目录
- 参考
- 概念
- 运行模式
- 数据存储
- 分区
- 表分桶概念原理
- 库表操作
- (1)创建分桶表创建用户表“user info”,并根据user id进行分桶,桶的数量为6,命令如下:
- > 创建成功后,查看表“user info”的描述信息,命令及主要描述信息如下:
- (2)创建中间表。执行以下命令,创建一张中间表“user info tmp”
- (3)向中间表导入数据。执行以下命令,将数据导入到表“user info tmp”中:
- (4)将中间表的数据导入到分桶表。执行以下命令,将中间表“user_info_tmp”中的数据导入到分桶表“user_ info”中:
- (5)查看桶数据对应的HDFS数据仓库文件查看HDFS数据仓库中表“user info”所在目录下的所有文件,可以看到,在目录user info下生成了6个文件,编号分别从而表“user info”的数据则均匀的分布在这些文件中,如图
- Hive自定义函数隐藏电话中间4位
- Hive JDBC 操作
- Hive整合HBase
参考
经典大数据开发实战(Hadoop &HDFS&Hive&Hbase&Kafka&Flume&Storm&Elasticsearch&Spark)
概念
Hive 是基于 Hadoop 的一个 数据仓库 工具,可以理解是客户端工具,严格来说,不是数据库,主要是让开发人员能够通过 SQL 来计算和处理 HDFS 上的结构化数据,适用于离线的批量数据计算。可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能。
Hive 中的表纯逻辑。
Hive 本身不存储和计算数据,它完全依赖于 HDFS 和 MapReduce,Hive 需要用到 HDFS 存储文件,需要用到 MapReduce 计算框架,而 MapReduce 处理数据是基于行的模式。
Hive 使用 Hadoop 来分析处理数据,而 Hadoop 系统是批处理系统,因此不能保证处理的低迟延问题,而且 只支持导入和查询。
Hive是一个基于Hadoop的数据仓库架构,使用SQL语句读、写和管理大型分布式数据集。Hive可以将SQL语句转化为MapReduce(或Apache Spark和Apache Tez)任务执行,大大降低了Hadoop的使用门槛,减少了开发MapReduce程序的时间成本。可以将Hive理解为一个客户端工具,其提供了一种类SQL查询语言,称为 HiveQL。这使得Hive十分适合数据仓库的统计分析,能够轻松使用HiveQL开启数据仓库任务,如提取/转换/加载(ETL)、分析报告和数据分析。Hive不仅可以分析HDFS文件系统中的数据也可以分析其他存储系统,例如HBase。
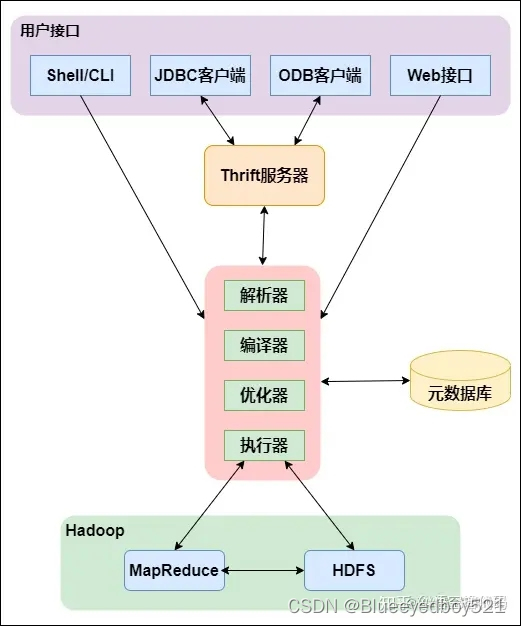
架构体系
-
用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI 为 shell 命令行;JDBC/ODBC 是 Hive 的JAVA 实现,与传统数据库 JDBC 类似;WebGUI 是通过浏览器访问 Hive。 -
元数据存储
通常是存储在关系数据库如 mysql/derby 中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 -
Driver驱动程序,
包括语法解析器、计划编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS中,并在随后有执行引擎调用执行 -
执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎 -
解释器、编译器、优化器、执行器
完成 HQL 查询语句从词法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有MapReduce 调用执行。 -
数据存储
Hive没有专门的数据存储格式,也没有为数据建立索引,Hive中所有数据都存储在HDFS中。
Hive包含以下数据模型:表、外部表、分区和桶
用mysql存储元数据
数据类型
Hive的数据类型分为基本数据类型和复杂数据类型,基本数据类型与常用的大部分数据库类似,包括以下几种
- 整型:TINYINT、SMALLINT、INT、BIGINT布尔型:TRUE/FALSE
- 浮点型:FLOAT(单精度)、DOUBLE(双精度)
- 定点型:DECIMAL
- 字符型:STRING、VARCHAR、CHAR
- 日期和时间型:TIMESTAMP、DATE进制型:BINARY。用于存储变长的二进制数据
- 复杂类型包括:
结构体、键值对、数组。
运行模式
Hive根据MetastoreServer的位置不同可以分为三种运行模式:内嵌模式、本地模式和远程模式。
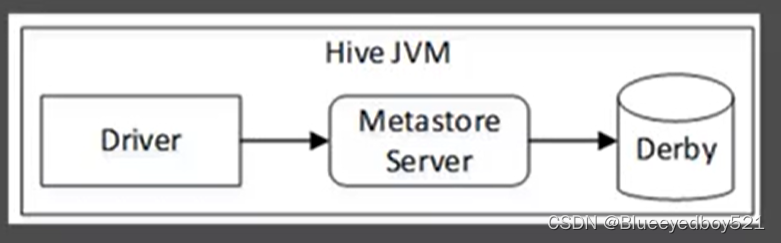
内嵌模式
内嵌模式是Hive入门的最简单方法,是Hive默认的启动模式,使用Hive内嵌的Derby数据库存储元数据,并将数据存储于本地磁盘上。在这种模式下,MetastoreServer、Hive服务、Derby三者运行于同一个M进程中,这就意味着,每次只能允许一个会话对Derby中的数据进行访问。若开启第二个会话进行访问,Hive将提示报错。因此内嵌模式常用于测试,不建议用于生产环境。内嵌模式的架构如图:
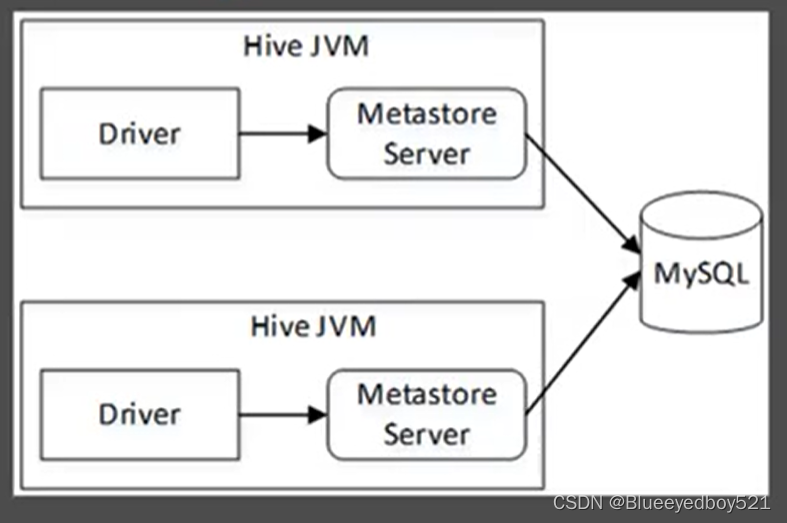
本地模式
需要使用其他关系型数据库来存储Hive元数据信息,最常用的为MSQL。在这种模式下,MetastoreServer与Hive服务仍然运行于同一个M进程中,但是MySQL数据库可以独立运行在另一个进行中,可以是同一台机器也可以是远程的机器。因此,本地模式支持多会话以及多用户对Hive数据的访问,每当开启一个连接会话,Hive将开启一个IVM进程。
本地模式的架构如图
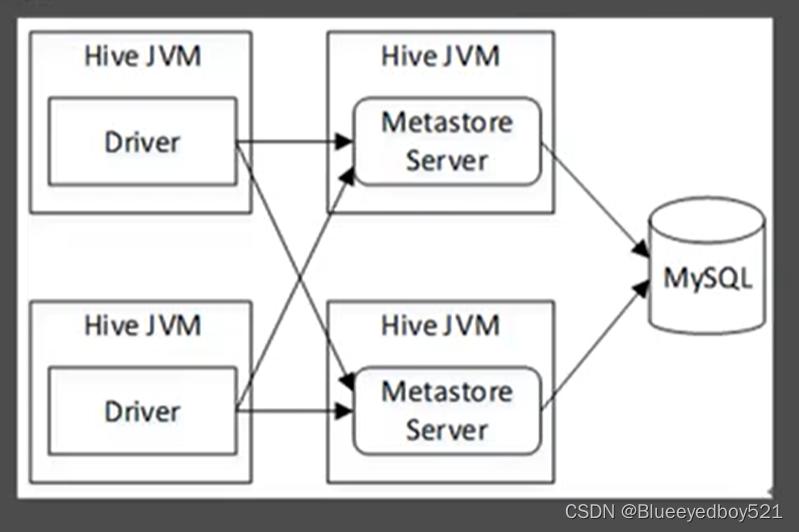
远程模式
将Metastore Server分离了出来,作为一个单独的进程,并且可以部罗多个,运行于不同的机器上。这样的模式,将数据库层完全置于防火墙后,使客户端访问时不需要数据库凭据(用户名和密码),提高了可管理性和安全性,
远程模式的架构如图:
远程模式分为服务端(Metastore Server,默认端口是9083)与客户端两部分,服务端的配置与本地模式相同,客户端需要单独配置。本例将centos01节点作为Hive的服务端,centos02节点作为Hive 的客户端。在本地模式的基础上继续进行远程模式的配置。
数据存储
数据都是存储在hdfs中
内部表
如下中student是default数据库中的标
test_db是我们自己创建的库,
表的元信息

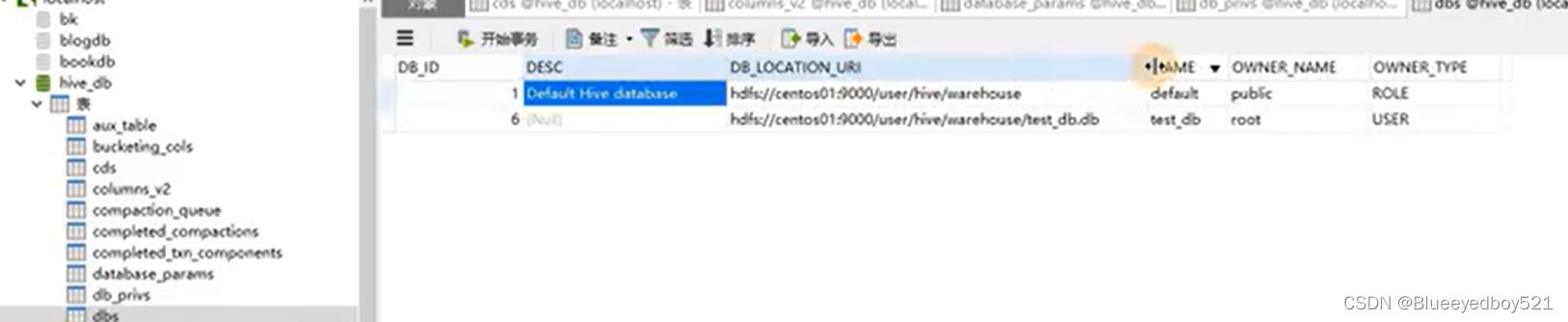
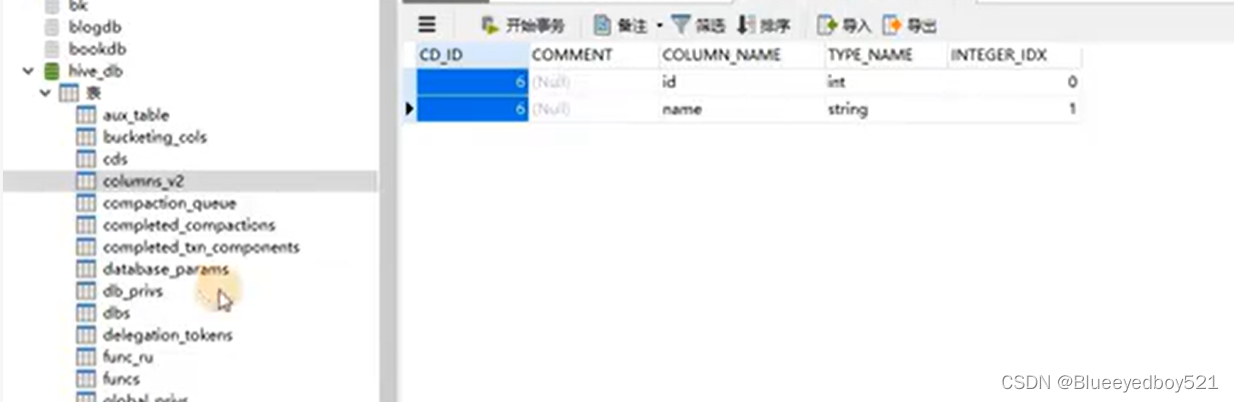
本地文件导入live
新建学生成绩表score,其中学号sno为整型,姓名name为字符串,得分score为整型,并指定以Tab键作为分隔符
hive> CREATE TABLE score(
> Sno INT,
> name STRING,
> score INT)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
在本地目录/home/hadoop中新建score.txt文件,并写入以下内容,列之间用Tab键隔开
1001 zhangsan 98
1002 lisi 92
1003 wanawu 87
执行以下命令,将score.txt中的数据导入到表score中:
hive> LOAD DATA LOCAL INPATH '/home/hadoop/score.txt' INTO TABLE score;
查询表score的所有数据:
hive> SELECT * FROM score;
OK
1001 zhangsan 98
1002 lisi 92
1003 wangwu 87
在hdfs中查看,可以发现导入的方式是直接拷贝文件了
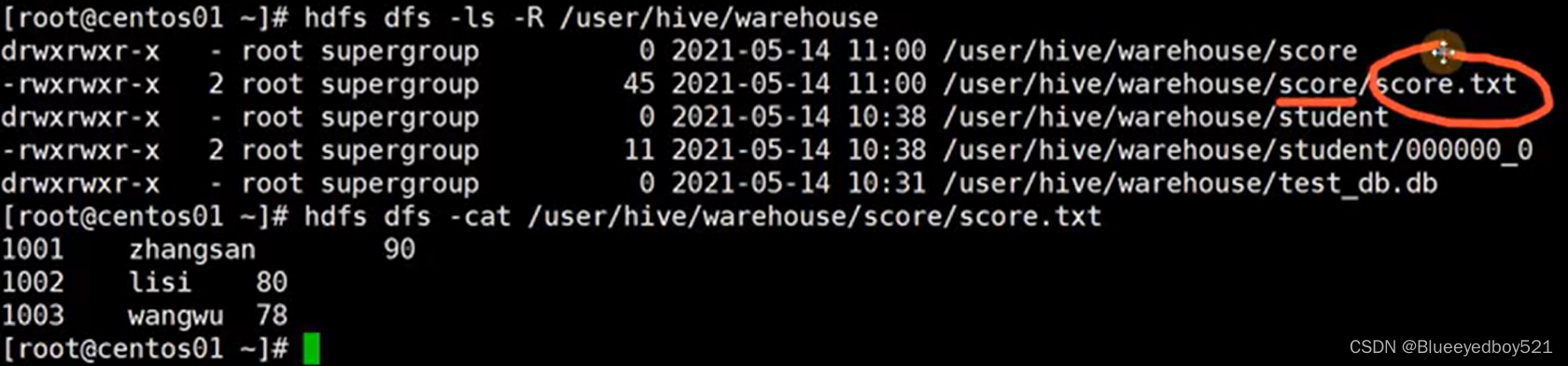
(5)删除表执行以下命令,删除test db数据库中的学生表student:
外部表 EXTERNAL
创建外部表时,使用LOCATION关键字,可以将表与HDFS中已经存在的数据相关联。
例如,执行以下命令,在数据库test db中创建外部表emp3,并指定表数据所在的HDFS中的存储目录为/input/hive(该目录已经存在数据文件emp.txt):
hive> CREATE EXTERNAL TABLE test db.emp3(
> id INT,
> name STRING)
> ROW FORMAT DELIMITED FIELDS
> TERMINATED BY '\t' LOCATION '/input/hive';
然后执行以下命令,查询表emp3的所有数据,发现该表已与数据文件emp.txt相关联:
hive> SELECT *FROM test db.emp3;
OK
1 xiaoming
2 zhangsan
3 wangqiang
内部表和外部表的区别
1.内部表:未被external修饰;外部表:被external修饰。
区别:
(1)内部表数据由Hive自身管理,外部表数据由HDFS管理;
(2)内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse), 外部表数据的存储位置由自己制定;
(3)删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
2.Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
需要注意的是传统数据库对表数据验证是 schema on write(写时模式),而 Hive 在load时是不检查数据是否符合schema的,hive 遵循的是 schema on read(读时模式),只有在读的时候hive才检查、解析具体的数据字段、schema。
读时模式的优势是load data 非常迅速,因为它不需要读取数据进行解析,仅仅进行文件的复制或者移动。
写时模式的优势是提升了查询性能,因为预先解析之后可以对列建立索引,并压缩,但这样也会花费要多的加载时间。
分区
概念
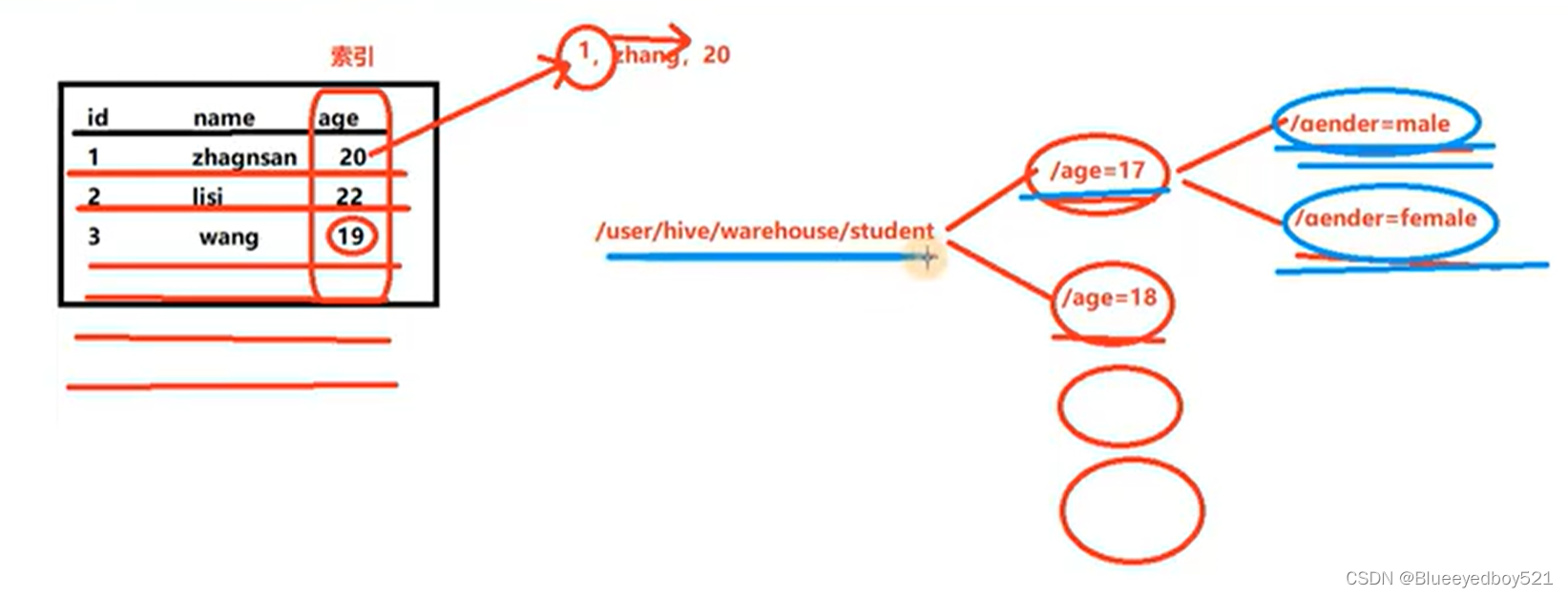
类似于索引。Hive分区是一种将表的数据按照某个列的值进行划分和存储的方式,旨在提高查询性能、管理灵活性以及支持更多的数据操作。通过分区,可以将数据按照特定的维度进行组织,使得查询只需要扫描特定分区的数据,从而减少了全表扫描的开销。如下就是以年龄和性别做分区,相当于在hdfs中创建年龄和性别多级目录
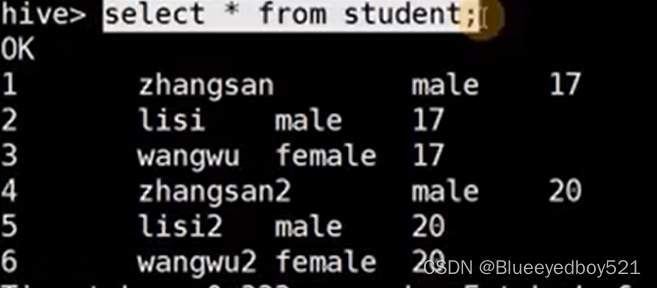
查询是结果如下:

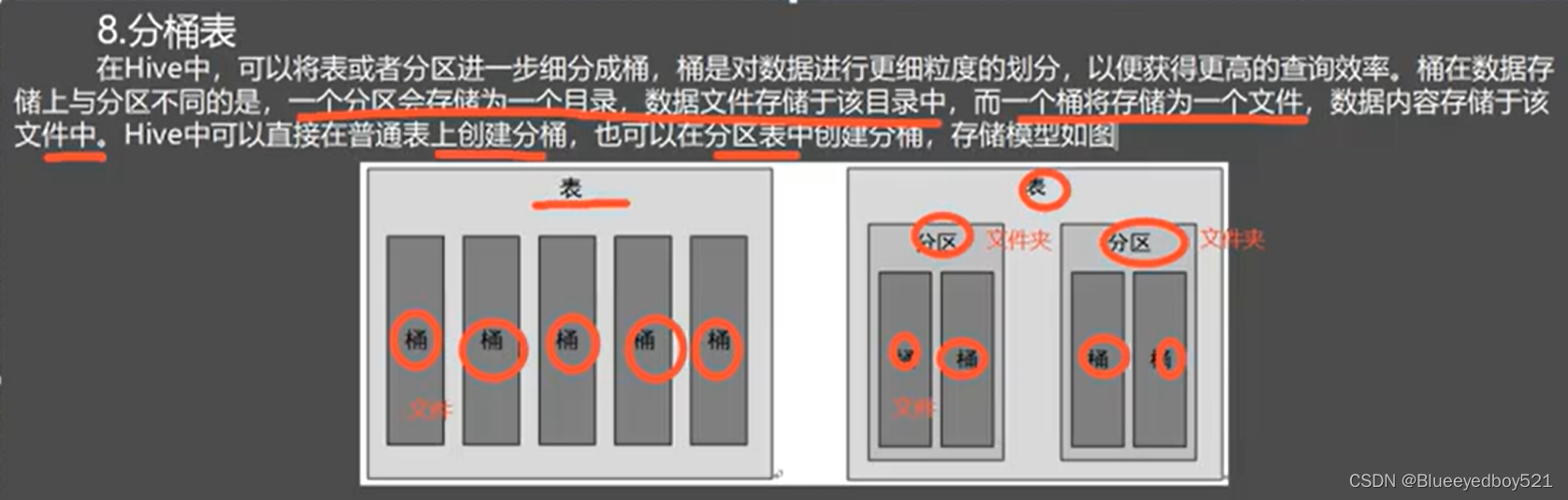
表分桶概念原理
分区表示一个文件夹,桶表示具体的文件
库表操作
(1)创建分桶表创建用户表“user info”,并根据user id进行分桶,桶的数量为6,命令如下:
hive > CREATE TABLE user_info (user id INT, name STRING)
> CLUSTERED BY(user id)
> INTO 6 BUCKETS
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t':
> 创建成功后,查看表“user info”的描述信息,命令及主要描述信息如下:
hive> DESC FORMATTED user info;
(2)创建中间表。执行以下命令,创建一张中间表“user info tmp”
hive> CREATE TABLE user_info_tmp (user id INT, name STRING)
> ROW FORMATDELIMITED FIELDSITERMINATED BY '\t';
(3)向中间表导入数据。执行以下命令,将数据导入到表“user info tmp”中:
hive> LOAD DATALOCAL INPATH '/home/hadoop/user_info.txt
> INTO TABLE user_info_tmp
(4)将中间表的数据导入到分桶表。执行以下命令,将中间表“user_info_tmp”中的数据导入到分桶表“user_ info”中:
hive> INSERT INTO TABLE user_info
> SELECT user id,name FROM user_info_tmp:
(5)查看桶数据对应的HDFS数据仓库文件查看HDFS数据仓库中表“user info”所在目录下的所有文件,可以看到,在目录user info下生成了6个文件,编号分别从而表“user info”的数据则均匀的分布在这些文件中,如图

Hive自定义函数隐藏电话中间4位
需求
当Hive提供的内置函数不能满足査询需求时,用户也可以根据自己的业务编写自定义函数(User Defined Functions,UDF),然后在HiveQL中调用。例如有这样一个需求:为了保护用户的隐私,当查询数据的时候,需要将用户手机号的中间四位用星号()代替,比如手机号18001292688需要显示为180***2688。这时候就可以写一个自定义函数来实现这个需求。
java引包
1.新建Java项目
在Eclipse中新建一个Java Maven项目,并在pom.xml中添加以下Maven依赖:<!–Hadoopcommon包->
<dependency>
<groupld>org.apache.hadoop</groupld>
<artifactld>hadoop-common</artifactld>
<version:3.3.1</version>>
</dependency>
<!--Hive UDF依赖包-->
<dependency>
<groupld>org.apache.hive</qroupld>
<artifactld>hive-exec</artifactld>
<version>2.3.3</version>
</dependency>
<!--指定JDK工具包的位置,需要本地配置好环境变量JAVA HOME->
<dependency>
<groupld>jdk.tools</qroupld>
<artifactld>jdk.tools</artifactld>
<version>1.8</version>
<scope>svstem</scope>
<systemPath>$ÚAVA HOME}/lib/tools,jar</systemPath>
</dependency>
编写java代码及打包
public class MyUDE extends UDE
/**
*女业
@param text
调用函数时需要传入的参数河
*@return 隐藏后的手机号码 自定义所数类需要有一个名为evaluate()的方法,Hive将调用该方法
**/
publie string evaluate(Text text){
String result="手机号码错误!";
if(text !=null && text.getLength()== 11){
string inputstr =text.toString();
StringBuffer sb =new StringBuffer();
sb.append(inputstr.substring(0,3));
sb.append("****");
sb.append(inputstr.substring(7));
result = sb.tostring();
}
return result;
}
hive引入包
hive> add jar /opt/softwares/hadoopdemo2-0.0.1-SNAPSHOT.jar
(3)创建函数名称
在Hive CL中执行以下命令,创建一个自定义函数名称并关联自定义类MyUDF。例如创建函数名称为“formatPhone”
hive> CREATE TEMPORARY FUNCTON formatPhone AS 'hive.demo.MyUDE"
上述命令中的hive.demo.MyUDF为类MyUDF.java所在的包的全路径,
(4)调用UDF
例如在Hive数据库test db中有一张用户表“t_user2”,该表有两列:id(整型)和phone(字符串),表数据如下
hive> SELECT * FROM t_user2
现需要在查询该表数据时将手机号的中间四位进行隐藏显示,命令及查询结果如下:
hive> SELECT id,formatPhone(phone) AS newPhone FROM t_user2;
OK
id newphone
1 131****7589
2 158****5673
3 180****2688
Hive JDBC 操作
public class HiveJDBCTest{
public static void main(Stringl arqs)throws Exception {
// 驱动名称
String driver ="org.apache.hive.jdbc.HiveDriver";
//连接地址,默认使用端口10000,使用默认数据库
string url= "idbc:hive2://192.168.170.133:10000/default";
//用户名(Hadoop集群的登录用户)
String username ="hadoop";
//密码(默认为空)
String password = "";
//1.加载JDBC驱动
Class.forName(driver);
//2.获取连接
Connection conn= DriverManager.qetConnection(url,username, password);
Statement stmt = conn.createStatement();
// 3.执行查询
ResultSet res = stmt,executeQuery("select * from student");
//4.处理结果
while (res.next()){
System.out.println(res.getInt(1)+ "\t" + res.getstring(2));
}
//5.关闭资源
res.close();
stmt.close();
conn.close();
}
}
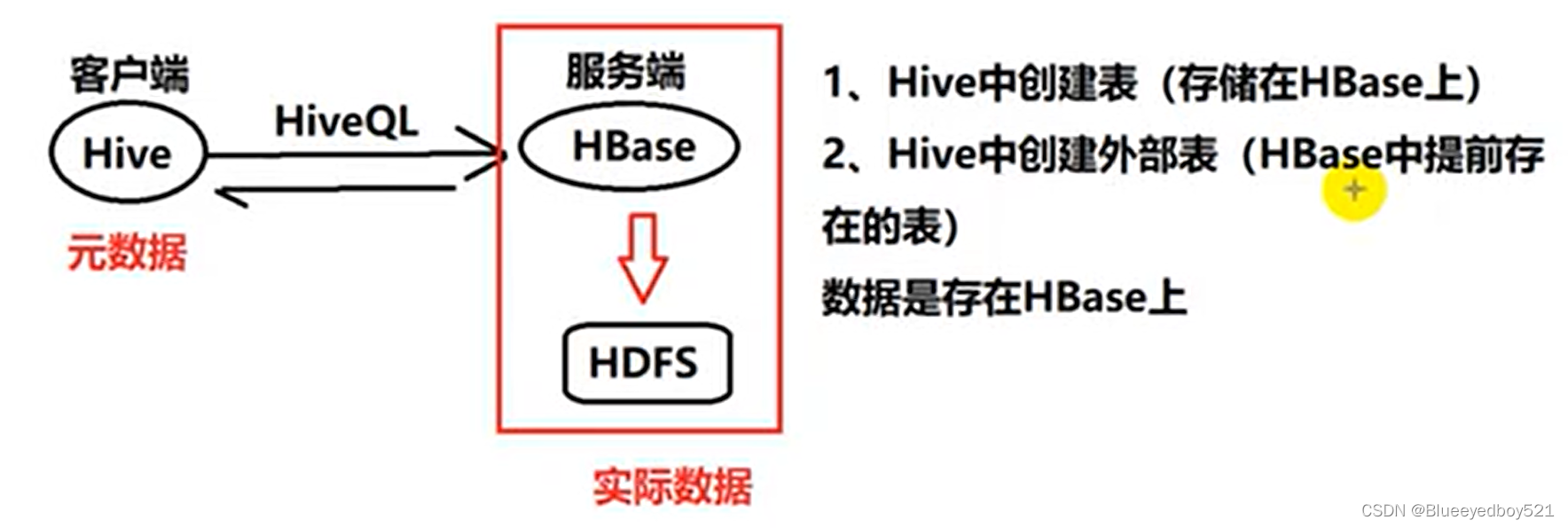
Hive整合HBase
整合配置文件
Hive创建表的同时创建HBase表
(1)在Hive中创建学生表“hive sludent”:
hive> CREATE TABLE hive_student(id INT,name STRING)
> STORED BY 'org.apacho.hadoop.hive.hbaso.HBaseStorageHandier'
> WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cfl:name")
> TBLPROPERTI8S("hbase.table.nane" = "hive_studont");
上述创建命令中的参数含义如下
- STORED BY :指定用于Hive与HBase通信的工具类HBaseStorageHandier
- WITH SERDEPROPERTIES:指定 HBase表与Hive 表对应的列。此处”:key, cfl:name"中的 key指的是 HBase表的 rowkey 列,对应 Hive表的id列;clf:name指的是 HBase 表中的列族 cfl和cfl中的列 name,对应 Hive表的 name 列。Hive 列与 HBase 列的对应不是通过列名称对应的,而是通过列的顺序。
- TBLPROPERTIES:指定HBase表的属性信息。参数值“hive_student”代表HBase的表名。
(2)创建成功后,新开一个XShel 窗口,在HBaseShell 中查看创建的表: