系统性能如何,有没有瓶颈,如何判断需要充分的世间,根据前人和自己的实际做个简单的判断.这次是用纯命令来分析.(,iostat,vmstat,top,sar)
1 iostat 磁盘IO 统计
cpu查看 iostat -c 1 3
`注意%iowait并不能反应磁盘瓶颈,%iowait = (cpu idle time)/(all cpu time),现在越是高速CPU是不是值越大.为什么是20ms呢?
设备查看 iostat -d 1 3
扩展分析 iostat -xtm 1 3
x 扩展统计信息
t 打印时间
m 数据传输单位Mb,当然可以用k,
输出结果参数一堆,我对觉得有用的参数分析一下
r/s 每秒读请求
w/s 每秒写请求
avgqu-sz 平均I/O队列长度 delta(aveq)/s/1000 (r/s+w/s)*await/1000
await 平均每次设备I/O操作的等待时间 (毫秒) (包括等待和处理时间)
%util 每秒中用于 I/O 操作利用率
如果持续avgqu-sz,await> 20ms,%util 值越高,就要分析cpu 和磁盘读写是否有问题了
一般来说,一次读写就是一次寻到+一次旋转延迟+数据传输的时间。由于,现代硬盘数据传输就是几微秒或者几十微秒的事情,远远小于寻道时间2~20ms和旋转延迟4~8ms,所以只计算这两个时间就差不多了,也就是15~20ms。只要大于20ms,就必须考虑是否交给磁盘读写的次数太多,导致系统性能降低了。`
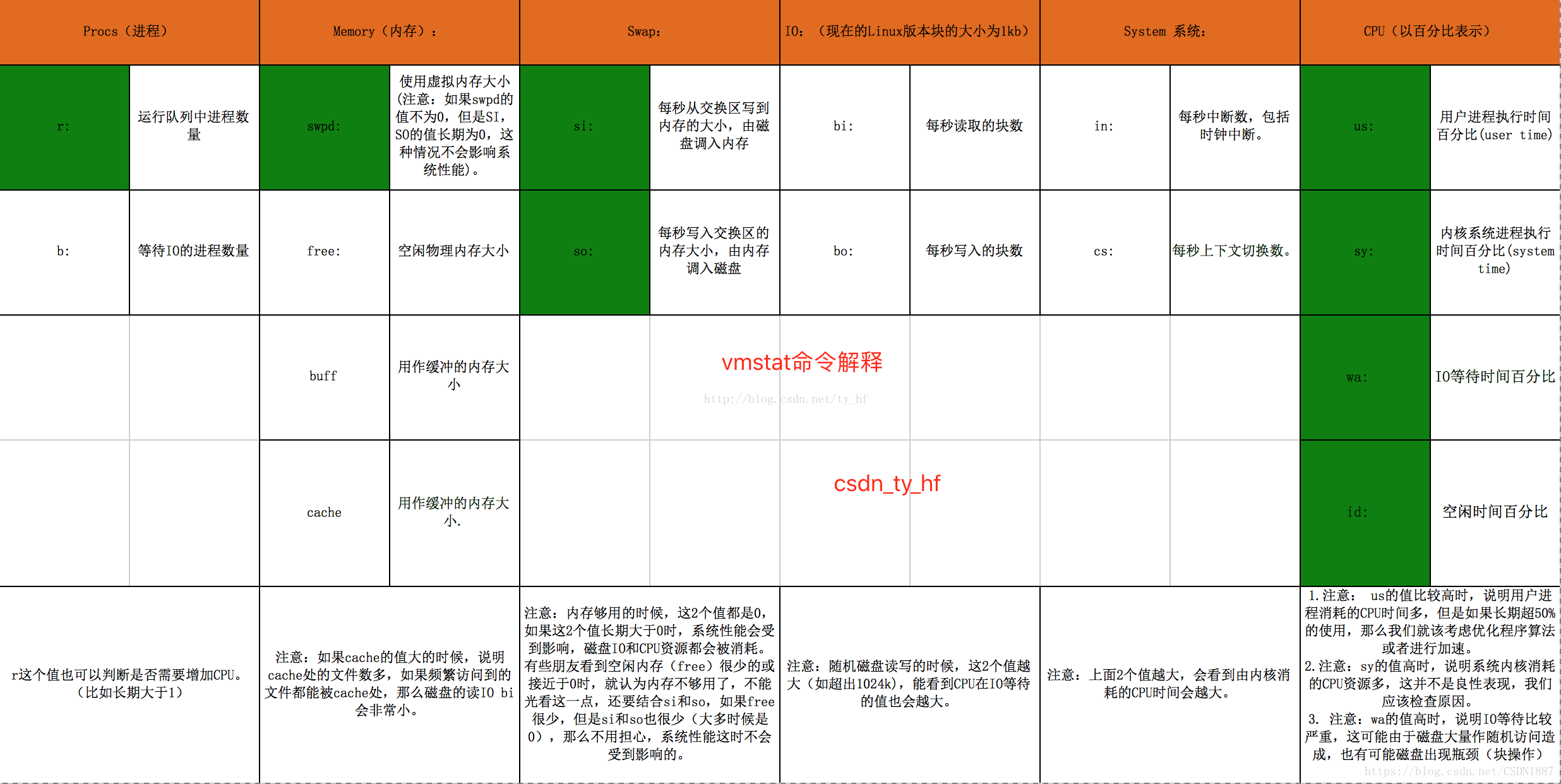
2 vmstat 虚拟内存统计
硬盘读写,除了正常的数据读写还有虚拟内存的交换,所以这个命令可以参考.
在系统中运行的每个进程都需要使用到物理内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。【这就是上边说的内存转换的过程】
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)
vmstat 分几部分procs,memory,swap,io,sysem,cpu
我觉得值得参考的是procs,memory,swap,cpu
procs有r,b参数
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量。
r 当这个值超过了CPU数目,就会出现CPU瓶颈了Memory(内存)
swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。Swap
si: 每秒从交换区写到内存的大小,由磁盘调入内存。
so: 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。cpu
us: 用户进程执行时间百分比(user time)
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)
sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分比
wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比这是某个高手总结的,我拿来抛砖引玉了
3 top
这个命令不用详细说了.很好描述了进程对cpu,mem资源的使用情况
关注cpu,mem,load average,command即可.
常用命令如下
l:切换显示平均负载和启动时间信息。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据驻留内存大小进行排序。
P:根据CPU使用百分比大小进行排序。
T:根据时间/累计时间进行排序。
W:将当前设置写入~/.toprc文件中。
s:改变两次刷新之间的延迟时间4 SAR
SAR是系统活动报告(System Activity Report)英文单词的首字母缩写。正如它的名字所表示的那样,SAR是一个在Unix和Linux操作系统中用来收集、报告和保存。
说实话用到这个命令,才发现好像是万能报告,CPU、内存、IO输入输出,硬件监控及端口传输率等使用情况的命令.当然部分细节没有前述命令描述的详细.
配置文件 centos /etc/sysconfig/sysstat
ubuntu /etc/sysstat/sysstat
常用命令
默认监控: sar 5 5 // CPU和IOWAIT统计状态
(1) sar -b 5 5 // IO传送速率
(2) sar -B 5 5 // 页交换速率
(3) sar -C 5 5 // 进程创建的速率
(4) sar -d 5 5 // 块设备的活跃信息
(5) sar -n DEV 5 5 // 网路设备的状态信息
(6) sar -n SOCK 5 5 // SOCK的使用情况
(7) sar -n ALL 5 5 // 所有的网络状态信息
(8) sar -P ALL 5 5 // 每颗CPU的使用状态信息和IOWAIT统计状态
(9) sar -q 5 5 // 队列的长度(等待运行的进程数)和负载的状态
(10) sar -r 5 5 // 内存和swap空间使用情况
(11) sar -R 5 5 // 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页)
(12) sar -u 5 5 // CPU的使用情况和IOWAIT信息(同默认监控)
(13) sar -v 5 5 // inode, file and other kernel tablesd的状态信息
(14) sar -w 5 5 // 每秒上下文交换的数目
(15) sar -W 5 5 // SWAP交换的统计信息(监控状态同iostat 的si so)
(16) sar -y 5 5 // TTY设备的活动状态
(17) 将输出到文件(-o)和读取记录信息(-f)现在来看能做什么
cpu分析
sar -u 5 5 界面很眼熟,所以不展开
sar -P ALL 每个单核的利用率,更详细了
sar -m CPU 1 1 CPU当前频率
sar -m FAN 风 扇转数
sar -m TEMP 当前cpu温度文件系统利用
sar -F 1 1 MBFree,MBFused,%fsused,%ufsused
统计每个设备的用量,占比,比df -lh更直观吧网络统计
sar -n DEV 每秒接收和发送的字节和包
-n 还可以用NFS,IP,TCP,SOCK等关键字这和netstat -s 功能接近进程队列与负载
sar -q 只是汇总,具体结合top p c m内存
sar -r 只是汇总,结合vmsat 更好当然你还可以来个大杂烩 sar -A .
所以基本上
1 寻找高CPU占用的进程,高mem占用
首选top t 排序 ,top M 排序
2 异常进程读写哪些文件
lsof -c mysql (比如mysql)
3 是否和磁盘瓶颈有关
iostat -x 观察队列和等待时间
vmstat 观察进程排队 r,b
4 网络进程查看
lsof -i tcp|udp lsof i:80|3306
是不是更直观阿
总结,命令是死的,所以应当理性的,多个方面互相印证具体分析.