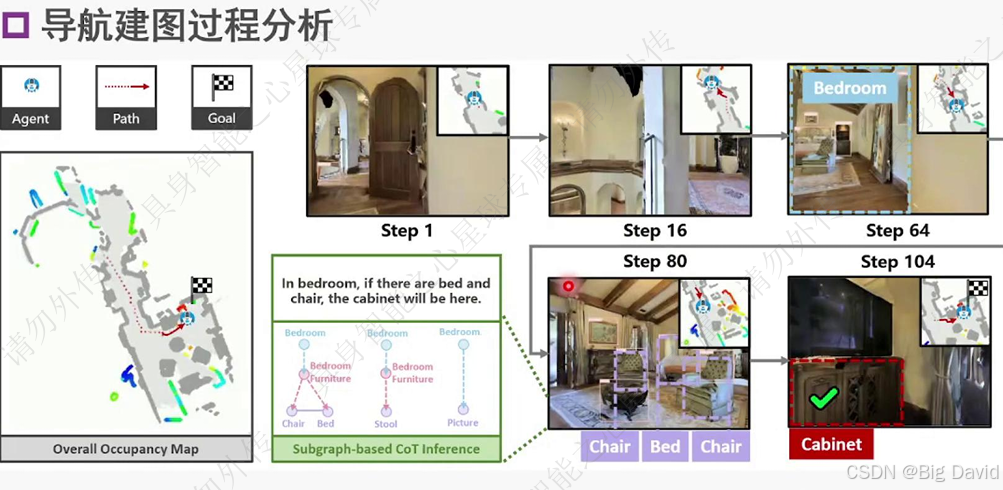
建立在线3D场景图、CoT推理目标位置、路径规划、目标重感知
SG-Nav主要就是上图

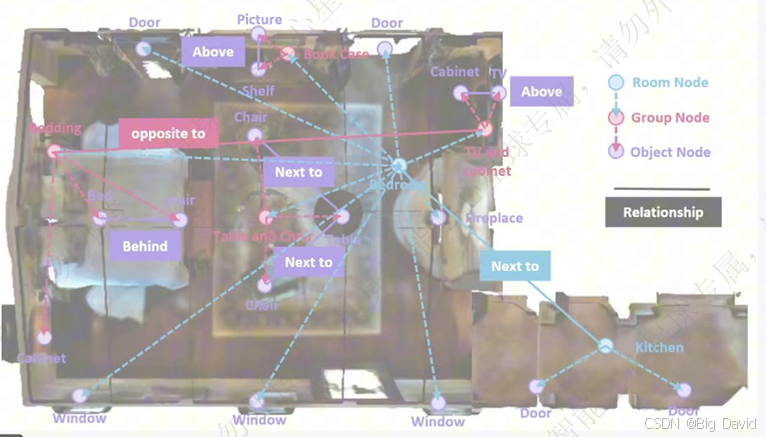
(3)3D场景图结构
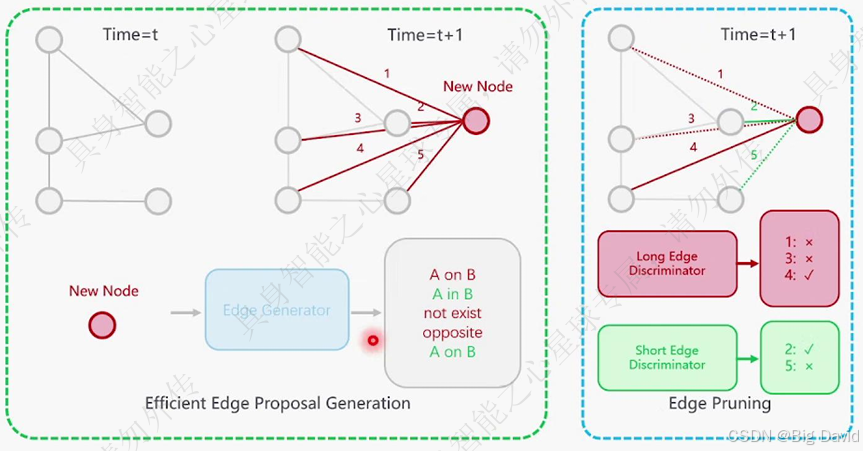
(4)在线建图:密集连接和剪枝
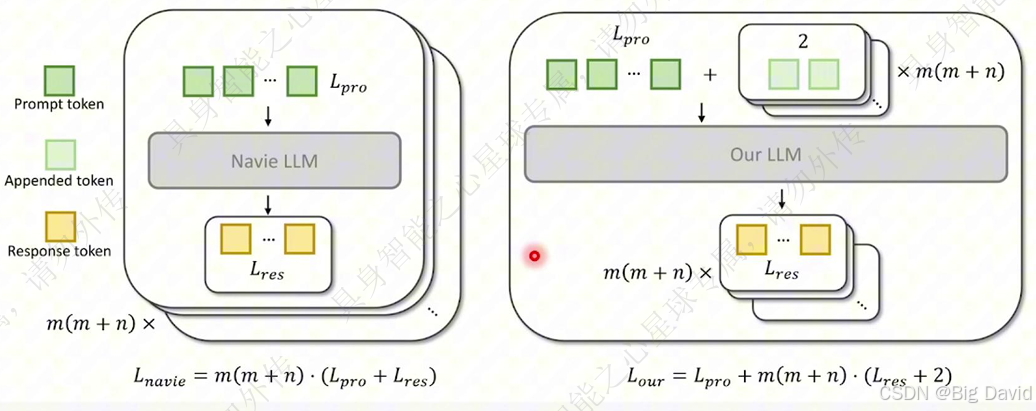
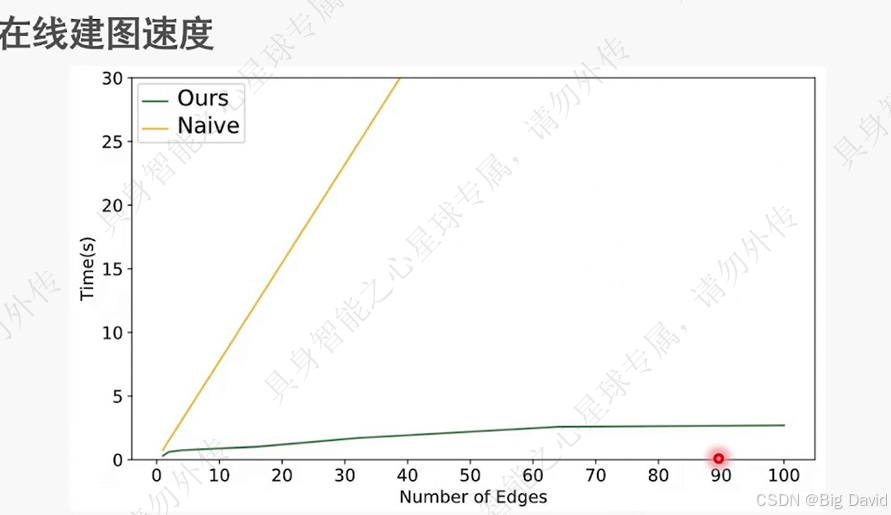
(5)高效率的在线建图设计
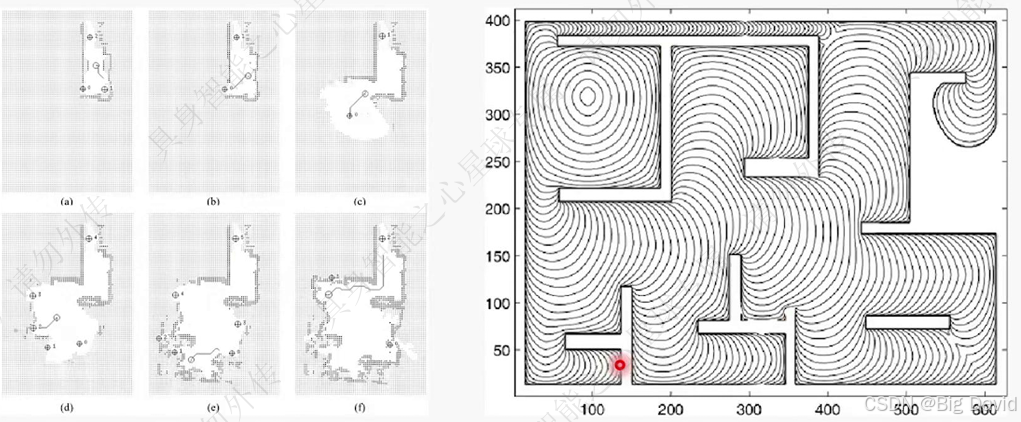
(6)边界点选择策略和底层路径规划
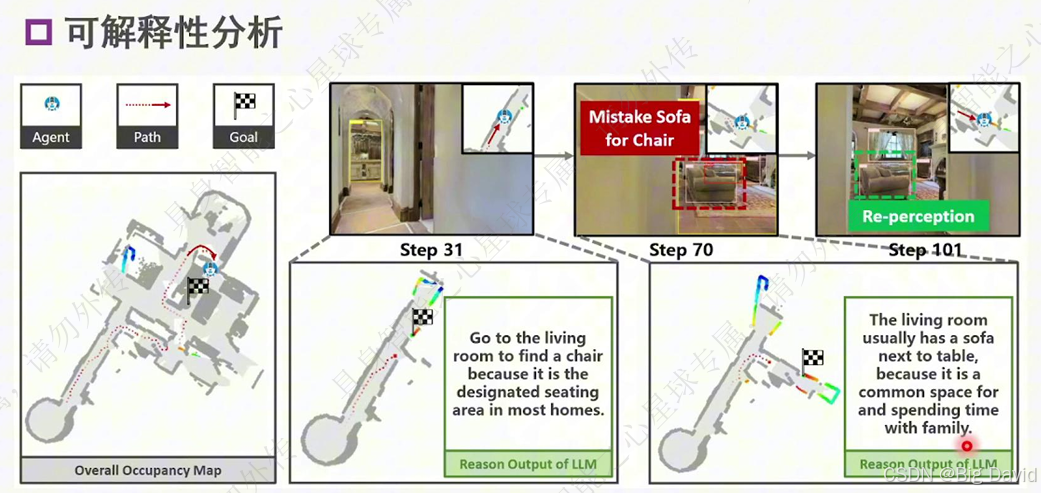
(7)可解释的层次化CoT
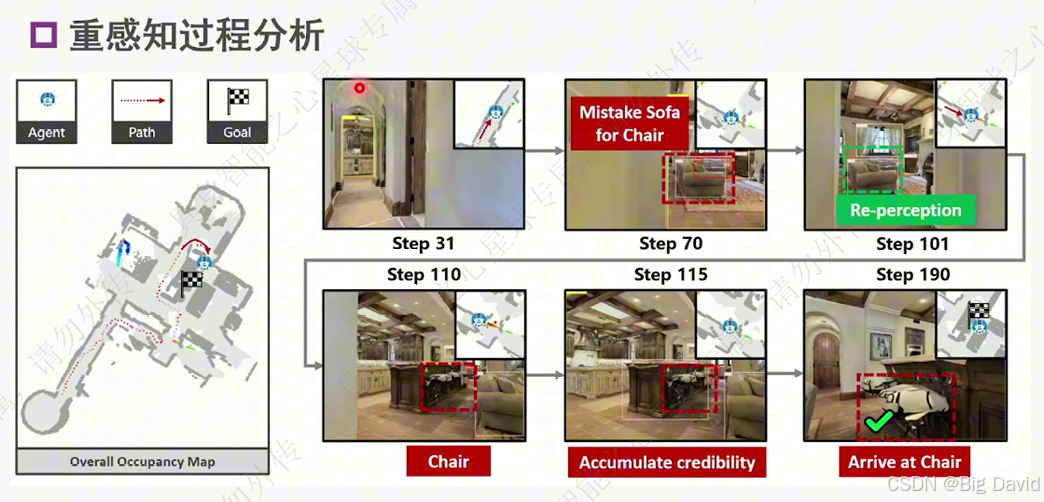
(8)重感知技术
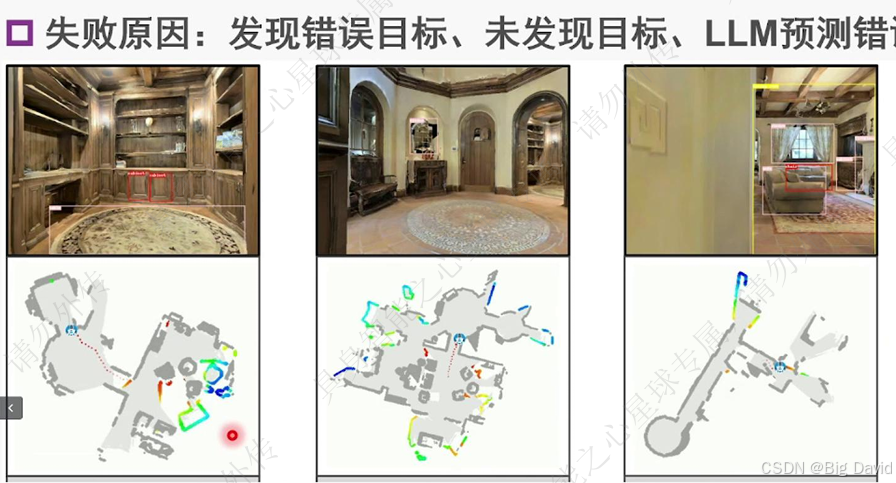
四、实验验证
(1)实验设置
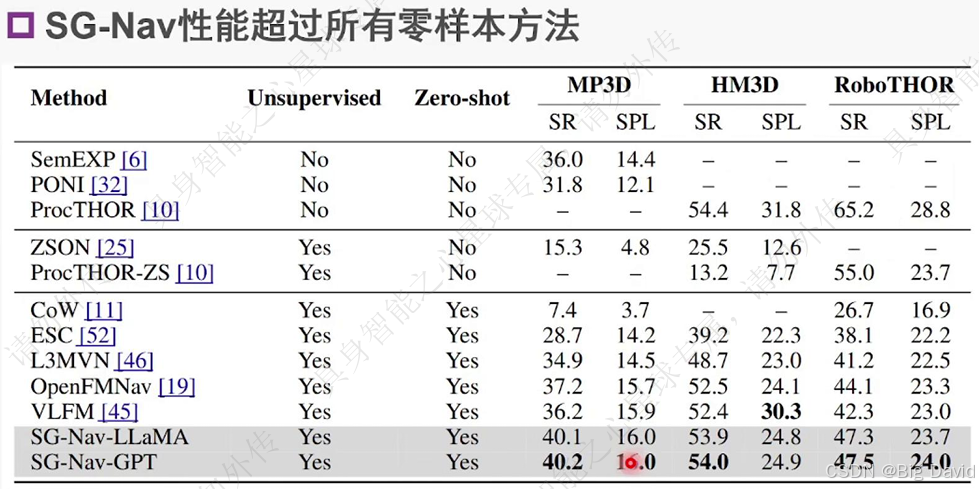
(2)对比零样本方法
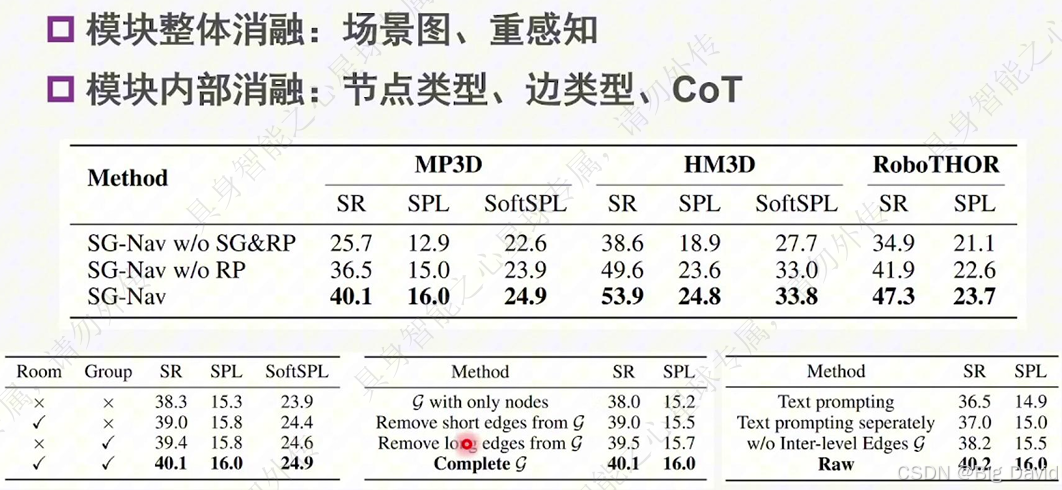
(3)消融实验