计算机视觉(Computer Vision,简称CV)是一种模拟人类视觉的科学,目标是让计算机能够感知、理解、分析、解释图像和视频数据。它在很多新兴领域都发挥着关键作用,包括人脸识别、自动驾驶、无人机、医学影像分析等等。
本文将为您介绍6个计算机视觉相关的开源项目,这些项目非常实用且功能强大,不仅在CV技术方面具有重要意义,而且为计算机视觉应用的发展提供了有力的支持。
1、OpenCV
OpenCV的全称是Open Source Computer Vision Library,是一个功能强大的跨平台计算机视觉和机器学习软件库,主要用于实时视觉应用。它提供了大量的图像和视频处理功能,包括特征检测、对象跟踪、运动分析、3D重建等等,是一个非常热门和基础的开源项目 。支持多种编程语言,比较热门的包括C++、Python、Objective-C、HTML等
它的特点:具有易用性、高效性、扩展性、跨平台兼容性、模块化设计

GitHub项目库地址:https://github.com/opencv
OpenCV网站:https://opencv.org
中文介绍:https://blog.csdn.net/chenlycly/article/details/131352357
2、Detectron2(目前在GitHub上29.4K星)
detectron2是Facebook开源的深度学习的目标检测框架,建立在Detectron和maskrcnn-benchmark基础之上,可以进行目标检测、语义分割、全景分割,以及人体体姿骨干的识别。目前新增了Densepose、Cascade R-CNN、PointRend、DeepLab、ViTDet、MViTv2等新模型;
模型可以导出为TorchScript格式或Caffe2格式进行部署。

detectron2框架的设计有以下一些优点:
1、强大:提供了包括目标检测、实例分割、全景分割等非常广泛的视觉任务模型库。
2、灵活:可以通过注册机制自定义模块或模型结构,从而进行扩展和改进。
3、易用:通过list of dict格式定义自己的数据集, 简单好用。
GitHub项目地址:https://github.com/facebookresearch/detectron2
官方文档:detector2.readthedocs.io/en/latest/
3、YOLOv10(目前在GitHub上8.3k星)
YOLOv10是毫秒级实时端到端目标检测的开源模型。5月25日,由清华大学研究人员推出YOLOv10,被认为是计算机视觉领域的突破性框架,它有效地将YOLO框架推End-to-End的推理范式。与 YOLOv9-C相比,在相同性能下,YOLOv10-B的延迟减少了46%,参数减少了25%。
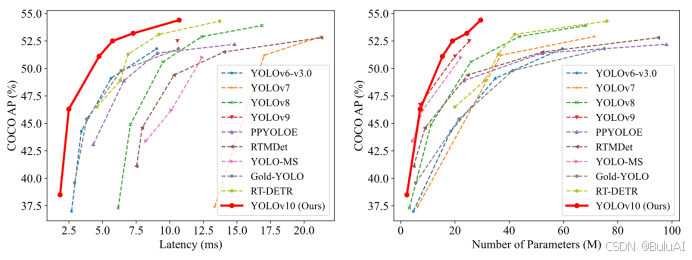
YOLOv10主要亮点:在效率和准确度方面有所突破,更值得注意的是它提出NMS-free训练的一致双分配策略来解决后处理中的冗余预测问题;
GitHub项目地址:https://github.com/THU-MIG/yolov10
论文地址:https://arxiv.org/pdf/2405.14458
4、MMDetection(目前在GitHub上28.6K星)
MMDetection是一个基于PyTorch的目标检测工具箱,包含了丰富的目标检测、实例分割、全景分割算法以及相关的组件和模块,也是OpenMMLab项目的一部分。MMDetection支持在Linux、Windows 和 macOS系统运行。官方建议需要Python 3.7+、CUDA 9.2+或PyTorch 1.8+。
MMDetection的主要特点包括:模块化设计、支持多种检测任务、高效

GitHub项目地址:https://github.com/open-mmlab/mmdetection
官方文档:GET STARTED — MMDetection 3.3.0 documentation
5、segment-anything(45.6K星)
segment-anything是由Meta提出的分割一切模型,简称SAM模型,是一个提示型模型。可根据点或框等输入提示生成高质量的物体蒙版,并可用于为图像中的所有物体生成蒙版。可以自动分割和识别图像、视频和音频中的任何对象,无需深度学习专业知识,是一个非常实用的图像处理工具。目前该模型已在包含1100 万张图像和 11 亿个蒙版的数据集上进行了训练,并且在各种分割任务中具有强大的零样本性能。

GitHub项目地址:https://github.com/facebookresearch/segment-anything
论文地址:https://arxiv.org/abs/2304.02643
demo地址:https://segment-anything.com/demo
6、Track-Anything (6.3K星)
Track-Anything,简称TAM,是一款灵活交互式的视频对象跟踪和分割工具,只需用户点击即可指定要跟踪和分割的任意目标而不需要手工标注,它是在Segment anything(SAM)的基础上开发出来的。SAM是针对图像的分割一切,而TAM是针对视频的分割一切。适用于:随着镜头变化的视频对象跟踪和分割;视频对象跟踪和分割的可视化开发和数据注释;
以目标为中心的相关视频任务,例如视频修复和编辑。
特点:易用、灵活而且可以跨平台。

GitHub项目地址:https://github.com/gaomingqi/Track-Anything
论文地址:https://arxiv.org/abs/2304.11968
教程地址:
https://github.com/gaomingqi/Track-Anything/blob/master/doc/tutorials.md
BuluAI是一家创新型的算力服务商,算力使用灵活,可为开发者提供强大计算资源和全面支持。帮助BuluAI的使用者能够更专注于计算机视觉技术的研究和优化,推动该领域的发展。产品预计9月份正式公测上线,敬请期待!