文章目录
一、What are strings?
The simplest distinction:
-
Character: a symbol in a written language, like letters, numerals, punctuation, space, etc.
-
String: a sequence of characters bound together
typeof("R")
## [1] "character"
typeof("Statistics") # strings are recognized as "character" data type in R
## [1] "character"
二、Whitespaces
Whitespaces count as characters and can be included in strings:
" "for space"\n"for newline"\t"for tab
str = "Dear Dr. Cai,\n\nPlease give me full marks in the final!\n\nSincerely, Mason"
str
## [1] "Dear Dr. Cai,\n\nPlease give me full marks in the final!\n\nSincerely, Mason"
Use cat() to print strings to the console, displaying whitespaces properly
cat(str) # concatenate and print
## Dear Dr. Cai,
##
## Please give me full marks in the final!
##
## Sincerely, Mason
三、Vectors/matrices of strings
The character is a basic data type in R (like numeric, or logical), so we can make vectors or matrices from them. Just like we would with numbers
str.vec = c("Statistical", "Computing", "isn't that bad") # Collect 3 strings
str.vec # All elements of the vector
## [1] "Statistical" "Computing" "isn't that bad"
str.vec[3] # The 3rd element
## [1] "isn't that bad"
str.vec[-(1:2)] # All but the 1st and 2nd
## [1] "isn't that bad"
str.mat = matrix("", 2, 3) # Build an empty 2 x 3 matrix
str.mat[1,] = str.vec # Fill the 1st row with str.vec
str.mat
## [,1] [,2] [,3]
## [1,] "Statistical" "Computing" "isn't that bad"
## [2,] "" "" ""
str.mat[2,1:2] = str.vec[1:2] # Fill the 2nd row, only entries 1 and 2, with those of str.vec
## [,1] [,2] [,3]
## [1,] "Statistical" "Computing" "isn't that bad"
## [2,] "Statistical" "Computing" "isn't a fad"
str.mat[2,3] = "isn't a fad" # Replace the 2nd row, 3rd entry, with a new string
str.mat # All elements of the matrix
t(str.mat) # Transpose of the matrix
## [,1] [,2]
## [1,] "Statistical" "Statistical"
## [2,] "Computing" "Computing"
## [3,] "isn't that bad" "isn't a fad"
四、Converting other data types to strings
Easy! Make things into strings with as.character()
as.character(0.8)
## [1] "0.8"
as.character(8e+10)
## [1] "8e+10"
as.character(1:5)
## [1] "1" "2" "3" "4" "5"
as.character(TRUE)
## [1] "TRUE"
五、Converting strings to other data types
Not as easy! Depends on the given string, of course
as.numeric("0.5")
## [1] 0.5
as.numeric("0.5 ")
## [1] 0.5
as.numeric("5e-10")
## [1] 5e-10
as.numeric("Hi!")
## Warning: NAs introduced by coercion
## [1] NA
as.logical("TRUE")
## [1] TRUE
as.logical("T")
## [1] TRUE
as.logical("true")
## [1] TRUE
as.logical("TRU")
## [1] NA
六、Number of characters
Use nchar() to count the number of characters in a string
nchar("coffee")
## [1] 6
nchar("code monkey")
## [1] 11
length("code monkey")
## [1] 1
length(c("code", "monkey"))
## [1] 2
nchar(c("code", "monkey")) # Vectorization!
## [1] 4 6
七、Getting a substring
1、Getting a substring
Use substr() to grab a subsequence of characters from a string, called a substring
phrase = "Give me a break"
substr(phrase, 1, 4)
## [1] "Give"
substr(phrase, nchar(phrase)-4, nchar(phrase))
## [1] "break"
substr(phrase, nchar(phrase)+1, nchar(phrase)+10)
## [1] ""
nchar(substr(phrase, nchar(phrase)+1, nchar(phrase)+10))
## [1] 0
2、substr() vectorizes
Just like nchar(), and many other string functions
presidents = c("Clinton", "Bush", "Reagan", "Carter", "Ford")
substr(presidents, 1, 2) # Grab the first 2 letters from each
## [1] "Cl" "Bu" "Re" "Ca" "Fo"
substr(presidents, 1:5, 1:5) # Grab the first, 2nd, 3rd, etc.
## [1] "C" "u" "a" "t" ""
substr(presidents, 1, 1:5) # Grab the first, first 2, first 3, etc.
## [1] "C" "Bu" "Rea" "Cart" "Ford"
substr(presidents, nchar(presidents)-1, nchar(presidents)) # Grab the last 2 letters from each
## [1] "on" "sh" "an" "er" "rd"
3、Replace a substring
Can also use substr() to replace a character, or a substring
phrase
## [1] "Give me a break"
substr(phrase, 1, 1) = "L"
phrase # "G" changed to "L"
## [1] "Live me a break"
substr(phrase, 1000, 1001) = "R"
phrase # Nothing happened
## [1] "Live me a break"
substr(phrase, 1, 4) = "Show"
phrase # "Live" changed to "Show"
## [1] "Show me a break"
4、Splitting a string
Use the strsplit() function to split based on a keyword
ingredients = "chickpeas, tahini, olive oil, garlic, salt"
split.obj = strsplit(ingredients, split=",")
split.obj
## [[1]]
## [1] "chickpeas" " tahini" " olive oil" " garlic" " salt"
class(split.obj)
## [1] "list"
length(split.obj)
## [1] 1
Note that the output is actually a list! (With just one element, which is a vector of strings)
5、strsplit() vectorizes
Just like nchar(), substr(), and the many others
ingredients = "chickpeas, tahini, olive oil, garlic, salt"
animals = "Cat, Dog, Tiger, Elephant, Monkey, Lion"
cars = "Ferrari, Benz, BWM, Tesla"
split.list = strsplit(c(ingredients, animals, cars), split=",")
split.list
## [[1]]
## [1] "chickpeas" " tahini" " olive oil" " garlic" " salt"
##
## [[2]]
## [1] "Cat" " Dog" " Tiger" " Elephant" " Monkey" " Lion"
##
## [[3]]
## [1] "Ferrari" " Benz" " BWM" " Tesla"
- Returned object is a list with 3 elements
- Each one a vector of strings, having lengths 5, 6, and 4
- Do you see why
strsplit()needs to return a list now?
6、Splitting character-by-character
Finest splitting you can do is character-by-character: use strsplit() with split=""
split.chars = strsplit(ingredients, split="")[[1]]
split.chars
## [1] "c" "h" "i" "c" "k" "p" "e" "a" "s" "," " " "t" "a" "h" "i" "n" "i" ",## [20] "o" "l" "i" "v" "e" " " "o" "i" "l" "," " " "g" "a" "r" "l" "i" "c" ",## [39] "s" "a" "l" "t"
length(split.chars)
## [1] 42
nchar(ingredients) # Matches the previous count
## [1] 42
7、Combining strings
Use the paste() function to join two (or more) strings into one, separated by a keyword
paste("Spider", "Man") # Default is to separate by " "
## [1] "Spider Man"
paste("Spider", "Man", sep="-")
## [1] "Spider-Man"
paste("Spider", "Man", "does whatever", sep=", ")
## [1] "Spider, Man, does whatever"
8、paste() vectorizes
Just like nchar(), substr(), strsplit(), etc. Seeing a theme yet?
presidents
## [1] "Clinton" "Bush" "Reagan" "Carter" "Ford"
paste(presidents, c("D", "R", "R", "D", "R"))
## [1] "Clinton D" "Bush R" "Reagan R" "Carter D" "Ford R"
paste(presidents, "D") # Notice the recycling
## [1] "Clinton D" "Bush D" "Reagan D" "Carter D" "Ford D"
paste(presidents, " (", 42:38, ")", sep="")
## [1] "Clinton (42)" "Bush (41)" "Reagan (40)" "Carter (39)" "Ford (38)"
9、Condensing a vector of strings
Can condense a vector of strings into one big string by using paste() with the collapse argument
presidents
## [1] "Clinton" "Bush" "Reagan" "Carter" "Ford"
paste(presidents, collapse="; ")
## [1] "Clinton; Bush; Reagan; Carter; Ford"
paste(presidents, collapse=NULL) # No condensing, the default
## [1] "Clinton" "Bush" "Reagan" "Carter" "Ford"
presidents1 <- paste(presidents, " (", 42:38, ")", sep="") # paste two vectors into one vector
presidents1
## [1] "Clinton (42)" "Bush (41)" "Reagan (40)" "Carter (39)" "Ford (38)"
presidents2 <- paste(presidents1, collapse="; ") # condense the vector into a character string
presidents2
## [1] "Clinton (42); Bush (41); Reagan (40); Carter (39); Ford (38)"
- We can combine the two steps together
paste(presidents, " (", 42:38, ")", sep="", collapse="; ")
## [1] "Clinton (42); Bush (41); Reagan (40); Carter (39); Ford (38)"
八、Text from the outside
1、Text from the outside
king.lines = readLines("king.txt")
class(king.lines) # We have a character vector
## [1] "character"
length(king.lines) # Many lines (elements)!
## [1] 59
king.lines[1:3] # First 3 lines
## [1] "Five score years ago, a great American, in whose symbolic shadow we st.."
## [2] ""
## [3] "But 100 years later, the Negro still is not free. One hundred years last"
2、Reconstitution
Reconstitution: Make one long string, then split the words
king.text = paste(king.lines, collapse=" ")
king.words = strsplit(king.text, split=" ")[[1]]
# Sanity check
substr(king.text, 1, 150)
## [1] "Five score years ago, a great American, in whose symbolic shadow we st.."
king.words[1:20]
## [1] "Five" "score" "years" "ago,"
## [5] "a" "great" "American," "in"
## [9] "whose" "symbolic" "shadow" "we"
## [13] "stand" "today," "signed" "the"
## [17] "Emancipation" "Proclamation." "This" "momentous"
3、Counting words
Our most basic tool for summarizing text: word counts, retrieved using table()
king.wordtab = table(king.words)
class(king.wordtab)
## [1] "table"
length(king.wordtab)
## [1] 622
king.wordtab[1:10]
## king.words
## - ...the ...to 'tis 100 1963 a able Again
## 29 2 1 1 1 1 1 37 8 1
What did we get? Alphabetically sorted unique words, and their counts = number of appearances
4、The names are words, the entries are counts
Note: this is actually a vector of numbers, and the words are the names of the vector
king.wordtab[1:5]
## king.words
## - ...the ...to 'tis
## 29 2 1 1 1
king.wordtab[2] == 2
## -
## TRUE
names(king.wordtab)[2] == "-"
## [1] TRUE
So with named indexing, we can now use this to look up whatever words we want
king.wordtab["dream"]
## dream
## 9
king.wordtab["equality"] # NA means King never mentioned equality
## <NA>
## NA
5、Most frequent words
Let’s sort in decreasing order, to get the most frequent words
king.wordtab.sorted = sort(king.wordtab, decreasing=TRUE)
length(king.wordtab.sorted)
## [1] 622
head(king.wordtab.sorted, 20) # First 20
## king.words
## of the to and a be will is
## 98 97 57 40 37 32 29 25 23
## as freedom in we from have our I Negro
## 19 18 18 18 17 17 16 14 13
tail(king.wordtab.sorted, 20) # Last 20
## king.words
## walk, wallow warm waters, well were Whe
## 1 1 1 1 1 1
## whirlwinds whites whose winds with. withering wrongful
## 1 1 1 1 1 1
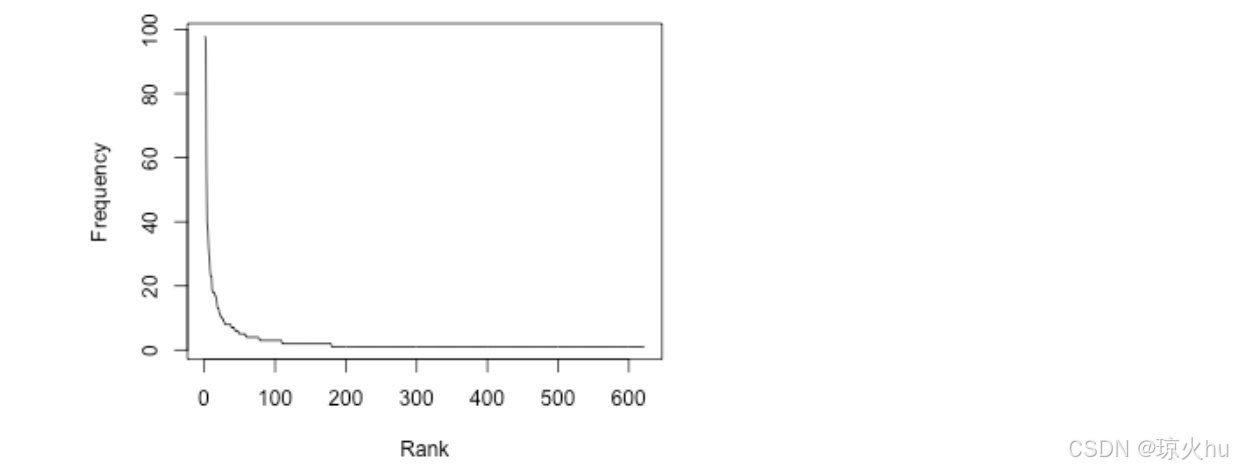
6、Visualizing frequencies
Let’s use a plot to visualize frequencies
nw = length(king.wordtab.sorted)
plot(1:nw, as.numeric(king.wordtab.sorted), type="l",xlab="Rank", ylab="Frequency")