JMM内存模型
注意这里提到的内存模型和我们在JVM中介绍的内存模型不在同一个层次,JVM中的内存模型是虚拟机规范对整个内存区域的规划,而**Java内存模型,是在JVM内存模型之上的抽象模型,具体实现依然是基于JVM内存模型实现的,**我们会在后面介绍。
Java内存模型
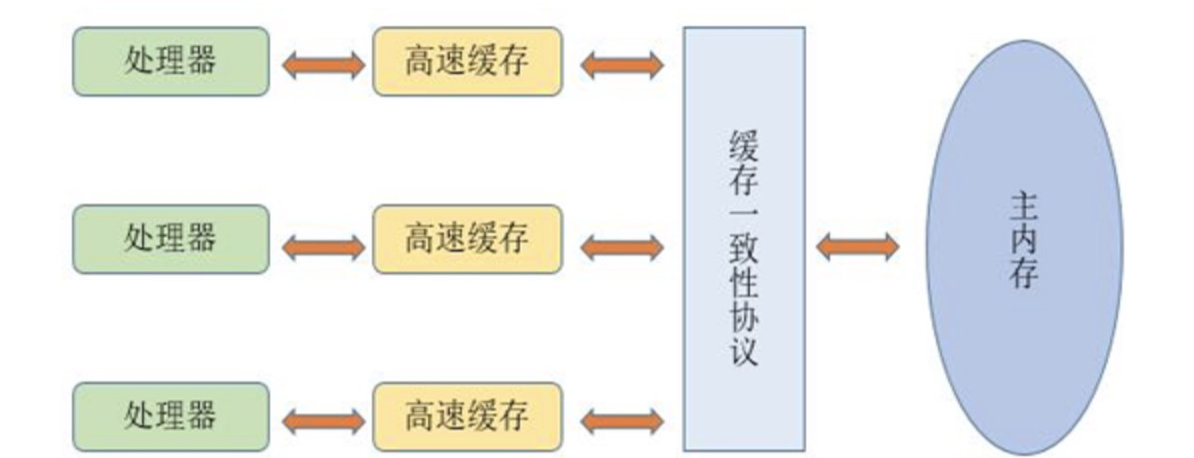
我们在计算机组成原理中学习过,在我们的CPU中,一般都会有高速缓存,而它的出现,是为了解决内存的速度跟不上处理器的处理速度的问题,所以CPU内部会添加一级或多级高速缓存来提高处理器的数据获取效率,但是这样也会导致一个很明显的问题,因为现在基本都是多核心处理器,每个处理器都有一个自己的高速缓存,那么又该怎么去保证每个处理器的高速缓存内容一致呢?
为了解决缓存一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、MESI(Illinois Protocol)、MOSI、Synapse、Firefly及Dragon Protocol等。【这一部分去看小林coding的图解系统】
而Java也采用了类似的模型来实现支持多线程的内存模型:
JMM(Java Memory Model)内存模型规定如下:
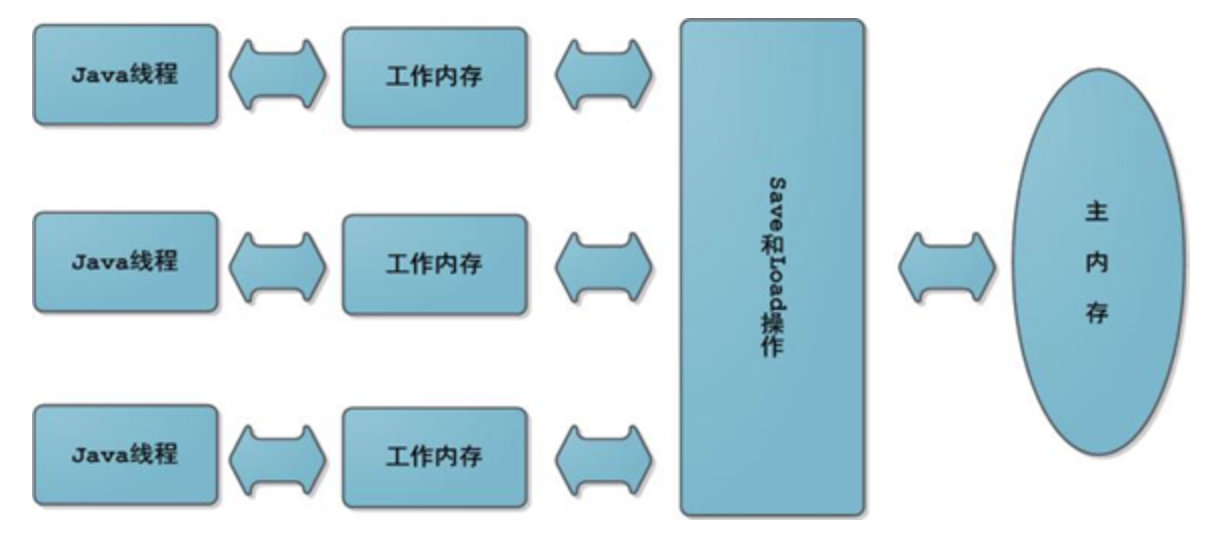
- 所有的变量全部存储在主内存(注意这里包括下面提到的变量,指的都是会出现竞争的变量,包括成员变量、静态变量等,而局部变量(方法体里的变量)这种属于线程私有,不包括在内)
- 每条线程有着自己的工作内存(可以类比CPU多个核心自己的高速缓存)线程对变量的所有操作,必须在工作内存中进行,不能直接操作主内存中的数据。
- 不同线程之间的工作内存相互隔离,如果需要在线程之间传递内容,只能通过主内存完成,无法直接访问对方的工作内存。
也就是说,每一条线程如果要操作主内存中的数据,那么得先拷贝到自己的工作内存中,并对工作内存中数据的副本进行操作,操作完成之后,也需要从工作副本中将结果拷贝回主内存中,具体的操作就是Save(保存)和Load(加载)操作。
那么各位肯定会好奇,这个内存模型,结合之前JVM所讲的内容,具体是怎么实现的呢?
- 主内存:对应堆中存放对象的实例的部分。
- 工作内存:对应线程的虚拟机栈的部分区域,虚拟机可能会对这部分内存进行优化,将其放在CPU的寄存器或是高速缓存中。比如在访问数组时,由于数组是一段连续的内存空间,所以可以将一部分连续空间放入到CPU高速缓存中,那么之后如果我们顺序读取这个数组,那么大概率会直接缓存命中,就不用多次从内存加载数据到缓存,这就是缓存命中率。
前面我们提到,在CPU中可能会遇到缓存不一致的问题,而Java中,也会遇到,比如下面这种情况:
public class Main {
private static int i = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
for (int j = 0; j < 100000; j++) i++;
System.out.println("线程1结束");
}).start();
new Thread(() -> {
for (int j = 0; j < 100000; j++) i++;
System.out.println("线程2结束");
}).start();
//等上面两个线程结束
Thread.sleep(1000);
System.out.println(i);
}
}
可以看到这里是两个线程同时对变量i各自进行100000次自增操作,但是实际得到的结果并不是我们所期望的那样。
输出结果是100000到200000之间,原因就在于Java采用了主内存和工作内存的做法,出现了缓存不一致的情况。
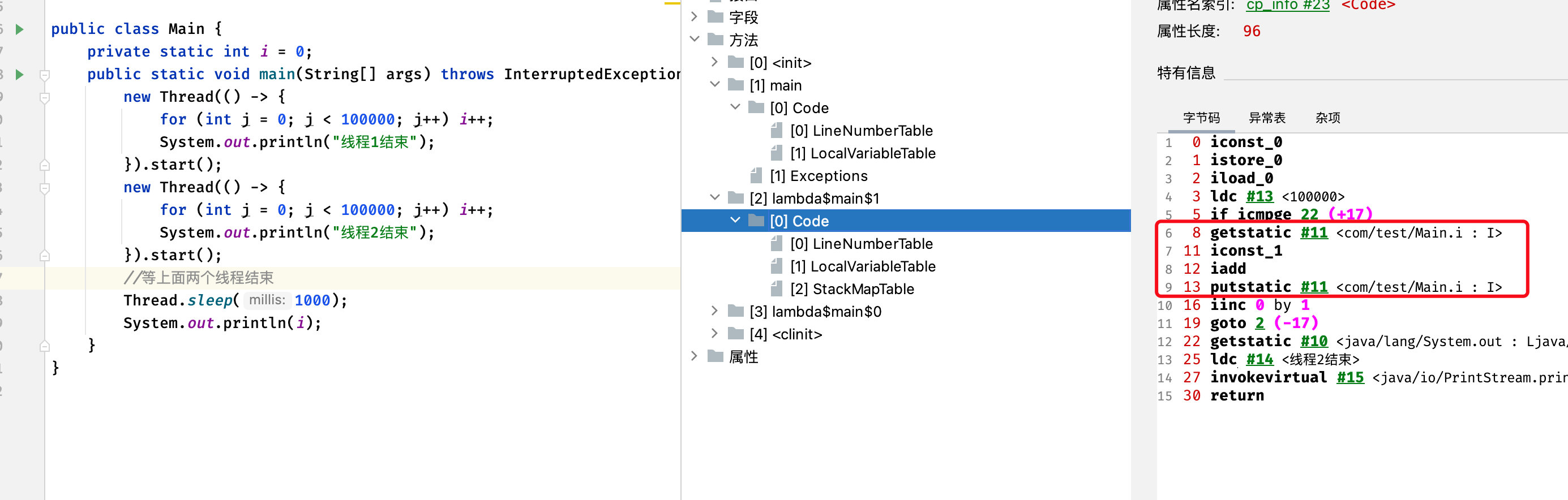
那么为什么会这样呢?在之前学习了JVM之后,相信各位应该已经知道,自增操作实际上并不是由一条指令完成的(注意一定不要理解为一行代码就是一个指令完成的):
包括变量i的获取、修改、保存,都是被拆分为一个一个的操作完成的,那么这个时候就有可能出现在修改完保存之前,另一条线程也保存了,但是当前线程是毫不知情的。
所以说,我们当时在JavaSE阶段讲解这个问题的时候,是通过synchronized关键字添加同步代码块解决的,当然,我们后面还会讲解另外的解决方案(原子类)

重排序
在编译或执行时,为了优化程序的执行效率,编译器或处理器常常会对指令进行重排序,有以下情况:
- 编译器重排序:Java编译器通过对Java代码语义的理解,根据优化规则对代码指令进行重排序。
- 机器指令级别的重排序:现代处理器很高级,能够自主判断和变更机器指令的执行顺序。
指令重排序能够在不改变结果(单线程)的情况下,优化程序的运行效率,比如:
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println(a + b);
}
我们其实可以交换第一行和第二行:
public static void main(String[] args) {
int b = 10;
int a = 20;
System.out.println(a + b);
}
即使发生交换,但是我们程序最后的运行结果是不会变的,当然这里只通过代码的形式演示,实际上JVM在执行字节码指令时也会进行优化,可能两个指令并不会按照原有的顺序进行。
虽然单线程下指令重排确实可以起到一定程度的优化作用,但是在多线程下,似乎会导致一些问题:
public class Main {
private static int a = 0;
private static int b = 0;
public static void main(String[] args) {
new Thread(() -> {
if(b == 1) {
if(a == 0) {
System.out.println("A");
}else {
System.out.println("B");
}
}
}).start();
new Thread(() -> {
a = 1;
b = 1;
}).start();
}
}
上面这段代码,在正常情况下,按照我们的正常思维,是不可能输出A的,因为只要b等于1,那么a肯定也是1才对,因为a是在b之前完成的赋值。但是,如果进行了重排序,那么就有可能,a和b的赋值发生交换,b先被赋值为1,而恰巧这个时候,线程1开始判定b是不是1了,这时a还没来得及被赋值为1,可能线程1就已经走到打印那里去了,所以,是有可能输出A的。
volatile关键字
volatile中文意思:易失的。
好久好久都没有认识新的关键字了,今天我们来看一个新的关键字volatile,开始之前我们先介绍三个词语:
- 原子性:其实之前讲过很多次了,就是要做什么事情要么做完,要么就不做,不存在做一半的情况。
- 可见性:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
- 有序性:即程序执行的顺序按照代码的先后顺序执行。
我们之前说了,如果多线程访问同一个变量,那么这个变量会被线程拷贝到自己的工作内存中进行操作,而不是直接对主内存中的变量本体进行操作,下面这个操作看起来是一个有限循环,但是是无限的:
public class Main {
private static int a = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (a == 0);
System.out.println("线程结束!");
}).start();
Thread.sleep(1000);
System.out.println("正在修改a的值...");
a = 1; //很明显,按照我们的逻辑来说,a的值被修改那么另一个线程将不再循环,但实际上a=1对另外一个线程不可见,因为都在自己的工作内存里
}
}
实际上这就是我们之前说的,虽然我们主线程中修改了a的值,但是另一个线程并不知道a的值发生了改变,所以循环中依然是使用旧值在进行判断,因此,普通变量是不具有可见性的。
要解决这种问题,我们第一个想到的肯定是加锁(对变量a加锁访问),同一时间只能有一个线程使用,这样总行了吧,确实,这样的话肯定是可以解决问题的:
public class Main {
private static int a = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (a == 0) {
synchronized (Main.class){}
}
System.out.println("线程结束!");
}).start();
Thread.sleep(1000);
System.out.println("正在修改a的值...");
synchronized (Main.class){
a = 1;
}
}
}
但是,除了硬加一把锁的方案,我们也可以使用volatile关键字来解决,此关键字的第一个作用,就是保证变量的可见性。当写一个volatile变量时,JMM会把该线程本地内存中的变量强制刷新到主内存中去,并且这个写会操作会导致其他线程中的volatile变量缓存无效,这样,另一个线程修改了这个变时,当前线程会立即得知,并将工作内存中的变量更新为最新的版本。
那么我们就来试试看:
public class Main {
//添加volatile关键字
private static volatile int a = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (a == 0);
System.out.println("线程结束!");
}).start();
Thread.sleep(1000);
System.out.println("正在修改a的值...");
a = 1;
}
}
结果还真的如我们所说的那样,当a发生改变时,循环立即结束。
当然,虽然说volatile能够保证可见性,**但是不能保证原子性,**要解决我们上面的i++的问题,以我们目前所学的知识,还是只能使用加锁来完成:
public class Main {
private static volatile int a = 0;
public static void main(String[] args) throws InterruptedException {
Runnable r = () -> {
for (int i = 0; i < 10000; i++) a++;
System.out.println("任务完成!");
};
new Thread(r).start();
new Thread(r).start();
//等待线程执行完成
Thread.sleep(1000);
System.out.println(a);
}
}
运行结果:
任务完成!
任务完成!
11622
不对啊,volatile不是能在改变变量的时候其他线程可见吗,那为什么还是不能保证原子性呢?还是那句话,自增操作是被瓜分为了多个步骤完成的,虽然保证了可见性,但是只要手速够快,依然会出现两个线程同时写同一个值的问题(比如线程1刚刚将a的值更新为100,这时线程2可能也已经执行到更新a的值这条指令了(虽然线程1那边的结果100可见,但是线程2早一步获取了a的值还是99),已经刹不住车了,所以依然会将a的值再更新为一次100)
那要是真的遇到这种情况,那么我们不可能都去写个锁吧?后面,我们会介绍原子类来专门解决这种问题。
最后一个功能就是volatile会禁止指令重排,也就是说,如果我们操作的是一个volatile变量,它将不会出现重排序的情况,也就解决了我们最上面的问题。(重排序小节最后那个例子,如果a,b变量使用了这个关键字,那就不会发生指令重排,那就不可能输出A。)
那么它是怎么解决的重排序问题呢?若用volatile修饰共享变量(成员变量、静态变量),在编译时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
下面引用部分了解就行。
内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
- 保证特定操作的顺序
- 保证某些变量的内存可见性(volatile的内存可见性,其实就是依靠这个实现的)
由于编译器和处理器都能执行指令重排的优化,如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序。
屏障类型 指令示例 说明 LoadLoad Load1;LoadLoad;Load2 保证Load1的读取操作在Load2及后续读取操作之前执行 StoreStore Store1;StoreStore;Store2 在Store2及其后的写操作执行前,保证Store1的写操作已刷新到主内存 LoadStore Load1;LoadStore;Store2 在Store2及其后的写操作执行前,保证Load1的读操作已读取结束 StoreLoad Store1;StoreLoad;Load2 保证load1的写操作已刷新到主内存之后,load2及其后的读操作才能执行

所以volatile能够保证,之前的指令一定全部执行,之后的指令一定都没有执行,并且前面语句的结果对后面的语句可见。
最后我们来总结一下volatile关键字的三个特性:
- 保证可见性
- 不保证原子性
- 防止指令重排
之后在写设计模式的博客中在看单例模式下volatile的运用。
happens-before原则
经过我们前面的讲解,相信各位已经了解了JMM内存模型以及重排序等机制带来的优点(提高执行效率)和缺点(多线程下可能导致错误),综上,JMM提出了happens-before(先行发生)原则,定义一些禁止编译优化的场景,来向各位程序员做一些保证,只要我们是按照原则进行编程,那么就能够保持并发编程的正确性。具体如下:
-
程序次序规则:同一个线程中,按照程序的顺序,前面的操作happens-before后续的任何操作。
同一个线程内,代码的执行结果是有序的。其实就是,可能会发生指令重排,但是保证代码的执行结果一定是和按照顺序执行得到的一致, 程序前面对某一个变量的修改一定对后续操作可见的,不可能会出现前面才把a修改为1,接着读a居然是修改前的结果,这也是程序运行最基本的要求。 -
监视器锁规则:对一个锁的解锁操作,happens-before后续对这个锁的加锁操作。
就是无论是在单线程环境还是多线程环境,对于同一个锁来说,一个线程对这个锁解锁之后,另一个线程获取了这个锁都能看到前一个线程的操作结果。比如前一个线程将变量x的值修改为了12并解锁,之后另一个线程拿到了这把锁,对之前线程的操作是可见的,可以得到x是前一个线程修改后的结果12(所以synchronized是有happens-before规则的) -
volatile变量规则:对一个volatile变量的写操作happens-before后续对这个变量的读操作。
就是如果一个线程先去写一个volatile变量,紧接着另一个线程去读这个变量,那么这个写操作的结果一定对读的这个变量的线程可见。 -
线程启动规则:主线程A启动线程B,线程B中可以看到主线程启动B之前的操作。
在主线程A执行过程中,启动子线程B,那么线程A在启动子线程B之前对共享变量的修改结果对线程B可见。 -
线程加入规则:如果线程A执行操作
join()线程B并成功返回,那么线程B中的任意操作happens-before线程Ajoin()操作成功返回。 -
传递性规则:如果A happens-before B,B happens-before C,那么A happens-before C。
那么我们来从happens-before原则的角度,来解释一下下面的程序结果:
public class Main {
private static int a = 0;
private static int b = 0;
public static void main(String[] args) {
a = 10;
b = a + 1;
new Thread(() -> {
if(b > 10) System.out.println(a);
}).start();
}
}
首先我们定义以上出现的操作:
- A:将变量
a的值修改为10 - B:将变量
b的值修改为a + 1 - C:主线程启动了一个新的线程,并在新的线程中获取
b,进行判断,如果为true那么就打印a
首先我们来分析,由于是同一个线程,并且B是一个赋值操作且读取了A,那么按照程序次序规则,A happens-before B,接着在B之后,马上执行了C,按照线程启动规则,在新的线程启动之前,当前线程之前的所有操作对新的线程是可见的,所以 B happens-before C,最后根据传递性规则,由于A happens-before B,B happens-before C,所以A happens-before C,因此在新的线程中会输出a修改后的结果10。(其实这个原则就是保证程序执行逻辑和正常思维一致,不至于程序员在写代码时还要考虑一系列的指令重排或可见问题,大大降低了写程序的难度。所以对于这些规则完全不用去背,用到的时候就查一下,这就是为啥它叫八股文,只是应付面试。)